










































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板

Applied Machine Learning for Ranking Products in an Ecommerce Setting
Applied Machine Learning for Ranking Products in an Ecommerce Setting
Applied Machine Learning for Ranking Products in an Ecommerce Setting
As a leading e-commerce company in fashion in the Netherlands, Wehkamp dedicates itself to provide a better shopping experience for the customers. Using Spark, the data science team is able to develop various machine-learning projects for this purpose based on the large scale data of products and customers. A major topic for the data science team is ranking products. If a visitor enters a search phrase, what are the best products that fit the search phrase and in what order should the products been shown? Ranking products is also important if a visitor enters a product overview page, where hundreds or even thousands of products of a certain article type are displayed.
In this project, Spark is used in the whole pipeline: retrieving and processing the search phrases and their results, making click models, creating feature sets, training and evaluating ranking models, pushing the models to production using ElasticSearch and creating Tableau dashboarding. In this talk, we are going to demonstrate how we use Spark to build up the whole pipeline of ranking products and the challenges we faced along the way.
展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
2 .Applied Machine Learning for Ranking Products in an Ecommerce Setting Arnoud de Munnik & Jerry Vos, wehkamp #UnifiedDataAnalytics #SparkAISummit
3 .Jerry Vos Arnoud de Munnik Data Scientist Data Scientist @wehkamp since 2001 @wehkamp since 2011 Education: Econometrics Education: Marketing Research #UnifiedDataAnalytics #SparkAISummit 3
4 .Agenda • Intro wehkamp • E-commerce ranking problem • Our learning-to-rank pipeline • Ranking model • Q&A #UnifiedDataAnalytics #SparkAISummit 4
5 .the online department store for families in the Netherlands
6 . our history where we come from 1952 - first advertisement 1955 - first catalog 1995 - first steps online 2010 - completely online 2018 - mobile first 2019 - a great shop experience
7 . our categories Fashion // Home & garden // Electronics // Entertainment // Household // Sports & Leisure // Beauty & Health 60% >400.000 >500.000 661 million of customers products daily visitors sales 18/19 shopping mobile 11 million 72% > 950 of our packages colleagues customers is female over 2.000 brands C&A // Vingino // Hunkemöller // Mango // Tommy Hilfiger // Scotch & Soda // ONLY HK Living // House Doctor // Woood // Bloomingville // Zuiver // whkmp’s own
8 .Our journey • We work(ed) with a traditional corporate data warehouse • Need: ML, flexibility, speed, enabling, etc. • 2 years ago: pilot Spark on Databricks – Challenges: Training of people, data in cloud • Today: – Transformation to Databricks / Cloud (S3) – Lots of new (ML) products/prototypes and colleagues on DB platform #UnifiedDataAnalytics #SparkAISummit 8
9 .Machine learning @ wehkamp Search Product Forecasti Recommend ers ranking ng Image Fraud Personalisat classificati detection And a ion on lot more #UnifiedDataAnalytics #SparkAISummit 9
10 .Machine learning @ wehkamp Search Product Forecasti Recommend ers ranking ng Image Fraud Personalisat classificati detection And a ion on lot more #UnifiedDataAnalytics #SparkAISummit 10
11 .Ranking problem for ecommerce
12 .Ranking problem for ecommerce User search for ‘jeans’ We return 4401 products Relevant? #UnifiedDataAnalytics #SparkAISummit 12
13 .Ranking problem for ecommerce User navigates to ‘ladies jeans’ overview page We return 2176 products Relevant? #UnifiedDataAnalytics #SparkAISummit 13
14 . Ranking problem for ecommerce ● Consider a visit to a ‘product overview page’ (example ‘ladies jeans’) as a user query ● Main problem: maximize the order of relevance of returned products given a user query #UnifiedDataAnalytics #SparkAISummit 14
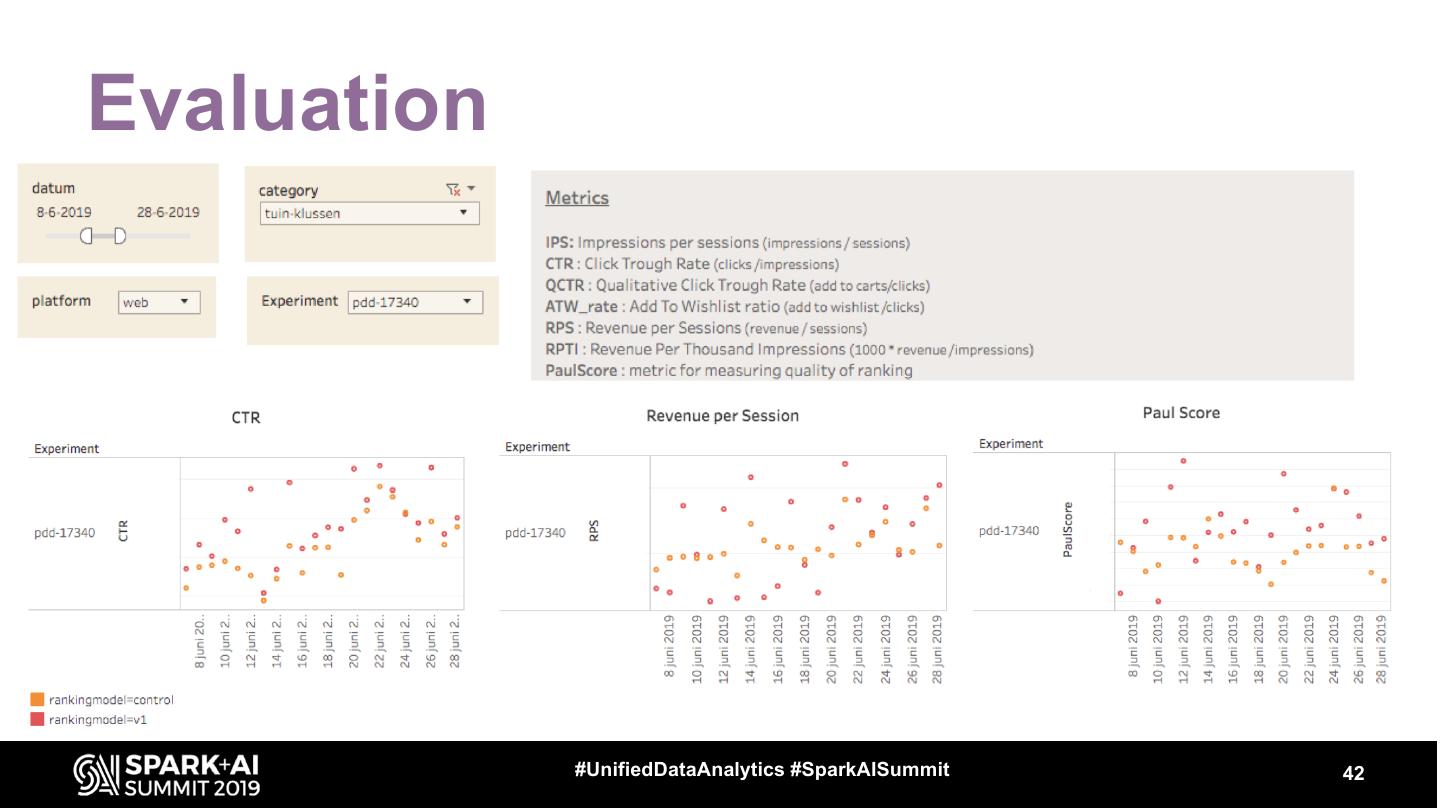
15 .Ranking problem for ecommerce ● How good is this list? ● Suppose we know how relevant each item is, can we define an overall score for the relevancy of this list? ● Yes we can, the answer is NDCG (Normalized Discounted Cumulative Gain) https://en.wikipedia.org/wiki/Discounted_cumulative_gain
16 . Ranking problem for ecommerce ● Suppose we know relevancy scores, let’s rank them i ● Let’s add a correction for position via 1 2 1,00 2,00 Log2(i+1) 2 3 4 2 3 1,58 1,89 ● Divide and sum to get a score: discounted cumulative gain (7,84) 3 4 2,00 2,00 4 ● Do the same, but for this list in 1 2,32 0,43 perfect order to get an Ideal DCG. 5 3 2,58 1,16 That score will be: 9,00 1 3 1 6 1 2,81 0,36 ● Divide our DCG / IDCG = normalized discounted cumulative gain (0.87) Sum: 7,84
17 .Ranking problem for ecommerce Relevancy scores Explain the scores with features Title match Article match Reviews Seasonality 2 3 1 4 Price … Maximize the NDCG, by giving weight to features
18 .Learning to rank pipeline
19 .Special thanks Wikimedia MjoLniR: https://github.com/wikimedia/search-MjoLniR
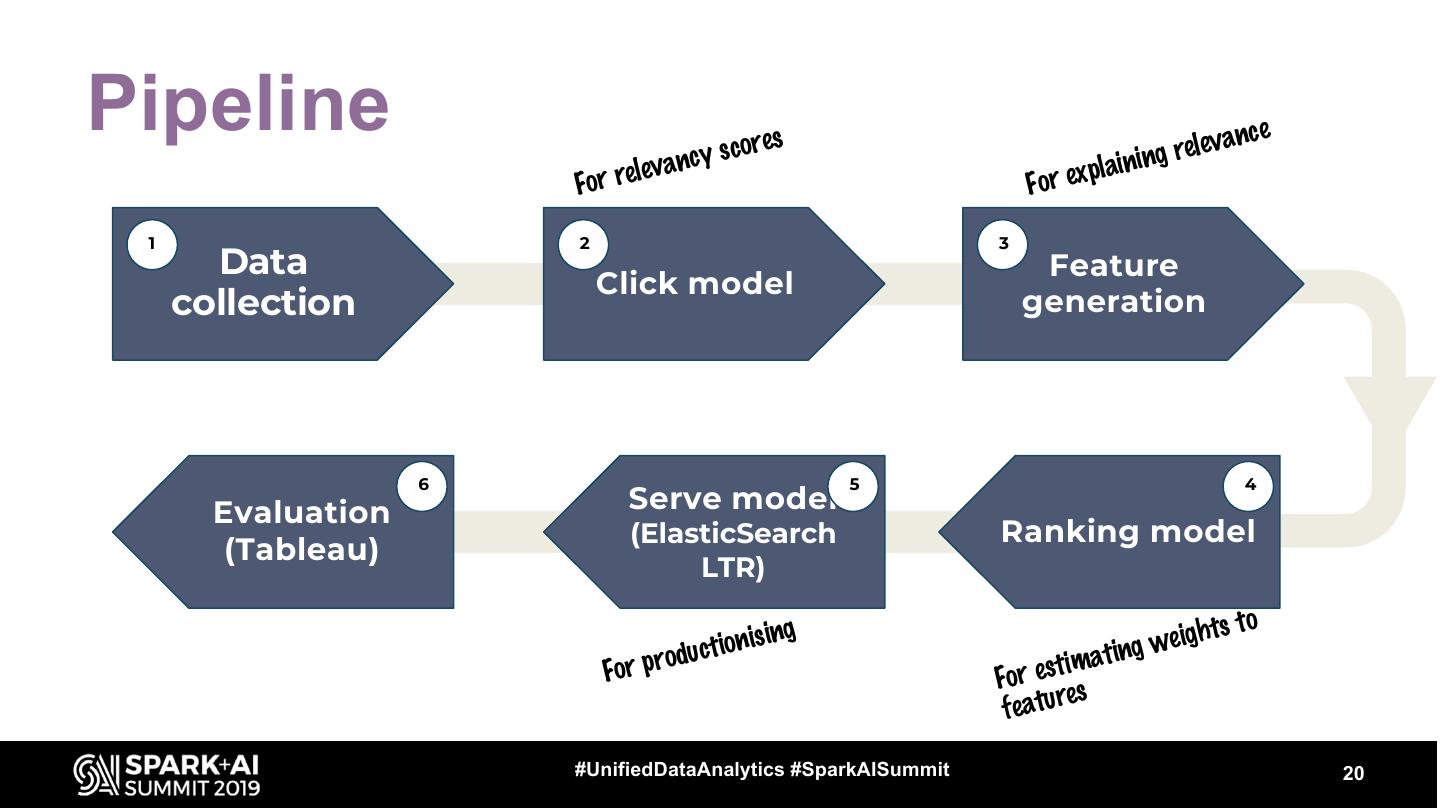
20 .Pipeline scores g relev ance e le vancy pla inin For r For ex 1 2 3 Data Feature Click model collection generation 6 5 4 Evaluation Serve model (ElasticSearch Ranking model (Tableau) LTR) ising hts to r oduction a ting weig For p tim For es s e featur #UnifiedDataAnalytics #SparkAISummit 20
21 .Efforts • Initial effort of building pipeline: 2 data scientists and 1 data engineer (for search and Product Overview Page) for a couple of months • New click/ranking model: 1 data scientist can train, test and push a new ranking model to production within 1 hour #UnifiedDataAnalytics #SparkAISummit 21
22 . Data collection ● Source: raw Google Analytics feed (daily) ● Per product list (i.e. search, overview page): ○ ProductID ○ Position / Page ○ Impression / Click ● Challenges: ○ tagging is different for web and app ○ devices have different display formats #UnifiedDataAnalytics #SparkAISummit 22
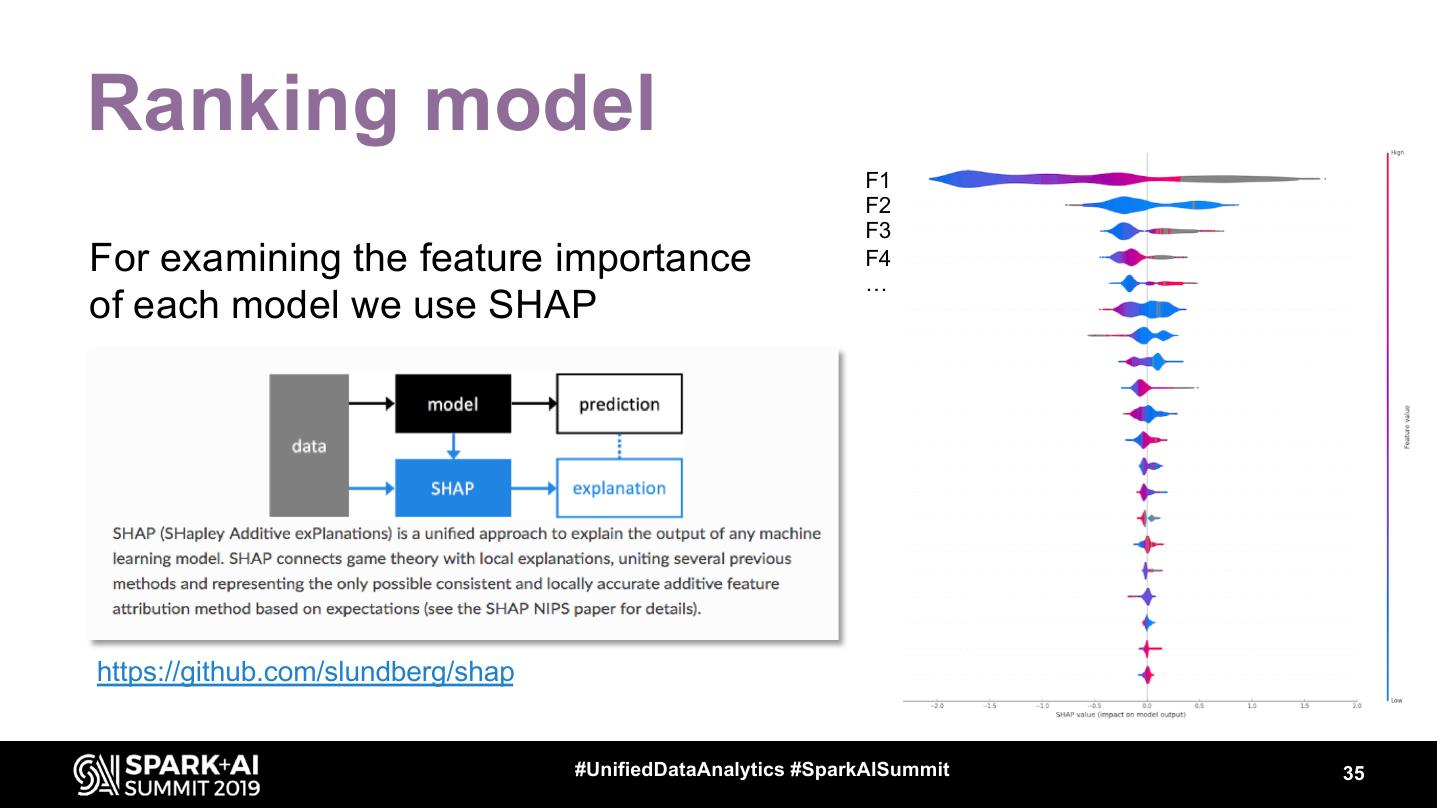
23 .Click model Reality: We don’t know the relevancy scores; use a click model. Goal: determine relevance of products in each SOP/POP Approach: predict the relevance of products based on impressions and clicks of products given its position • DBN click model • Clicks over Expected clicks (COEC) (https://github.com/varepsilon/clickmodels) • Corrected for small search queries • Paper: Dynamic Bayesian Network ( DBN ) model: Chapelle, O. and Zhang, Y. 2009. A dynamic bayesian network click model for web search ranking. WWW (2009) In our case: better results, easier to train & explain
24 .COEC click model Example #UnifiedDataAnalytics #SparkAISummit 24
25 .COEC click model search phrase Product Id clicks Expected Bucket aka clicks relevancy Jeans 0123456 250 50 3 Jeans 6543210 200 20 4 Jeans 3211231 300 300 2 Jeans 4566543 400 800 1 Jeans Random product Add id - random data - 0 9997979 #UnifiedDataAnalytics #SparkAISummit 25
26 . Demo clickmodel Query: “Flared jeans” Relevancy: 1 Relevancy: 4 #UnifiedDataAnalytics #SparkAISummit 26
27 . Feature generation Try to explain and predict which attributes (i.e. features) of products (wrt user query) contribute to its relevance score Feature examples - Title match - Popularity Description match Limit the number of features to - - Discount / Promo ● < 100 (latency issues) - Tf-idf - Seasonality - … - Reviews ● For POP features we did not - Days online use OHE, but a Bayesian encoder to limit number of - Brand features - .. #UnifiedDataAnalytics #SparkAISummit 27
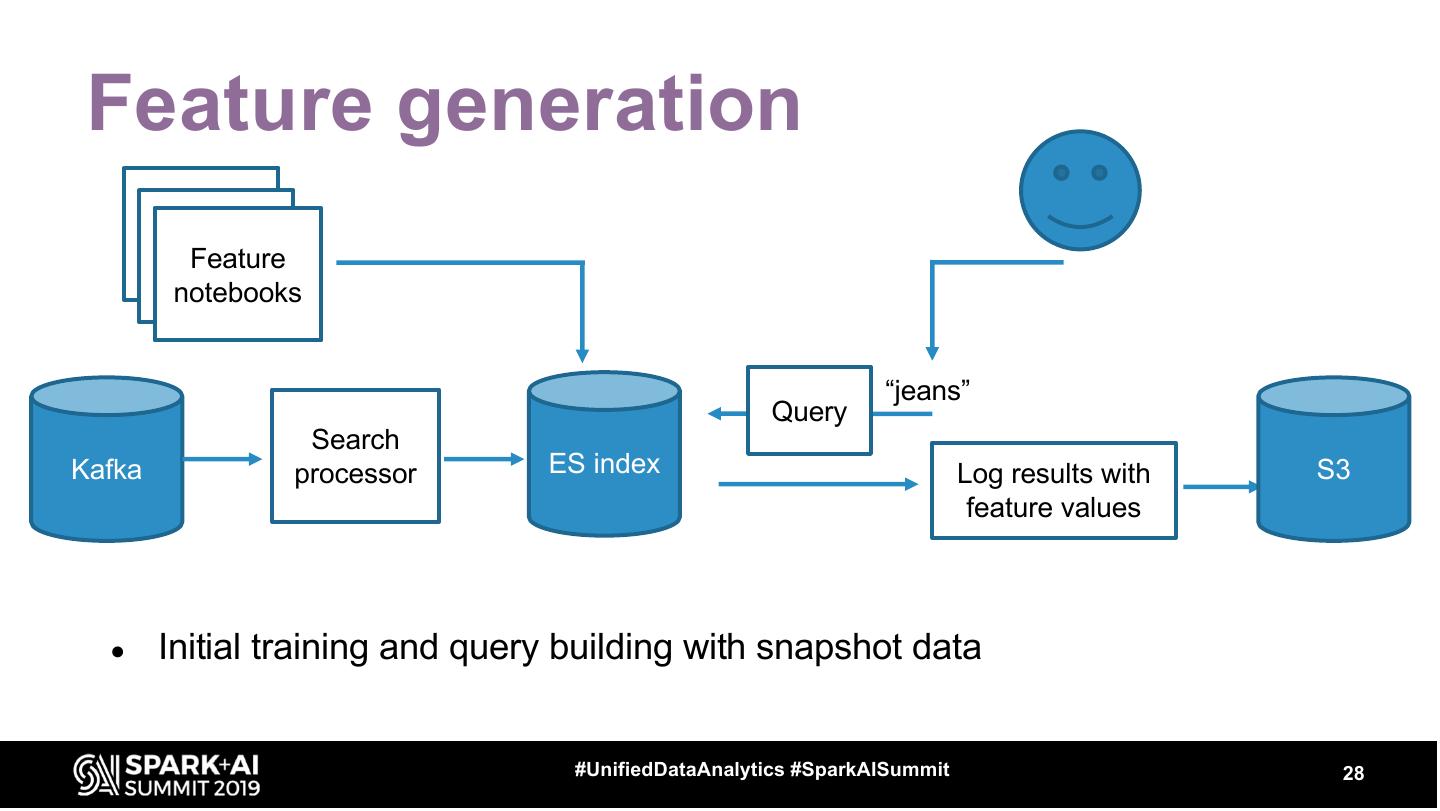
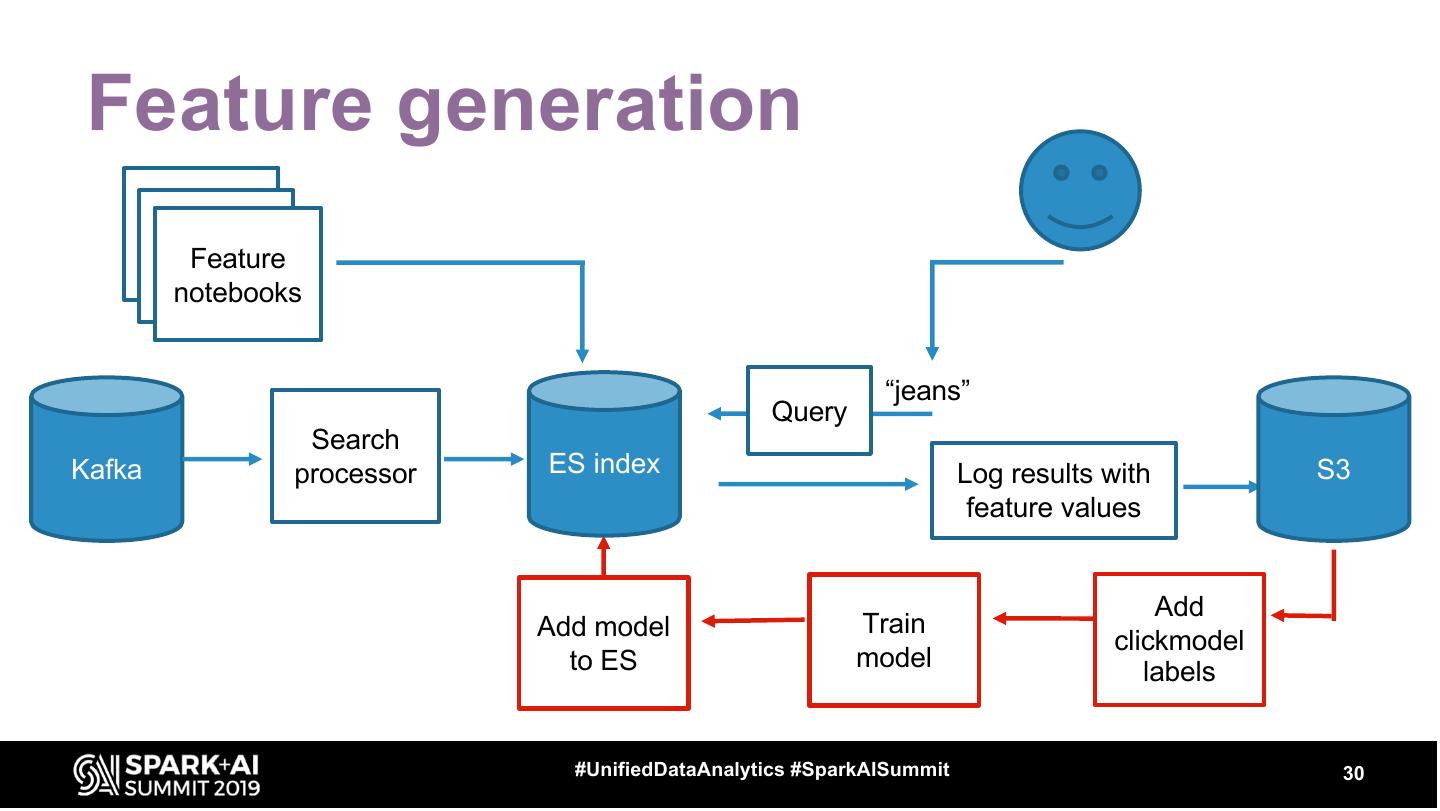
28 . Feature generation Feature notebooks “jeans” Query Search Kafka processor ES index Log results with S3 feature values ● Initial training and query building with snapshot data #UnifiedDataAnalytics #SparkAISummit 28
29 .Feature generation Delta pre- processed OpenWeatherMap data API Seasonality Feature estimate per notebooks article type AGG Delta view/sales/promo feature data DB Fetch features Timeseries models and send ES index with prediction à to ES Scaled via Pandas UDF #UnifiedDataAnalytics #SparkAISummit 29
3秒后跳转登录页面
去登陆

