











































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
2019.12, 大连Meetup 2019. Apache IoTDB 工业互联网时序数据库. Reporter Xiangdong Huang
展开查看详情
1 . Apache IoTDB 工业互联网时序数据库系统 清华大学 软件学院 大数据系统软件国家工程实验室 Apache IoTDB Team: Xiangdong Huang
2 . Outline • 为什么开发时序数据库系统 • IoTDB介绍 • 基于RocketMQ与IoTDB的应用示例
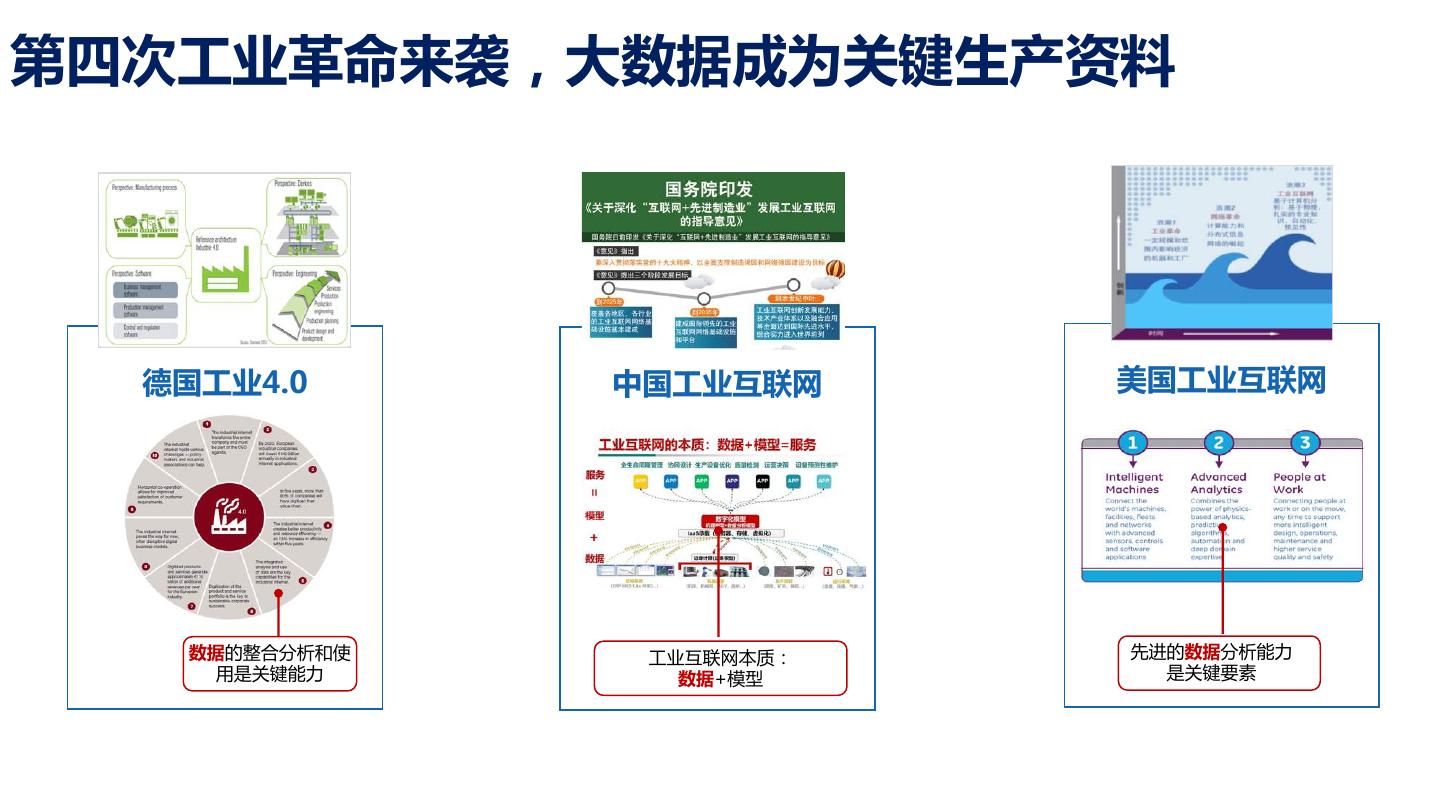
3 .第四次工业革命来袭,大数据成为关键生产资料 德国工业4.0 中国工业互联网 美国工业互联网 数据的整合分析和使 工业互联网本质: 先进的数据分析能力 用是关键能力 数据+模型 是关键要素
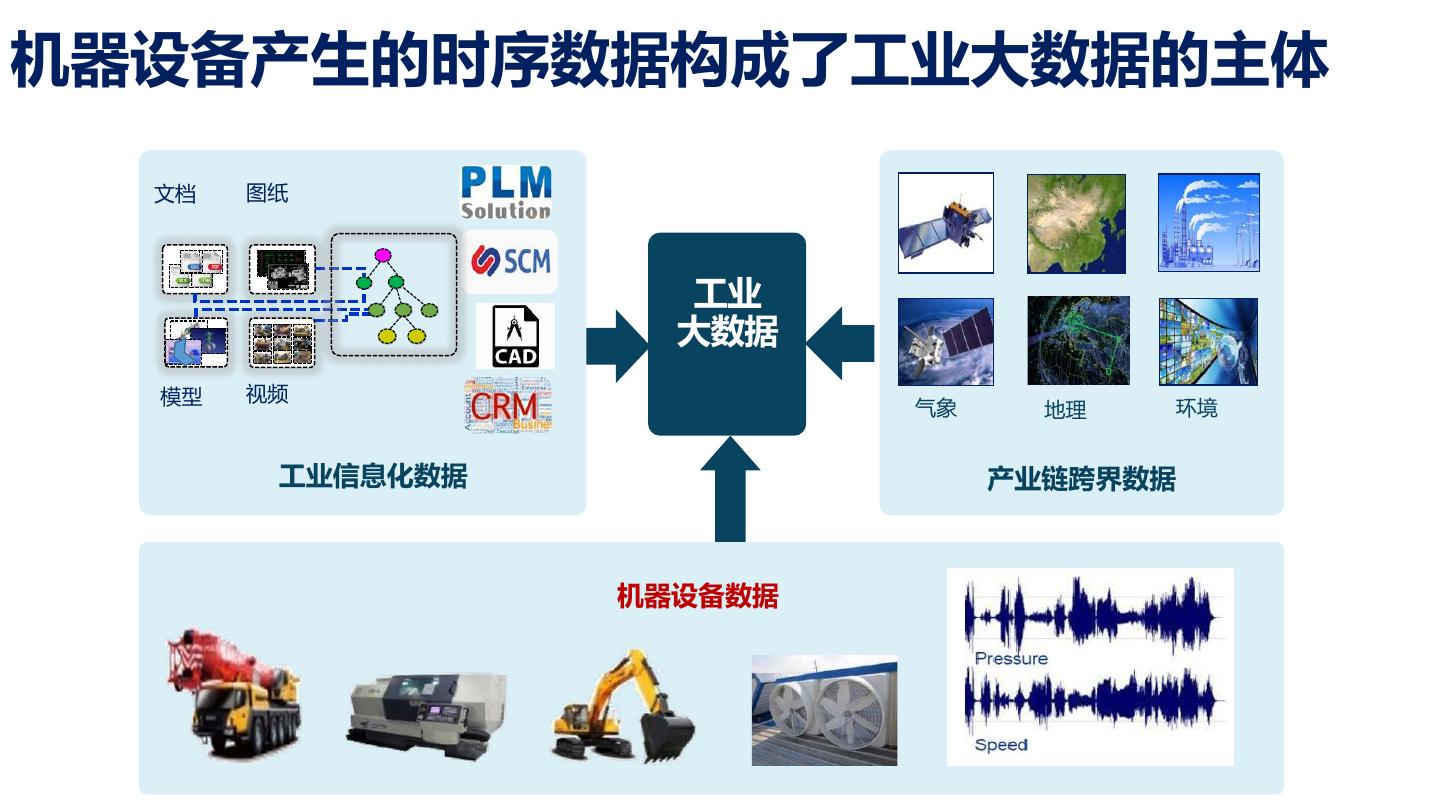
4 .机器设备产生的时序数据构成了工业大数据的主体 文档 图纸 工业 大数据 模型 视频 气象 地理 环境 工业信息化数据 产业链跨界数据 机器设备数据
5 .时间序列数据普遍存在 无人驾驶 穿戴设备 在设备远程运维、数字画像、健康评估、故障预测、备件调度、生产工艺控制与改进等多方面有着重要的应用前景
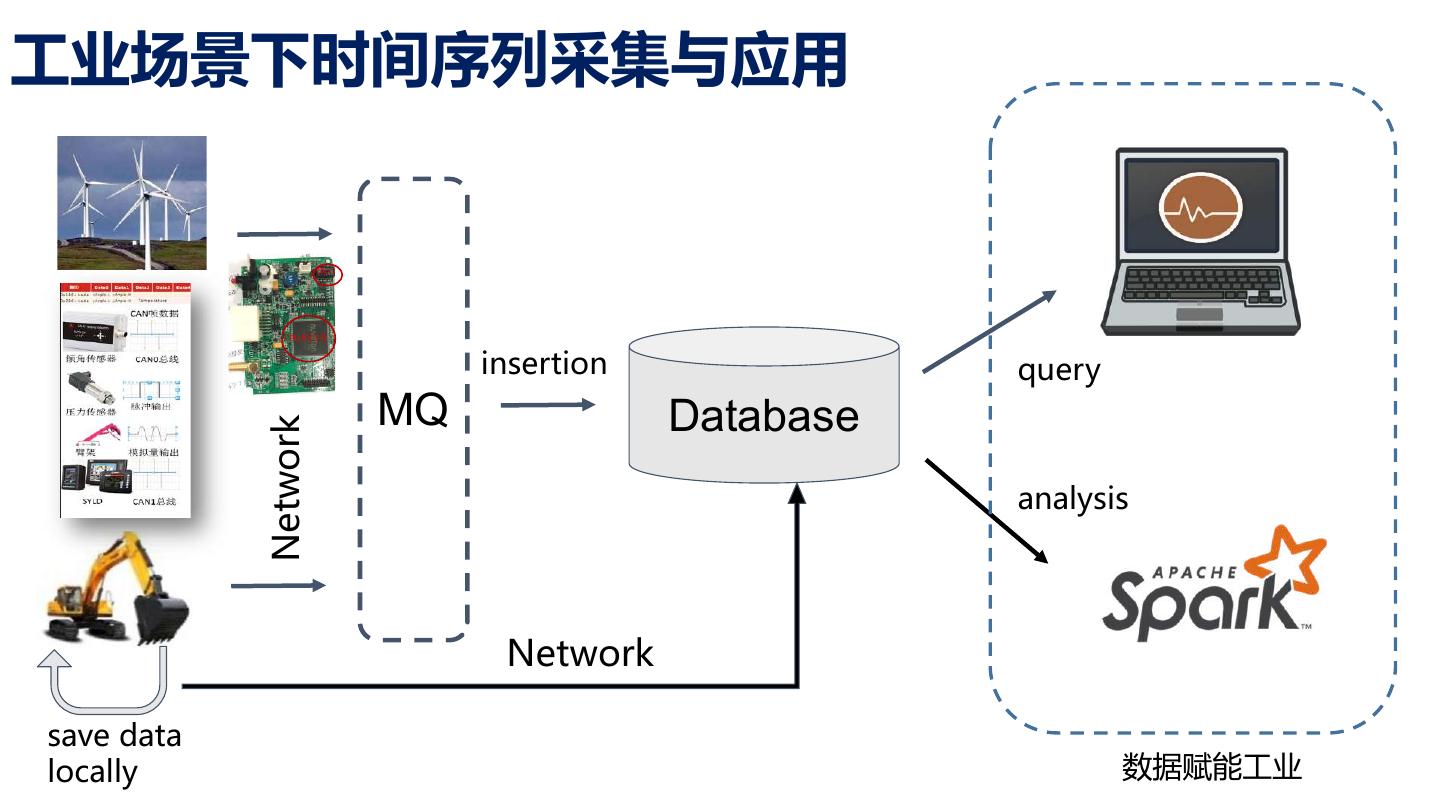
6 .工业场景下时间序列采集与应用 CPU insertion query MQ Database Network analysis Network save data locally 数据赋能工业
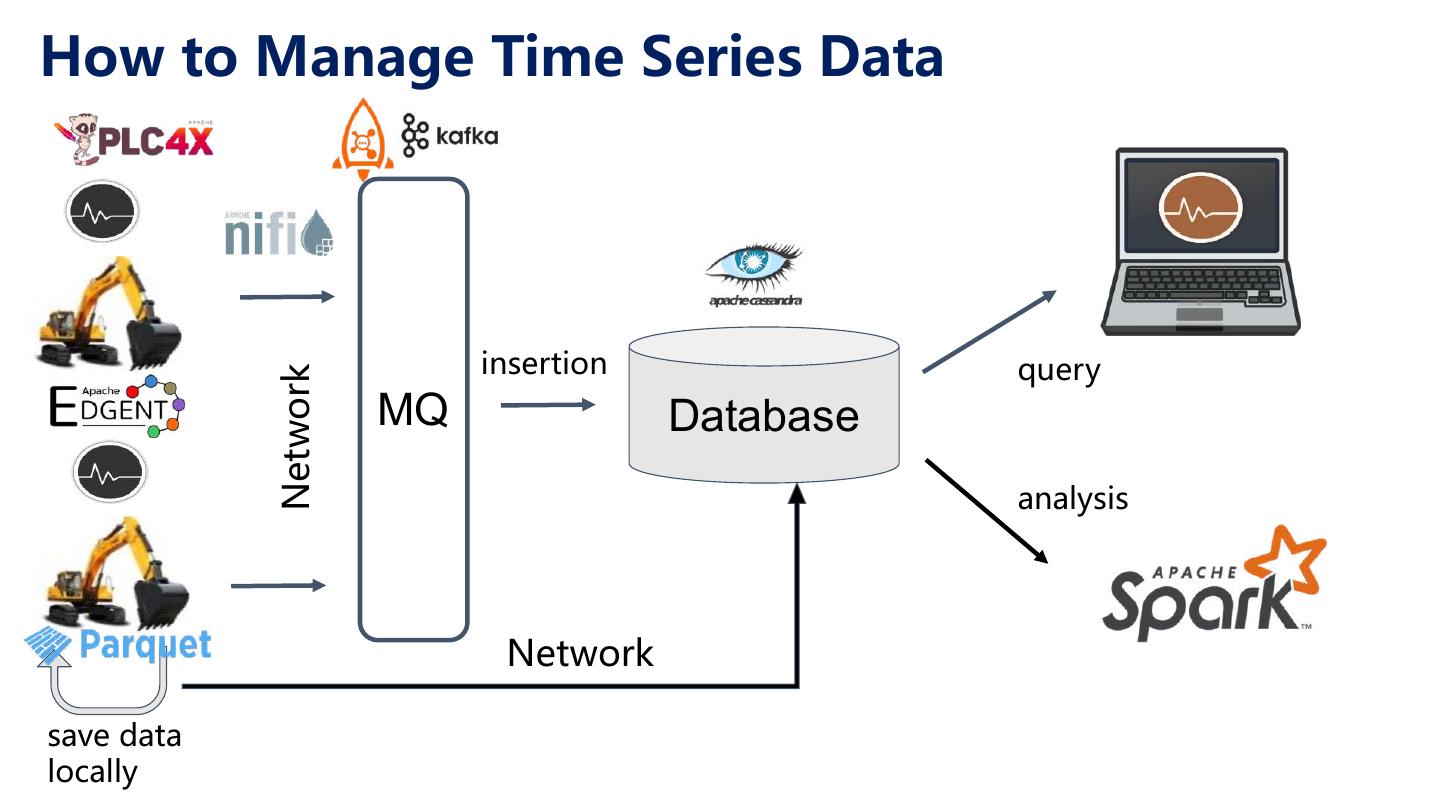
7 .How to Manage Time Series Data insertion query Network MQ Database analysis Network save data locally
8 .需求与挑战:提升工业时序数据利用率,从有效存储开始 大规模时序数据的特点 占用空间极大 数据总吞吐量大 时序数据存储的需求 产生速度快且不间断 【全时全量】 保证数据全时全量存储 【高效写入】 保证数据库可以承受高吞吐写入 【紧凑存储】 对数据进行有效压缩减少磁盘空间占用 超过20,000个风机 一个风机约有120~510传感器 采集频率从0.00167 Hz 到 50Hz 不等
9 .需求与挑战:支撑复杂工业场景,克服领域技术难点 排口有大量取值异常的 § 场景1:由于网络延迟、设备故障等原因数 采样点,例如PH值超 过10,000 据无法完全保序到达 § 场景2:由于设备故障、损坏等原因,在进 行分析等操作前需要对错误数据进行修正 § 场景3:清理过时数据或无效、无用数据 该排口连续164天缺失 上报PH值 时序数据数据乱序操作的需求 数据库需要支持时间序列数据的乱序写入 数据库需要支持时间序列数据的批量更新 数据库需要支持时间序列数据的清理删除
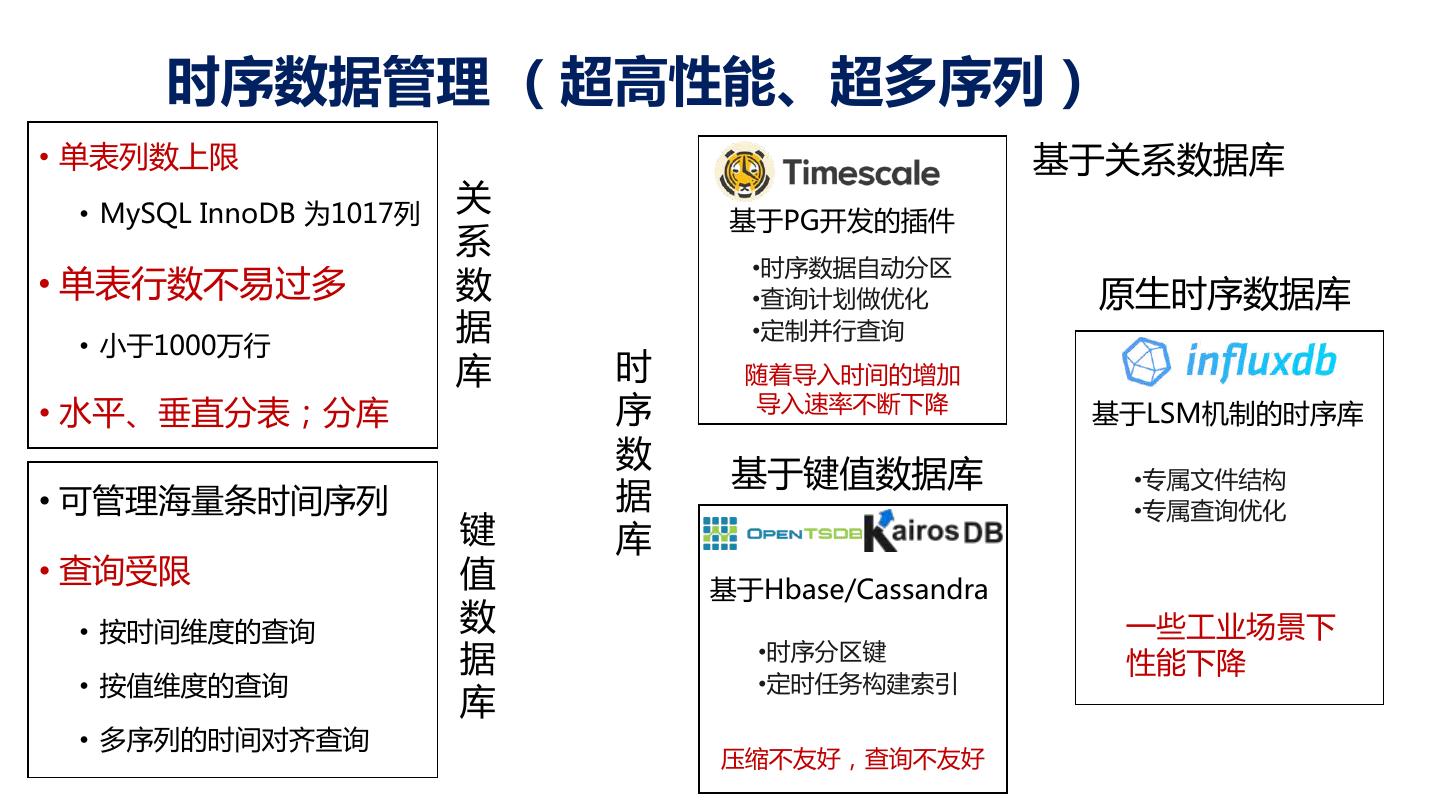
10 . 时序数据管理 (超高性能、超多序列) • 单表列数上限 基于关系数据库 • MySQL InnoDB 为1017列 关 基于PG开发的插件 系 •时序数据自动分区 • 单表行数不易过多 数 •查询计划做优化 原生时序数据库 • 小于1000万行 据 •定制并行查询 库 时 随着导入时间的增加 • 水平、垂直分表;分库 序 导入速率不断下降 基于LSM机制的时序库 数 基于键值数据库 •专属文件结构 • 可管理海量条时间序列 据 •专属查询优化 键 库 • 查询受限 值 基于Hbase/Cassandra • 按时间维度的查询 数 一些工业场景下 据 •时序分区键 性能下降 • 按值维度的查询 •定时任务构建索引 库 • 多序列的时间对齐查询 压缩不友好,查询不友好
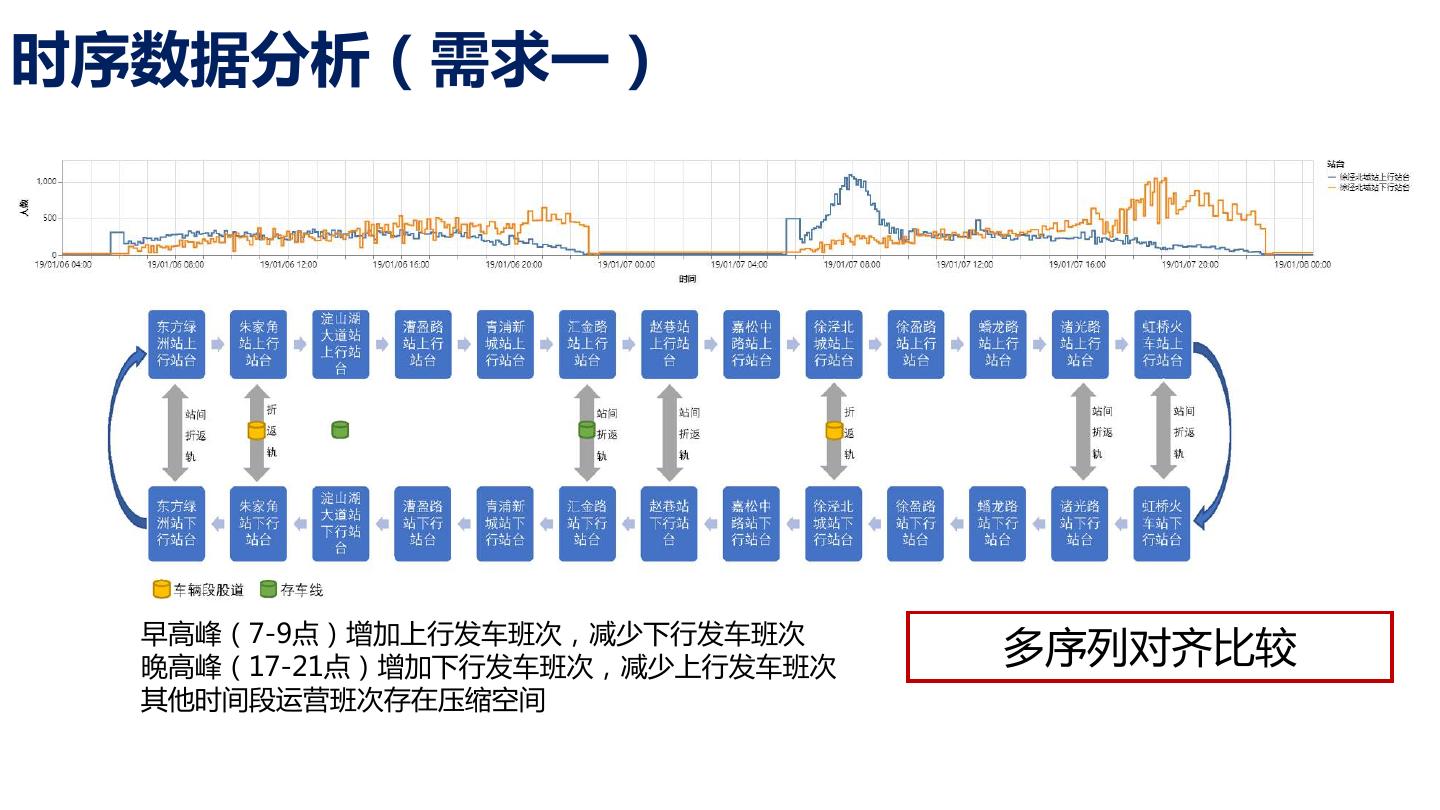
11 .时序数据分析(需求一) 早高峰(7-9点)增加上行发车班次,减少下行发车班次 晚高峰(17-21点)增加下行发车班次,减少上行发车班次 多序列对齐比较 其他时间段运营班次存在压缩空间
12 .时序数据分析(性能) analysis insertion Database ETL • 查询友好 • 分析友好 • 写入友好 KairosDB:导出每辆车每天3000种的数据:1小时 气象大数据系统:大量时间花费在数据获取上 批量使用历史数据,漫长的ETL
13 .需求与挑战:面向工业应用场景,提升数据处理能力 高通量写入 高效压缩 指定查询过滤条件 查询延迟低、时效高 按时间、设备、传感器类型等过滤 TB 级数据百毫秒查询 聚合查询数据 模式匹配 十亿点数数十毫秒查询 Say No to ETL 序列对齐查询 时序分割 多序列按时间维度对齐 序列填充查询 数字水印 空值填充
14 . Outline • 为什么开发时序数据库系统 • IoTDB介绍 • 基于RocketMQ与IoTDB的应用示例
15 .面向工业互联网的高性能轻量级时序数据库 清华数为工业互联网时序数据库 - > Apache IoTDB 中国高校目前唯一Apache基金会项目 – 工业领域千万条量级时间序列管理 – 单节点万亿数据点管理 – 单节点数十TB级时间序列数据管理 – 支持Hadoop、Spark、Matlab、 Grafana等多种生态
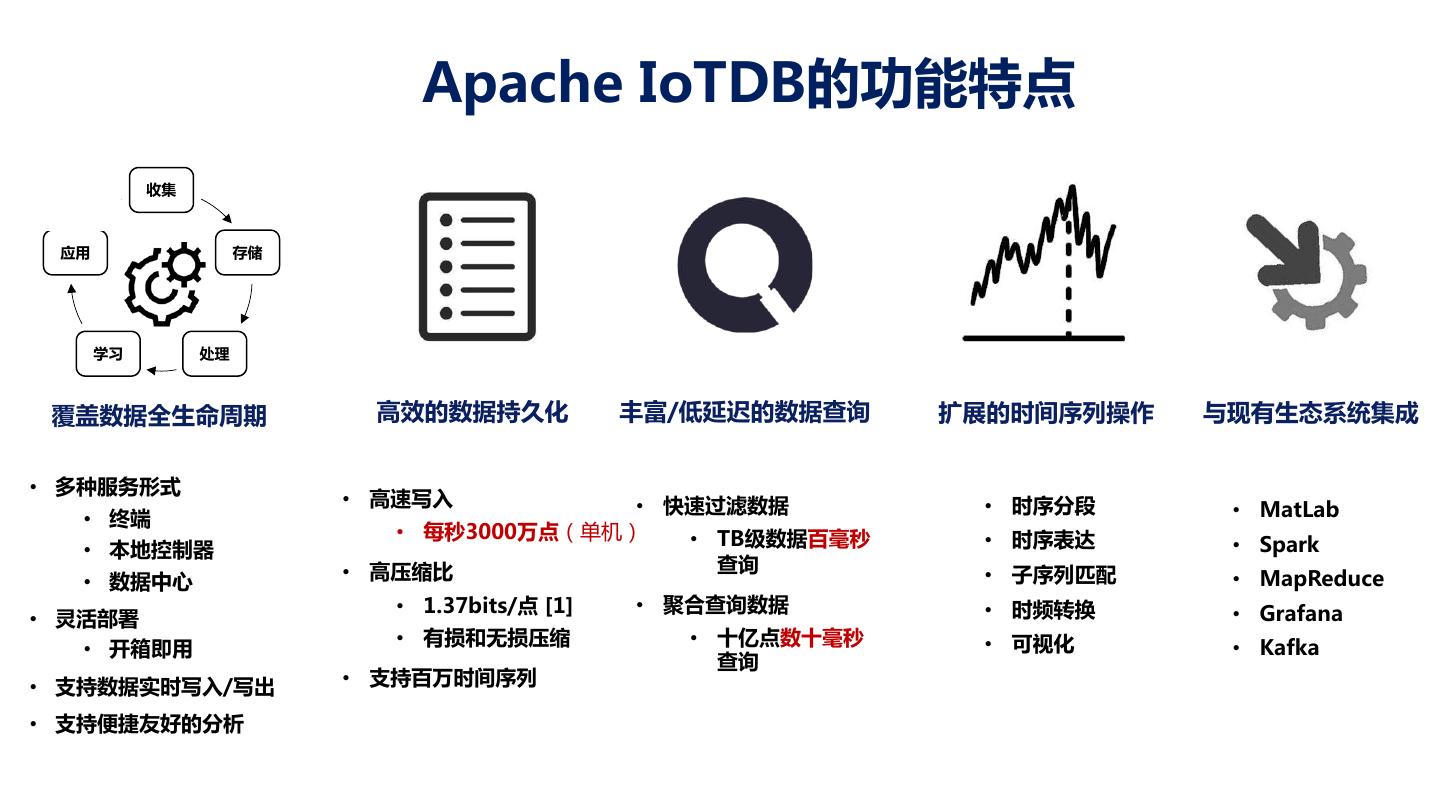
16 . Apache IoTDB的功能特点 收集 应用 存储 学习 处理 覆盖数据全生命周期 高效的数据持久化 丰富/低延迟的数据查询 扩展的时间序列操作 与现有生态系统集成 • 多种服务形式 • 高速写入 • 快速过滤数据 • 时序分段 • 终端 • MatLab • 每秒3000万点(单机) • TB级数据百毫秒 • 时序表达 • 本地控制器 • Spark • 高压缩比 查询 • 子序列匹配 • 数据中心 • MapReduce • 1.37bits/点 [1] • 聚合查询数据 • 时频转换 • Grafana • 灵活部署 • 有损和无损压缩 • 十亿点数十毫秒 • 可视化 • Kafka • 开箱即用 查询 • 支持数据实时写入/写出 • 支持百万时间序列 • 支持便捷友好的分析
17 .产品形态:灵活适配“云-网-端”计算环境 部署在嵌入式终端设备的时序 部署在工控机等边缘计算设备 部署在云端数据中心的 “数据文件” 的时序“数据库” 时序“数据仓库” 终端 场控 数据中心 为时序数据而生的zip文件 高效丰富的时间序列查询引擎 与大数据分析框架无缝集成 支持高性能写入,高压缩比存 提供增删改查,以及聚合查询 支持时序数据处理,挖掘分析 储,支持简单查询 时序对齐等高级功能 与机器学习
18 .Integration with other systems Analysis with Matlab Big data analysis Visualization (small data set) (Manual data explore) 18
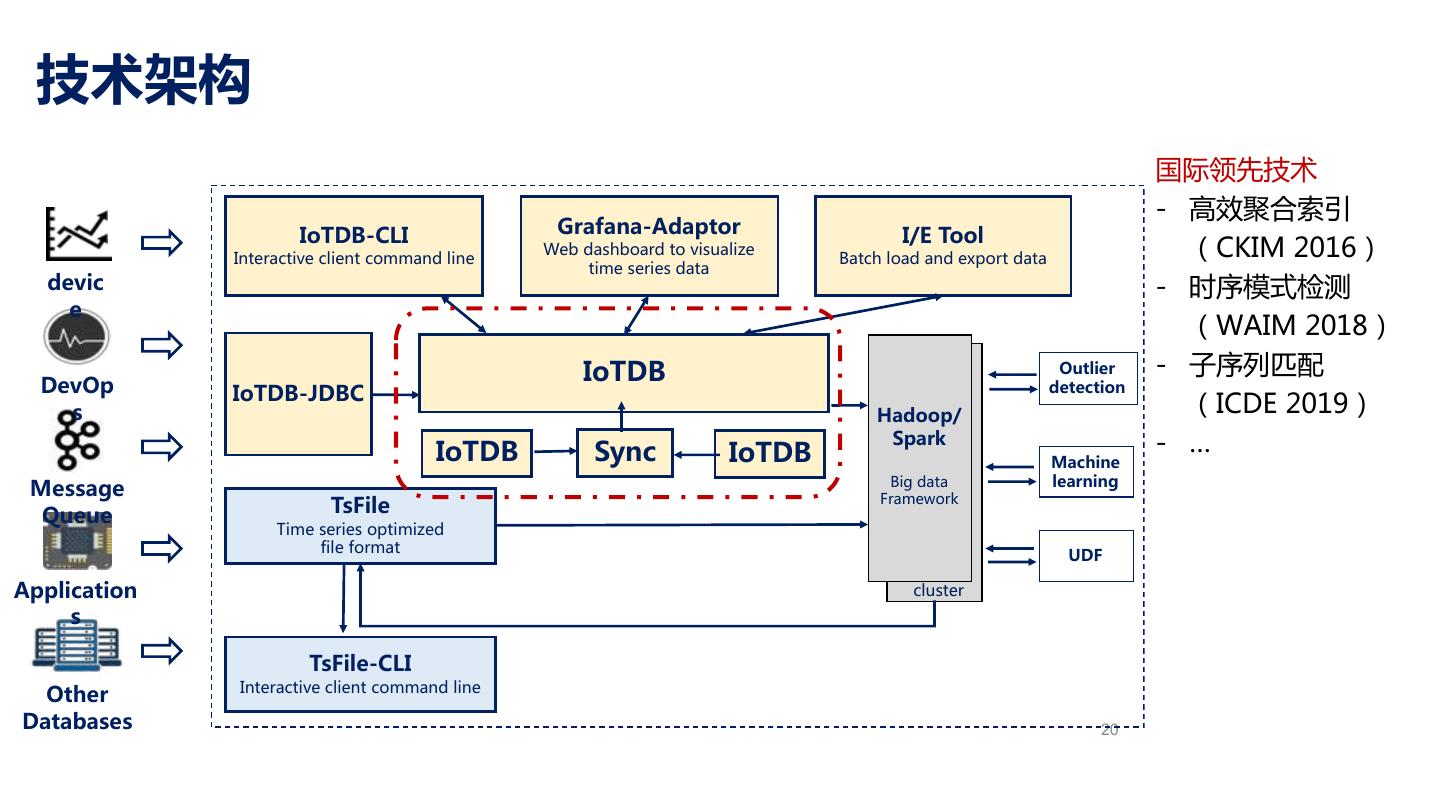
19 .技术架构 国际领先技术 - 高效聚合索引 (CKIM 2016) - 时序模式检测 (WAIM 2018) - 子序列匹配 (ICDE 2019) - … 20
20 .直接将数据存储成为分析友好的结构 20
21 .高压缩与高吞吐 Others Others Raw data: - 12 Bytes per point - 112 GB totally
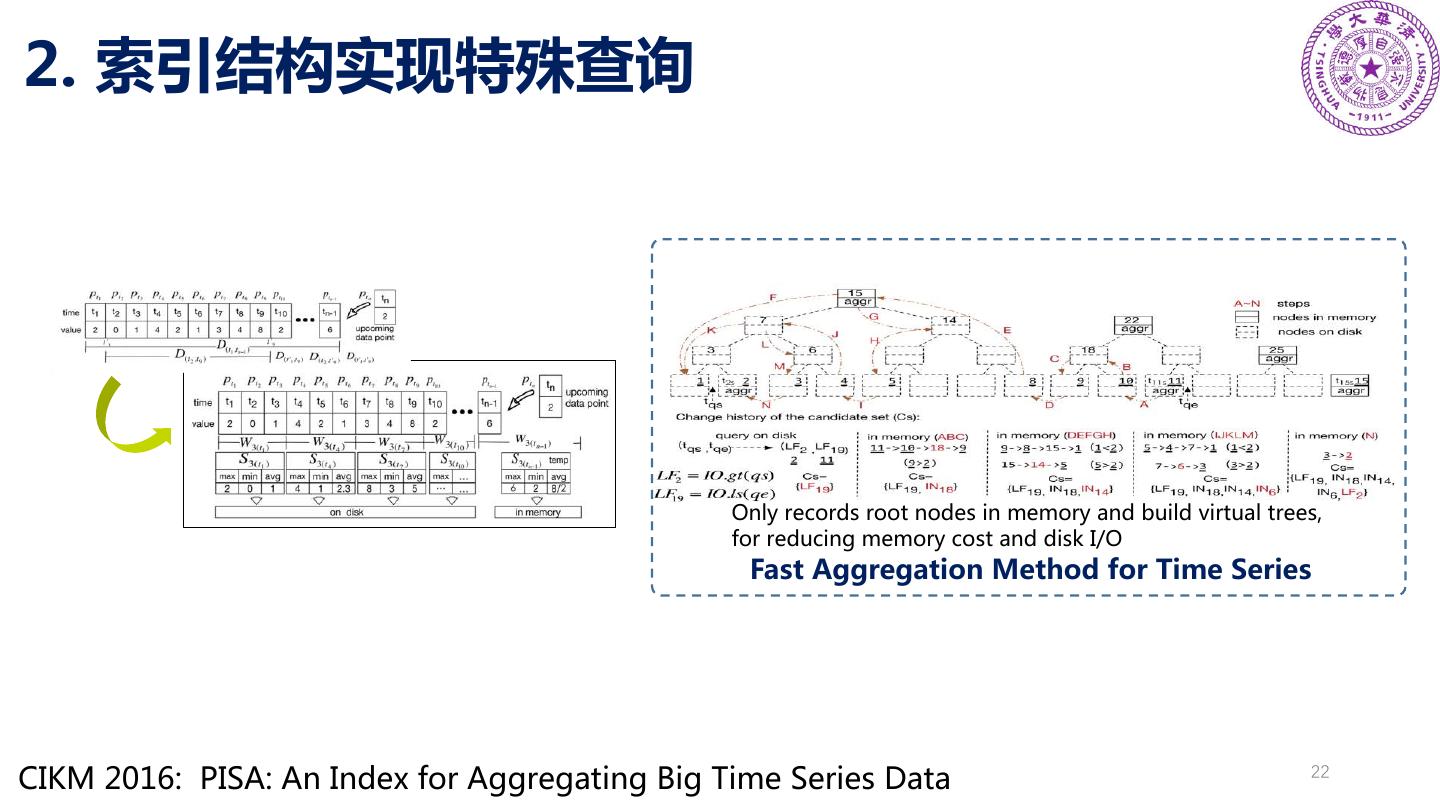
22 .2. 索引结构实现特殊查询 Only records root nodes in memory and build virtual trees, for reducing memory cost and disk I/O Fast Aggregation Method for Time Series CIKM 2016: PISA: An Index for Aggregating Big Time Series Data 22
23 .高效查询 Others
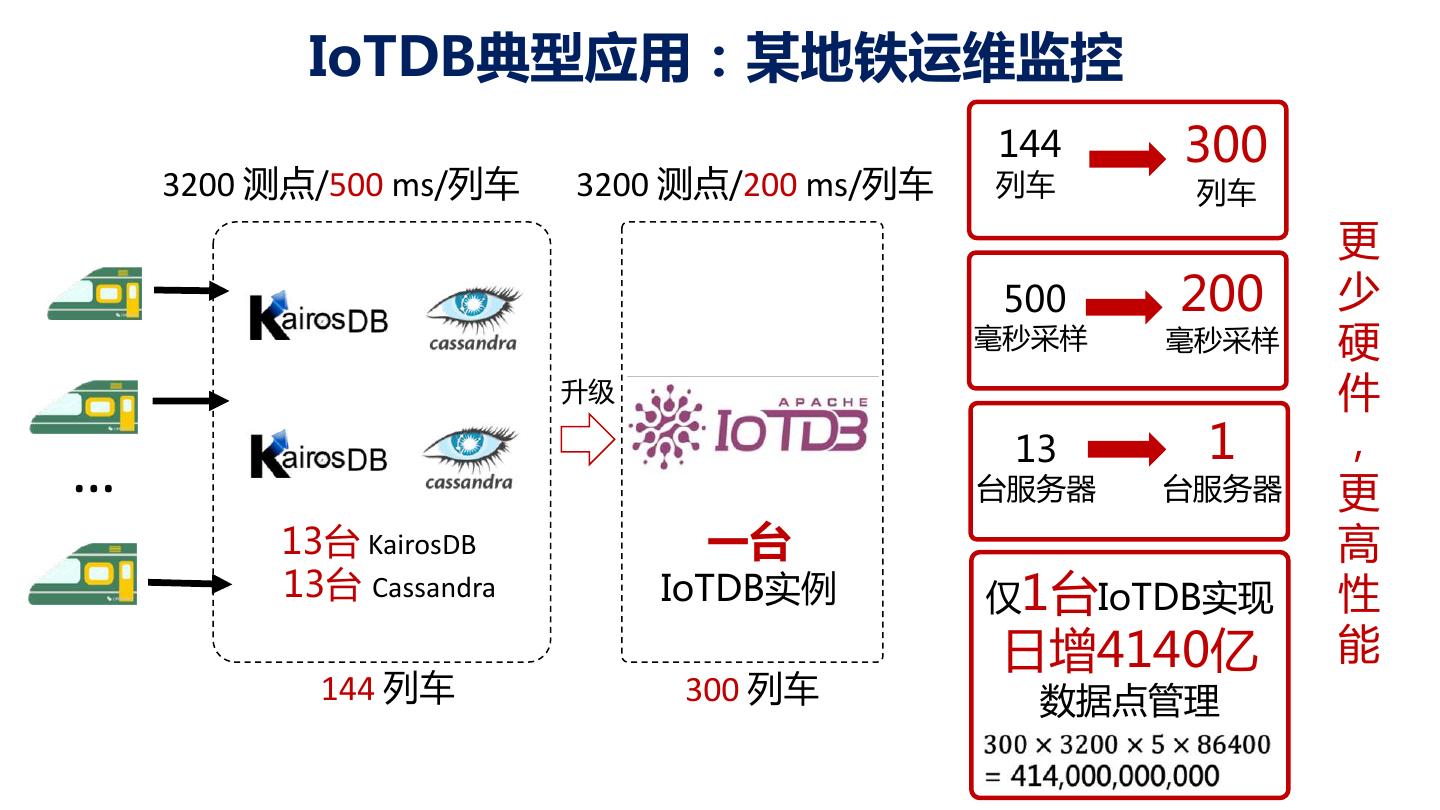
24 . IoTDB典型应用:某地铁运维监控 144 300 3200 测点/500 ms/列车 3200 测点/200 ms/列车 列车 列车 更 500 200 少 毫秒采样 毫秒采样 硬 升级 件 13 1 , … 台服务器 台服务器 更 13台 KairosDB 一台 高 13台 Cassandra IoTDB实例 仅1台IoTDB实现 性 日增4140亿 能 144 列车 300 列车 数据点管理
25 . 其他应用 商飞 InfluxDB(可能)丢失了大量数据 IoTDB保存了数据细节
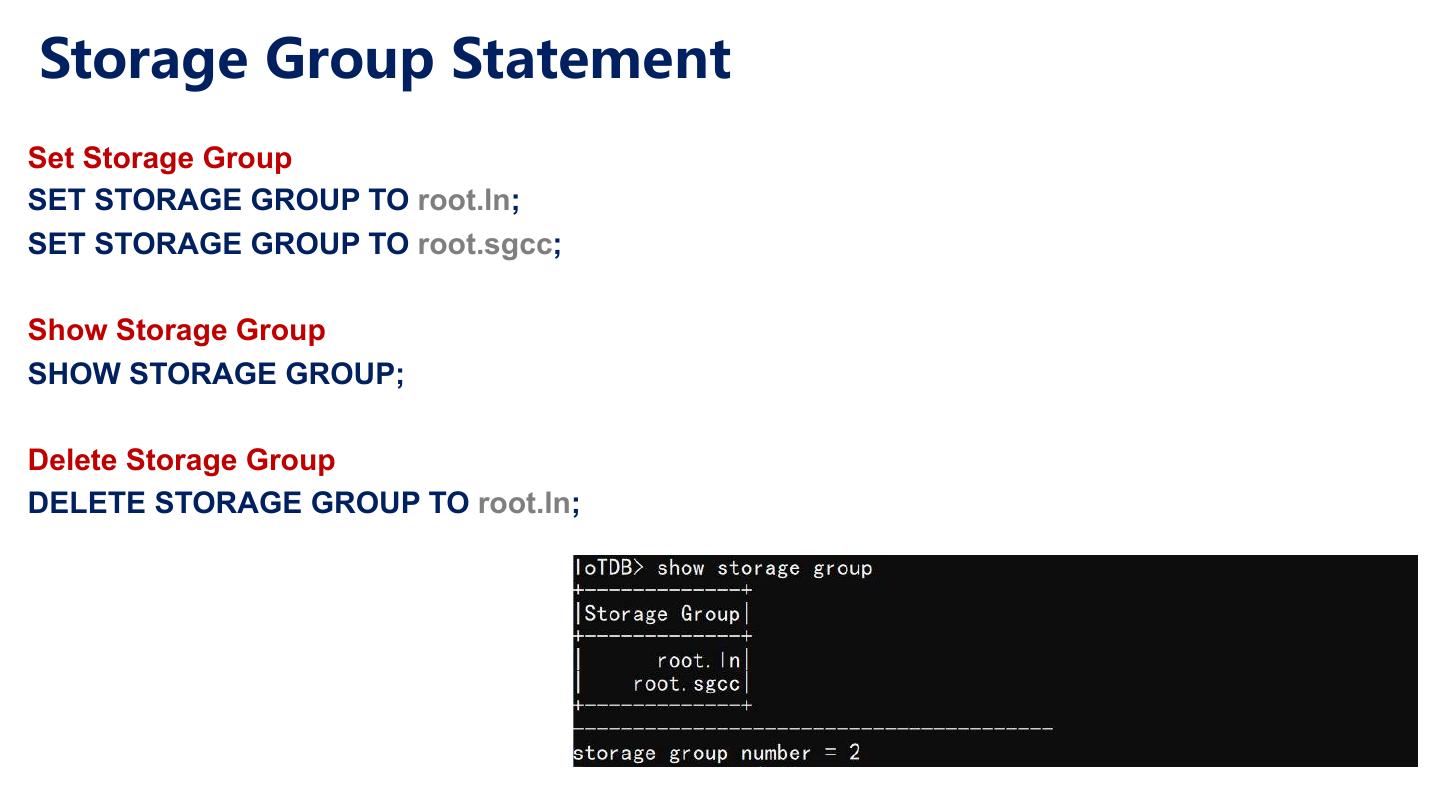
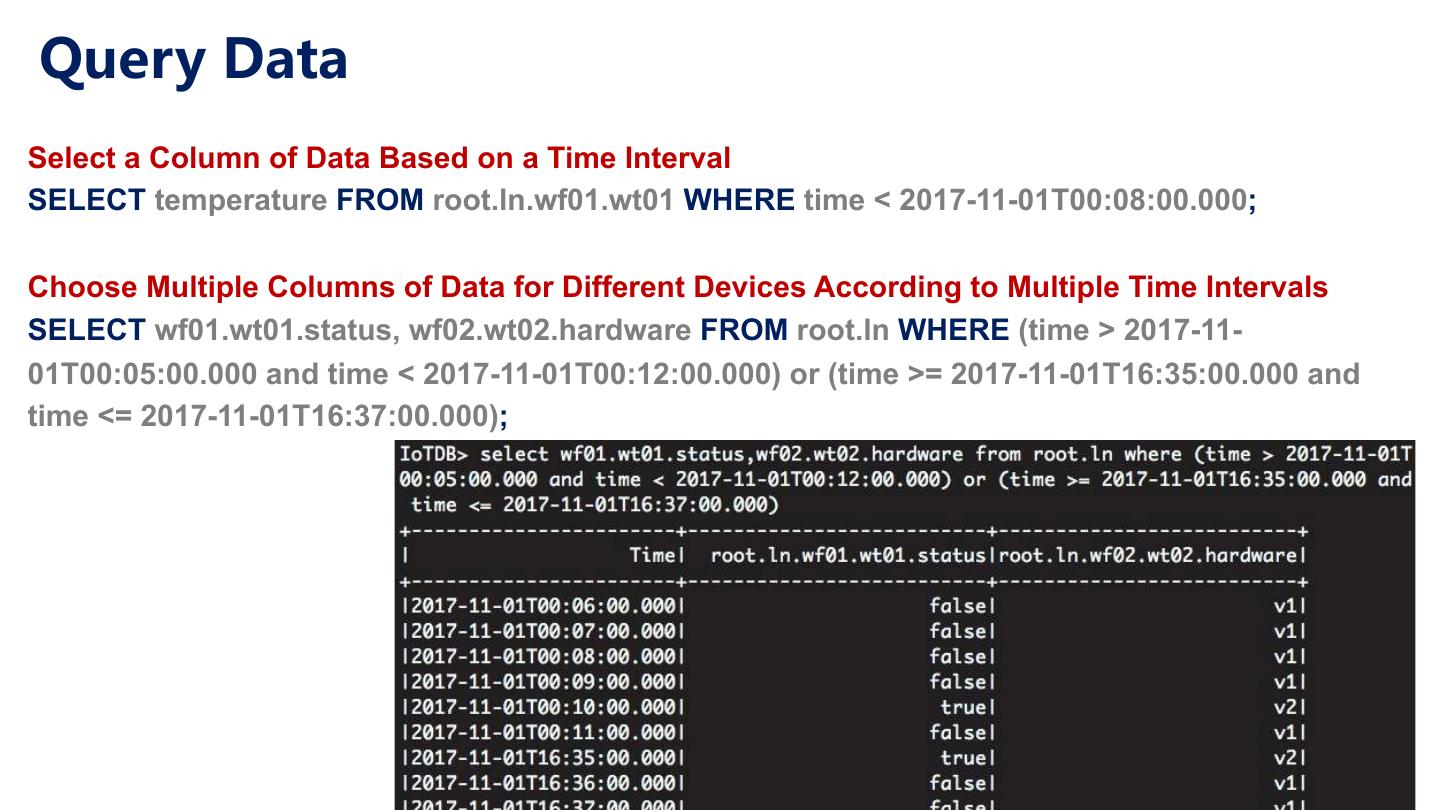
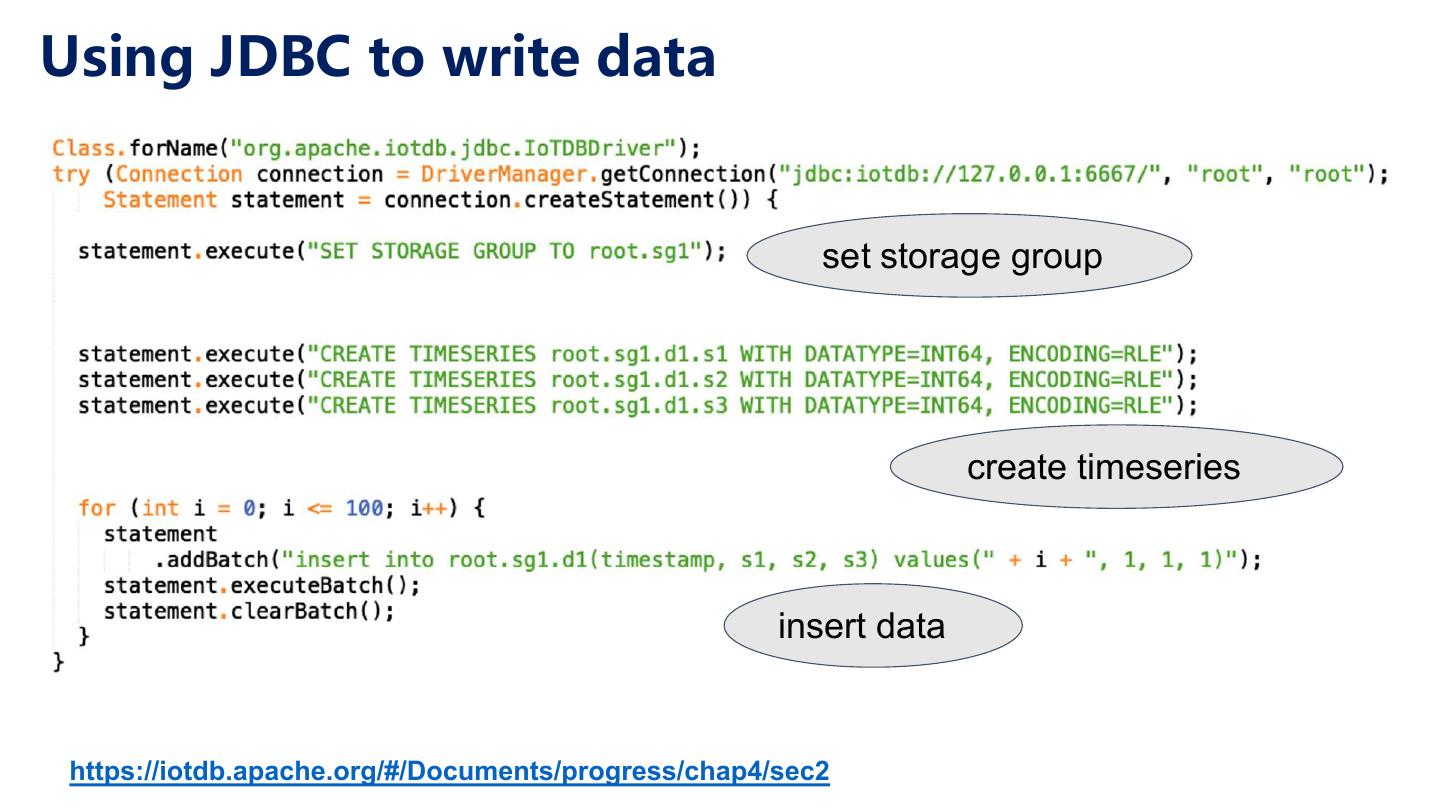
26 .Concepts in IoTDB (The Schema) Device (i.e., Data source) Cadillac XT5 • A machine instance Measurement (e.g., sensor) • A device can have many measurements Time Series • Device + Measurement • is represented as a path that begins with root, like “root.Cadillac_XT5.USA.CA.7BTC409.fuelRemain” Storage Group (SG) • A storage group can have many devices • Storage groups have independent resources (threads and files) to increase parallelism and reduce competitions for locks.
27 . The schema mapping 1 IoTDB Schema OLTP Schema root.Cadillac_XT5.USA.CA.7BTC409.fuelRemain Table Storage group Dimension Device,timestamp root.Cadillac_XT5.USA.CA.7BTC409.speed Column root.Cadillac_XT5.USA.NV.6BAC321.speed Metric Measurement Column Table Name: Cadillac_XT5 (RDB schema or NoSQL like Cassandra) country state device name timestamp fuelRemain speed USA CA 7BTC409 t1 5.0 120 USA CA 7BTC409 t2 4.9 109 USA CA 6BAC321 t1 NULL 50 USA CA 6BAC321 t3 NULL 65 Tags and Fields in InfluxDB, KariosDB, OpenTSDB…
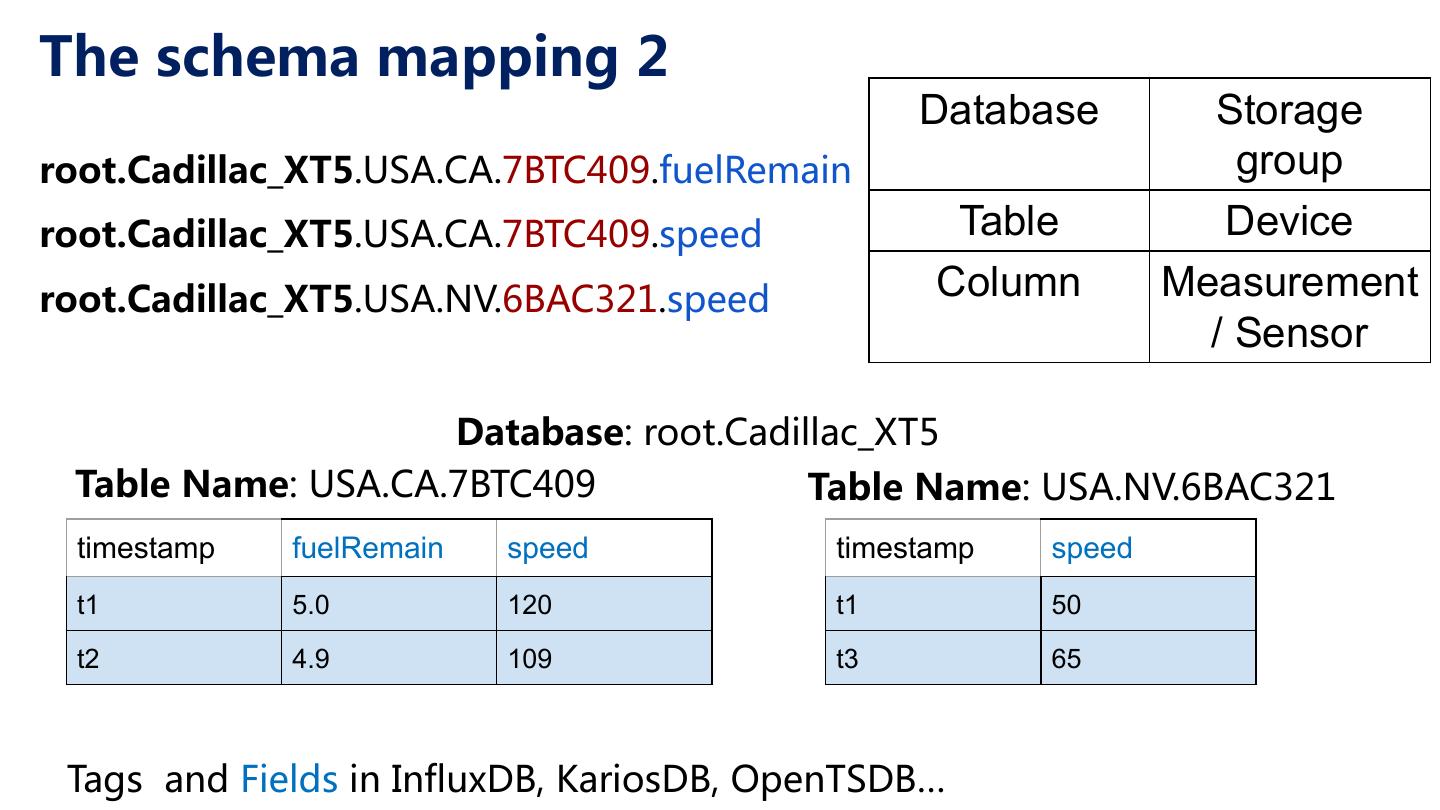
28 .The schema mapping 2 Database Storage root.Cadillac_XT5.USA.CA.7BTC409.fuelRemain group root.Cadillac_XT5.USA.CA.7BTC409.speed Table Device root.Cadillac_XT5.USA.NV.6BAC321.speed Column Measurement / Sensor Database: root.Cadillac_XT5 Table Name: USA.CA.7BTC409 Table Name: USA.NV.6BAC321 timestamp fuelRemain speed timestamp speed t1 5.0 120 t1 50 t2 4.9 109 t3 65 Tags and Fields in InfluxDB, KariosDB, OpenTSDB…
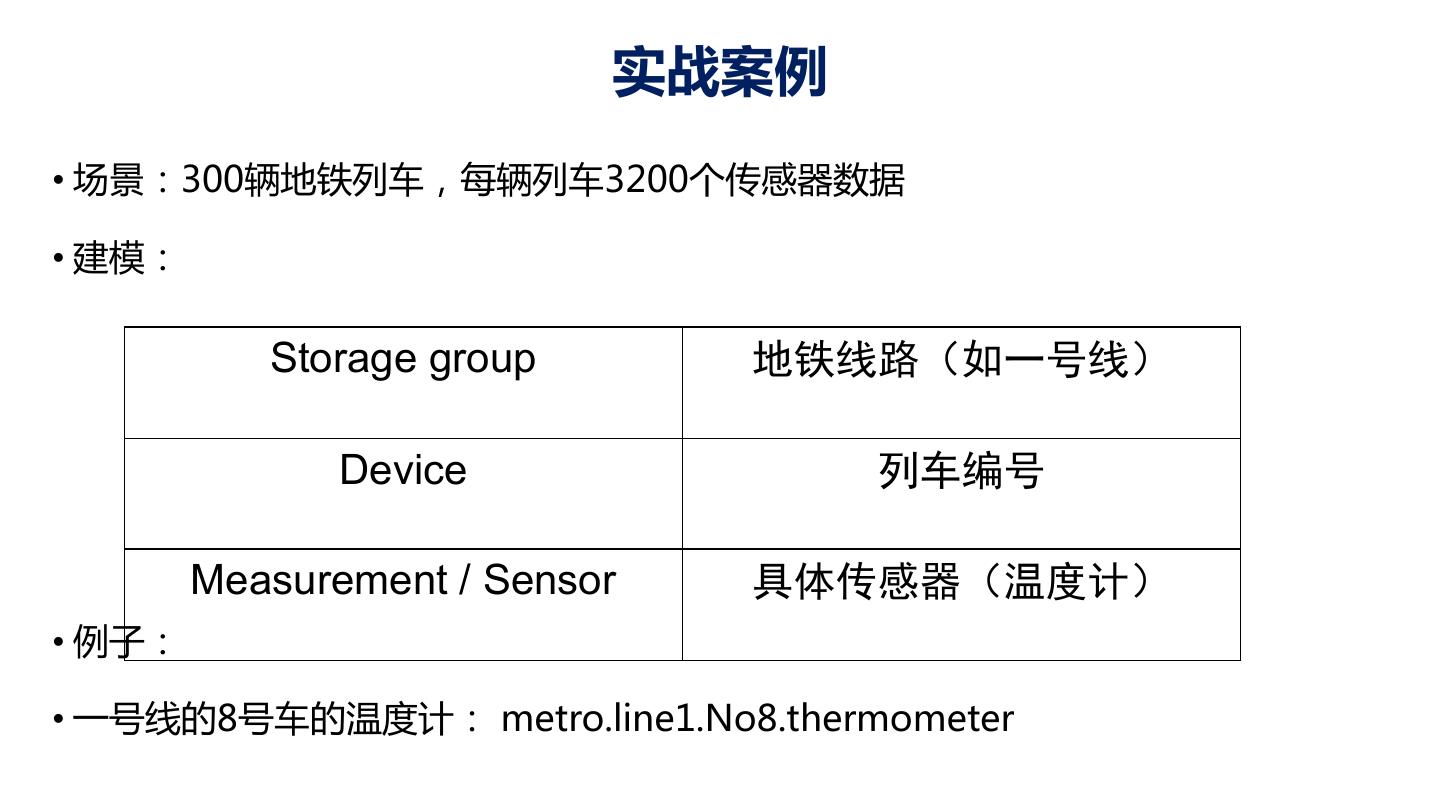
29 . 实战案例 • 场景:300辆地铁列车,每辆列车3200个传感器数据 • 建模: Storage group 地铁线路(如一号线) Device 列车编号 Measurement / Sensor 具体传感器(温度计) • 例子: • 一号线的8号车的温度计: metro.line1.No8.thermometer
3秒后跳转登录页面
去登陆

