
























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板

Apache Spark for Cyber Security in an Enterprise Company
Apache Spark for Cyber Security in an Enterprise Company
Apache Spark for Cyber Security in an Enterprise Company
• Introduction
• Challenges in Cyber Security
• Using Spark to help process an increasing amount of data
– Offloading current applications
– Replacing current applications by Big Data technologies
• Adding additional detection capabilities by Machine Learning
– Machine Learning Introduction
– Use Cases
– High level architecture
– Lessons learned
展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
2 .Apache Spark for Cyber Security in an Enterprise Company Josef Niedermeier, HPE #UnifiedDataAnalytics #SparkAISummit
3 .Agenda • Introduction • Challenges in Cyber Security • Using Spark to help process an increasing amount of data – Offloading current applications – Replacing current applications by Big Data technologies • Adding additional detection capabilities by Machine Learning – Machine Learning Introduction – Use Cases – High level architecture – Lessons learned • Q&A #UnifiedDataAnalytics #SparkAISummit 3
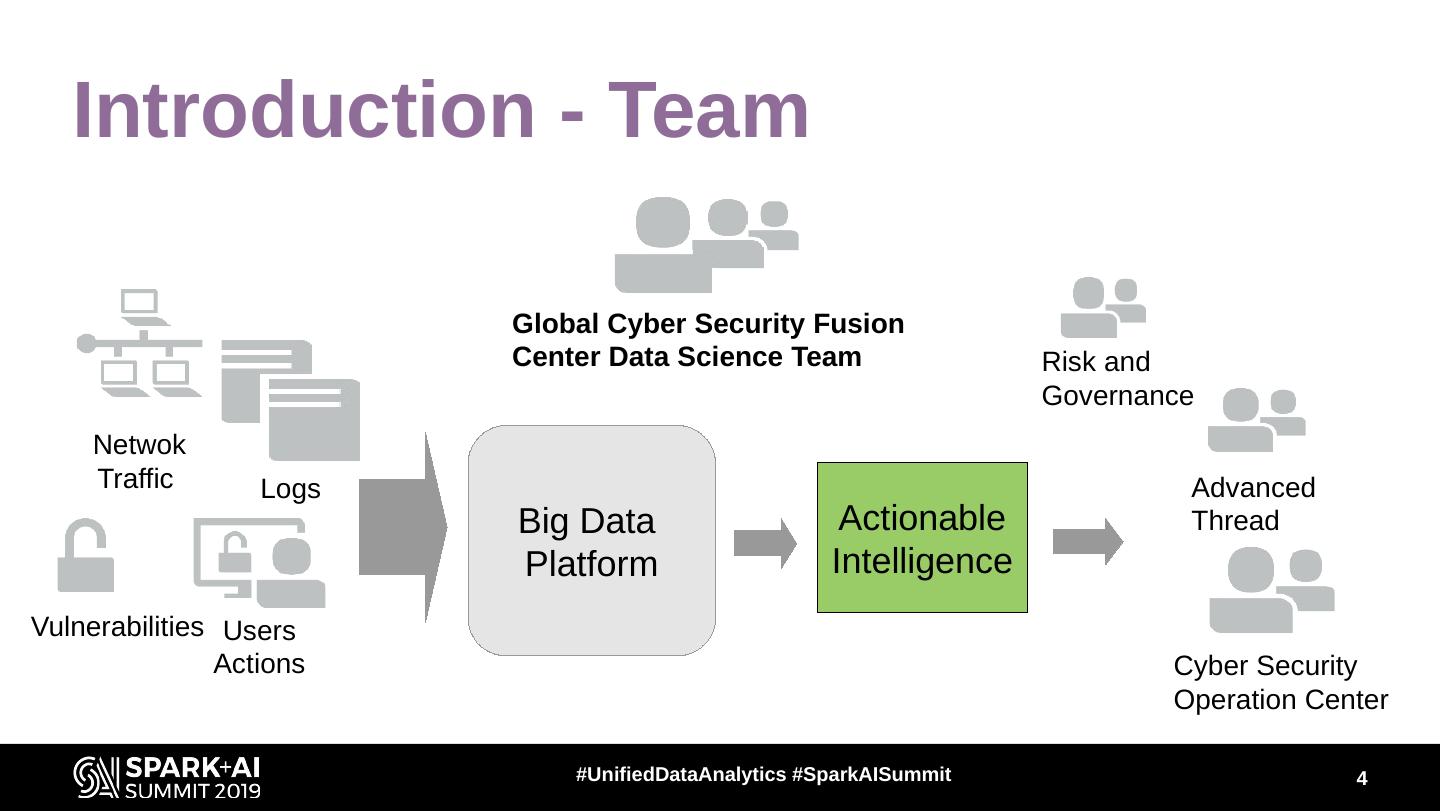
4 . Introduction - Team Global Cyber Security Fusion Center Data Science Team Risk and Governance Netwok Traffic Logs Advanced Big Data Actionable Thread Platform Intelligence Vulnerabilities Users Actions Cyber Security Operation Center #UnifiedDataAnalytics #SparkAISummit 4
5 .Introduction - SIEM SIEM - security information and event management Security Event Manager (SEM): generates alerts based on predefined rules and input events Security Information Manager (SIM): stores relevant cyber security data and allows querying to get context data SIEM Aggregation SEM Alerts Filtering Enriching SIM Query/Context events Security Analysts #UnifiedDataAnalytics #SparkAISummit 5
6 .Challenges in Cyber Security • Scalability and performance – Increasing amount of data: according to Gartner, 25K EPS is enterprise size, but in big organization there are several 100K EPS. – Limited storage for historical data. – Long query response time. – IoT makes situation even worse. • Quickly evolving requirements • Lack of qualified and skilled professionals #UnifiedDataAnalytics #SparkAISummit 6
7 .Using Spark to help process an increasing amount of data #UnifiedDataAnalytics #SparkAISummit
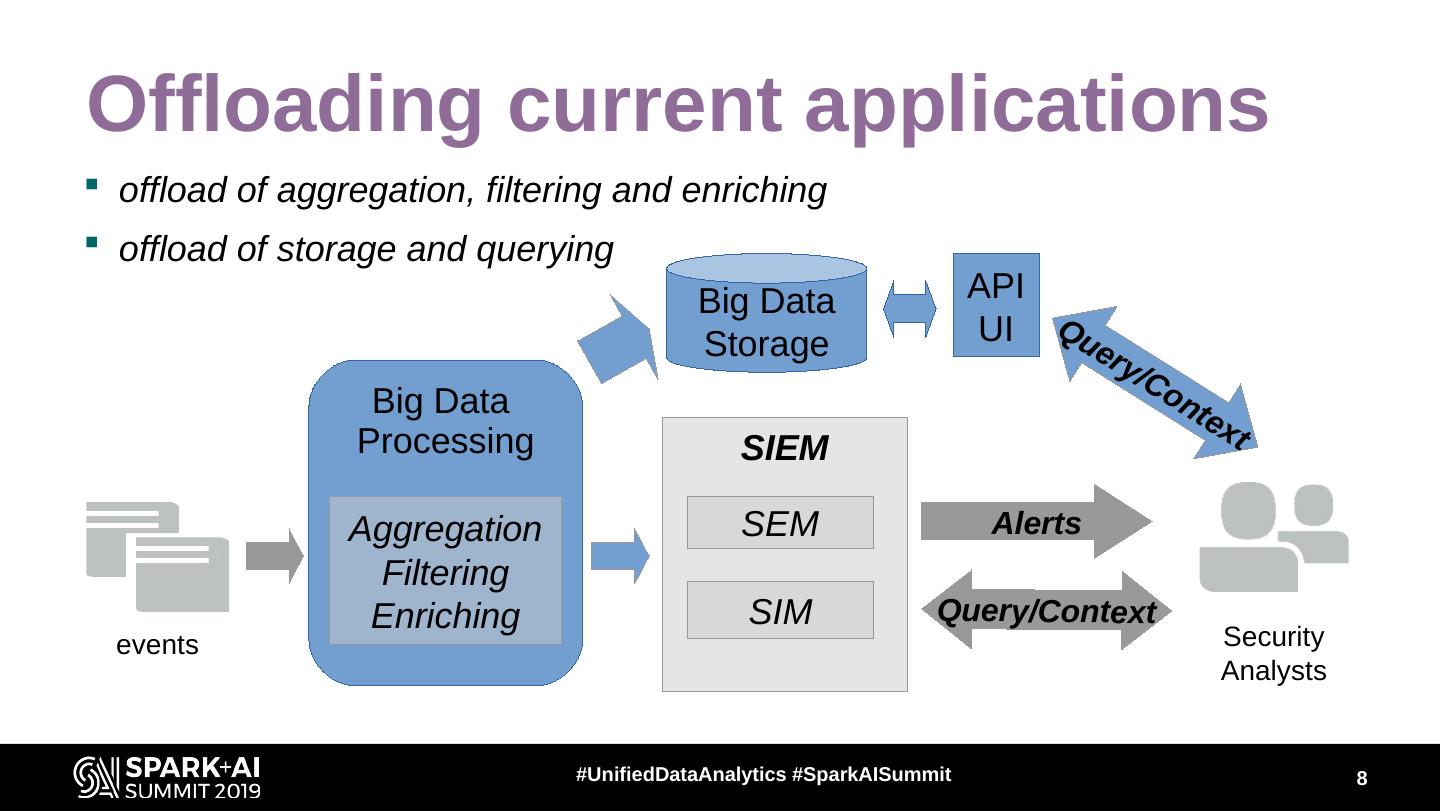
8 .Offloading current applications offload of aggregation, filtering and enriching offload of storage and querying Big Data API Storage UI Que ry /C Big Data on tex Processing SIEM t Aggregation SEM Alerts Filtering Enriching SIM Query/Context events Security Analysts #UnifiedDataAnalytics #SparkAISummit 8
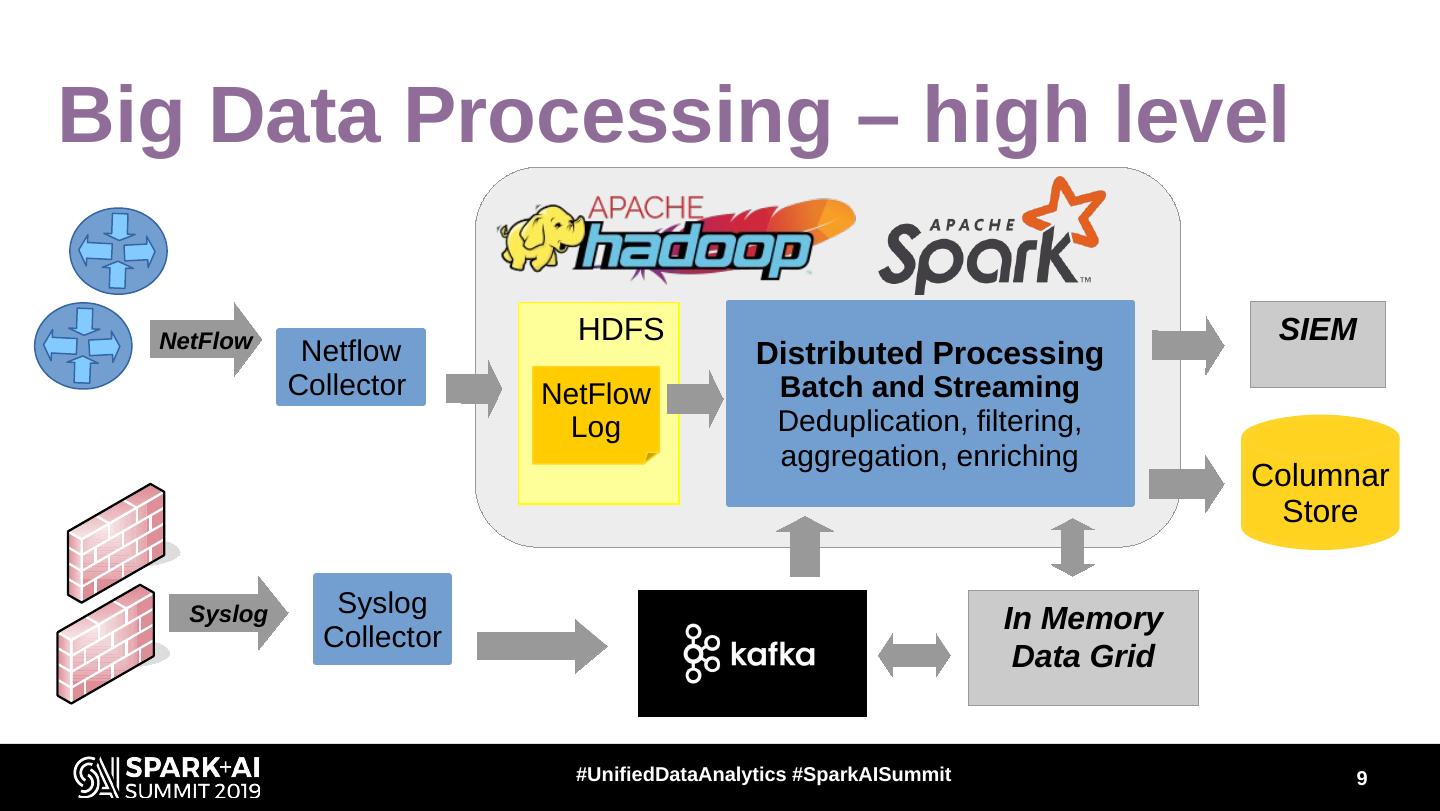
9 .Big Data Processing – high level NetFlow HDFS SIEM Netflow Distributed Processing Collector NetFlow Batch and Streaming Log Deduplication, filtering, aggregation, enriching Columnar Store Syslog Syslog In Memory Collector Data Grid #UnifiedDataAnalytics #SparkAISummit 9
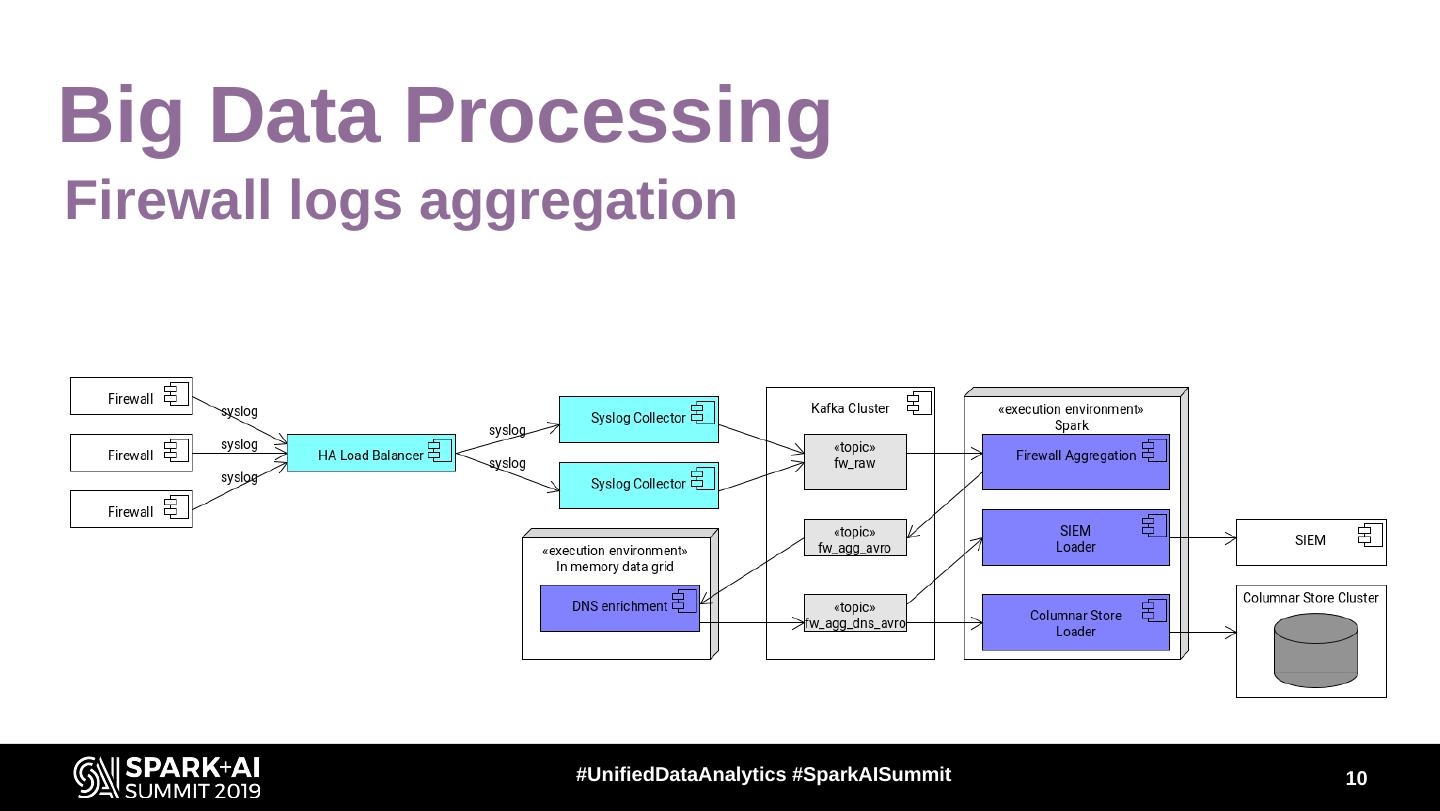
10 .Big Data Processing Firewall logs aggregation #UnifiedDataAnalytics #SparkAISummit 10
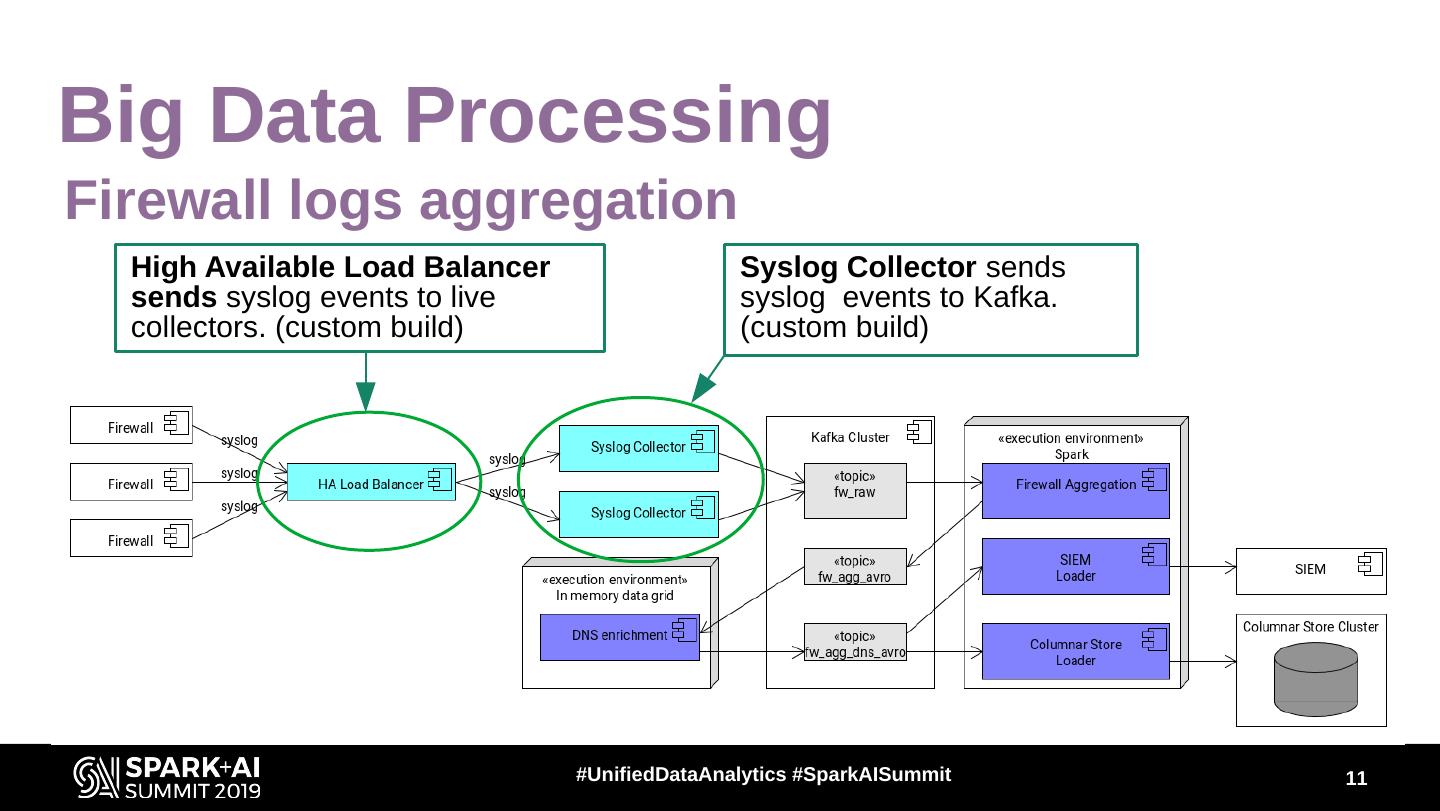
11 .Big Data Processing Firewall logs aggregation High Available Load Balancer Syslog Collector sends sends syslog events to live syslog events to Kafka. collectors. (custom build) (custom build) #UnifiedDataAnalytics #SparkAISummit 11
12 .Big Data Processing Firewall logs aggregation Firewall Aggregation (5 sec. streaming job) aggregates events. (using DStream.reduceByKey) DNS enrichment adds DNS names using DHCP and DNS logs. #UnifiedDataAnalytics #SparkAISummit 12
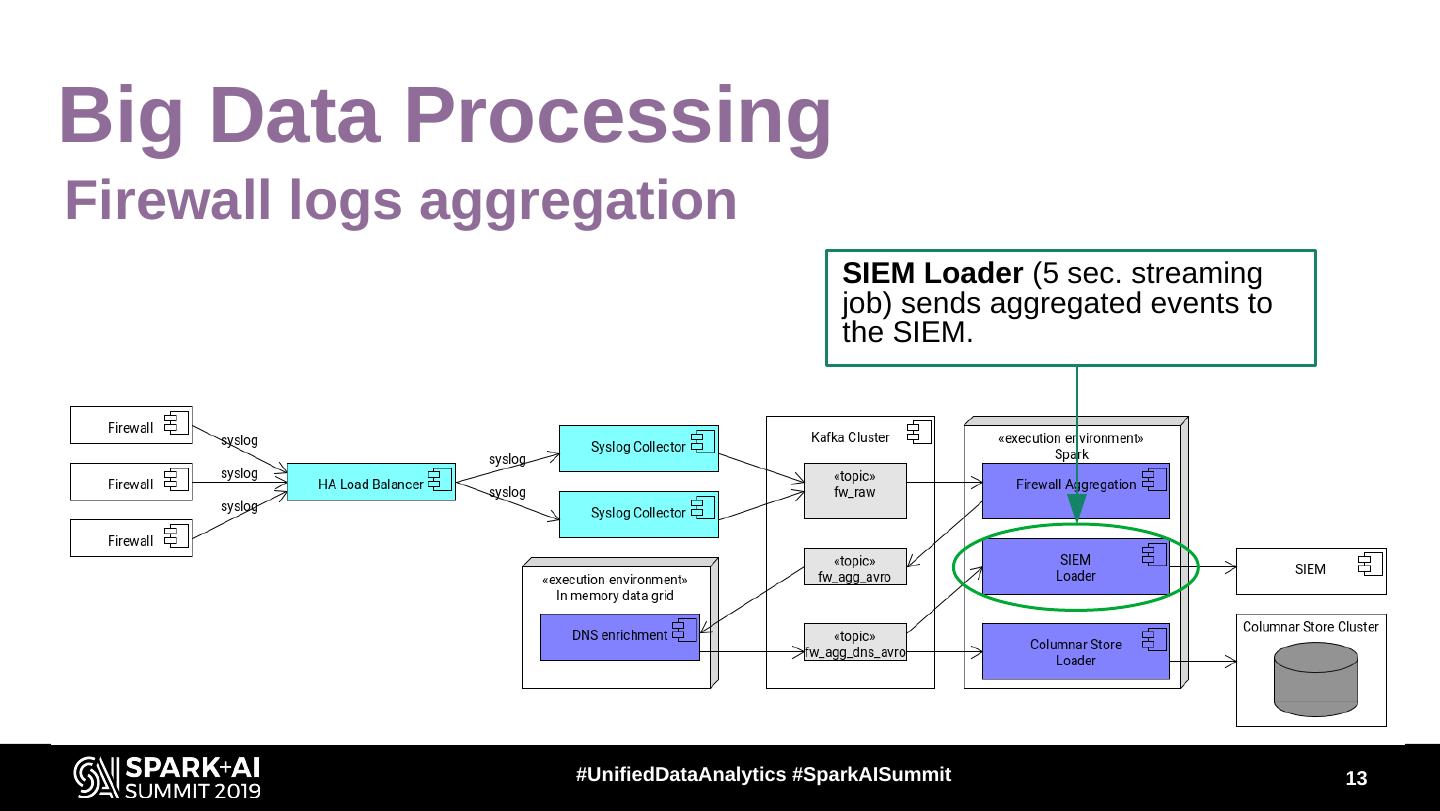
13 .Big Data Processing Firewall logs aggregation SIEM Loader (5 sec. streaming job) sends aggregated events to the SIEM. #UnifiedDataAnalytics #SparkAISummit 13
14 .Big Data Processing Firewall logs aggregation Columnar Store Loader (5 sec. Columnar Store streaming job) loads aggregated offloads storage events to the Columnar Store and querying #UnifiedDataAnalytics #SparkAISummit 14
15 .Big Data Processing Firewall logs aggregation ● Environment ● Inputs 65,000 EPS and 32,000 EPS 5 sec micro-batches (Spark Streaming) ● 24 executors x 11 cores each on non-dedicated, heavily utilized Hortonworks cluster ● Results ● Number of the events is reduced to half ● Query times are reduced to seconds #UnifiedDataAnalytics #SparkAISummit 15
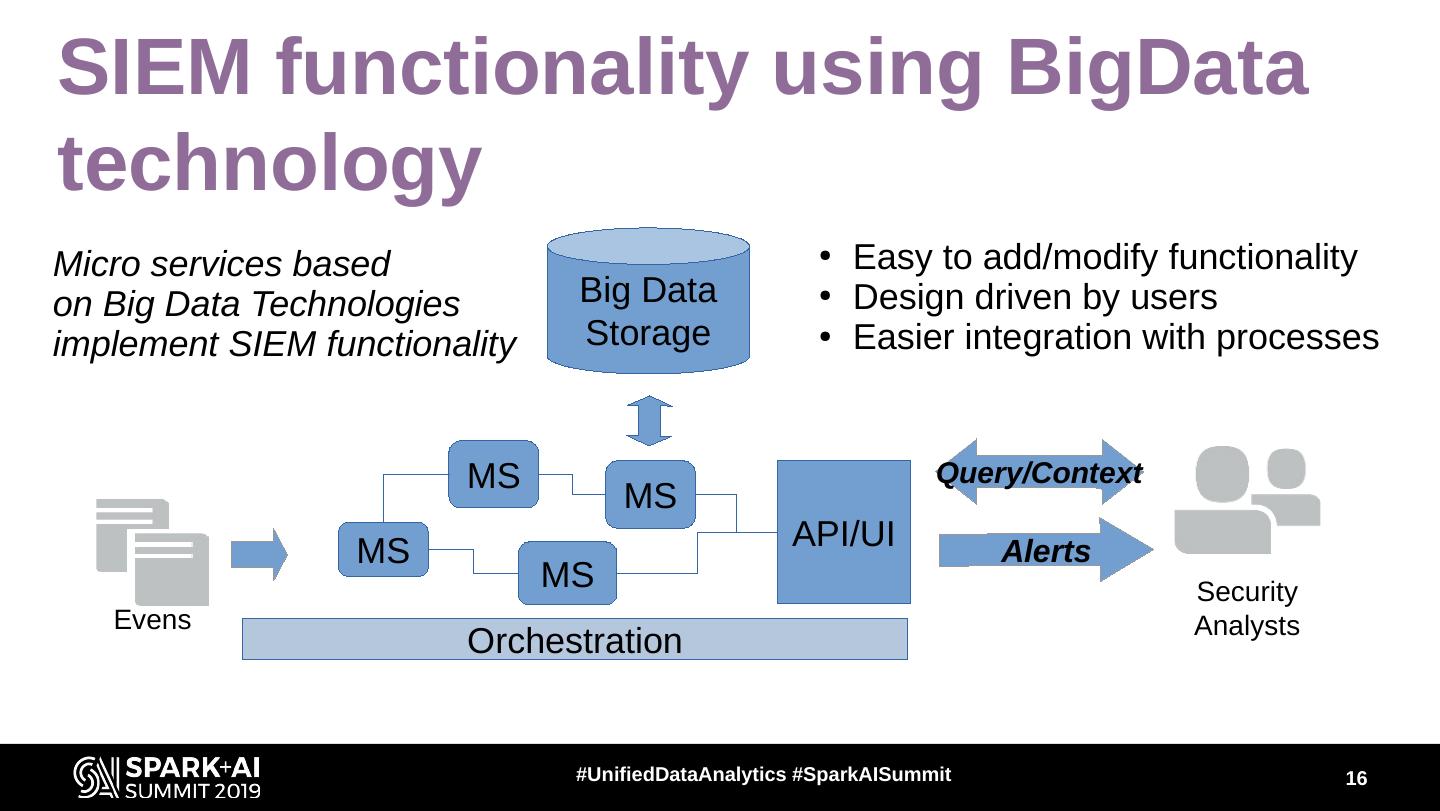
16 .SIEM functionality using BigData technology Micro services based ● Easy to add/modify functionality on Big Data Technologies Big Data ● Design driven by users implement SIEM functionality Storage ● Easier integration with processes MS Query/Context MS MS API/UI Alerts MS Security Evens Analysts Orchestration #UnifiedDataAnalytics #SparkAISummit 16
17 .SIEM functionality using BigData technology Rule development and testing similar to software testing Similar process and tools (Jira, Git etc) Fast Forward Testing Rule Unit Production With Development Testing Deployment Production Sample Tools Spark, In Memory Data Grid Preliminary Results 15 - 20 minutes to test a rule on 24h data ( 2B events) (24 executors) linearly scalable #UnifiedDataAnalytics #SparkAISummit 17
18 .Adding additional detection capabilities by Machine Learning #UnifiedDataAnalytics #SparkAISummit
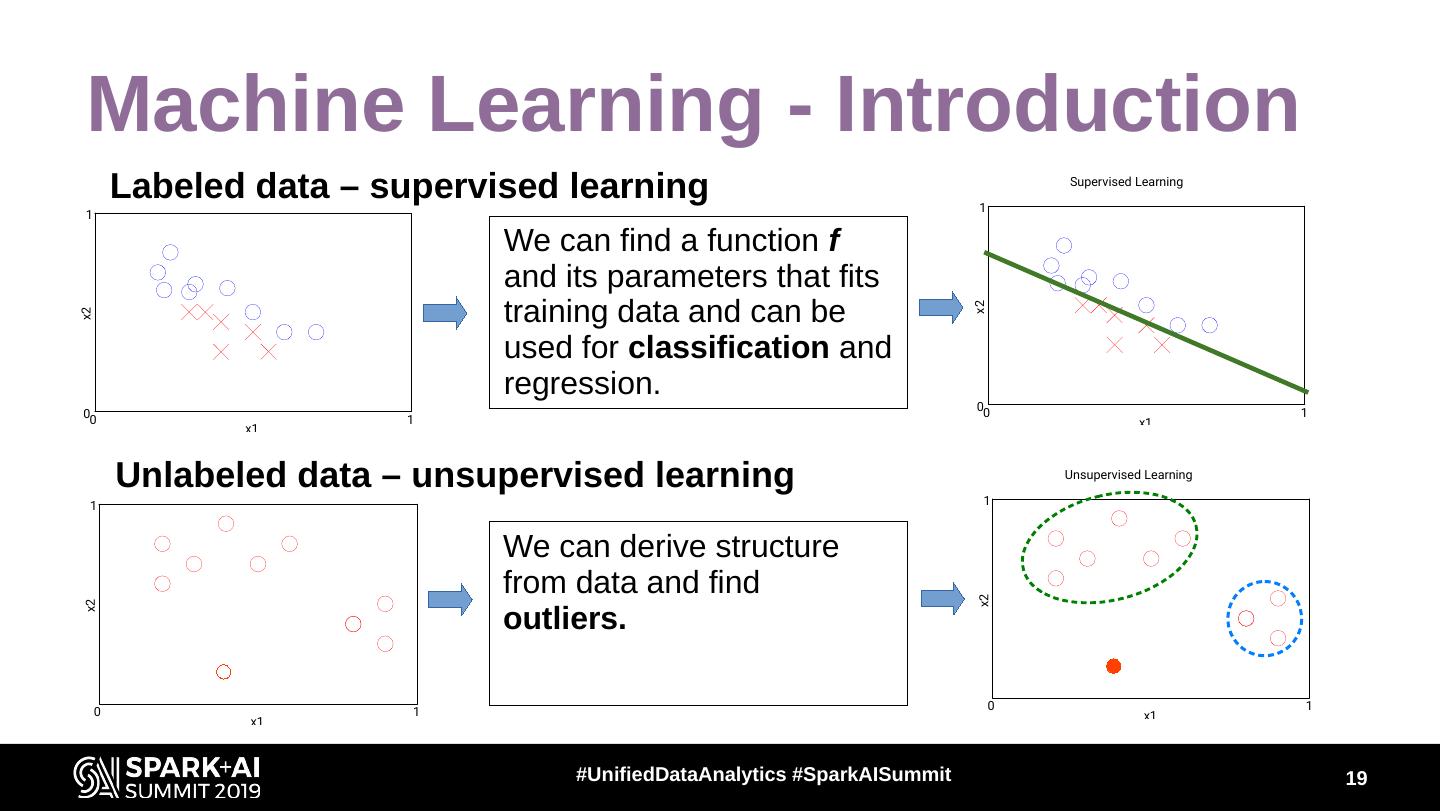
19 . Machine Learning - Introduction Labeled data – supervised learning Supervised Learning 1 Supervised Learning 1 We can find a function f and its parameters that fits training data and can be x2 x2 used for classification and regression. 00 1 00 1 x1 x1 Unlabeled data – unsupervised learning Unsupervised Learning 1 Unsupervised Learning 1 We can derive structure from data and find x2 x2 outliers. 0 1 0 1 x1 x1 #UnifiedDataAnalytics #SparkAISummit 19
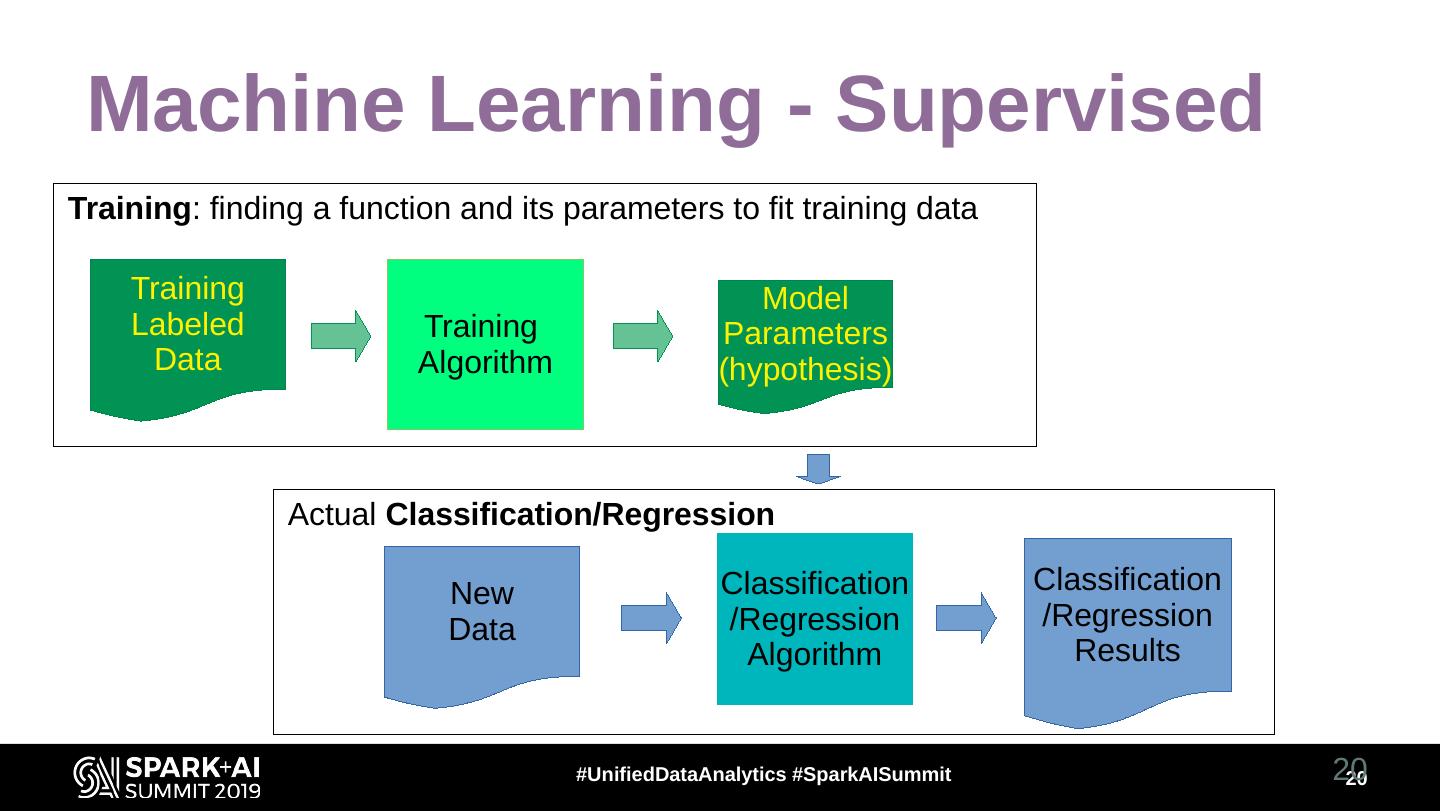
20 . Machine Learning - Supervised Training: finding a function and its parameters to fit training data Training Model Labeled Training Parameters Data Algorithm (hypothesis) Actual Classification/Regression New Classification Classification Data /Regression /Regression Algorithm Results #UnifiedDataAnalytics #SparkAISummit 20 20
21 . Machine Learning – Example Training Labeled Data Supervised Learning ● f: if x2 > (p0 + p1 * x1) then O else X 1 ● finding parameters to minimize # of wrongly classified data points (cost function) x2 Supervised Learning Parameters 0 0 1 1 x1 p0 p1 Line Cost 0.6 0 3 x2 0.9 -0.9 2 0.8 - 0.7 0 00 1 x1 #UnifiedDataAnalytics #SparkAISummit 21 21
22 .Machine Learning - example New data Classified new data classification if x2 > (0.8 – 0.7 * x1) then O else X #UnifiedDataAnalytics #SparkAISummit 22 22
23 .Machine Learning – Terminology True Positive Precision= =Proportion of selected items that are relevant True Positive+ False Positive True Positive Recall= =Proportion of relevant items that was selected True Positive + False Negative Source: https://en.wikipedia.org/wiki/Precision_and_recall #UnifiedDataAnalytics #SparkAISummit 23 23
24 .Machine Learning – Challenges ● Too many false positives ● Precision ~ 99% can be too low ● Data cleanliness ● Wrong time on a device can be detected as anomaly ● Missing labeled data ● Hard to evaluate recall #UnifiedDataAnalytics #SparkAISummit 24
25 . Machine Learning – Challenges Is 99% precision good enough? ● A ML algorithm for detecting a specific malware infection: ● precision = 99% ● recall = 99%. ● The infection is relatively rare: 1 % of computers are infected. What is probability that the computer is really infected if it is classified as infected? (99% or 91% or 50% or 1%) #UnifiedDataAnalytics #SparkAISummit 25 25
26 .Machine Learning – Challenges Suppose there are 10 000 computers: ● 100 are infected ● 99 infected are correctly classified as infected (true positive) ● 1 infected is classified as not infected (false negative) ● 9,900 clean ● 99 are classified incorrectly as infected (false positive) ● 9,801 are correctly classified as not infected (true negative) ● 99 true positivo and 99 false positive = 198 computers classified as infected but only 99 are really infected so probability that the computer classified as infected is really infected is 50%. P(classified as infected given infected )∗P(infected ) 0.99∗0.01 Using Bayes' theorem: P(infected given classified as infected )= P(classified as infected ) = (0.99∗0.01+ 0.01∗0.99) =0.5 #UnifiedDataAnalytics #SparkAISummit 26 26
27 .Machine Learning – Challenges Classifier with precision and recall 99 % infected computers [%] really infected/classified as infected [%] 1.00% 50% 0.10% 9% 0.01% 1% ● Usually a human should make final assessment. ● Reasonable use cases: ● High ratio of “infection” ● Limited (selected) data #UnifiedDataAnalytics #SparkAISummit 27 27
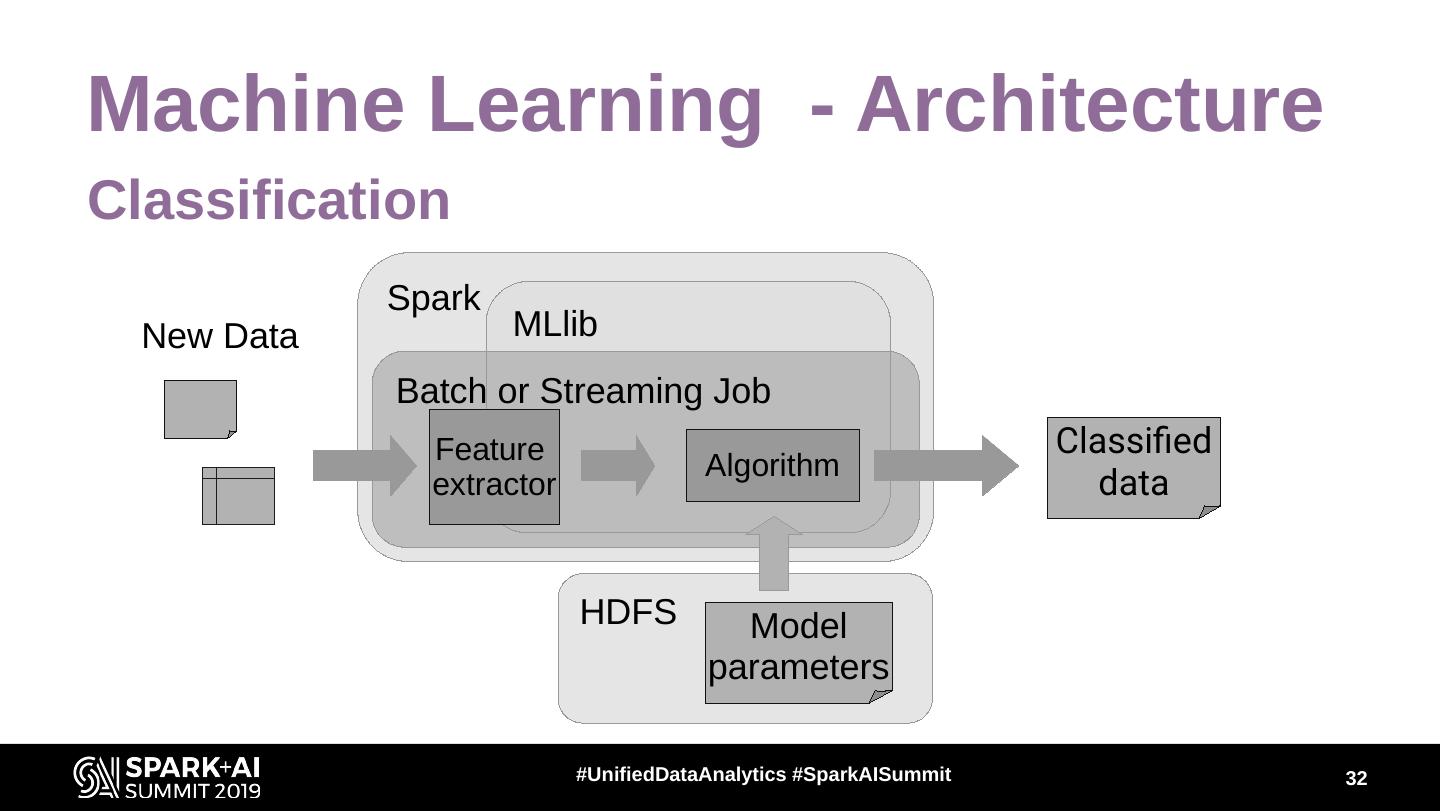
28 .Machine Learning and Spark ● MLlib is Apache Spark's scalable machine learning library. ● ML algorithms ● ML workflow utilities (data → feature, evaluation, persistence, ...) ● Several deep learning frameworks ● Databricks – spark-deep-learning, Deep Learning Pipelines for Apache Spark ● Yahoo -TensorFlowOnSpark ● Intel – BigDL ● ... #UnifiedDataAnalytics #SparkAISummit 28
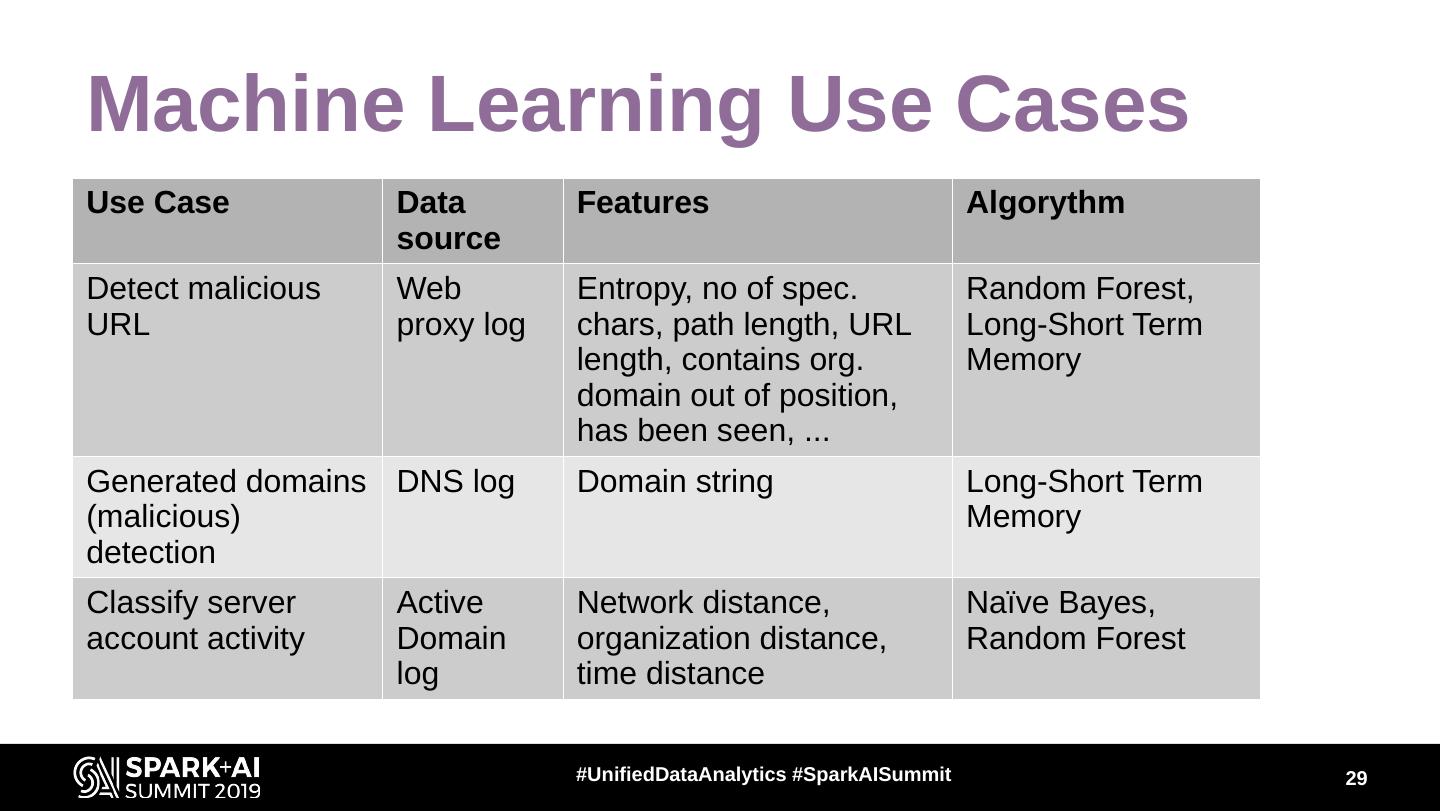
29 .Machine Learning Use Cases Use Case Data Features Algorythm source Detect malicious Web Entropy, no of spec. Random Forest, URL proxy log chars, path length, URL Long-Short Term length, contains org. Memory domain out of position, has been seen, ... Generated domains DNS log Domain string Long-Short Term (malicious) Memory detection Classify server Active Network distance, Naïve Bayes, account activity Domain organization distance, Random Forest log time distance #UnifiedDataAnalytics #SparkAISummit 29
3秒后跳转登录页面
去登陆

