


























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Automated Production Ready ML at Scale_iteblog
• AI journey @ H&M
• Machine learning blueprint
• Automated ML development process
• ML orchestration for scale
展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
2 .AUTOMATED PRODUCTION READY ML @ SCALE Errol Koolmeister, H&M Keven Wang, H&M #UnifiedDataAnalytics #SparkAISummit
3 .Agenda • AI journey @ H&M • Machine learning blueprint • Automated ML development process • ML orchestration for scale 3
4 .Agenda • AI journey @ H&M • Machine learning blueprint • Automated ML development process • ML orchestration for scale 4
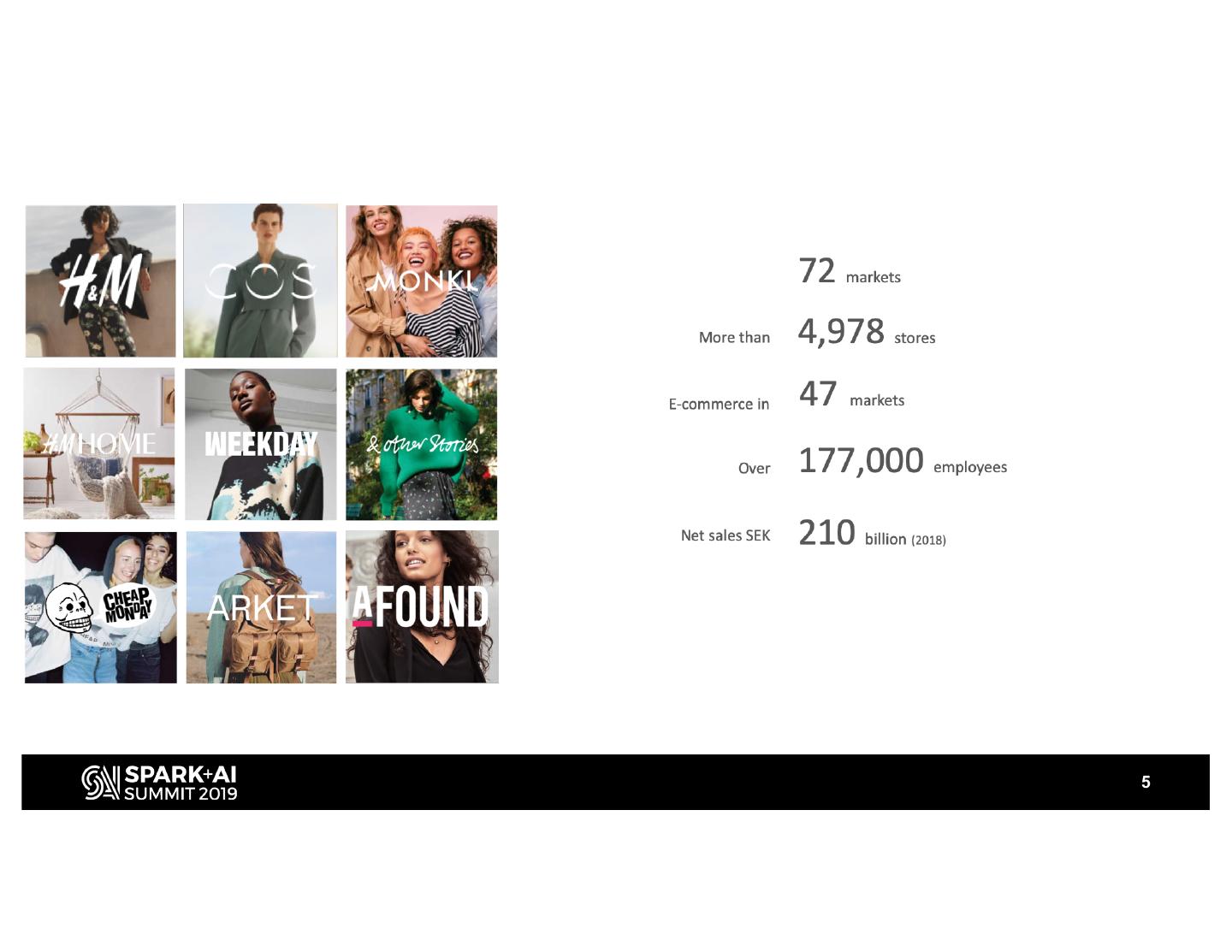
5 .5
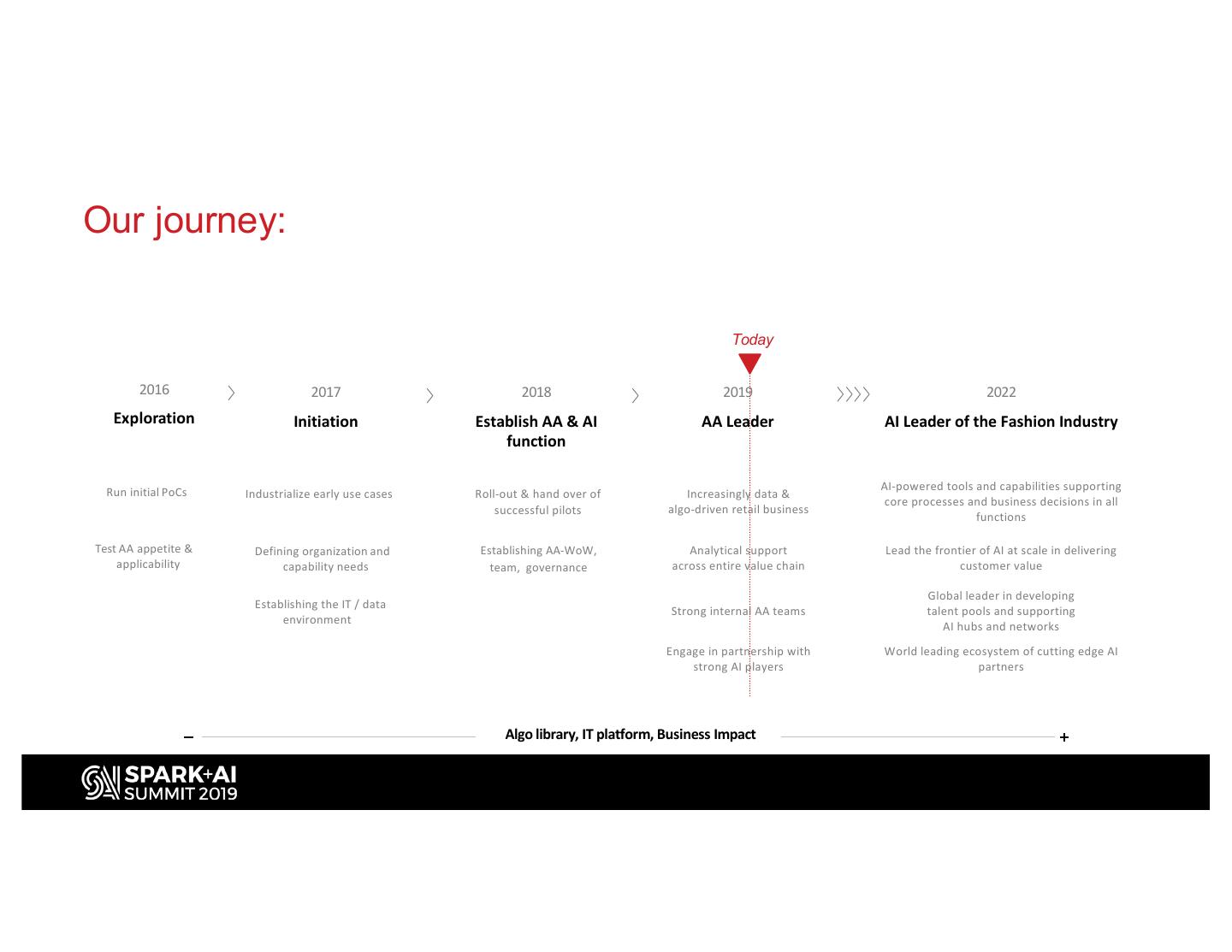
6 .Our journey: Today 2016 2017 2018 2019 2022 Exploration Initiation Establish AA & AI AA Leader AI Leader of the Fashion Industry function Run initial PoCs AI-powered tools and capabilities supporting Industrialize early use cases Roll-out & hand over of Increasingly data & core processes and business decisions in all successful pilots algo-driven retail business functions Test AA appetite & Defining organization and Establishing AA-WoW, Analytical support Lead the frontier of AI at scale in delivering applicability capability needs team, governance across entire value chain customer value Global leader in developing Establishing the IT / data Strong internal AA teams talent pools and supporting environment AI hubs and networks Engage in partnership with World leading ecosystem of cutting edge AI strong AI players partners Algo library, IT platform, Business Impact
7 .AI @ H&M quick facts Growing # of Several Combined New ways of colleagues nationalities teams working Sprints 100+ co-located 30+ different Standups FTEs nationalities Product mgmt. Azure Databricks Consultants Epics Algo HAAL Cloud
8 .H&M use cases Design / Buying Production Logistics Sales Marketing Assortment quantification Allocation Markdown Online Personalized Promotions, Recommendations & Journeys Fashion Forecast Markdown Store Common components eg Algos & Tech H&M Advanced Analytics Landscape
9 .Agenda • AI journey @ H&M • Machine learning blueprint • Automated ML development process • ML orchestration for scale 9
10 .Fragmented solution landscape #UnifiedDataAnalytics #SparkAISummit 10
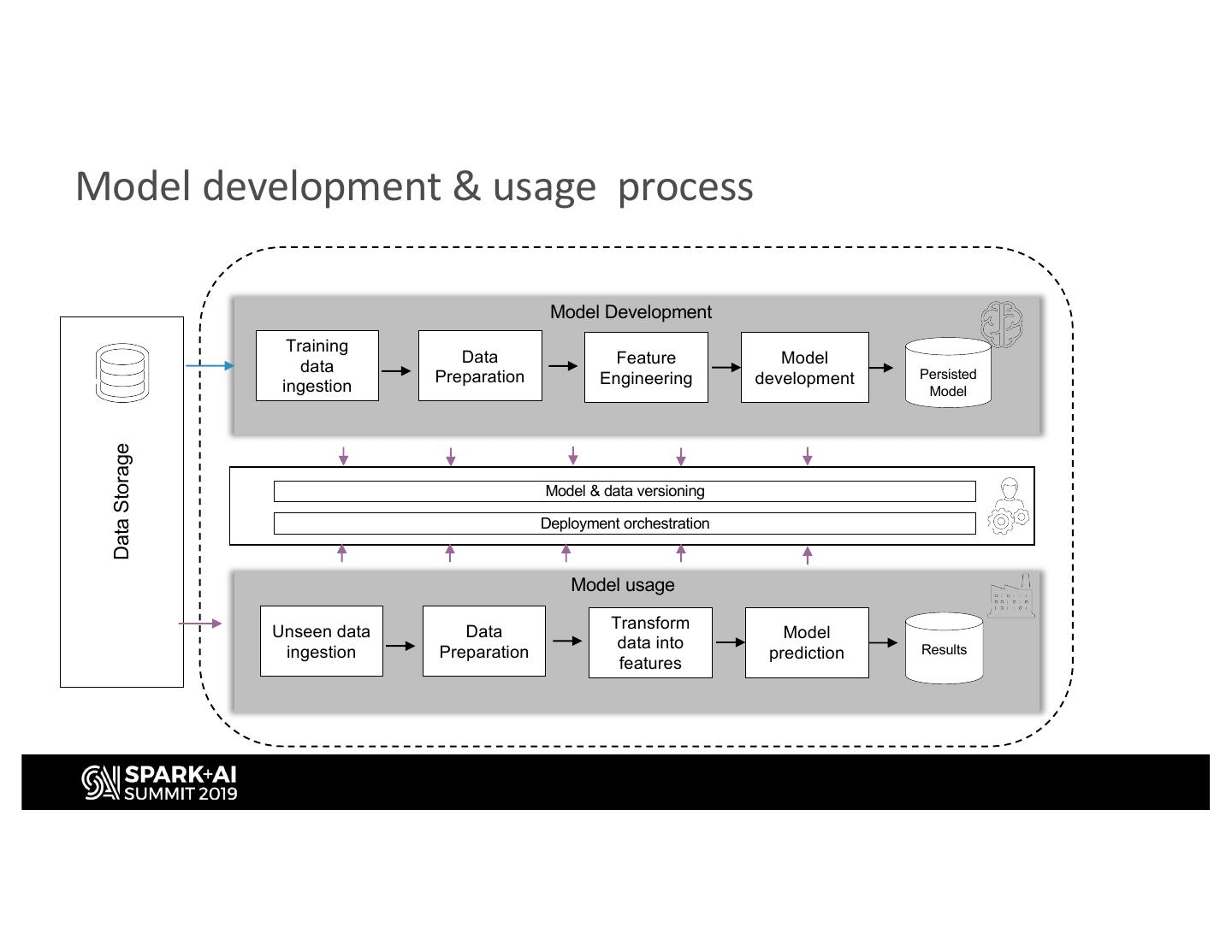
11 .Model development & usage process Model Development Training Data Feature Model data Persisted Preparation Engineering development ingestion Model Data Storage Model & data versioning Deployment orchestration Model usage Transform Unseen data Data Model data into Results ingestion Preparation prediction features
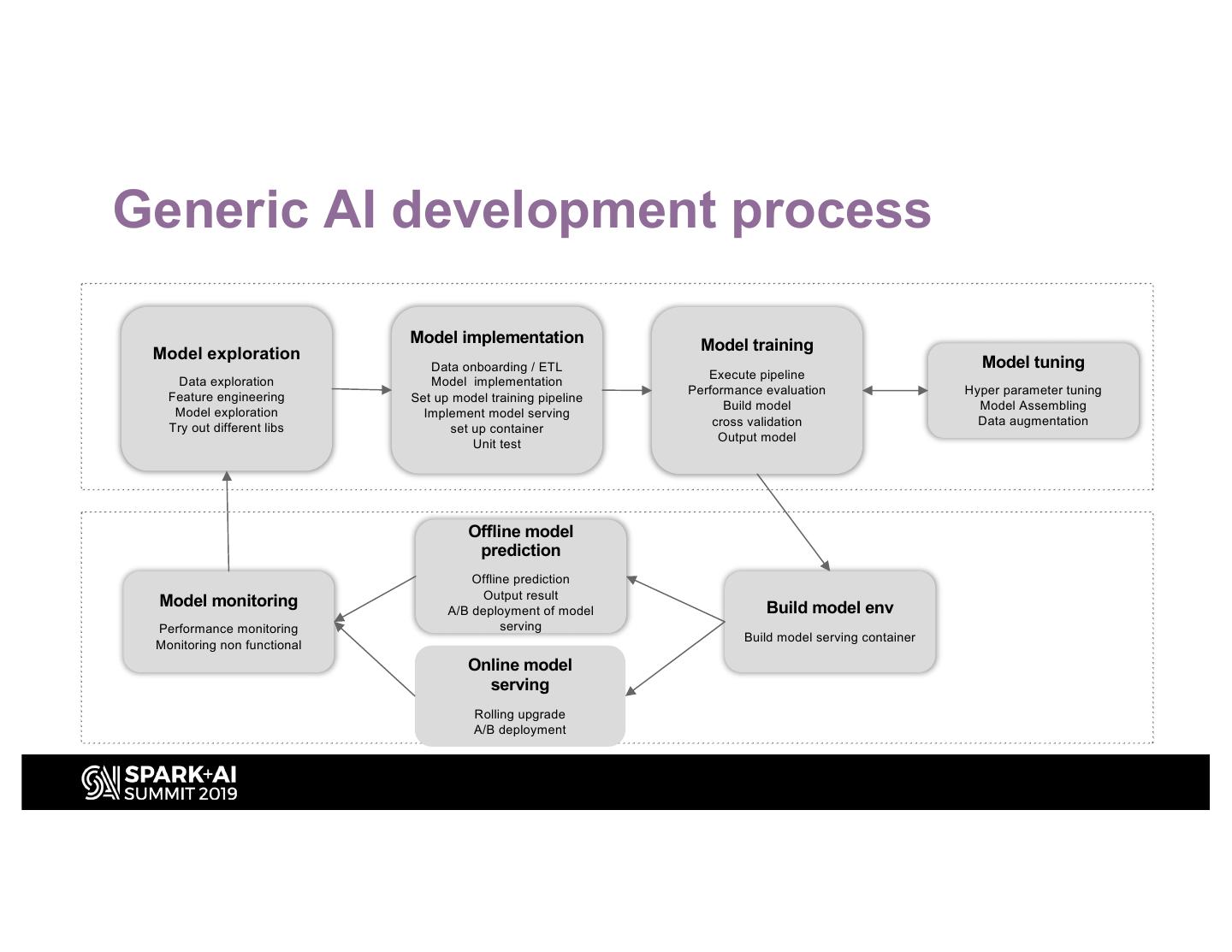
12 .Generic AI development process Model implementation Model training Model exploration Data onboarding / ETL Model tuning Execute pipeline Data exploration Model implementation Performance evaluation Hyper parameter tuning Feature engineering Set up model training pipeline Build model Model Assembling Model exploration Implement model serving cross validation Data augmentation Try out different libs set up container Output model Unit test Offline model prediction Offline prediction Output result Model monitoring A/B deployment of model Build model env Performance monitoring serving Build model serving container Monitoring non functional Online model serving Rolling upgrade A/B deployment
13 .Development process – tool mapping Model Model exploration Model training Model tuning implementation Model development Azure Databricks PyCharm Azure Databricks Data Lake Store PyCharm VS Code Airflow Azure Databricks Data Lake Store Offline model prediction Model monitoring Build model applying env Prediction Online model serving Kubernetes Container Registry
14 .Architecture Principals SEPARATION OF CONCERN STATELESS AUTOMATED CLOUD NATIVE SERVERLESS
15 .Unifying architecture for speed & scale 15
16 .Agenda • AI journey @ H&M • Machine learning blueprint • Automated ML development process • ML orchestration for scale 16
17 .AUTOMATED ML DEVELOPMENT 4.1 job execution 4.2 log model info 4.3 Commit model Model 7 Auto deploy repository new container Azure Databricks Container 3.2 Trigger pipeline Registry Kubernetes 3.1 Push 5.1 Fetch model to DBFS 6 Push container image 5.2 Build container image CI Orchestrator 2 code static check, unit test, Package 1 Code commit Triggering PyCharm 17
18 .Connect the dots Exploration Implementation Build and packaging Training and prediction Monitoring • Shared VS dedicated cluster • Notebook VS python modules • Library management • Training on worker nodes • Logging with Mlflow 18
19 .Agenda • AI journey @ H&M • Machine learning blueprint • Automated ML development process • ML orchestration for scale 19
20 . Source Prepare Feature Training Optimization data Data engineering hyper-param tuning Train Test Val GLPK Large size Large size Medium size Medium size Medium size Parallel process Parallel process Parallel process Iterative/Parallel process Iterative process 20
21 .Distributed computation Single machine computation Internal information Spark Spark Python Python Python task 1 task 2 task 1 task 2 task 3 21
22 . Scenario 1 • Geo location l1 Source Prep Feature data data engine… Train Optimize 30 mins • Product type p 1 • Time t1 Scenario 2 • Geo location l2 Source Prep Feature 60 mins Train Optimize • Product type p 2 data data engine… • Time t2 Databricks Cluster Scenario 3 • Geo location l3 Source Prep Feature • Product type p 3 Train Optimize data data engine… 5 mins • Time t3 … Spark task Spark task Python Python Python … 1 Spark task 2 Spark task task 1 Python task 2 Python task 3 Python Scenario m … • Geo location lm 1 Spark task 2 Spark task task 1 Python task 2 Python task 3 Python ? mins 1 Source 2 Prep Feature task 1 task 2 task 3 • Product type p m data Train Optimize data engine… • Time tm 22
23 . Scenario 1 • Geo location l1 Source Prep Feature Train Optimize • Product type p 1 data data engine… • Time t1 Scenario 2 • Geo location l2 Source Prep Feature Train Optimize • Product type p 2 data data engine… • Time t2 Scenario set Scenario 3 • Geo location l3 Source Prep Feature Train Optimize • Product type p 3 data data engine… • Time t3 Scenario i • Geo location li Source Prep Feature Train Optimize • Product type p i data data engine… • Time ti Databricks Cluster VM VM Databricks Cluster Container Databricks Cluster 23
24 .What we are looking for • A ML orchestrator to train models for different scenarios (scenario set) • Scenario set can be parameterized • Leverage different computation patterns, like Spark, Docker • Parallelize each scenarios as much as possible • Optimize both resource utilization and total lead time 24
25 .ML orchestrator - Airflow How Apache Airflow Distributes Jobs on Celery workers Feature Challenge • Implement Pipeline/DAG by Python • Multi source of failure • Workflow Scheduler by Airbnb • Lack of elasticity, scaling up/down • Integration with different source & sink • Coupling app dependency with infrastructure 25
26 . Databricks Databricks Databricks Cluster Cluster Cluster Scenario Source Prep Feature Train Optimize DAG task 1 Scenario task 1 data Source data Source data Prep data Prep engine… Feature engine… Feature Train Optimize Scenario 1 Train Optimize Scenario data Source Prep data engine… Feature Train Optimize task 1 Scenario data Source data Prep engine… Feature Train Optimize Airflow task 1 data data engine… Source Prep Feature Webserver Scenario Scenario 2 Train Optimize data data engine… set Scenario Scenario Source Prep Feature Train Optimize set task 1 Scenario data Source data Prep engine… Feature Scenario Train Optimize task 1 data data engine… set Source Prep Feature Scenario 3 Train Optimize data data engine… Airflow Scenario Source Prep Feature Train Optimize Scheduler task 1 Scenario data Source data Prep engine… Feature Train Optimize Airflow MetaDB task 1 data Source data Prep engine… Feature Scenario i Train Optimize data data engine… AKS Azure File share Persistent Container Kubernetes Airflow Airflow Pod Logs dags Volume Registry
27 .DAG at a glance
28 .DON’T FORGET TO RATE AND REVIEW THE SESSIONS SEARCH SPARK + AI SUMMIT
3秒后跳转登录页面
去登陆

