展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Briefing on the Modern
ML Stack with R
Javier Luraschi, RStudio
#UnifiedDataAnalytics #SparkAISummit
�
3 .Intro to R
“R is a programming language and free
software environment for statistical
computing and graphics."
#UnifiedDataAnalytics #SparkAISummit 3
�
4 .Modern R
The tidyverse is an opinionated collection of R packages designed for data
science. All packages share an underlying design philosophy, grammar, and
data structures.
library(tidyverse)
flights %>%
group_by(month, day) %>%
summarise(count = n(), avg_delay = mean(dep_delay, na.rm = TRUE)) %>%
filter(count > 1000)
#UnifiedDataAnalytics #SparkAISummit 4
�
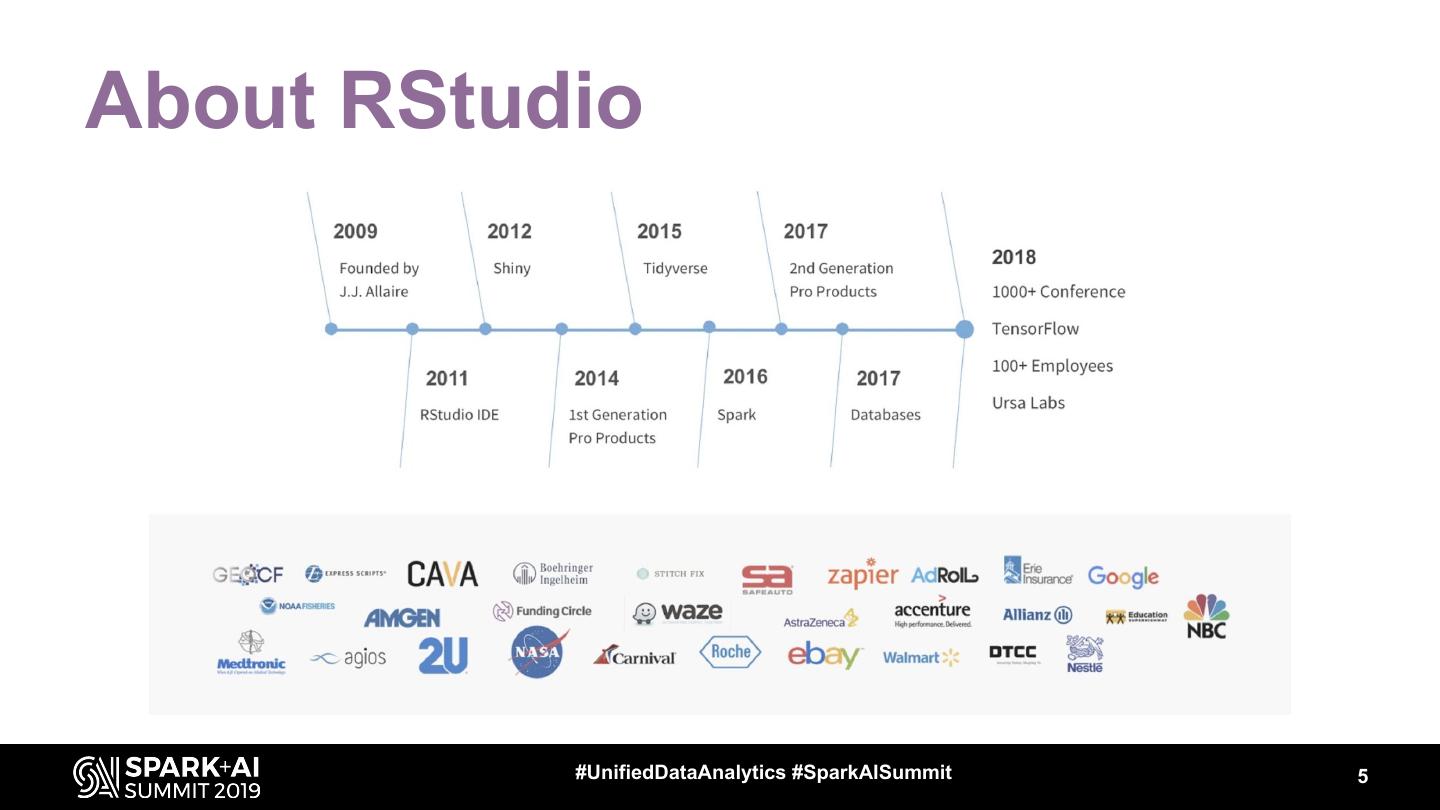
5 .About RStudio
#UnifiedDataAnalytics #SparkAISummit 5
�
6 .RStudio Multiverse Team
Authors of R packages to support Apache Spark, TensorFlow and MLflow.
Contributors to tidyverse and Apache Arrow.
#UnifiedDataAnalytics #SparkAISummit 6
�
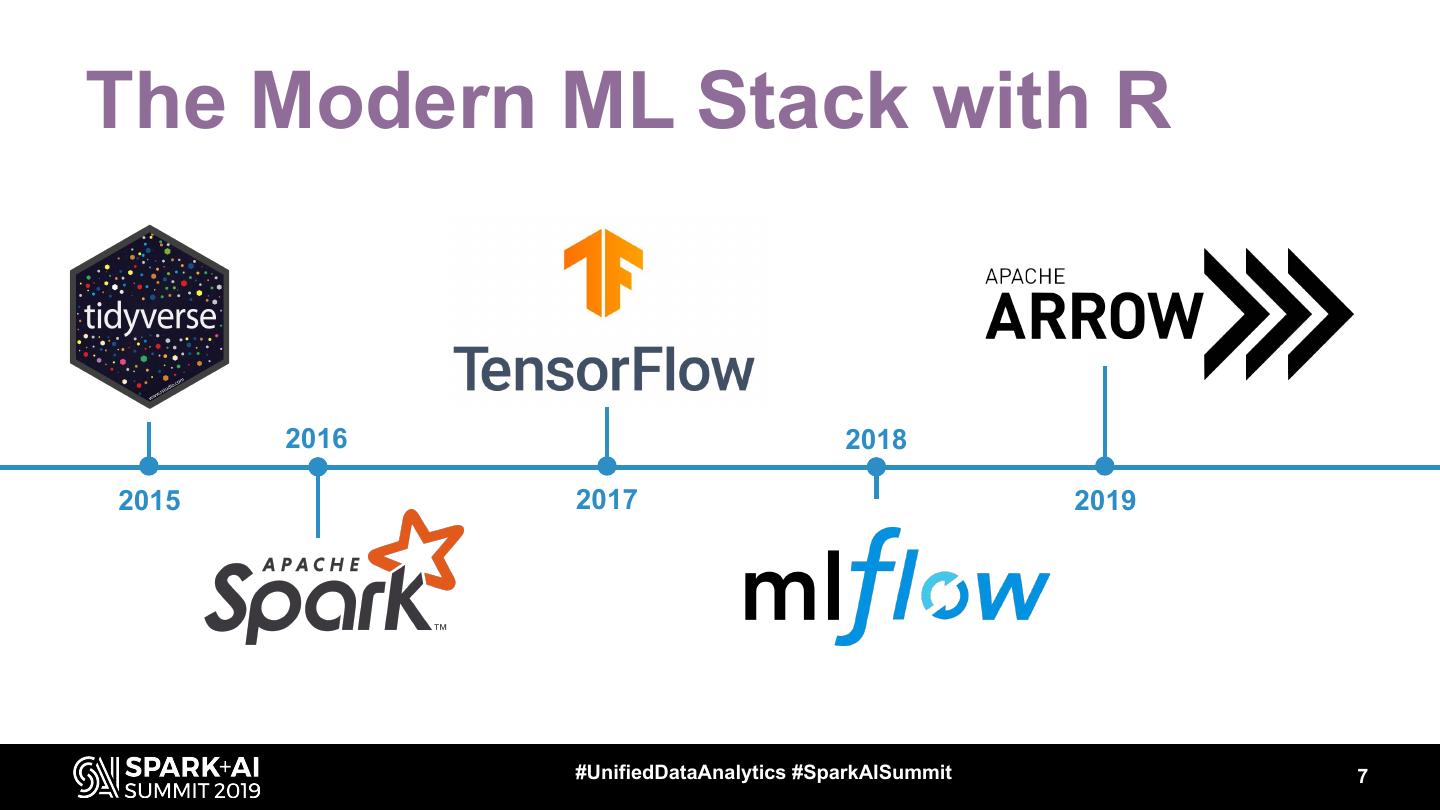
7 .The Modern ML Stack with R
2016 2018
2015 2017 2019
#UnifiedDataAnalytics #SparkAISummit 7
�
8 .#UnifiedDataAnalytics #SparkAISummit 8
�
9 .Spark with R - Motivation
library(sparklyr)
sc <- spark_connect(master = “local|yarn|mesos|spark|livy”)
flights <- copy_to(sc, flights)
library(tidyverse)
flights %>%
group_by(month, day) %>%
summarise(count = n(), avg_delay = mean(dep_delay, na.rm = TRUE)) %>%
filter(count > 1000)
#UnifiedDataAnalytics #SparkAISummit 9
�
10 .Spark with R - Timeline
sparklyr 0.7
Spark
sparklyr 0.5 sparklyr 0.9
Pipelines and
Livy and dplyr Streams and
Machine
improvements. Kubernetes.
Learning.
Sep 2016 Jul 2017 May 2018 Mar 2019
Jan 2017 Jan 2018 Oct 2018 Oct 2019
sparklyr 0.4 sparklyr 0.6 sparklyr 0.8 sparklyr 1.0
R interface for Distributed R and Production Arrow,
Apache Spark. external sources. pipelines and XGBoost,
graphs. Broom and
TFRecords
#UnifiedDataAnalytics #SparkAISummit 10
�
11 .Spark - What’s new?
library(sparklyr)
library(arrow)
#UnifiedDataAnalytics #SparkAISummit 11
�
12 .Spark - What’s new? - XGBoost
library(sparkxgb)
iris <- copy_to(sc, iris)
xgb_model <- xgboost_classifier(iris, Species ~ ., num_class =3, num_round = 50, max_depth = 4)
xgb_model %>% ml_predict(iris) %>%
select(Species, predicted_label, starts_with(
"probability_")) %>% glimpse()
#UnifiedDataAnalytics #SparkAISummit 12
�
13 .Spark - What’s new? - Broom
#UnifiedDataAnalytics #SparkAISummit 13
�
14 .Spark - New? - TF Records
#UnifiedDataAnalytics #SparkAISummit 14
�
15 . Spark - What’s next? - Genomics
github.com/r-spark/variantspark by Samuel Macêdo
library(sparklyr)
library(variantspark)
sc <- spark_connect(master = "local")
vsc <- vs_connect(sc)
hipster_vcf <- vs_read_vcf(vsc, "inst/extdata/hipster.vcf.bz2")
hipster_labels <- vs_read_csv(vsc,
"inst/extdata/hipster_labels.txt")
labels <- vs_read_labels(vsc, "inst/extdata/hipster_labels.txt")
vs_importance_analysis(vsc, hipster_vcf, labels, n_trees = 100)
#UnifiedDataAnalytics #SparkAISummit 15
�
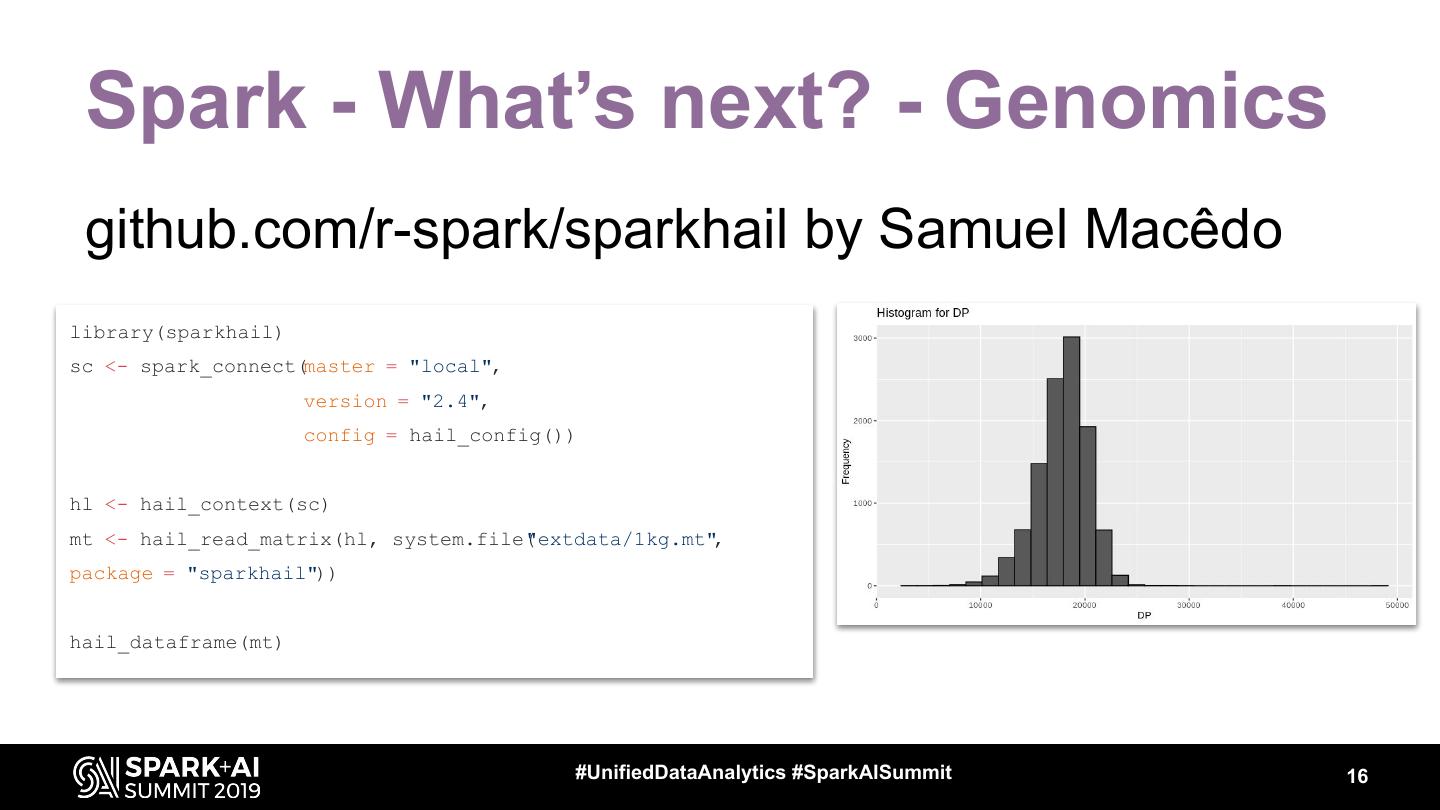
16 . Spark - What’s next? - Genomics
github.com/r-spark/sparkhail by Samuel Macêdo
library(sparkhail)
sc <- spark_connect(master = "local",
version = "2.4",
config = hail_config())
hl <- hail_context(sc)
mt <- hail_read_matrix(hl, system.file(
"extdata/1kg.mt",
package = "sparkhail"))
hail_dataframe(mt)
#UnifiedDataAnalytics #SparkAISummit 16
�
17 .Spark - What’s next? - Genomics
github.com/lawremi/hailr by Michael Lawrence
#UnifiedDataAnalytics #SparkAISummit 17
�
18 .Spark - What’s next? - NLP
github.com/r-spark/sparknlp by Kevin Kuo
#UnifiedDataAnalytics #SparkAISummit 18
�
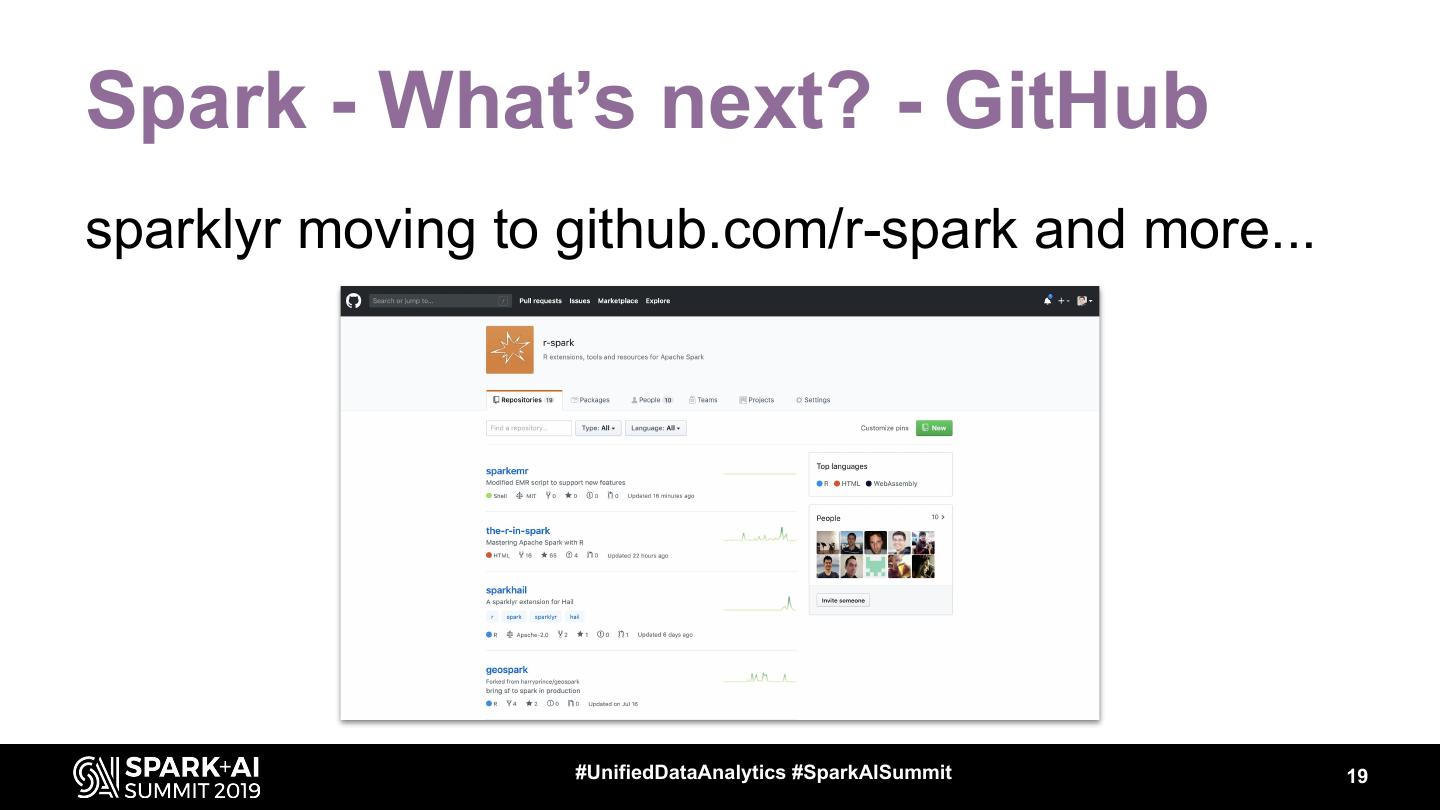
19 .Spark - What’s next? - GitHub
sparklyr moving to github.com/r-spark and more...
#UnifiedDataAnalytics #SparkAISummit 19
�
20 .#UnifiedDataAnalytics #SparkAISummit 20
�
21 .TensorFlow with R - Timeline
tfdatasets 1.5
Initial Release
tensorflow
keras 2.0.5 Eager Execution
Initial Release
Mar 2017 Dec 2017 Jun 2018 Oct 2018
Jul 2017 Jan 2018 Aug 2018
tensorflow 0.7 tfestimators 1.4.2 cloudml 0.5 tfprobability
Initial Release Initial Release Initial Release Initial Release
#UnifiedDataAnalytics #SparkAISummit 21
�
22 .TensorFlow - New? - tfdatasets
Feature specs
ft_spec <- training %>%
select(-id) %>%
feature_spec(target ~ .) %>%
step_numeric_column(ends_with("bin")) %>%
step_numeric_column(-ends_with("bin"),
-ends_with("cat"),
normalizer_fn = scaler_standard()) %>%
step_categorical_column_with_vocabulary_list(ends_with("cat")) %>%
step_embedding_column(ends_with("cat"),
dimension = function(vocab_size) as.integer(sqrt(vocab_size) + 1)) %>%
fit()
#UnifiedDataAnalytics #SparkAISummit 22
�
23 .TensorFlow - New? - tfprobability
Combine probabilistic models and deep learning
on modern hardware
# create a binomial distribution with n = 7 and p = 0.3
d <- tfd_binomial(total_count = 7, probs = 0.3)
# compute mean
d %>% tfd_mean()
# compute variance
d %>% tfd_variance()
# compute probability
d %>% tfd_prob(2.3)
github.com/rstudio/tfprobability
#UnifiedDataAnalytics #SparkAISummit 23
�
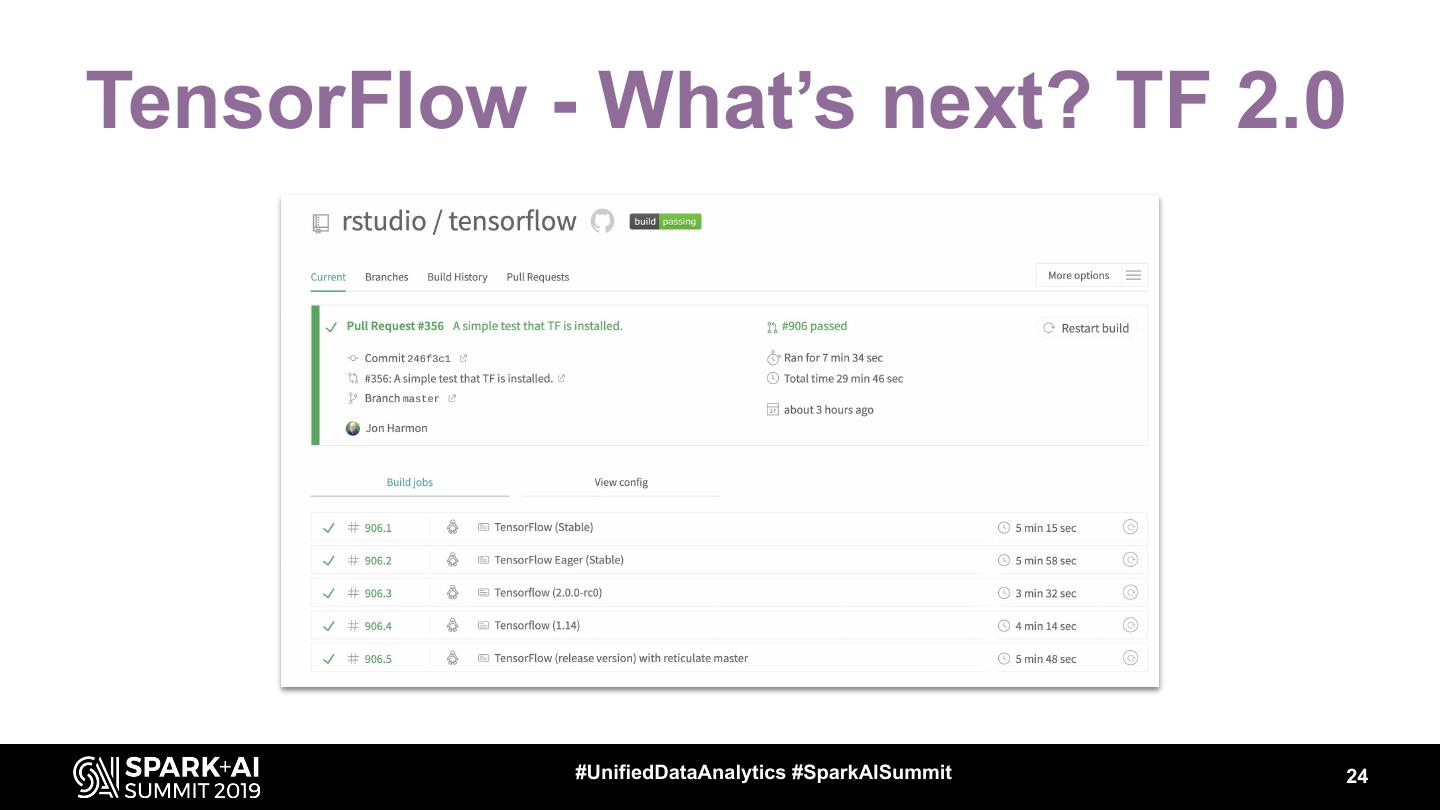
24 .TensorFlow - What’s next? TF 2.0
#UnifiedDataAnalytics #SparkAISummit 24
�
25 .TensorFlow - Next? - Distributed
#UnifiedDataAnalytics #SparkAISummit 25
�
26 .#UnifiedDataAnalytics #SparkAISummit 26
�
27 .MLflow - Timeline
Available in CRAN since v0.7.0
#UnifiedDataAnalytics #SparkAISummit 27
�
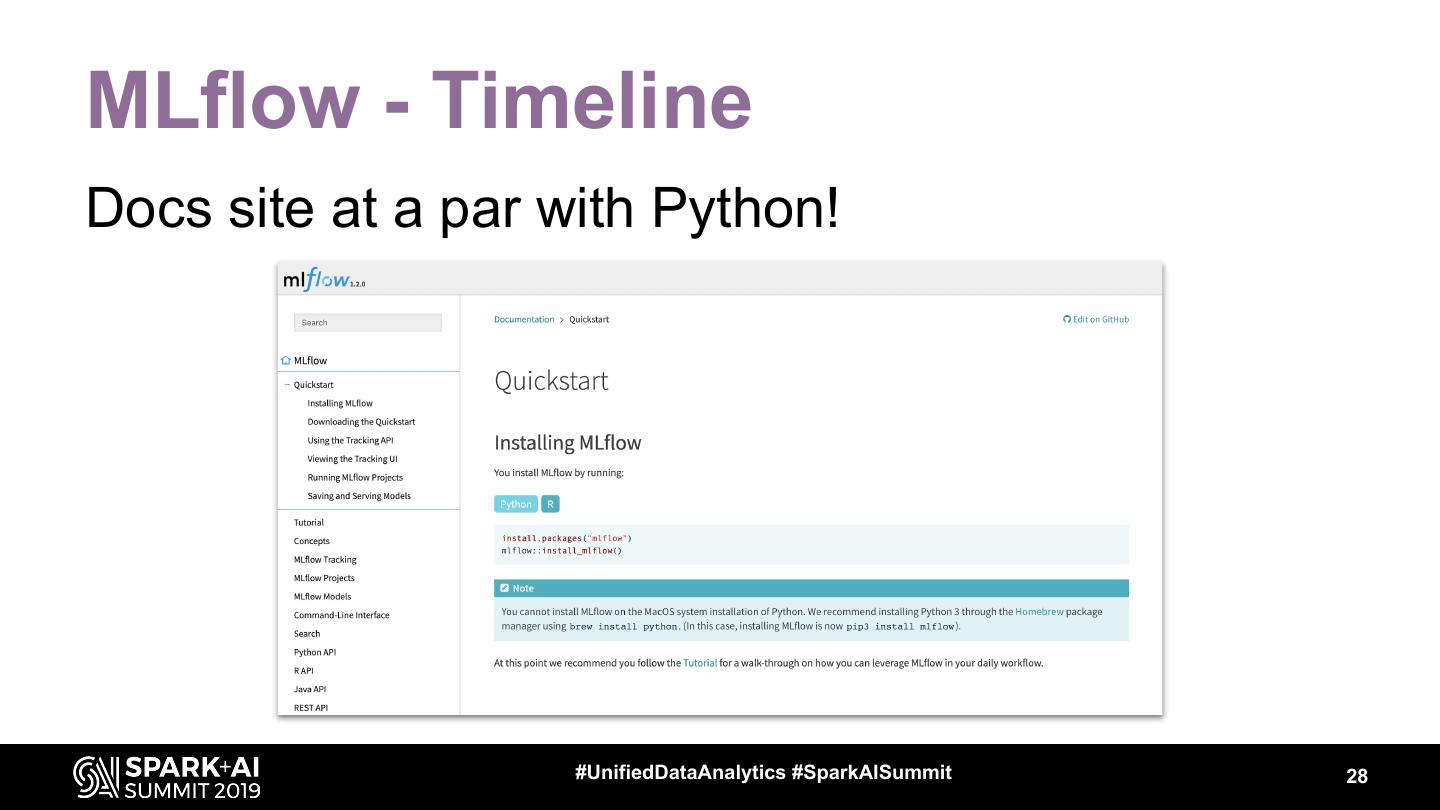
28 .MLflow - Timeline
Docs site at a par with Python!
#UnifiedDataAnalytics #SparkAISummit 28
�
29 .MLflow - What’s next?
● renv (packrat successor)
● Cloud Deployment Targets
● Keras Autolog
#UnifiedDataAnalytics #SparkAISummit 29
�