展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Deep Learning Pipelines
for High Energy Physics
using Apache Spark with
Distributed Keras and
Analytics Zoo
Luca Canali, CERN
#UnifiedDataAnalytics #SparkAISummit
�
3 .About Luca
• Data Engineer at CERN
– Hadoop and Spark service, database services
– 19+ years of experience with data engineering
• Sharing and community
– Blog, notes, tools, contributions to Apache Spark
@LucaCanaliDB – http://cern.ch/canali
#UnifiedDataAnalytics #SparkAISummit 3
�
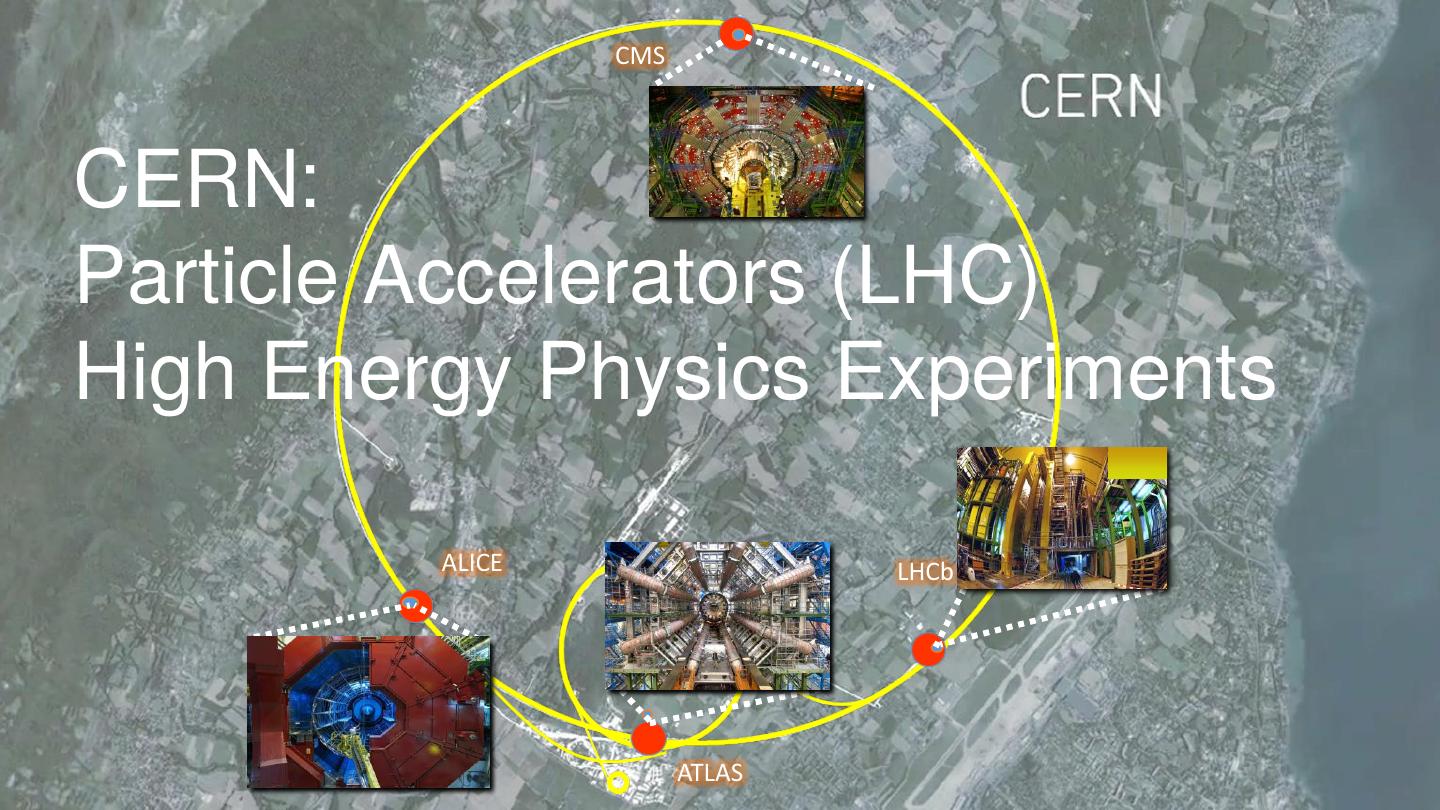
4 . CMS
CERN:
Particle Accelerators (LHC)
High Energy Physics Experiments
ALICE LHCb
ATLAS
�
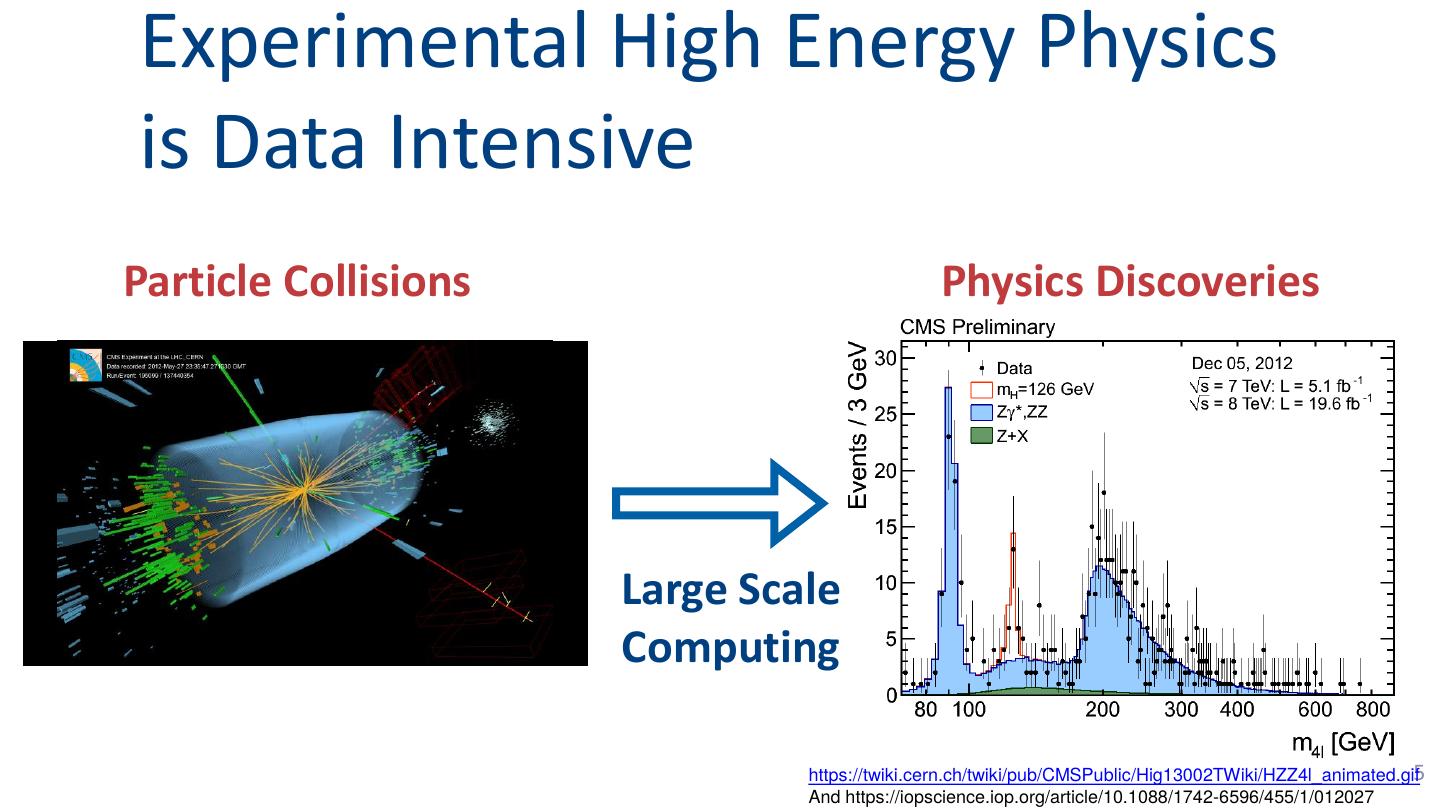
5 .Experimental High Energy Physics
is Data Intensive
Particle Collisions Physics Discoveries
Large Scale
Computing
https://twiki.cern.ch/twiki/pub/CMSPublic/Hig13002TWiki/HZZ4l_animated.gif5
And https://iopscience.iop.org/article/10.1088/1742-6596/455/1/012027
�
6 .Key Data Processing Challenge
• Proton-proton collisions at LHC experiments happen at 40MHz.
• Hundreds of TB/s of electrical signals that allow physicists to investigate
particle collision events.
• Storage, limited by bandwidth
• Currently, only 1 every ~40K events stored to disk (~10 GB/s).
2018: 5 collisions/beam cross 2026: 400 collisions/beam cross
Current LHC Future: High-Luminosity LHC upgrade
�
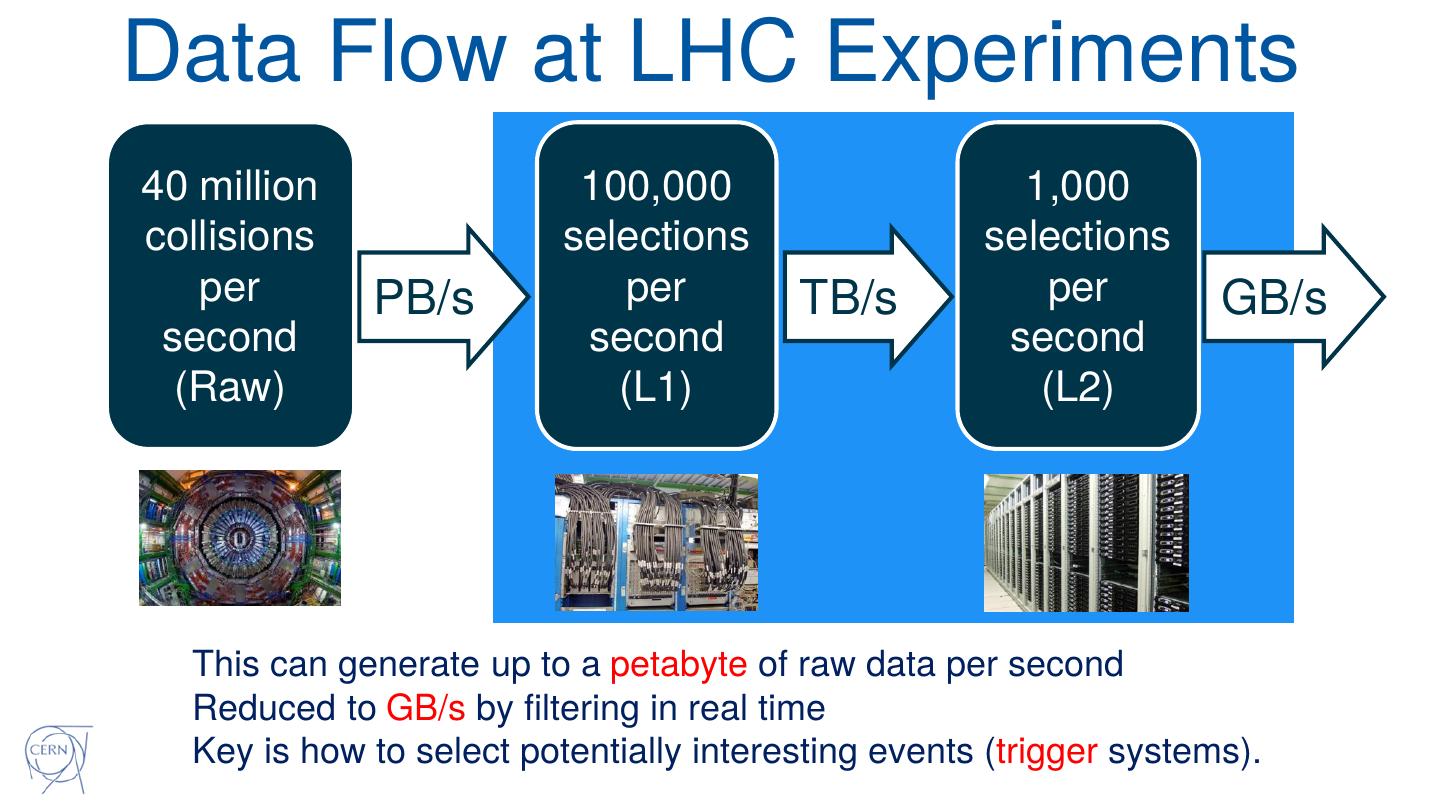
7 .Data Flow at LHC Experiments
40 million 100,000 1,000
collisions selections selections
per PB/s per TB/s per GB/s
second second second
(Raw) (L1) (L2)
This can generate up to a petabyte of raw data per second
Reduced to GB/s by filtering in real time
Key is how to select potentially interesting events (trigger systems).
�
8 .R&D – Data Pipelines
• Improve the quality of filtering systems
• Reduce false positive rate
• From rule-based algorithms to classifiers based on
Deep Learning
• Advanced analytics at the edge
• Avoid wasting resources in offline computing
• Reduction of operational costs
�
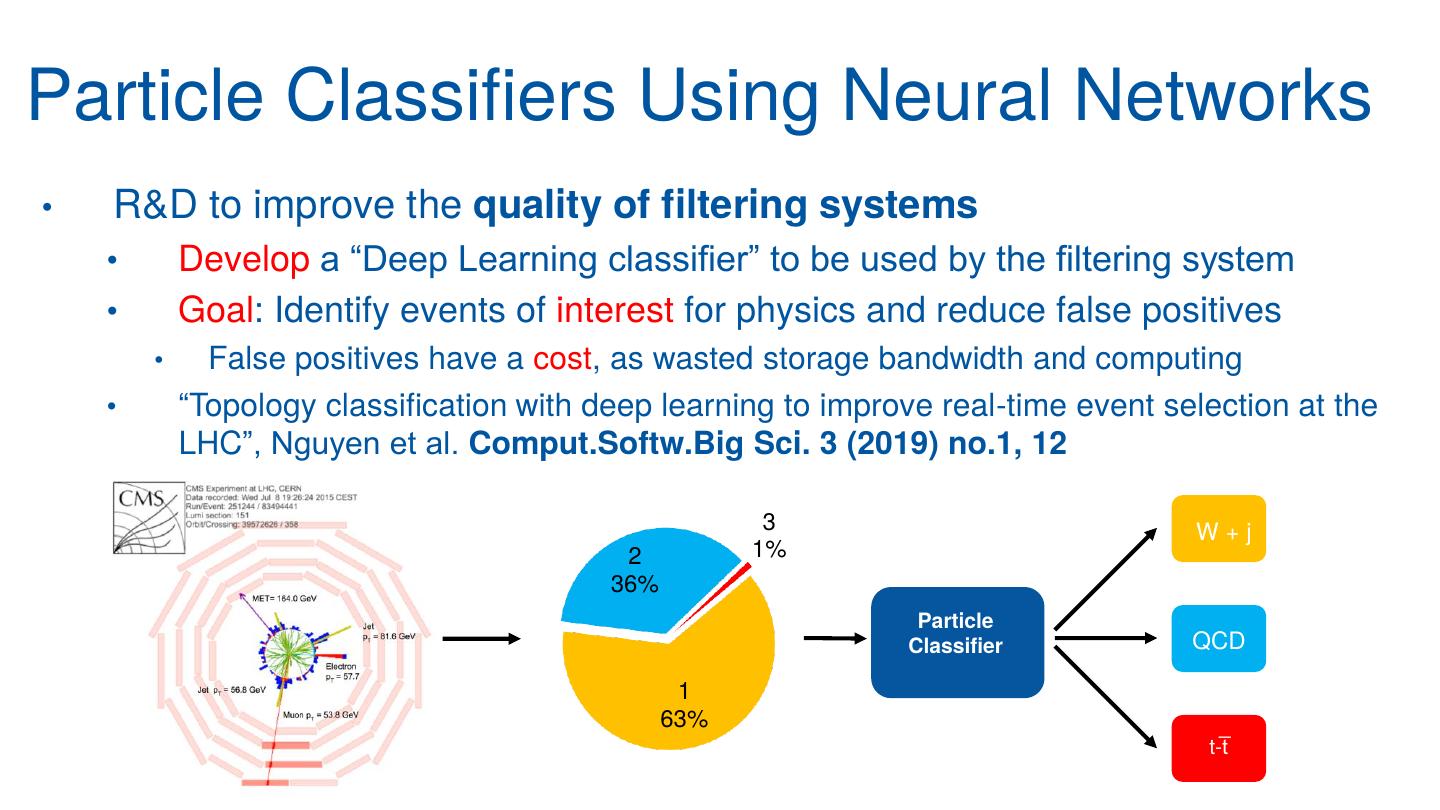
9 .Particle Classifiers Using Neural Networks
• R&D to improve the quality of filtering systems
• Develop a “Deep Learning classifier” to be used by the filtering system
• Goal: Identify events of interest for physics and reduce false positives
• False positives have a cost, as wasted storage bandwidth and computing
• “Topology classification with deep learning to improve real-time event selection at the
LHC”, Nguyen et al. Comput.Softw.Big Sci. 3 (2019) no.1, 12
3 W+j
2 1%
36%
Particle
Classifier QCD
1
63%
t-t̅
�
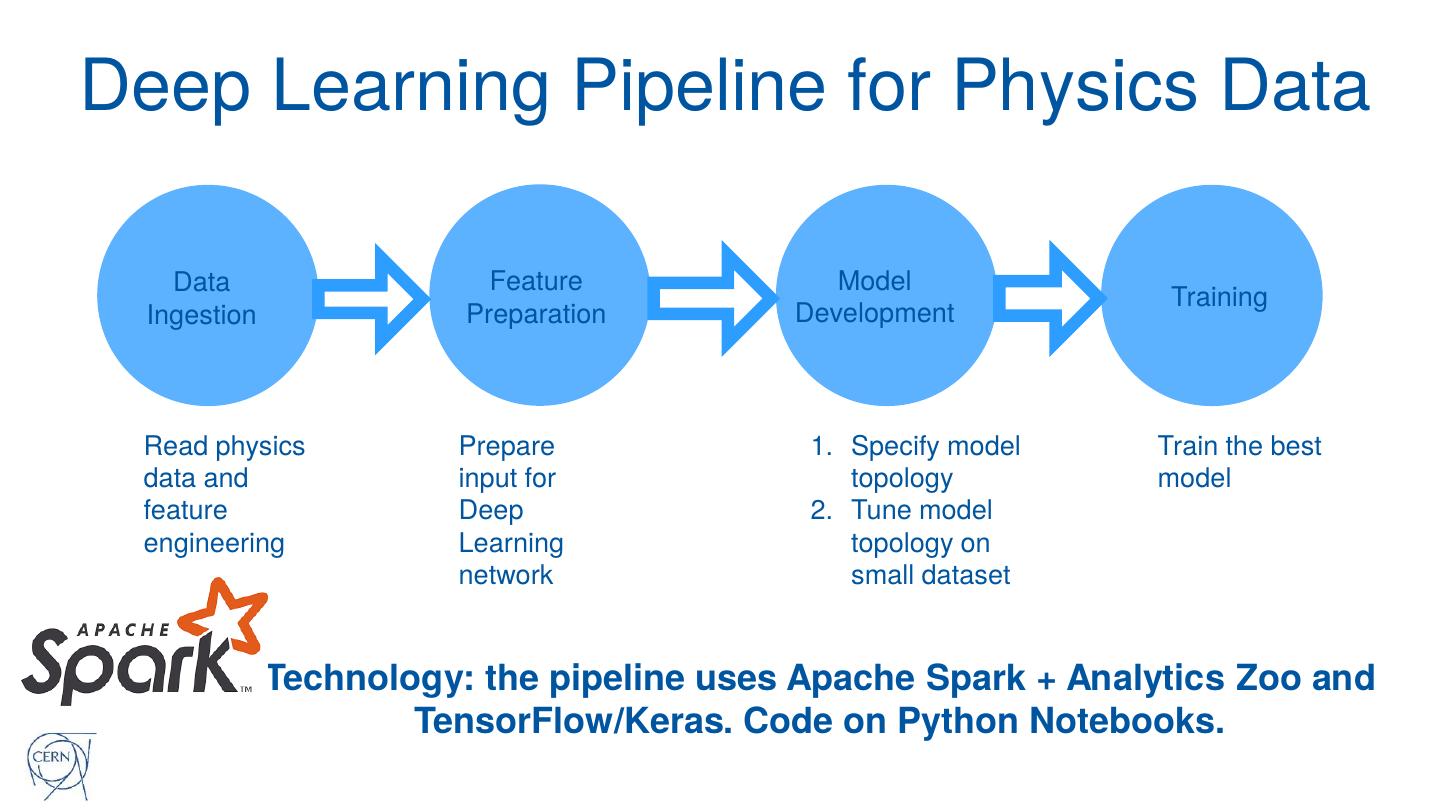
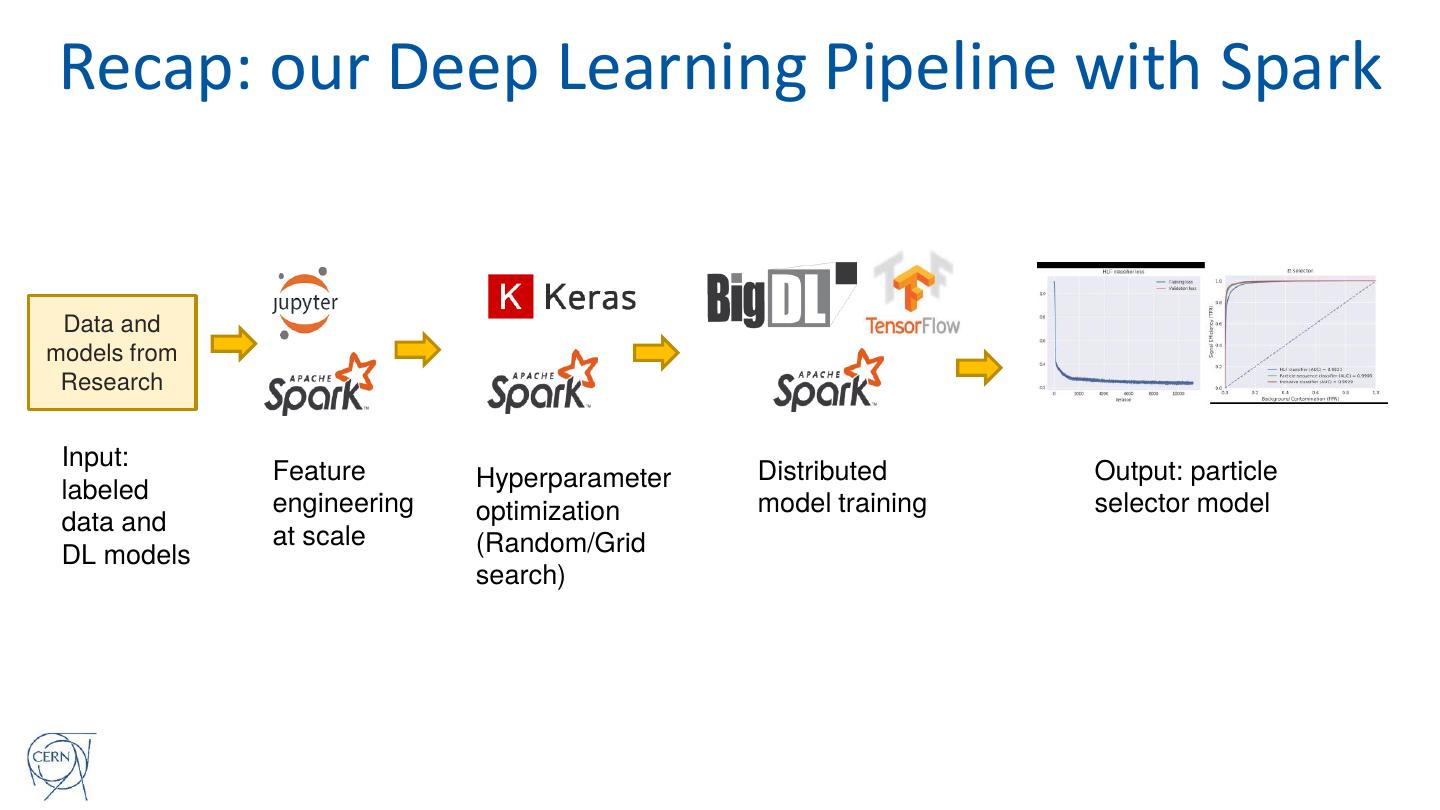
10 .Deep Learning Pipeline for Physics Data
Data Feature Model
Training
Ingestion Preparation Development
Read physics Prepare 1. Specify model Train the best
data and input for topology model
feature Deep 2. Tune model
engineering Learning topology on
network small dataset
Technology: the pipeline uses Apache Spark + Analytics Zoo and
TensorFlow/Keras. Code on Python Notebooks.
�
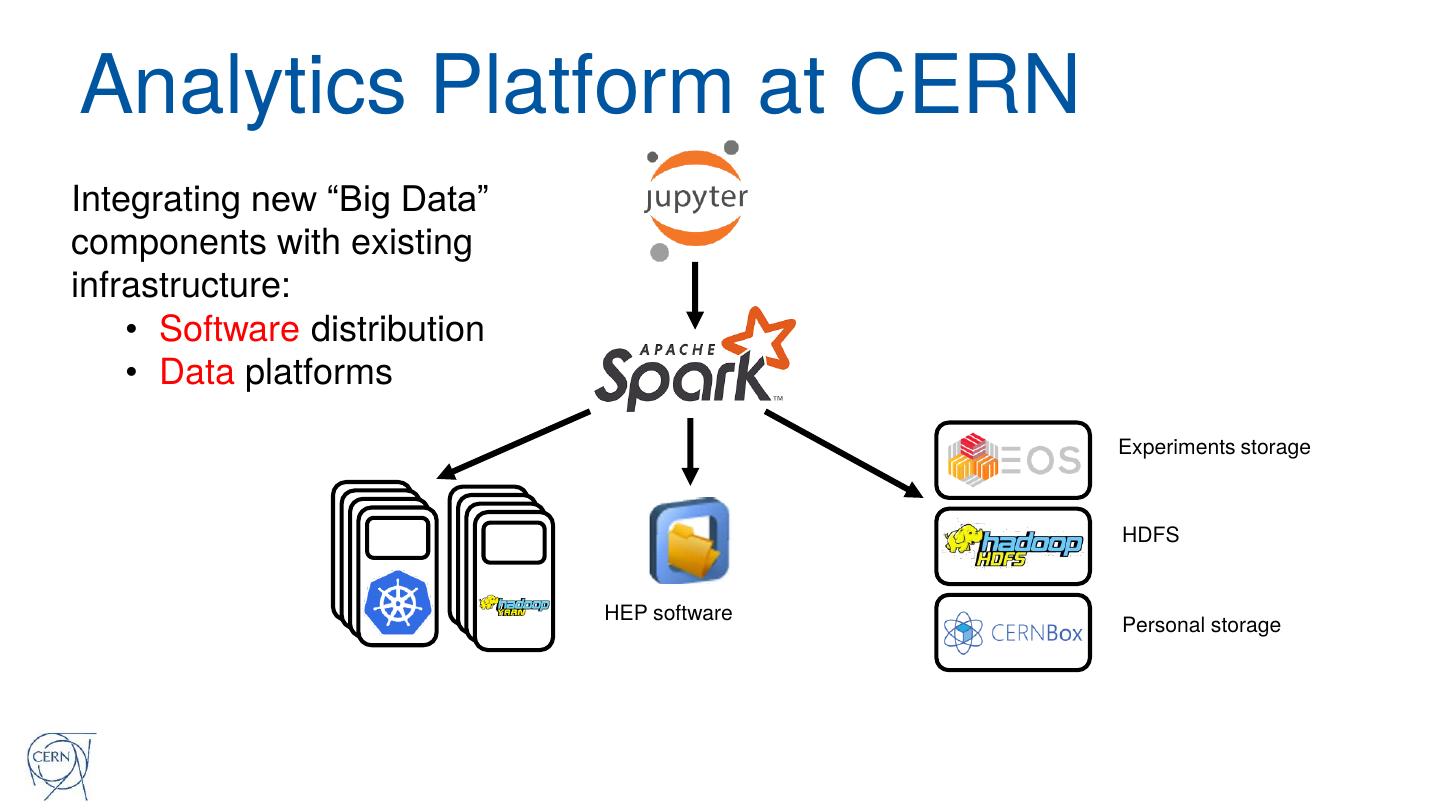
11 .Analytics Platform at CERN
Integrating new “Big Data”
components with existing
infrastructure:
• Software distribution
• Data platforms
Experiments storage
HDFS
HEP software
Personal storage
�
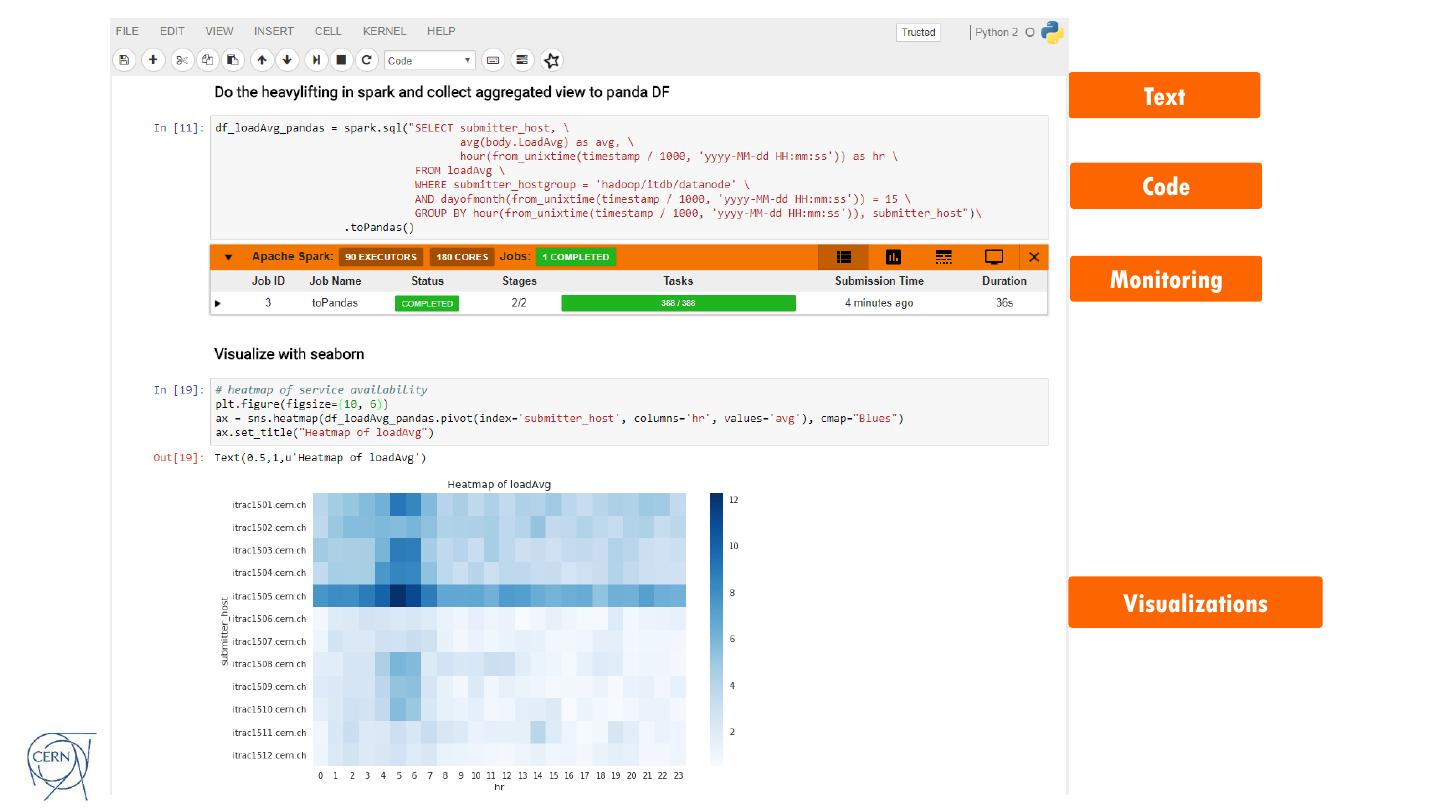
12 . Text
Code
Monitoring
Visualizations
�
13 .Hadoop and Spark Clusters at CERN
• Clusters:
• YARN/Hadoop
• Spark on Kubernetes
• Hardware: Intel based servers, continuous refresh and capacity expansion
Accelerator logging Hadoop - YARN - 30 nodes
(part of LHC (Cores - 1200, Mem - 13 TB, Storage – 7.5 PB)
infrastructure)
General Purpose Hadoop - YARN, 65 nodes
(Cores – 2.2k, Mem – 20 TB, Storage – 12.5 PB)
Cloud containers Kubernetes on Openstack VMs, Cores - 250, Mem – 2 TB
Storage: remote HDFS or EOS (for physics data)
�
14 . Extending Spark to Read Physics Data
• Physics data
• Currently: >300 PBs of Physics data, increasing ~90 PB/year
• Stored in the CERN EOS storage system in ROOT Format and
accessible via XRootD protocol
• Integration with Spark ecosystem
• Hadoop-XRootD connector, HDFS compatible filesystem
• Spark Datasource for ROOT format
C++ Java
https://github.com/cerndb/hadoop-xrootd
EOS Hadoop
https://github.com/diana-hep/spark-root Storage HDFS
Service XRootD Hadoop- API
JNI XRootD
Client
Connector
�
15 .Labeled Data for Training and Test
● Simulated events
● Software simulators are used to generate events
and calculate the detector response
● Raw data contains arrays of simulated particles
and their properties, stored in ROOT format
● 54 million events
�
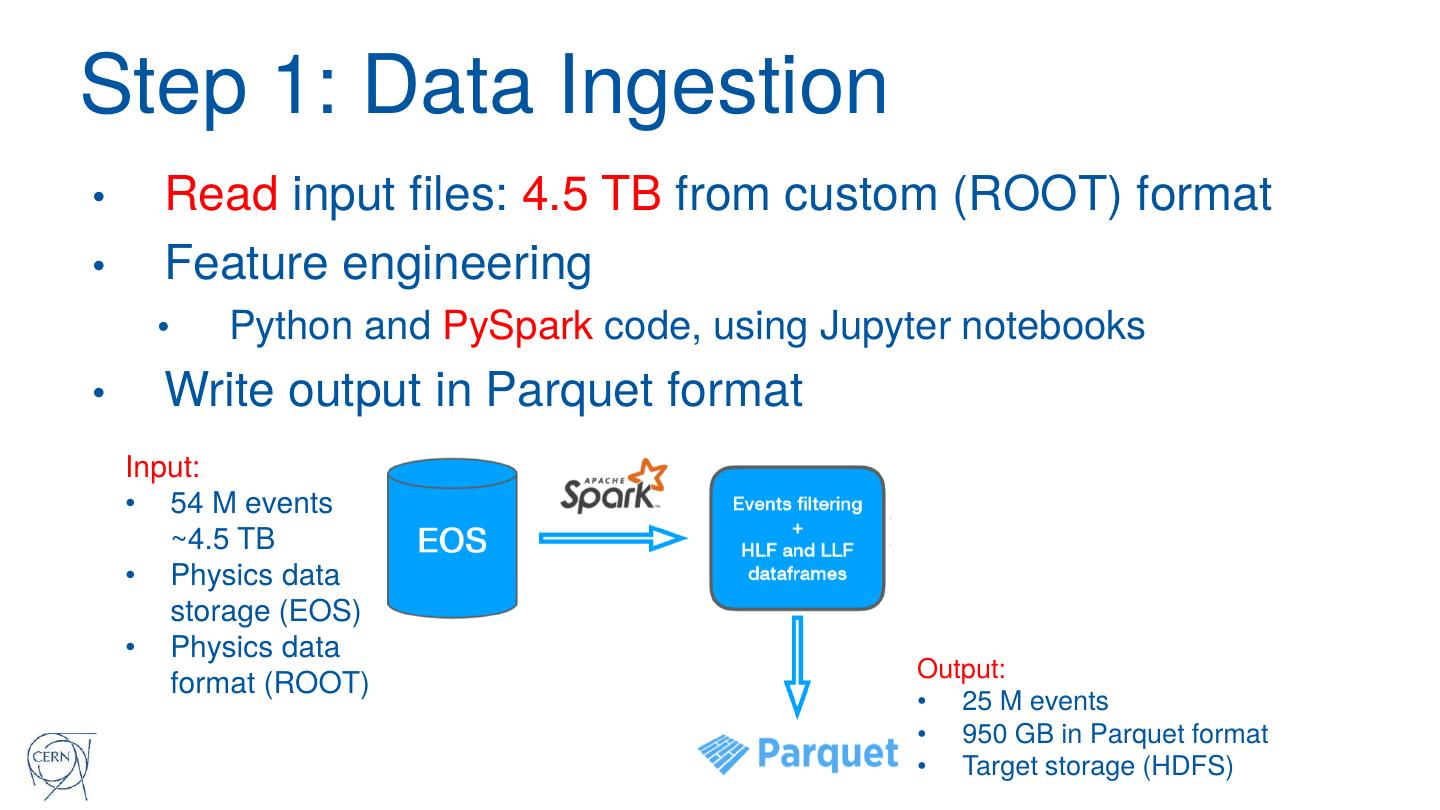
16 .Step 1: Data Ingestion
• Read input files: 4.5 TB from custom (ROOT) format
• Feature engineering
• Python and PySpark code, using Jupyter notebooks
• Write output in Parquet format
Input:
• 54 M events
~4.5 TB
• Physics data
storage (EOS)
• Physics data
Output:
format (ROOT)
• 25 M events
• 950 GB in Parquet format
• Target storage (HDFS)
�
17 .Feature Engineering
● Filtering
● Multiple filters, keep only events of interest
● Example: “events with one electrons or muon with Pt > 23 Gev”
• Prepare “Low Level Features”
• Every event is associated to a matrix of particles and features (801x19)
• High Level Features (HLF)
• Additional 14 features are computed from low level particle features
• Calculated based on domain-specific knowledge
�
18 . Step 2: Feature Preparation
Features are converted to formats
suitable for training
• One Hot Encoding of categories
• MinMax scaler for High Level Features
• Sorting Low Level Features: prepare input
for the sequence classifier, using a metric
based on physics. This use a Python UDF.
• Undersampling: use the same number of
events for each of the three categories
Result
• 3.6 Million events, 317 GB
• Shuffled and split into training and test
datasets
• Code: in a Jupyter notebook using
PySpark with Spark SQL and ML
�
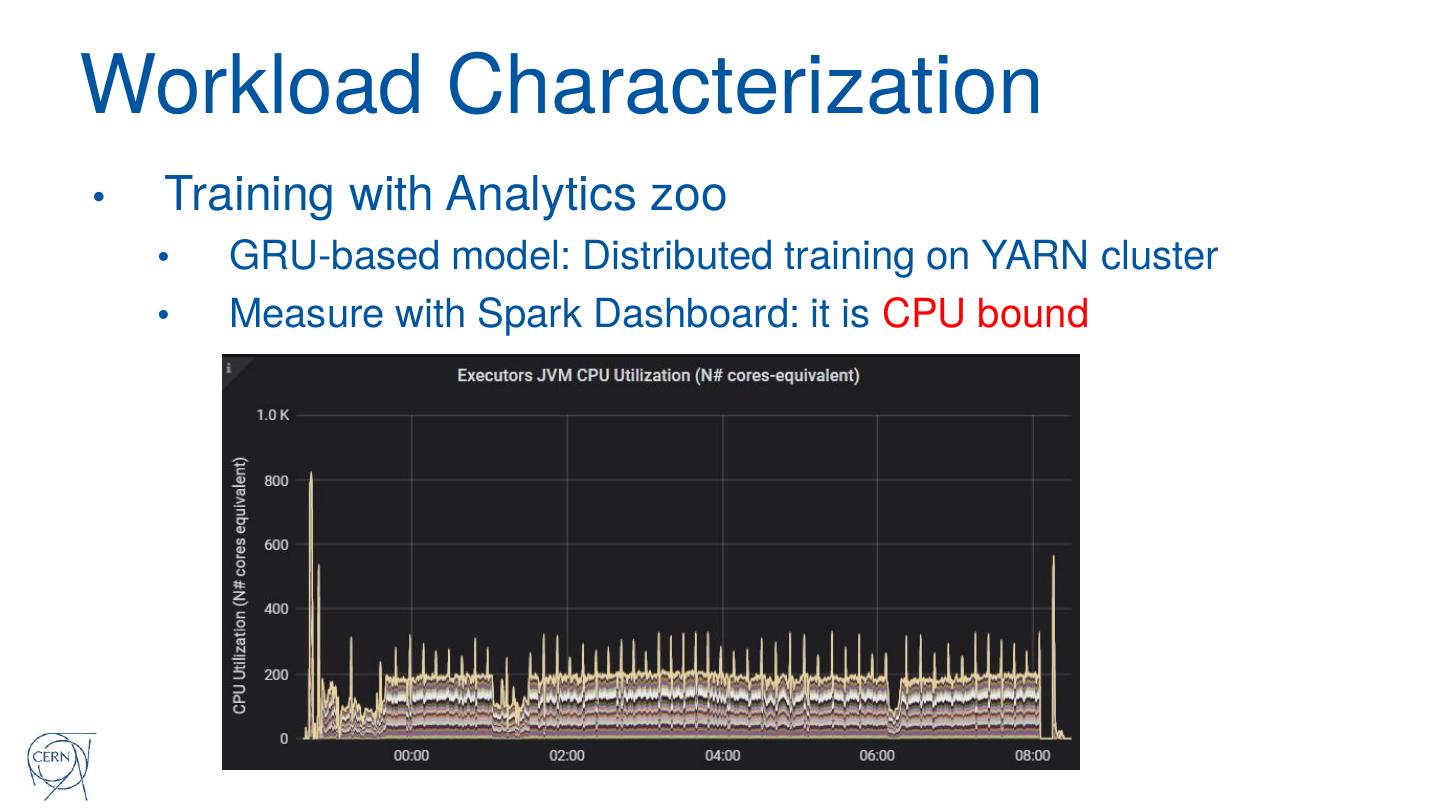
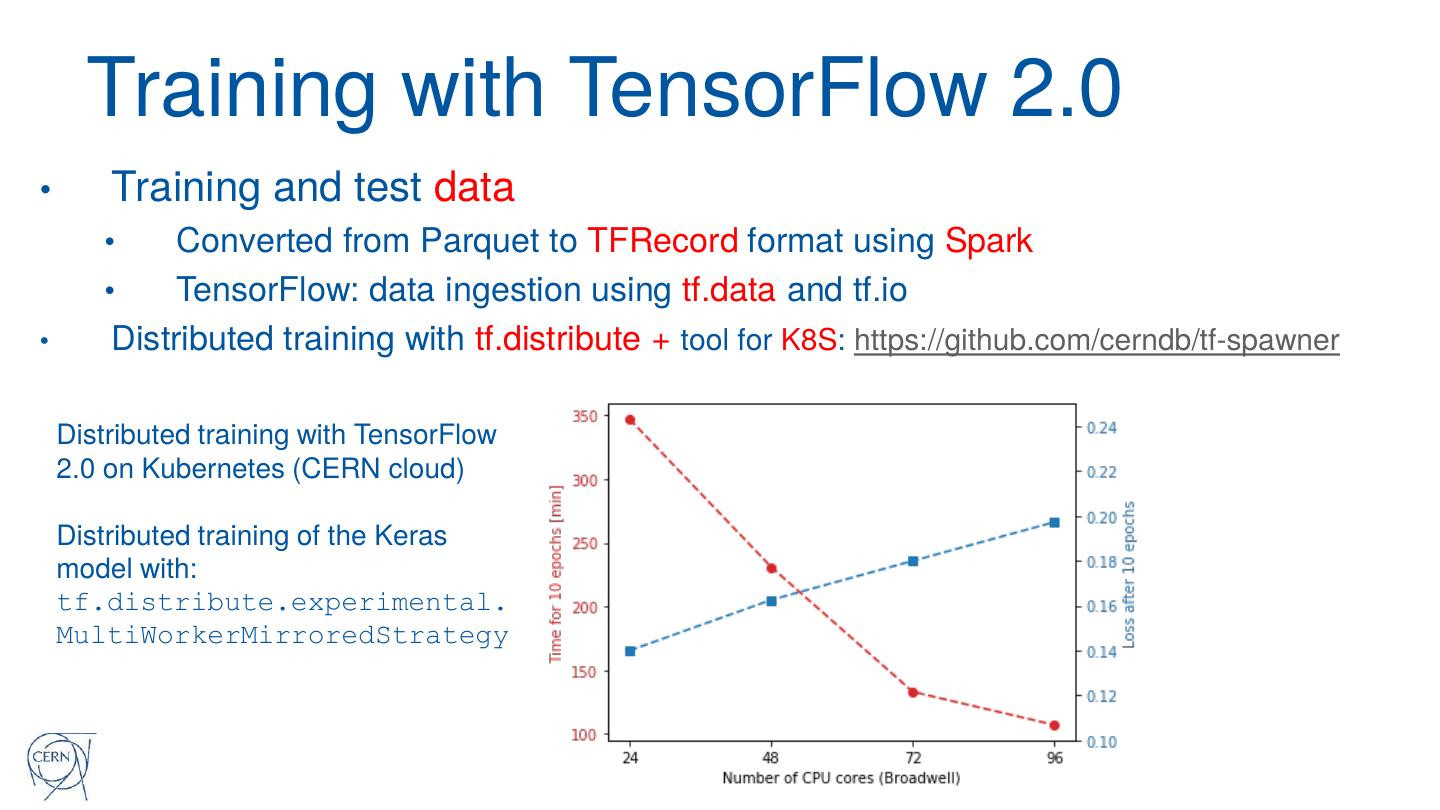
19 .Performance and Lessons Learned
• Data preparation is CPU bound
• Heavy serialization-deserialization due to Python UDF
• Ran using 400 cores: data ingestion took ~3 hours,
• It can be optimized, but is it worth it ?
• Use Spark SQL, Scala instead of Python UDF
• Optimization: replacing parts of Python UDF code with Spark SQL
and higher order functions: run time from 3 hours to 2 hours
�
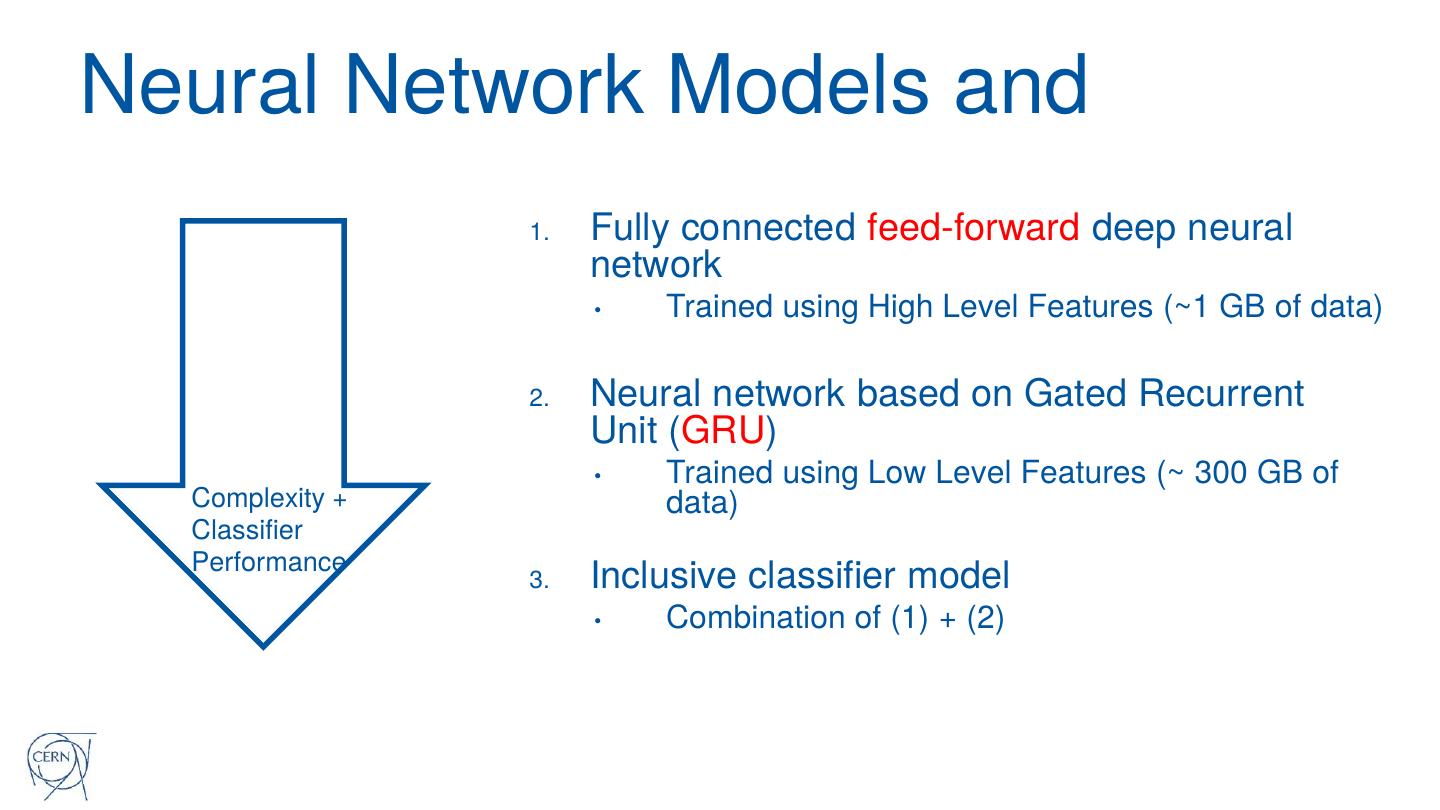
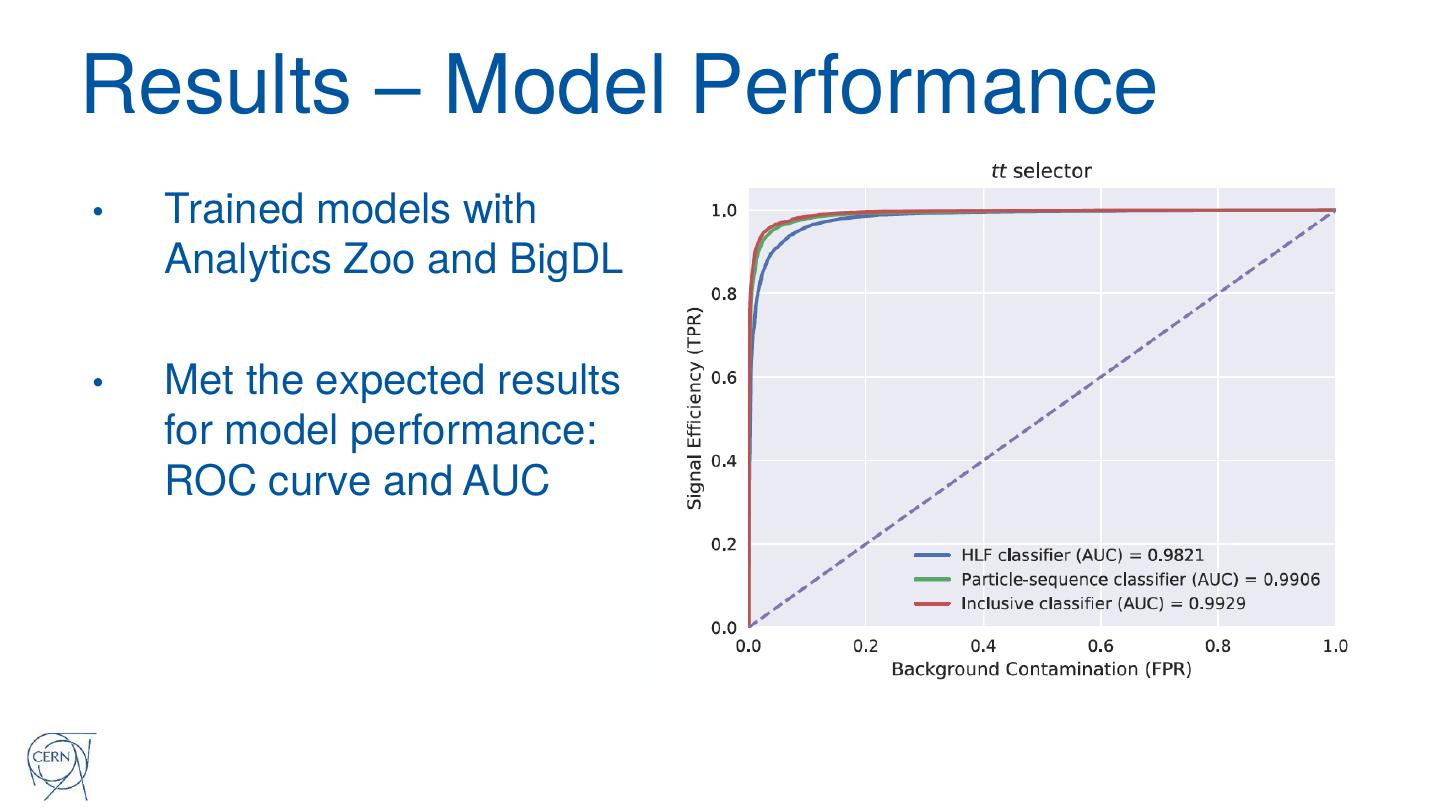
20 .Neural Network Models and
1. Fully connected feed-forward deep neural
network
• Trained using High Level Features (~1 GB of data)
2. Neural network based on Gated Recurrent
Unit (GRU)
• Trained using Low Level Features (~ 300 GB of
Complexity + data)
Classifier
Performance
3. Inclusive classifier model
• Combination of (1) + (2)
�
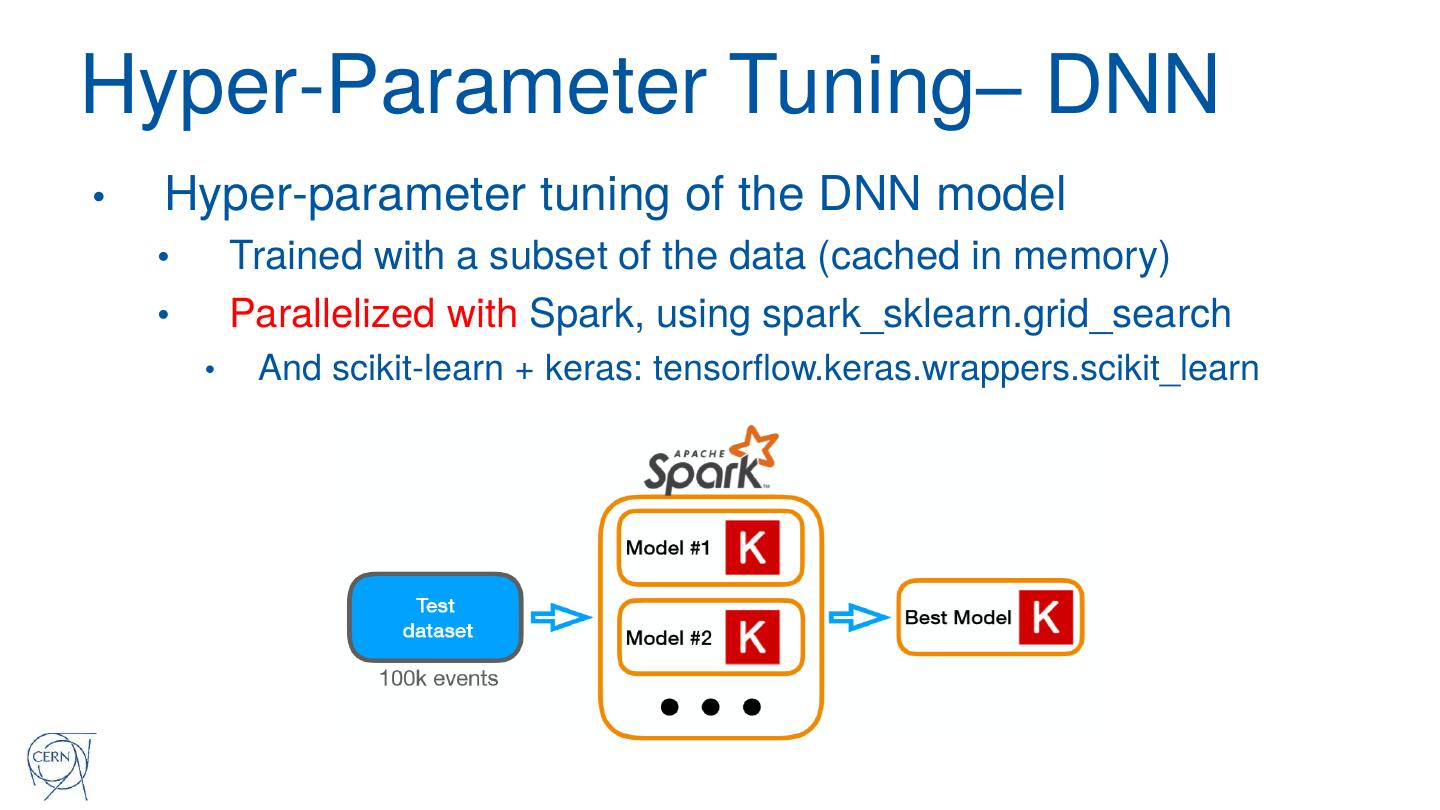
21 .Hyper-Parameter Tuning– DNN
• Hyper-parameter tuning of the DNN model
• Trained with a subset of the data (cached in memory)
• Parallelized with Spark, using spark_sklearn.grid_search
• And scikit-learn + keras: tensorflow.keras.wrappers.scikit_learn
�
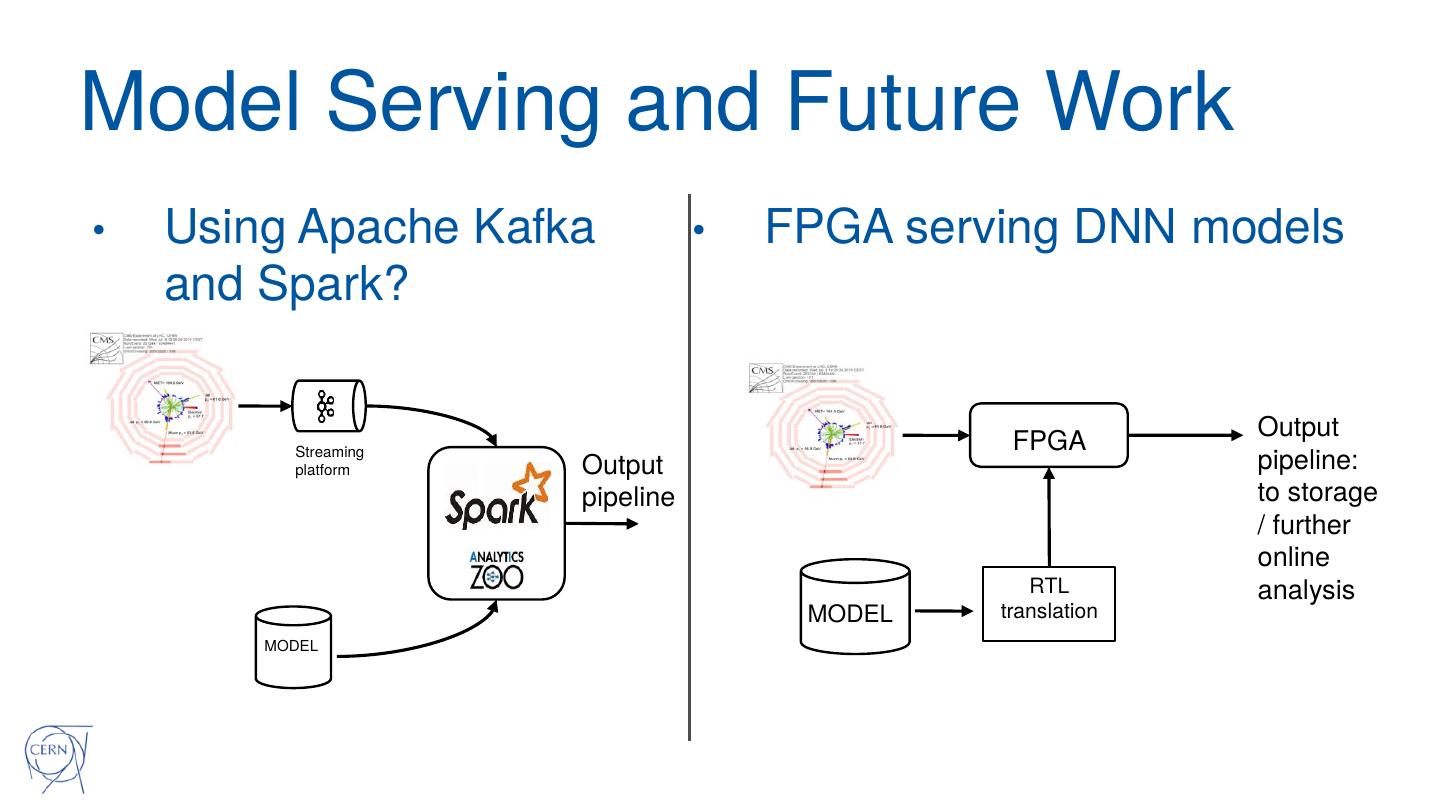
22 .Deep Learning at Scale with Spark
• Investigations and constraints for our exercise
• How to run deep learning in a Spark data pipeline?
• Neural network models written using Keras API
• Deploy on Hadoop and/or Kubernetes clusters (CPU clusters)
• Distributed deep learning
• GRU-based model is complex
• Slow to train on a single commodity (CPU) server
�
23 .Spark, Analytics Zoo and BigDL
• Apache Spark
• Leading tool and API for data processing at scale
• Analytics Zoo is a platform for unified analytics
and AI
• Runs on Apache Spark leveraging BigDL / Tensorflow
• For service developers: integration with infrastructure
(hardware, data access, operations)
• For users: Keras APIs to run user models, integration
with Spark data structures and pipelines
• BigDL is an open source distributed deep learning
framework for Apache Spark
�
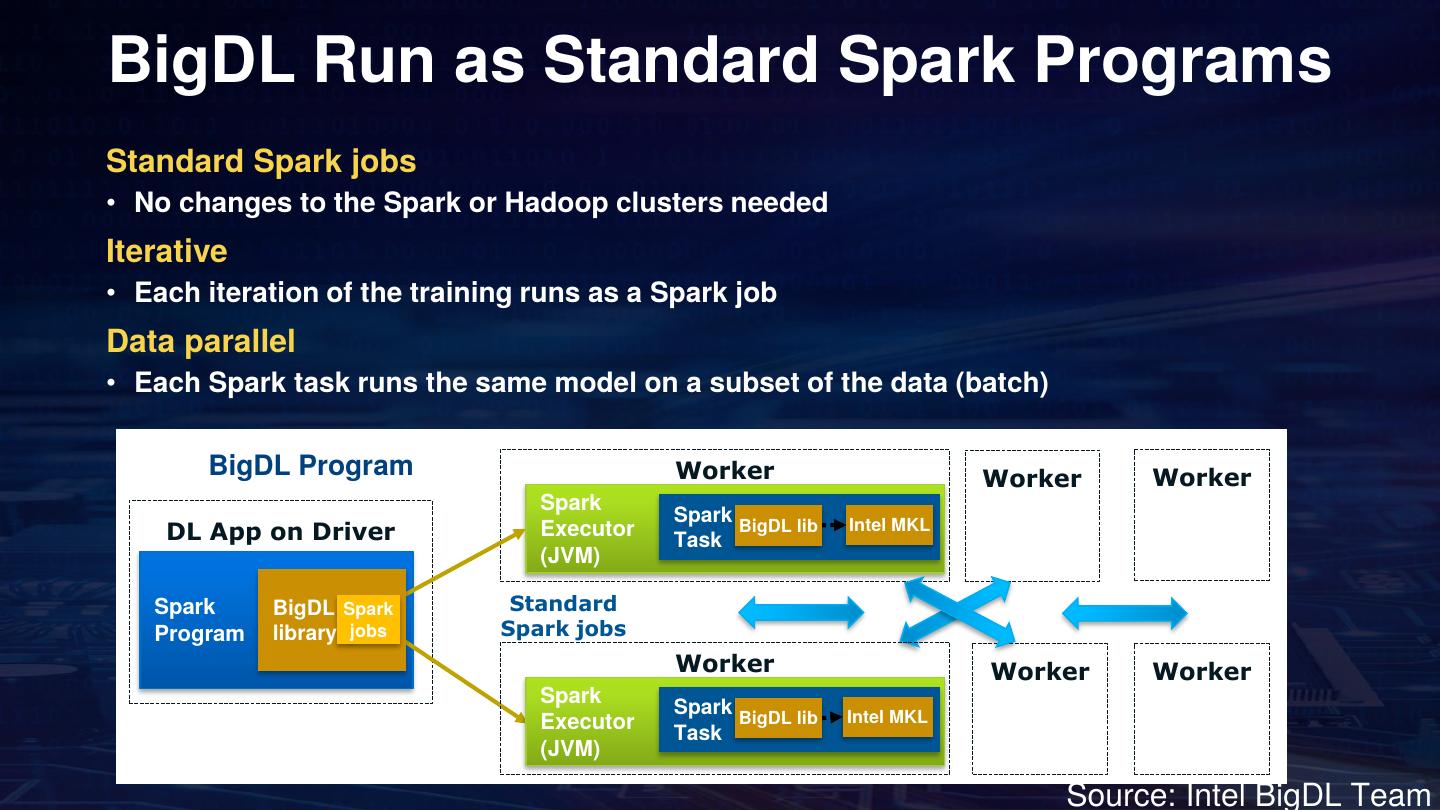
24 .BigDL Run as Standard Spark Programs
Standard Spark jobs
• No changes to the Spark or Hadoop clusters needed
Iterative
• Each iteration of the training runs as a Spark job
Data parallel
• Each Spark task runs the same model on a subset of the data (batch)
BigDL Program Worker Worker Worker
Spark
Spark BigDL lib
DL App on Driver Executor Task
Intel MKL
(JVM)
Spark BigDL Spark Standard
Program library jobs Spark jobs
Worker Worker Worker
Spark
Spark BigDL lib Intel MKL
Executor Task
(JVM)
Source: Intel BigDL Team
�
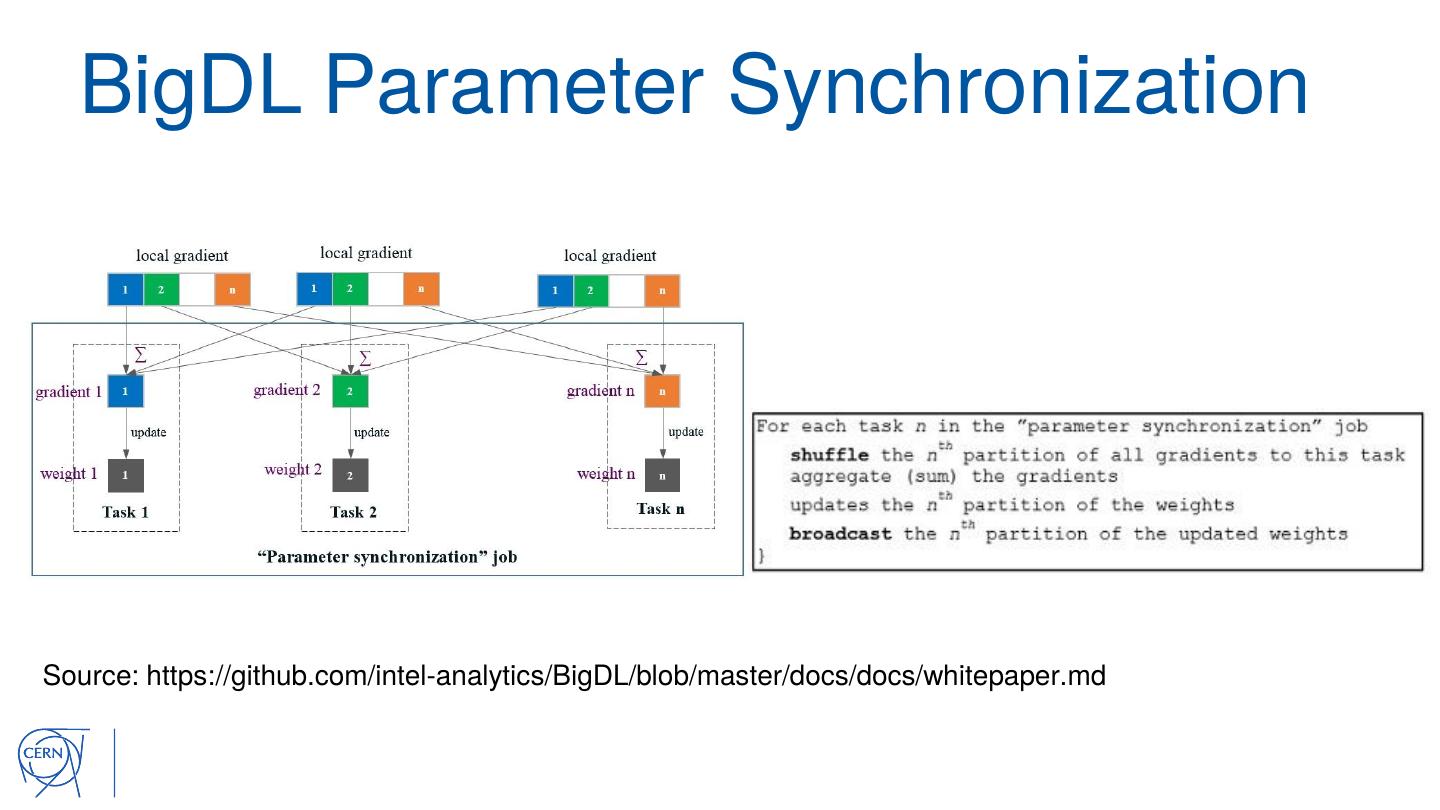
25 . BigDL Parameter Synchronization
Source: https://github.com/intel-analytics/BigDL/blob/master/docs/docs/whitepaper.md
�
26 .Model Development – DNN for HLF
• Model is instantiated using the Keras-
compatible API provided by Analytics Zoo
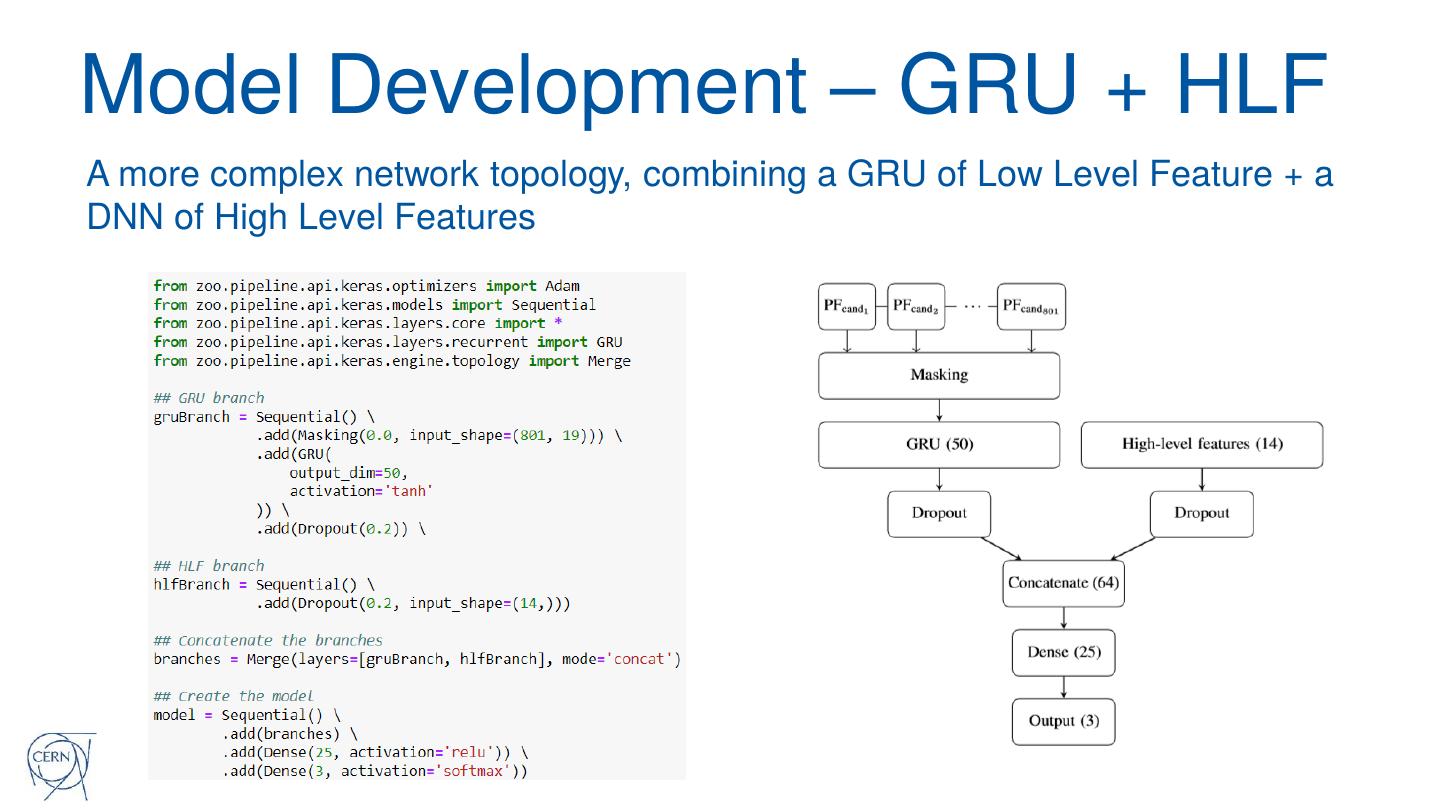
�
27 .Model Development – GRU + HLF
A more complex network topology, combining a GRU of Low Level Feature + a
DNN of High Level Features
�
28 .Distributed Training
Instantiate the estimator using Analytics Zoo / BigDL
The actual training is distributed to Spark executors
Storing the model for later use
�
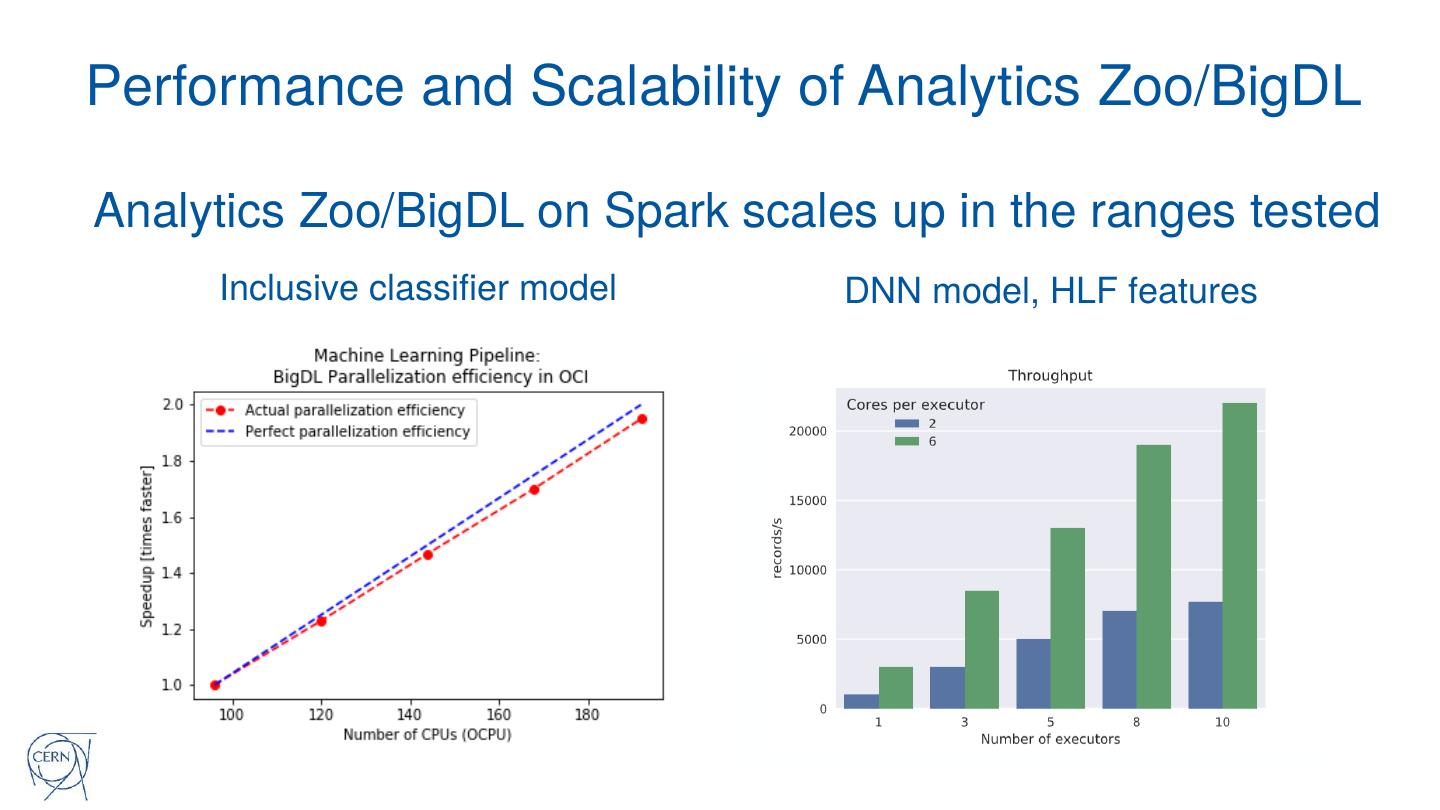
29 .Performance and Scalability of Analytics Zoo/BigDL
Analytics Zoo/BigDL on Spark scales up in the ranges tested
Inclusive classifier model DNN model, HLF features
�