




























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板

Asynchronous Hyperparameter Optimization with Apache Spark
Asynchronous Hyperparameter Optimization with Apache Spark
Asynchronous Hyperparameter Optimization with Apache Spark
For the past two years, the open-source Hopsworks platform has used Spark to distribute hyperparameter optimization tasks for Machine Learning. Hopsworks provides some basic optimizers (gridsearch, randomsearch, differential evolution) to propose combinations of hyperparameters (trials) that are run synchronously in parallel on executors as map functions. However, many such trials perform poorly, and we waste a lot of CPU and harware accelerator cycles on trials that could be stopped early, freeing up the resources for other trials.
In this talk, we present our work on Maggy, an open-source asynchronous hyperparameter optimization framework built on Spark that transparently schedules and manages hyperparameter trials, increasing resource utilization, and massively increasing the number of trials that can be performed in a given period of time on a fixed amount of resources. Maggy is also used to support parallel ablation studies using Spark. We have commercial users evaluating Maggy and we will report on the gains they have seen in reduced time to find good hyperparameters and improved utilization of GPU hardware. Finally, we will perform a live demo on a Jupyter notebook, showing how to integrate maggy in existing PySpark applications.
展开查看详情
1 .Asynchronous Hyperparameter Optimization with Apache Spark Jim Dowling, Logical Clocks AB and KTH @jim_dowling Moritz Meister, Logical Clocks AB @morimeister #UnifiedDataAnalytics #SparkAISummit
2 . The Bitter Lesson (of AI)* “Methods that scale with computation are the future of AI”** Rich Sutton (Father of Reinforcement Learning) “The two (general purpose) methods that seem to scale ... are search and learning.”* * http://www.incompleteideas.net/IncIdeas/BitterLesson.html ** https://www.youtube.com/watch?v=EeMCEQa85tw 2
3 . This talk is about why bulk- Spark scales with synchronous parallel compute available compute (Spark) does not scale efficiently for search and how => we made Spark efficient for Spark is the answer! directed search (task-based asynchronous parallel compute). 3
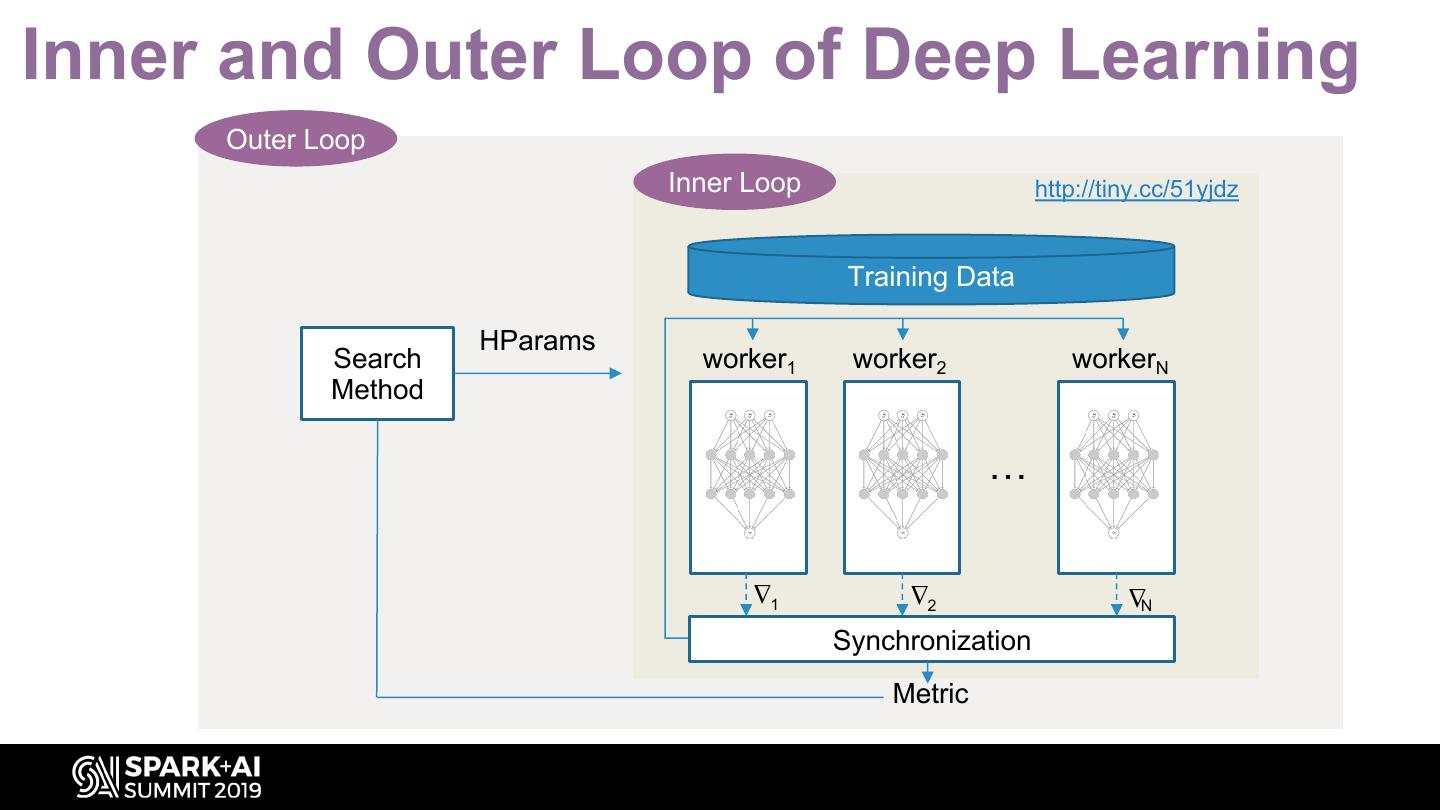
4 .Inner and Outer Loop of Deep Learning Outer Loop Inner Loop http://tiny.cc/51yjdz Training Data HParams Search worker1 worker2 workerN Method … ∆ ∆ ∆ 1 2 N Synchronization Metric
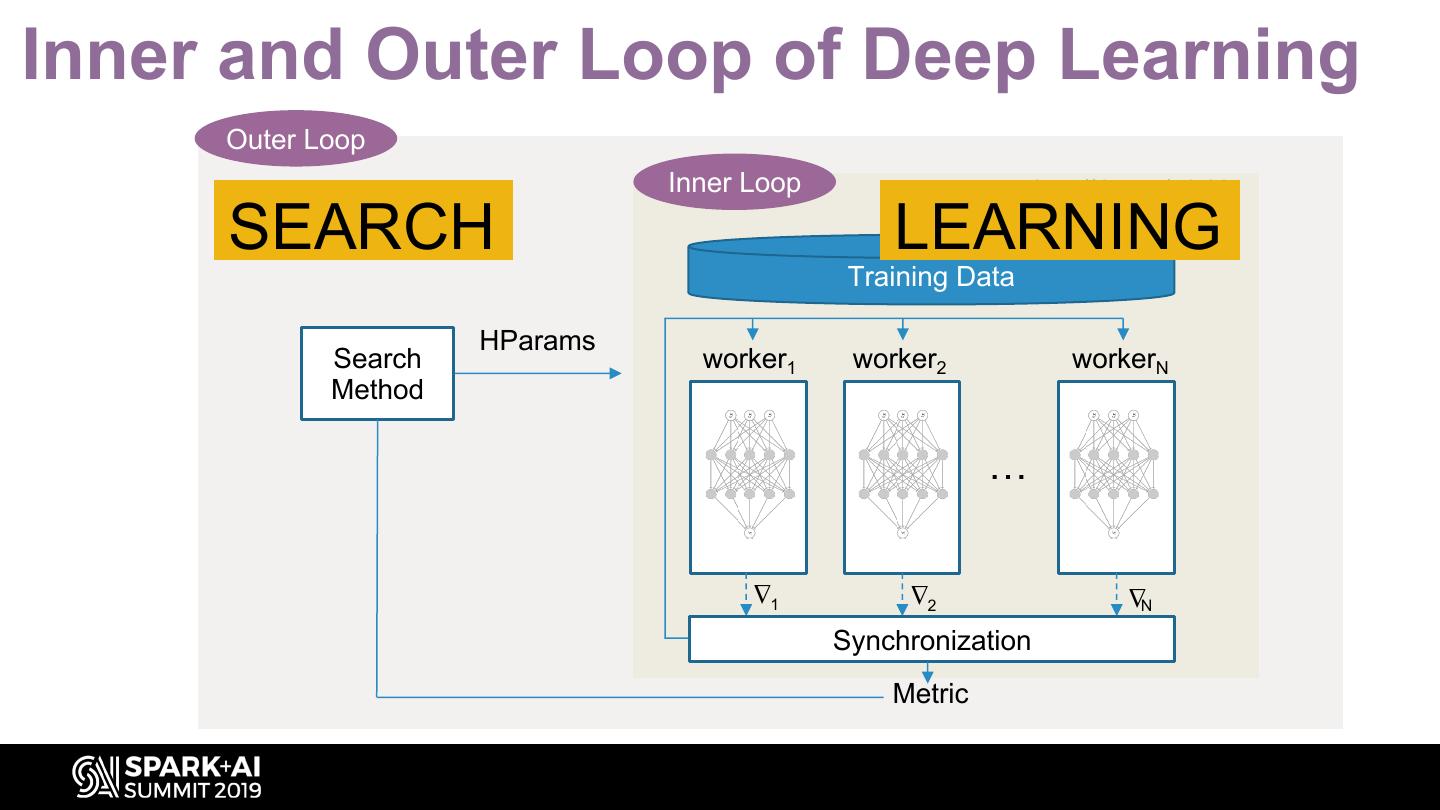
5 .Inner and Outer Loop of Deep Learning Outer Loop Inner Loop http://tiny.cc/51yjdz SEARCH LEARNING Training Data HParams Search worker1 worker2 workerN Method … ∆ ∆ ∆ 1 2 N Synchronization Metric
6 .Hopsworks – a platform for Data-Intensive AI 6
7 . Hopsworks Technical Milestones World’s fastest First non-Google ML World’s first World’s First Platform with HDFS Published at Hadoop platform to Open Source TensorFlow Extended USENIX FAST with support Feature Store for (TFX) support through Oracle and Spotify GPUs-as-a-Resource Machine Learning Beam/Flink 2017 2018 2019 Winner of IEEE World’s most scalable World’s first Scale Challenge World’s First POSIX-like Hierarchical Unified Distributed Filesystem to 2017 Filesystem with Hyperparam and store small files in metadata with HopsFS - 1.2m Multi Data Center Availability Ablation Study on NVMe disks ops/sec with 1.6m ops/sec on GCP Framework 7
8 . The Complexity of Deep Learning A/B Distributed Testing Training Data validation Data Model Prediction Data Model Collection φ(x) Serving HyperParameter Tuning Monitoring Hardware Management Feature Engineering Pipeline Management [Adapted from Schulley et al “Technical Debt of ML” ] 8
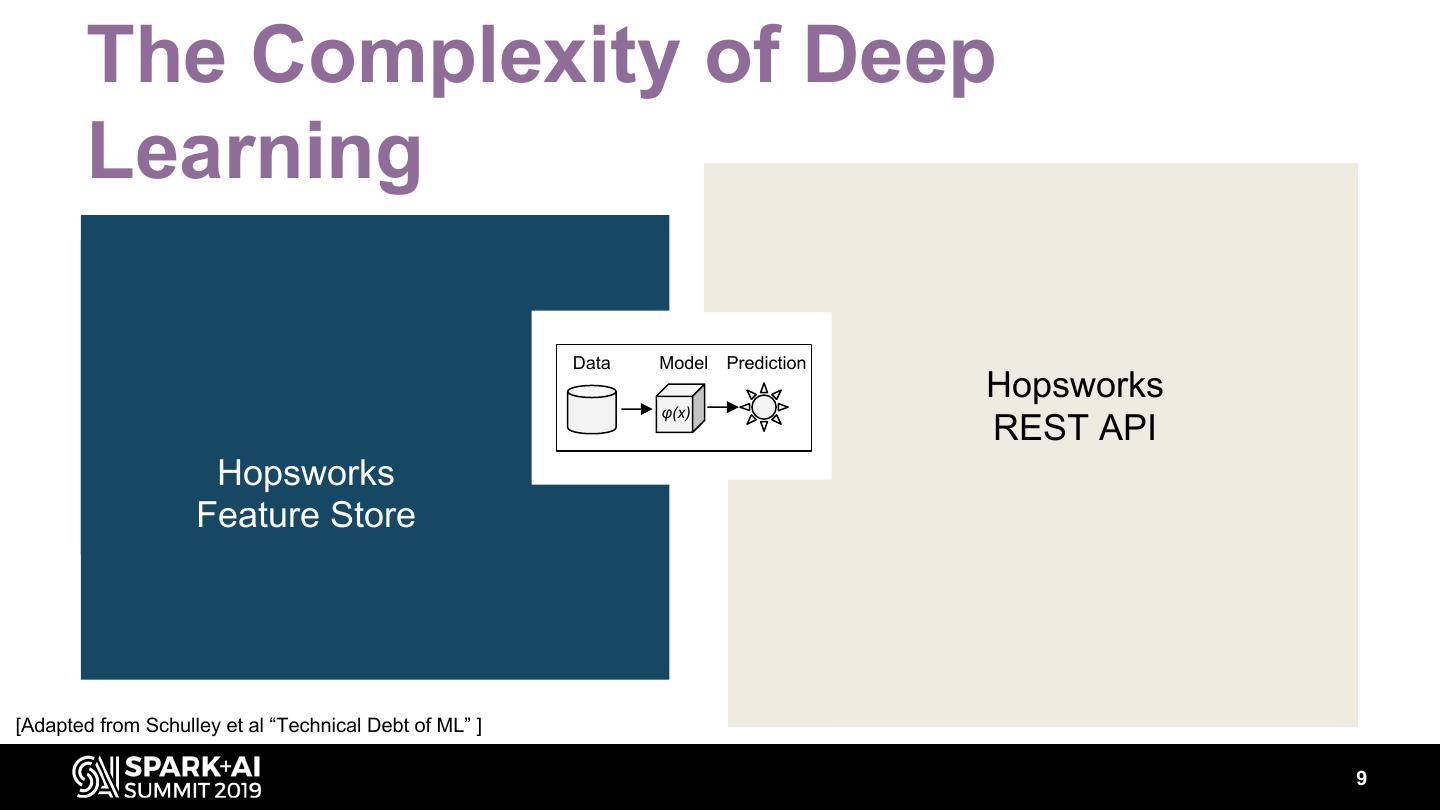
9 . The Complexity of Deep Learning A/B Distributed Testing Training Data validation Data Model Prediction Data Hopsworks Model φ(x) Serving Collection REST API HyperParameter Hopsworks Tuning Monitoring Hardware Feature Management Store Feature Engineering Pipeline Management [Adapted from Schulley et al “Technical Debt of ML” ] 9
10 .10
11 .11
12 . Hops works Orches tration in Airflow Batch Dis tributed Model ML & DL Serving Apache Beam Apache Spark Pip Kubernetes Conda Tensorflow s cikit-learn Hops works Applications Datas ources Keras Feature Store API Strea ming J upyter Model Das hboards Notebooks Monitoring Apache Bea m Kafka + Apache Spark Tensorboard Spark Apache Flink Streaming Files ys tem and Metada ta s tora ge Hops FS Data Preparation Experimentation Deploy & Inges tion & Model Training & Productionalize 12
13 .“AI is the new Electricity” – Andrew Ng What engine should we use? 14
14 .Engines Matter! [Image from https://twitter.com/_youhadonejob1/status/1143968337359187968?s=20] 15
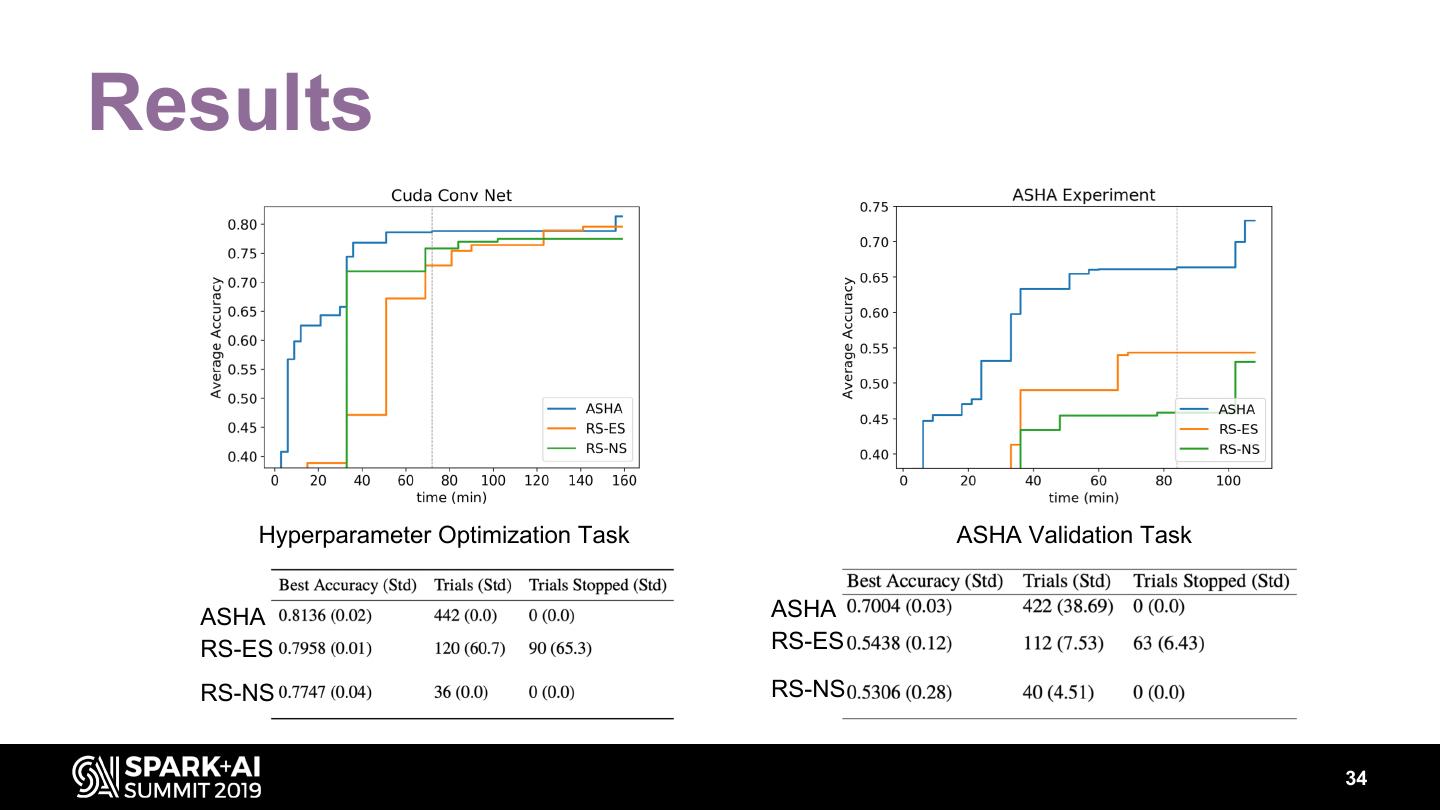
15 .Engines Really Matter! Photo by Zbynek Burival on Unsplash 16
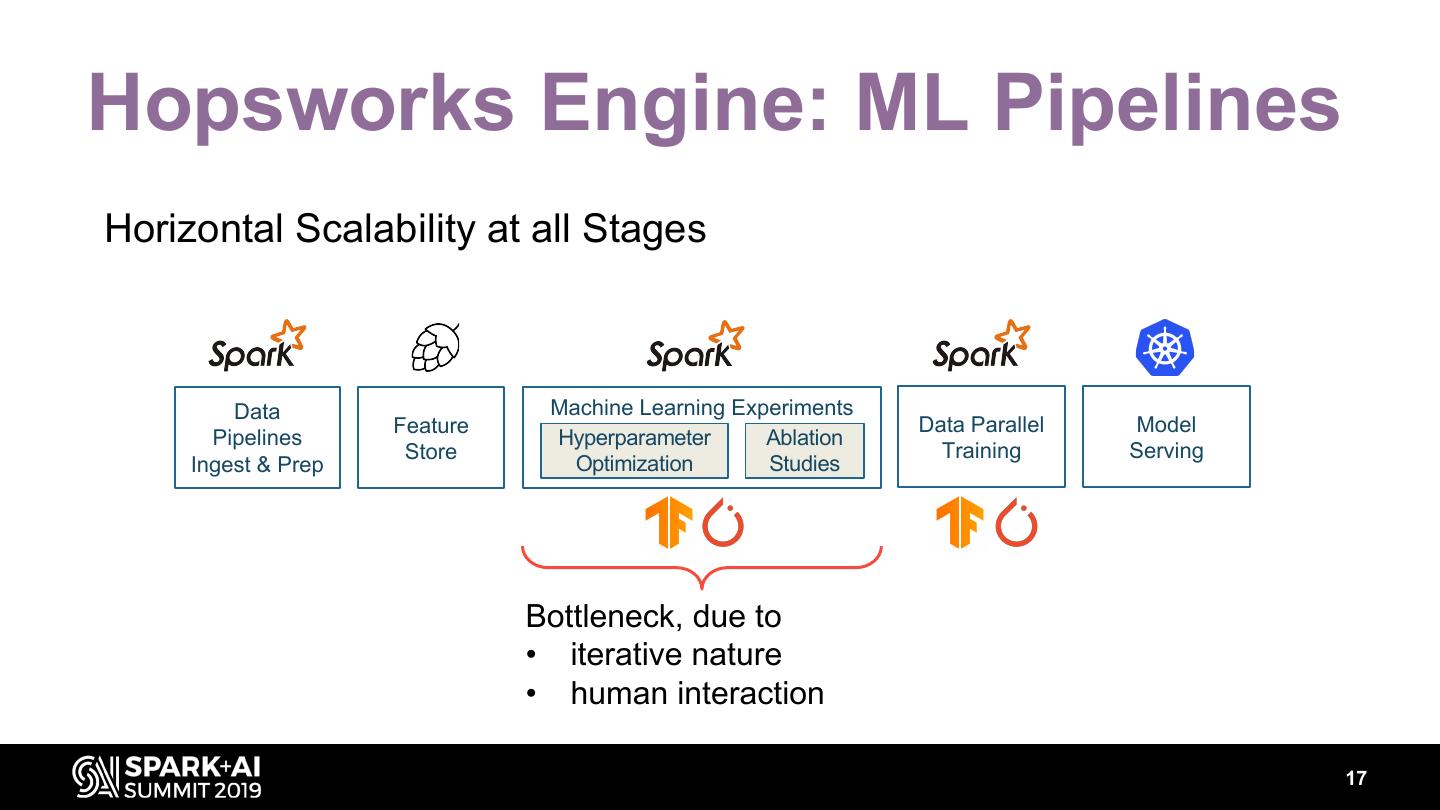
16 .Hopsworks Engine: ML Pipelines Horizontal Scalability at all Stages Data Machine Learning Experiments Feature Data Parallel Model Pipelines Hyperparameter Ablation Store Training Serving Ingest & Prep Optimization Studies Bottleneck, due to • iterative nature • human interaction 17
17 .Iterative Model Development Set Hyper- parameters • Trial and Error is slow • Iterative approach is greedy • Search spaces are usually large Evaluate • Sensitivity and interaction of Train Model Performance hyperparameters 18
18 .Black Box Optimization Search space Meta-level Learning learning & Black Box optimization Metric 19
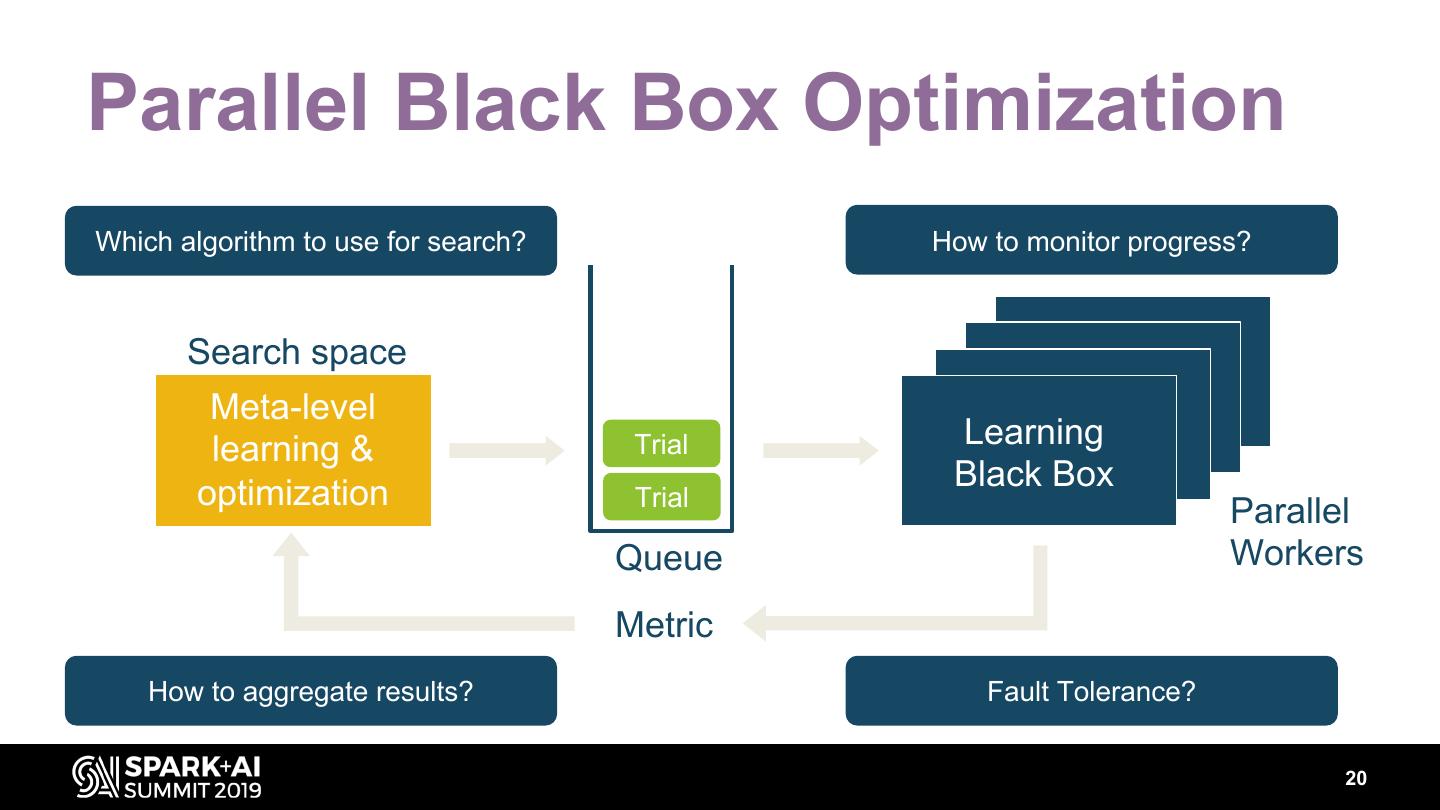
19 .Parallel Black Box Optimization Which algorithm to use for search? How to monitor progress? Search space Meta-level learning & Trial Learning Black Box optimization Trial Parallel Queue Workers Metric How to aggregate results? Fault Tolerance? 20
20 .Parallel Black Box Optimization Which algorithm to use for search? How to monitor progress? Search space Meta-level This should learning & be managed Trial with platform support! Learning Black Box optimization Trial Parallel Queue Workers Metric How to aggregate results? Fault Tolerance? 21
21 .Maggy A flexible framework for running different black-box optimization algorithms on Hopsworks: ASHA, Bayesian Optimization, Random Search, Grid Search and more to come… 22
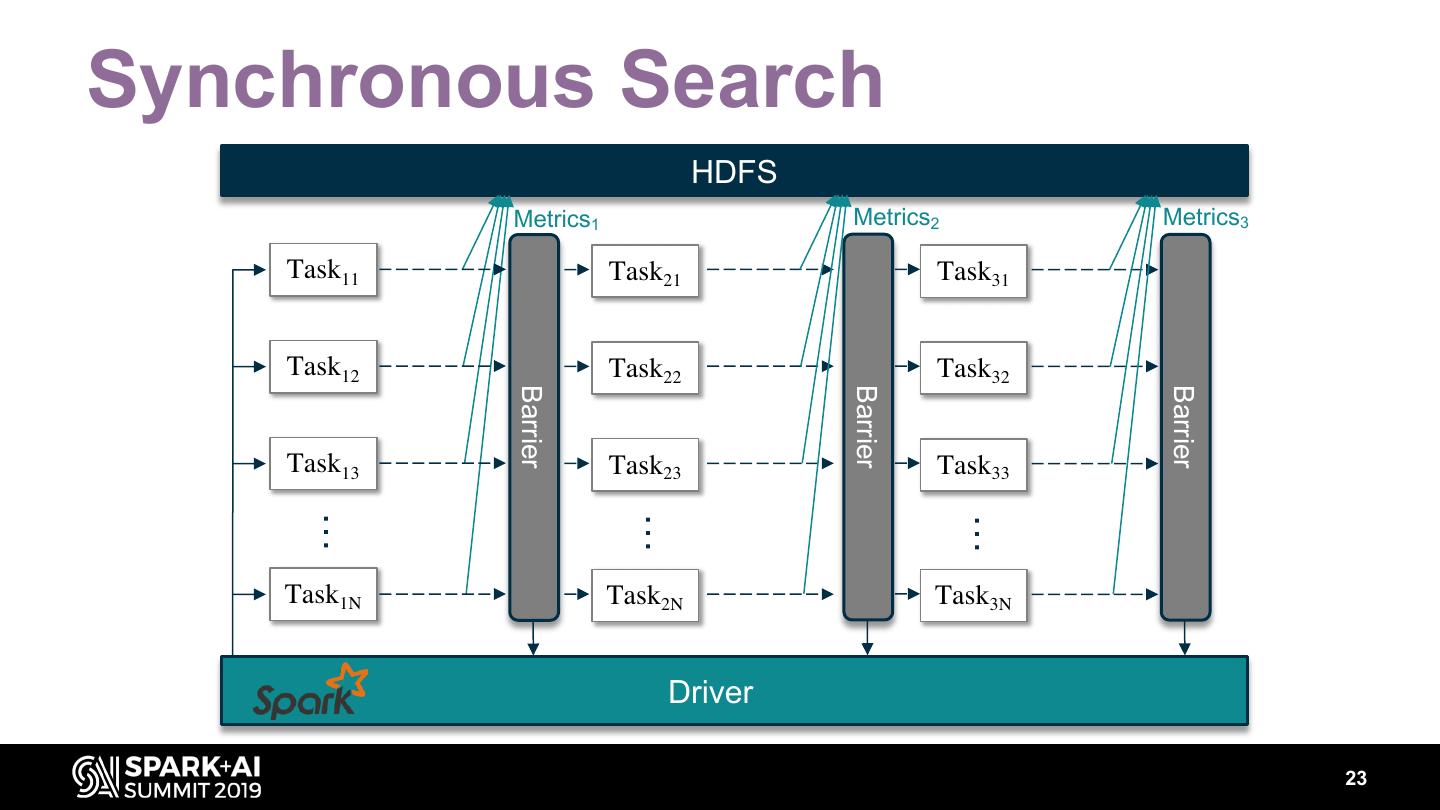
22 .Synchronous Search HDFS Metrics1 Metrics2 Metrics3 Task11 Task21 Task31 Task12 Task22 Task32 Barrier Barrier Barrier Task13 Task23 Task33 … … … Task1N Task2N Task3N Driver 23
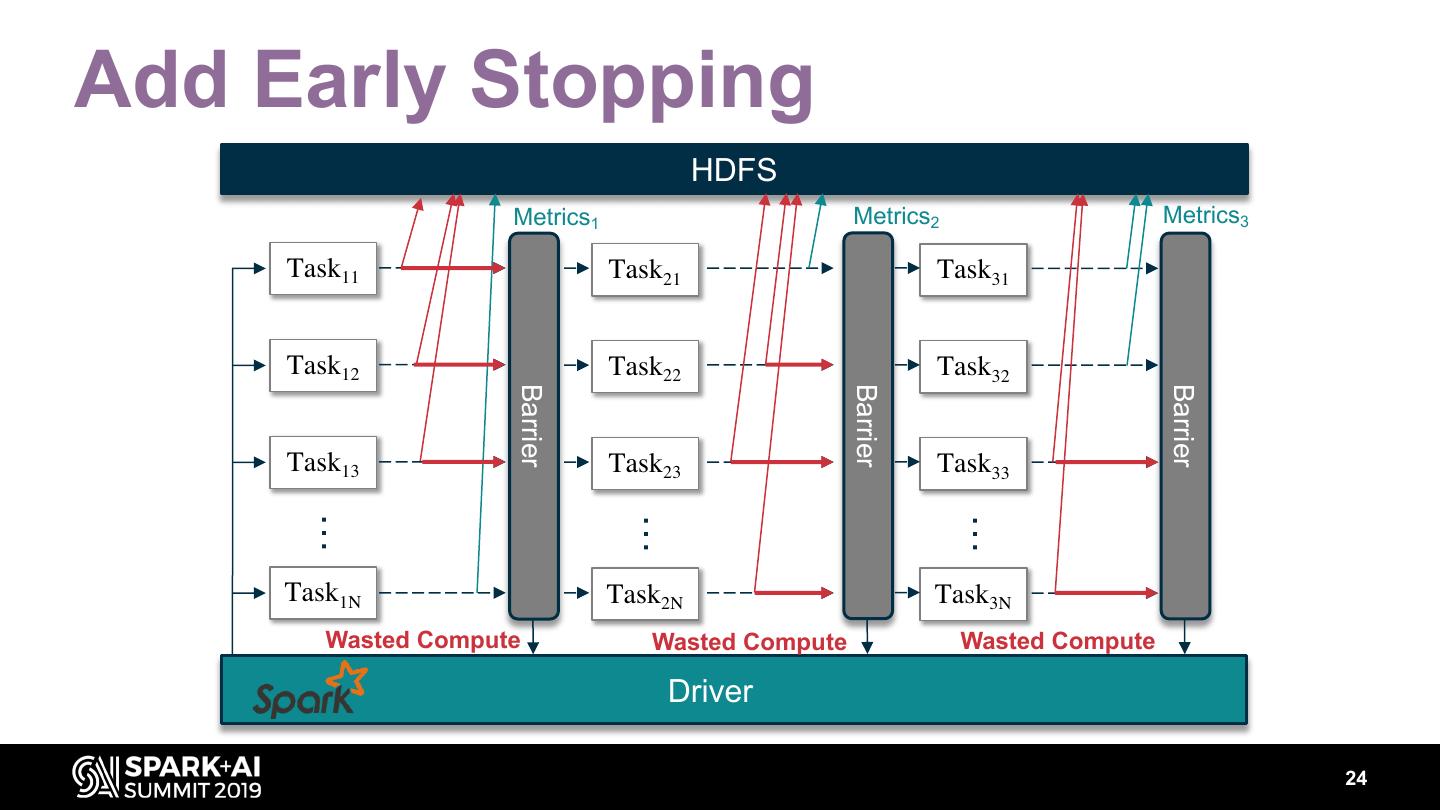
23 .Add Early Stopping HDFS Metrics1 Metrics2 Metrics3 Task11 Task21 Task31 Task12 Task22 Task32 Barrier Barrier Barrier Task13 Task23 Task33 … … … Task1N Task2N Task3N Wasted Compute Wasted Compute Wasted Compute Driver 24
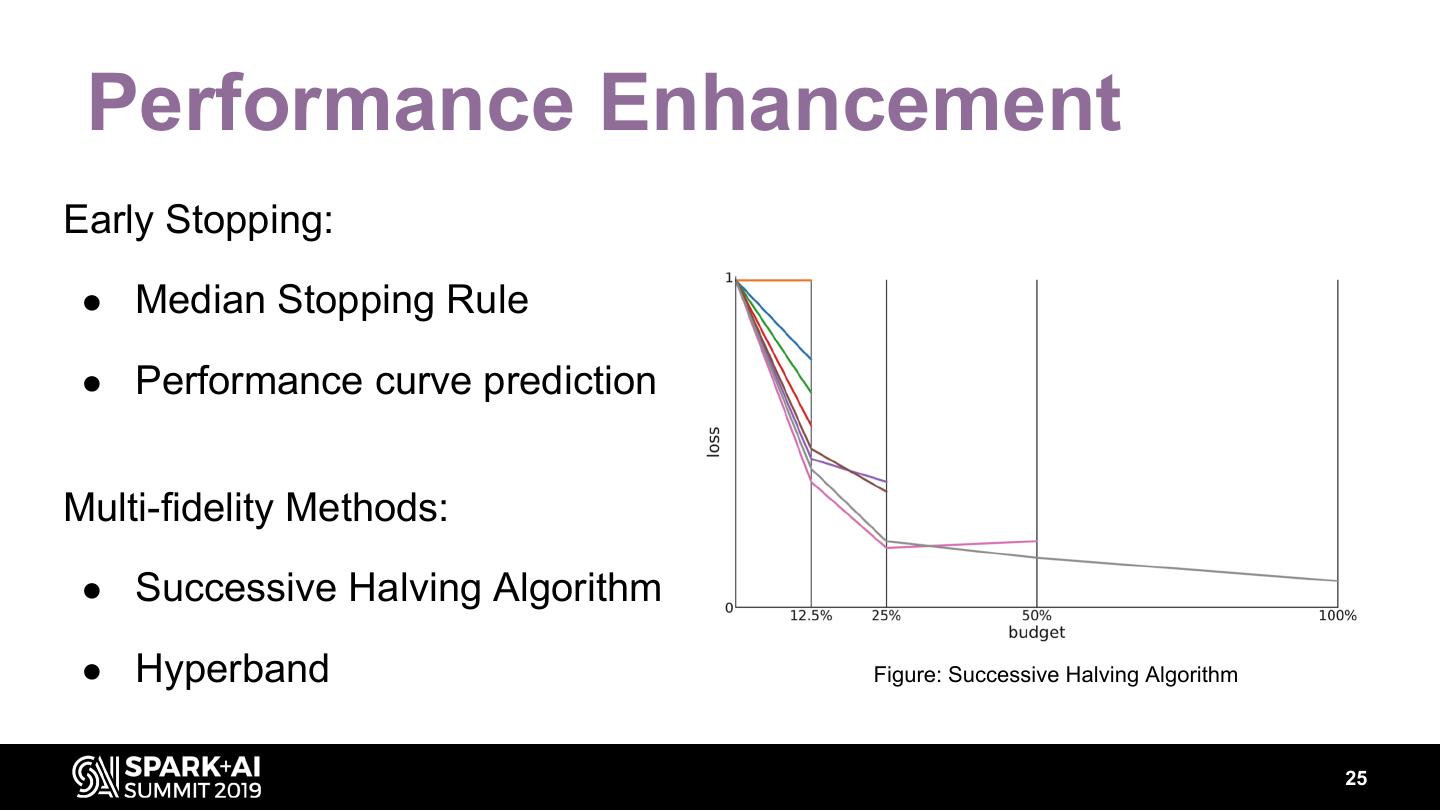
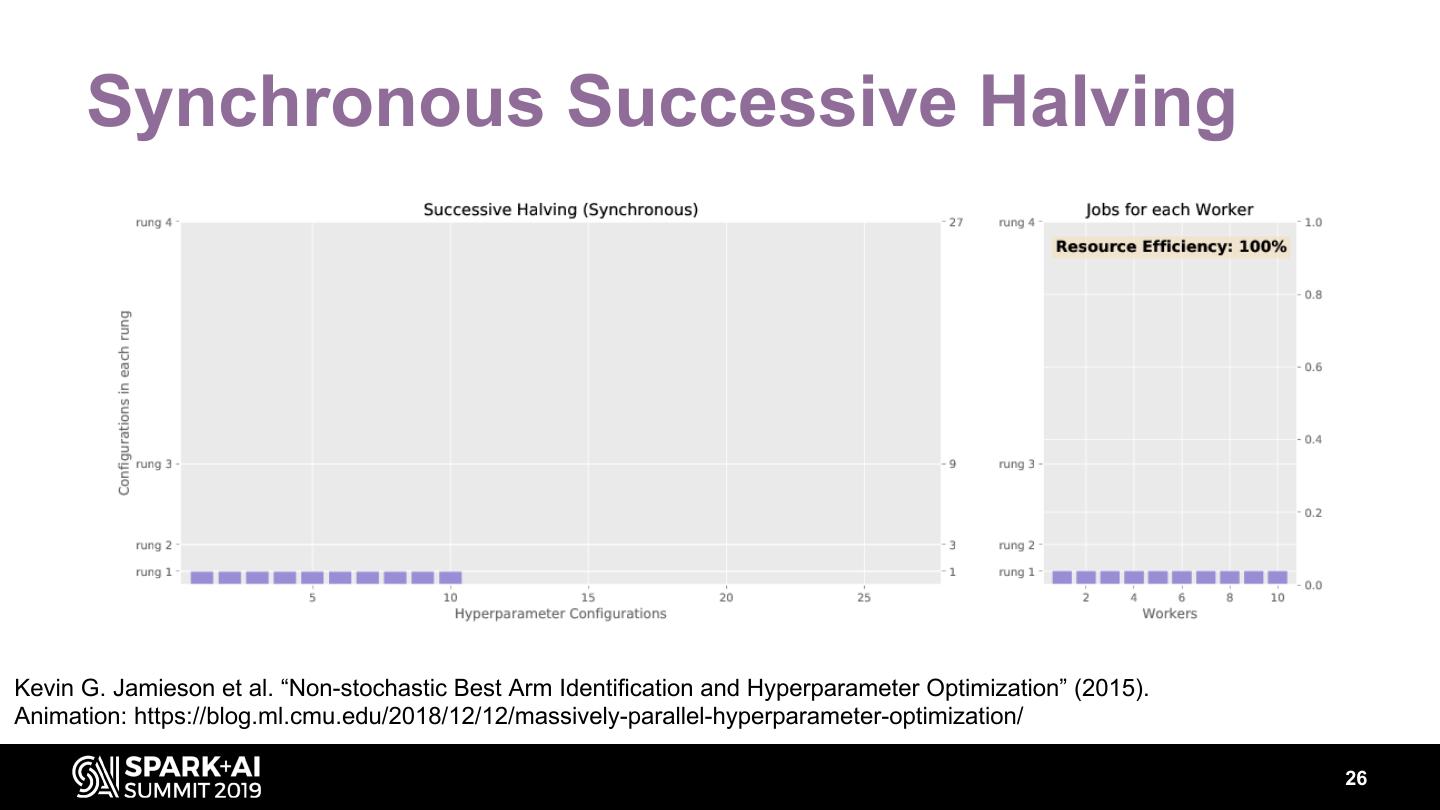
24 . Performance Enhancement Early Stopping: ● Median Stopping Rule ● Performance curve prediction Multi-fidelity Methods: ● Successive Halving Algorithm ● Hyperband Figure: Successive Halving Algorithm 25
25 . Synchronous Successive Halving Kevin G. Jamieson et al. “Non-stochastic Best Arm Identification and Hyperparameter Optimization” (2015). Animation: https://blog.ml.cmu.edu/2018/12/12/massively-parallel-hyperparameter-optimization/ 26
26 . Asynchronous Successive Halving Liam Li et al. “Massively Parallel Hyperparameter Tuning” (2018). Animation: https://blog.ml.cmu.edu/2018/12/12/massively-parallel-hyperparameter-optimization/ 27
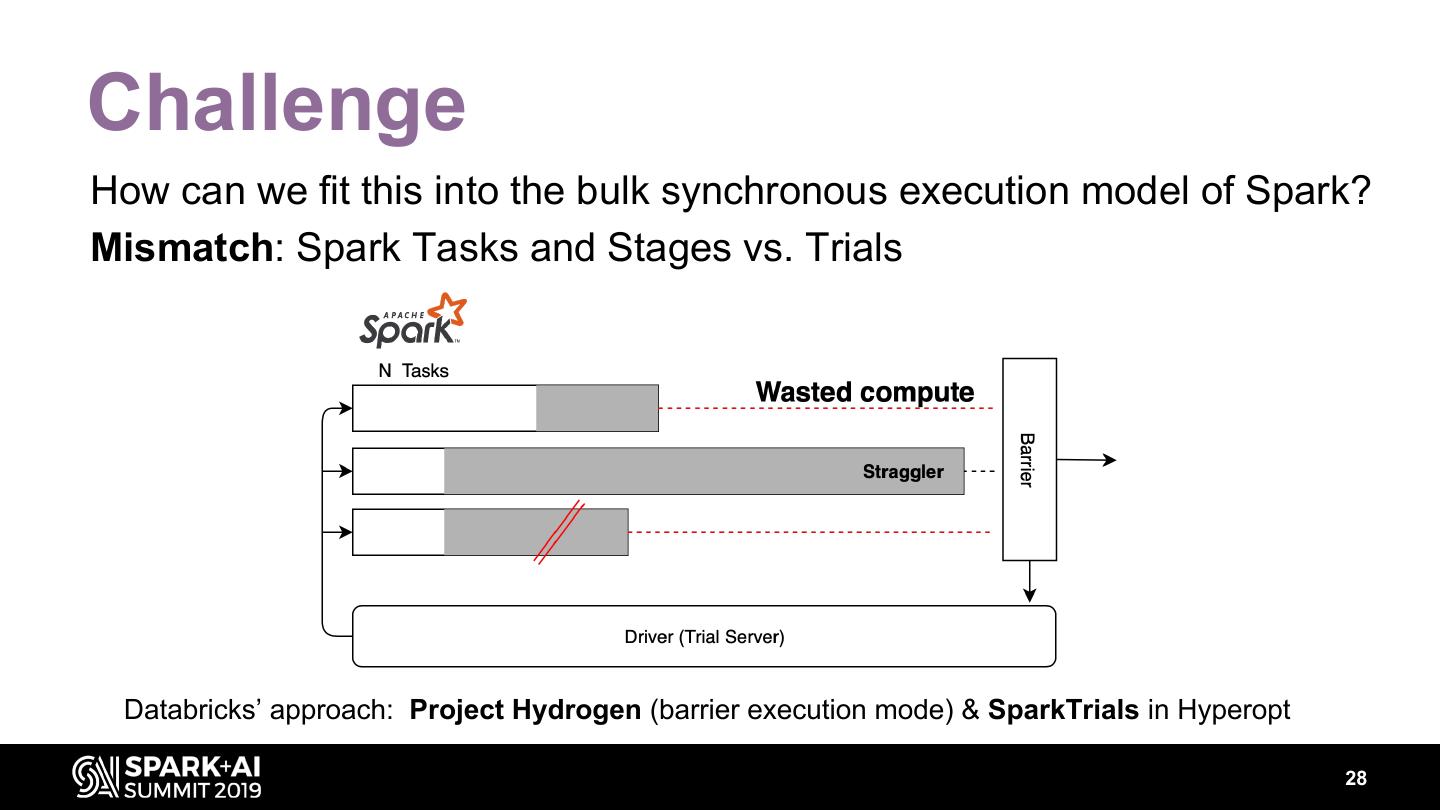
27 .Challenge How can we fit this into the bulk synchronous execution model of Spark? Mismatch: Spark Tasks and Stages vs. Trials Databricks’ approach: Project Hydrogen (barrier execution mode) & SparkTrials in Hyperopt 28
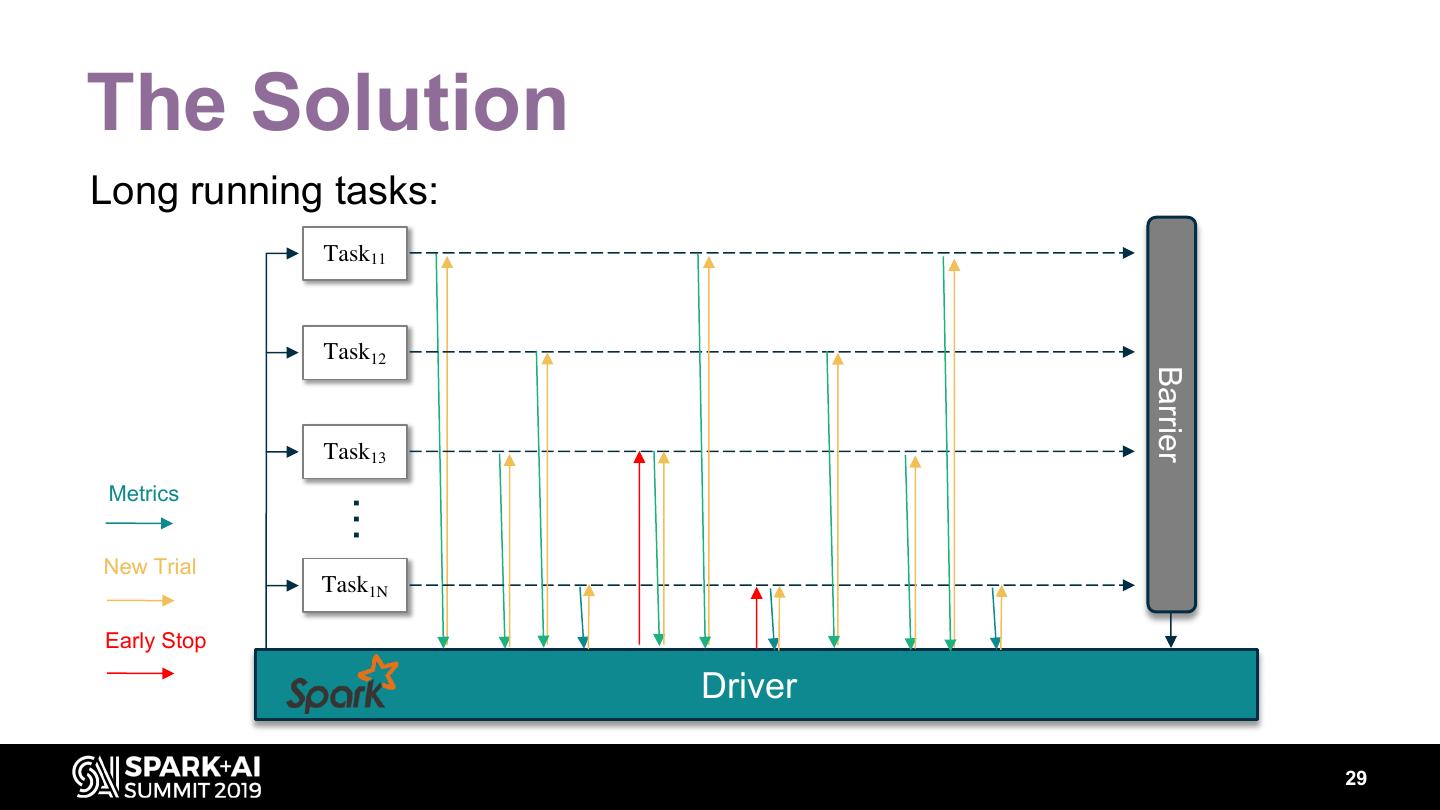
28 .The Solution Long running tasks: Task11 Task12 Barrier Task13 Metrics … New Trial Task1N Early Stop Driver 29
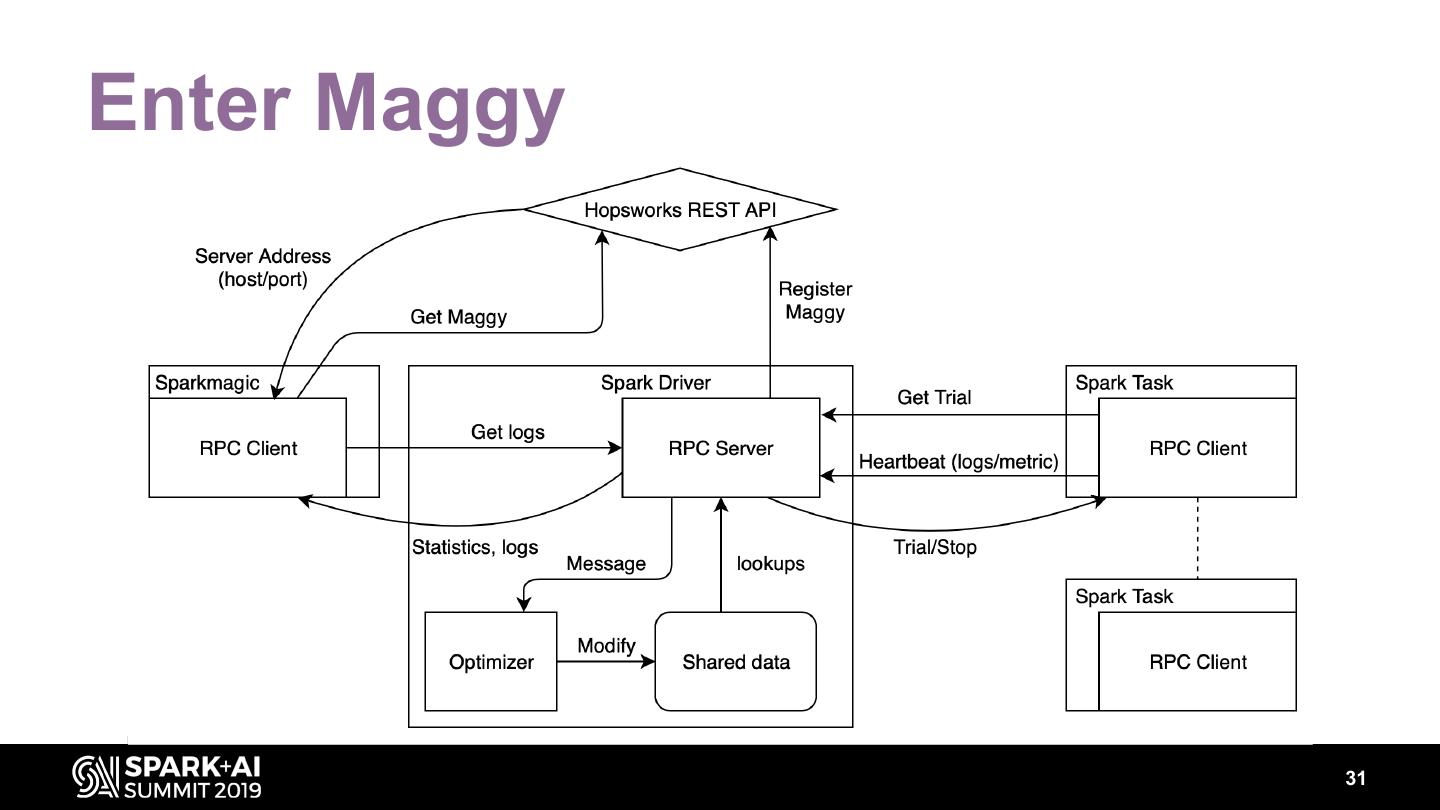
29 .Enter Maggy 31
3秒后跳转登录页面
去登陆

