展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Assessing Graph Solutions for Apache Spark
Songting Chen , Victor Lee (TigerGraph)
#UnifiedDataAnalytics #SparkAISummit
�
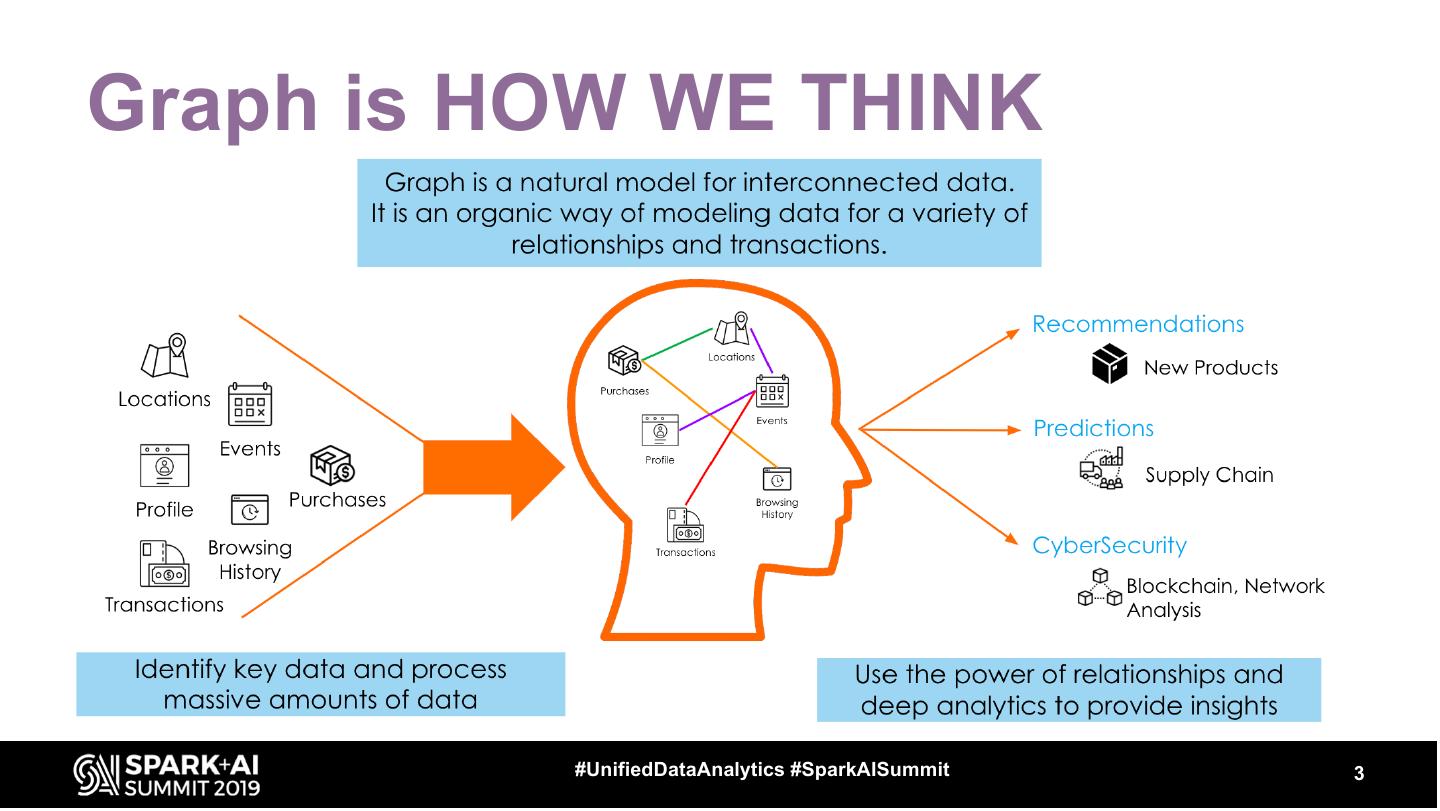
3 .Graph is HOW WE THINK
#UnifiedDataAnalytics #SparkAISummit 3
�
4 .We Use Graph Every Day
#UnifiedDataAnalytics #SparkAISummit 4
�
5 . The Evolution of Graph Analysis
• Early days
– PageRank etc, focus on graph algorithms
– Pregel programming API
• Nowadays
– Query language, more declarative without losing expressive power
– AI + graph data: graph features, training, predictions
– More real time (updates, queries)
– Scale, scale, scale
– Gartner: Graph DB market grows 100% YOY through 2022
#UnifiedDataAnalytics #SparkAISummit 5
�
6 .Typical Workload / Use Cases
• Batch / offline processing
– Web Search/PageRank, etc
• Real time graph queries / updates
– Graph feature extraction for AI training and
prediction, e.g., spam phone call detection
– Data center monitoring (server, router, apps, rack)
– Entire big data industry moves towards real time
• Scalability: large data volume, high QPS
#UnifiedDataAnalytics #SparkAISummit 6
�
7 .This Talk
• Spark: General scalable big data / ML platform
– GraphX: Spark-based Graph Platform
• TigerGraph: Scalable Native Graph Platform
v How they differ, pros and cons for graph applications
v How they work together to provide end-to-end solutions
#UnifiedDataAnalytics #SparkAISummit 7
�
8 .Comparing GraphX and
TigerGraph
�
9 .Areas of Focus
• Graph Data Storage
• Query Expressiveness
• Supported Workload
• Scalability and Performance
#UnifiedDataAnalytics #SparkAISummit 9
�
10 .Graph Data Storage
• TigerGraph
• ETL preload / optimized storage
• GraphX
– Data stored elsewhere and load them on the fly
• Pros and cons
– Load data once (initial cost, good for repeated analysis)
– Load data many times (minimal initial cost, good for initial
exploratory analysis)
#UnifiedDataAnalytics #SparkAISummit 10
�
11 .Query Expressiveness
GraphX - API-based for creating graph algorithm
PageRank(...)
…
while (iteration < numIter) {
rankGraph.cache()
val rankUpdates = rankGraph.aggregateMessages[Double](
ctx => ctx.sendToDst(ctx.srcAttr * ctx.attr), 1
_ + _,
TripletFields.Src) msg: 1/4 = 0.25
prevRankGraph = rankGraph
rankGraph = rankGraph.outerJoinVertices(rankUpdates) {
(id, oldRank, msgSumOpt) => msg
resetProb + (1.0 - resetProb) * msgSumOpt.getOrElse(0.0)
}.cache() msg
rankGraph.edges.foreachPartition(x => {}) +: {msg}
prevRankGraph.vertices.unpersist()
prevRankGraph.edges.unpersist()
iteration += 1
}
#UnifiedDataAnalytics #SparkAISummit 11
�
12 .TigerGraph’s GSQL: Declarative Graph Algorithm Design
SumAccum @received_score = 0;
SumAccum @score = 1; @score
@received_score
people = {People.*};
WHILE True LIMIT maxIter DO src
people = SELECT src
FROM people:src-(:follow)→people:tgt tgt.@received_score
ACCUM tgt.@received_score += src.@score/src.outdegree() += src.@score/src.outdegree()
POST-ACCUM s.@score = (1-resetProb) +
resetProb * t.@received_score, tgt
s.@received_score = 0, src
END;
src
#UnifiedDataAnalytics #SparkAISummit 12
�
13 .TigerGraph’s GSQL – cont.
SumAccum @received_score = 0;
SumAccum @score = 1;
MaxAccum @received_max_neighbor_score = 0; src
MaxAccum @max_neighbor_score = 1;
tgt.@received_score
people = {People.*}; += src.@score/src.degree()
WHILE True LIMIT maxIter DO tgt.@max_neighbor_score
Start = SELECT src += src.@score
FROM people:src-(follow:e)→people:tgt;
ACCUM tgt.@ received_score += src.@score/(s.outdegree()), tgt
tgt.@ received_max_neighbor_score += src.@score
POST-ACCUM s.@score = (1-resetProb) + resetProb * t.@received_score,
src
s.@received_score = 0,
s.@max_neighbor_score = s.@received_max_neighbor_score,
s.@received_max_neighbor_score = 0; src
END;
Simultaneously compute many metrics in a declarative way for complex algorithms
#UnifiedDataAnalytics #SparkAISummit 13
�
14 .GraphFrame: Declarative Pattern Query
val chain4 = g.find("(a)-[ab]->(b); (b)-[bc]->(c); (c)-[cd]->(d)")
def sumFriends(cnt: Column, relationship: Column): Column = {
when(relationship === "friend", cnt + 1).otherwise(cnt)
}
val condition = Seq("ab", "bc", "cd").
foldLeft(lit(0))((cnt, e) => sumFriends(cnt, col(e)("relationship")))
// (c) Apply filter to DataFrame.
val chainWith2Friends2 = chain4.where(condition >= 2)
#UnifiedDataAnalytics #SparkAISummit 14
�
15 .TigerGraph’s GSQL: declarative pattern matching + algorithm
@rank
A simple recommendation algorithm @common_buys
SumAccum @common_buys;
OrAccum @already_bought;
SumAccum @product_rank; @common_buys
other_people = SELECT g
FROM seed_people:s-(buy)→ product:t ← (buy)-people:g
ACCUM g.@common_buys += 1, @common_buys
t.@already_bought += true
recommended_products = SELECT t
FROM other_people:s -> (buy:e) -> product:t
WHERE t.already_bought = false
@rank
ACCUM t.rank += log(1 + s.@common_buys)
ORDER BY t.rank DESC
LIMIT 20
Real time updates / queries could significantly improve the effectiveness of the recommendation algorithm.
#UnifiedDataAnalytics #SparkAISummit 15
�
16 .Query Expressiveness - Summary
• GraphX (API for designing graph algorithm) +
GraphFrame (declarative pattern queries)
• GSQL (SQL-procedure query language, declarative on
both graph algorithm and pattern matching)
• Both provide powerful graph analytics capabilities
#UnifiedDataAnalytics #SparkAISummit 16
�
17 .Query Workload
GraphX TigerGraph
Big Analytics Query ✓ ✓
High QPS, Sub-second Query ✓
Workload
Real Time Transactional Updates ✓
GraphX (OLAP) TigerGraph (HTAP)
#UnifiedDataAnalytics #SparkAISummit 17
�
18 .Scalability
• Spark/GraphX is well-known for its scalability
and MPP capabilities.
• TigerGraph is also designed from ground up
with MPP and scalability in mind.
#UnifiedDataAnalytics #SparkAISummit 18
�
19 .TigerGraph: Analytics Query Scalability
Twitter dataset (41M vertices, 1.4B edges)
AWS 16 r5.2xlarge servers (8 cores, 64GB memory)
Latency (s)
# servers
#UnifiedDataAnalytics #SparkAISummit 19
�
20 .TigerGraph: Point Query Scalability
Point query: 3-step graph traversals from a seed vertex
Application: real time ML prediction based on graph features
QPS
# servers
#UnifiedDataAnalytics #SparkAISummit 20
�
21 .Performance Comparison
GraphX: EdgePartition2D; AWS 16 r5.x2large servers (8 cores, 64GB memory)
Latency (s)
#UnifiedDataAnalytics #SparkAISummit 21
�
22 .Performance Comparison Cont.
GraphX: EdgePartition2D; AWS 16 r5.x2large servers (8 cores, 64GB memory)
Latency (s)
#UnifiedDataAnalytics #SparkAISummit 22
�
23 .Summary / Recommendations
• GraphX: Quick-to-result exploratory analysis
without having to preload the graph data
• TigerGraph: High performance graph
analytics, real time transactional updates, high
QPS sub-second query workload
#UnifiedDataAnalytics #SparkAISummit 23
�
24 .How Spark and TigerGraph
Work Together
�
25 .Reference Architecture: Spark + TigerGraph for AI
25
�
26 .Connect Spark-TigerGraph through JDBC
• Support Read and Write bi-directional data flow to/from TigerGraph
• Read: Convert graph query results to DataFrame
• Write: Load DataFrame/Files to Vertex/Edges in TigerGraph
• Open Source
– https://github.com/tigergraph/ecosystem/tree/master/etl/tg_jdbc_driver
26
�
27 .Benefits of Spark + TigerGraph
• Take full advantage of the value from graph data in real time
• Combine them with all other data for deep insights and AI
• Scalable in every step
• Already have actual use cases running in this architecture
27
�