




































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Kylin Real-time OLAP功能深度解析
Apache Kylin是一个成熟和高性能的基于Hadoop的OLAP解决方案,使用Kylin可以在PB级数据上支持亚秒级的查询延迟;分享会首先从Kylin 本身开始特点介绍Kylin的特点和适用场景,重点讲述 Real-time OLAP的主要组件以及重要特性,并且结合使用案例来说明Real-time OLAP在一些场景下发挥的价值。
展开查看详情
1 . Introduction of Kylin 3.0’s real-time OLAP Kyligence ⼤数据⼯程师-俞霄翔 Xiaoxiang Yu 北京 2020/04 1 2019/04/13
2 . 议程 What is Real-time OLAP Real-time Deep Dive Case of Real-time OLAP 介绍 Real-time OLAP 的概念、主 介绍 Real-time OLAP 的实现细节 丁香园 - 基于 Kylin 3.0 的站点实时 要特性和基本架构 和注意事项 访问统计 概念介绍 实现细节 ⽤户案例 2
3 . What is Real-time 1 OLAP 3
4 . Apache Kylin OLAP on Hadoop • Analytical Data Warehouse for Big Data • 支持 Star/Snowflake 模型;多维度分析,SQL on Hadoop • 通过预计算满足亚秒级数据查询延迟 • 支持通过 JDBC,ODBC,Rest API查询;对接开源和商业的BI工具 4
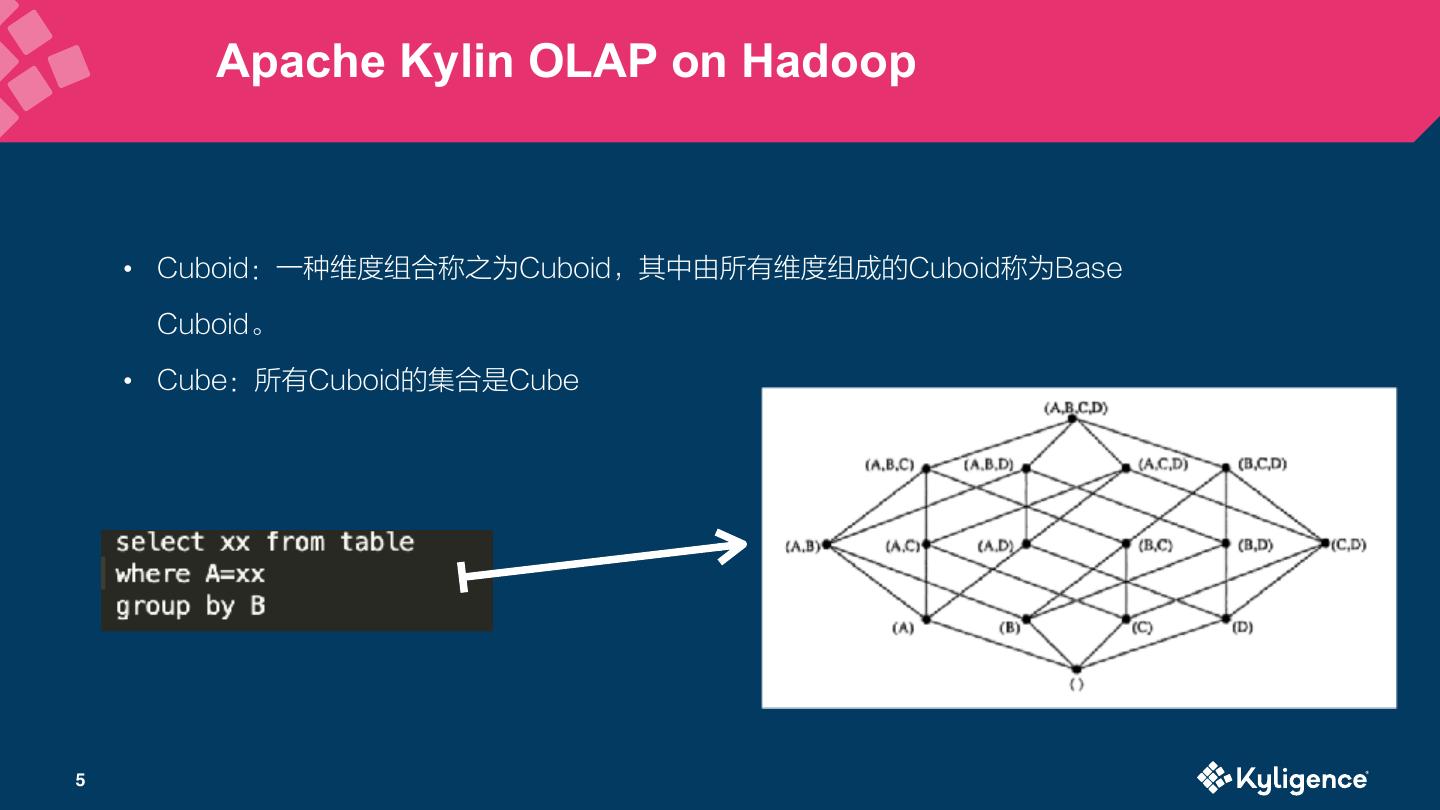
5 . Apache Kylin OLAP on Hadoop • Cuboid:一种维度组合称之为Cuboid,其中由所有维度组成的Cuboid称为Base Cuboid。 • Cube:所有Cuboid的集合是Cube 5
6 . Apache Kylin 从批处理到实时处理的历程 • 2014 年 Kylin 诞生,支持 Hive 批数据源,从海量历史数据挖掘价值; • 2015 年 v1.5 首次支持 Kafka 数据源,采用单机微批次构建; • 2016 年 v1.6 发布准实时(NRT Streaming), 使用 Hadoop 微批次消费流数 据; • 2017 年 v2.0 支持雪花模型和 Spark 引擎; eBay 团队开始尝试 real-time; • 2018 年 v2.4 支持 Kafka 流数据 与 Hive 维度表 join; eBay 开源 real-time OLAP 实现; • 2019 年 Q1,经过社区 review 和完善,合并 master; • 2019 年 Q4,v3.0 发布 Real-time OLAP,实现秒级数据准备延迟 6
7 . 流式数据处理流程 Long Long Latency Latency Data Pre- OLAP- Producer Collector ETL BI Tools Warehouse calculate Platform Smart phone/PC/ Message Hive, Kylin/Druid Apache server logs/IOT Bus such as Teradata, superset device Kafka Greenplum 7
8 . Kylin Real-time OLAP 基本架构 Kylin Query Server Historical Server Real-time Server Distributed Local Storage Storage Event Source 8
9 . Kylin Real-time OLAP 重要特性 低数据延迟 自动化的数据状态 Receiver 和 列式存储和倒排索 Checkpoint 管理 Coordinator 的HA 引 数据一旦进入,将立刻在 自动化的数据状态管理, 基于 Replica Set 可以实 Receiver 端的数据使用 Local Checkpoint 和 内存计算 cuboid,即刻 自动化的构建作业调度 现 Receiver 节点的高可 列式存储和倒排索引来加 Remote Checkpoint 来 可被查询(亚秒级的数据 用 速查询 保证重启数据不丢失 延迟) 9
10 . Kylin Streaming Receiver • Streaming Receiver 的角色是worker,受 Coordinator 的管理,它的主 要职责包含: • 摄入实时数据 • 在内存构建 cuboid • 接受对当前 Receiver 负责的 partition 的查询请求 • 当 segment 变为不可变后,上传到 HDFS 或者从本地删除 • Receiver Cluster : streaming receiver 组成的集合称为 Receiver 集群。 10
11 . Kylin Streaming Coordinator • Streaming coordinator Streaming coordinator 作为 receiver 集群的 Master 节点。它的主要职责包含将 topic partition 分配/解除分配到指定的 replica set, 暂停或者恢复消费,收集和展示各项统计指标(如 message per second)。当kylin.server.mode 被设置为all或者stream_coordinator, 这个进程就成为一个 streaming coordinator。Coordinator只处理元数据和 集群调度,不摄入数据。 • Coordinator cluster 多个coordinator可以同时存在,组成一个 coordinator 集群。同一时刻只存在一个 Leader,只有 Leader 才可以响应 请求,其余进程作为 standby/backup。 11
12 . Replica Set • Replica Set 是一组 Streaming Receiver。Replica Set 作为任务分配的最 小单位,Replica Set 下的所有 Receiver 做相同的工作(消费相同的一组 partition),互为 backup。当集群中存在一些 Receiver 进程不可达,但能 保证每一个 Replica Set 至少存在一个 Receiver,那么集群仍能正常工作并 且查询正常。 • 在一个 Replica Set 中,将存在一个 Leader 来做额外的工作。 12
13 . Real-time OLAP 整体架构 Data movement Schedule request Query request Submit job to merge data from different replica set and build into HBase Load into HBase HBase Metadata request Coordinator MR/Spark Assign partitions to replica set Start/pause/stop consume Zookeeper Metadata Receiver HDFS Upload local segments Query real-time part Query historical part Kafka Query Server 13
14 . Kylin Real-time 2 OLAP Deep Dive 14
15 . Streaming Segment Seg_3 Seg_4 1 … L In Memory Seg_2 Store 1 … M Fragments Unbounded 1 … J Seg_1 streaming events 1 … N Active Immutable Segments Segments Open to Write Close to Process 15
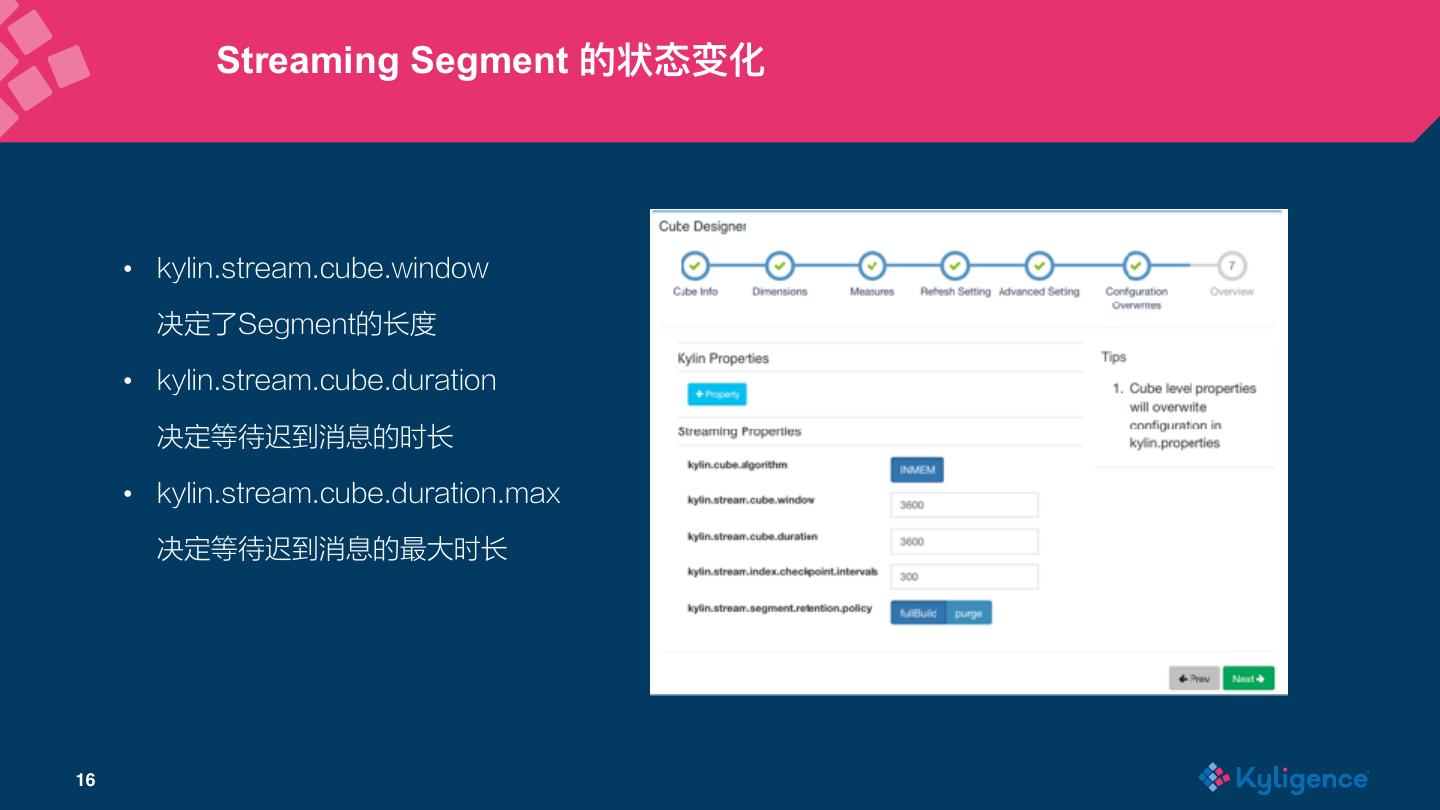
16 . Streaming Segment 的状态变化 • kylin.stream.cube.window 决定了Segment的长度 • kylin.stream.cube.duration 决定等待迟到消息的时长 • kylin.stream.cube.duration.max 决定等待迟到消息的最大时长 16
17 . Streaming Segment 的状态变化 Segment max duration Scheduled to Scheduled to be upload be build Segment duration 2019-04-13 20:00:00 event Segment Event window 2019-04-13 20:50:22 时间轴 20:00 21:00 23:00 09:00 09:20 09:50 Remote Active Active Immutable Persisted 17
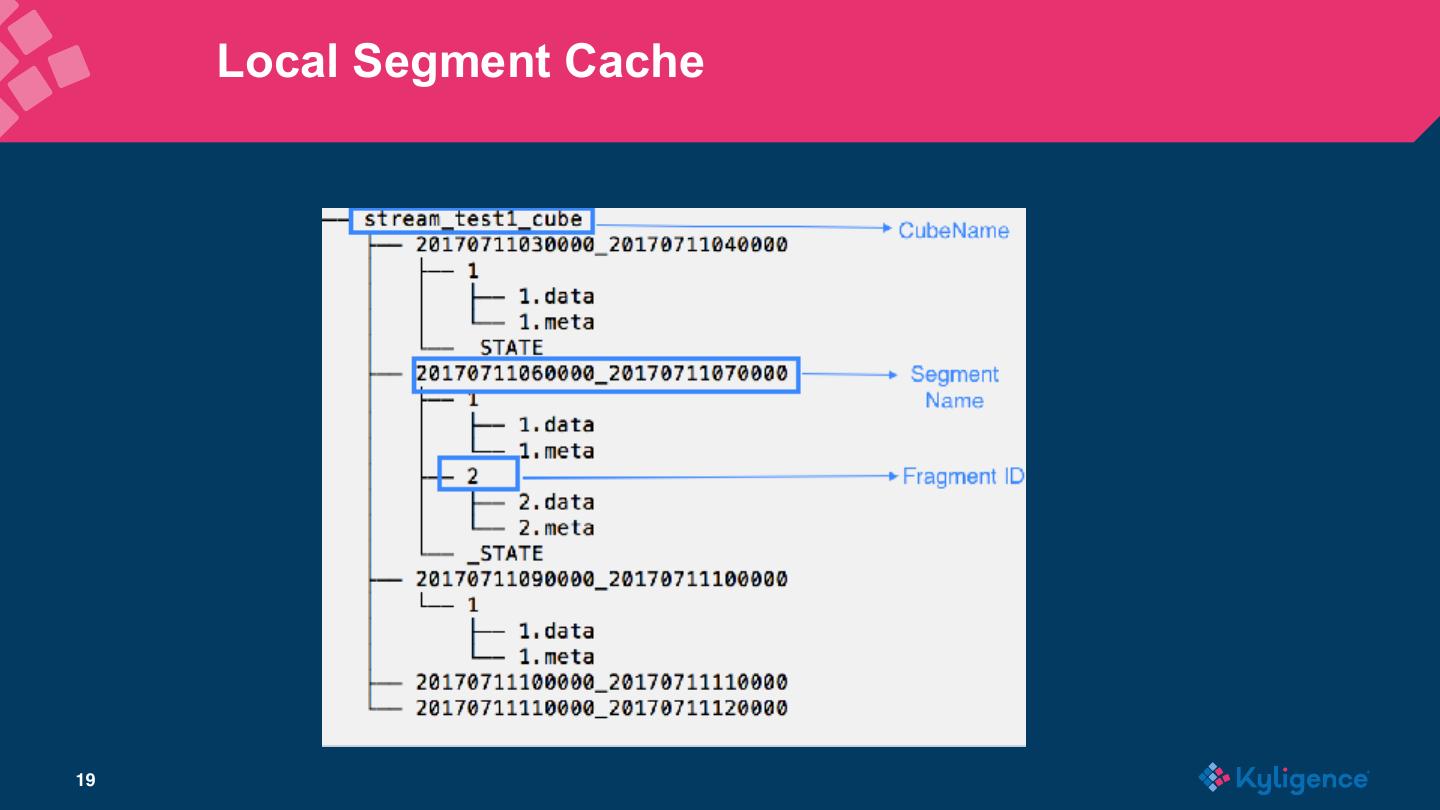
18 . Local Segment Cache • Memory Store 保存了最近的摄入数据(base cuboid 和 extra cuboid),数 据量达到阈值会 flush 到磁盘 • Fragment file 是内存数据flush到磁盘形成的文件,文件格式使用了列式存储 和倒排索引,以便加速查询。Fragment 文件是本地 checkpoint 使用的数据 文件。Fragment 文件会由线程池定期检查并且 merge。 • 实时数据的查询结果等于两者的合并的结果。 18
19 . Local Segment Cache 19
20 . Local Segment Cache Format 20
21 . 实时数据进⼊历史部分 • 取决于 Retention Policy 的设置 • 当设置为 Full Build 时, Immutable 的segment 会被上传到 HDFS, 等到全部 Replica Set 上传完毕时,Coordinator 会进行 cube building,通过 MapReduce/Spark 将上传到HDFS 的 segment cache 转换为 HFile 保存到 HBase; • 当设置为Purge后,本地的 segment 将被定期删除,没有上传和构建动 作。 • 构建步骤: • Merge dictionary 21 • Convert to base cuboid from columnar record
22 . Streaming Query • 根据查询条件来确定是否需要查询历史和实时这两部分: • 对历史部分的查询来自于所有状态为 Ready 的 Segment,并记录历史 部分最晚时间戳 • 对实时部分的查询来自于 Receiver 集群,时间条件限制到历史部分最晚 时间戳以后 • 对于单个 Cube,查询将尽可能查询固定的 Receiver 22
23 . Rebalance and Re-assign • Assignment 是一个[Replica Set -> Partition List] 的结构,指定某个 Replica Set 应该消费哪些 Partition • 当单位时间数据量产生发生很大变化,或者 Partition 数量增加,或者增加了 Replica Set,这时需要重新调整 Assignment,让 Partition 的分配更加均 匀,使得每个 Receiver 都处于消费压力相当的状态 • Rebalance 过程是一个比较复杂的分布式事务,中间涉及到集群的暂停,记 录 checkpoint,调整 Receiver 负责的 partition,和重新启动等若干步骤, 23
24 . 启⽤ Lambda Mode • 什么是 Lambda Mode? • 允许同时从 Kafka 和 Hive 构建 segment • 允许在 Hive 中对数据做二次 ETL,确保准确性;同时结合 Kafka 弥补 实时数据 • 如何在 Kylin 中开启 Lambda • 创建一个 Hive 表,要求包含全部 Kafka Topic 的字段 • 创建Streaming Table,勾选 “lambda” • 创建Cube时,Retention Policy 可以选中为Full Build或者Purge • 定期从 Hive 构建(经过ETL处理后的) 24 • 从 Hive 构建的 segment 可以覆盖从 Kafka 构建出来的 segment
25 .实时部分基于列存和倒排索引,延迟为秒级别 数据延迟五分钟以上,有很多⼩的 Hadoop Job,浪费资源 额外部署⼀个分布式计算和存储集群,有学习/ Kylin 仅仅作为客户端,借助于MapReduce 维护/管理成本 稳定性,以较低的代价达到较好的稳定性 Real-time Streaming VS NRT Streaming 不⽀持某些度量(如TOPN); ⽀持 JOIN 维度表,⽀持所有现有度量 不⽀持 JOIN 维度表 25
26 . Case of 3 Real-time OLAP 26
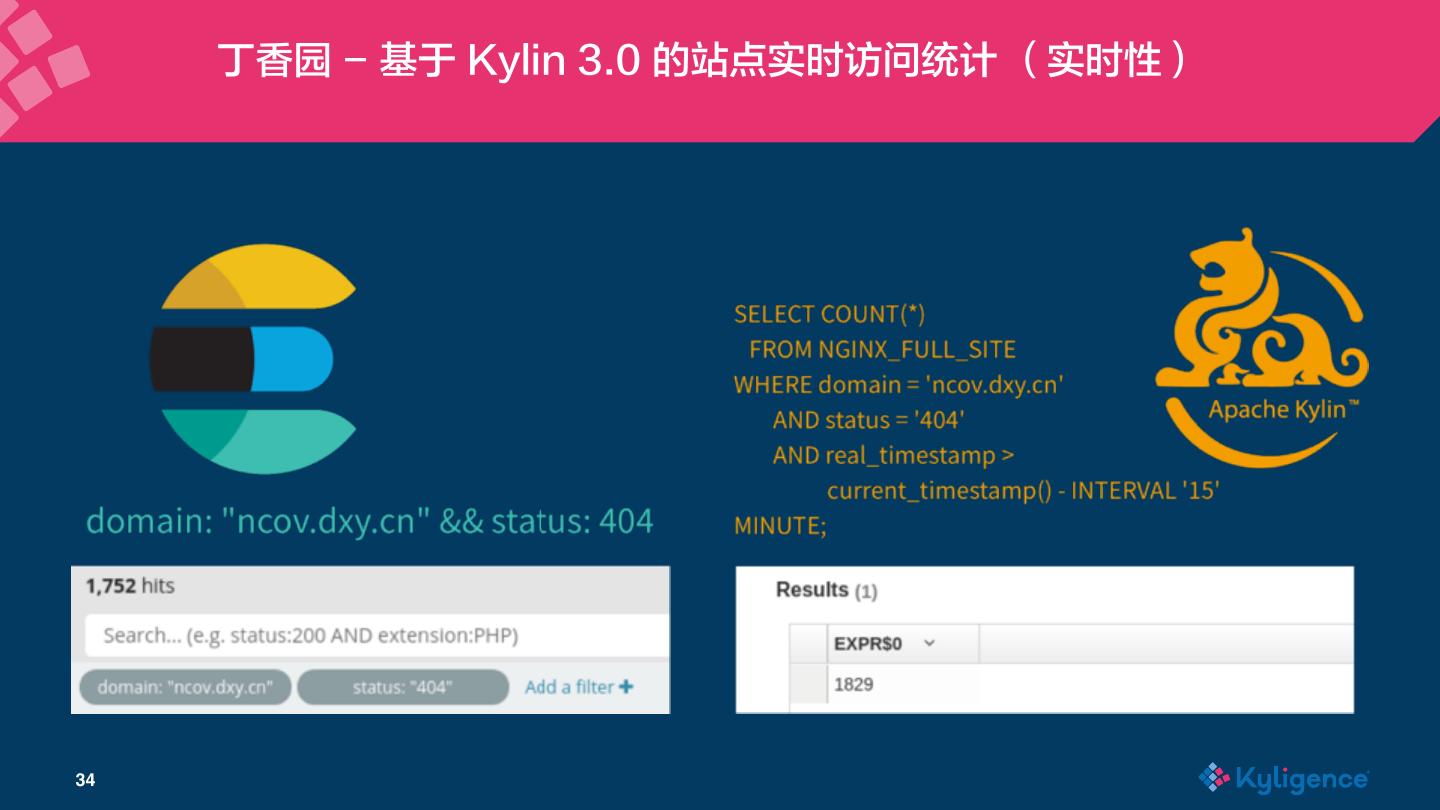
27 . 丁香园 - 基于 Kylin 3.0 的站点实时访问统计 27
28 . 丁香园 - 基于 Kylin 3.0 的站点实时访问统计 28
29 . 丁香园 - 基于 Kylin 3.0 的站点实时访问统计 29
3秒后跳转登录页面
去登陆

