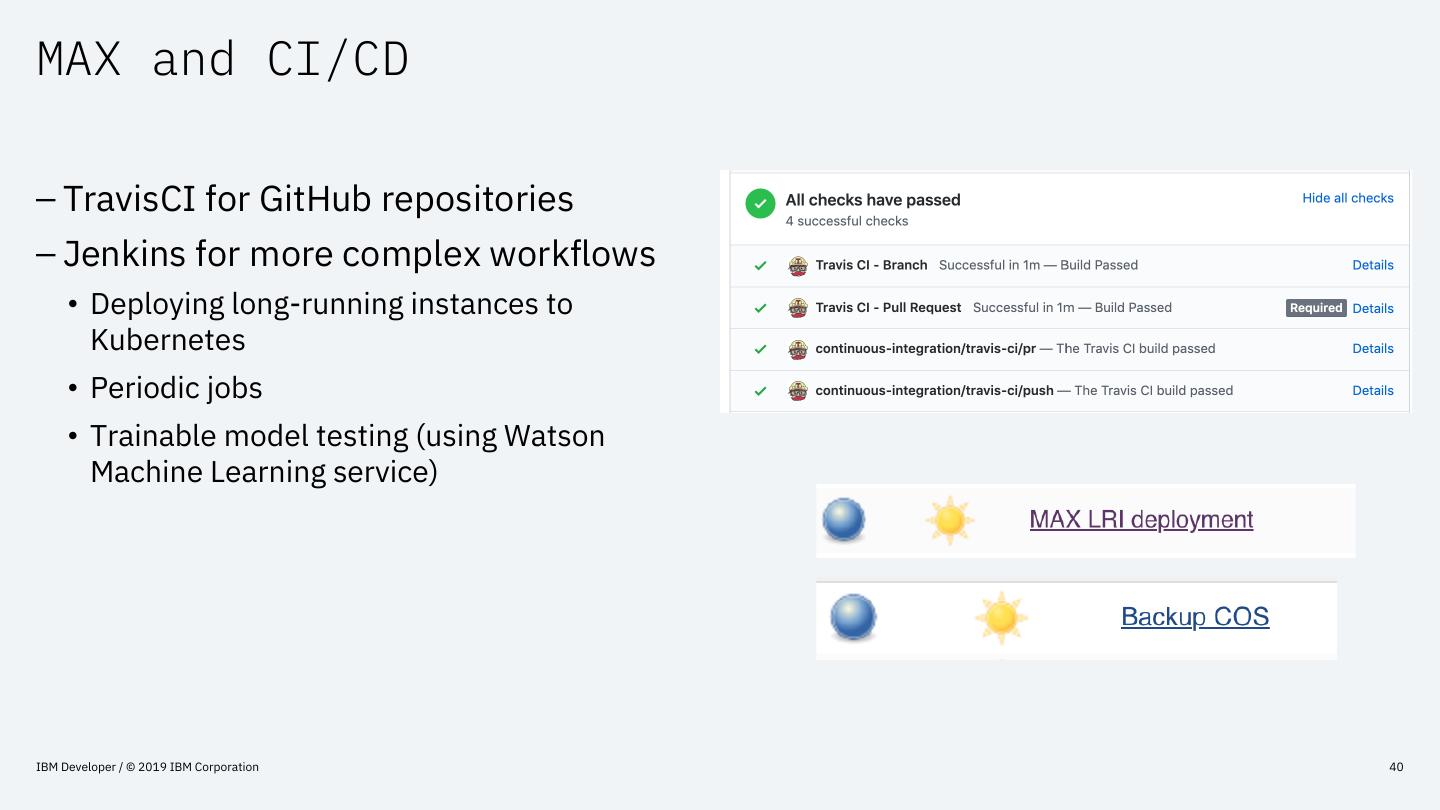
展开查看详情
1 .Continuous Deployment
for Deep Learning
—
Nick Pentreath
Principal Engineer
@MLnick
�
2 .About
– @MLnick on Twitter & Github
– Principal Engineer, IBM CODAIT (Center for
Open-Source Data & AI Technologies)
– Machine Learning & AI
– Apache Spark committer & PMC
– Author of Machine Learning with Spark
– Various conferences & meetups
IBM Developer / © 2019 IBM Corporation 2
�
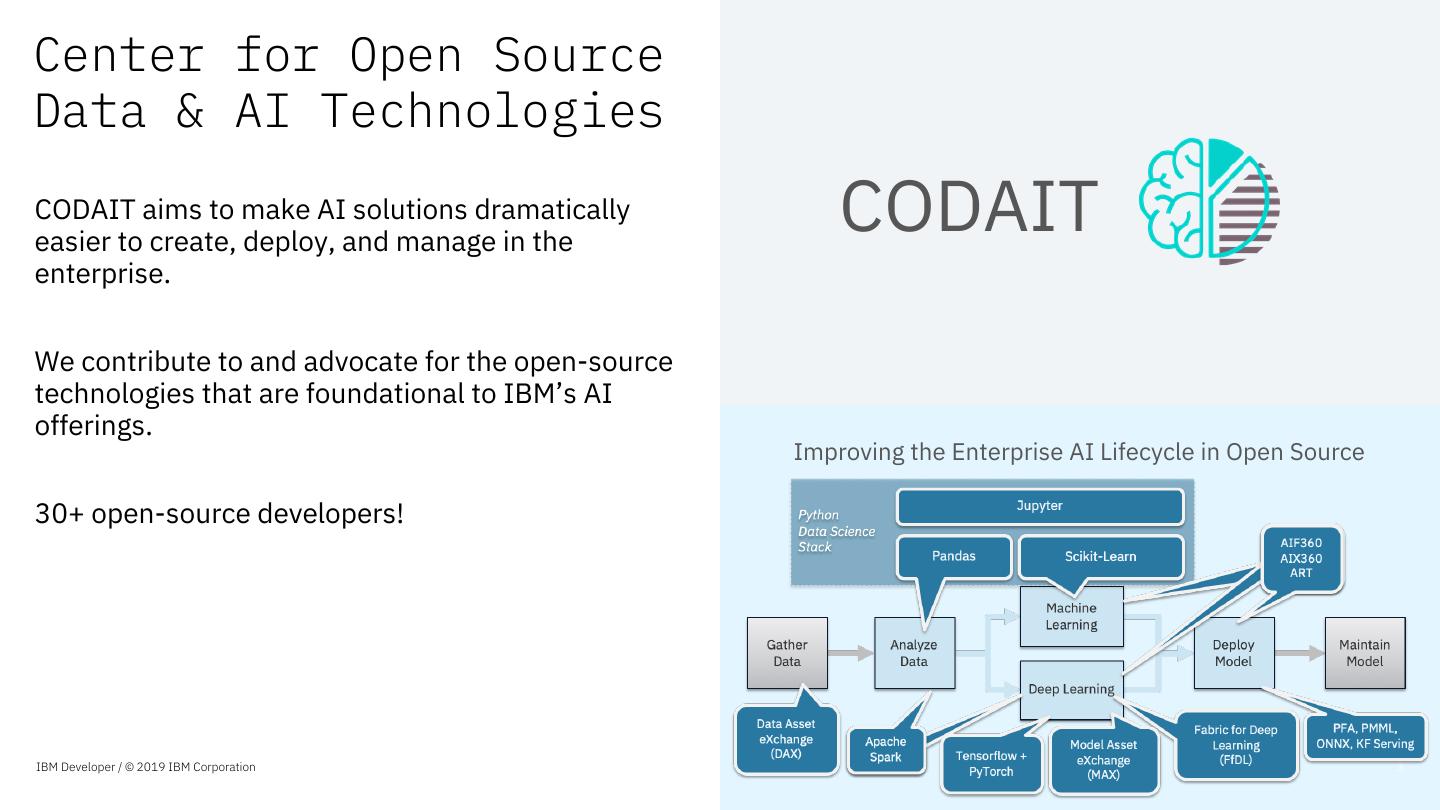
3 .Center for Open Source
Data & AI Technologies
CODAIT aims to make AI solutions dramatically
easier to create, deploy, and manage in the
CODAIT
enterprise.
We contribute to and advocate for the open-source
technologies that are foundational to IBM’s AI
offerings.
Improving the Enterprise AI Lifecycle in Open Source
30+ open-source developers!
IBM Developer / © 2019 IBM Corporation 3
�
4 .Agenda
– Overview of Continuous Integration &
Deployment
– The Machine Learning Workflow
– How is CI/CD for ML Different & Challenges
– Model Asset Exchange
– Conclusion
IBM Developer / © 2019 IBM Corporation 4
�
5 .Continuous Integration
& Deployment
IBM Developer / © 2019 IBM Corporation 5
�
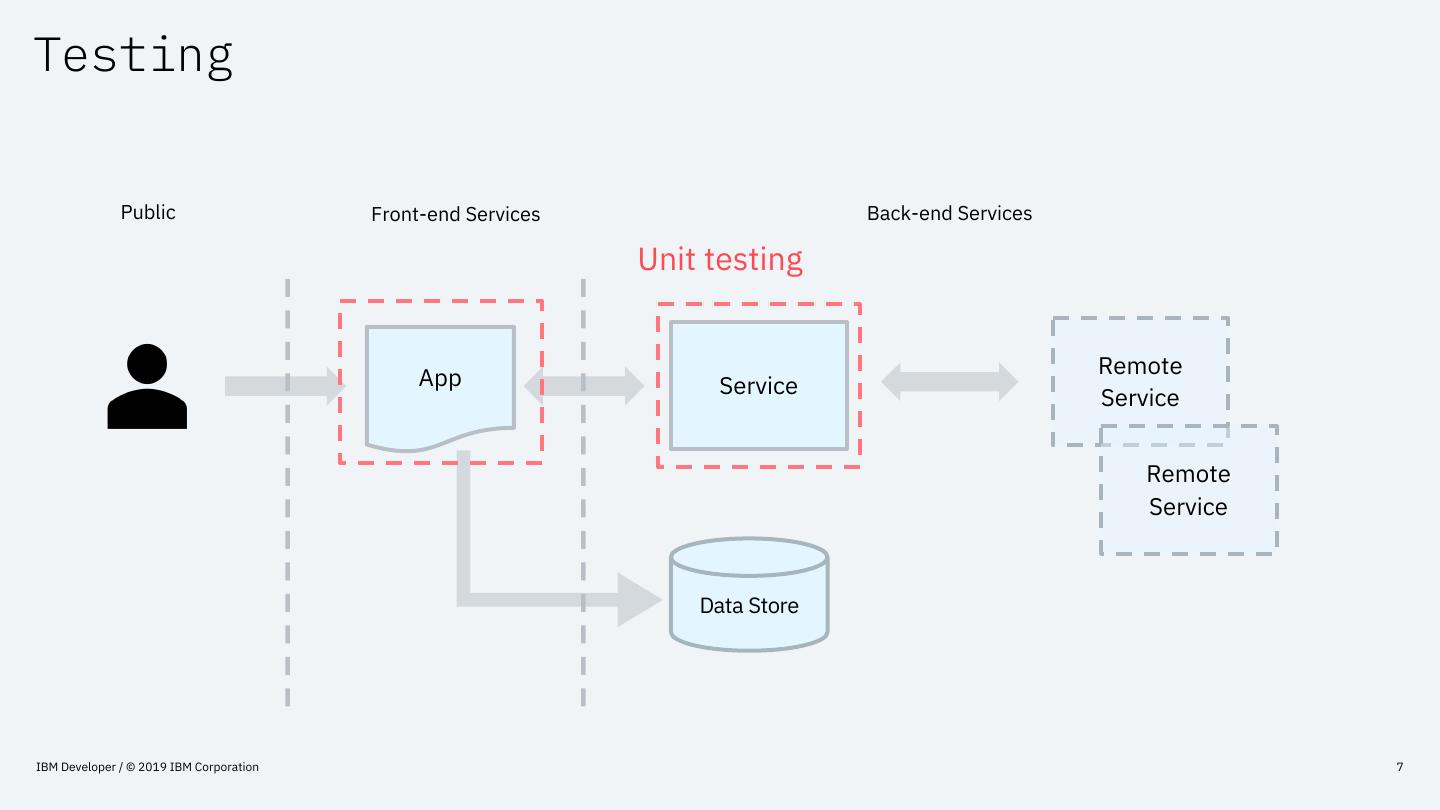
6 .Testing
Public Front-end Services Back-end Services
App Remote
Service Service
Remote
Service
Data Store
IBM Developer / © 2019 IBM Corporation 6
�
7 .Testing
Public Front-end Services Back-end Services
Unit testing
App Remote
Service Service
Remote
Service
Data Store
IBM Developer / © 2019 IBM Corporation 7
�
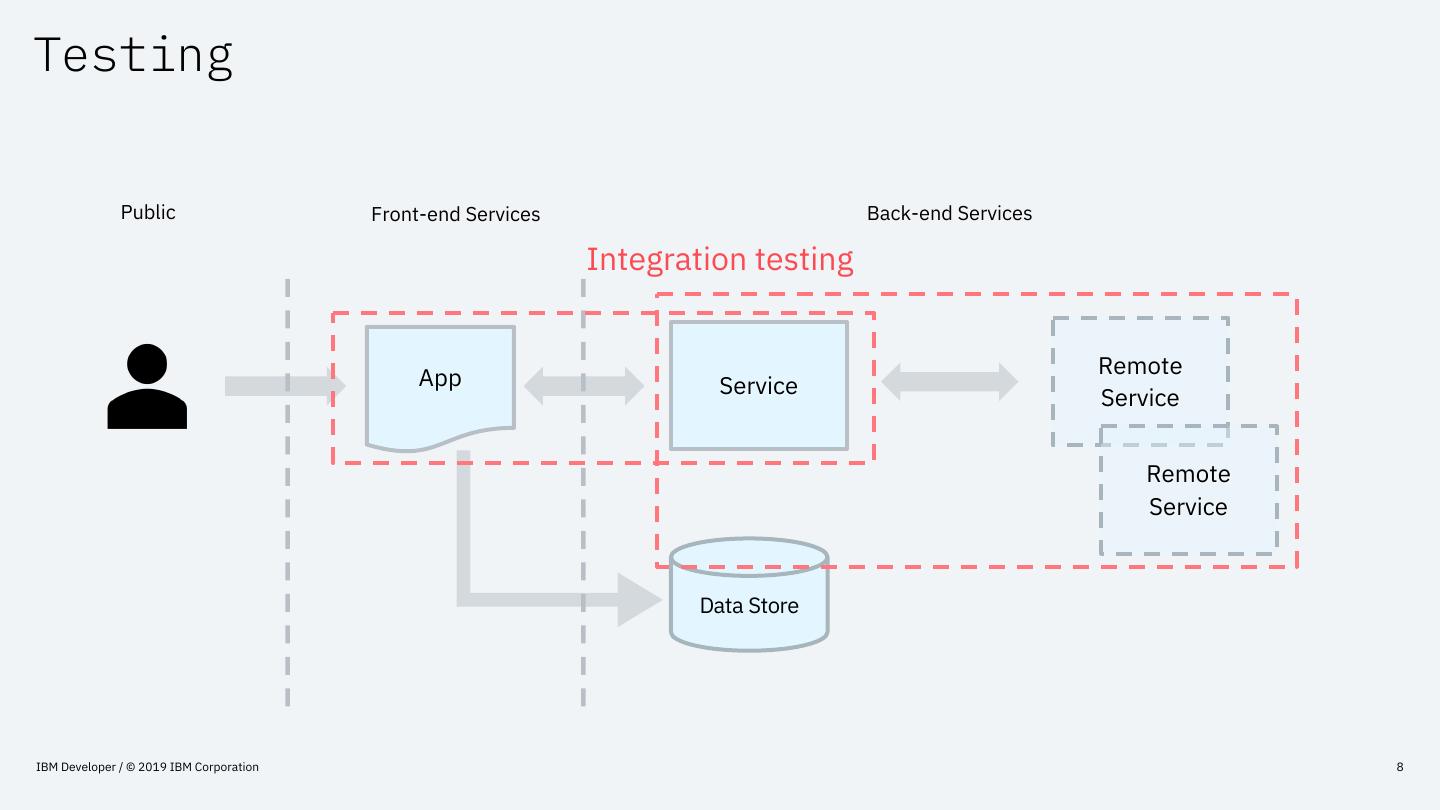
8 .Testing
Public Front-end Services Back-end Services
Integration testing
App Remote
Service Service
Remote
Service
Data Store
IBM Developer / © 2019 IBM Corporation 8
�
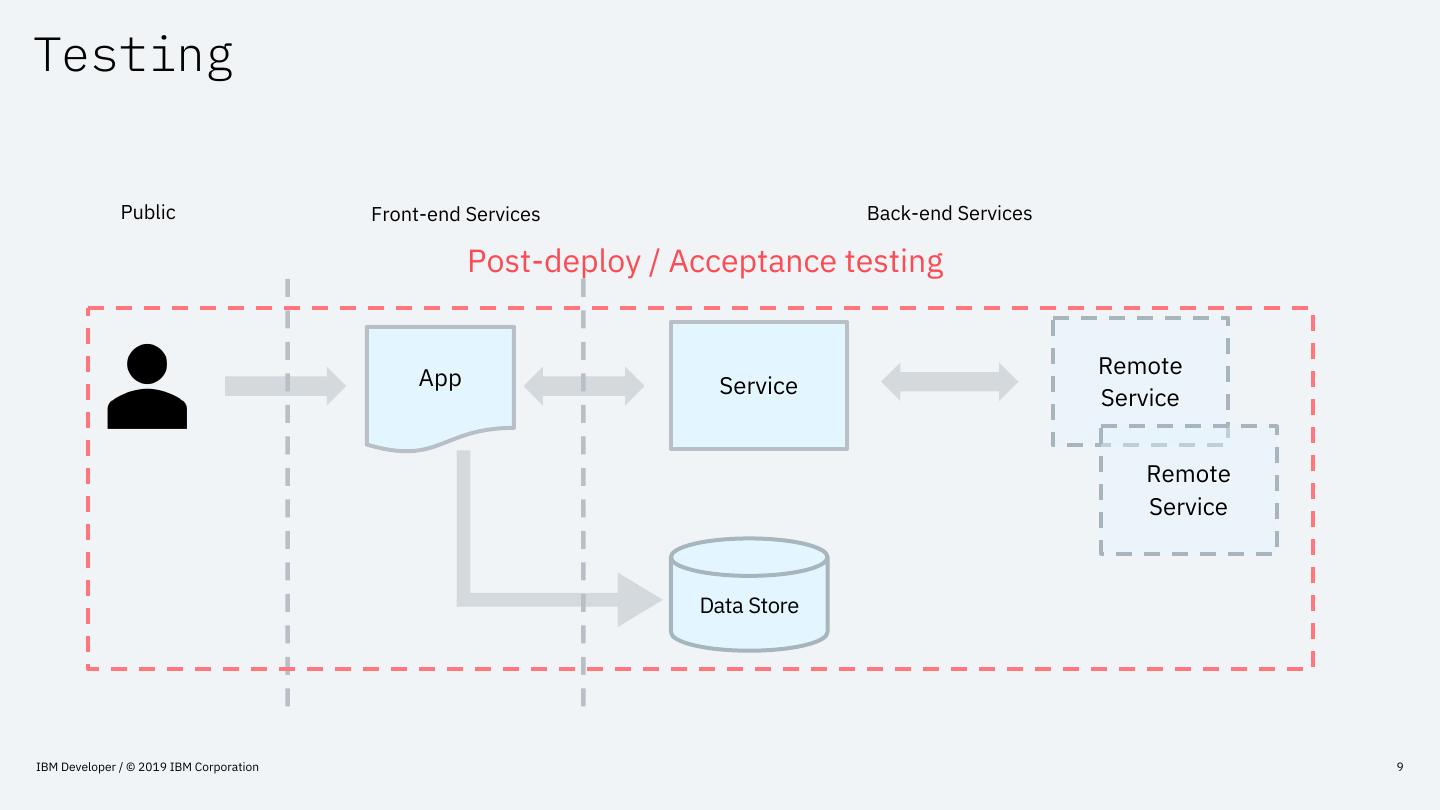
9 .Testing
Public Front-end Services Back-end Services
Post-deploy / Acceptance testing
App Remote
Service Service
Remote
Service
Data Store
IBM Developer / © 2019 IBM Corporation 9
�
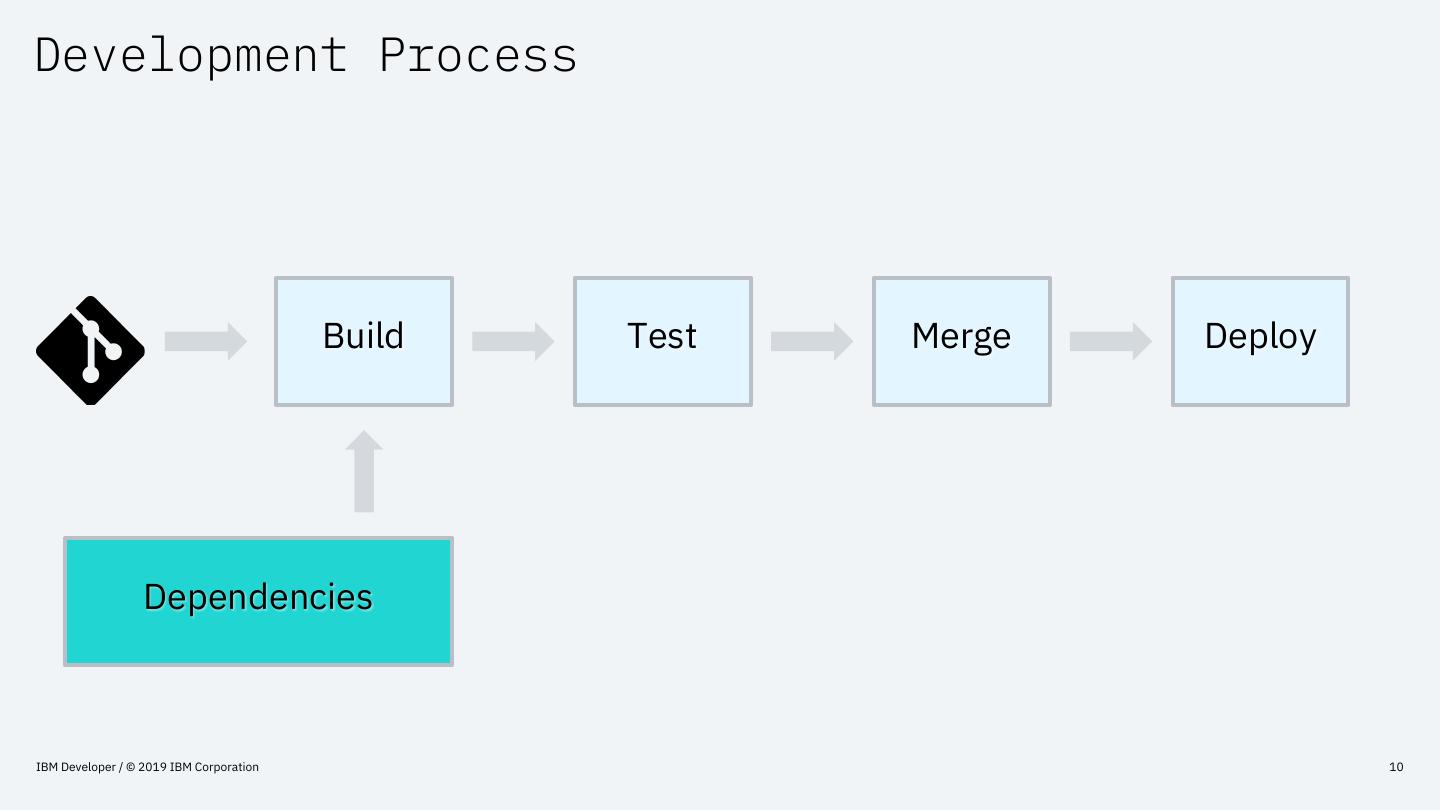
10 .Development Process
Build Test Merge Deploy
Dependencies
IBM Developer / © 2019 IBM Corporation 10
�
11 .Starting Point
Build Test Merge Deploy
Automated
Dependencies
Manual
IBM Developer / © 2019 IBM Corporation 11
�
12 .Continuous Integration
Build Test Merge Deploy
Automated
Dependencies
Manual
IBM Developer / © 2019 IBM Corporation 12
�
13 .Continuous Deployment
Build Test Merge Deploy
Automated
Dependencies
Manual
IBM Developer / © 2019 IBM Corporation 13
�
14 .Source of changes
Build Test Merge Deploy
Changes come from:
• Our code
Dependencies
• Internal dependencies
• 3rd party dependencies
IBM Developer / © 2019 IBM Corporation 14
�
15 .The Machine Learning
Workflow
IBM Developer / © 2019 IBM Corporation 15
�
16 .Perception
IBM Developer / © 2019 IBM Corporation 16
�
17 .In reality the
workflow spans teams …
IBM Developer / © 2019 IBM Corporation 17
�
18 .… and tools …
IBM Developer / © 2019 IBM Corporation 18
�
19 .… and is a small (but critical!)
piece of the puzzle
IBM Developer / © 2019 IBM Corporation 19
*Source: Hidden Technical Debt in Machine Learning Systems
�
20 .What is a “model”?
IBM Developer / © 2019 IBM Corporation 20
�
21 .Deep learning pipeline
Input image Image pre-processing Inference Post-processing Prediction
beagle: 0.82
Decode image [0.2, 0.3, … ]
Resize Label map basset: 0.09
Normalization (label, prob)
bluetick: 0.07
Convert types / format Sort
...
PIL, OpenCV, tf.image, Custom
… Python
IBM Developer / © 2019 IBM Corporation 21
* Logos trademarks of their respective projects
�
22 .Pipelines, not Models
– Deploying (and testing) just the model – Pipelines in frameworks
part of the workflow is not enough • scikit-learn
– Entire pipeline must be taken into • Spark ML pipelines
account • TensorFlow Transform
• Data transforms • pipeliner (R)
• Feature extraction & pre-processing
• DL / ML model
• Prediction transformation
– Even ETL is part of the pipeline!
IBM Developer / © 2019 IBM Corporation 22
�
23 .Continuous Integration
for Machine Learning
IBM Developer / © 2019 IBM Corporation 23
�
24 .Source of changes
Build Test Merge Deploy
Changes come from:
• Our code
• Internal dependencies
Data Model Dependencies • 3rd party dependencies
• Data
• Model
• Time
IBM Developer / © 2019 IBM Corporation 24
�
25 .Data
– Data types
• Images, video, audio, raw text,
unstructured
– Size
– Schemas
IBM Developer / © 2019 IBM Corporation 25
* Logos trademarks of their respective projects
�
26 .Models
– Size of models
– Resource requirements
– Hardware
• CPU, GPU, TPU, Mobile, Edge
– Need to manage and bridge many
different languages, frameworks
– Formats
– State of the art is changing very
rapidly
IBM Developer / © 2019 IBM Corporation 26
* Logos trademarks of their respective projects
�
27 .Monitoring & Feedback
over Time
IBM Developer / © 2019 IBM Corporation 27
�
28 .Monitoring
Traditional software monitoring
Latency, throughput, resource usage, etc
Model performance metrics
Traditional ML evaluation measures Software
(accuracy, prediction error, AUC etc)
Business metrics
Impact of predictions on business
outcomes
Monitoring
• Additional revenue - e.g. uplift from recommender
• Cost savings – e.g. value of fraud prevented
Performance Business
• Metrics implicitly influencing these – e.g. user
engagement
IBM Developer / © 2019 IBM Corporation
�
29 .Feedback
Adapt
An intelligent system must automatically Data
learn from & adapt to the world around it
Continual learning
Retraining, online learning,
reinforcement learning Feedback Transform
Feedback loops
Explicit: models create or directly
influence their own training data
Implicit: predictions influence behavior
in longer-term or indirect ways
Deploy Train
Humans in the loop
IBM Developer / © 2019 IBM Corporation
�