展开查看详情
1 .Building Reliable Delta
Lakes at scale
�
2 .Steps to running this tutorial
Instructions - https://dbricks.co/saiseu19-delta
1. Create an account + sign in to Databricks Community Edition
https://databricks.com/try
2. Create a cluster with Databricks Runtime 6.1
3. Import the Python notebook and attach it to the cluster
You can also use Scala notebook if you prefer
�
3 .The Promise of the Data Lake
1. Collect 2. Store it all in 3. Data Science &
Everything the Data Lake Machine Learning
🔥
🔥 🔥
🔥
🔥 🔥 🔥 • Recommendation Engines
• Risk, Fraud Detection
• IoT & Predictive Maintenance
• Genomics & DNA Sequencing
Garbage In Garbage Stored Garbage Out
Tutorial instructions - https://dbricks.co/saiseu19-delta
�
4 . What does a typical
data lake project look like?
Tutorial instructions - https://dbricks.co/saiseu19-delta
�
5 . Evolution of a Cutting-Edge Data Lake
Events
?
Streaming
Analytics
Data Lake AI & Reporting
Tutorial instructions - https://dbricks.co/saiseu19-delta
�
6 . Evolution of a Cutting-Edge Data Lake
Events
Streaming
Analytics
Data Lake AI & Reporting
Tutorial instructions - https://dbricks.co/saiseu19-delta
�
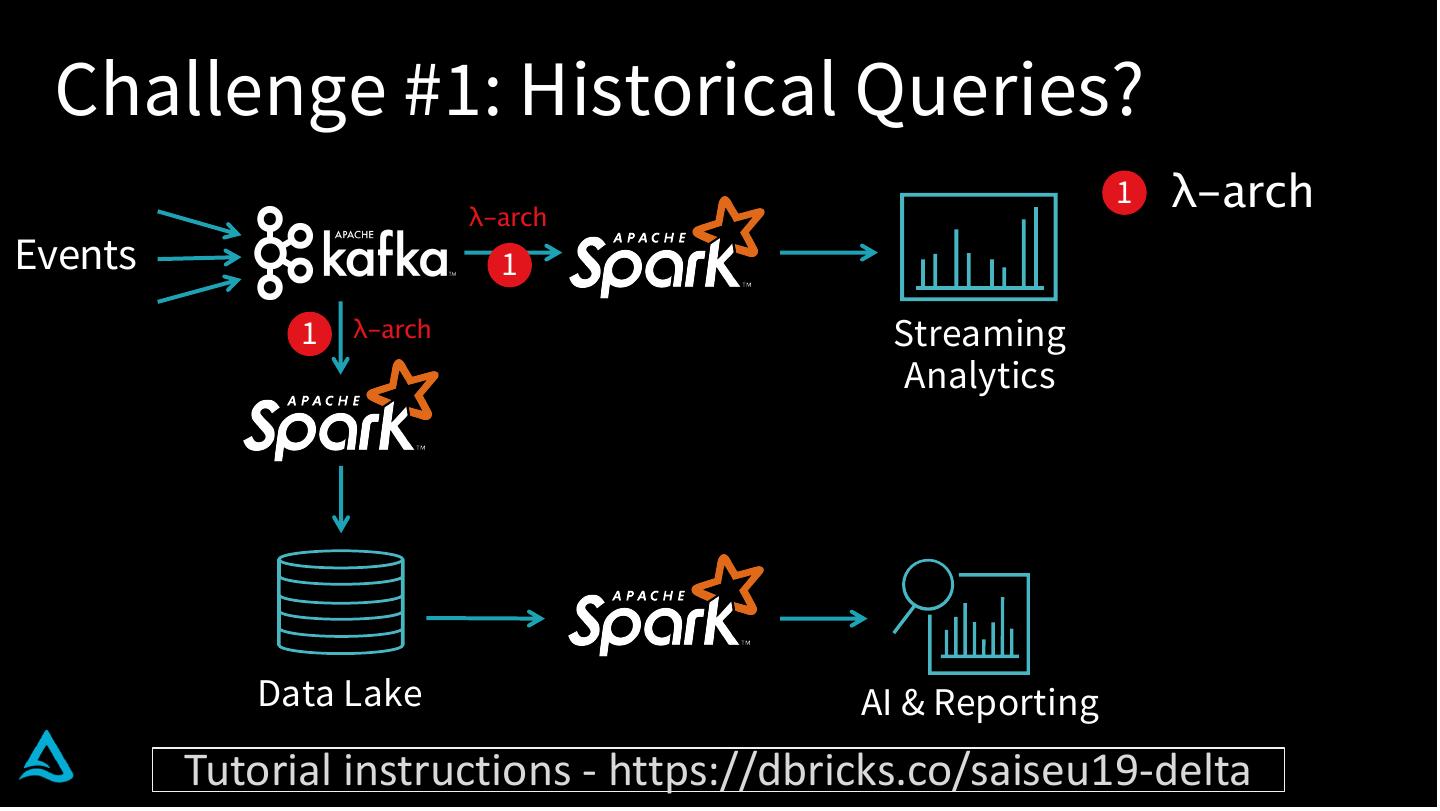
7 . Challenge #1: Historical Queries?
λ-arch
1 λ-arch
Events 1
1 λ-arch Streaming
Analytics
Data Lake AI & Reporting
Tutorial instructions - https://dbricks.co/saiseu19-delta
�
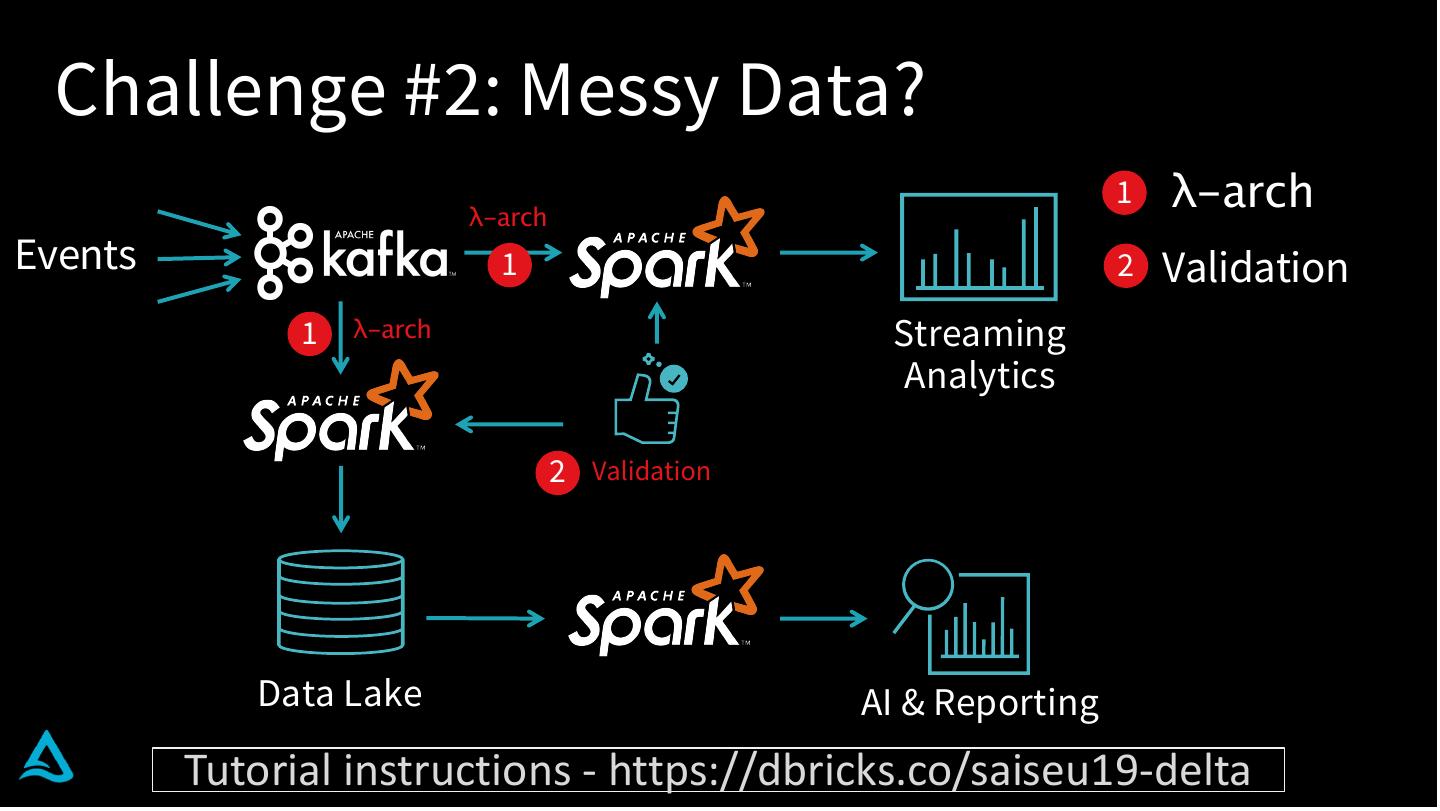
8 . Challenge #2: Messy Data?
λ-arch
1 λ-arch
Events 1 2 Validation
1 λ-arch Streaming
Analytics
2 Validation
Data Lake AI & Reporting
Tutorial instructions - https://dbricks.co/saiseu19-delta
�
9 . Challenge #3: Mistakes and Failures?
λ-arch
1 λ-arch
Events 1 2 Validation
1 λ-arch Streaming 3 Reprocessing
Analytics
2 Validation
Partitioned
3
Reprocessing
Data Lake AI & Reporting
Tutorial instructions - https://dbricks.co/saiseu19-delta
�
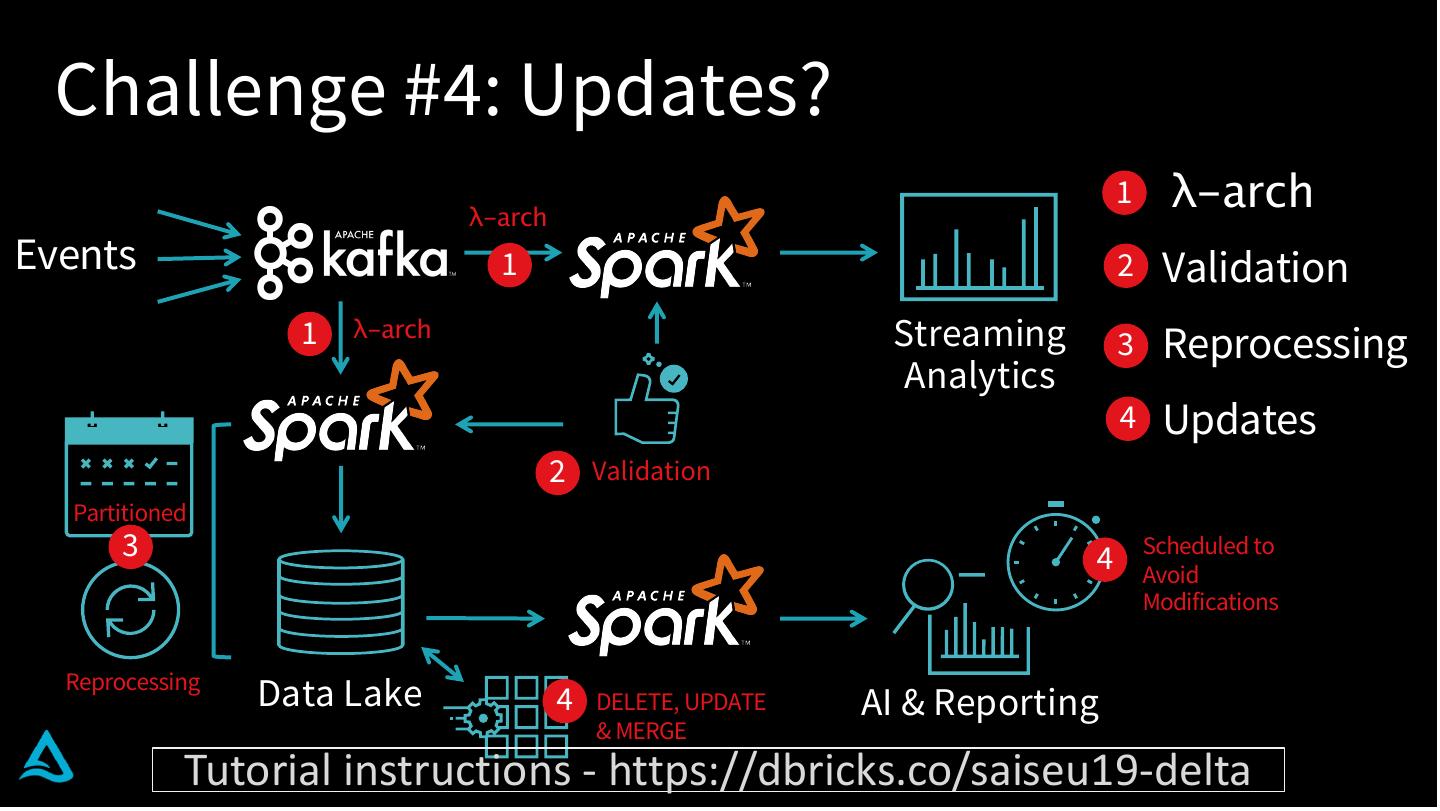
10 . Challenge #4: Updates?
λ-arch
1 λ-arch
Events 1 2 Validation
1 λ-arch Streaming 3 Reprocessing
Analytics
4 Updates
2 Validation
Partitioned
3 4 Scheduled to
Avoid
Modifications
Reprocessing
Data Lake 4 DELETE, UPDATE AI & Reporting
& MERGE
Tutorial instructions - https://dbricks.co/saiseu19-delta
�
11 .Wasting Time & Money
Solving Systems Problems
Instead of Extracting Value From Data
Tutorial instructions - https://dbricks.co/saiseu19-delta
�
12 .Data Lake Distractions
No atomicity means failed production jobs
✗ leave data in corrupt state requiring tedious
recovery
No quality enforcement creates inconsistent
and unusable data
No consistency / isolation makes it almost
impossible to mix appends and reads, batch and
streaming
Tutorial instructions - https://dbricks.co/saiseu19-delta
�
13 .Let’s try it instead with
Tutorial instructions - https://dbricks.co/saiseu19-delta
�
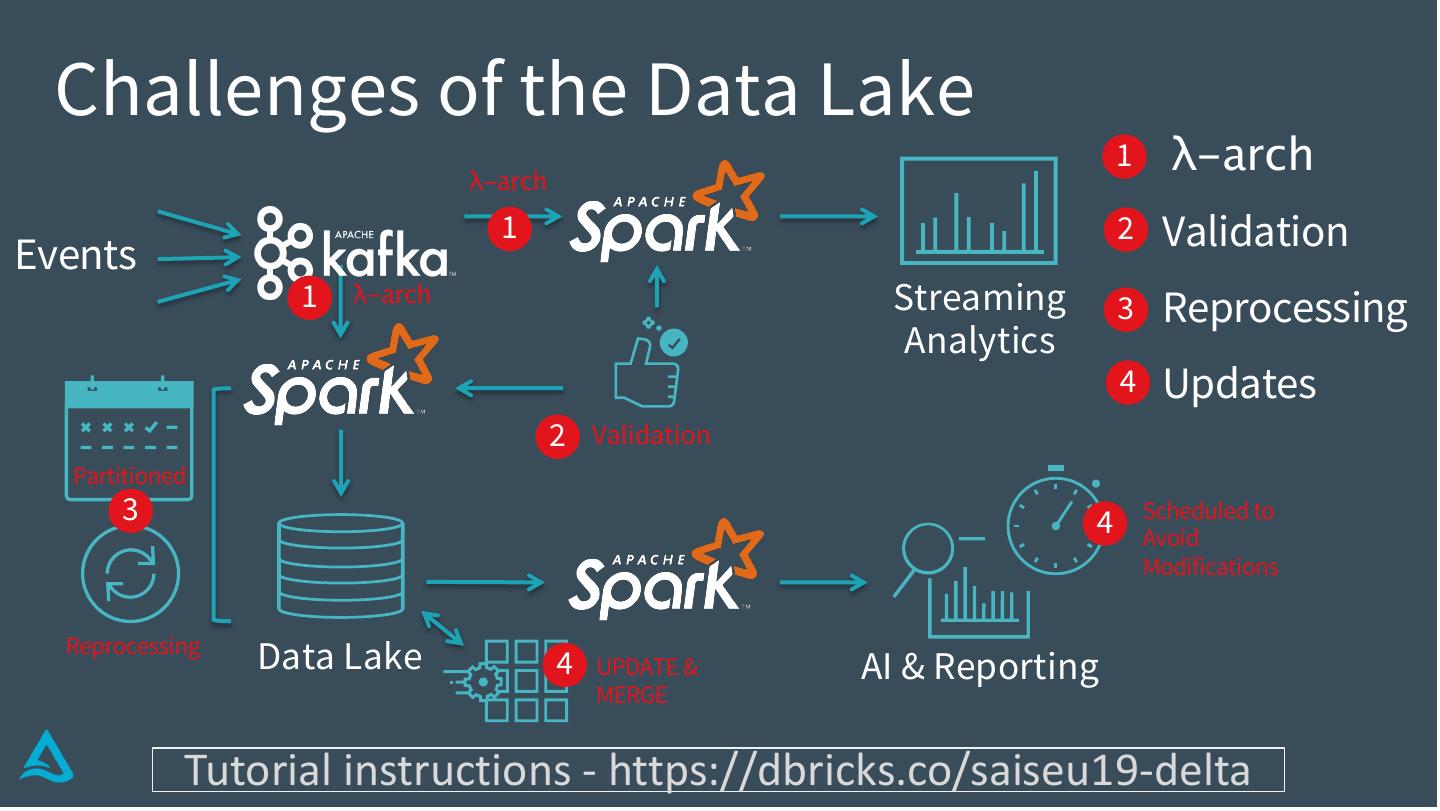
14 . Challenges of the Data Lake
λ-arch
1 λ-arch
1 2 Validation
Events
1 λ-arch Streaming 3 Reprocessing
Analytics
4 Updates
2 Validation
Partitioned
3 4 Scheduled to
Avoid
Modifications
Reprocessing
Data Lake 4 UPDATE & AI & Reporting
MERGE
Tutorial instructions - https://dbricks.co/saiseu19-delta
�
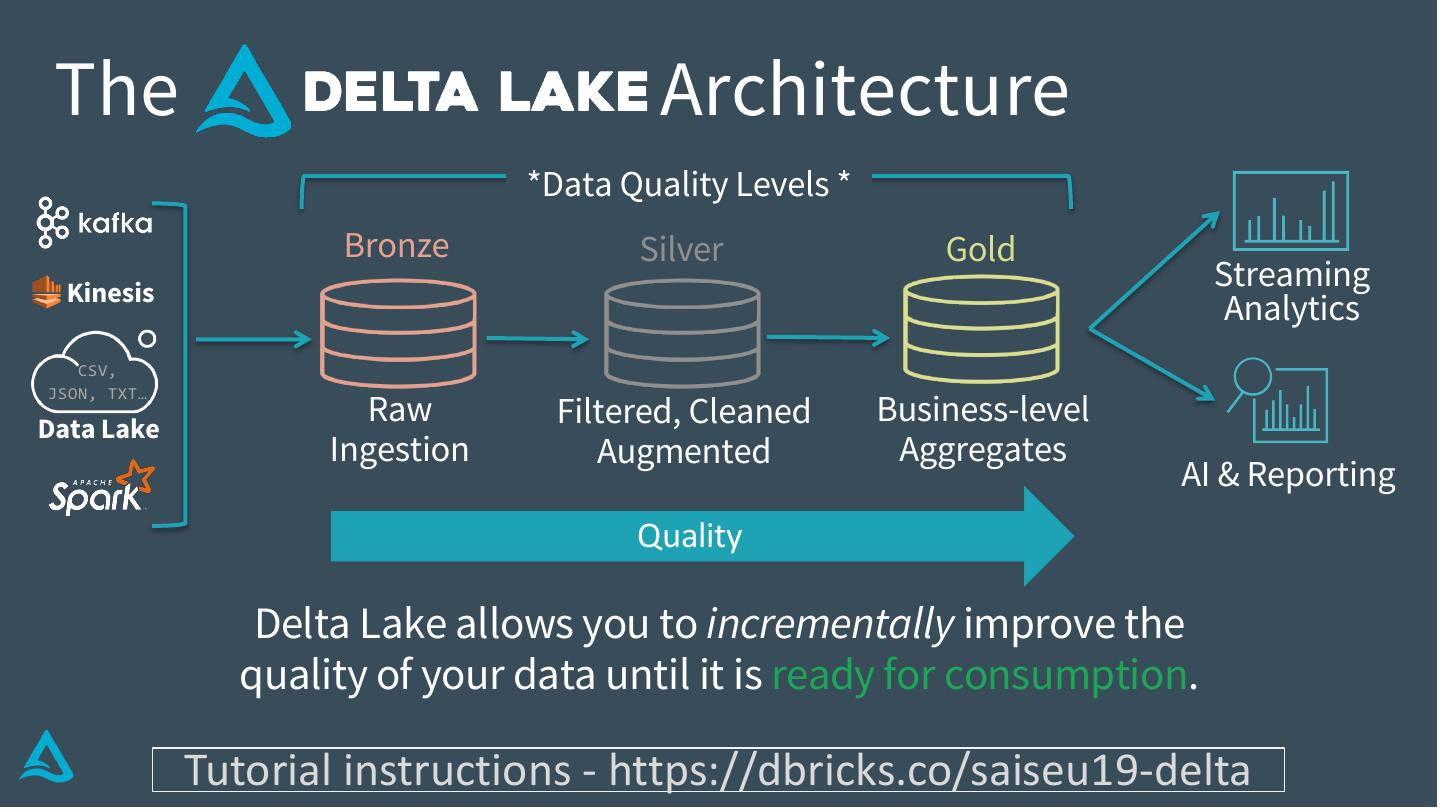
15 . The Architecture
*Data Quality Levels *
Bronze Silver Gold
Kinesis
Streaming
Analytics
CSV,
Raw Business-level
JSON, TXT…
Data Lake
Filtered, Cleaned
Ingestion Augmented Aggregates
AI & Reporting
Quality
Delta Lake allows you to incrementally improve the
quality of your data until it is ready for consumption.
Tutorial instructions - https://dbricks.co/saiseu19-delta
�
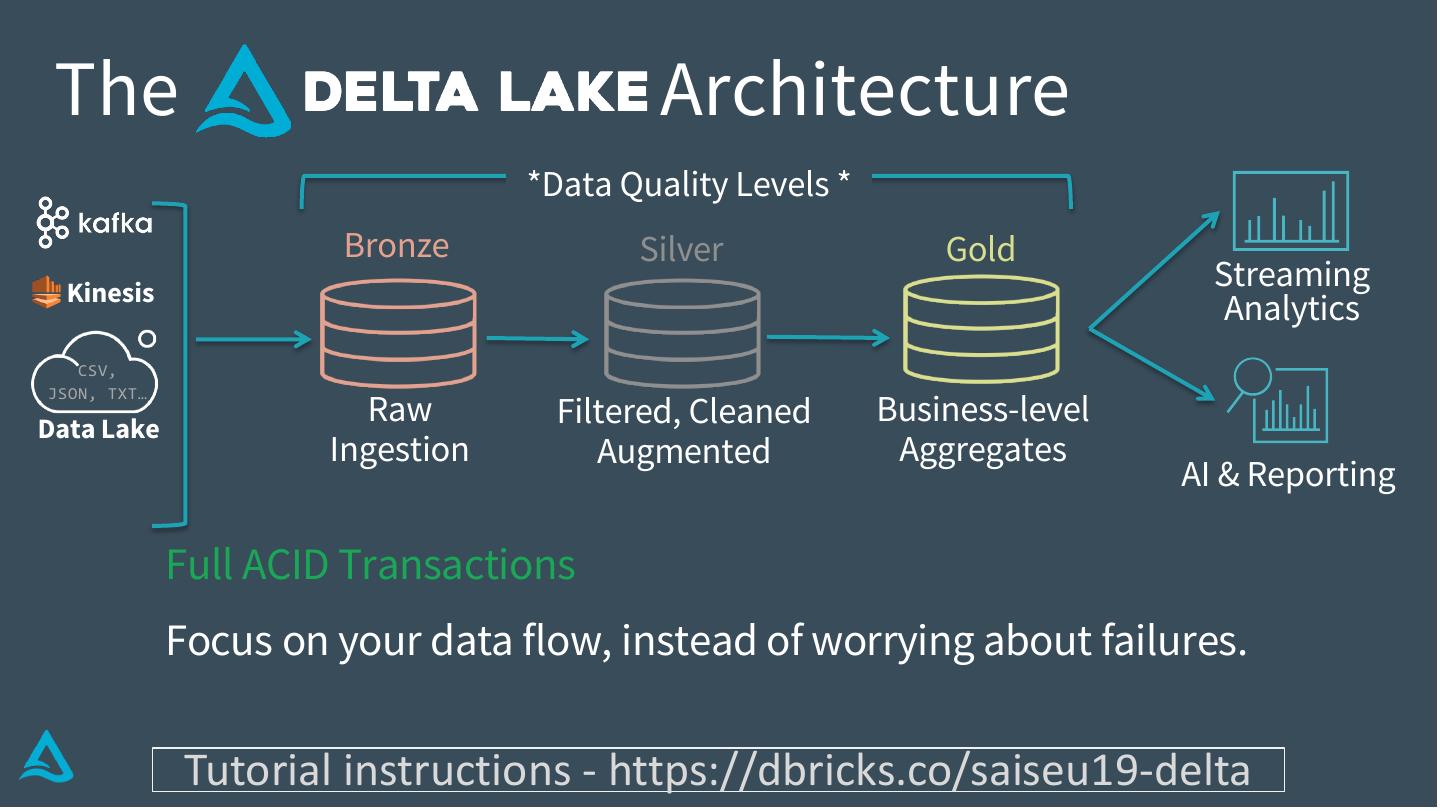
16 . The Architecture
*Data Quality Levels *
Bronze Silver Gold
Kinesis
Streaming
Analytics
CSV,
Raw Business-level
JSON, TXT…
Data Lake
Filtered, Cleaned
Ingestion Augmented Aggregates
AI & Reporting
Full ACID Transactions
Focus on your data flow, instead of worrying about failures.
Tutorial instructions - https://dbricks.co/saiseu19-delta
�
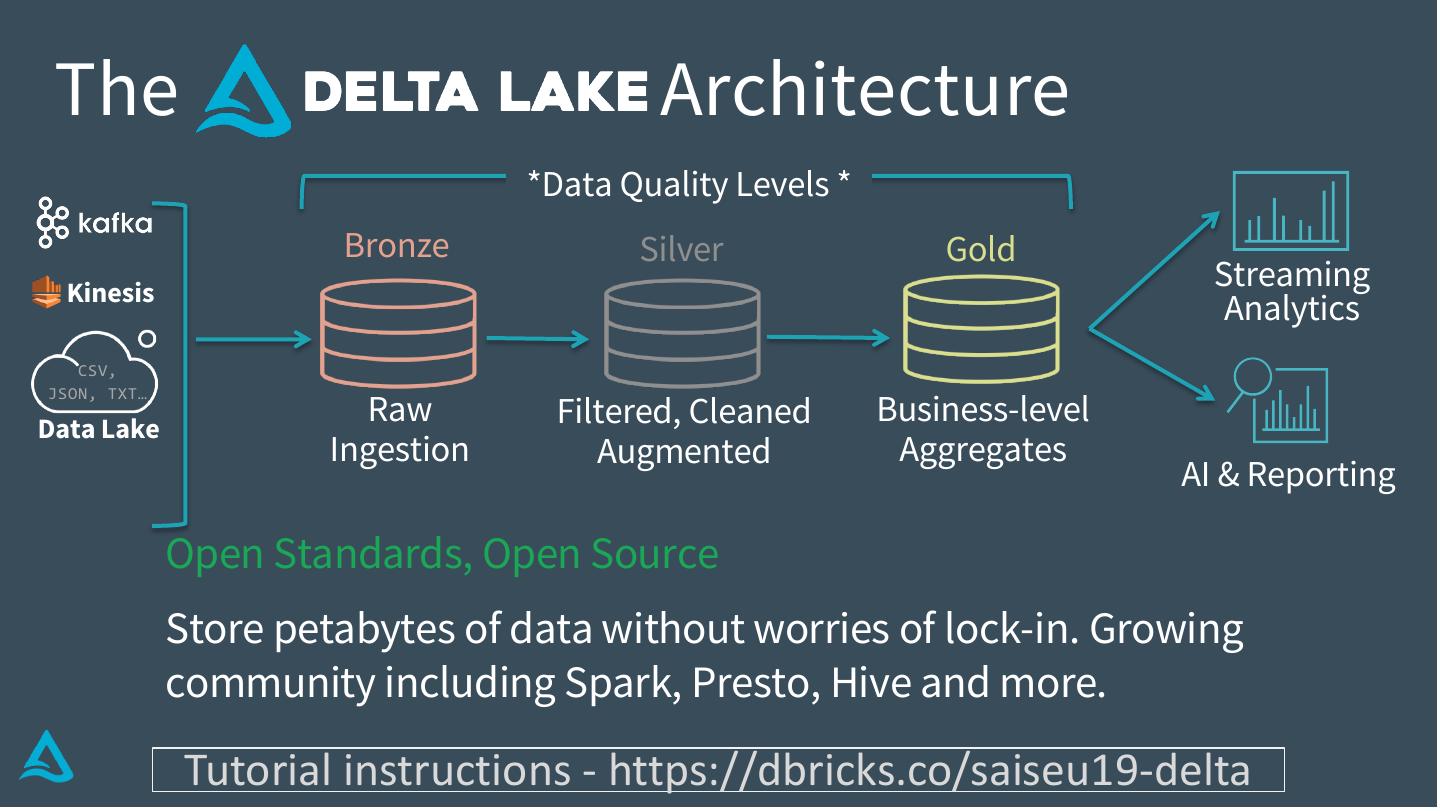
17 . The Architecture
*Data Quality Levels *
Bronze Silver Gold
Kinesis
Streaming
Analytics
CSV,
Raw Business-level
JSON, TXT…
Data Lake
Filtered, Cleaned
Ingestion Augmented Aggregates
AI & Reporting
Open Standards, Open Source
Store petabytes of data without worries of lock-in. Growing
community including Spark, Presto, Hive and more.
Tutorial instructions - https://dbricks.co/saiseu19-delta
�
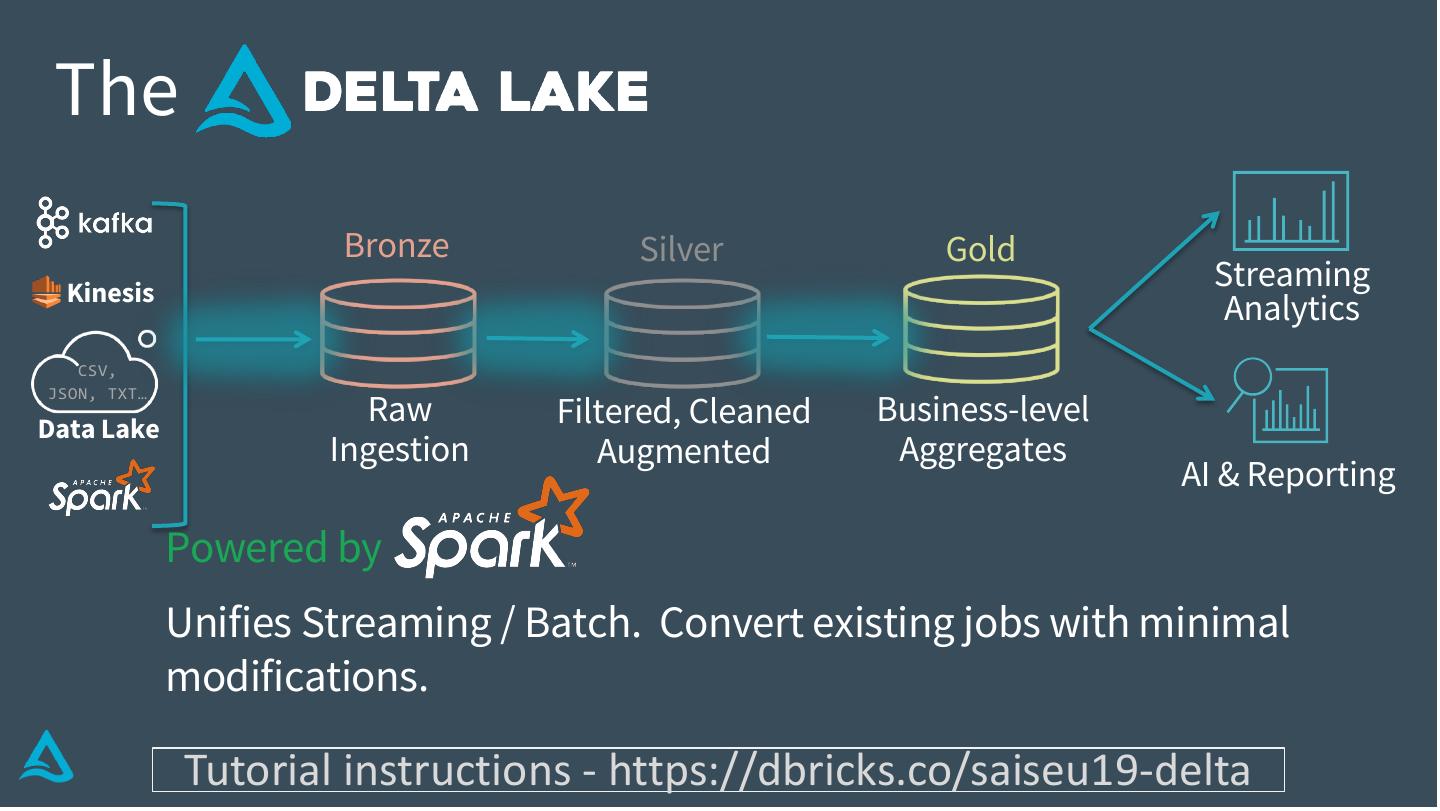
18 . The
Bronze Silver Gold
Kinesis
Streaming
Analytics
CSV,
Raw Business-level
JSON, TXT…
Data Lake
Filtered, Cleaned
Ingestion Augmented Aggregates
AI & Reporting
Powered by
Unifies Streaming / Batch. Convert existing jobs with minimal
modifications.
Tutorial instructions - https://dbricks.co/saiseu19-delta
�
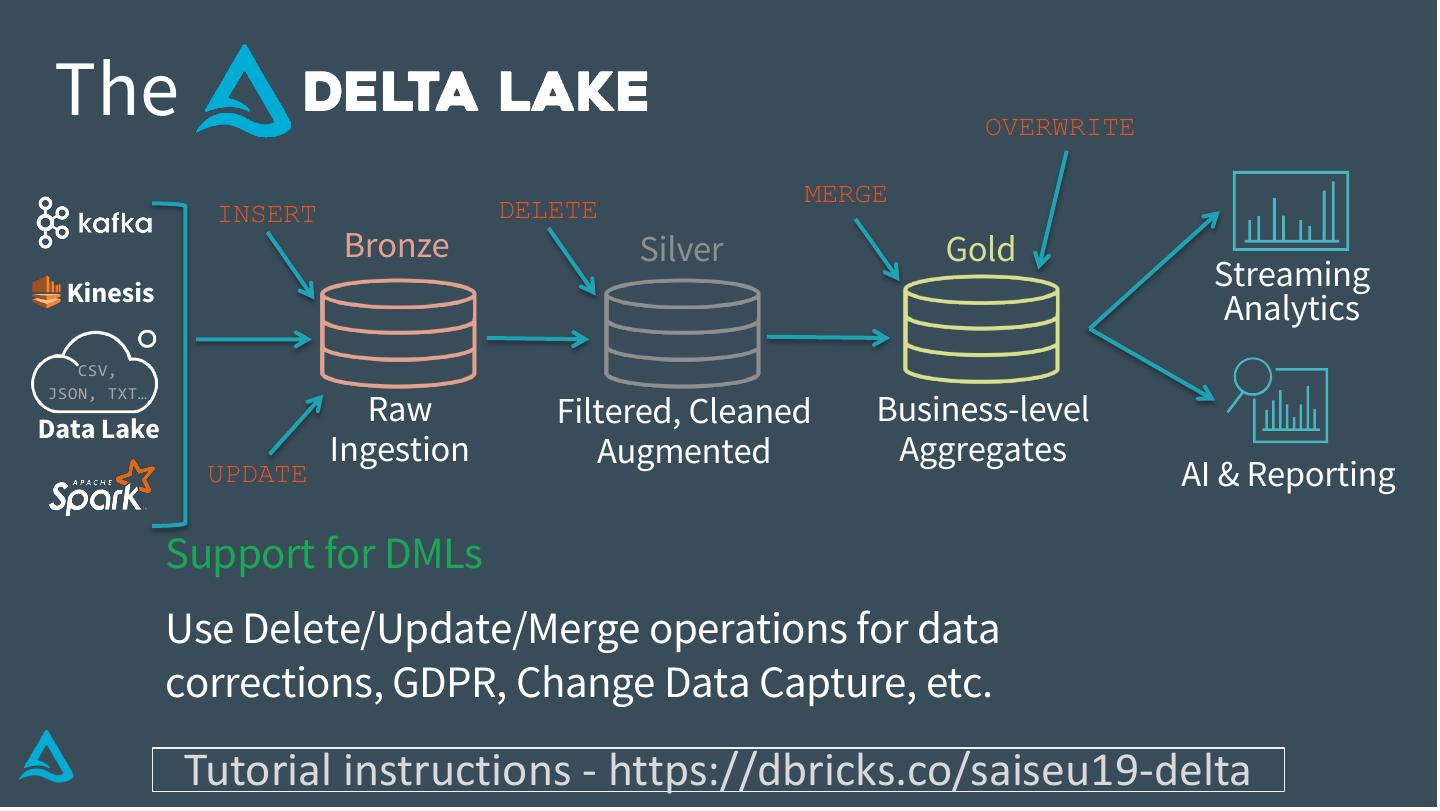
19 . The OVERWRITE
MERGE
INSERT DELETE
Bronze Silver Gold
Kinesis
Streaming
Analytics
CSV,
Raw Business-level
JSON, TXT…
Data Lake
Filtered, Cleaned
Ingestion Augmented Aggregates
UPDATE AI & Reporting
Support for DMLs
Use Delete/Update/Merge operations for data
corrections, GDPR, Change Data Capture, etc.
Tutorial instructions - https://dbricks.co/saiseu19-delta
�
20 .Open source and open formats Delete, Update, Merge
Unified Batch and Streaming Audit History
sources Versioning and Time Travel
ACID Transactions Scalable metadata management
Schema Enforcement and Support from Spark, Presto, Hive
Evolution
Tutorial instructions - https://dbricks.co/saiseu19-delta
�
21 .Used by 1000s of organizations world wide
> 2 exabyte processed last month alone
Tutorial instructions - https://dbricks.co/saiseu19-delta
�
22 .Let’s begin the tutorial!
�
23 .Build your own Delta Lake
at https://delta.io
�