展开查看详情
1 .A recommender story:
Improving backend data quality
while reducing costs
Jacques Doux, Elsevier
#UnifiedDataAnalytics #SparkAISummit
�
2 .Elsevier – in a nutshel
We are a Data and Analytics Company delivering solutions for Science and Health.
• Modern Elsevier Born in 1880 in Amsterdam
https://www.elsevier.com/about/history
• The biggest Academic publisher
38k books – 3000 journals (~25% of ever cited content)
• First publisher to have provided electronic version of its content
From ADONIS (1979) to ScienceDirect (1997) and now hosting ~17M full text documents
• Empowering decision support :
https://www.elsevier.com/solutions
− Abstract and indexing
− Research & Data management tools
− Research evaluation and showcasing tools
− Adaptative learning for health professionals
− Clinical decision support
− Discovery sandbox
to combine Elsevier high quality data with your own proprietary data
2
�
3 . endeley helps academics stay on top
• By providing solutions for
− References management
− Academic & Research networking
− Managing Datasets
− Finding academic job opportunity
− Finding Funding opportunity
• Powered by
− Data
− Search and Discovery tools
3
�
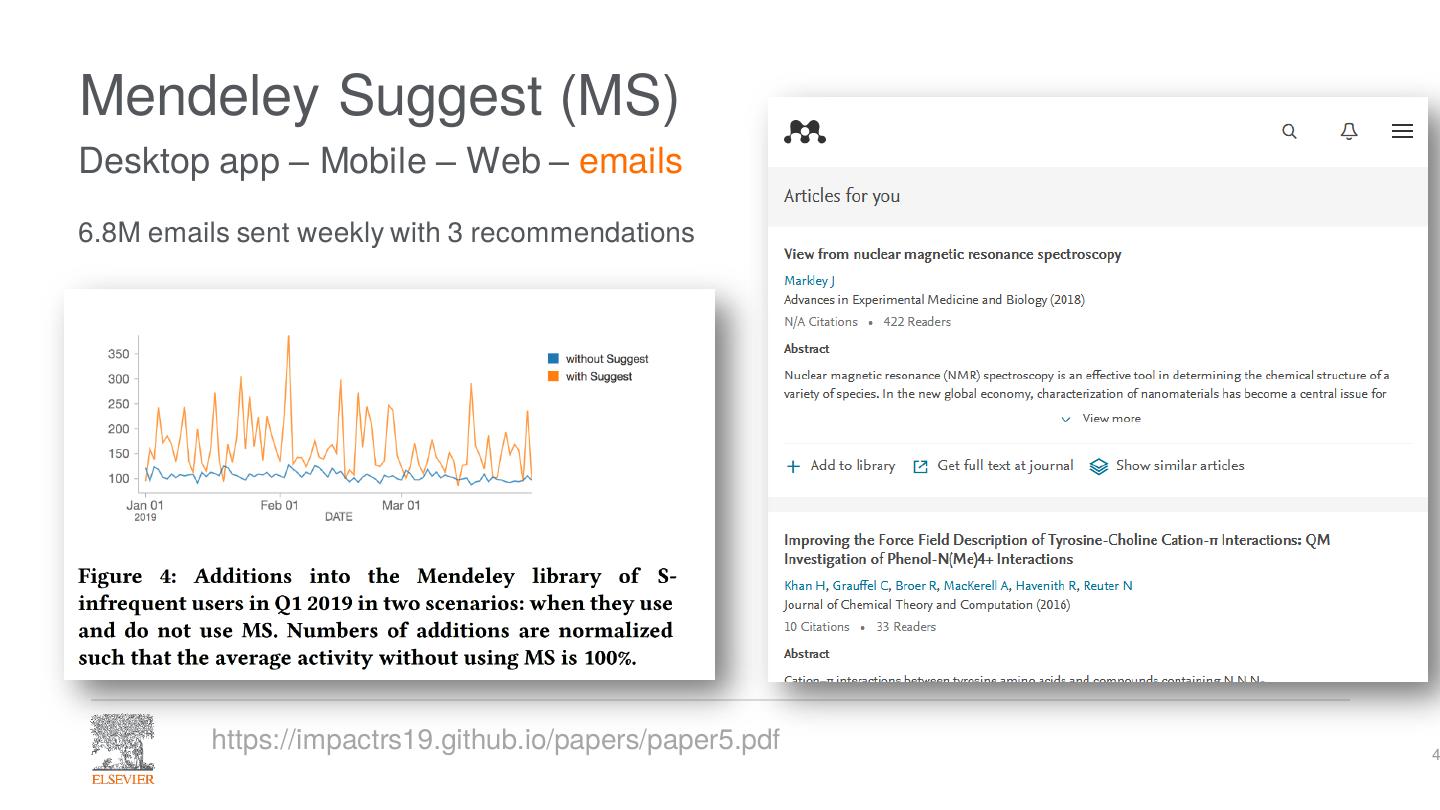
4 .Mendeley Suggest (MS)
Desktop app – Mobile – Web – emails
6.8M emails sent weekly with 3 recommendations
https://impactrs19.github.io/papers/paper5.pdf 4
�
5 .How does Mendeley Suggest work
• Custom implementation of user based
collaborative filtering
• Significance Weighting
• Time Decay
• Impression Discounting
• Dithering
• Data… lots of it
• Content records (Catalogue)
• User profiles
• Ambient data
https://doi.org/10.1142/9789813275355_0018
5
�
6 .Issues with catalogue impacts dependent systems
Under-merged
Relevant, but already added it a while back
Very “focused” recommendations !
Many obvious duplicates creeping up
search result…
… splitting metrics apart impacting
relevance ranking
6
�
7 .How it’s made: Catalogue
Evolution of document records
in Mendeley catalogue
Start project
2,000 M
# document records
publication of
1,500 M old
deduplication
algorithm
1,000 M old algorithm something
inception needs to be
done
public birth of
500 M >= 24h to run
Mendeley
acquisition by too many visible
Elsevier issues
0M
2009 2010 2011 2012 2013 2014 2015 2016 2017 2018 2019
year of addition
https://doi.org/10.1108/PROG-02-2015-0021
7
�
8 .Redesign without breaking: Goals
1. Improve overall user experience
Better document disambiguation : better classifier
2. Improve scalability and processing speed
Need to work for > 2B records and faster than it
currently does
3. Improve code maintainability and ease of evolution
Migrate from Hadoop MR in Java to Spark + Scala
8
�
9 . Improving the classifier: are those duplicates?
title authors doi published_in year
Coseismic extension recorded within the damage zone of the Harold Leah, Michele Fondriest, Alessio Lucca,
Duplicates
10.31223/osf.io/5y3pn 2018
BUT !
Vado di Ferruccio Thrust Fault, Central Apennines, Italy Fabrizio Storti, Fabrizio Balsamo, Giulio Di Toro
Coseismic extension recorded within the damage zone of the Harold Leah, Michele Fondriest, Alessio Lucca,
10.1016/j.jsg.2018.06.015 Journal of Structural Geology 2018
Vado di Ferruccio Thrust Fault, Central Apennines, Italy Fabrizio Storti, Fabrizio Balsamo, Giulio Di Toro
Determination of cefpirome concentrations in lung extracellular Croneberger, A.S., Kietzmann, M., Ehinger,
Duplicates
10.1111/j.1365-2885.2009.01090.x Journal of Veterinary Pharmacology and Therapeutics 2009
BUT !
fluid of pigs by microdialysis and ….. A.M., Allan, M., Nuernberger, M.C.
Not
Oral communications 10.1111/j.1365-2885.2009.01090.x Journal of Veterinary Pharmacology and Therapeutics 2009
Médecine & Droit; The judge, the physician and the prisoner. A
Duplicates
Chassagne A, Godard-Marceau A 2019
critical view of the “suspension de peine” for medical reason
Le juge, le médecin et le détenu. Regard critique sur la
Chassagne A, Godard-Marceau A 10.1016/j.meddro.2019.01.001 Medecine et Droit 2019
suspension de peine pour raison médicale
Duplicates
Hearing loss: Diagnosis and Management John M Lasak, Patrick Allen, Douglas Lewis Primary Care Clinics in Office Practice 2014
Not
John M Lasak, Patrick Allen, Tim McVay,
Hearing loss: diagnosis and management. Primary care 2014
Douglas Lewis
On the number and structure of sum-free sets in a segment of
Duplicates
K. G. Omelyanov,A. A. Sapozhenko Discrete Mathematics and Applications 2002
positive integers
On the number and structure of sum-free sets in a segment of
K. G. Omelyanov,A. A. Sapozhenko Discrete Mathematics and Applications 2003
positive integers
Vertex-disjoint cycles containing specified edges in a bipartite Guantao Chen, Hikoe Enomoto, Ken Ichi
Duplicates
Dicscrete Mathematics(Elsevier) 2001
graph Kawarabayashi, Katsuhiro Ota…
Not
Vertex-disjoint cycles containing specified vertices in a bipartite Guantao Chen, Hikoe Enomoto, Ken Ichi
2004
graph Kawarabayashi, Katsuhiro Ota…
9
�
10 .Improving the classifier: What have we done?
Bootstrap with
previous
training set
Engineer
relevant
features
Find document
Tune & Train
pairs at the Benchmark
model
decision boundary
Heurristic +
Manual
Classification
Deploy
10
�
11 .Scalability issues: Reduce problem cardinality
Record exclusion
Data normalization
Exact duplicates detection and
Identifier based duplicates detection
Tuneable blocking step
MinHash-LSH and sub blocking if needed
Divide classifier tasks by 2
by removing equal pairs (A,B) = (B,A)
11
�
12 . Performance
Old New
F1 Score
New manually
Old data set
annotated data Comute time
(1M pairs)
set (9.2k pairs)
Old
0.98 0.60 >24h
Dedup
new
0.98 0.96 ~13h
Dedup
Verdict Same Much better Much better
If 3% error rate, over 2B
=> 60M miss classified
12
�
13 .Lessons learned
• Monitor your systems
• Data matters !
− Know your data!
− “More data” vs “Good data”
• Engineering
− Keep it as simple as possible
If it works with simpler model don’t use more complex ones
e.g. Random Forest vs SVM with RBF kernel vs Neural Networks
− Extensive testing
Especially if production code will use different language / libraries / library versions
− With big data, hash collision is real
• As a data scientist, work in tight collaboration engineers implementing
production grade code Make sure things are feasible within their tech stack
13
�
14 . Come join us in solving problems
7,500 >1,000
Empoyees Thank you technologists
https://www.elsevier.com/about/careers/technology-careers
15
�
15 .DON’T FORGET TO RATE
AND REVIEW THE SESSIONS
SEARCH SPARK + AI SUMMIT
�