





























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Apache Spark Core – Practical Optimization
Properly shaping partitions and your jobs to enable powerful optimizations, eliminate skew and maximize cluster utilization. We will explore various Spark Partition shaping methods along with several optimization strategies including join optimizations, aggregate optimizations, salting and multi-dimensional parallelism.
展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
2 .Spark Core – Proper Optimization Daniel Tomes, Databricks #UnifiedAnalytics #SparkAISummit
3 .TEMPORARY – NOTE FOR REVIEW I gave this talk at Summit US 2019. I will be adding supplemental slides for SparkUI deep dive and delta optimization depending on how many people in the crowd has seen this presentation on YT. If none, I will go with same presentation, if many, I will do the first half as review and second half with new info. New info to come soon. #UnifiedAnalytics #SparkAISummit 3
4 .Talking Points • Spark Hierarchy • The Spark UI • Understanding Partitions • Common Opportunities For Optimization #UnifiedAnalytics #SparkAISummit 4
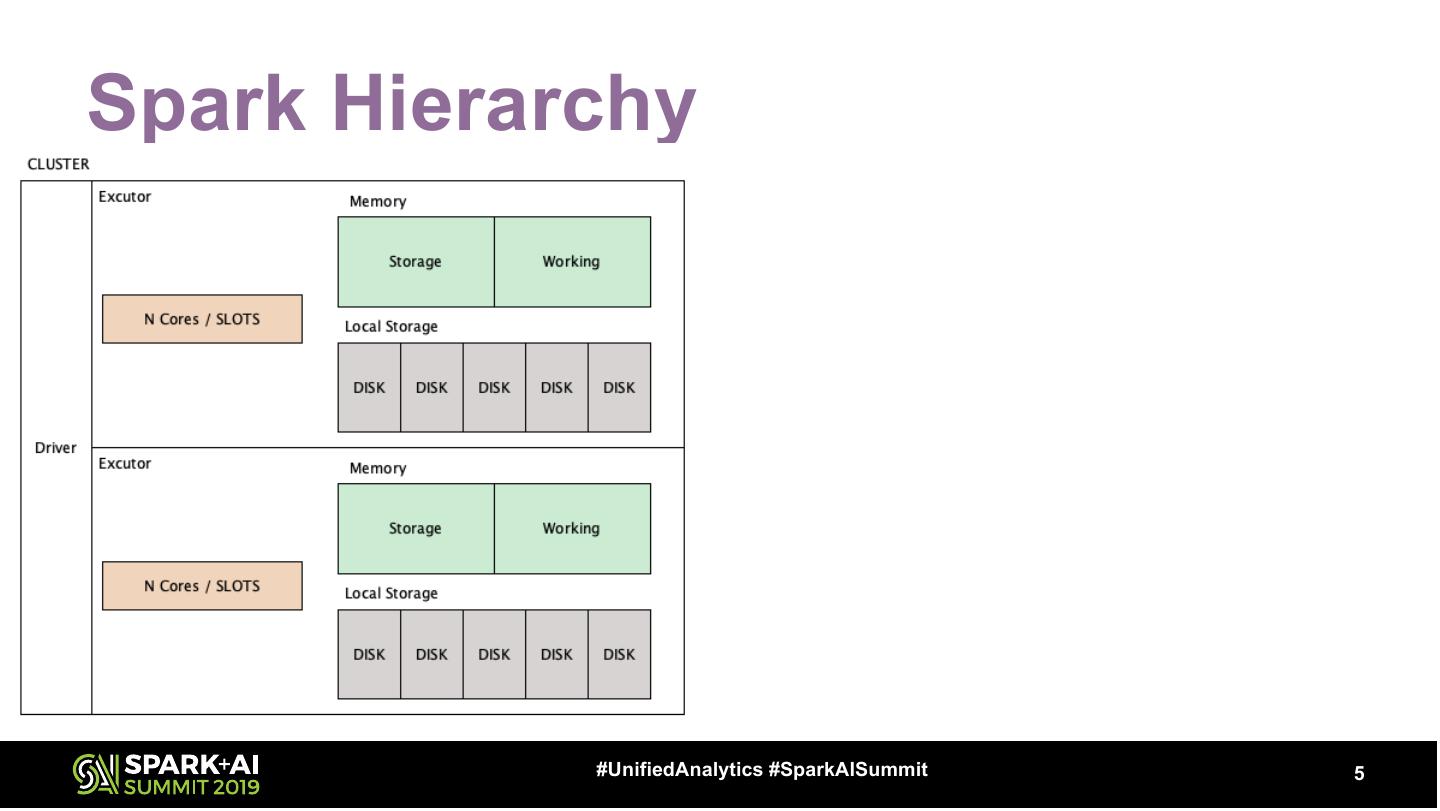
5 .Spark Hierarchy #UnifiedAnalytics #SparkAISummit 5
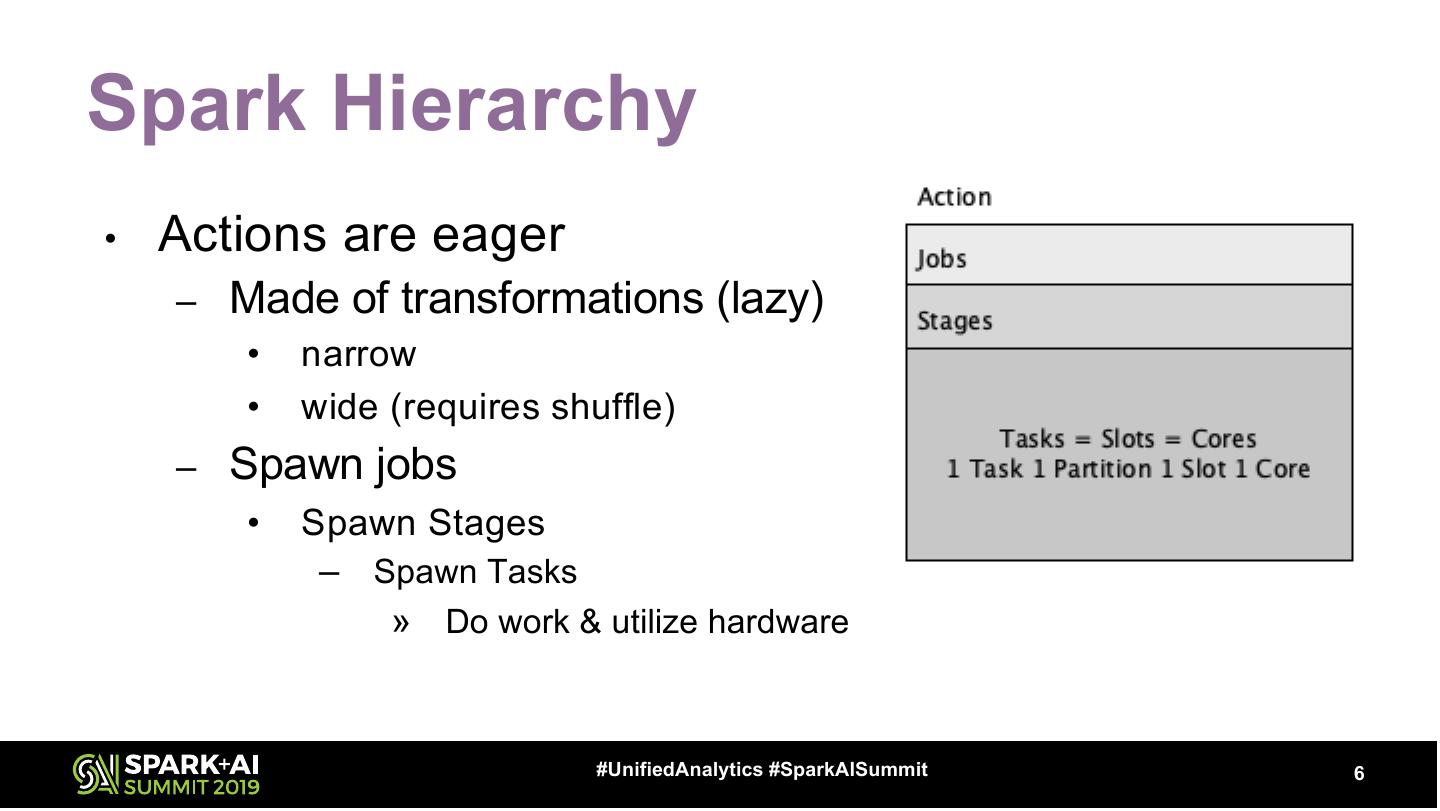
6 .Spark Hierarchy • Actions are eager – Made of transformations (lazy) • narrow • wide (requires shuffle) – Spawn jobs • Spawn Stages – Spawn Tasks » Do work & utilize hardware #UnifiedAnalytics #SparkAISummit 6
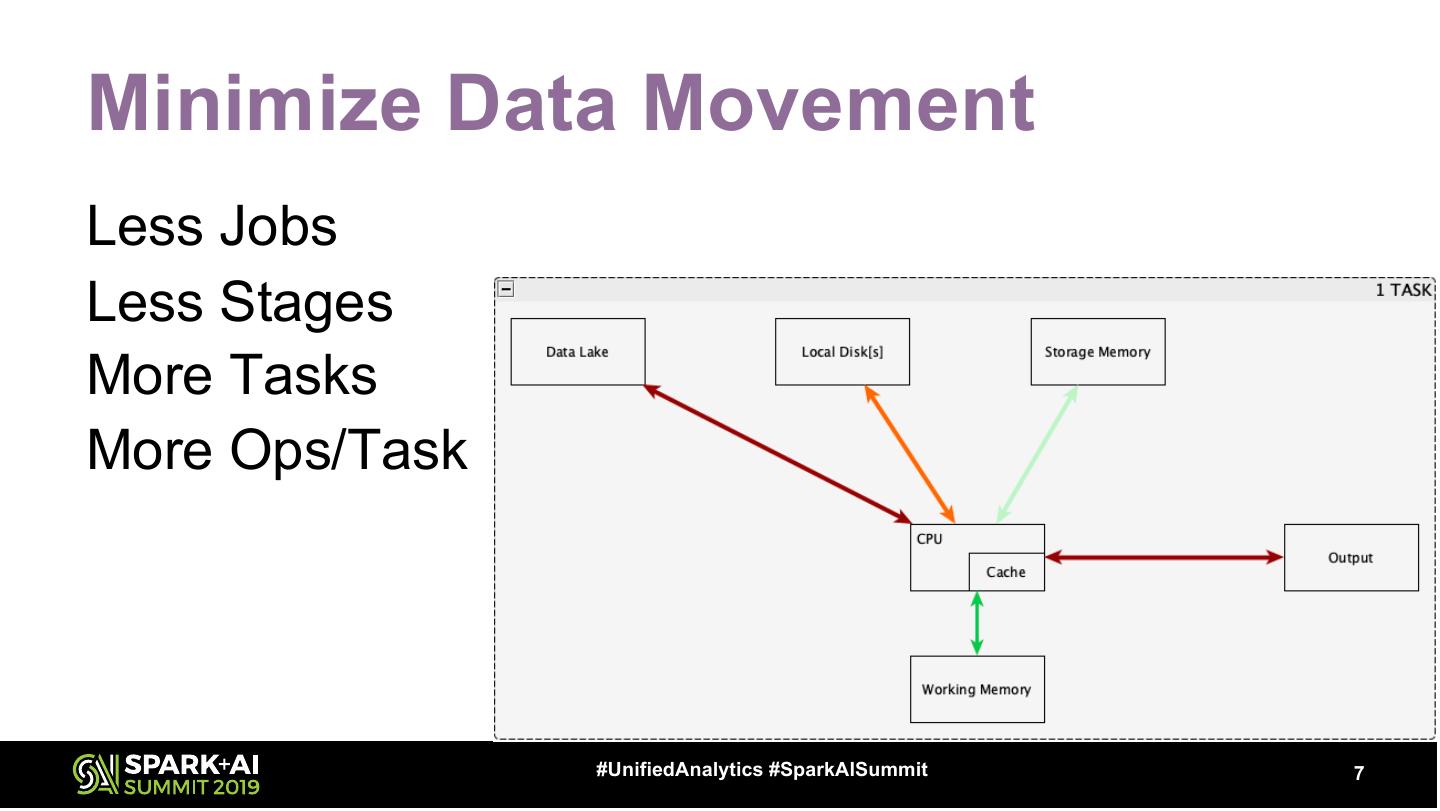
7 .Minimize Data Movement Less Jobs Less Stages More Tasks More Ops/Task #UnifiedAnalytics #SparkAISummit 7
8 .Navigating The Spark UI DEMO #UnifiedAnalytics #SparkAISummit 8
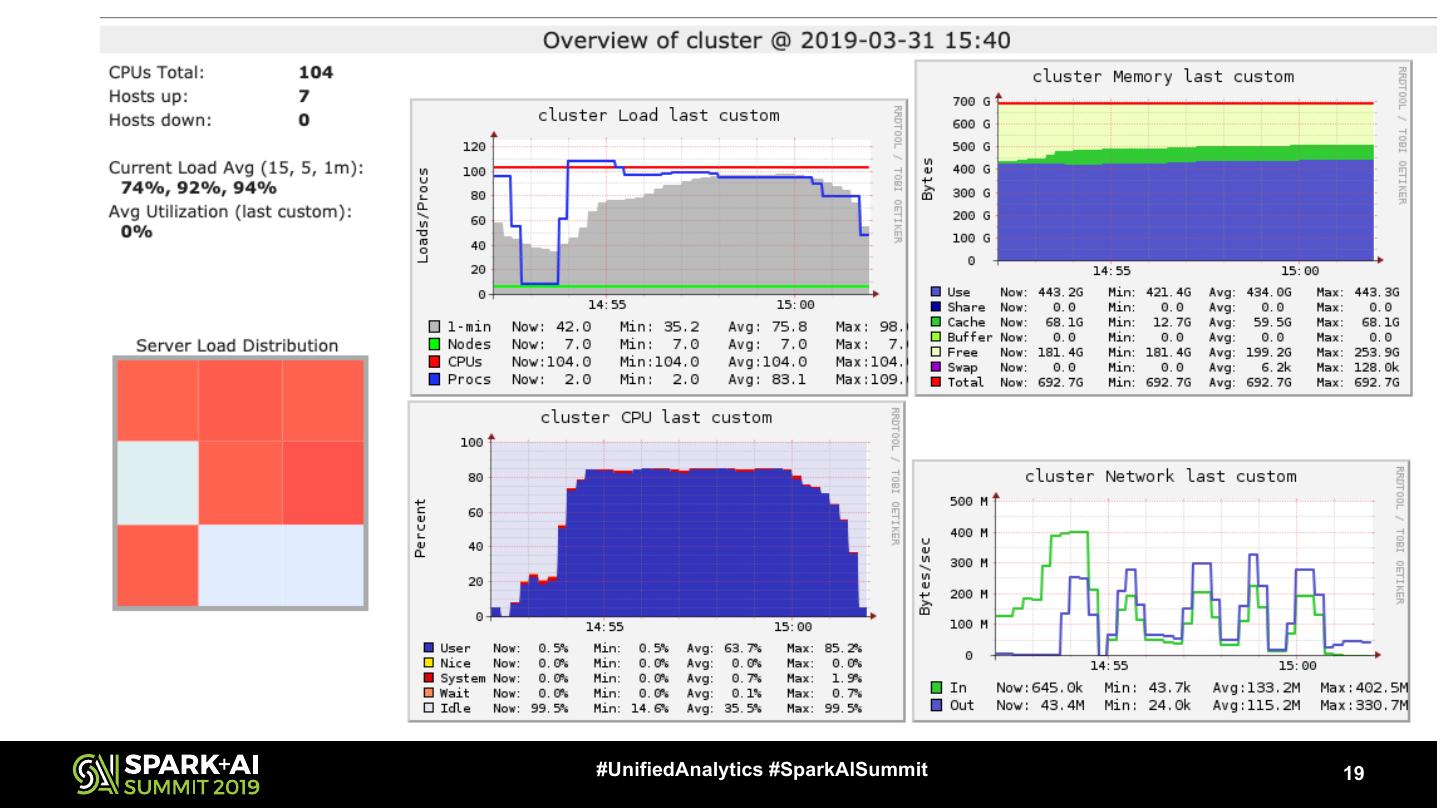
9 .Get A Baseline Goal • Is your action efficient? – Spills? • CPU Utilization – GANGLIA / YARN / Etc – Tails #UnifiedAnalytics #SparkAISummit 9
10 .Understand Your Hardware • Core Count & Speed • Memory Per Core (Working & Storage) • Local Disk Type, Count, Size, & Speed • Network Speed & Topology • Data Lake Properties (rate limits) • Cost / Core / Hour – Financial For Cloud – Opportunity for Shared & On Prem #UnifiedAnalytics #SparkAISummit 10
11 .Minimize Data Scans (Lazy Load) • Data Skipping – HIVE Partitions – Bucketing • Only Experts – Nearly Impossible to Maintain – Databricks Delta Z-Ordering • What is It • How To Do It #UnifiedAnalytics #SparkAISummit 11
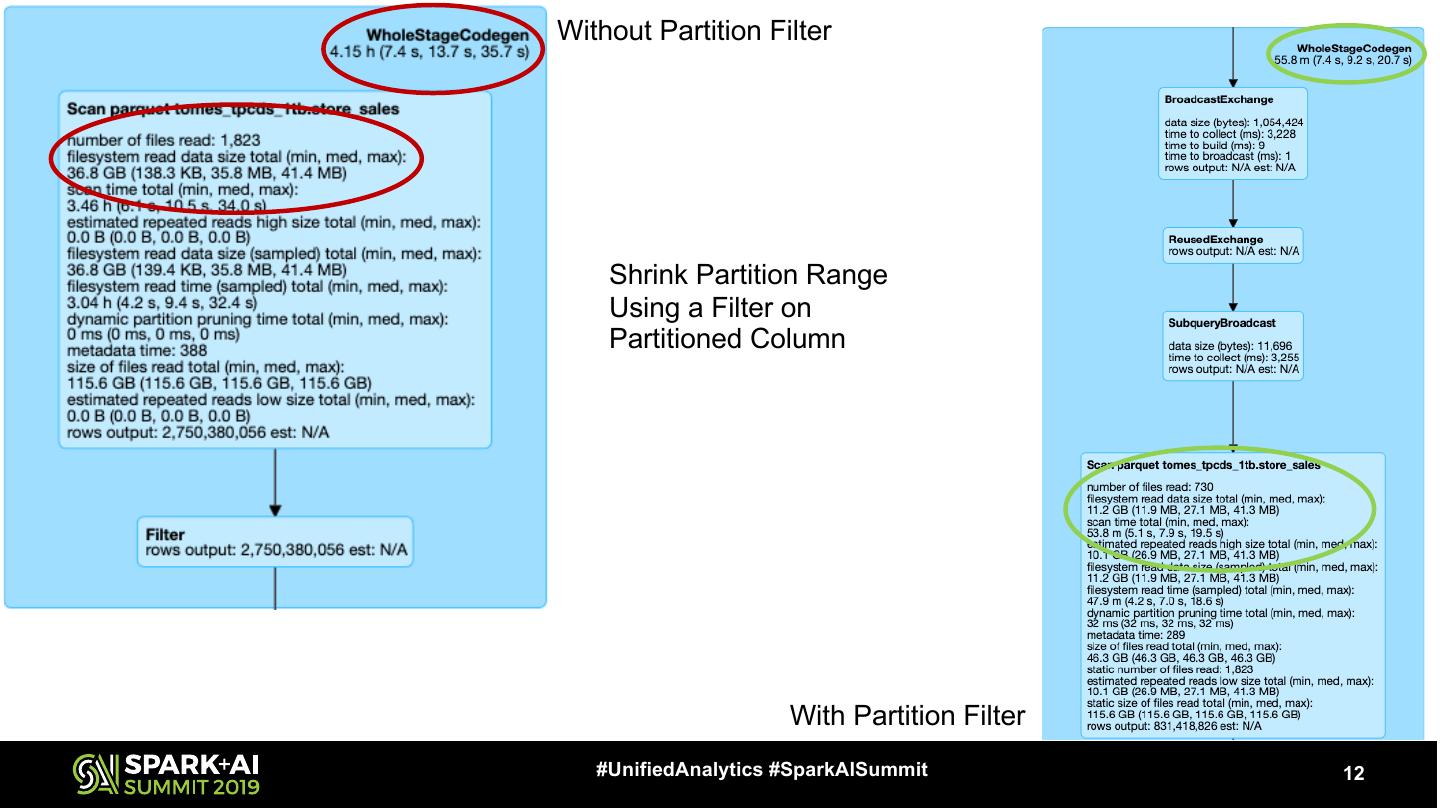
12 .Without Partition Filter Shrink Partition Range Using a Filter on Partitioned Column With Partition Filter #UnifiedAnalytics #SparkAISummit 12
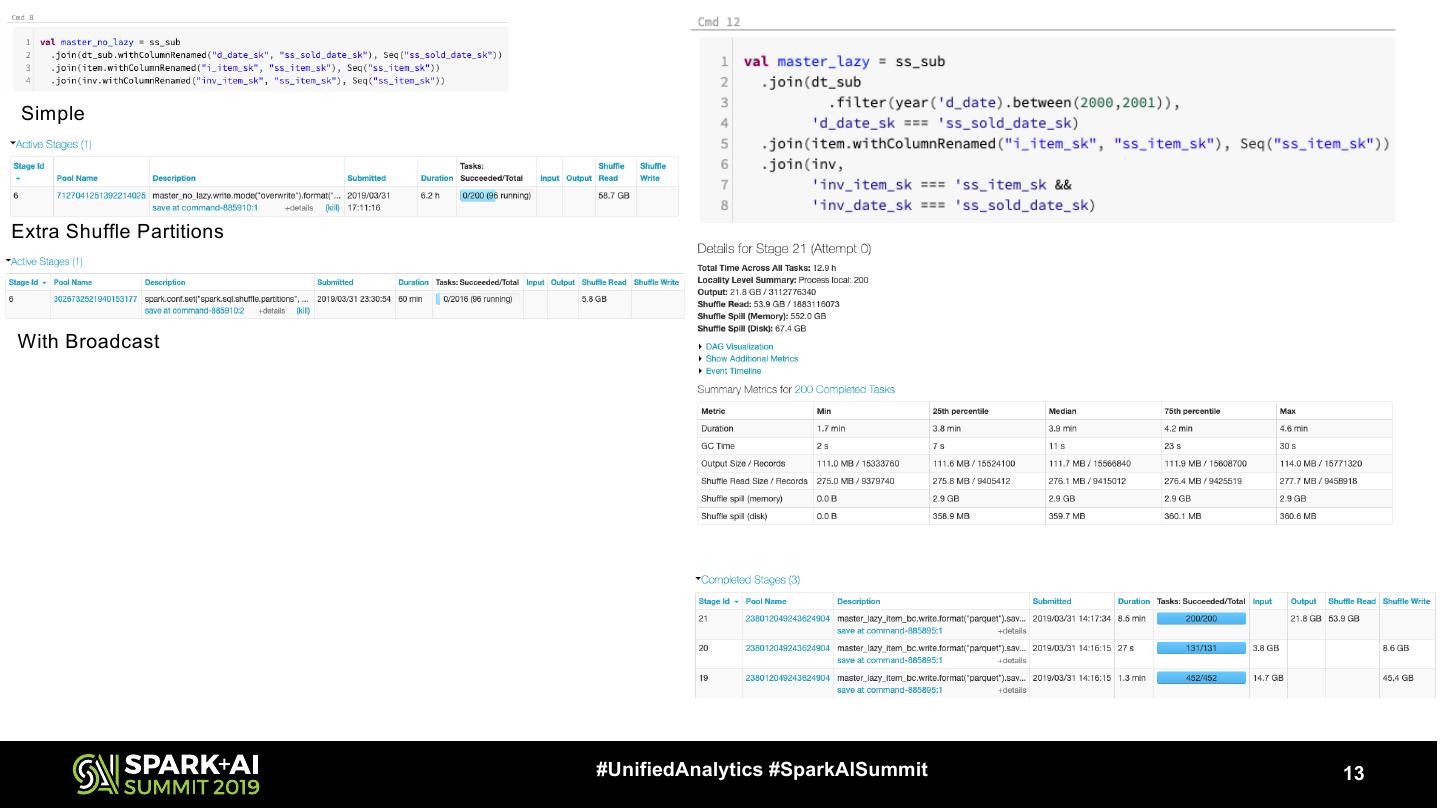
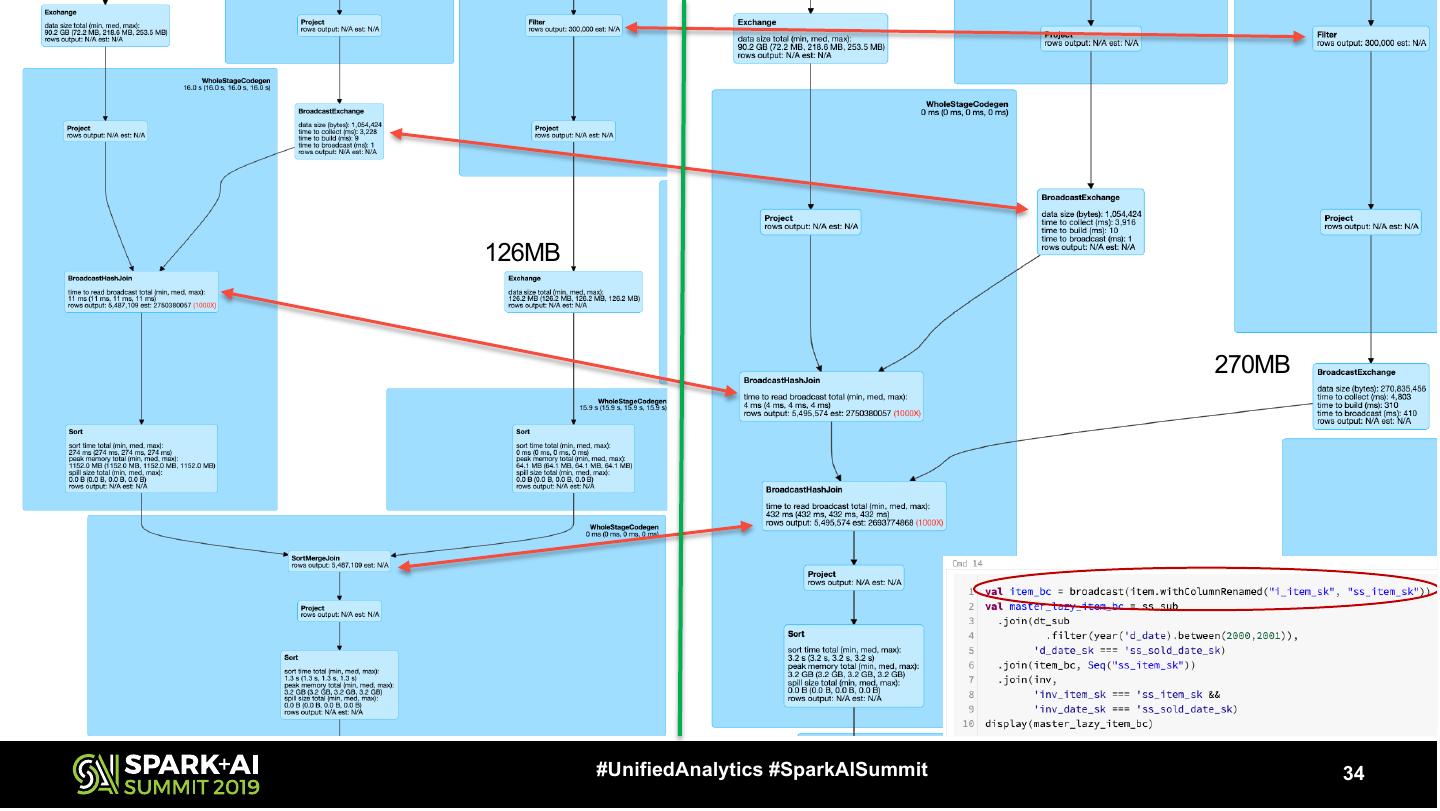
13 . Simple Extra Shuffle Partitions With Broadcast #UnifiedAnalytics #SparkAISummit 13
14 .Partitions – Definition Each of a number of portions into which some operating systems divide memory or storage HIVE PARTITION == SPARK PARTITION #UnifiedAnalytics #SparkAISummit 14
15 .Spark Partitions – Types • Input – Controls • spark.default.parallelism (don’t use) • spark.sql.files.maxPartitionBytes (mutable) – assuming source has sufficient partitions • Shuffle – Control = partition count • spark.sql.shuffle.partitions • Output – Control = stage partition count split by max records per file • Coalesce(n) to shrink • Repartition(n) to increase and/or balance (shuffle) • df.write.option(“maxRecordsPerFile”, N) #UnifiedAnalytics #SparkAISummit 15
16 .Partitions – Right Sizing – Shuffle – Master Equation • Largest Shuffle Stage – Target Size <= 200 MB/partition • Partition Count = Stage Input Data / Target Size – Solve for Partition Count EXAMPLE Shuffle Stage Input = 210GB x = 210000MB / 200MB = 1050 spark.conf.set(“spark.sql.shuffle.partitions”, 1050) BUT -> If cluster has 2000 cores spark.conf.set(“spark.sql.shuffle.partitions”, 2000) #UnifiedAnalytics #SparkAISummit 16
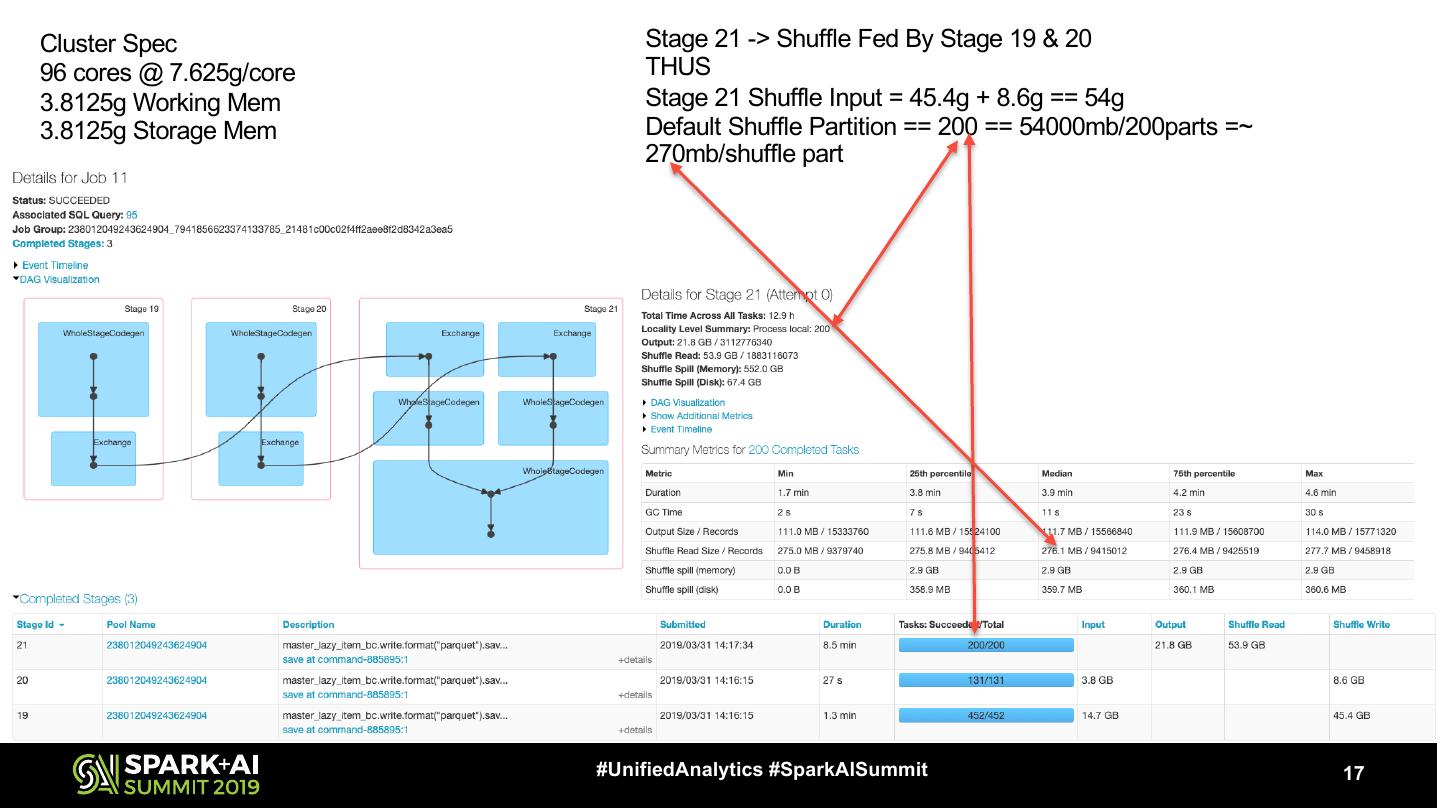
17 .Cluster Spec Stage 21 -> Shuffle Fed By Stage 19 & 20 96 cores @ 7.625g/core THUS 3.8125g Working Mem Stage 21 Shuffle Input = 45.4g + 8.6g == 54g 3.8125g Storage Mem Default Shuffle Partition == 200 == 54000mb/200parts =~ 270mb/shuffle part #UnifiedAnalytics #SparkAISummit 17
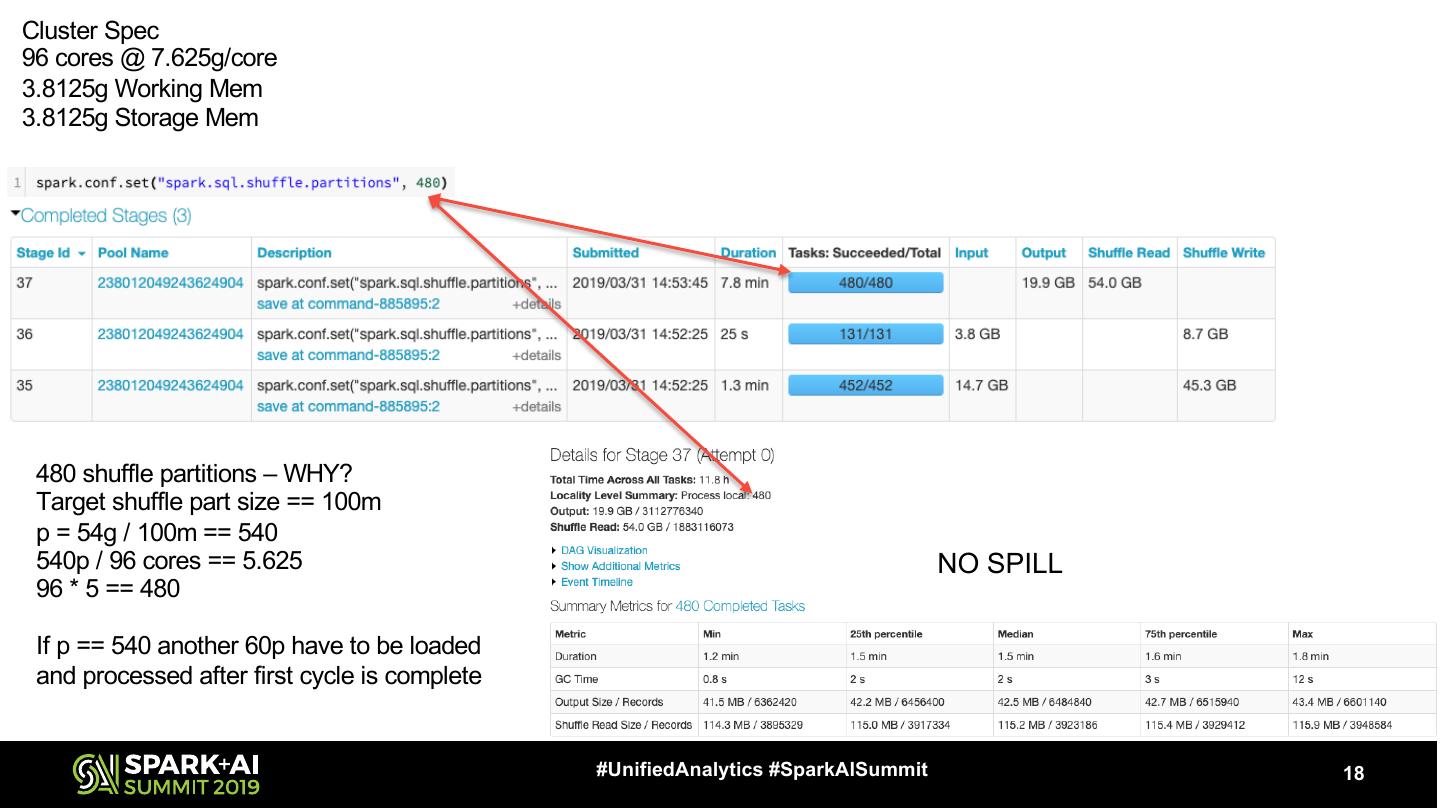
18 .Cluster Spec 96 cores @ 7.625g/core 3.8125g Working Mem 3.8125g Storage Mem 480 shuffle partitions – WHY? Target shuffle part size == 100m p = 54g / 100m == 540 540p / 96 cores == 5.625 NO SPILL 96 * 5 == 480 If p == 540 another 60p have to be loaded and processed after first cycle is complete #UnifiedAnalytics #SparkAISummit 18
19 .#UnifiedAnalytics #SparkAISummit 19
20 .Partitions – Right Sizing (input) • Use Spark Defaults (128MB) unless… – Source Structure is not optimal (upstream) – Remove Spills – Increase Parallelism – Heavily Nested/Repetitive Data – UDFs Get DF Partitions df.rdd.partitions.size #UnifiedAnalytics #SparkAISummit 20
21 . Parquet Consideration: Source must have sufficient row blocks sc.hadoopConfiguration.setInt("parquet.block.size", 1024 * 1024 * 16) df.write… FIX THIS SLIDE 14.7g/452part == 32.3mb/part spark.sql.files.maxPartitionBytes == 128MB #UnifiedAnalytics #SparkAISummit 21
22 .Partitions – Right Sizing (output) • Write Once -> Read Many – More Time to Write but Faster to Read • Perfect writes limit parallelism – Compactions (minor & major) Write Data Size = 14.7GB Desired File Size = 1500MB Max stage parallelism = 10 96 – 10 == 86 cores idle during write #UnifiedAnalytics #SparkAISummit 22
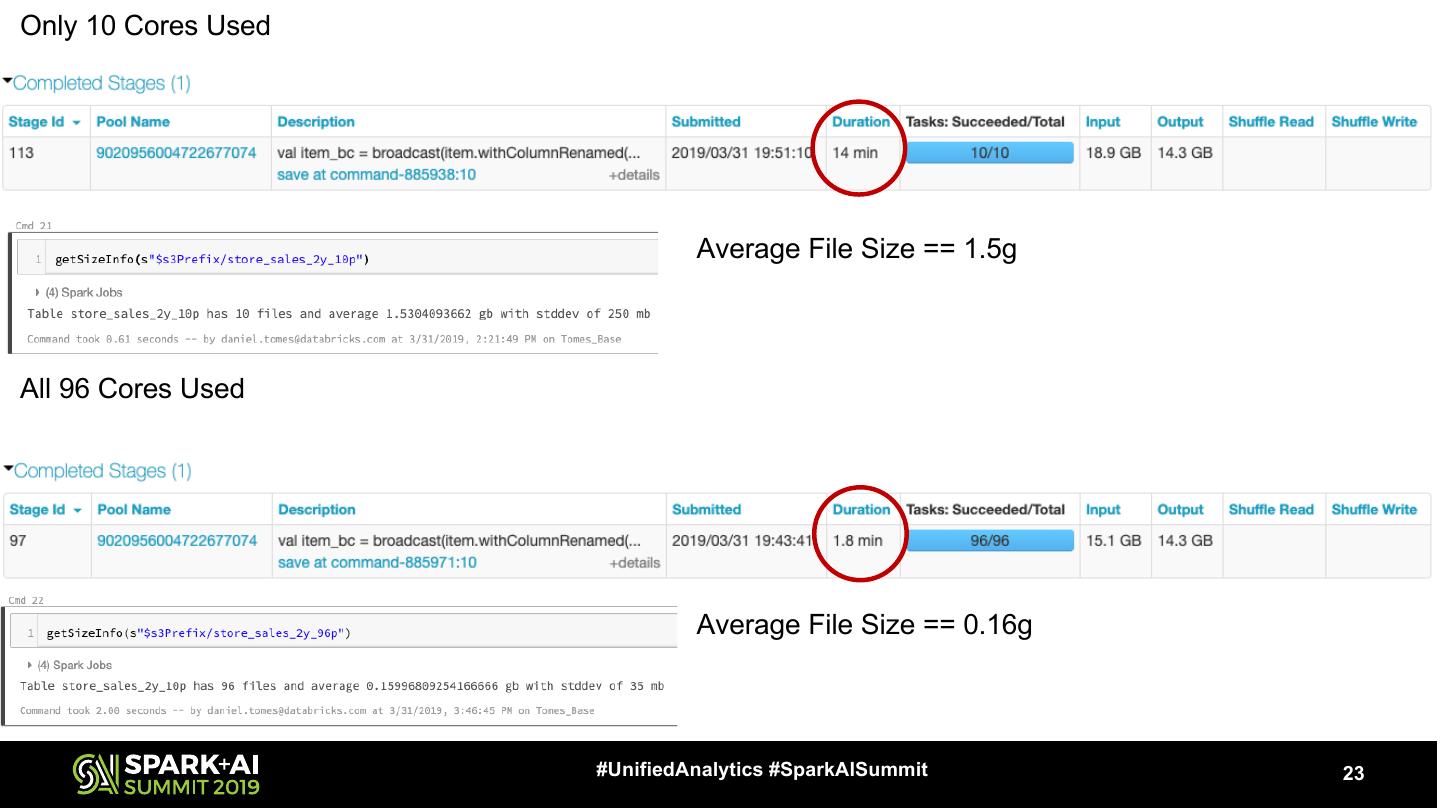
23 .Only 10 Cores Used Average File Size == 1.5g All 96 Cores Used Average File Size == 0.16g #UnifiedAnalytics #SparkAISummit 23
24 .Partitions – Why So Serious? • Avoid The Spill – If (Partition Size > Working Memory Size) Spill – If (Storage Memory Available) Spill to Memory – If (Storage Memory Exhausted) Spill to Disk – If (Local Disk Exhausted) Fail Job • Maximize Parallelism – Utilize All Cores – Provision only the cores you need #UnifiedAnalytics #SparkAISummit 24
25 .Balance Input Partitions • Maximizing Resources Requires Balance Shuffle Partitions – Task Duration Output Files Spills – Partition Size GC Times • SKEW – When some partitions are significantly larger than most Straggling Tasks #UnifiedAnalytics #SparkAISummit 25
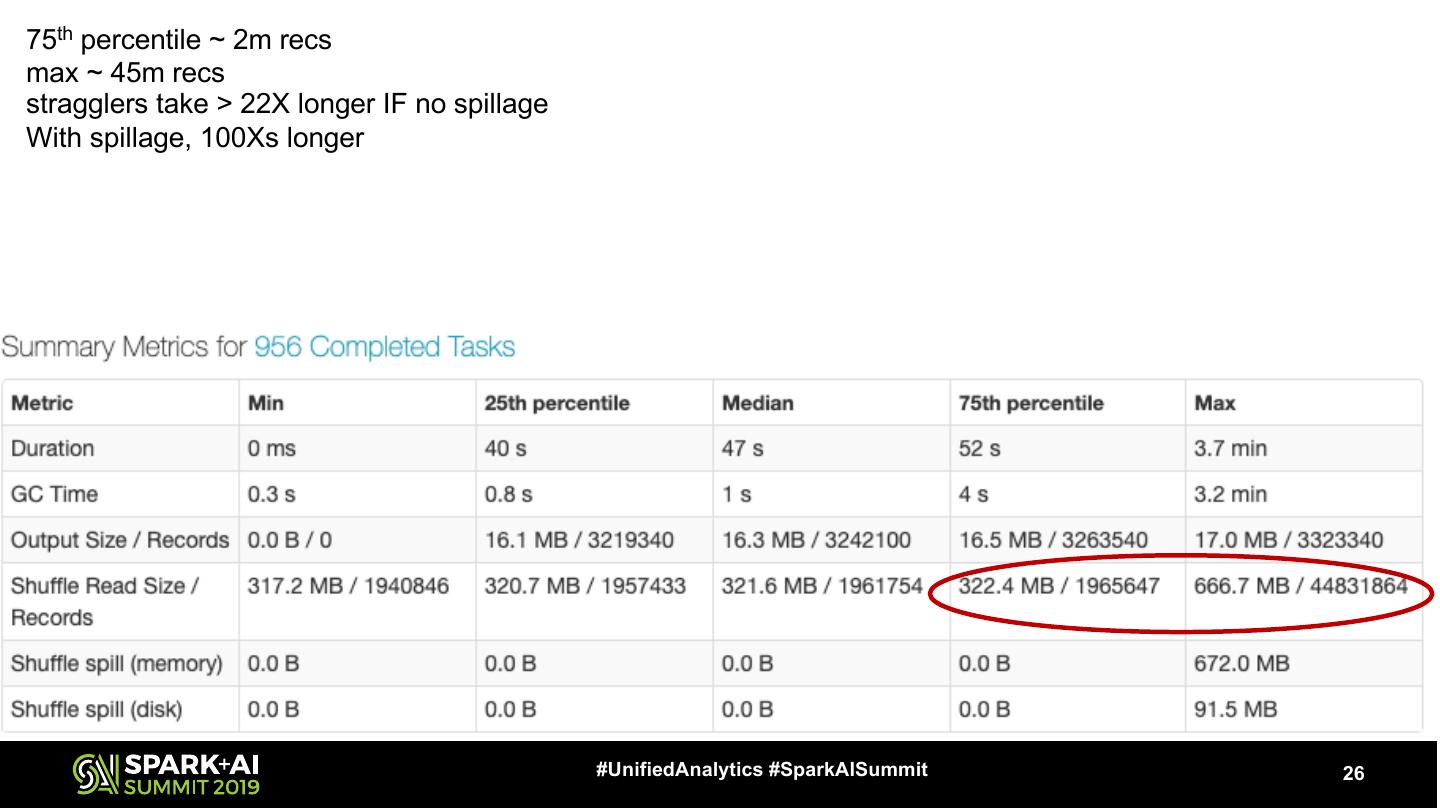
26 .75th percentile ~ 2m recs max ~ 45m recs stragglers take > 22X longer IF no spillage With spillage, 100Xs longer #UnifiedAnalytics #SparkAISummit 26
27 .Skew Join Optimization • OSS Fix – Add Column to each side with random int between 0 and spark.sql.shuffle.partitions – 1 to both sides – Add join clause to include join on generated column above – Drop temp columns from result • Databricks Fix (Skew Join) val skewedKeys = List(”id1”, “id200”, ”id-99”) df.join( skewDF.hint(“tblA”, “skewKey”, skewedKeys), Seq(keyCol), “inner”) #UnifiedAnalytics #SparkAISummit 27
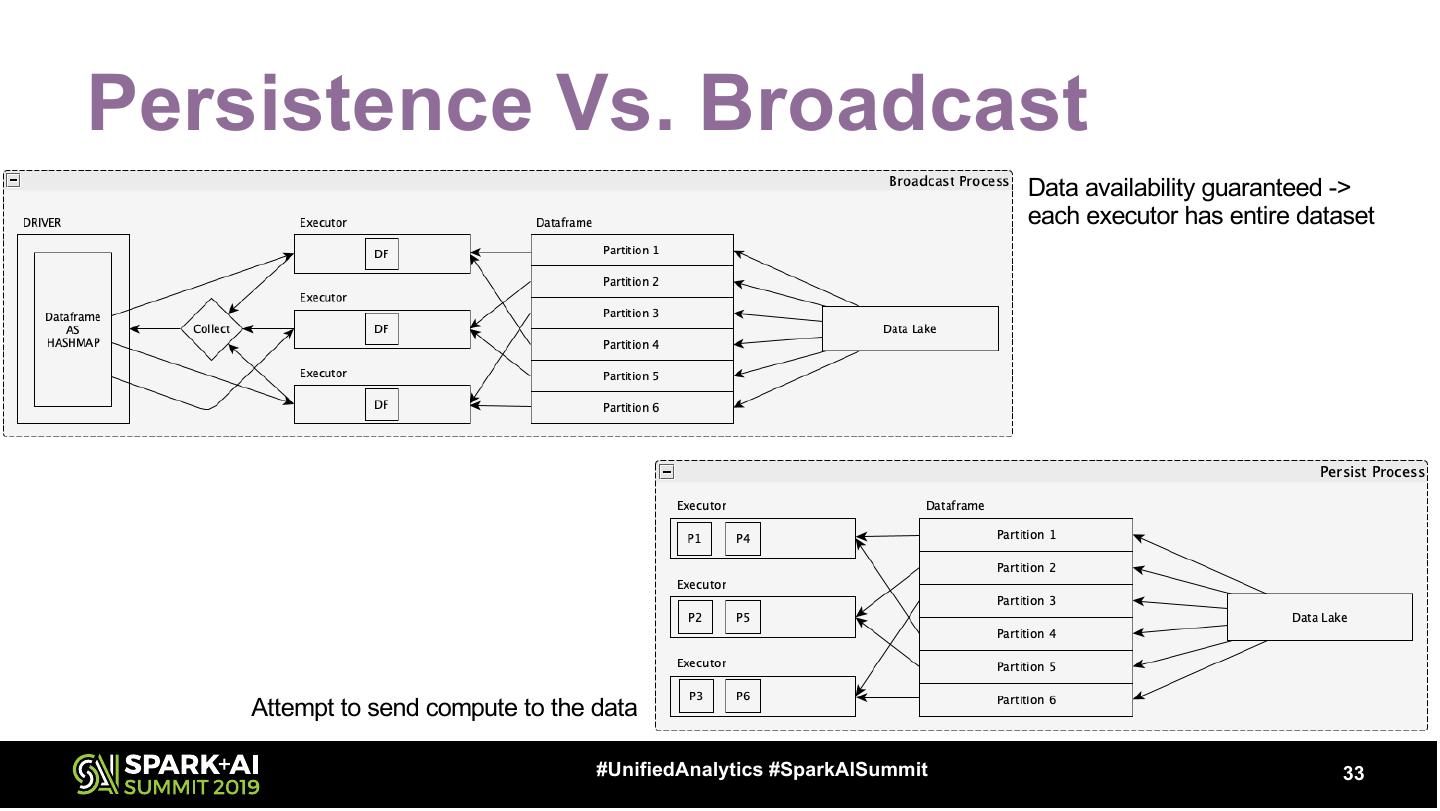
28 .Minimize Data Scans (Persistence) df.cache == df.persist(StorageLevel.MEMORY_AND_DISK) • Persistence • Types – Not Free – Default (MEMORY_AND_DISK) • Deserialized • Repetition – Deserialized = Faster = Bigger – SQL Plan – Serialized = Slower = Smaller – _2 = Safety = 2X bigger – MEMORY_ONLY – DISK_ONLY Don’t Forget To Cleanup! df.unpersist #UnifiedAnalytics #SparkAISummit 28
29 .#UnifiedAnalytics #SparkAISummit 29
3秒后跳转登录页面
去登陆

