展开查看详情
1 .WIFI SSID:Spark+AISummit | Password: UnifiedDataAnalytics
�
2 .A Spark-based Intelligent
Assistant
Making Data Exploration in Natural Language Real
Georgia Koutrika, ATHENA Research Center
#UnifiedDataAnalytics #SparkAISummit
�
3 . Data, Data, Data
Data growth
More data than humans can process and comprehend
Data democratization
From scientists to the public, increasingly more users are consumers of data
#UnifiedDataAnalytics #SparkAISummit 3
�
4 .HOW CAN WE EXPLORE AND
LEVERAGE OUR DATA?
4
�
5 .Select p.status SQL Results
queries
from conference_attendees p
where p.conference=‘SPARK+AI2019’ Data Store
#UnifiedDataAnalytics #SparkAISummit 5
�
6 .How are you today?
#UnifiedDataAnalytics #SparkAISummit 6
�
7 .The phases of data
exploration
7
�
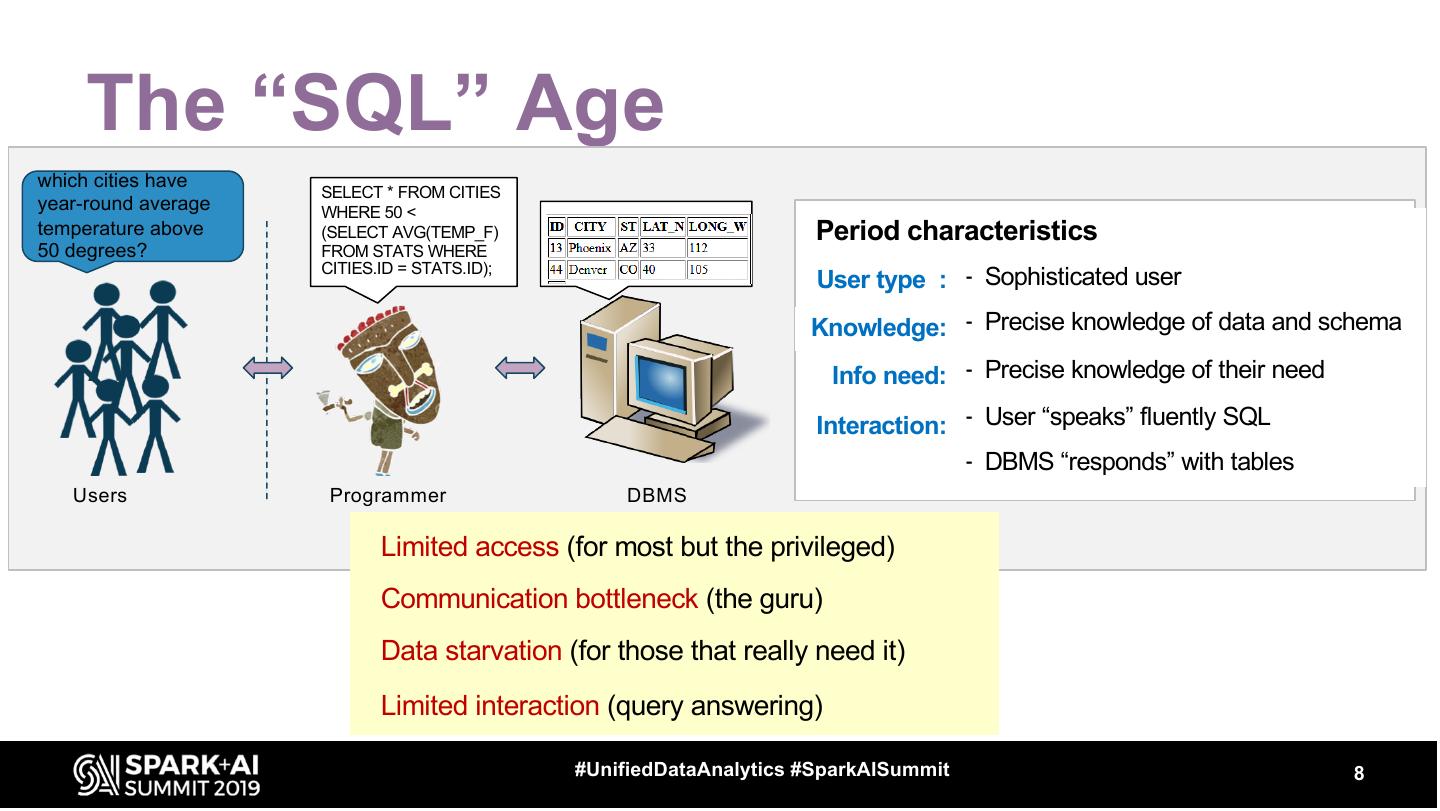
8 . The “SQL” Age
which cities have
SELECT * FROM CITIES
year-round average WHERE 50 <
temperature above (SELECT AVG(TEMP_F) Period characteristics
50 degrees? FROM STATS WHERE
CITIES.ID = STATS.ID);
User type : - Sophisticated user
Knowledge: - Precise knowledge of data and schema
Info need: - Precise knowledge of their need
Interaction: - User “speaks” fluently SQL
- DBMS “responds” with tables
Users Programmer DBMS
Limited access (for most but the privileged)
Communication bottleneck (the guru)
Data starvation (for those that really need it)
Limited interaction (query answering)
#UnifiedDataAnalytics #SparkAISummit 8
�
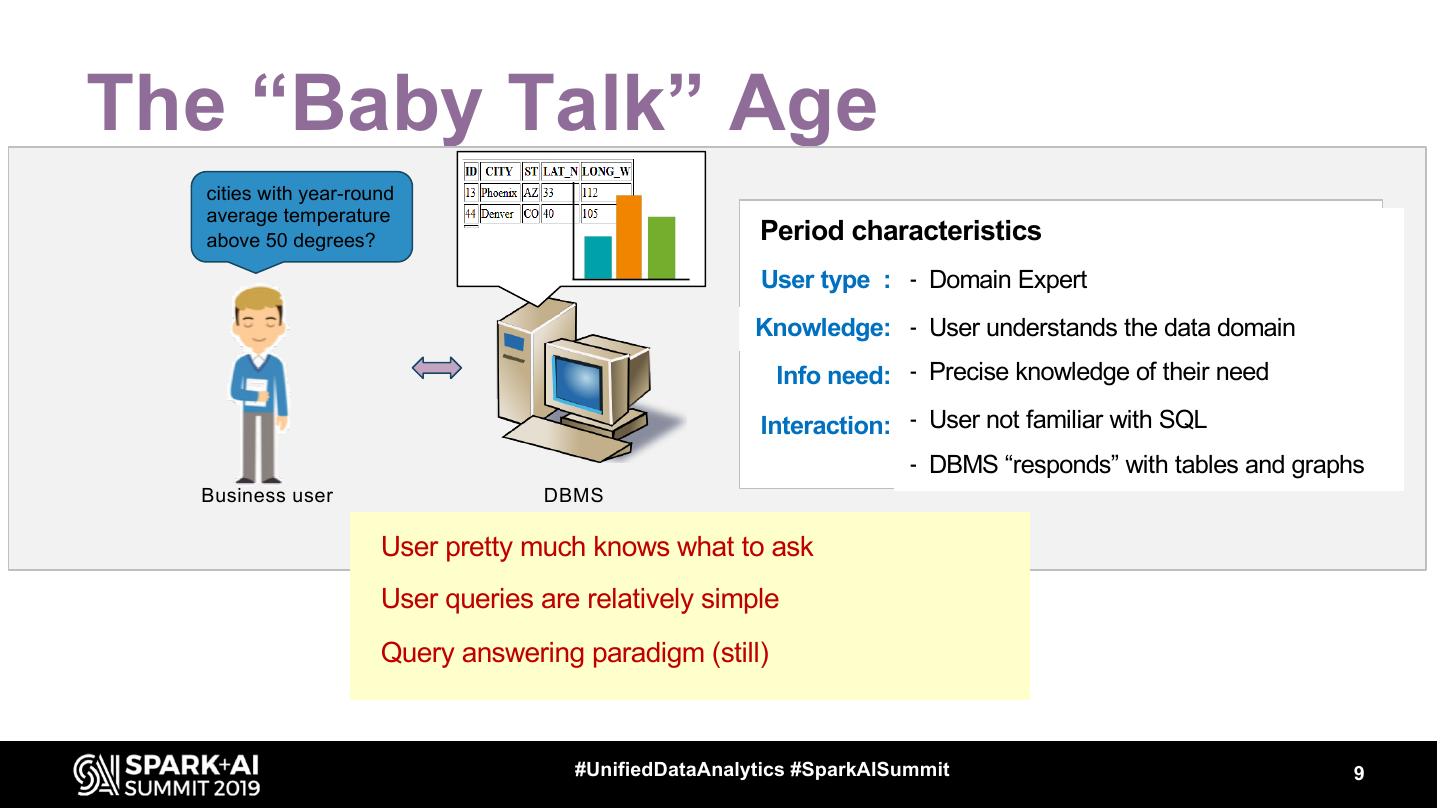
9 .The “Baby Talk” Age
cities with year-round
average temperature
above 50 degrees? Period characteristics
User type : - Domain Expert
Knowledge: - User understands the data domain
Info need: - Precise knowledge of their need
Interaction: - User not familiar with SQL
- DBMS “responds” with tables and graphs
Business user DBMS
User pretty much knows what to ask
User queries are relatively simple
Query answering paradigm (still)
#UnifiedDataAnalytics #SparkAISummit 9
�
10 .Chatbots
A chatbot:
• mimics conversations with people
• uses artificial intelligence techniques
• lives on consumer messaging platforms, as a means
for consumers to interact with brands.
Drawbacks
• Primarily text interfaces based on rules
• Encourage canned, linear-driven interactions
• Deal with simple,https://medium.com/swlh/chatbots-of-the-future-86b5bf762bb4
unambiguous questions (“what is the weather forecast today”)
• Cannot answer random or complex queries over data repositories
#UnifiedDataAnalytics #SparkAISummit 10
�
11 . Conversational AI
For example, Google Duplex: demo released in May 2018
• The technology is directed towards completing specific tasks, such as scheduling certain types of
appointments.
• For such tasks, the system makes the conversational experience as natural as possible.
• One of the key research insights was to constrain Duplex to closed domains.
• Duplex can only carry out natural conversations after being deeply trained in such domains
#UnifiedDataAnalytics #SparkAISummit 11
�
12 .Human-like Data Exploration
Requirements
User type : - From expert to data consumer
Knowledge: - Intuition about the data
Info need: - Not necessarily sure what to ask
Interaction: - Intuitive, natural, interaction
#UnifiedDataAnalytics #SparkAISummit 12
�
13 .Human-like Data Exploration
An Intelligent Data Assistant
• converses with the user in a more natural bilateral interaction;
• actively guides the user offering explanations and suggestions;
• keeps track of the context and can respond and adapt accordingly;
• constantly improves its behavior by learning and adapting.
#UnifiedDataAnalytics #SparkAISummit 13
�
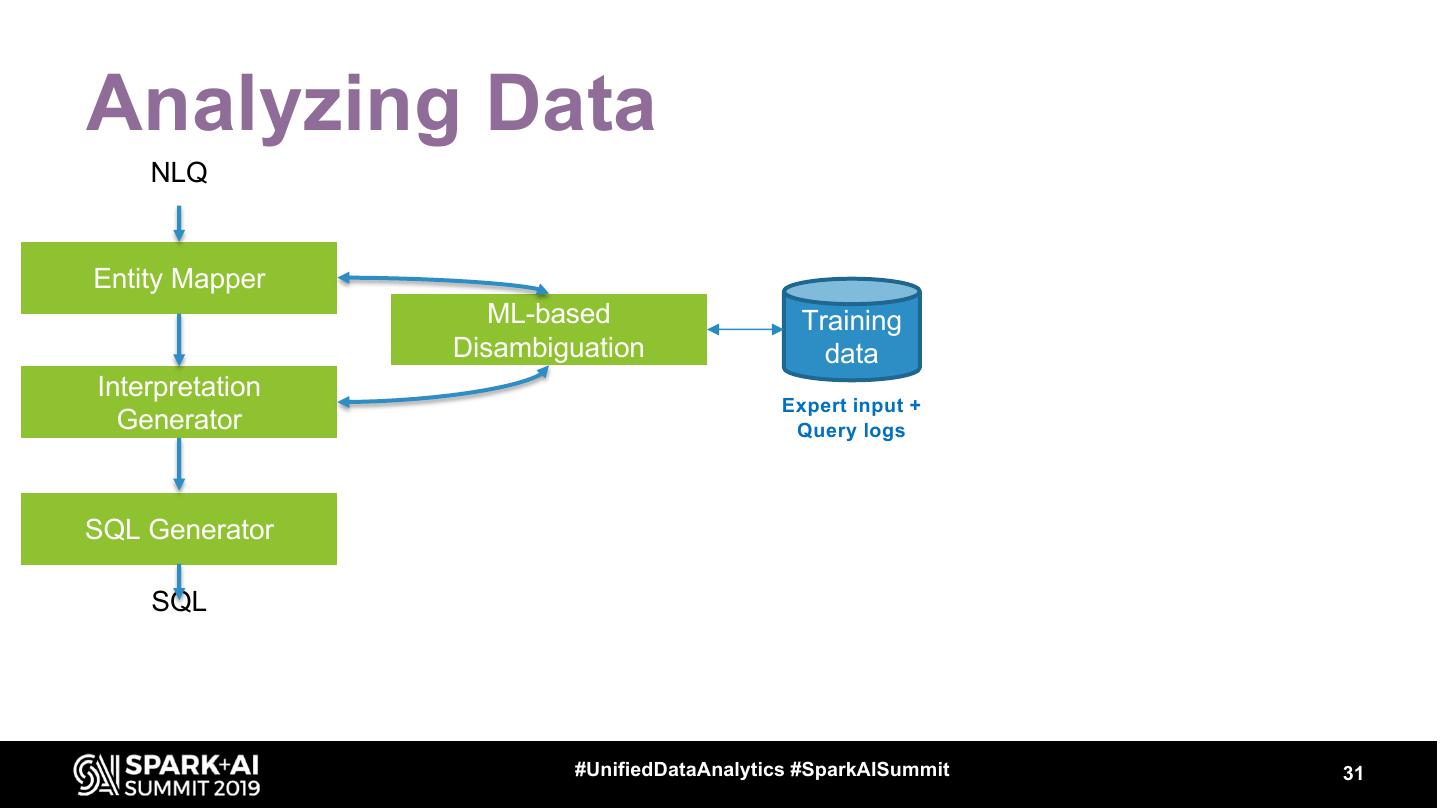
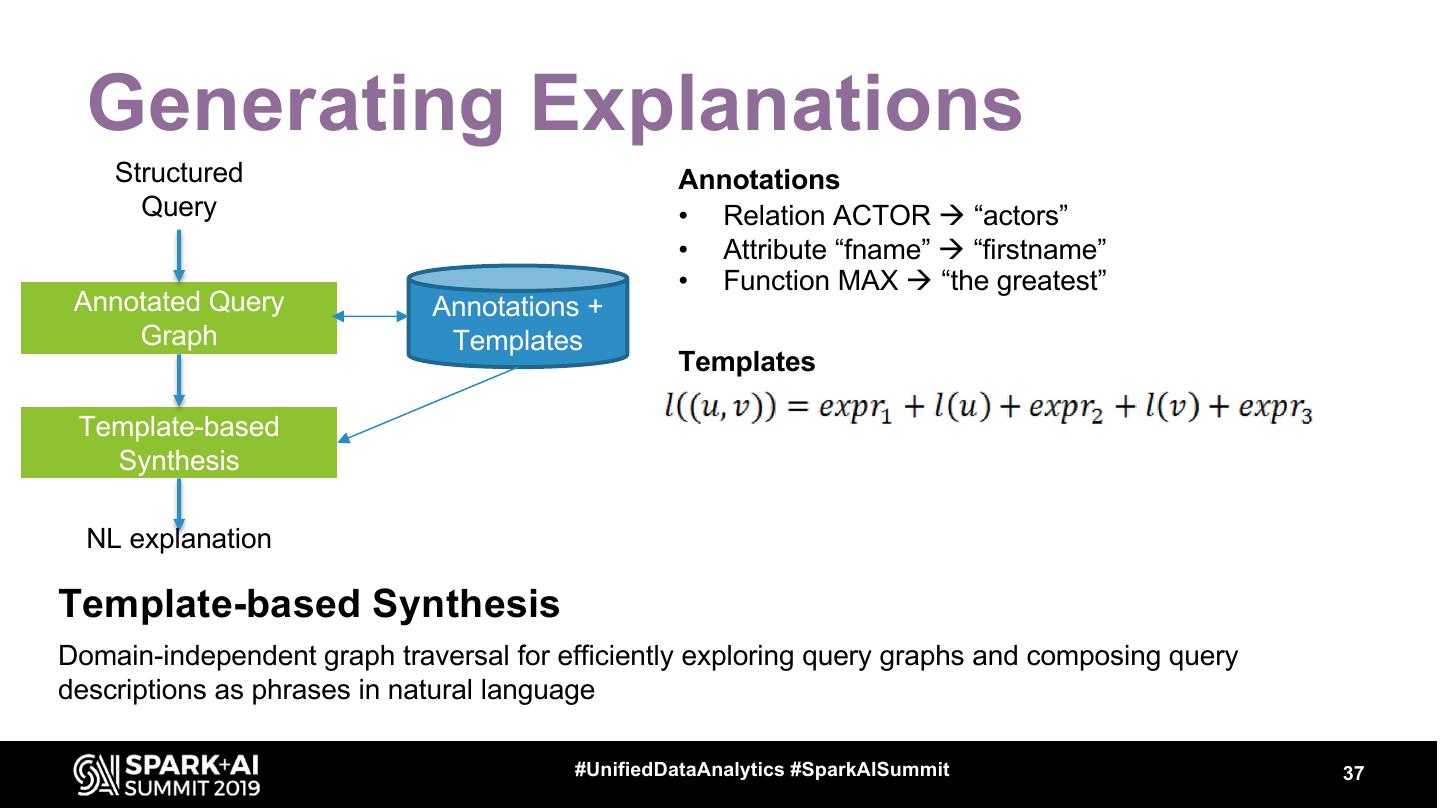
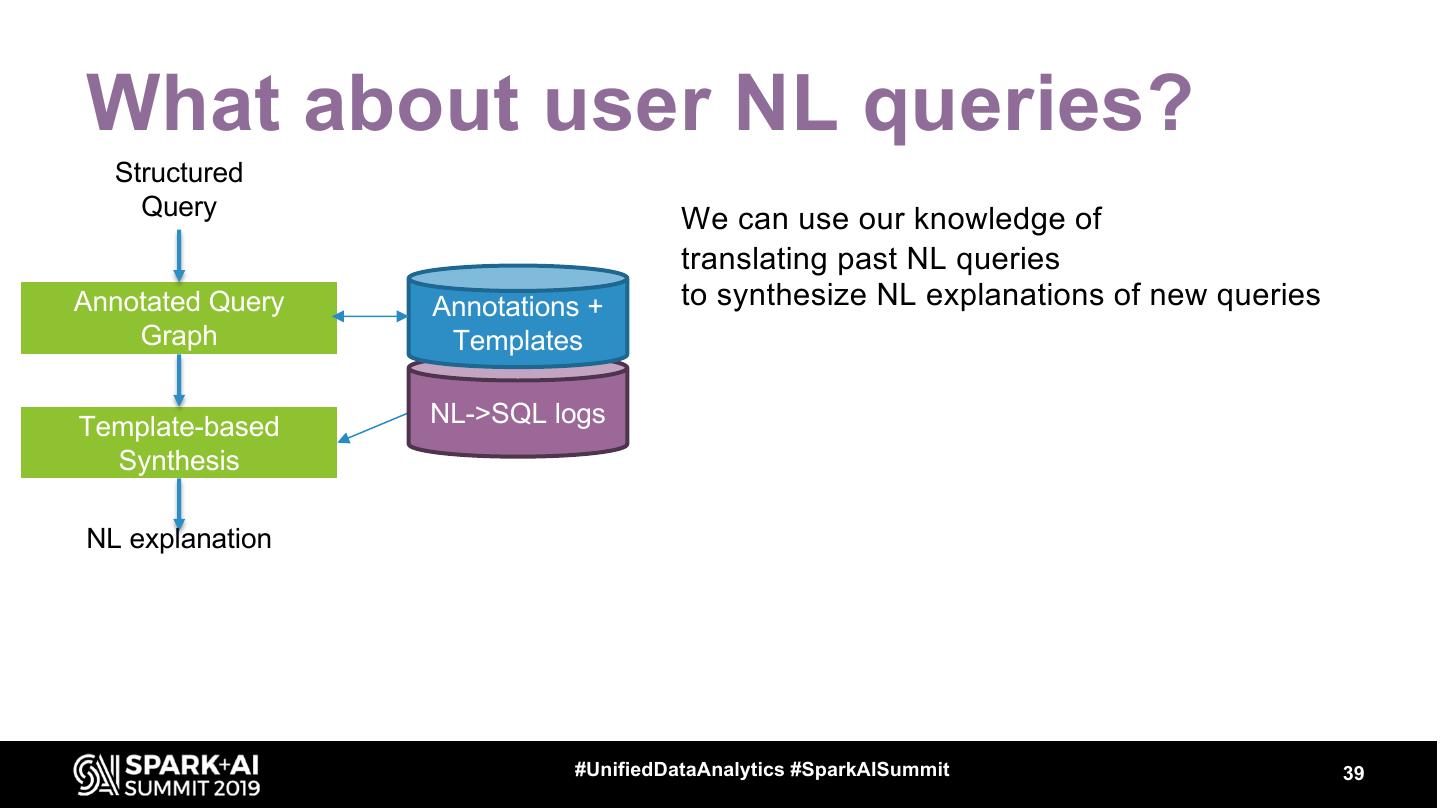
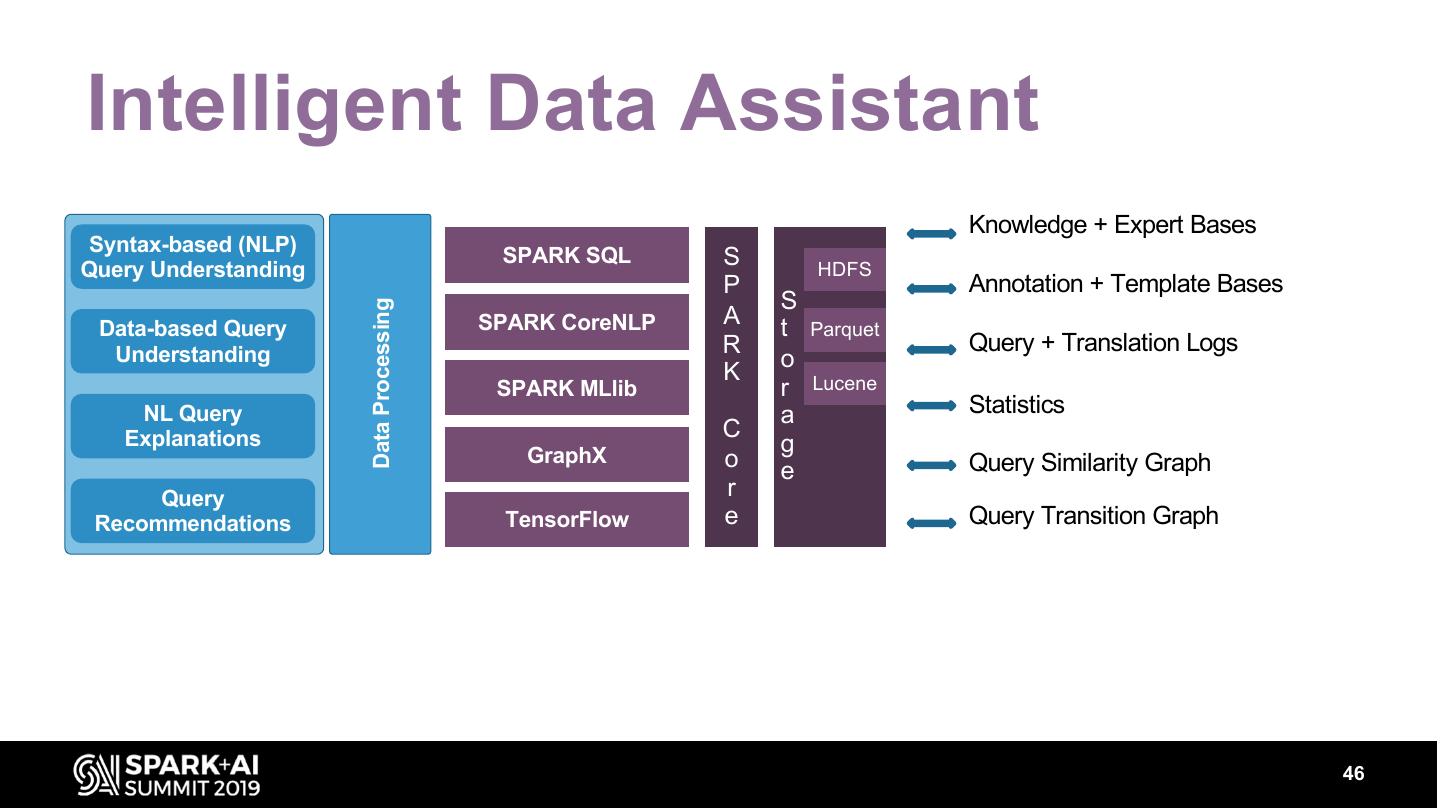
14 . Intelligent Data Assistant
Syntax-based (NLP)
Query Understanding
Data-based Query
Understanding
NL Query
Explanations
Query
Recommendations
#UnifiedDataAnalytics #SparkAISummit 14
�
15 . Step 1: Let the user ask
Syntax-based (NLP)
using natural language
Query Understanding
Data-based Query
Understanding
NL Query
Explanations
Query
Recommendations
�
16 .Facts
Unlike search engines, users tend to express sophisticated
query logics to a data assistant and expect perfect results
Translating a natural language query to a structured query is hard!
#UnifiedDataAnalytics #SparkAISummit 16
�
17 . Challenges: from the NL Side
Synonymy: multiple words with the same Paraphrasing Multiple way to say the same thing
meaning e.g.,“movies" and “films" E.g. ‘how many people live in ..." could be a mention of the
“Population“ column.
Polysemy: a single word has multiple meanings
e.g. Paris as in the city and Paris Hilton Context dependent terms:
Syntactic: Multiple readings based on syntax E.g., “Return the top product" the term “top" is a modifier for
e.g., “Find all German movie directors“ means: “product". Does it mean Based on popularity?? Based on
“directors that have directed German movies" ?? number of sales??
“directors from Germany that have directed a movie“?? Elliptical queries: sentences from which one or
Semantic: Multiple meanings for a sentence. more words are omitted.
e.g. “Are Brad and Angelina married?". E.g. , “Return the movies of Clooney".
Are they married to each other or separately.
Non-exact matching: mentions do not map
exactly to values or tables/attributes)
E.g. Who is the best actress in 2011 à ‘actress’ should map to
the “actor” column
#UnifiedDataAnalytics #SparkAISummit 17
�
18 . Challenges: from the Data Side
Complex Syntax: SQL is a structured language with a strict grammar
and limited expressivity when compared to natural language.
e.g., “Return the movie with the best rating".
Should look like “SELECT name , MAX( rating ) FROM Movie ;” but it is WAY more
complicated
Database Structure:
E.g., for the term “date" a system may need to retrieve three attributes: year, month, day
Multiple relationships: mentions may connect in multiple ways/join
disambiguation
E.g., “Woody Allen movies” may need several tables to be joined.
Ranking: how to rank multiple answers
e.g., “Return Woody Allen movies".
#UnifiedDataAnalytics #SparkAISummit 18
�
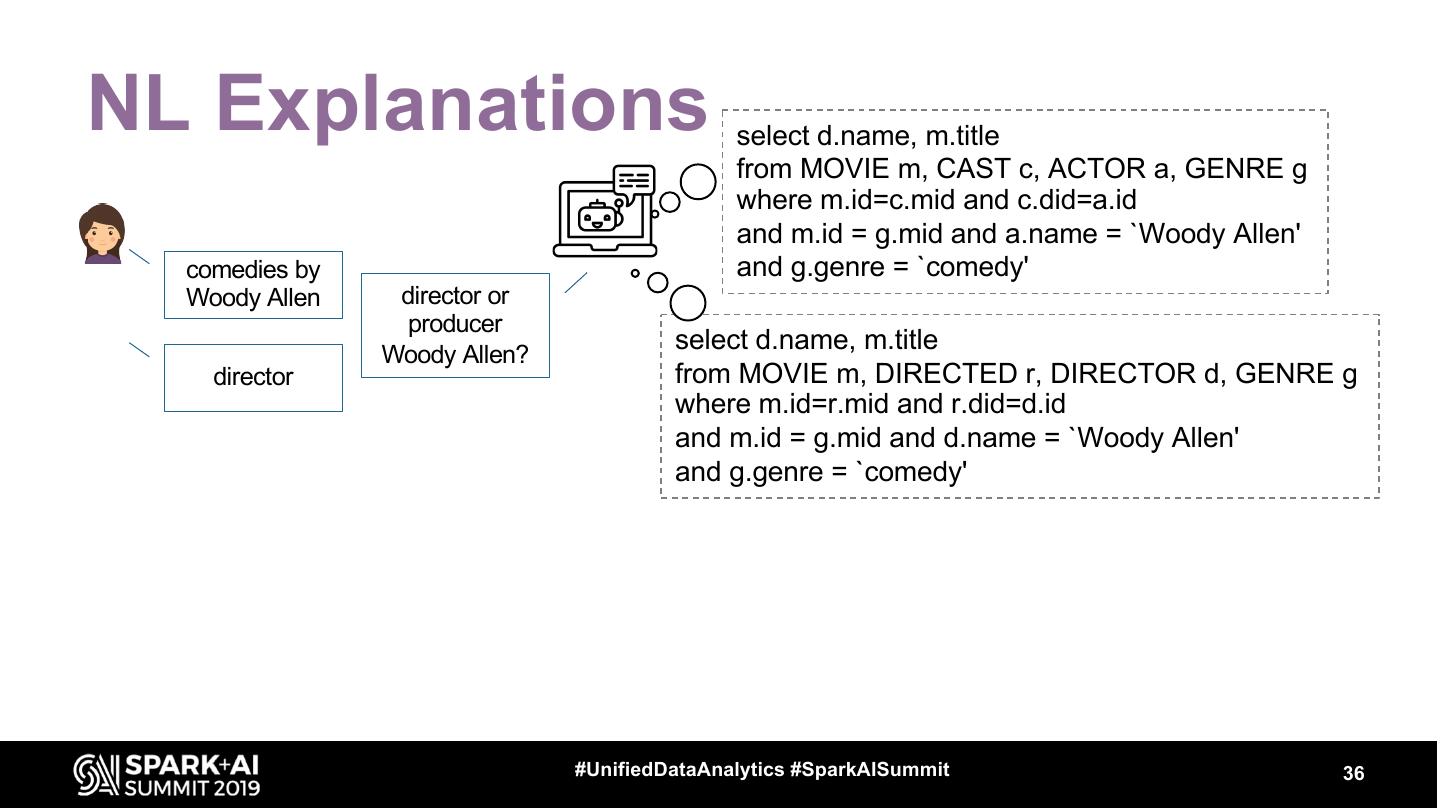
19 .Ask a query
What movies have the same director as
the movie “Revolutionary Road”
#UnifiedDataAnalytics #SparkAISummit 19
�
20 .Understanding Syntax
NLQ
Syntactic Parser Step 1. Understand the natural language query linguistically.
Generate a dependency parse tree:
• part-of-speech (POS) tags
that describe each word's syntactic function
+
• syntactic relationships between words in the sentence.
#UnifiedDataAnalytics #SparkAISummit 20
�
21 .Understanding Syntax
NLQ
Syntactic Parser
Step 2.
1. Map query elements to data elements:
Node Mapper
• tables, attributes, values – using indexes
• commands (e.g., order by) – using a dictionary
2. Keep best mappings
#UnifiedDataAnalytics #SparkAISummit 21
�
22 .Understanding Syntax
NLQ
Syntactic Parser
Node Mapper
Step 3. Map the parse tree to the database structure and build a query tree
Tree Mapper
#UnifiedDataAnalytics #SparkAISummit 22
�
23 .Understanding Syntax
NLQ
Syntactic Parser
Node Mapper
Tree Mapper
SQL Generator Step 4. Generate the SQL query to execute
SQL
#UnifiedDataAnalytics #SparkAISummit 23
�
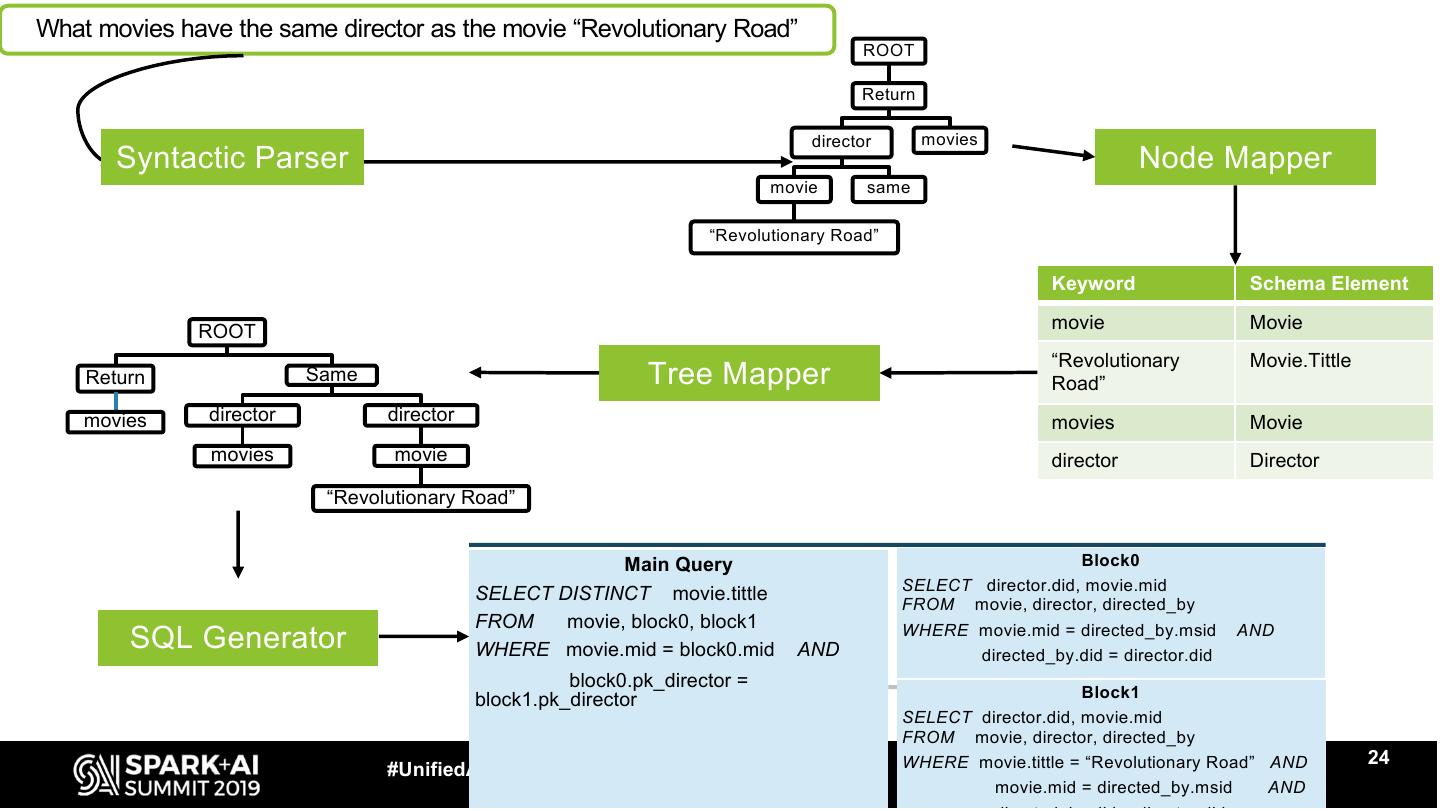
24 .What movies have the same director as the movie “Revolutionary Road”
ROOT
Return
director movies
Syntactic Parser Node Mapper
movie same
“Revolutionary Road”
Keyword Schema Element
ROOT movie Movie
“Revolutionary Movie.Tittle
Return Same Tree Mapper Road”
movies director director movies Movie
movies movie director Director
“Revolutionary Road”
Main Query Block0
SELECT director.did, movie.mid
SELECT DISTINCT movie.tittle
FROM movie, director, directed_by
FROM movie, block0, block1
SQL Generator WHERE movie.mid = block0.mid AND
WHERE movie.mid = directed_by.msid
directed_by.did = director.did
AND
block0.pk_director =
block1.pk_director Block1
SELECT director.did, movie.mid
FROM movie, director, directed_by
WHERE movie.tittle = “Revolutionary Road” AND 24
#UnifiedAnalytics #SparkAISummit
movie.mid = directed_by.msid AND
�
25 .Understanding Syntax
Why is Parsing So Hard For Computers to Get Right?
• Human languages show remarkable levels of ambiguity.
• It is not uncommon for moderate length sentences to have hundreds, thousands, or even tens of
thousands of possible syntactic structures.
• A natural language parser must somehow search through all of these alternatives, and find the most
plausible structure given the context.
#UnifiedDataAnalytics #SparkAISummit 25
�
26 . Step 1: Let the user ask
Syntax-based (NLP)
using natural language
Query Understanding
Data-based Query
Understanding
NL Query
Explanations
Query
Recommendations
�
27 .Ask a query
Show me Italian restaurants
Not much value a parser can add
#UnifiedDataAnalytics #SparkAISummit 27
�
28 .Ambiguity Several possible mappings
#UnifiedDataAnalytics #SparkAISummit 28
�
29 . Ambiguity
Likely
Several possible query interpretations
1 "business categorized as restaurant and as Italian” “restaurant''= Category(category), "italian''= Category(category)
2 "business categorized as Italian whose name includes restaurant”
Unlikely "restaurant''= Business(name), "italian''= Category(category)
3 "business categorized as Italian whose address includes restaurant” "restaurant''= Business(address), "italian''= Category(category)
4 "business categorized as restaurant that serves Italian” "restaurant''= Category(category), "italian''= Attribute(value)
5 "business whose address contains restaurant and Italian” "restaurant''= Business(address), "italian''= Business(address)
#UnifiedDataAnalytics #SparkAISummit 29
�