展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .AXS - Astronomical Data
Processing on the LSST
Scale with Apache Spark
Petar Zečević, SV Group, University of Zagreb
Mario Jurić, DIRAC Institute, University of Washington
#UnifiedDataAnalytics #SparkAISummit
�
3 .About us
Mario Jurić
• Prof. of Astronomy at the University of Washington
• Founding faculty of DIRAC & eScience Institute Fellow
• Fmr. lead of LSST Data Management
Petar Zečević
• CTO at SV Group, Croatia
• CS PhD student at University of Zagreb
• Visiting Fellow at DiRAC institute @ UW
• Author of “Spark in Action”
#UnifiedDataAnalytics #SparkAISummit 3
�
4 .About us
#UnifiedDataAnalytics #SparkAISummit 4
�
5 .Context: The Large Survey
Revolution in Astronomy
�
7 .Hipparchus of Rhodes (180-125 BC)
In 129 BC, constructed one of the first star
catalogs, containing about 850 stars.
�
8 .Galileo Galilei (1564-1642)
Researched a variety of topics in physics,
but called out here for the introduction of
the Galilean telescope.
Galileo’s telescope allowed us for the first
time to zoom in on the cosmos, and study
the individual objects in great detail.
�
9 .The Astrophysics Two-Step
• Surveys
– Construct catalogs and maps of objects in the sky. Focus on coarse
classification and discovering targets for further follow-up.
• Large telescopes
– Acquire detailed observations of a few representative objects.
Understand the details of astrophysical processes that govern them,
and extrapolate that understanding to the entire class.
�
10 . The Story of Astronomy:
2000 Years of being Data Poor
10
�
11 . Sloan Digital Sky Survey
2.5m telescope >14,500 deg2 0.1” astrometry r<22.5 flux limit
5 band, 1%, photometry for over 900M stars
Over 3M R=2000 spectra
10 years of ops: ~10 TB of imaging
�
12 . Facilitated the development
of large databases, data-
driven discovery, motion
towards what we recognize
as Data Science today.
1,231,051,050 rows (SDSS DR10, PhotoObjAll table)
~500 columns
�
13 .Panoramic Survey Telescope and Rapid Response System
1.8m telescope 30,000 deg2 50mas astrometry r<23 flux limit
5 band, better than 1% photometry (goal)
~700 GB/night
�
14 .Gaia DR2: 1.7 billion stars
https://sci.esa.int/s/wV6oG5w
14
�
15 .The Large Synoptic Survey Telescope
A Public, Deep, Wide and Fast, Optical Sky Survey
First Light: 2020 Operations: 2022
Deep (24th mag), Wide (60% of the sky), Fast (every 15 seconds)
Largest astronomical camera in the world
Will repeatedly observe the night sky over 10 years
10 million alerts each night (60 seconds)
37 billion astronomical sources, with time series
30 trillion measurements
�
16 .LSST’s mission is to build a well-understood system that
Overview
provides a vast astronomical dataset for unprecedented
discovery of the deep and dynamic universe.
�
17 .The Scale of Things to Come
Metric Amount
Number of detections 7 trillion rows
Number of objects 37 billion rows
Nightly alert rate 10 million
Nightly data rate >15 TB
Alert latency 60 seconds
Total images after 10 yrs 50 PB
Total data after 10 yrs 83 PB
Objects detected, measured, and stored in queryable catalogs (tables)
17
�
18 .Catalog-driven Science
• Once a catalog is available, astronomers “ask” all kinds of questions
• The traditional paradigm:
– Subset (filter data using a catalog SQL interface online)
– Download data locally
– Analyze (usually Python)
#UnifiedDataAnalytics #SparkAISummit 18
�
19 .Challenges (part 0)
Dataset Size
(keeping ~PBs of data in RBDMSes is not easy, or cheap)
What do you do when the dataset subset is a few ~TBs?
�
20 .Challenges (part 1)
Dataset Size
(keeping ~TBs of data in RBDMs-es is not easy)
Better Together I Want it All
(joining datasets is powerful) (interesting science w. whole dataset operations)
�
21 .Challenges (part 2)
Scalability Resources
(how do I write an analysis code that will (where are the resources to run this code?)
scale to petabytes of data?)
How do you scale exploratory data analysis to ~PB-sized datasets
and thousands of simultaneous users?
�
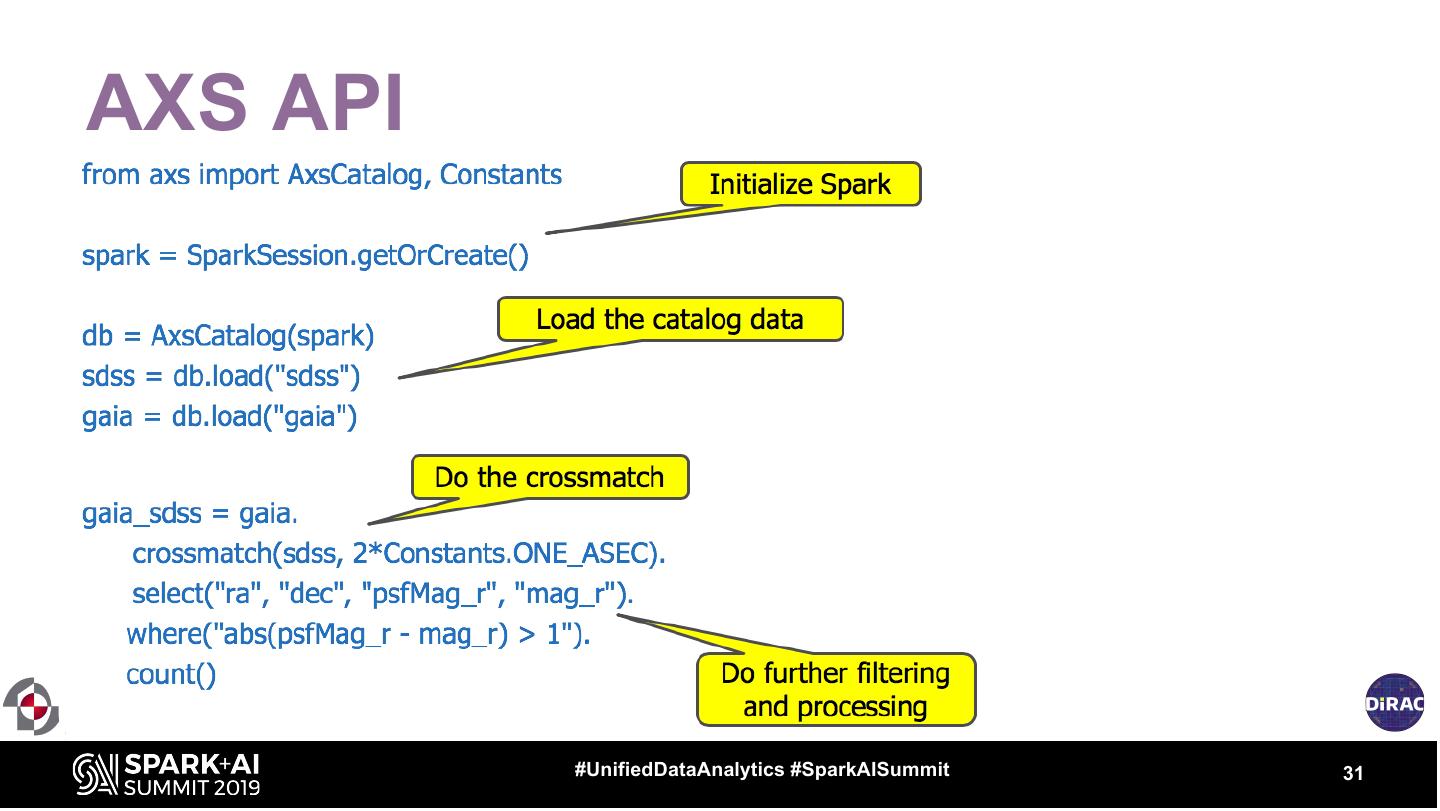
22 .Enter Spark, AXS
• AXS: Astronomy eXtensions for Spark
• The main idea:
– Spark is a proven, scalable, cloud-ready and widely-supported analytics
framework with full SQL support (legacy support).
– Extend it to exploratory data analysis.
– Add a scalable positional cross-match operator
– Add a domain-specific Python API layer to PySpark
– Couple to S3 API for storage, Kubernetes for orchestration…
• … A scalable platform supporting an arbitrarily sized dataset and a
large number of users, deployable on either public or private cloud.
22
�
23 .Key Issue: Scalable Cross-matching
A match
Search perimeter
(can also use similarity)
DEC and RA coordinates
#UnifiedDataAnalytics #SparkAISummit 23
�
24 .AXS data partitioning
• Data partitioning is at the root of AXS' efficient cross-
matching
• Based on (late) Jim Gray's “zones algorithm” (MS Rsch)
• Sky divided into horizontal “zones” of a certain height
• Adapted for distributed architectures
• Data stored in Parquet files
– bucketed by zone
– sorted by zone and ra columns
– data from zone borders duplicated to the zone below
24
�
25 .AXS data partitioning
25
�
26 .AXS - optimal joins
26
�
27 .AXS - optimal joins
27
�
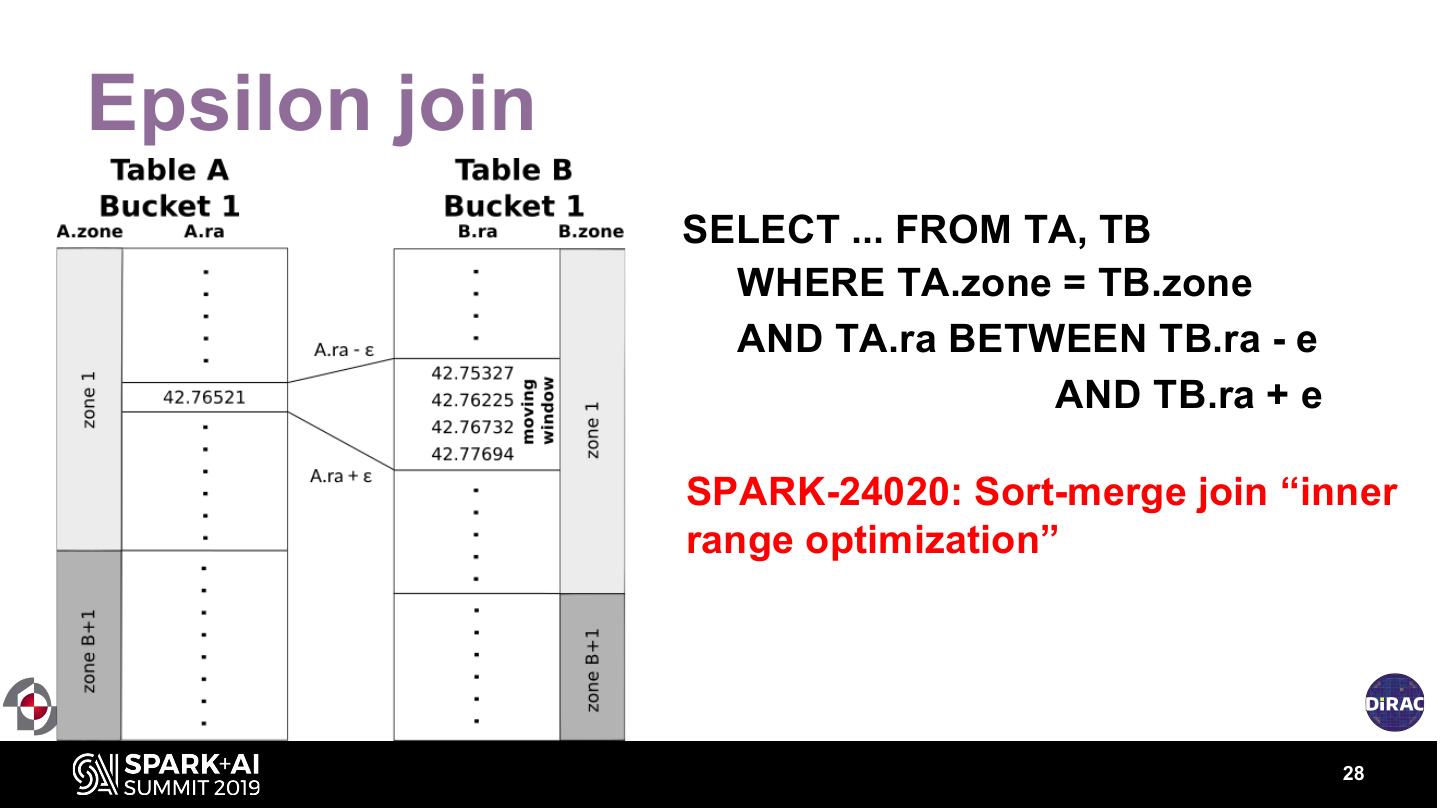
28 .Epsilon join
SELECT ... FROM TA, TB
WHERE TA.zone = TB.zone
AND TA.ra BETWEEN TB.ra - e
AND TB.ra + e
SPARK-24020: Sort-merge join “inner
range optimization”
28
�
29 .Other approaches
Other systems use
HEALPix
or Hierarchical Triangular Mesh (HTM)
29
�