展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Deep Learning with DL4J
on Apache Spark: Yeah
it's Cool, but are You
Doing it the Right Way?
Guglielmo Iozzia, MSD
#UnifiedDataAnalytics #SparkAISummit
�
3 .About Me
Currently at
Previously at
Author at Packt Publishing
Got some awards lately
Champion I love cooking
3
#UnifiedDataAnalytics #SparkAISummit #GuglielmoIozzia
�
4 .MSD in ireland
+ 50 years
Approx. 2,000 employees
2017 + 300 jobs & €280m investment
MSD Biotech, Dublin, coming in 2021
$2.5 billion investment to date
€6.1 billion turnover in 2017
Approx 50% MSD’s top 20 products manufactured here
Export to + 60 countries
#UnifiedDataAnalytics #SparkAISummit 4
�
5 .The Dublin Tech Hub
#UnifiedDataAnalytics #SparkAISummit 5
�
6 .Deep Learning
It is a subset of machine learning where
artificial neural networks, algorithms
inspired by the human brain, learn from
large amounts of data.
6
#UnifiedDataAnalytics #SparkAISummit
�
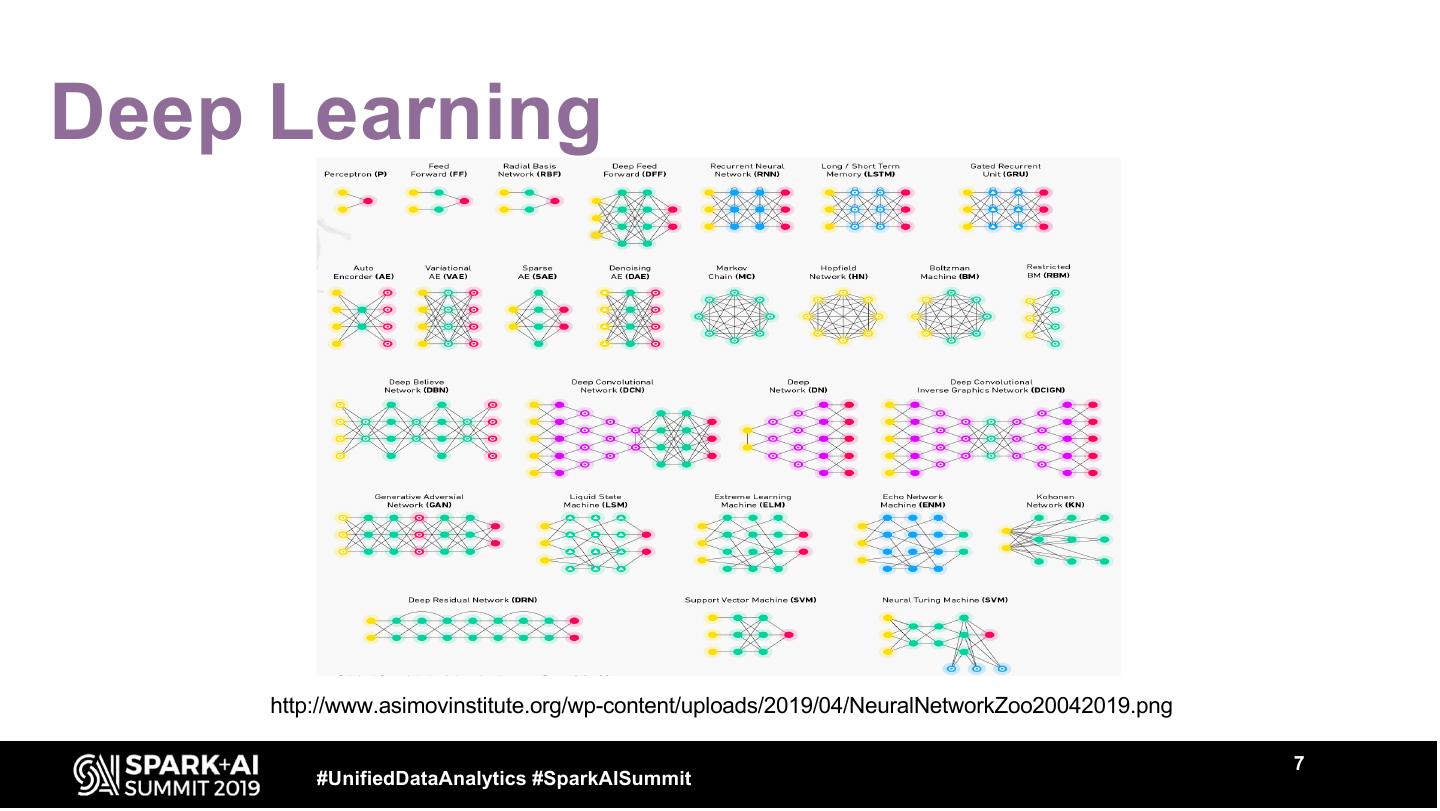
7 .Deep Learning
http://www.asimovinstitute.org/wp-content/uploads/2019/04/NeuralNetworkZoo20042019.png
7
#UnifiedDataAnalytics #SparkAISummit
�
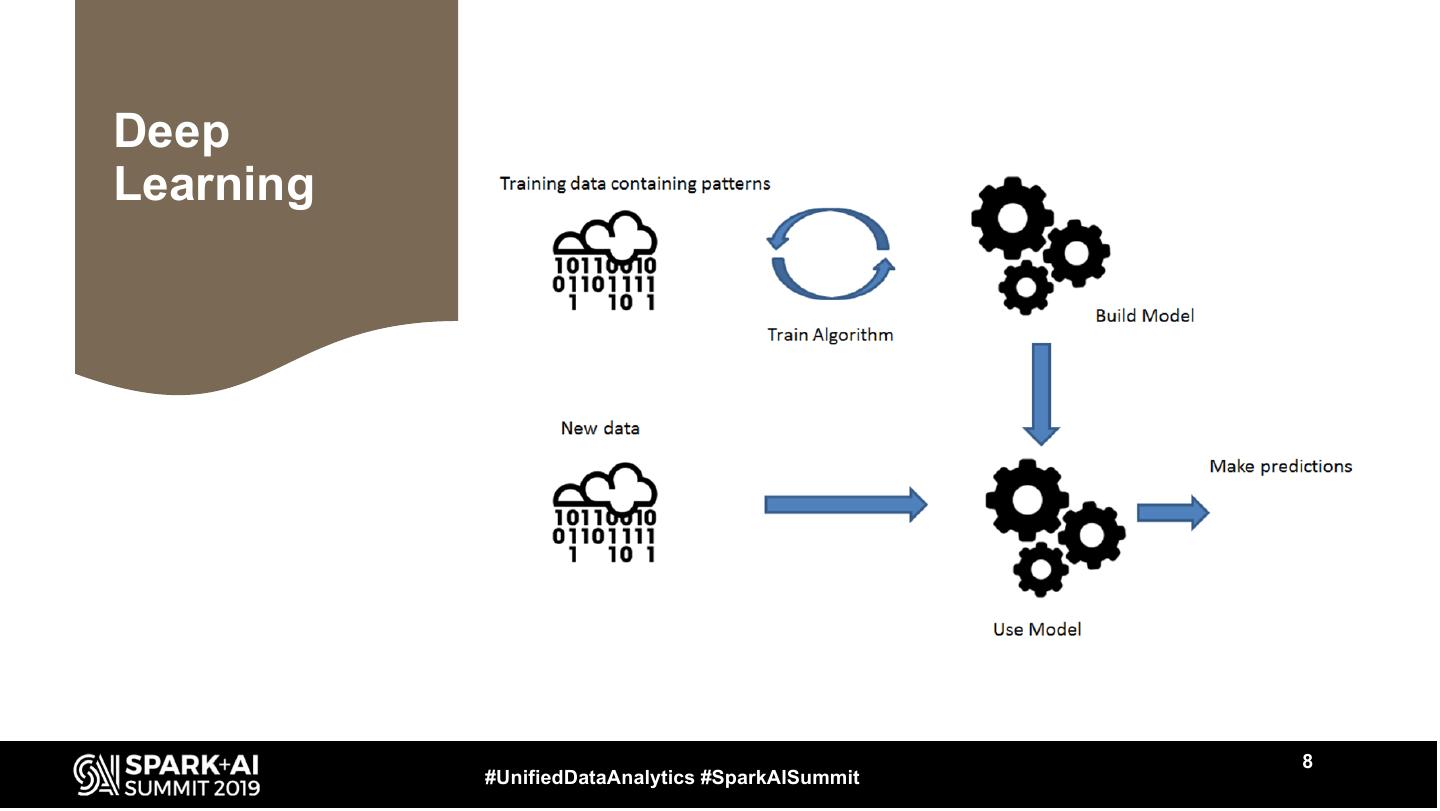
8 .Deep
Learning
8
#UnifiedDataAnalytics #SparkAISummit
�
9 .Some practical applications of
Deep Learning
• Computer vision
• Text generation
• NLP and NLU
• Autonomous cars
• Robotics
• Gaming
• Quantitative finance
• Manufacturing
#UnifiedDataAnalytics #SparkAISummit 9
�
10 .Challenges of training MNNs in
Spark
• Different execution models between Spark and
the DL frameworks
• GPU configuration and management
• Performance
• Accuracy
#UnifiedDataAnalytics #SparkAISummit 10
�
11 . DeepLearning4J
It is integrated with Hadoop
and Apache Spark.
It is an Open Source, distributed,
Deep Learning framework written
for JVM languages.
It can be used on distributed
GPUs and CPUs.
#UnifiedDataAnalytics #SparkAISummit 11
�
12 .DL4J modules
• DataVec
• Arbiter
• NN
• Datasets
• RL4J
• DL4J-Spark
• Model Import
• ND4J
#UnifiedDataAnalytics #SparkAISummit 12
�
13 .DL4J Code Example
Training and Evaluation
Network
Configuration
#UnifiedDataAnalytics #SparkAISummit 13
�
14 .ND4J
It is an Open Source linear algebra and
matrix manipulation library which supports
n-dimensional arrays and it is integrated
with Apache Hadoop and Spark.
14
#UnifiedDataAnalytics #SparkAISummit
�
15 .ND4J Code Example
#UnifiedDataAnalytics #SparkAISummit 15
�
16 .Why Distributed MNN Training
with DL4J and Apache Spark?
Why this is a powerful combination?
#UnifiedDataAnalytics #SparkAISummit 16
�
17 .DL4J + Apache Spark
• DL4J provides high level API to design, configure, train and
evaluate MNNs.
• Spark performances are excellent in particular for ETL/streaming,
but in terms of computation, in a MNN training context, some data
transformation/aggregation need to be done using a low-level
language.
• DL4J uses ND4J, which is a C++ library that provides high level
Scala API to developers.
#UnifiedDataAnalytics #SparkAISummit 17
�
18 .DL4J + Apache Spark
Model Parallelization Data Parallelization
#UnifiedDataAnalytics #SparkAISummit 18
�
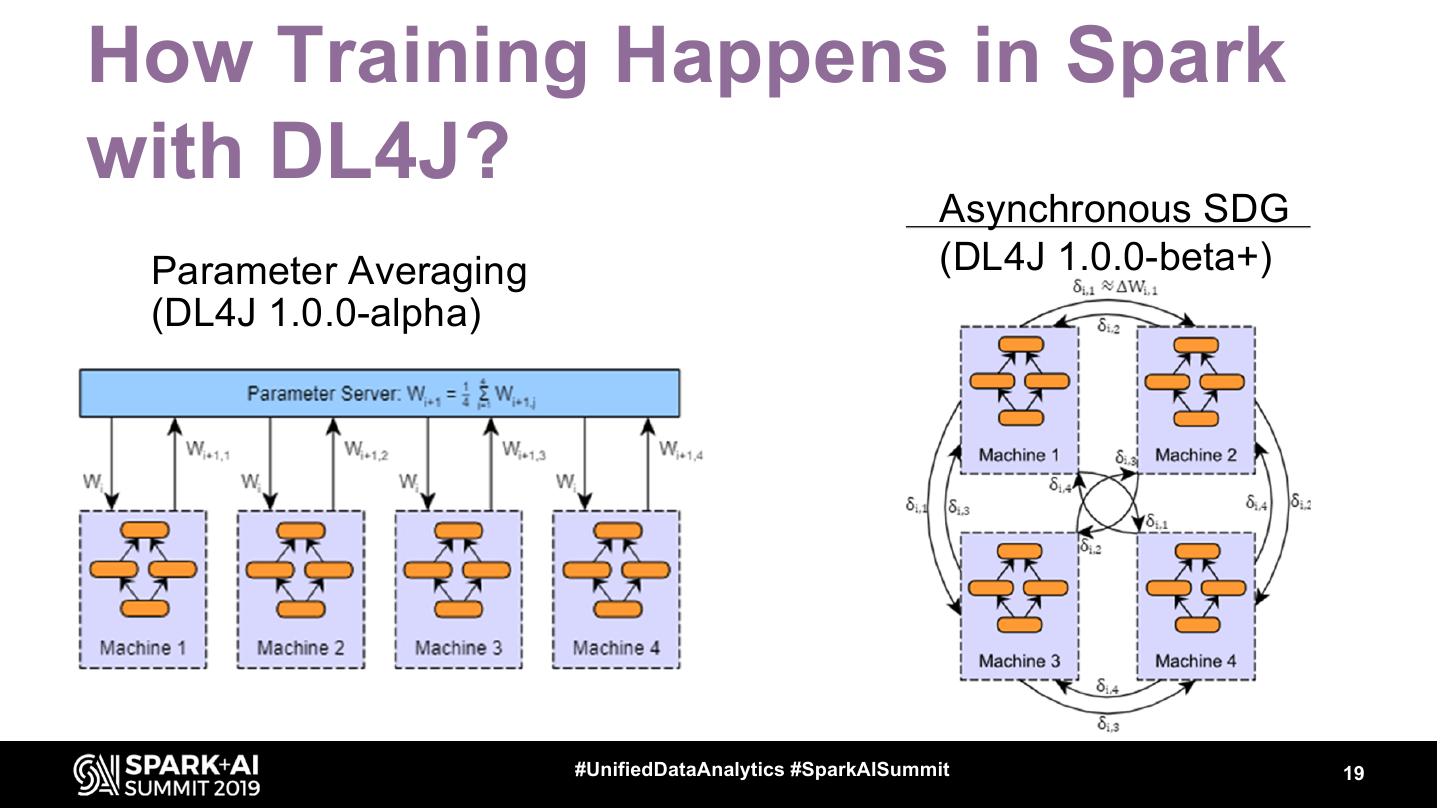
19 .How Training Happens in Spark
with DL4J?
Asynchronous SDG
Parameter Averaging (DL4J 1.0.0-beta+)
(DL4J 1.0.0-alpha)
#UnifiedDataAnalytics #SparkAISummit 19
�
20 .So: What could possibly go wrong?
#UnifiedDataAnalytics #SparkAISummit 20
�
21 .Memory
Management
And now, for something
(a little bit) different.
#UnifiedDataAnalytics #SparkAISummit 21
�
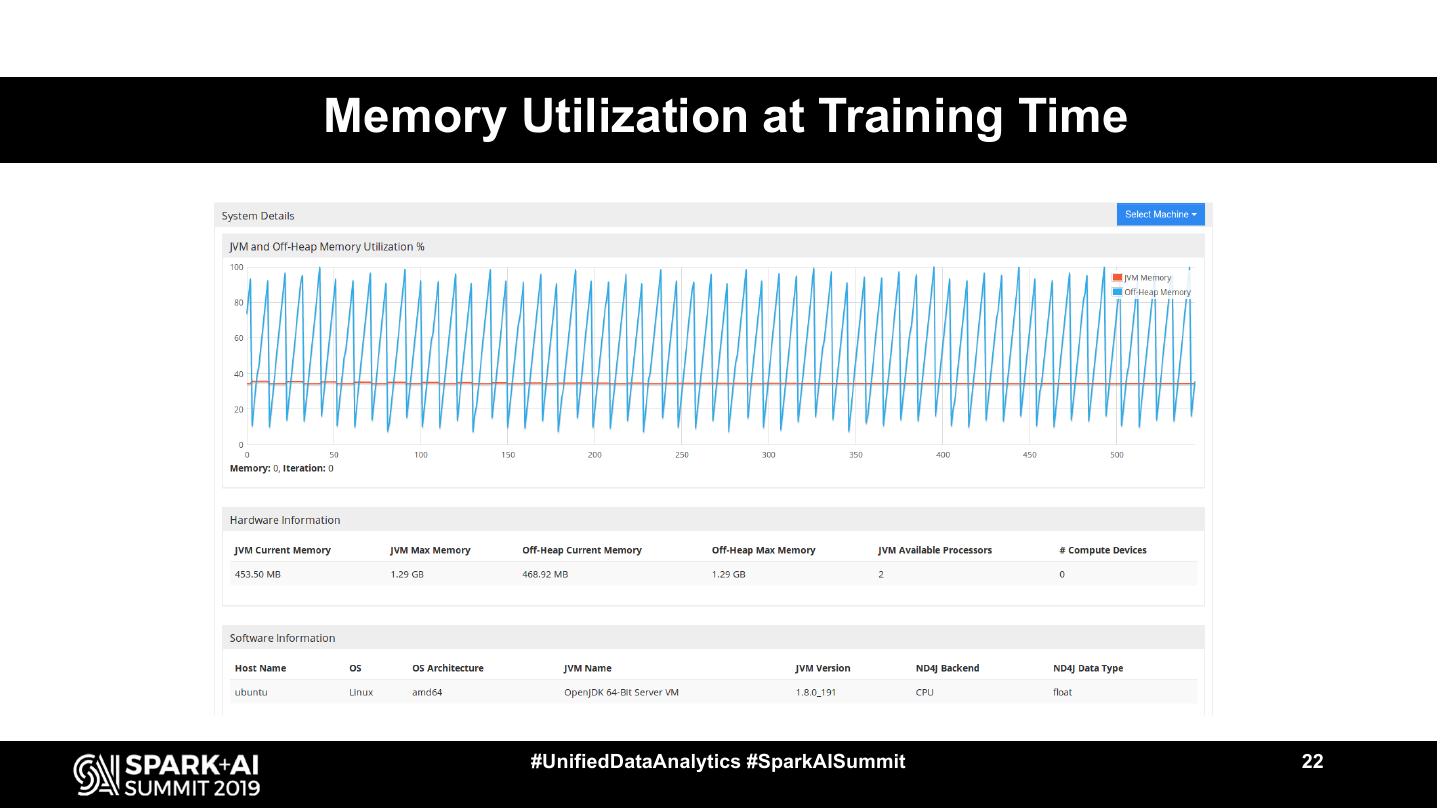
22 .Memory Utilization at Training Time
#UnifiedDataAnalytics #SparkAISummit 22
�
23 .Memory Management in DL4J
Memory allocations can be managed using two different approaches:
• JVM GC and WeakReference tracking
• MemoryWorkspaces
The idea behind both is the same:
once a NDArray is no longer required, the off-heap memory associated
with it should be released so that it can be reused.
#UnifiedDataAnalytics #SparkAISummit 23
�
24 .Memory Management in DL4J
The difference between the two approaches is:
• JVM GC: when a INDArray is collected by the garbage collector, its
off-heap memory is deallocated, with the assumption that it is not
used elsewhere.
• MemoryWorkspaces: when a INDArray leaves the workspace
scope, its off-heap memory may be reused, without deallocation
and reallocation.
Better performance for training and inference.
#UnifiedDataAnalytics #SparkAISummit 24
�
25 .Memory Management in DL4J
Please remember that, when a training process uses
workspaces, in order to get the most from this approach,
periodic GC calls need to be disabled:
Nd4j.getMemoryManager.togglePeriodicGc(false)
or their frequency needs to be reduced:
val gcInterval = 10000 // In milliseconds
Nd4j.getMemoryManager.setAutoGcWindow(gcInterval)
#UnifiedDataAnalytics #SparkAISummit 25
�
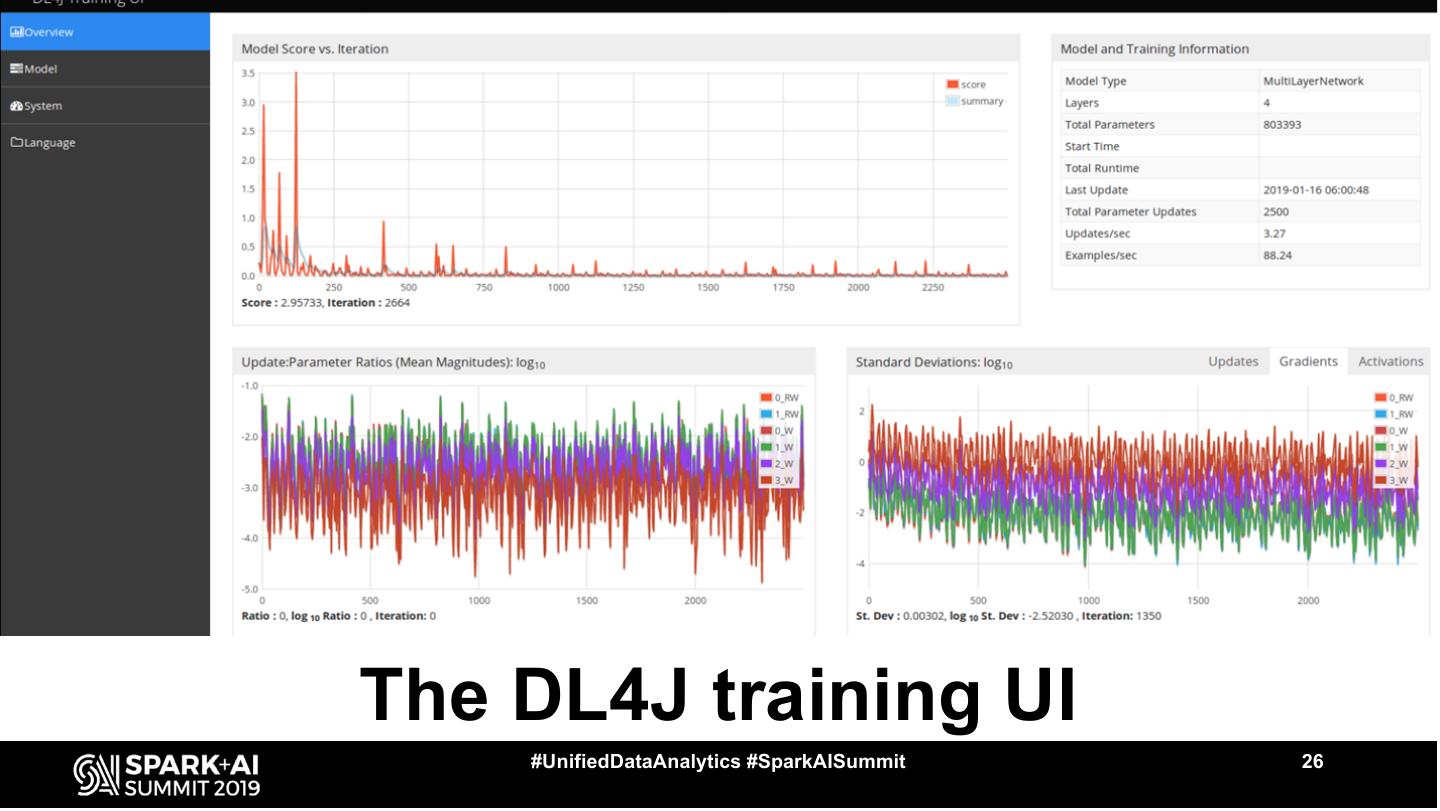
26 .The DL4J training UI
#UnifiedDataAnalytics #SparkAISummit 26
�
27 .Root Cause and Potential
Solutions
Dependencies conflict between the DL4J-UI library and
Apache Spark when running in the same JVM.
Two alternatives are available:
• Collect and save the relevant training stats at runtime,
and then visualize them offline later.
• Execute the UI and use its remote functionality into
separate JVMs (servers). Metrics are uploaded from
the Spark master to the UI server.
#UnifiedDataAnalytics #SparkAISummit 27
�
28 .Serialization & ND4J
Data Serialization is the process of converting the
in-memory objects to another format that can be
used to store or send them over the network.
Two options available in Spark:
• Java (default)
• Kryo
#UnifiedDataAnalytics #SparkAISummit 28
�
29 .Do You Opt for Kryo?
Kryo doesn’t work well with
off-heap data structures.
#UnifiedDataAnalytics #SparkAISummit 29
�