展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Automating Loss
Prevention Using NLP
with FastAI on Azure
Databricks
Mike Vedomske, PhD, PetSmart
#UnifiedDataAnalytics #SparkAISummit
�
3 .Who are we?
• 1,600 stores in North America
• Largest specialty pet retailer
Our team: Advanced Analytics Group
A small team of business-oriented strategy and data
science professionals
#UnifiedDataAnalytics #SparkAISummit 3
�
4 .The Use Case
Loss prevention
Reduction of preventable losses whether it be
from, theft, fraud, vandalism, waste, abuse,
incidents, accidents, or misconduct.
#UnifiedDataAnalytics #SparkAISummit 4
�
5 .The Use Case
• The Ask: Can we automate this please?
– If we can auto-classify low-priority reports so
investigators can spend time on higher-priority
– I.e., actually investigate
– Improve daily work experience and results of current
investigators, reduce need for more hires
The (Implied) Need: Near-Human Performance
#UnifiedDataAnalytics #SparkAISummit 5
�
6 .The Data
• 13 years or ~500k store reports
• Imbalanced data: most were low-priority
• Free text, frequent incorrect spelling and
grammar, unconventional abbreviations
• Legacy system was a mess, broken since 2001:
– Field leakage
– Some behavior auto-triggered high priority
#UnifiedDataAnalytics #SparkAISummit 6
�
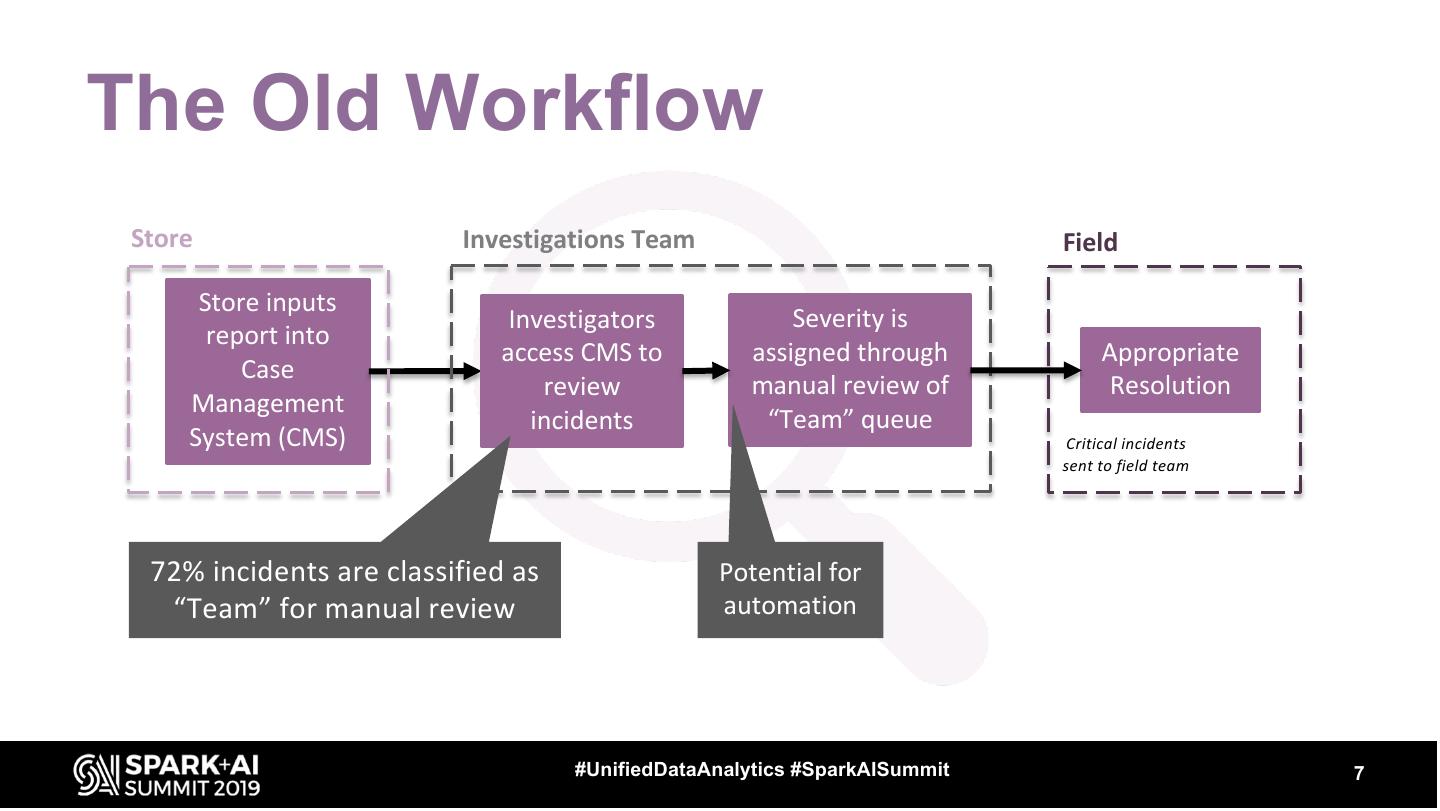
7 .The Old Workflow
Store Investigations Team Field
Store inputs
Investigators Severity is
report into
access CMS to assigned through Appropriate
Case
review manual review of Resolution
Management
incidents “Team” queue
System (CMS) Critical incidents
sent to field team
72% incidents are classified as Potential for
“Team” for manual review automation
#UnifiedDataAnalytics #SparkAISummit 7
�
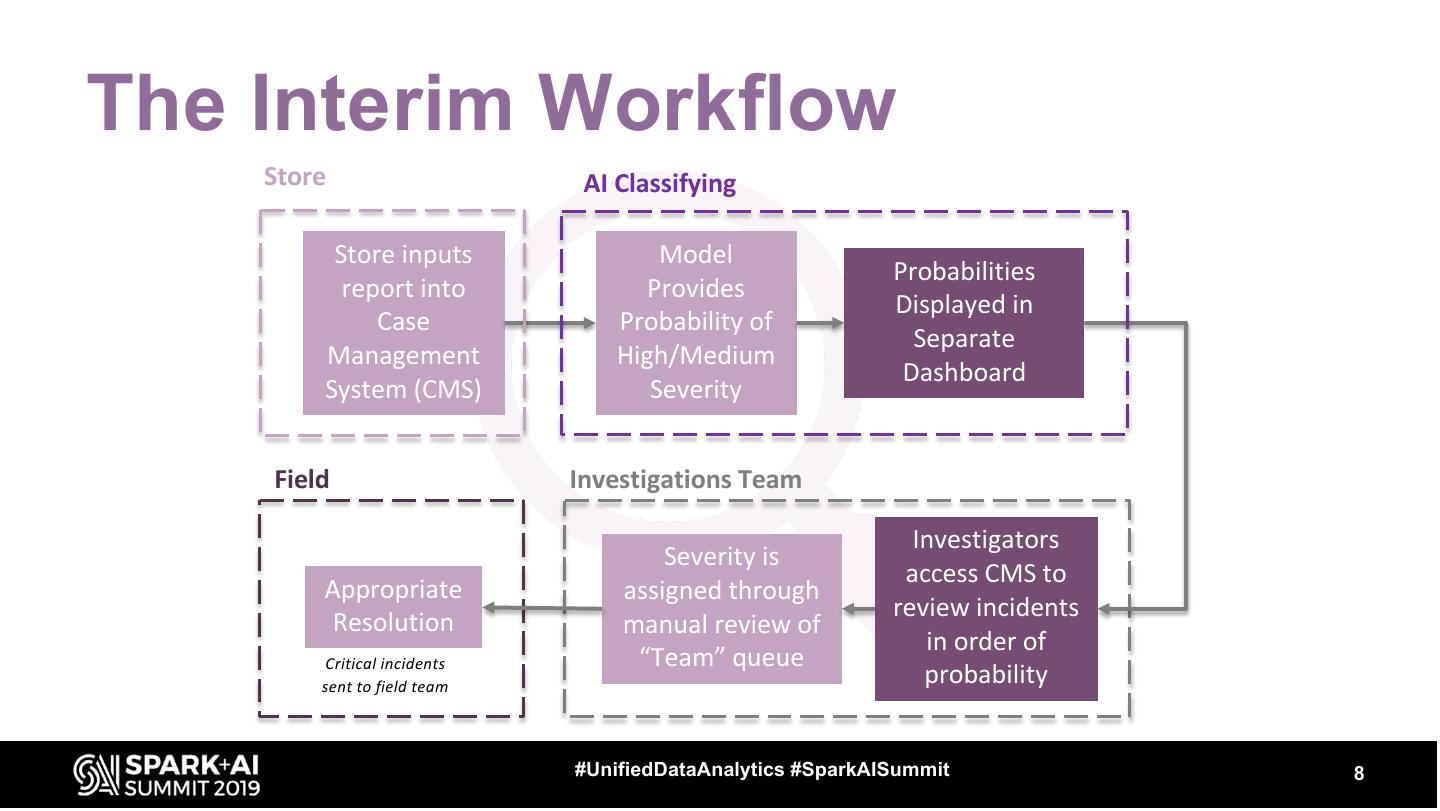
8 .The Interim Workflow
Store AI Classifying
Store inputs Model
Probabilities
report into Provides
Displayed in
Case Probability of
Separate
Management High/Medium
Dashboard
System (CMS) Severity
Field Investigations Team
Investigators
Severity is
access CMS to
Appropriate assigned through
review incidents
Resolution manual review of
in order of
Critical incidents “Team” queue
sent to field team
probability
#UnifiedDataAnalytics #SparkAISummit 8
�
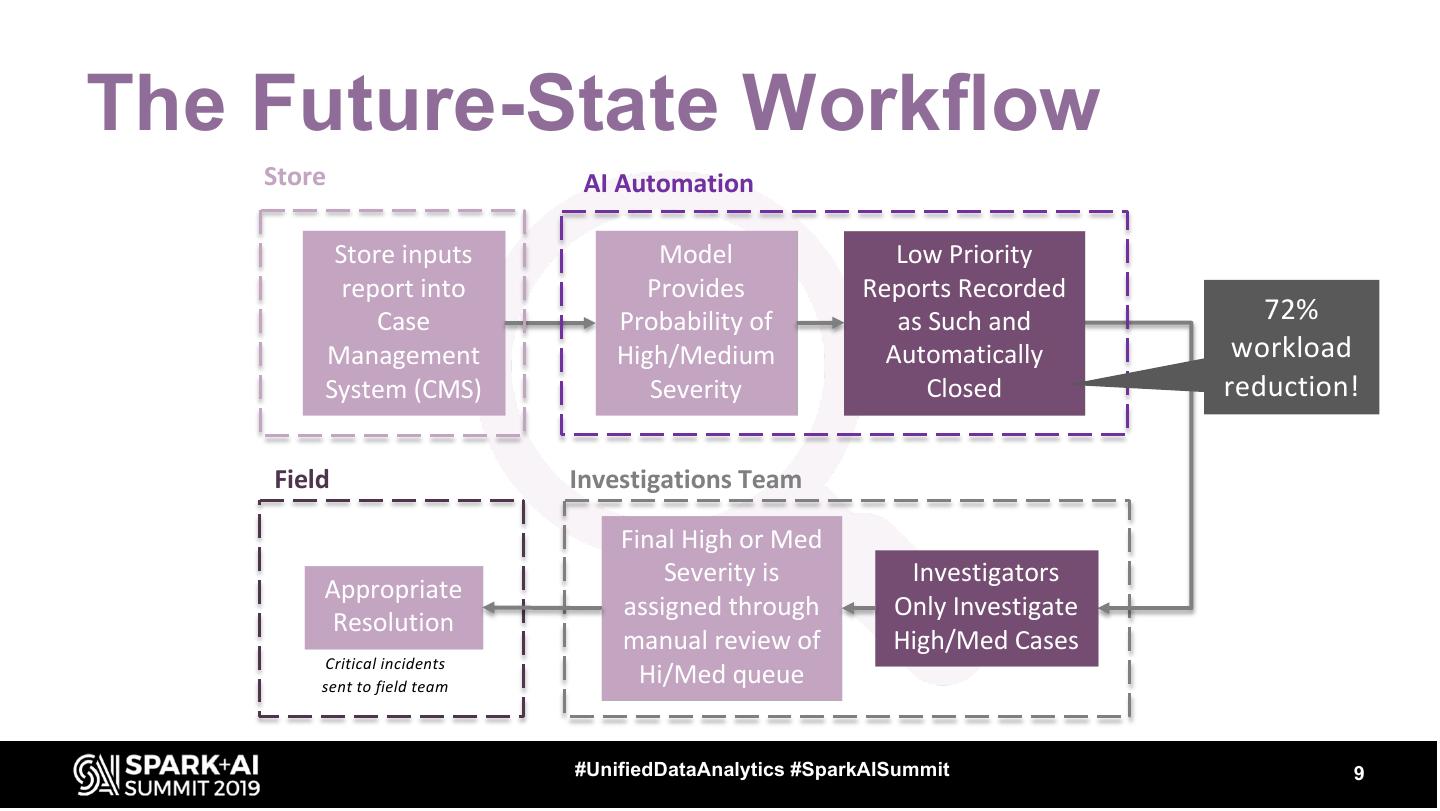
9 .The Future-State Workflow
Store AI Automation
Store inputs Model Low Priority
report into Provides Reports Recorded
Case Probability of as Such and 72%
Management High/Medium Automatically workload
System (CMS) Severity Closed reduction!
Field Investigations Team
Final High or Med
Severity is Investigators
Appropriate
assigned through Only Investigate
Resolution
manual review of High/Med Cases
Critical incidents
sent to field team
Hi/Med queue
#UnifiedDataAnalytics #SparkAISummit 9
�
10 .Early Modeling Attempts
• TF-IDF, word counts, n-gram TF-IDF
• Classifiers tried:
– Logistic Regression (81% AUC)
– Random Forest (64% AUC) ß ¯\_(ツ)_/¯
– XGBoost (75% multiclass accuracy)
• Performance was…fine, but not good enough
#UnifiedDataAnalytics #SparkAISummit 10
�
11 .FastAI:NLP A (Super) Brief Intro
• Who: Jeremy Howard & Sebastian Ruder
• What: “an effective transfer learning method that can be applied to
any task in NLP, and…techniques that are key for fine-tuning a
language model.”
• What: “Our method significantly outperforms the state-of-the-art on
six text classification tasks, reducing the error by 18-24% on the majority
of datasets. Furthermore, with only 100 labeled examples, it matches the
performance of training from scratch on 100x more data.”
#UnifiedDataAnalytics #SparkAISummit 11
�
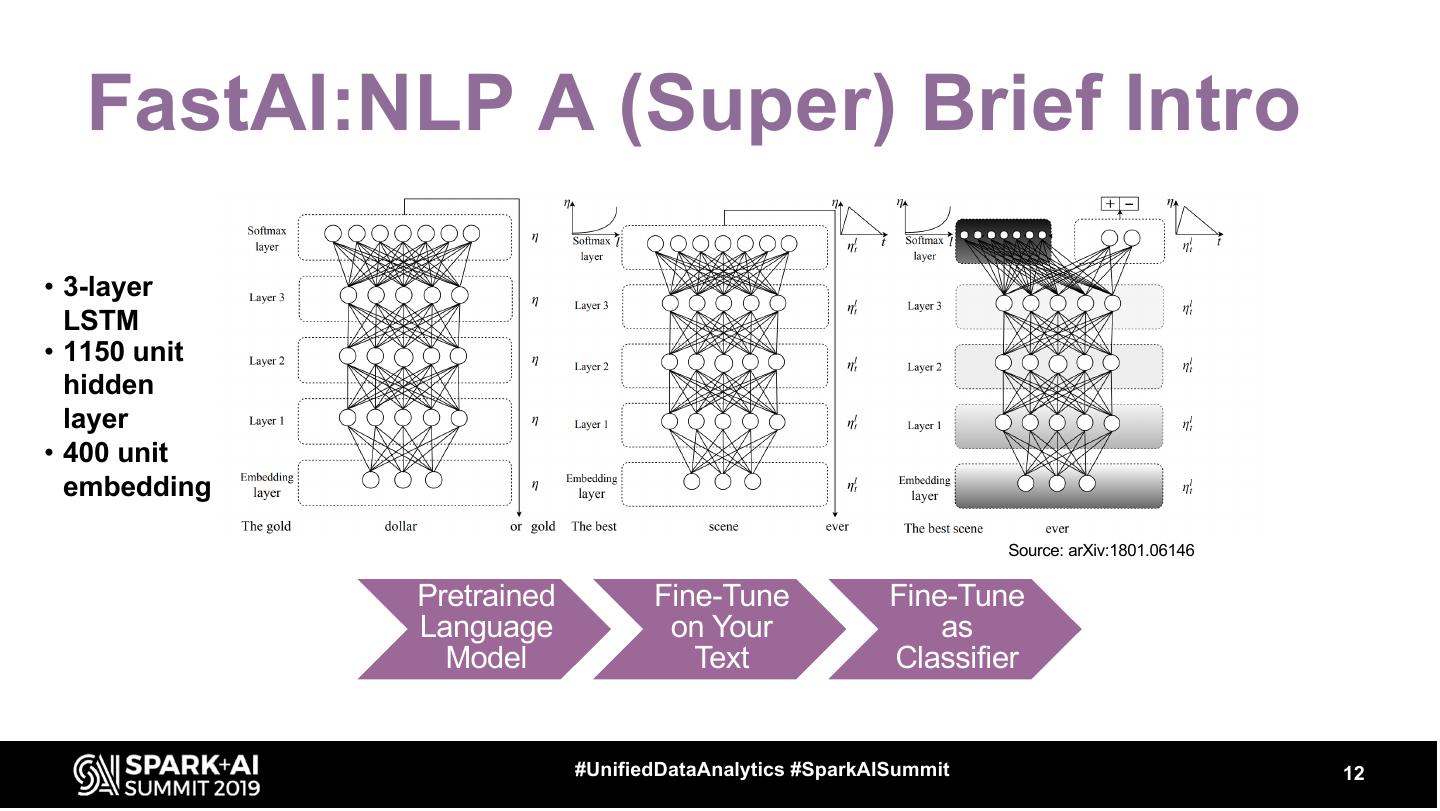
12 . FastAI:NLP A (Super) Brief Intro
• 3-layer
LSTM
• 1150 unit
hidden
layer
• 400 unit
embedding
Source: arXiv:1801.06146
Pretrained Fine-Tune Fine-Tune
Language on Your as
Model Text Classifier
#UnifiedDataAnalytics #SparkAISummit 12
�
13 .FastAI:NLP A (Super) Brief Intro
Pretrained Fine-Tune Fine-Tune
Language on Your as
Model Text Classifier
1. “carefully control how fast our model learns”
2. “update the pre-trained model so that it does not forget what it has
previously learned”
3. “we can make training text classification models for languages
other than English a lot easier as all we need is access to a
Wikipedia, which is currently available for 301 languages”
#UnifiedDataAnalytics #SparkAISummit 13
�
14 .FastAI on “the big Mac”
The Original Setup
• Mac Pro, 64 GB RAM, 2.7 GHz 12-
Core Intel Xeon E5
• NO NVIDIA GPUs
• Jupyter notebook
7 days for Language Model
Tuning…we need something else
The Big Mac
#UnifiedDataAnalytics #SparkAISummit 14
�
15 .FastAI on Azure Databricks
• The Setup
– FastAI 0.7.0 "This is an alpha version.”
– Needed Python 3.6+ and a bunch of dependencies
• Providence Provided!
– 5.0 ML (Beta), now deprecated
– Driver: 4 Nvidia GPUs, 224 GB RAM
– 1 worker: 2 GPUs, 112 GB RAM
#UnifiedDataAnalytics #SparkAISummit 15
�
16 .FastAI Performance
• Initial Model Performance
– Forward only model: 92% accuracy
– Bidirectional model: 93% accuracy
• Language Model fine tuning: ~24 hours
• Classifier Training: ~24 hours
#UnifiedDataAnalytics #SparkAISummit 16
�
17 .Squeezing Out a Bit More Juice
• Train LM on all data 2005-Present
• Train Classifier on 2016+ data
• Final Classifier Performance:
96% accuracy…yeah, we can use this
Pretrained Fine-Tune Fine-Tune
Language on Your as
Model Text Classifier
#UnifiedDataAnalytics #SparkAISummit 17
�
18 .FastAI in Production
• Score hourly (streaming in the future?)
• Retrain monthly, adds latest reports
• Moving it from dev to production was super
easy on Azure Databricks:
1. Clone
2. Configure Cluster
3. Create Job
#UnifiedDataAnalytics #SparkAISummit 18
�
19 .Final Thoughts
• Took some work to get it up and running
• Performance is spectacular
• Azure Databricks was most cost effective
#UnifiedDataAnalytics #SparkAISummit 19
�
20 .DON’T FORGET TO RATE
AND REVIEW THE SESSIONS
SEARCH SPARK + AI SUMMIT
�