
























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
2020.01, 北京Meetup 2019. Apache IoTDB的前世今生与技术细节. Reporter Xiangdong Huang
展开查看详情
1 .IoTDB的前世今生 与技术细节揭秘 2019-01-04 SPEAKER 演讲
2 .黄向东 清华大学 软件学院 大数据系统软件国家工程实验室
3 . 目录/Contens 1.工业场景下的时序数据库需求 2.从Cassandra到IoTDB 3. IoTDB的单机千万点写入性能实现
4 .工业场景下的时序 数据库需求
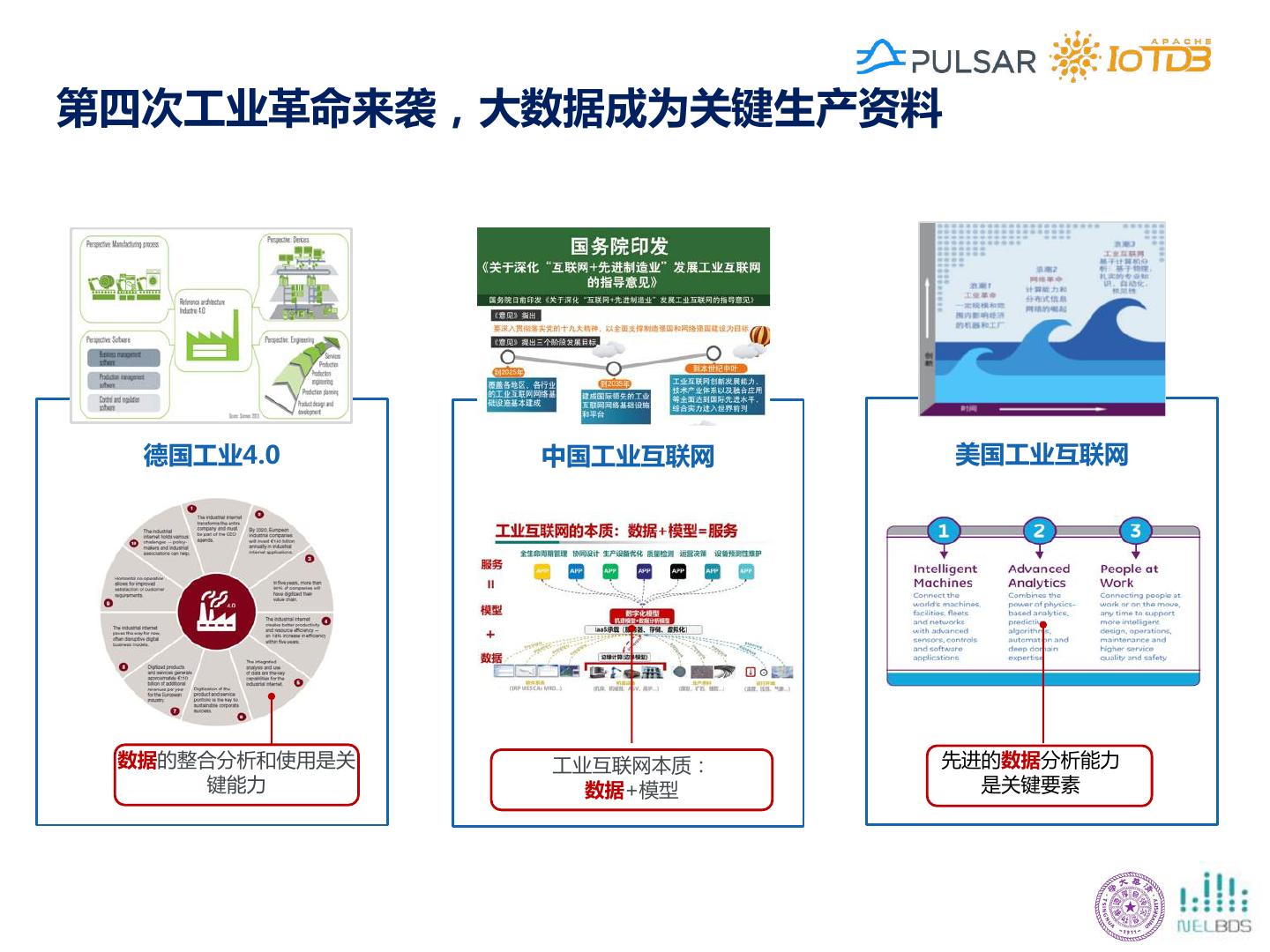
5 .第四次工业革命来袭,大数据成为关键生产资料 德国工业4.0 中国工业互联网 美国工业互联网 数据的整合分析和使用是关 工业互联网本质: 先进的数据分析能力 键能力 数据+模型 是关键要素
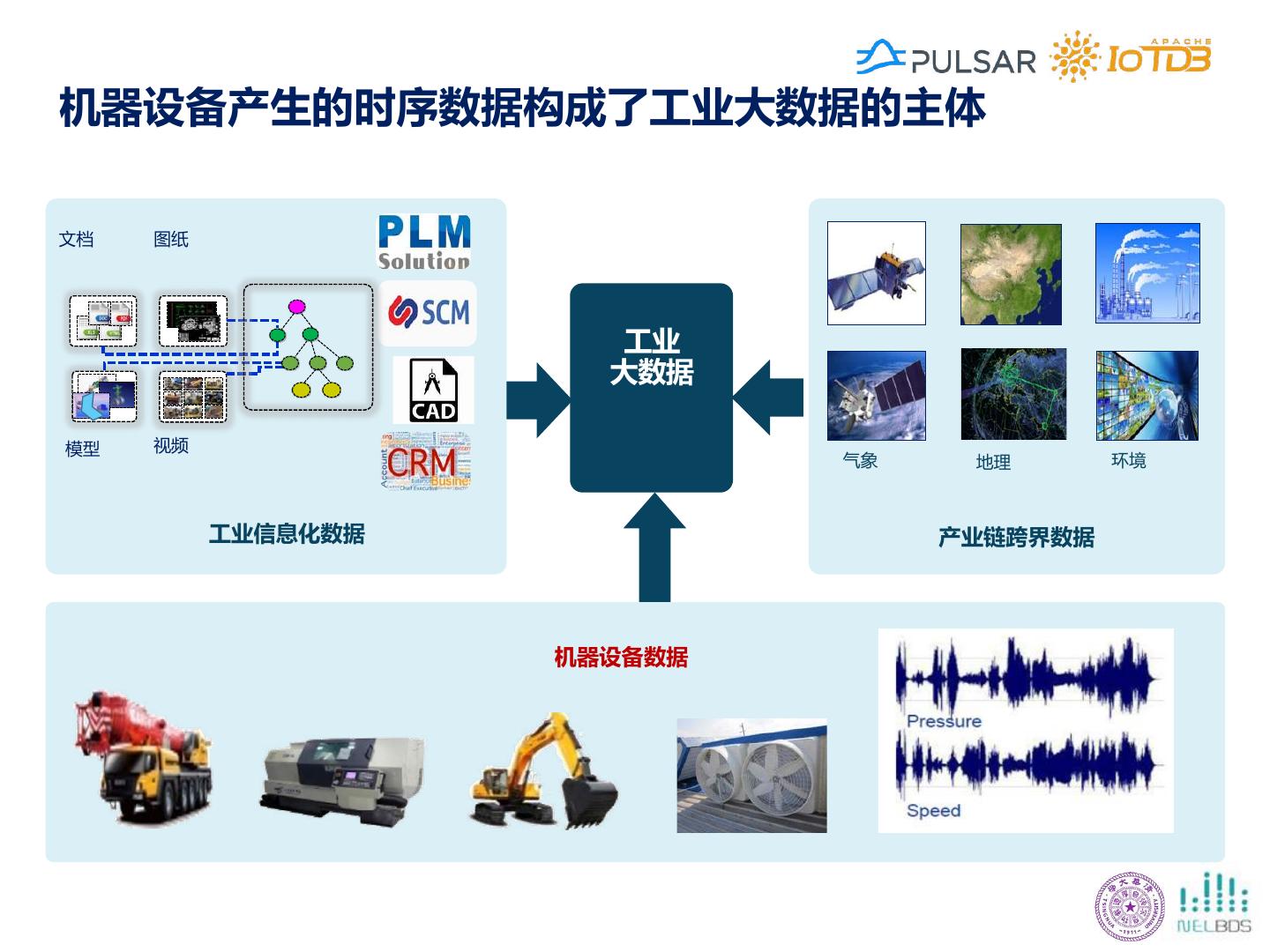
6 .机器设备产生的时序数据构成了工业大数据的主体 文档 图纸 工业 大数据 模型 视频 气象 地理 环境 工业信息化数据 产业链跨界数据 机器设备数据
7 .时间序列数据普遍存在 无人驾驶 穿戴设备 在设备远程运维、数字画像、健康评估、故障预测、备件调度、生产工艺控制与改进等多方面有着重要的应用前景
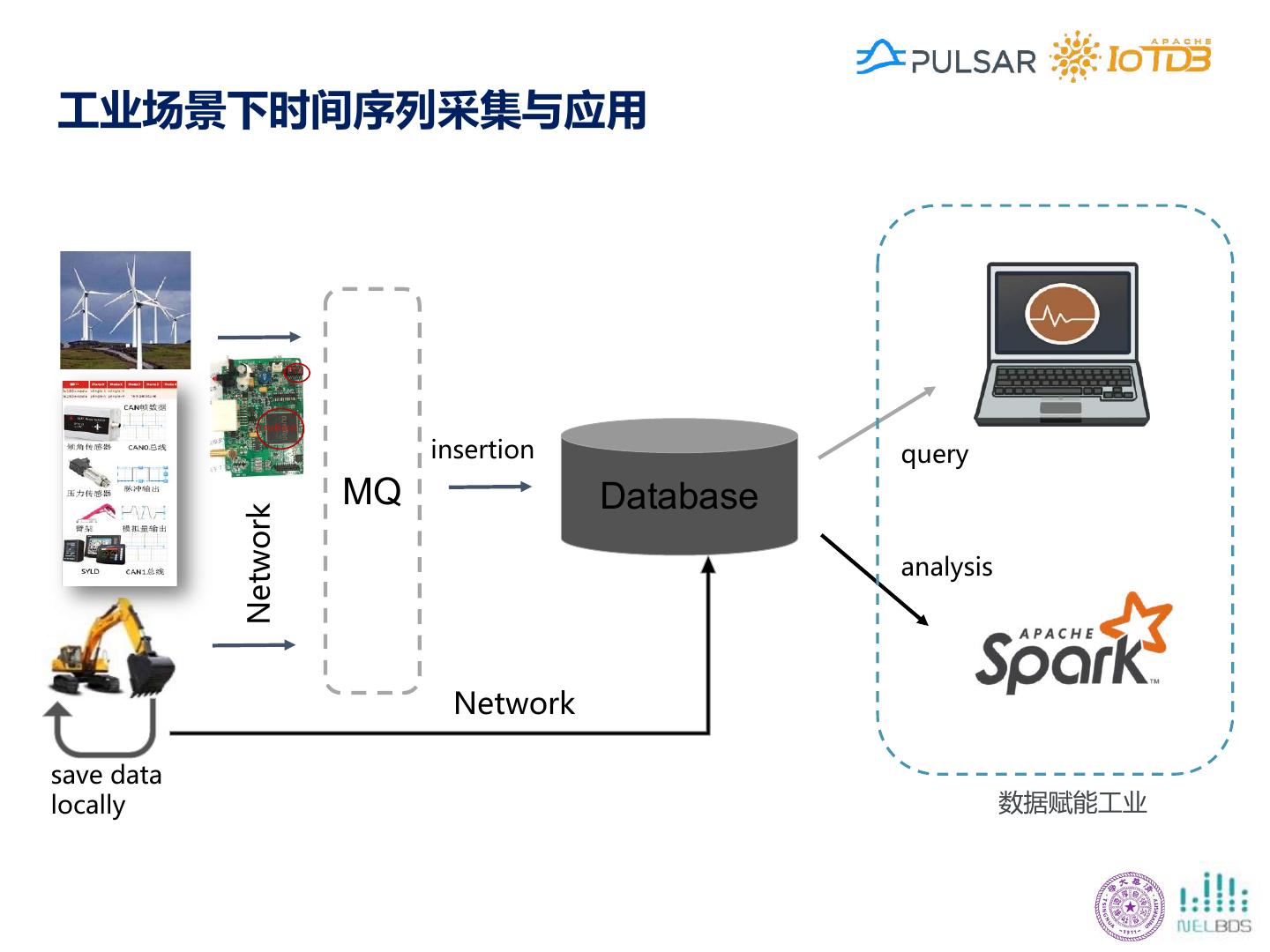
8 .工业场景下时间序列采集与应用 CPU insertion query MQ Database Network analysis Network save data locally 数据赋能工业
9 .How to Manage Time Series Data insertion query Network MQ Database analysis Network save data locally
10 .需求与挑战:提升工业时序数据利用率,从有效存储开始 大规模时序数据的特点 占用空间极大 数据总吞吐量大 时序数据存储的需求 产生速度快且不间断 【全时全量】 保证数据全时全量存储 【高效写入】 保证数据库可以承受高吞吐写入 【紧凑存储】 对数据进行有效压缩减少磁盘空间占用 超过20,000个风机 一个风机约有120~510传感器 采集频率从0.00167 Hz 到 50Hz 不等
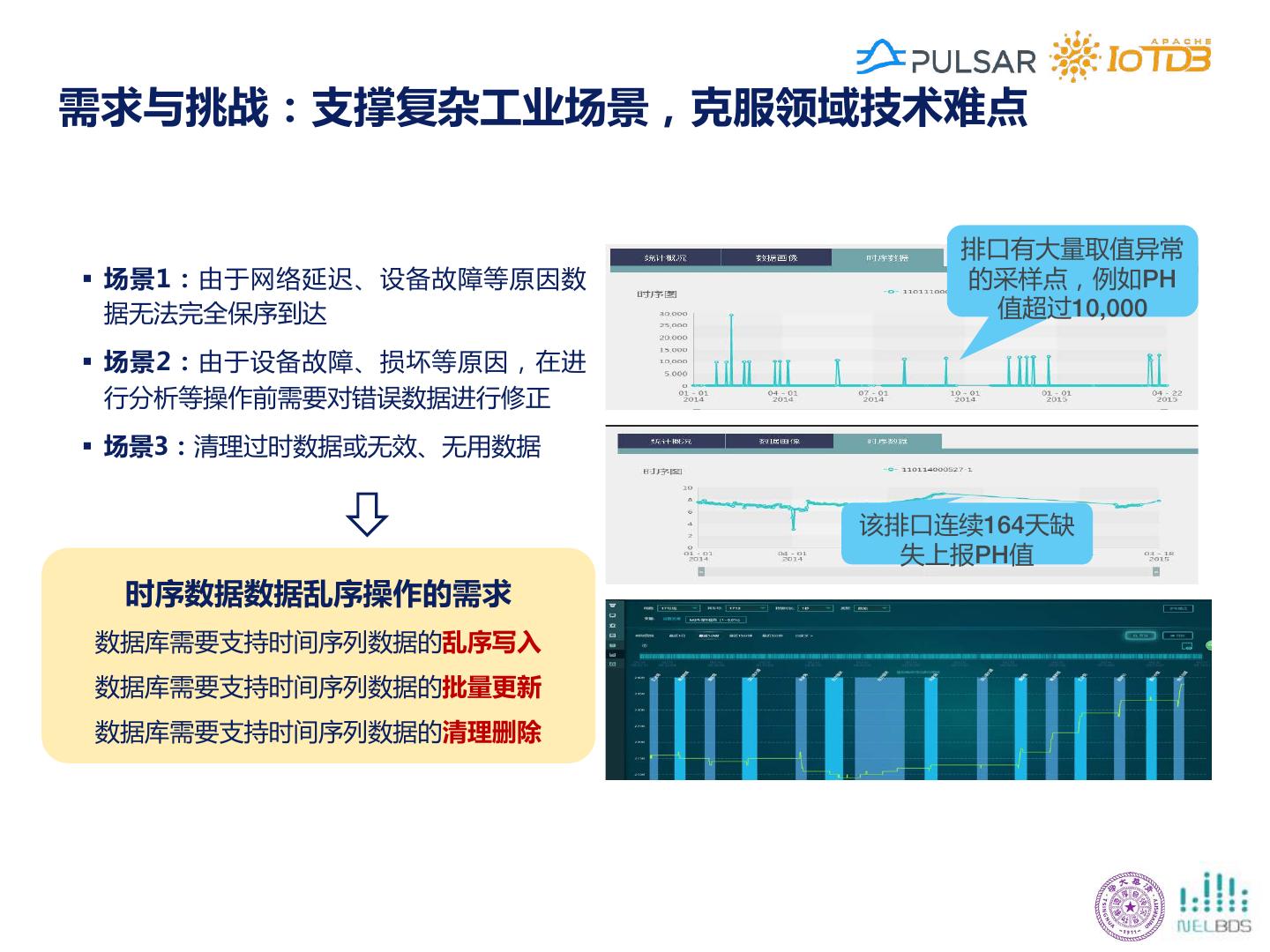
11 .需求与挑战:支撑复杂工业场景,克服领域技术难点 排口有大量取值异常 § 场景1:由于网络延迟、设备故障等原因数 的采样点,例如PH 据无法完全保序到达 值超过10,000 § 场景2:由于设备故障、损坏等原因,在进 行分析等操作前需要对错误数据进行修正 § 场景3:清理过时数据或无效、无用数据 该排口连续164天缺 失上报PH值 时序数据数据乱序操作的需求 数据库需要支持时间序列数据的乱序写入 数据库需要支持时间序列数据的批量更新 数据库需要支持时间序列数据的清理删除
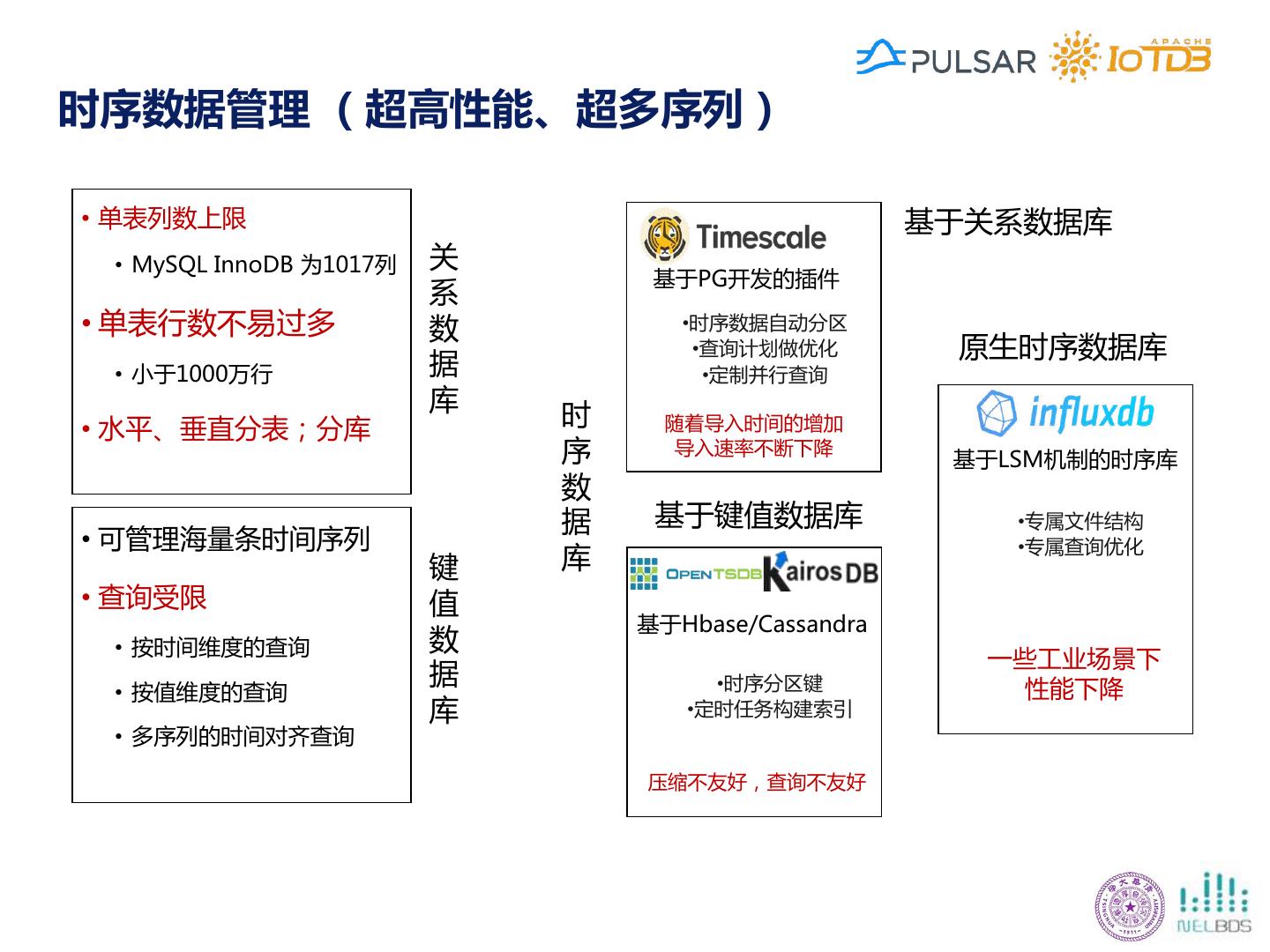
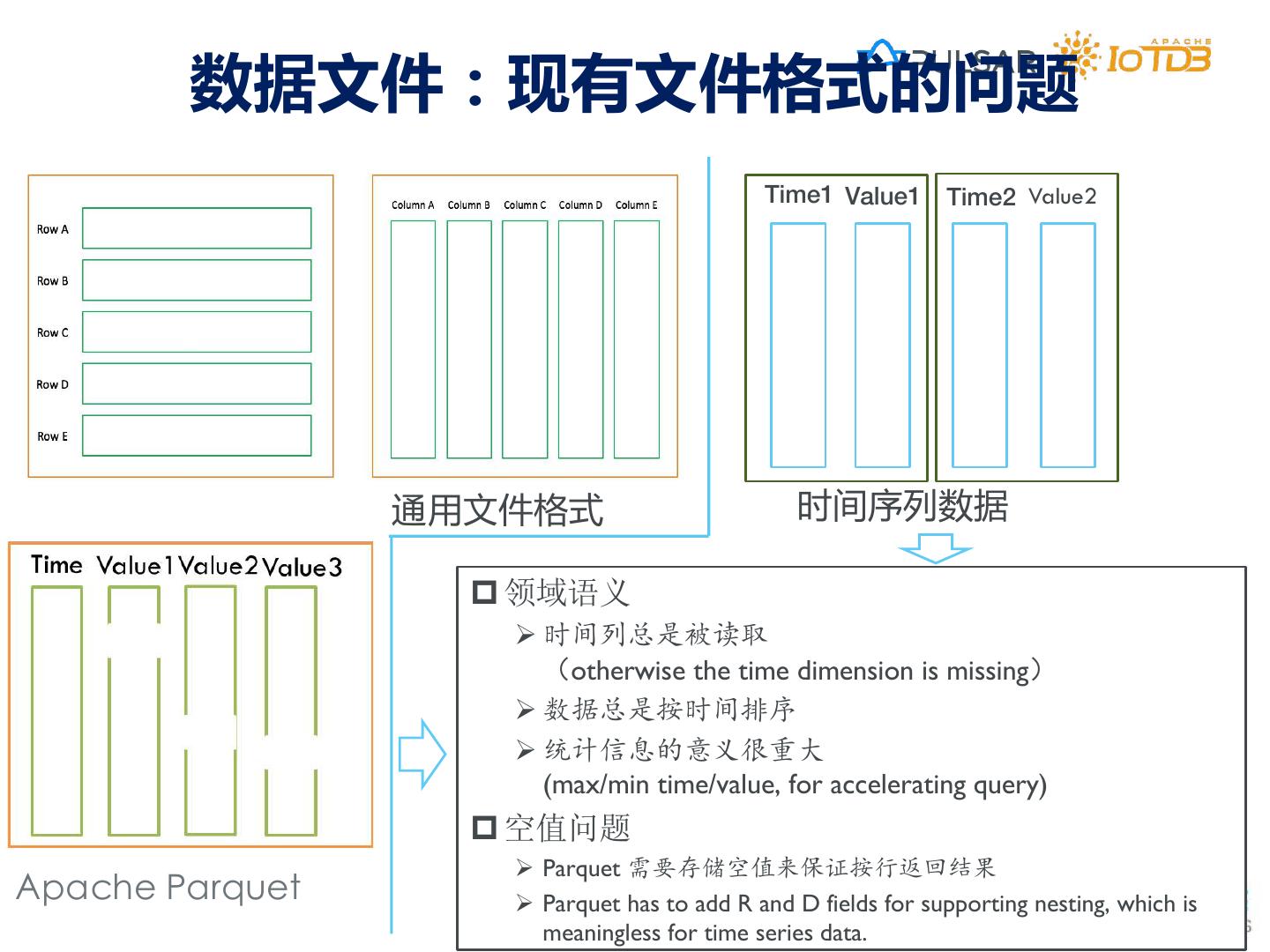
12 .时序数据管理 (超高性能、超多序列) • 单表列数上限 基于关系数据库 • MySQL InnoDB 为1017列 关 基于PG开发的插件 系 • 单表行数不易过多 数 •时序数据自动分区 •查询计划做优化 原生时序数据库 • 小于1000万行 据 •定制并行查询 库 • 水平、垂直分表;分库 时 随着导入时间的增加 序 导入速率不断下降 基于LSM机制的时序库 数 据 基于键值数据库 •专属文件结构 • 可管理海量条时间序列 •专属查询优化 键 库 • 查询受限 值 基于Hbase/Cassandra • 按时间维度的查询 数 一些工业场景下 据 •时序分区键 性能下降 • 按值维度的查询 库 •定时任务构建索引 • 多序列的时间对齐查询 压缩不友好,查询不友好
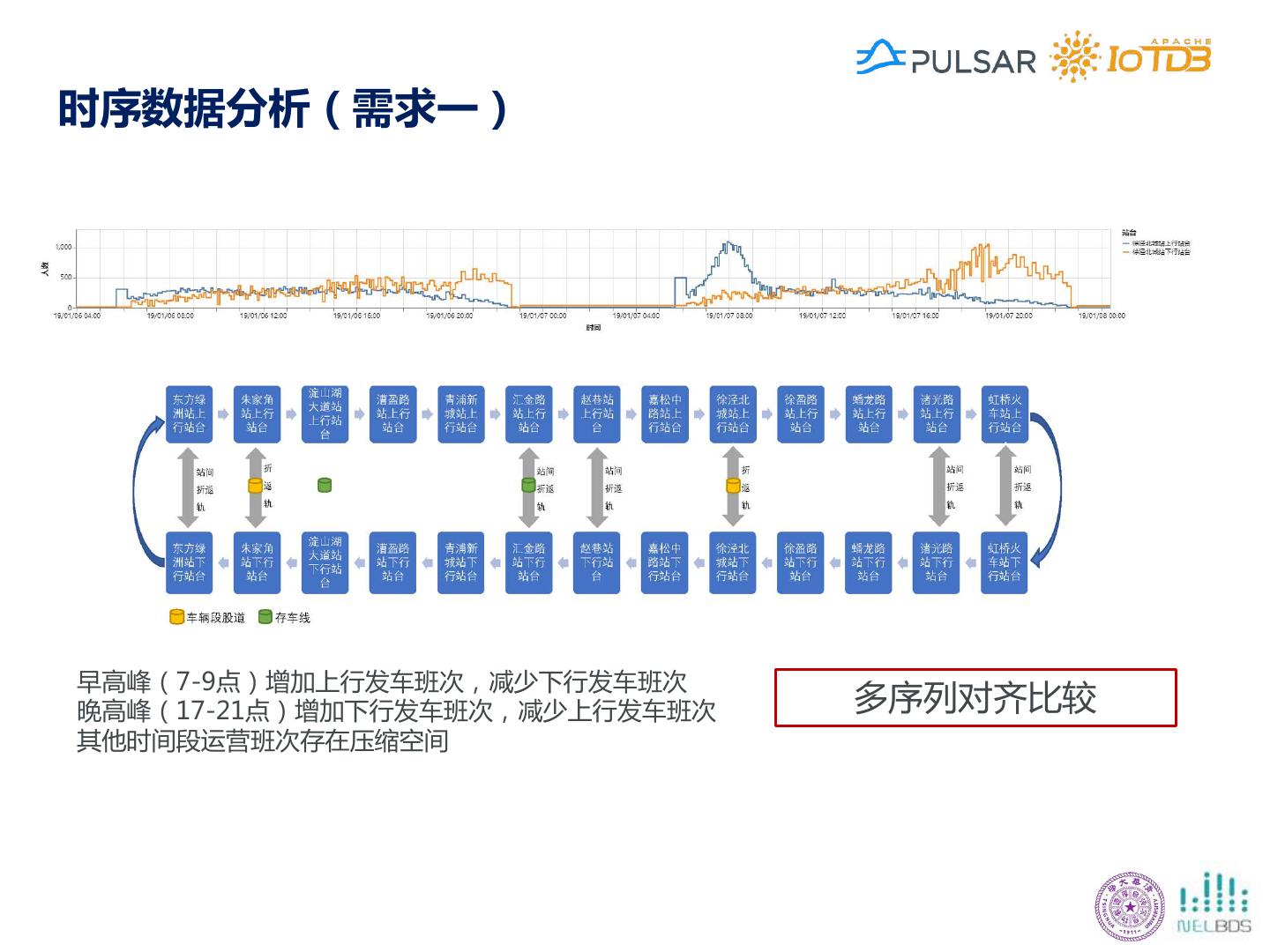
13 .时序数据分析(需求一) 早高峰(7-9点)增加上行发车班次,减少下行发车班次 晚高峰(17-21点)增加下行发车班次,减少上行发车班次 多序列对齐比较 其他时间段运营班次存在压缩空间
14 .时序数据分析(需求二) 时间序列HMM分割算法 中等风没满转 超大风满转 准确计算各站点人流量 大风满转 超低风0转 低风低转速(下降) 准确计算各状态下的统计值 低风低转速(稳定) 时间序列分割
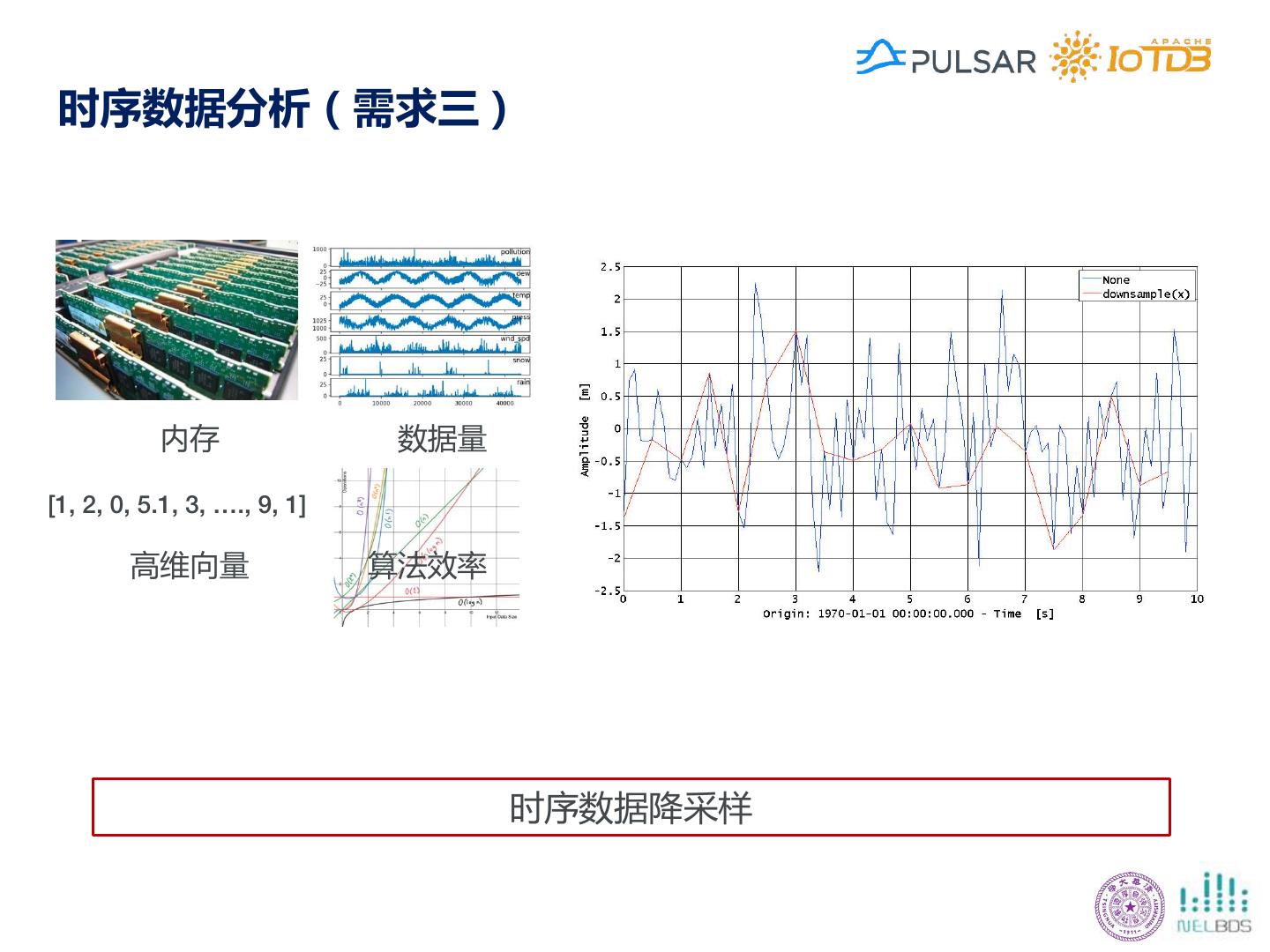
15 . 时序数据分析(需求三) 内存 数据量 [1, 2, 0, 5.1, 3, …., 9, 1] 高维向量 算法效率 时序数据降采样
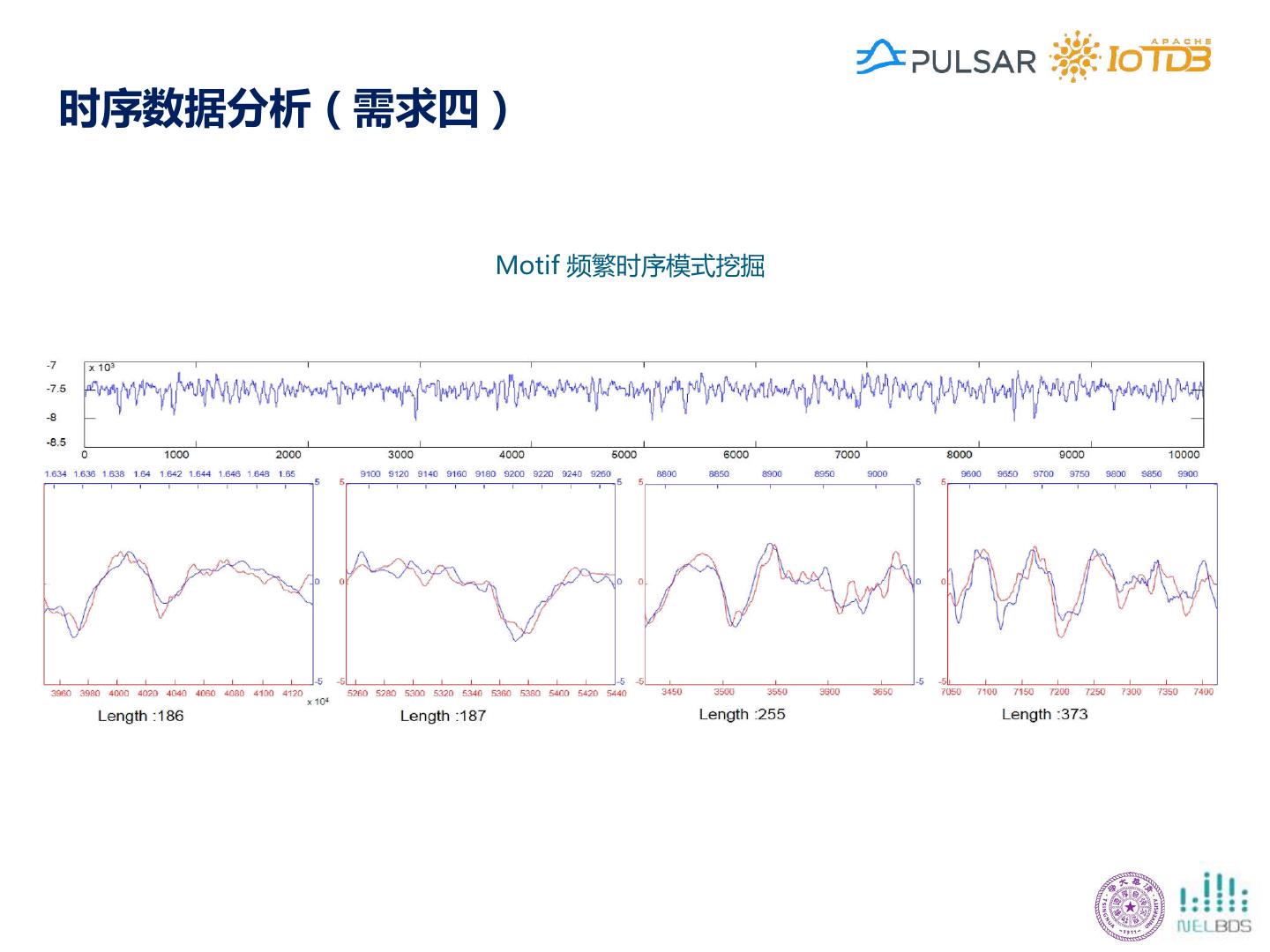
16 .时序数据分析(需求四) Motif 频繁时序模式挖掘
17 .时序数据分析(性能) analysis insertion Database ETL • 查询友好 • 分析友好 • 写入友好 KairosDB:导出每辆车每天3000种的数据:1小时 气象大数据系统:大量时间花费在数据获取上 批量使用历史数据,漫长的ETL
18 .需求与挑战:面向工业应用场景,提升数据处理能力 高通量写入 高效压缩 指定查询过滤条件 查询延迟低、时效高 按时间、设备、传感器类型等过滤 TB 级数据百毫秒查询 聚合查询数据 模式匹配 十亿点数数十毫秒查询 Say No to ETL 序列对齐查询 时序分割 多序列按时间维度对齐 序列填充查询 数字水印 空值填充
19 .从Cassandra到IoTDB
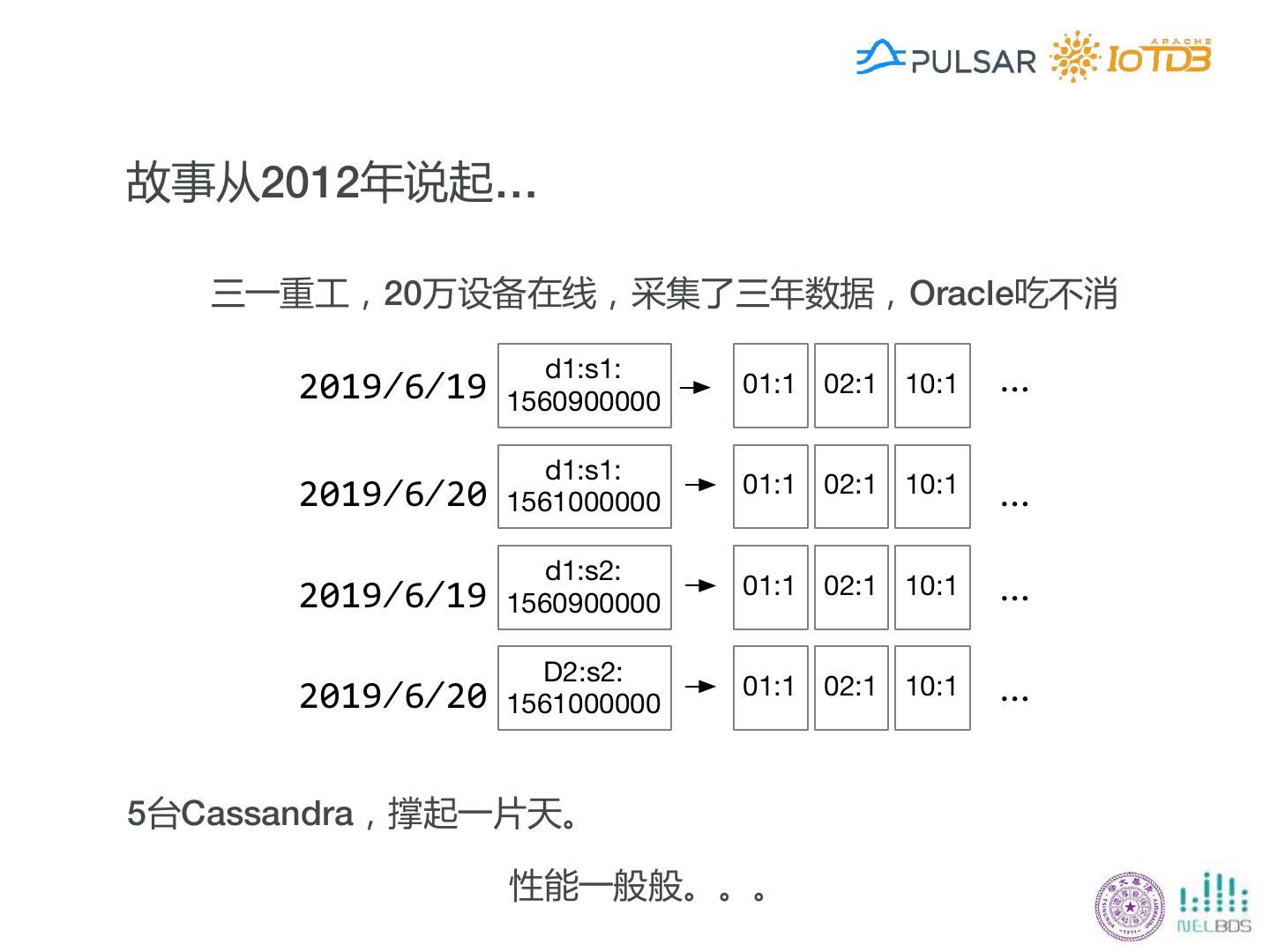
20 .故事从2012年说起… 三一重工,20万设备在线,采集了三年数据,Oracle吃不消 d1:s1: 01:1 02:1 10:1 1560900000 d1:s1: 01:1 02:1 10:1 1561000000 d1:s2: 01:1 02:1 10:1 1560900000 D2:s2: 01:1 02:1 10:1 1561000000 5台Cassandra,撑起一片天。 性能一般般。。。
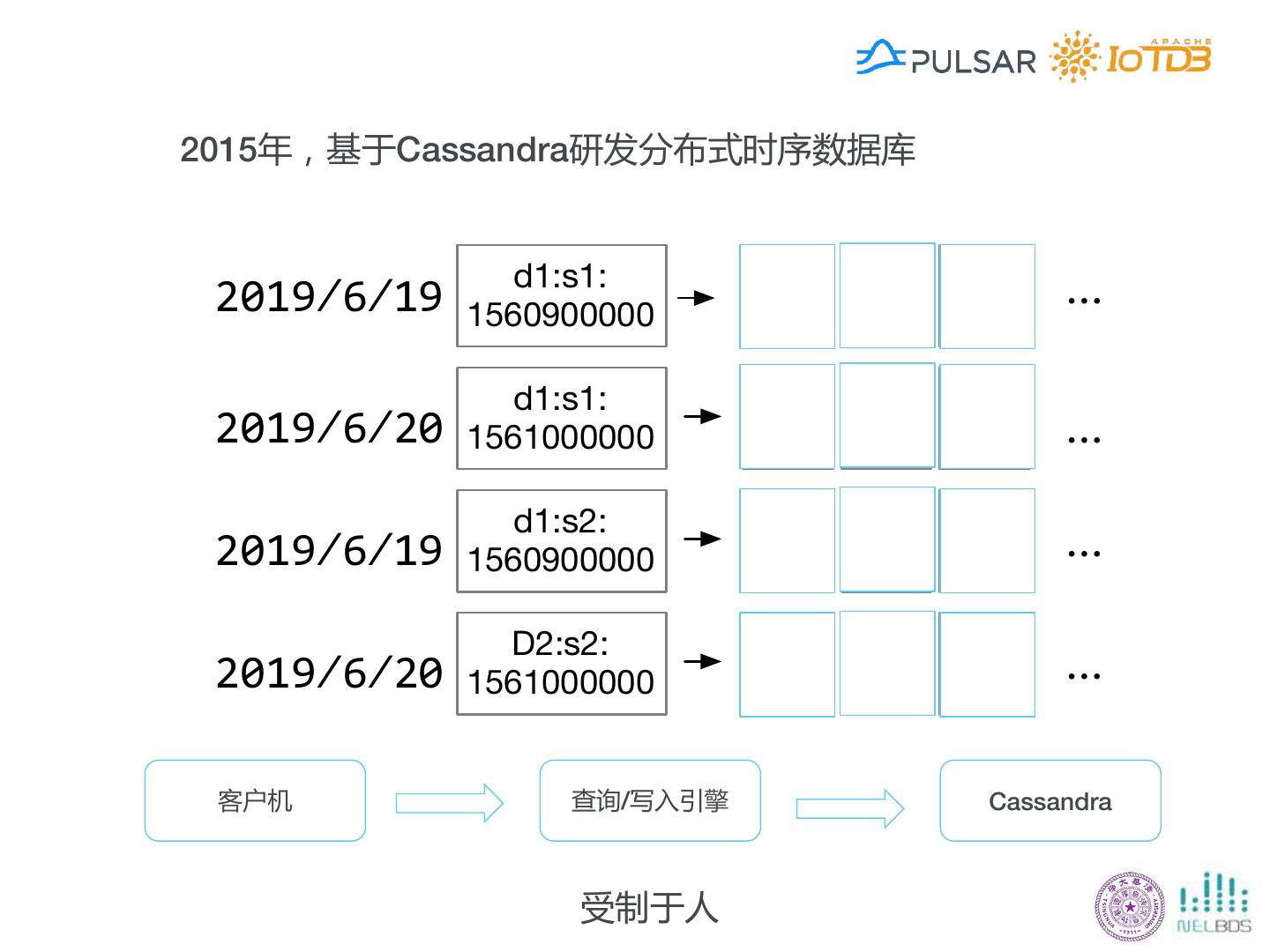
21 .2015年,基于Cassandra研发分布式时序数据库 d1:s1: 01:1 02:1 10:1 1560900000 d1:s1: 01:1 02:1 10:1 1561000000 d1:s2: 01:1 02:1 10:1 1560900000 D2:s2: 01:1 02:1 10:1 1561000000 客户机 查询/写入引擎 Cassandra 受制于人
22 .撸起袖子加油干 高效存储数据 实时读写数据 分布式HTAP
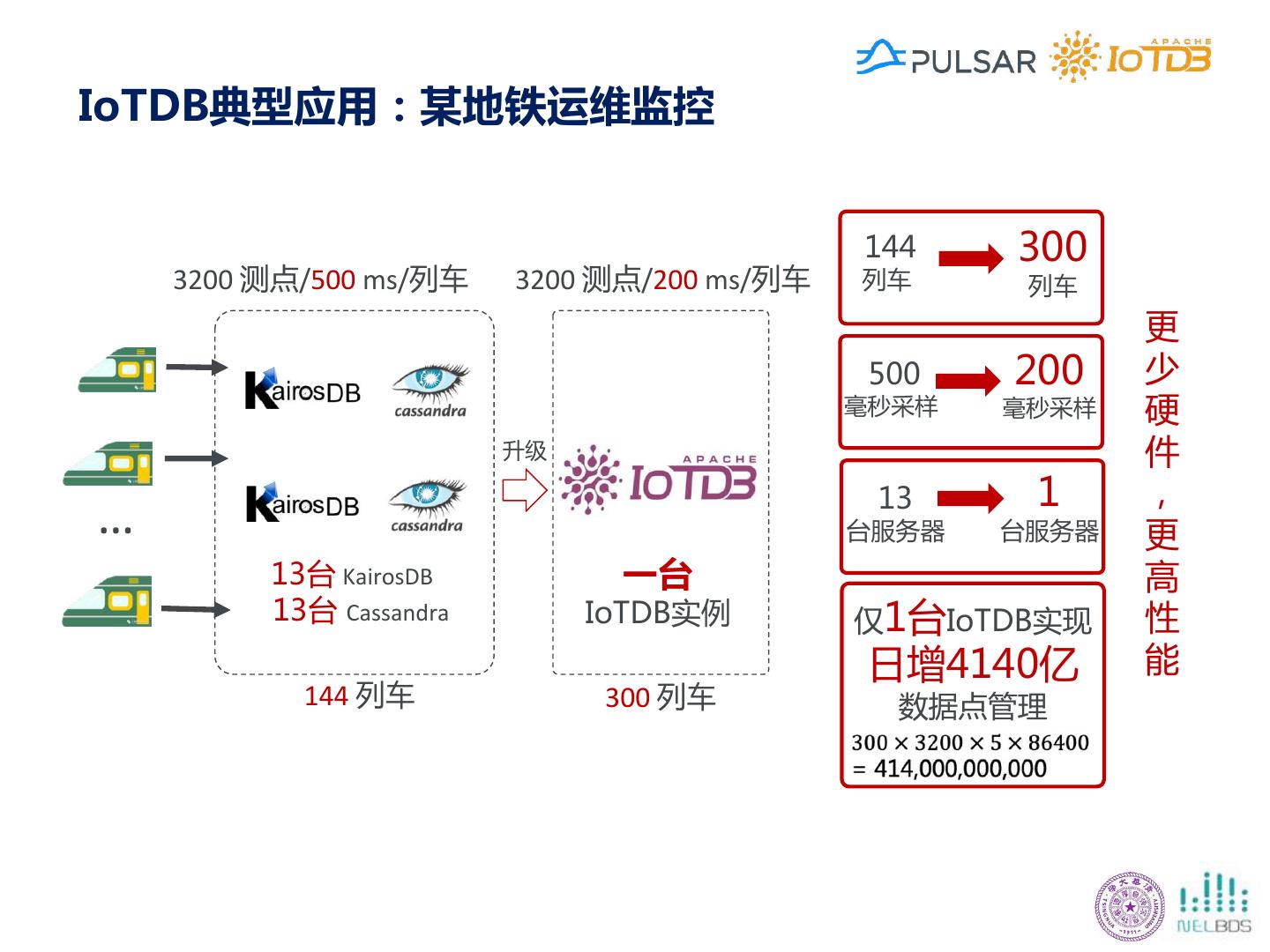
23 .面向工业互联网的高性能轻量级时序数据库 清华数为工业互联网时序数据库 Apache IoTDB 中国高校唯一Apache基金会项目 – 工业领域千万条量级时间序列管 – 单节点万亿数据点管理 – 单节点数十TB级时间序列数据管理 – 支持Hadoop、Spark、Matlab、 Grafana等多种生态
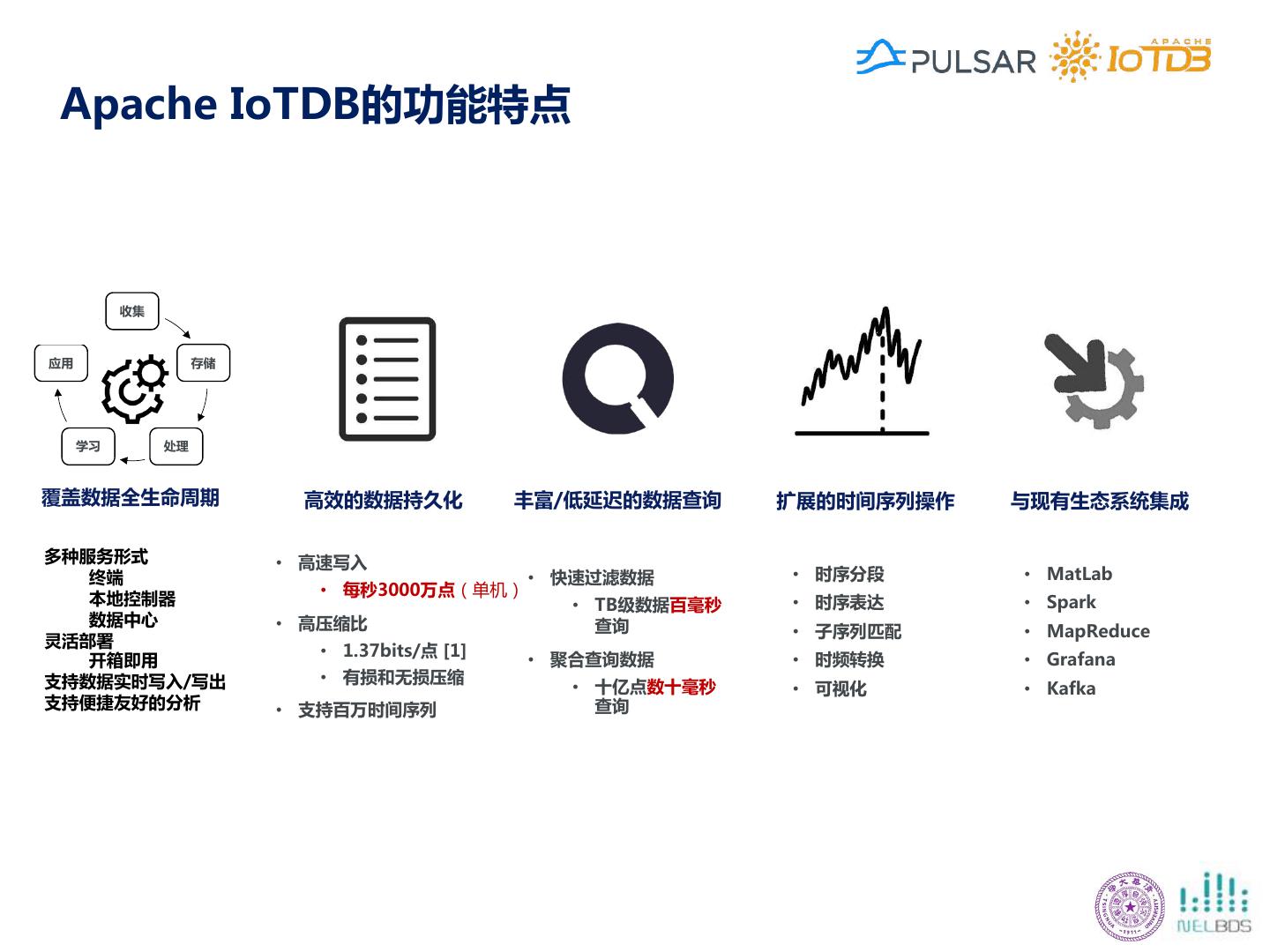
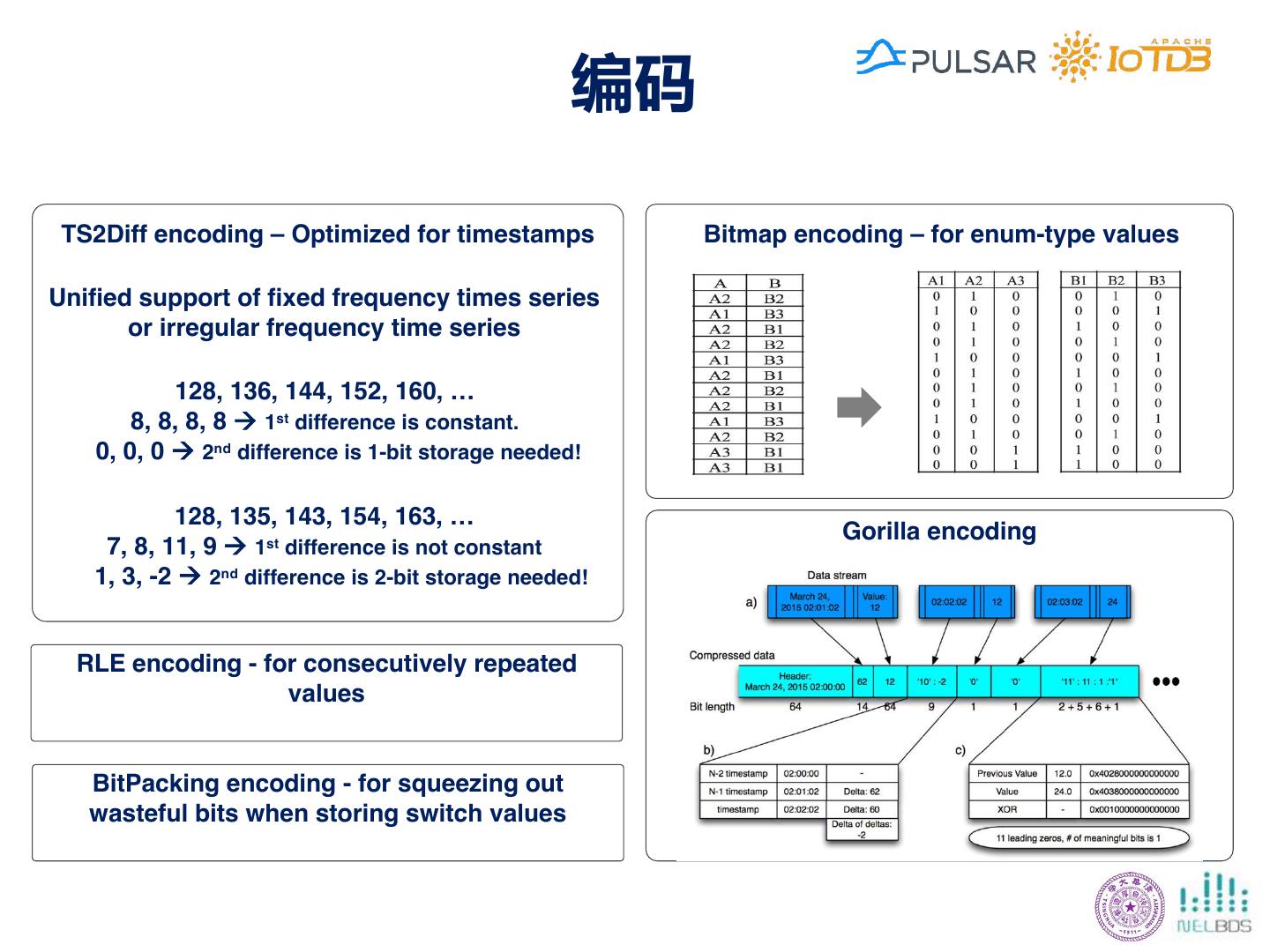
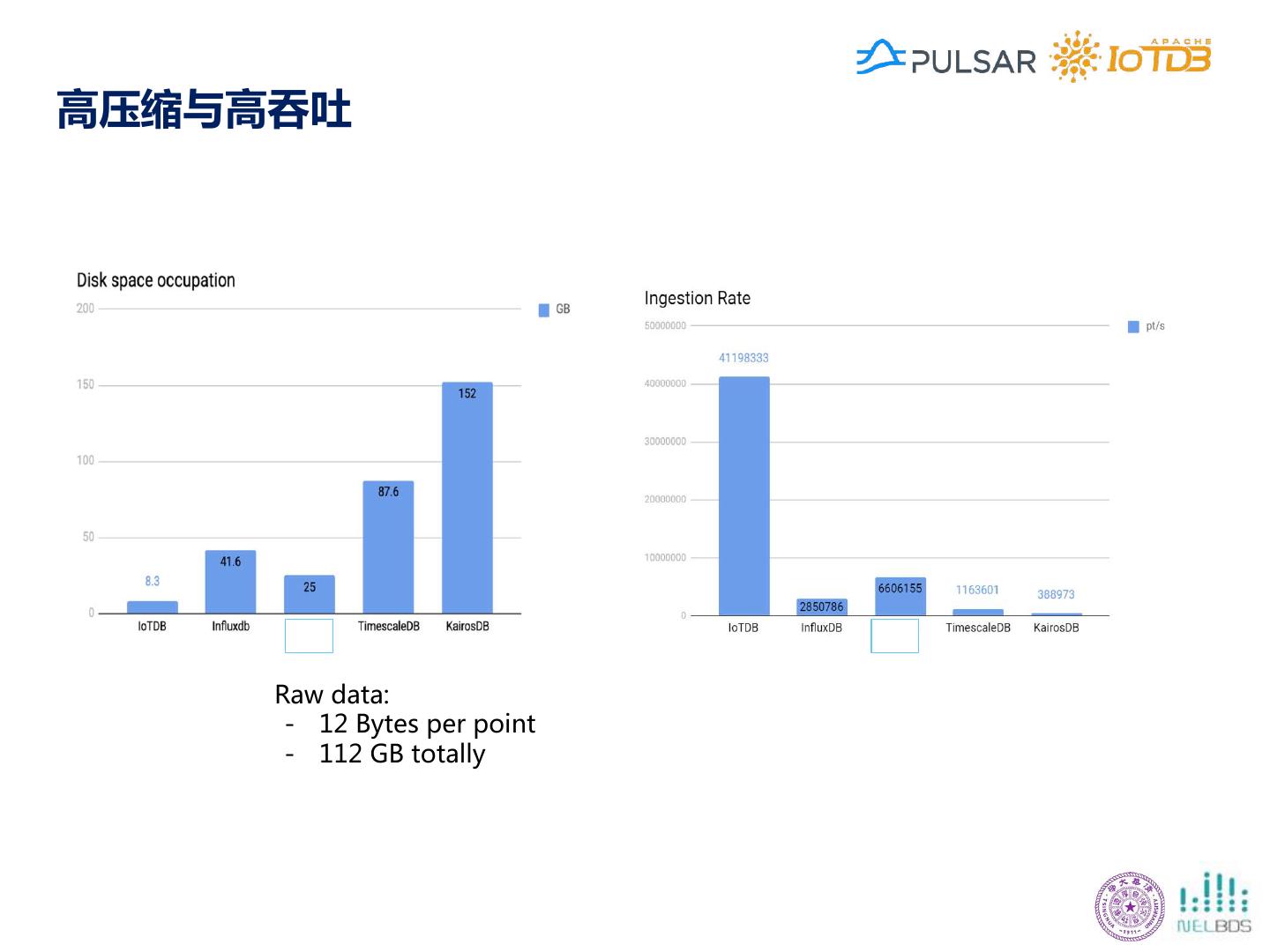
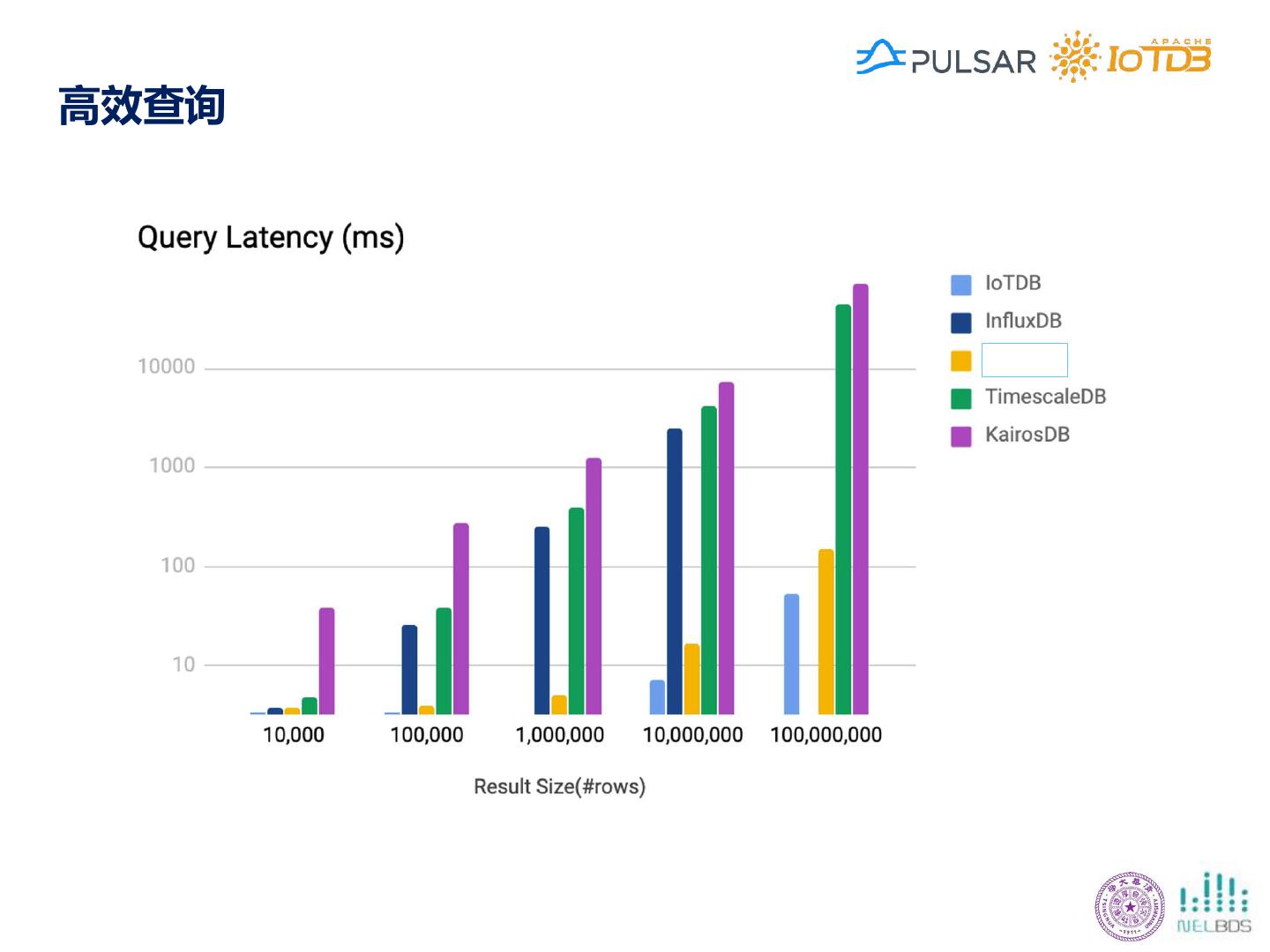
24 .Apache IoTDB的功能特点 收集 应用 存储 学习 处理 覆盖数据全生命周期 高效的数据持久化 丰富/低延迟的数据查询 扩展的时间序列操作 与现有生态系统集成 多种服务形式 • 高速写入 终端 • 快速过滤数据 • 时序分段 • MatLab • 每秒3000万点(单机) 本地控制器 • TB级数据百毫秒 • 时序表达 • Spark 数据中心 • 高压缩比 查询 • 子序列匹配 • MapReduce 灵活部署 • 1.37bits/点 [1] 开箱即用 • 聚合查询数据 • 时频转换 • Grafana 支持数据实时写入/写出 • 有损和无损压缩 • 十亿点数十毫秒 • 可视化 • Kafka 支持便捷友好的分析 • 支持百万时间序列 查询
25 .产品形态:灵活适配“云-网-端”计算环境 部署在嵌入式终端设备的时 部署在工控机等边缘计算设 部署在云端数据中心的 序“数据文件” 备的时序“数据库” 时序“数据仓库” 终端 场控 数据中心 为时序数据而生的zip文件 高效丰富的时间序列查询引 与大数据分析框架无缝集成 支持高性能写入,高压缩比 擎 支持时序数据处理,挖掘分 存储,支持简单查询 提供增删改查,以及聚合查 析与机器学习 询时序对齐等高级功能
26 .Integration with other systems Visualization Analysis with Matlab Big data analysis (Manual data explore) (small data set) 26
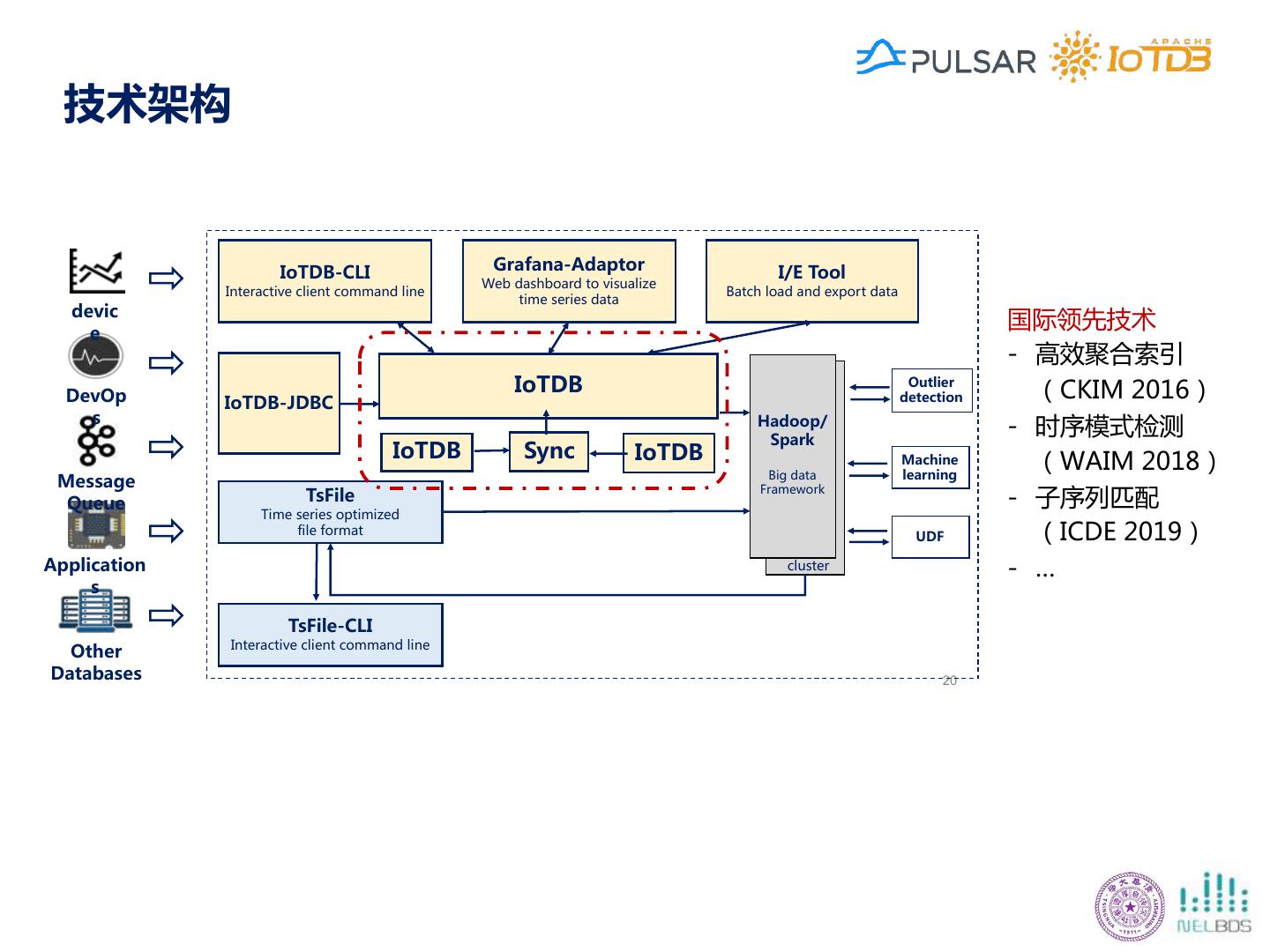
27 .技术架构 国际领先技术 - 高效聚合索引 (CKIM 2016) - 时序模式检测 (WAIM 2018) - 子序列匹配 (ICDE 2019) - … 20
28 .IoTDB的单机千万点 写入性能
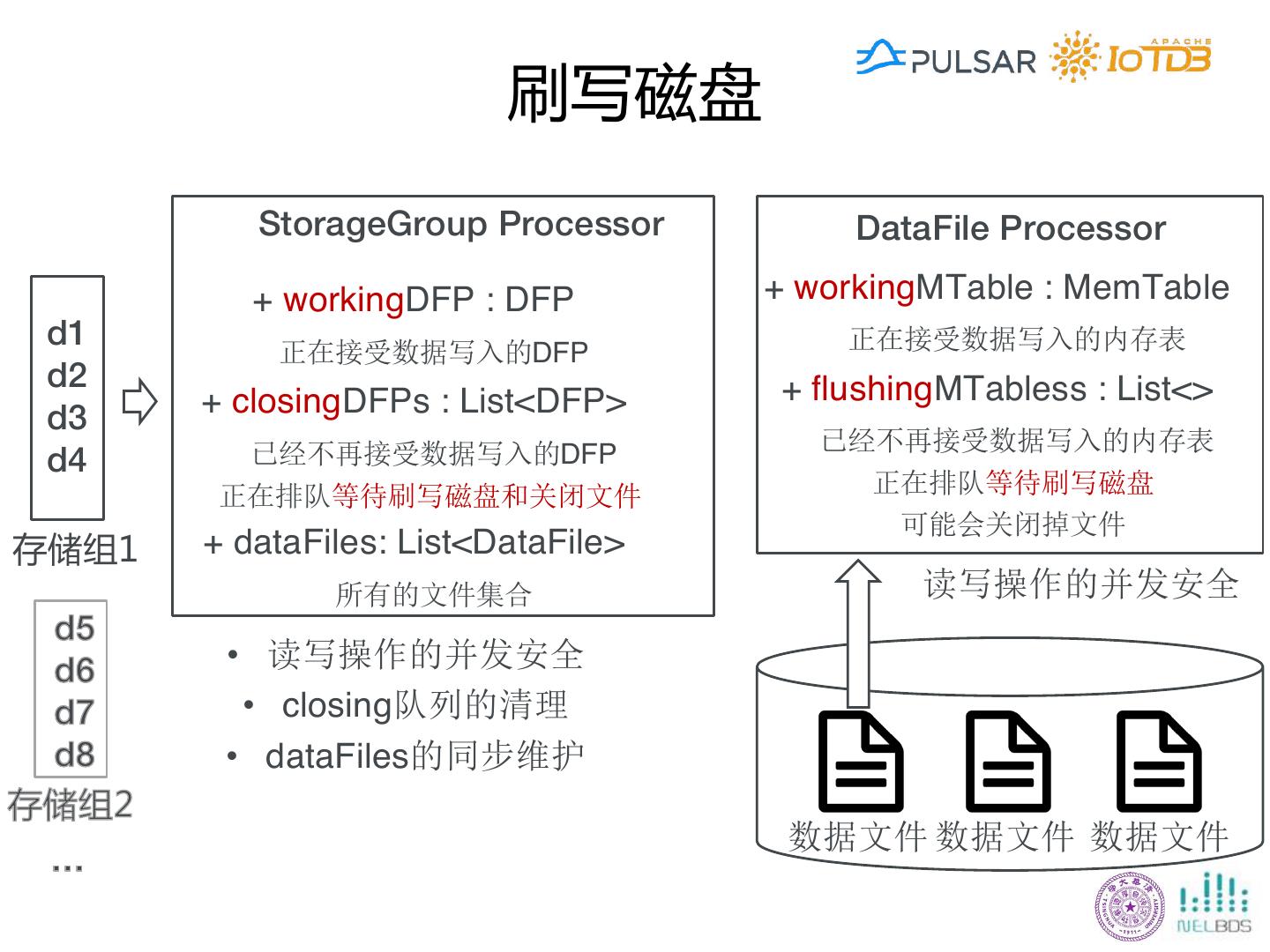
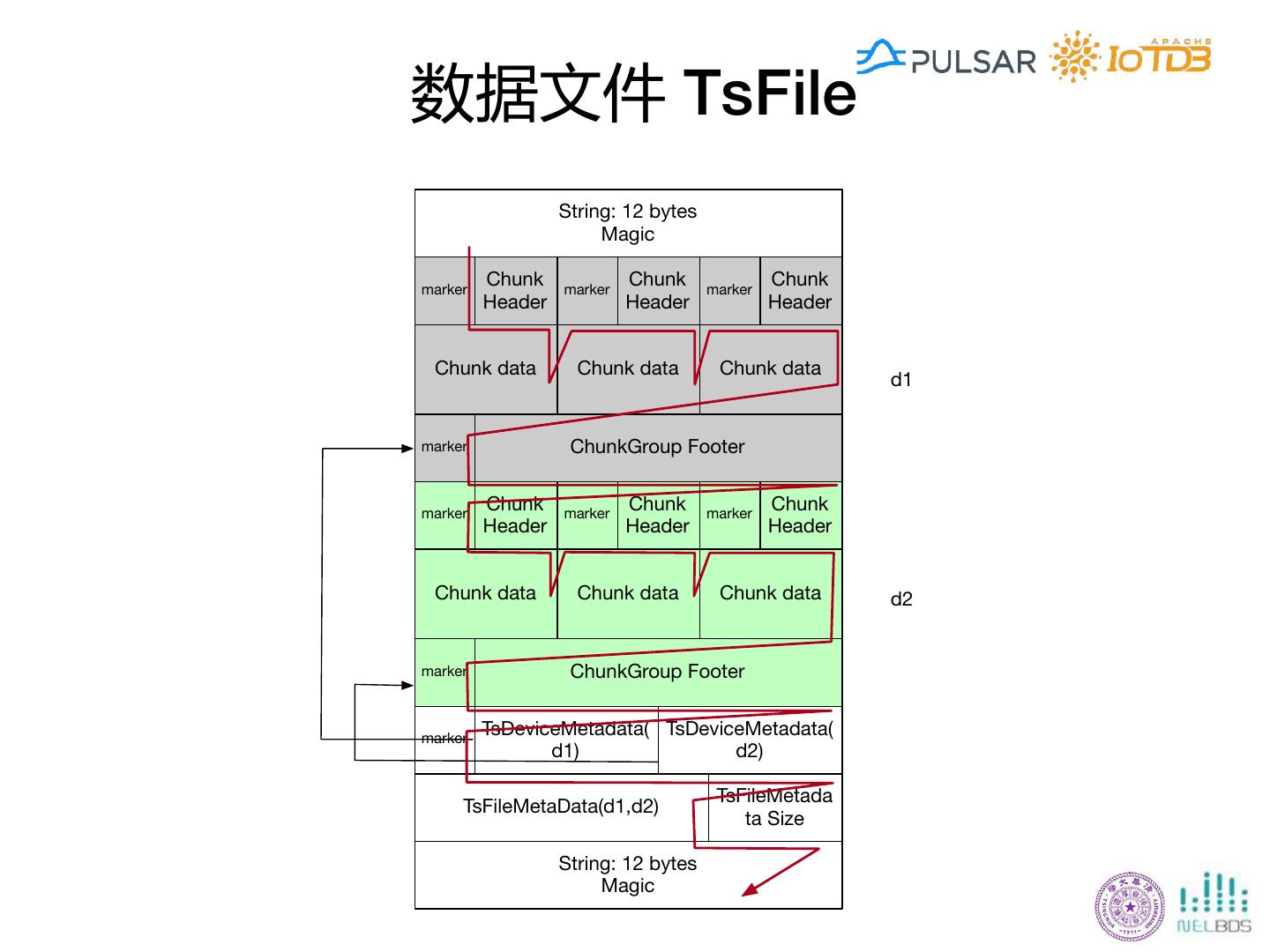
29 .简单理解IoTDB数据Schema Storage Group, Device, Measurement/Metric, <Time,Value>
3秒后跳转登录页面
去登陆

