
























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板

Best Practices for Building and Deploying Data Pipelines in Apache Spark
Best Practices for Building and Deploying Data Pipelines in Apache Spark
Best Practices for Building and Deploying Data Pipelines in Apache Spark
Many data pipelines share common characteristics and are often built in similar but bespoke ways, even within a single organisation. In this talk, we will outline the key considerations which need to be applied when building data pipelines, such as performance, idempotency, reproducibility, and tackling the small file problem. We’ll work towards describing a common Data Engineering toolkit which separates these concerns from business logic code, allowing non-Data-Engineers (e.g. Business Analysts and Data Scientists) to define data pipelines without worrying about the nitty-gritty production considerations.
We’ll then introduce an implementation of such a toolkit in the form of Waimak, our open-source library for Apache Spark (https://github.com/CoxAutomotiveDataSolutions/waimak), which has massively shortened our route from prototype to production. Finally, we’ll define new approaches and best practices about what we believe is the most overlooked aspect of Data Engineering: deploying data pipelines.
展开查看详情
1 .Best Practices for Building and Deploying Data Pipelines in Apache Spark Vicky Avison Cox Automotive UK Alex Bush KPMG Lighthouse New Zealand #UnifiedDataAnalytics #SparkAISummit
2 .Cox Automotive Data Platform
3 .KPMG Lighthouse Centre of Excellence for Information and Analytics We provide services across the data value chain including: ● Data strategy and analytics maturity assessment ● Information management ● Data engineering ● Data warehousing, business intelligence (BI) and data visualisation ● Data science, advanced analytics and artificial intelligence (AI) ● Cloud-based analytics services
4 .What is this talk about? - What are data pipelines and who builds them? - Why is data pipeline development difficult to get right? - How have we changed the way we develop and deploy our data pipelines?
5 .What are data pipelines and who builds them?
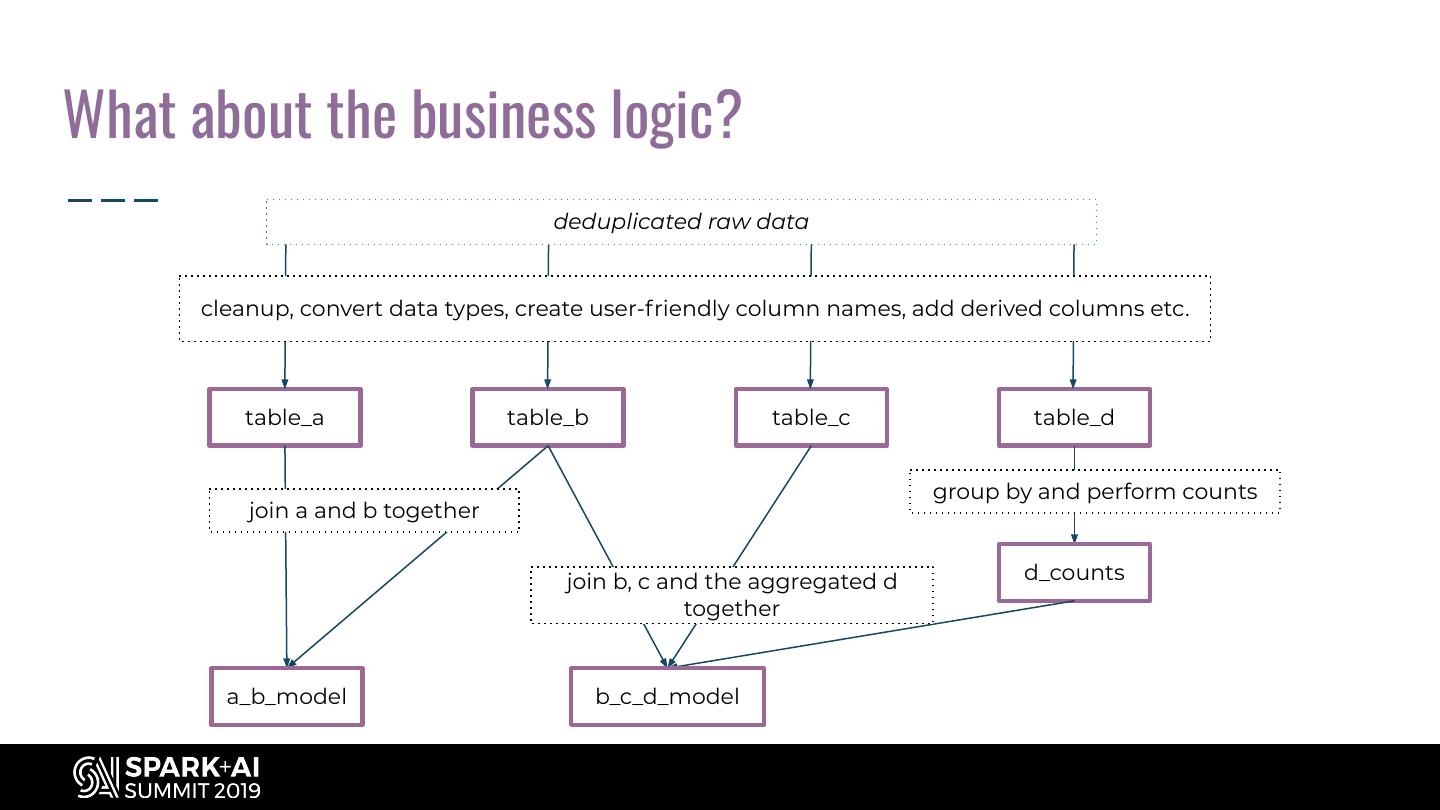
6 .What do we mean by ‘Data Pipeline’? 1 Ingest the raw data Data Platform (storage + compute) Data Sources 2 Prepare the data for use (e.g. files, relational raw data prepared data in further analysis and databases, REST APIs) 1 2 dashboards, meaning: table_a data model_a table_b a. Deduplication table_c data model_b b. Cleansing c. Enrichment ... d. Creation of data data model_c table_d models i.e joins, aggregations etc. table_e data model_d table_f ...
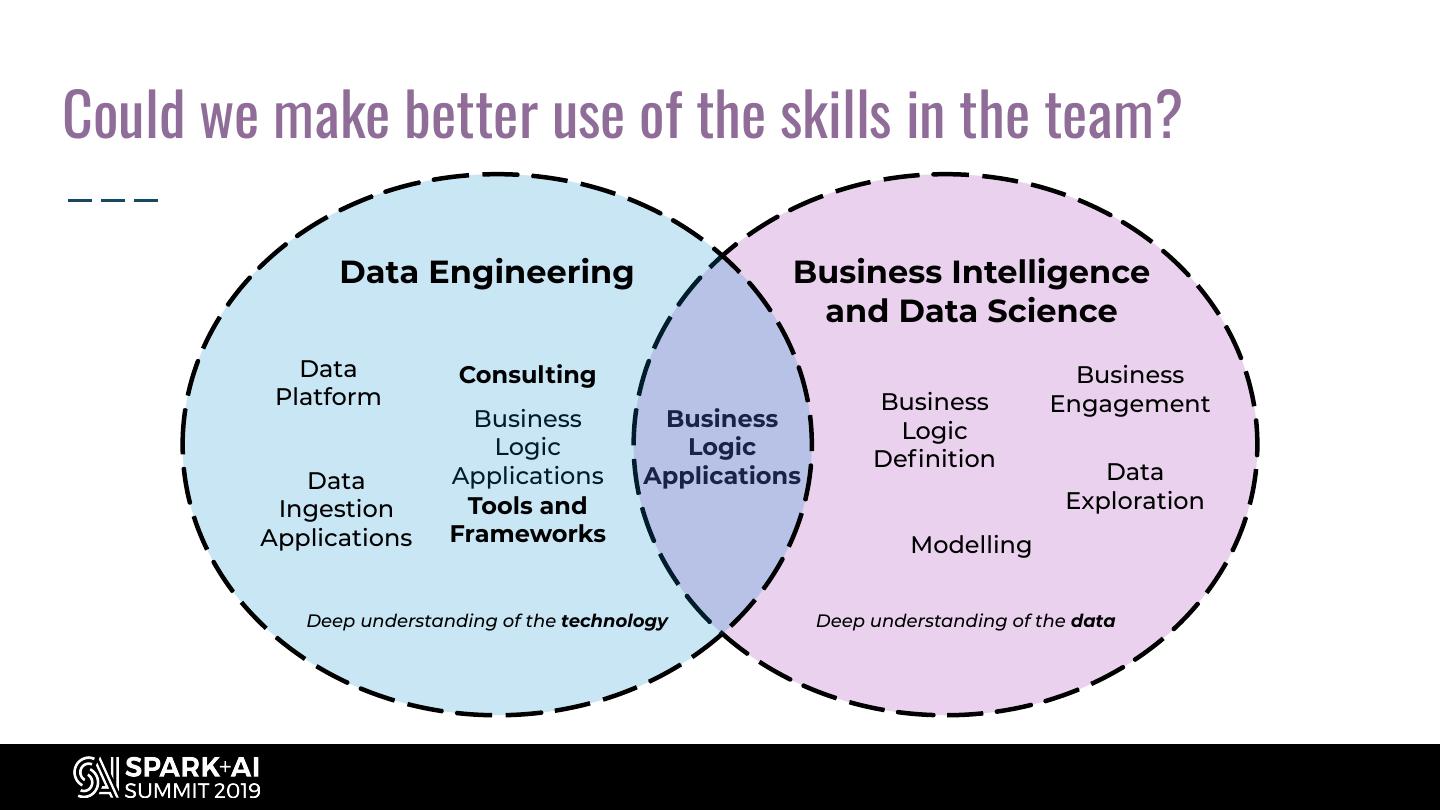
7 .Who is in a data team? Data Engineering Business Intelligence and Data Science Deep understanding of the technology Deep understanding of the data Know how to build robust, Know how to extract business performant data pipelines value from the data
8 .Why is data pipeline development difficult to get right?
9 .What do we need to think about when building a pipeline? 1. How do we handle late-arriving or duplicate data? 2. How can we ensure that if the pipeline fails part-way through, we can run it again without any problems? 3. How do we avoid the small-file problem? 4. How do we monitor data quality? 5. How do we configure our application? (credentials, input paths, output paths etc.) 6. How do we maximise performance? 7. How do extract only what we need from the source (e.g. only extract new records from RDBM)?
10 .What about the business logic? deduplicated raw data cleanup, convert data types, create user-friendly column names, add derived columns etc. table_a table_b table_c table_d group by and perform counts join a and b together join b, c and the aggregated d d_counts together a_b_model b_c_d_model
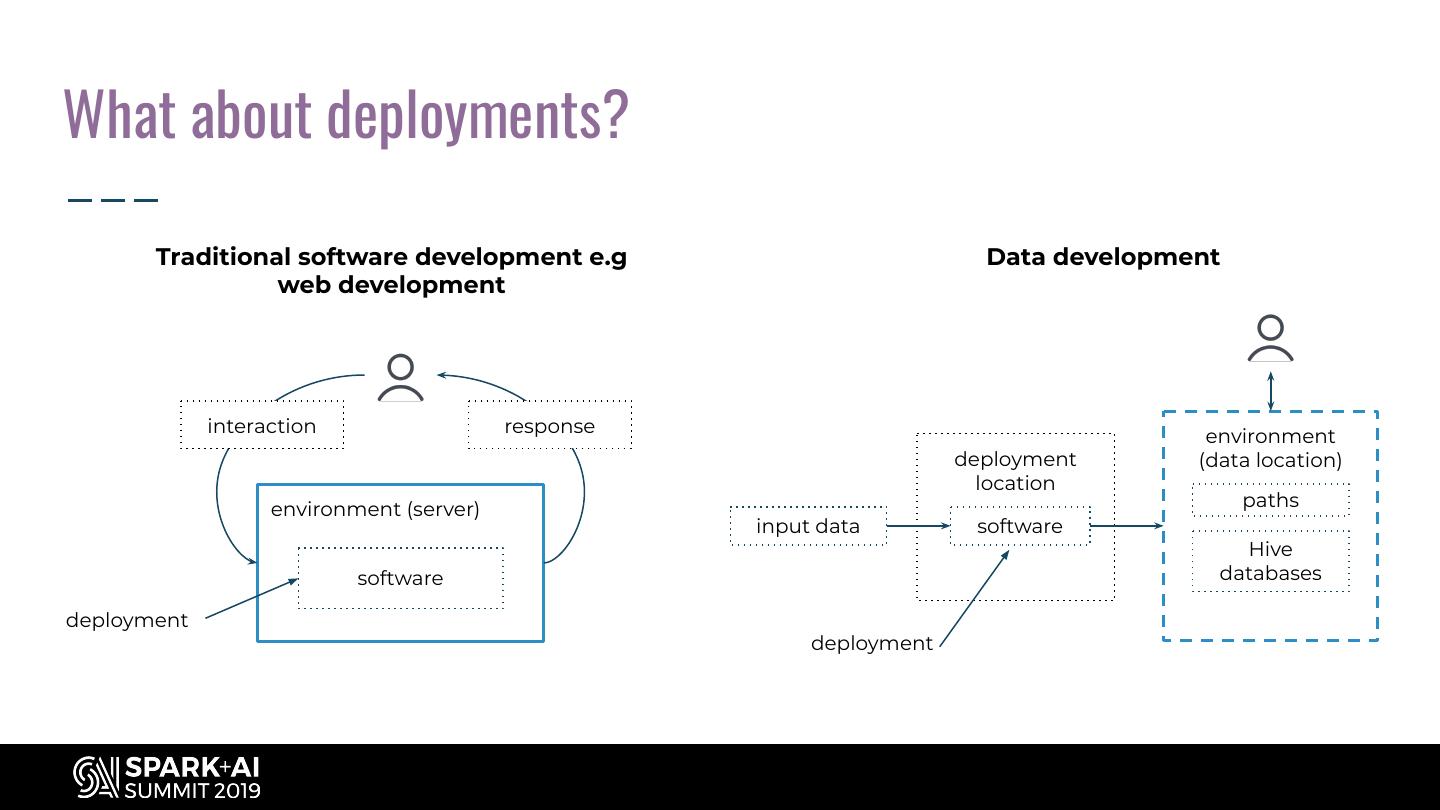
11 .What about deployments? Traditional software development e.g Data development web development interaction response environment deployment (data location) location environment (server) paths input data software Hive software databases deployment deployment
12 .What are the main challenges? - A lot of overhead for every new data pipeline, even when the problems are very similar each time - Production-grade business logic is hard to write without specialist Data Engineering skills - No tools or best practice around deploying and managing environments for data pipelines
13 .How have we changed the way we develop and deploy our data pipelines?
14 .A long(ish) time ago, in an office quite far away….
15 .How were we dealing with the main challenges? A lot of overhead for every new data pipeline, even when the problems are very similar each time We were… shoehorning new pipeline requirements into a single application in an attempt to avoid the overhead
16 .How were we dealing with the main challenges? Production-grade business logic hard to write without specialist Data Engineering skills We were… taking business logic defined by our BI and Data Science colleagues and reimplementing it
17 .How were we dealing with the main challenges? No tools or best practice around deploying and managing environments for data pipelines We were… manually deploying jars, passing environment-specific configuration to our applications each time we ran them
18 .Could we make better use of the skills in the team? Data Engineering Business Intelligence and Data Science Data Consulting Business Platform Business Engagement Business Business Logic Logic Logic Definition Data Applications Applications Data Ingestion Tools and Exploration Applications Frameworks Modelling Deep understanding of the technology Deep understanding of the data
19 .What tools and frameworks would we need to provide? Data Engineering Data Engineering frameworks Data Engineering Data Science and Business tools Applications Intelligence Applications Configuration Environment Data Ingestion Business Logic Management Management Idempotency and Boilerplate and Deduplication Atomicity Structuring Application Deployment Table Metadata Compaction Action Coordination Management Third-party services and libraries Spark and Hadoop KMS Delta Lake Deequ Etc...
20 .How would we design a Data Engineering framework? Business Logic Input High-level APIs Performance Optimisations Configuration Mgmt { Inputs } Data Quality Monitoring Deduplication Compaction { Transformations } Business Logic { Outputs } etc. Output Spark and Hadoop Complexity hidden Intuitive structuring of Efficient scheduling of Injection of optimisations behind high-level APIs business logic code transformations and and monitoring actions
21 . How would we like to manage deployments? Paths v 0.1 v 0.2 /data/prod/my_project master /data/dev/my_project/feature_one feature/two /data/dev/my_project/feature_two feature/one Deployed jars Hive databases my_project-0.2.jar my_project-0.1.jar prod_my_project my_project_feature_one-0.2-SNAPSHOT.jar dev_my_project_feature_one my_project_feature_two-0.2-SNAPSHOT.jar dev_my_project_feature_two
22 .What does this look like in practice?
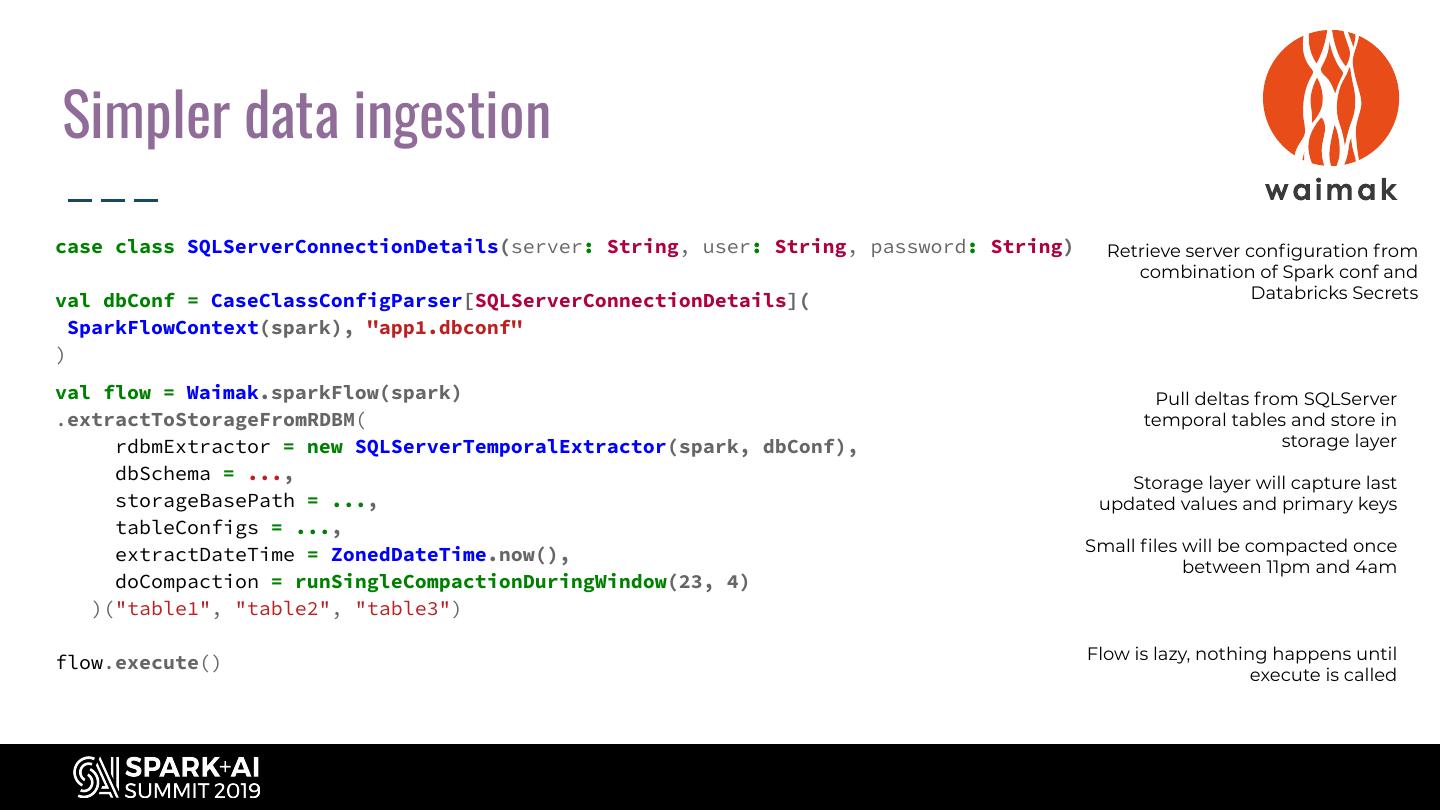
23 .Simpler data ingestion case class SQLServerConnectionDetails(server: String, user: String, password: String) Retrieve server configuration from combination of Spark conf and val dbConf = CaseClassConfigParser[SQLServerConnectionDetails]( Databricks Secrets SparkFlowContext(spark), "app1.dbconf" ) val flow = Waimak.sparkFlow(spark) Pull deltas from SQLServer .extractToStorageFromRDBM( temporal tables and store in rdbmExtractor = new SQLServerTemporalExtractor(spark, dbConf), storage layer dbSchema = ..., Storage layer will capture last storageBasePath = ..., updated values and primary keys tableConfigs = ..., Small files will be compacted once extractDateTime = ZonedDateTime.now(), between 11pm and 4am doCompaction = runSingleCompactionDuringWindow(23, 4) )("table1", "table2", "table3") Flow is lazy, nothing happens until flow.execute() execute is called
24 .Simpler business logic development val flow = Waimak.sparkFlow(spark) Execute with flow.execute() .snapshotFromStorage(basePath, tsNow)("table1", "table2", "table3") Read from storage layer and deduplicate .transform("table1", "table2")("model1")( Perform two transformations on labels (t1, t2) => t1.join(t2, "pk1") using the DataFrame API, generating ) two more labels .transform("table3", "model1")("model2")( (t3, m1) => t3.join(m1, "pk2") ) .sql("table1", "model2")("reporting1", Perform a Spark SQL transformation on a table and label generated during a """select m2.pk1, count(t1.col1) from model2 m2 transform, generating one more label left join table1 t1 on m2.pk1 = t1.fpk1 group by m2.pk1""" ) .writeHiveManagedTable("model_db")("model1", "model2") Write labels to two different databases .writeHiveManagedTable("reporting_db")("reporting1") .sparkCache("model2") Add explicit caching and data quality .addDeequCheck( monitoring actions "reporting1", Check(Error, "Not valid PK").isPrimaryKey("pk1") )(ExceptionQualityAlert())
25 .Simpler environment management case class MySparkAppEnv(project: String, //e.g. my_spark_app Environment consists of a base path: environment: String, //e.g. dev /data/dev/my_spark_app/feature_one/ branch: String //e.g. feature/one And a Hive database: ) extends HiveEnv dev_my_spark_app_feature_one object MySparkApp extends SparkApp[MySparkAppEnv] { Define application logic given a override def run(sparkSession: SparkSession, env: MySparkAppEnv): Unit = SparkSession and an environment //We have a base path and Hive database available in env via env.basePath and env.baseDBName Use MultiAppRunner to run apps ??? individually or together with dependencies } spark.waimak.apprunner.apps = my_spark_app spark.waimak.apprunner.my_spark_app.appClassName = com.example.MySparkApp spark.waimak.environment.my_spark_app.environment = dev spark.waimak.environment.my_spark_app.branch = feature/one
26 .Simpler deployments
27 .Questions? github.com/ CoxAutomotiveDataSolutions/ waimak
3秒后跳转登录页面
去登陆

