展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .Application and challenges of streaming
analytics and machine learning on multi-variate
time series data for smart manufacturing
Pranav Prakash, Quartic.ai
#UnifiedDataAnalytics #SparkAISummit
�
3 .Pranav Prakash
• Co-Founder, VP Engineering at
Quartic.ai
• Ex- LinkedIn SlideShare
• Passionate about
– A.I., Computer Vision, 3D
Printing
– Music, Caffeine
3
�
4 . Downtime
What A cool startup
solving some real-
Reduction use
case of a critical
asset in Pharma
you’ll life use cases world
•And a “secret” to
solve such problems
learn in
next 40 Challenges in
Industrial Stream
Spark specific stuff
that we learned
Processing
mins
4
�
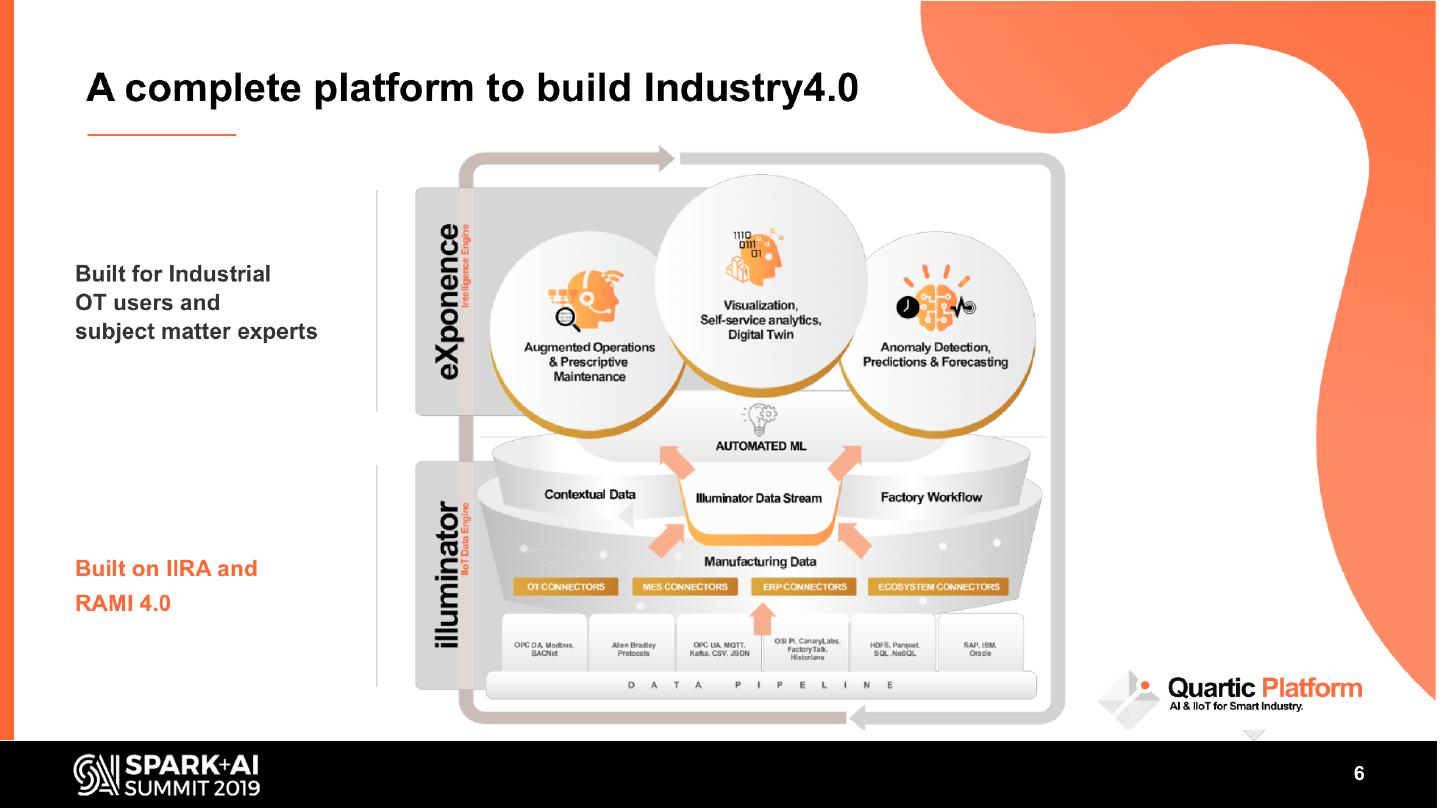
5 .We enable Industry 4.0
• AI powered smart manufacturing platform
• Processing Billions of sensor data every
day
• Work with top Pharma companies on
multiple use cases
• Team of 22 techies including Engineers &
Data Scientists + 4 Domain Veterans
#UnifiedDataAnalytics #SparkAISummit 5
�
7 . We started by • Increased uptime of sterilization autoclave by 7 days
building • Increased yield of protein from fermentation process
solutions for • Incubated egg harvester – increase uptime during
critical flu season
pharmaceutical • Cold-chain monitoring for pharma refrigeration –
reduced downtime and waste
manufacturing • Predictive health monitoring of air handlers for clean
rooms in pharma
And created a • Enable continuous validation of biologic production
DIY platform process
• Medical Device Assembly – reduce recalls caused by
poor quality.
�
8 .Case study – an Intelligent
Asset Health Monitoring system
for an Industrial Autoclave
• Mission - Improve the
reliability of a complex asset.
• Details - 13 different modes
(cycles)
• Runs 24/7
• Critical Asset
�
9 . • Capture process, condition data
• Establish baseline and measure
Equipment deviations
Reliability •
•
Forecast the future
Classify errors early
• “Advisory Mode” AI
�
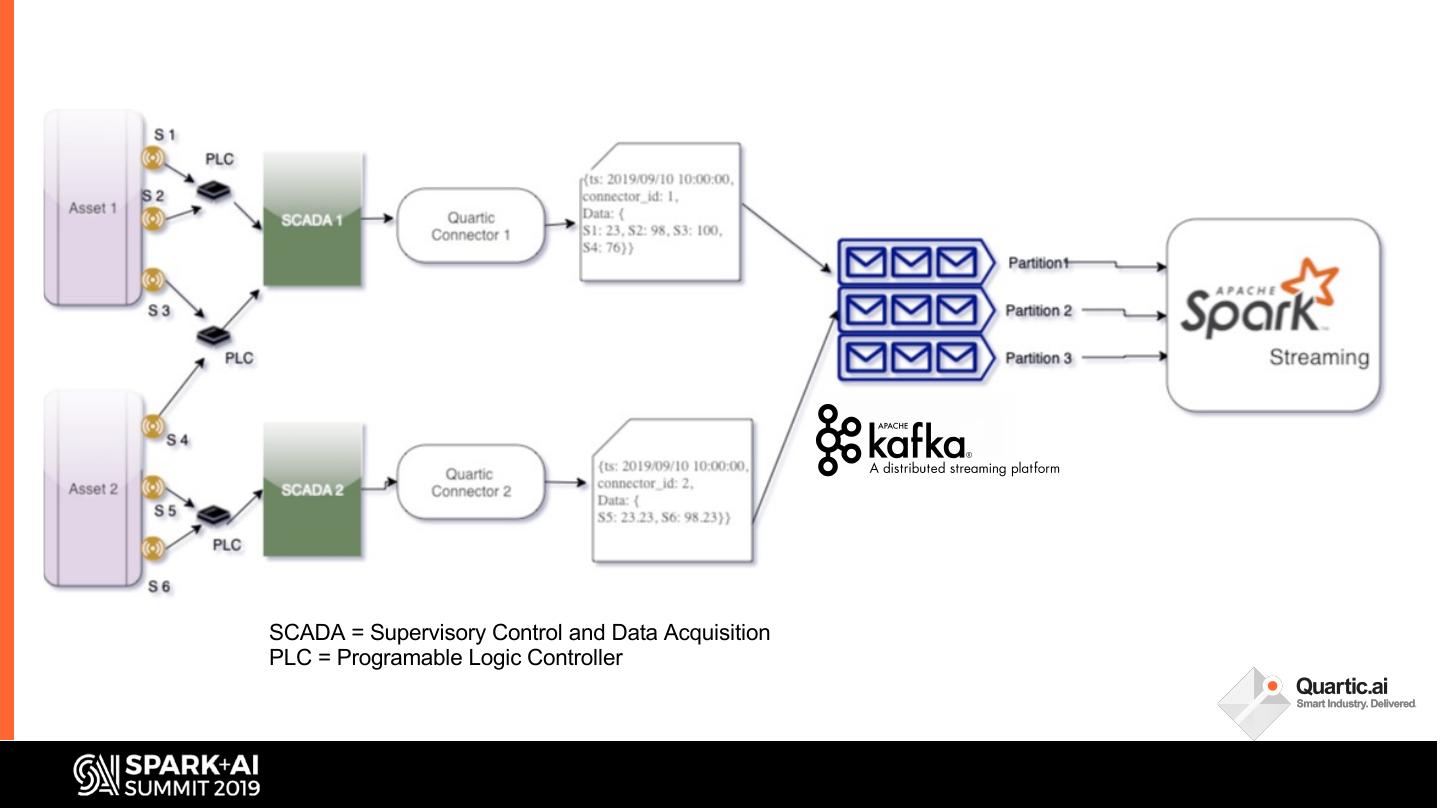
10 .SCADA = Supervisory Control and Data Acquisition
PLC = Programable Logic Controller
�
11 . • Data
– Speed: 10ms – 2 hours
System – Volume: Couple 1,000s sensors per
asset. 10,000s of asset per
Design enterprise
– Data Type: String, Numeric,
Params Boolean, Array
– Timeseries, Discrete
�
12 . • Deployment
– Edge (80%)
System • Hardware Limit
Design • Many cloud-only solutions won’t
work
Params • High Uptime, Low Response
Time
– Cloud (20%)
�
13 . • Use Cases
System – Automatic Model Param Tuning,
Model Training
Design – 1000s of ML Models Deployment
– Complex Event Processing (CEP)
Params – Statistical & Analytical Processing
• Rule Recommendation
• Near Real Time Stream Processing
�
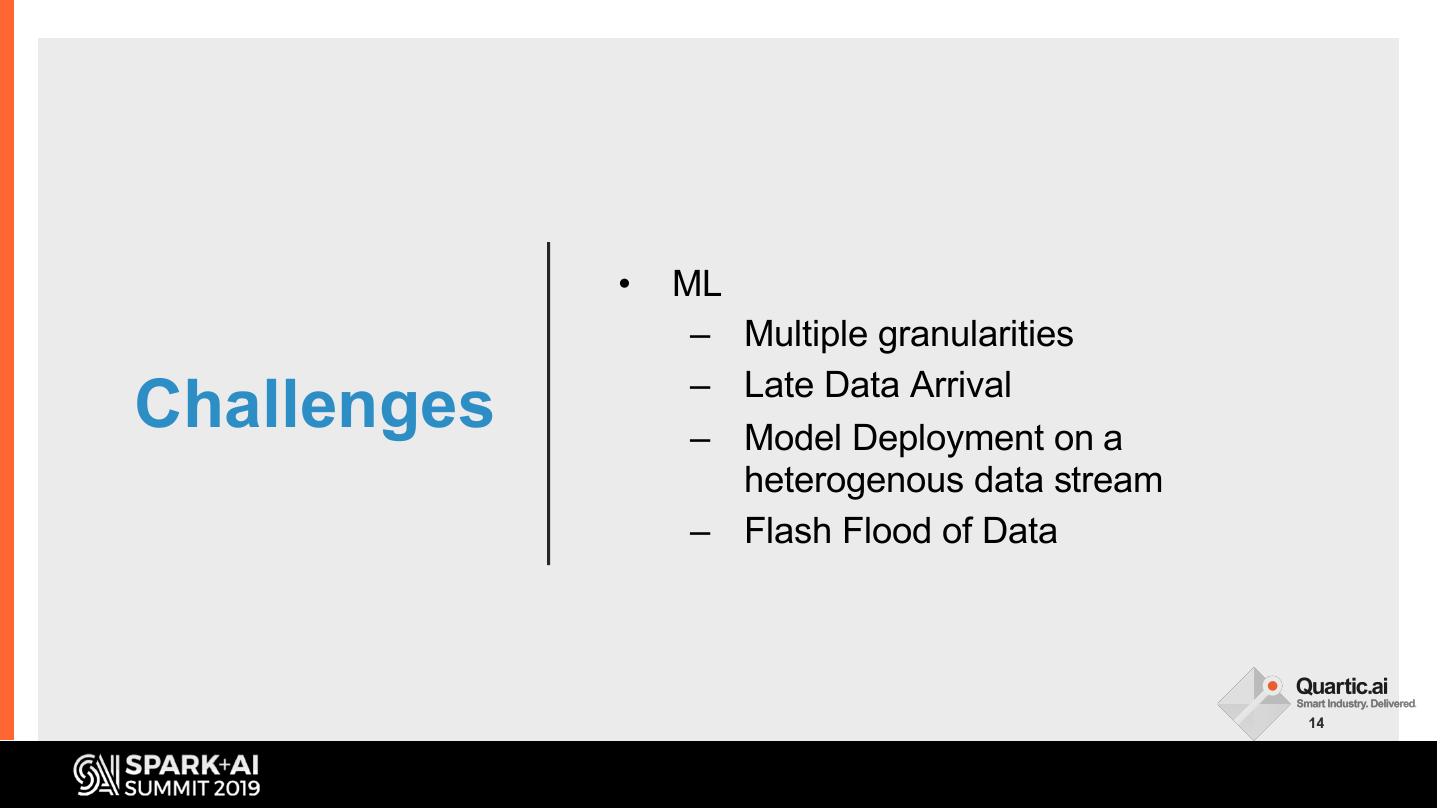
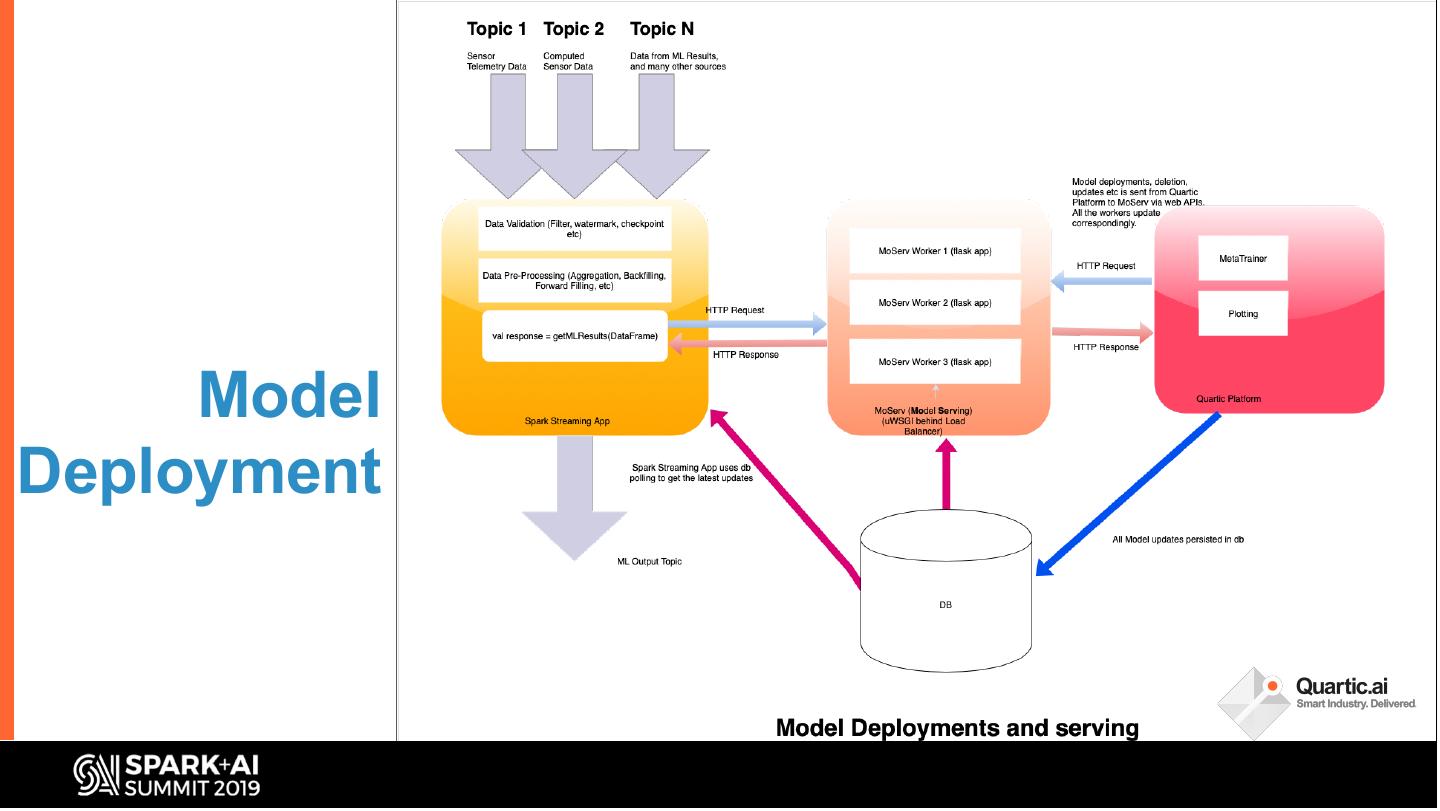
14 . • ML
– Multiple granularities
– Late Data Arrival
Challenges – Model Deployment on a
heterogenous data stream
– Flash Flood of Data
�
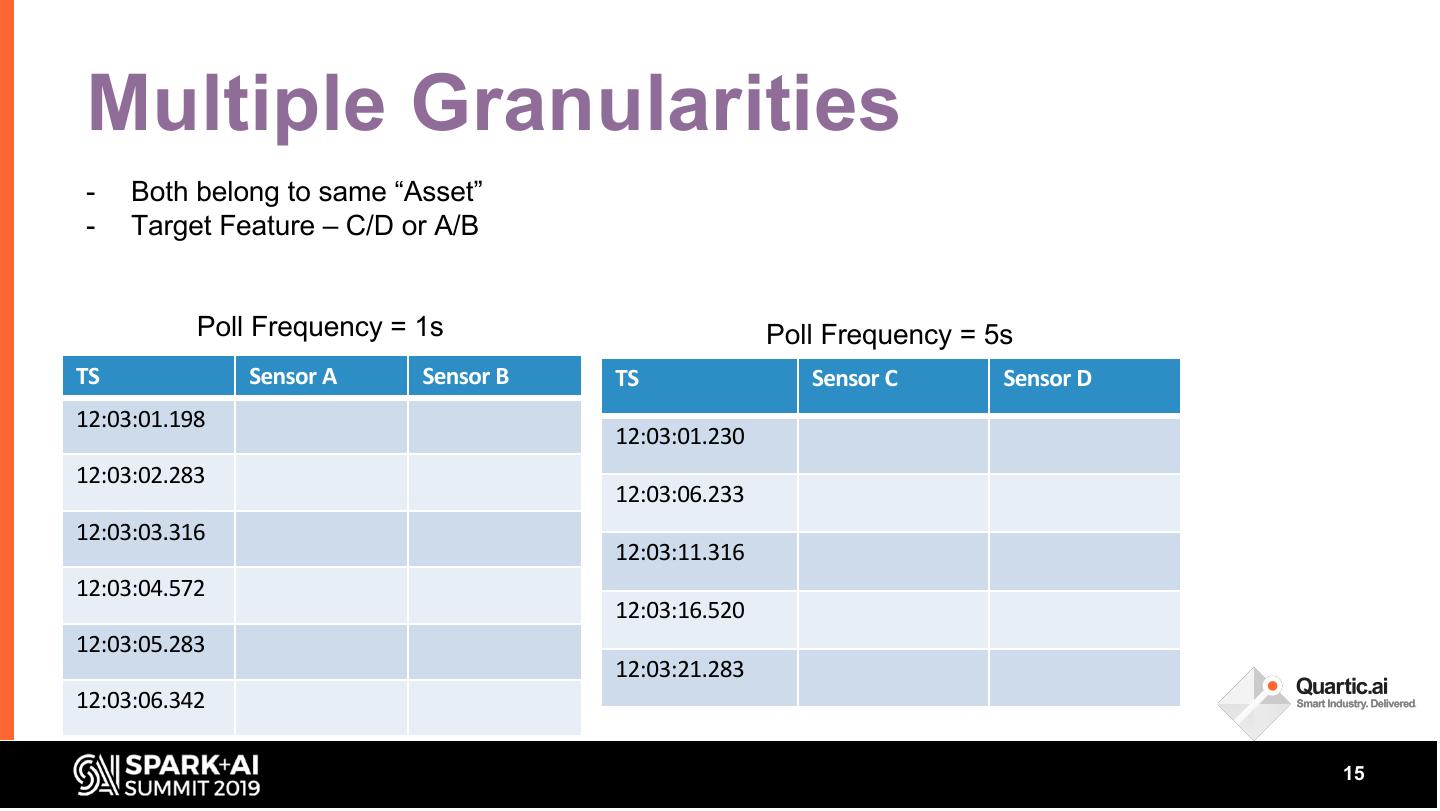
15 .Multiple Granularities
- Both belong to same “Asset”
- Target Feature – C/D or A/B
Poll Frequency = 1s Poll Frequency = 5s
TS Sensor A Sensor B TS Sensor C Sensor D
12:03:01.198
12:03:01.230
12:03:02.283
12:03:06.233
12:03:03.316
12:03:11.316
12:03:04.572
12:03:16.520
12:03:05.283
12:03:21.283
12:03:06.342
15
�
16 . Multiple • Approximation (Roundoff)
• Aggregation
Granularities • Filling - Forward or Backward or
Average
�
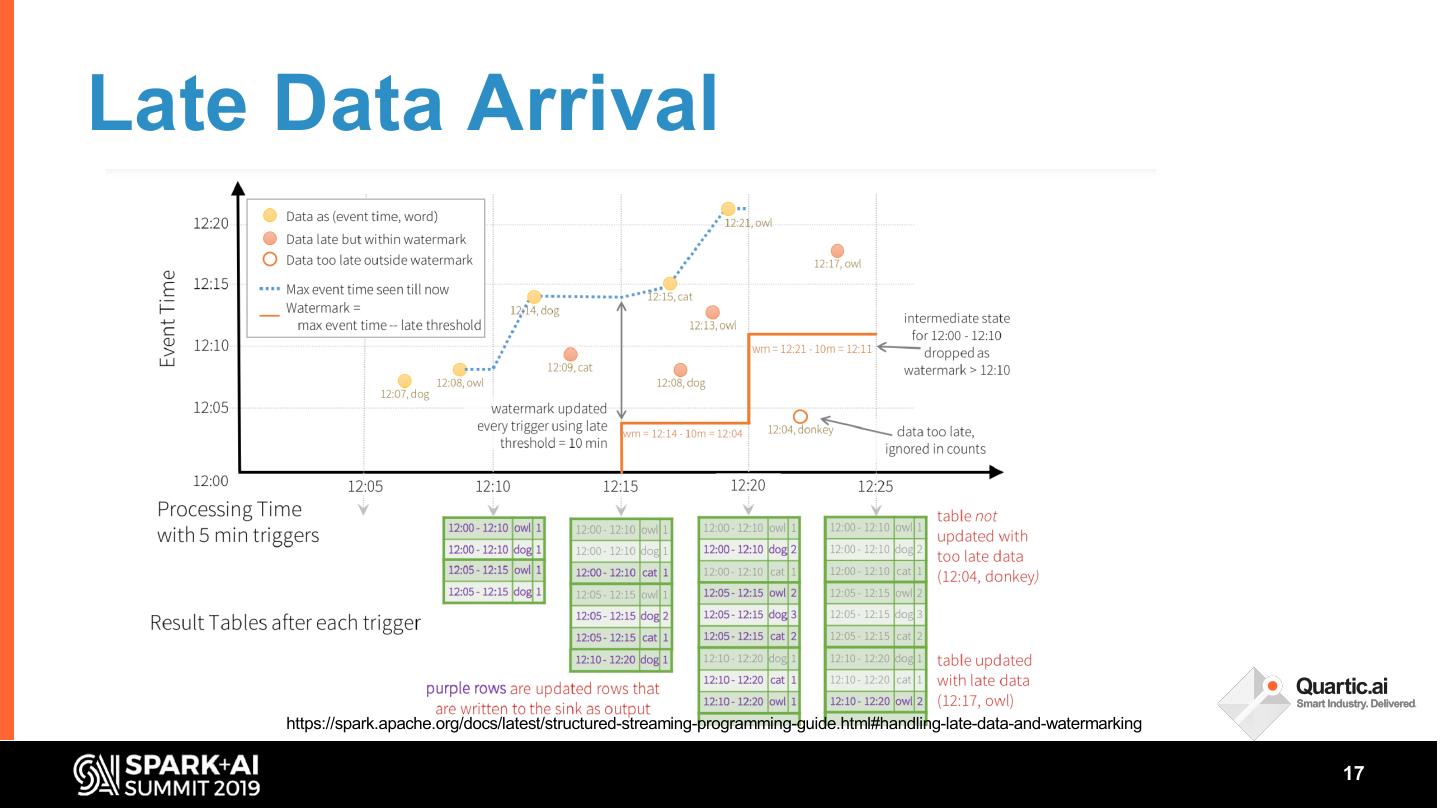
17 .Late Data Arrival
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#handling-late-data-and-watermarking
17
�
18 . • Watermarking
Late Data – Homogenous stream: One
watermark per Stream
Arrival – Heterogenous stream: multiple
watermark per “Usage
Condition”
�
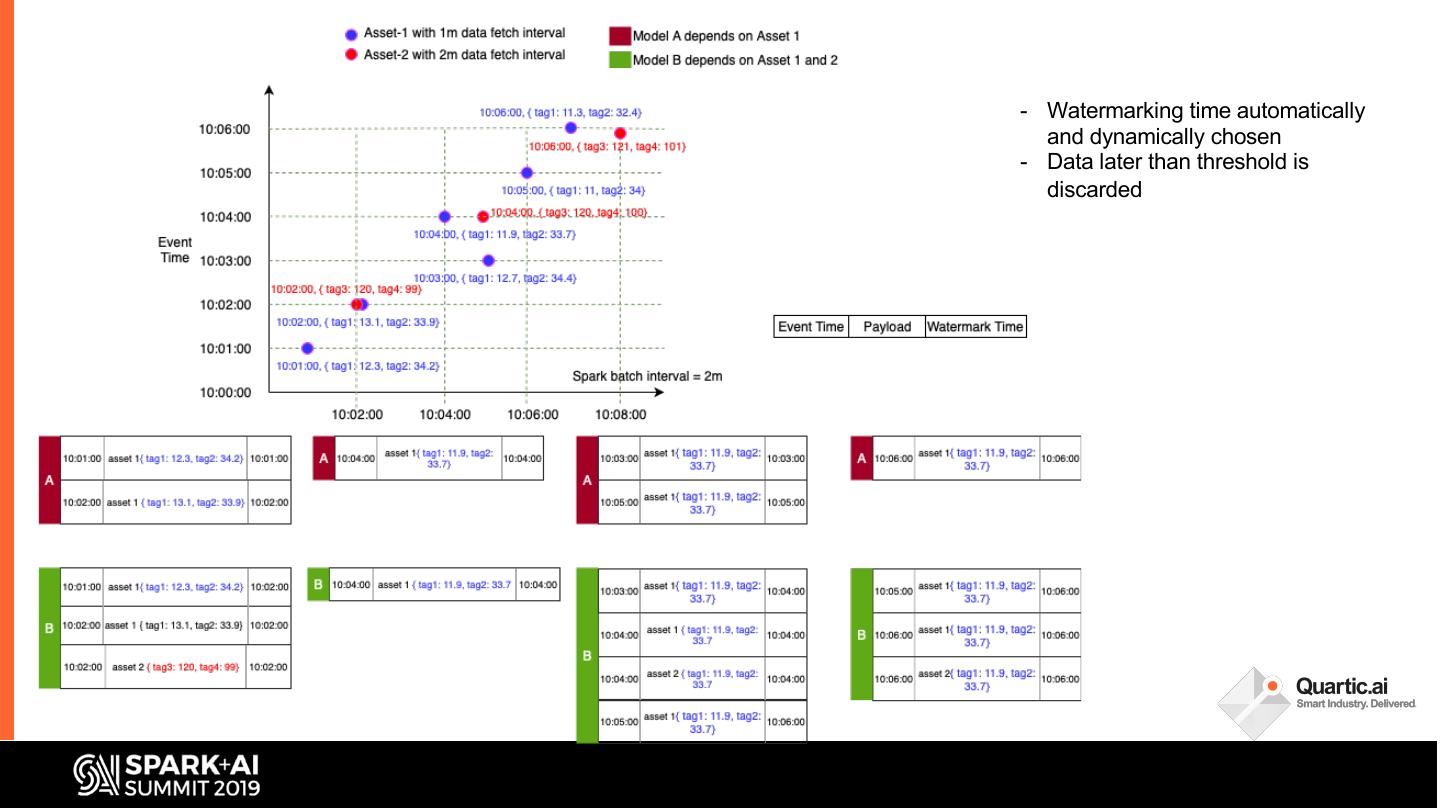
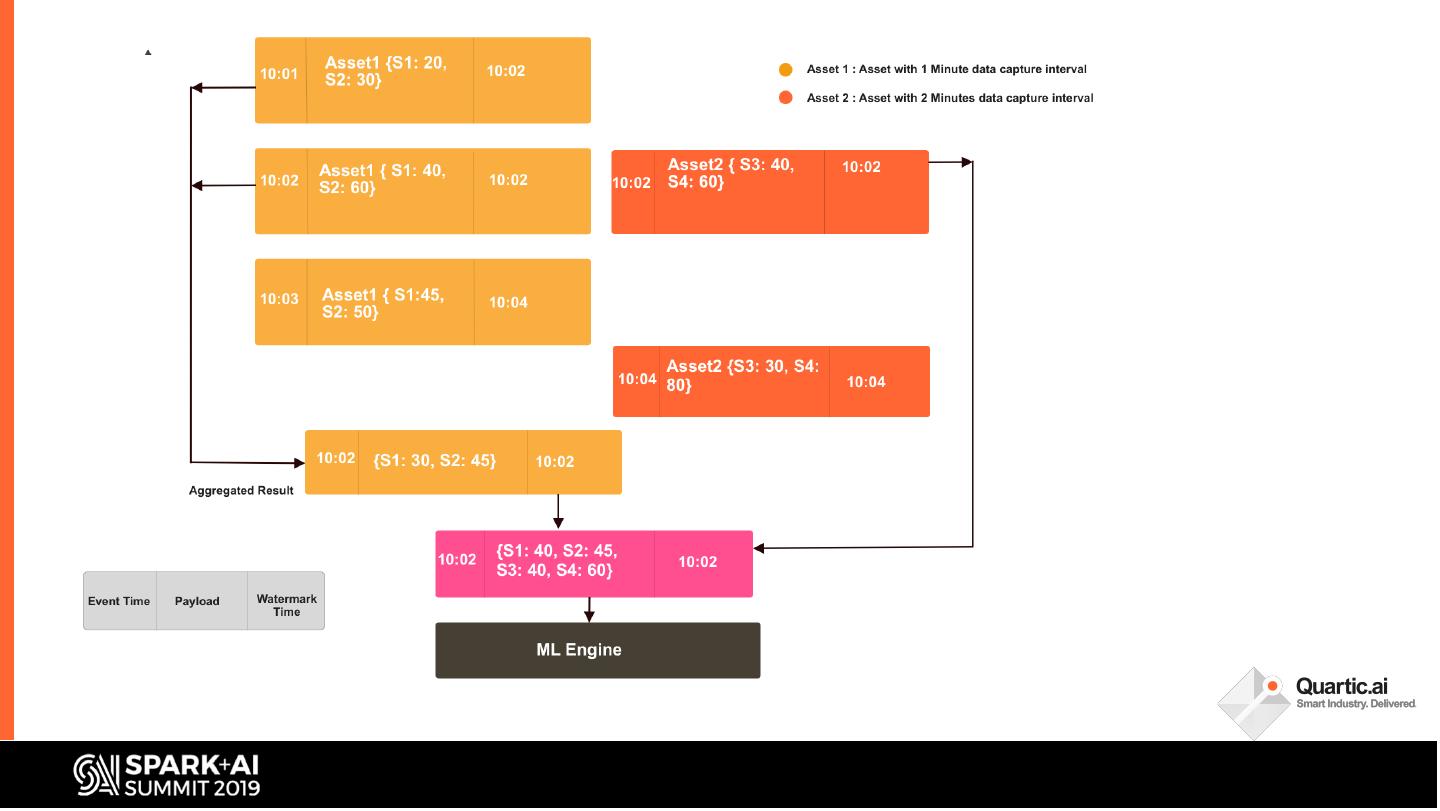
19 .- Watermarking time automatically
and dynamically chosen
- Data later than threshold is
discarded
�
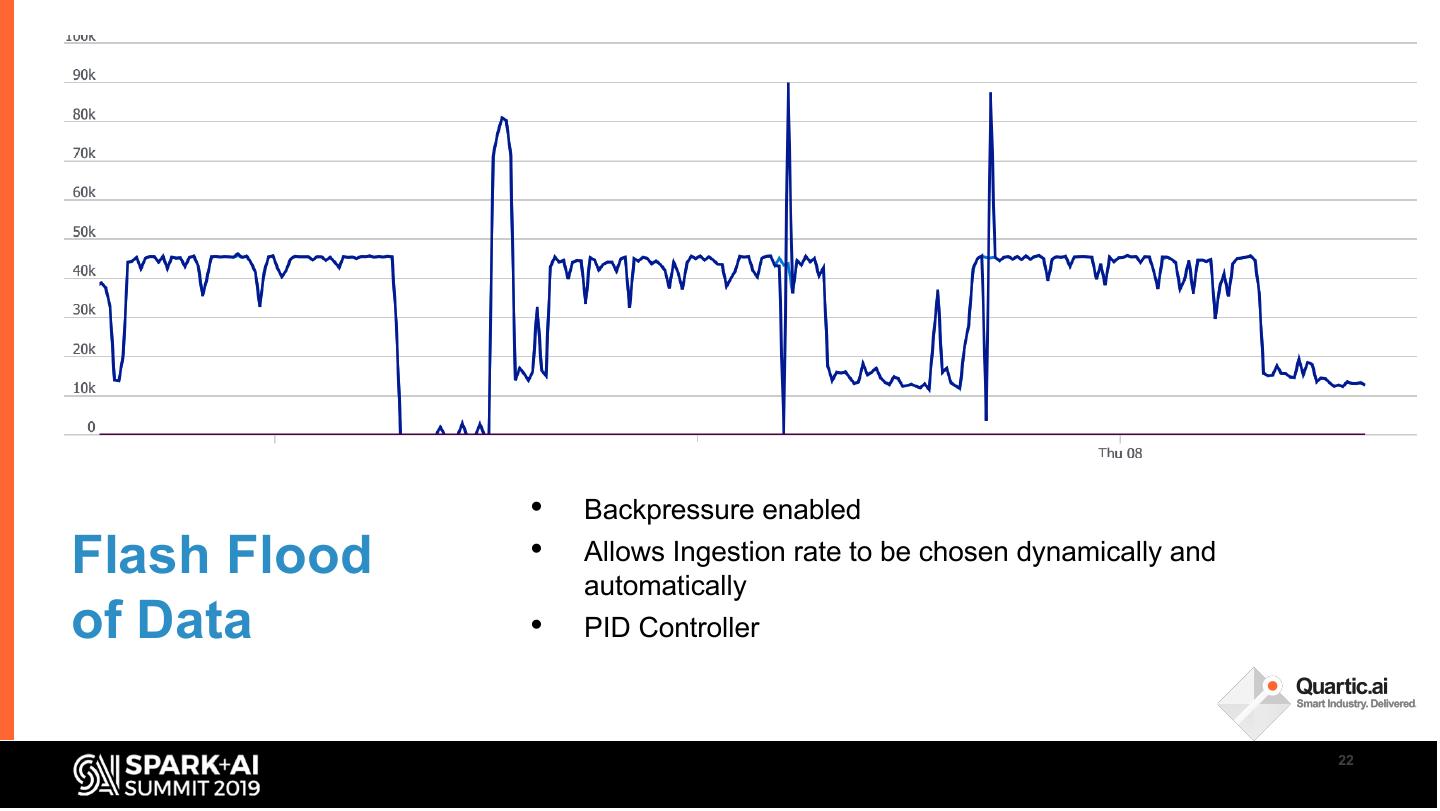
22 . • Backpressure enabled
Flash Flood • Allows Ingestion rate to be chosen dynamically and
automatically
of Data • PID Controller
22
�
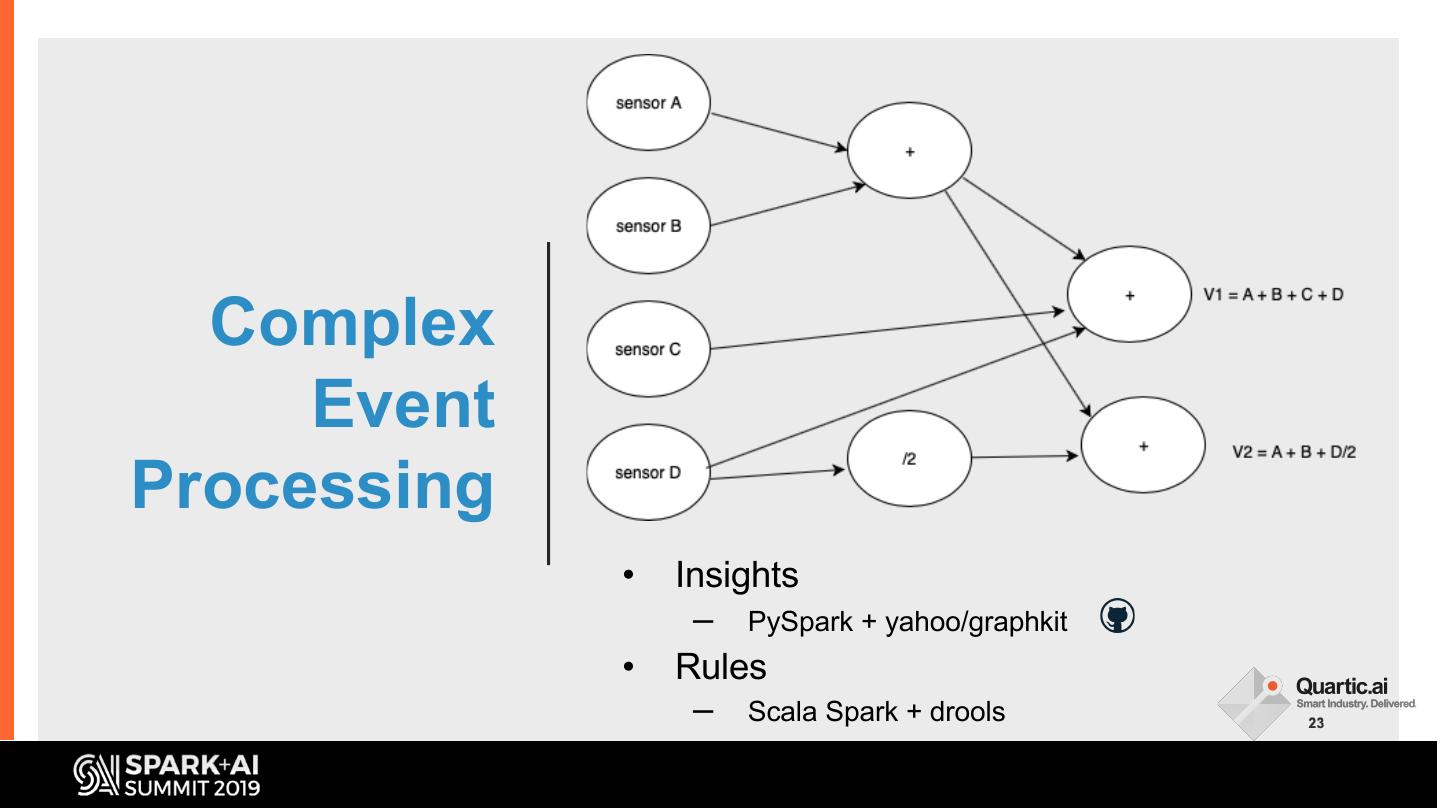
23 . Complex
Event
Processing
• Insights
– PySpark + yahoo/graphkit
• Rules
– Scala Spark + drools
�
24 . • Industrial IoT is different
• Context = Process Data + Condition Data
Summing • Techniques for processing heterogenous
stream
it up
�
25 .We’re hiring
helloworld@quartic.ai
2
5
�
26 .DON’T FORGET TO RATE
AND REVIEW THE SESSIONS
SEARCH SPARK + AI SUMMIT
�