































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
边缘视觉智能研究及应用
讲者简介:陈玉荣博士现任英特尔首席研究员、英特尔中国研究院认知计算实验室主任。负责领导视觉识别、理解、认知和机器学习研究工作,驱动英特尔研究院基于英特尔平台的智能视觉数据处理技术创新。他和团队推动了基于深度学习的视觉理解以及领先人脸分析技术研究来影响英特尔架构/平台设计及软硬件解决方案,包括Movidius VPU、OpenVINO、RealSense技术、Unite无线会议解决方案、物联网视频端对端分析解决方案、智能笔记本视觉感知和三维运动员跟踪技术等。他曾获得3次英特尔研究院全球最高学术奖“戈登•摩尔奖”和1次“英特尔中国奖”。发表顶级学术会议或期刊论文50余篇,拥有70余项美国/国际专利及申请。参与组织多个NeurIPS/ICML/ISCA的研讨会及专题讲座,担任J-STSP的客座编辑。2004年中科院软件所博士后出站后加入英特尔。2002年获得清华大学计算数学博士学位。
报告摘要:深度学习在许多领域尤其是视觉识别/理解方面取得了巨大突破,但它在模型训练和部署方面都存在一些挑战。本次演讲将介绍我们为实现边缘深度学习视觉推断而进行的高效CNN算法设计、领先DNN模型压缩和部署时网络结构优化以及以人为中心的视觉分析与合成的前沿研究。相关研究成果已经在计算机视觉和机器学习顶会及期刊上发表,包括最早提出的从头开始训练物体检测器DSOD (ICCV’17/TPAMI, 2020)、轻量级CNN骨干网络HBONet (ICCV’19),DNN网络剪枝技术DNS (NIPS’16),Network Slimming (ICCV’17)及低比特DNN模型量化技术INQ (ICRL’17)、Network Sketching (CVPR’17)、ELQ (CVPR’18),以及视线目标估计 (IJCV, 2020)、人脸重光照 (Siggraph Asia 2020)、三维人体姿态估计等近期工作。我们还将介绍几个通过我们的研究创新、基于英特尔计算平台实现的智能笔记本,智能办公室和三维运动员跟踪等边缘视觉智能应用。
展开查看详情
1 .南京大数据技术Meetup 边缘视觉智能研究及应用 Edge Visual Intelligence Research & Applications 陈玉荣 博士(CCF高级会员),英特尔中国研究院
2 .2 议程 • 简介 • 高效CNN算法设计及实际应用 • 深度模型压缩优化及技术落地 • 以人为中心的视觉分析与合成 • 总结及展望 Intel Labs | The Future Begins Here 2
3 .3 议程 • 简介 • 高效CNN算法设计及实际应用 • 深度模型压缩优化及技术落地 • 以人为中心的视觉分析与合成 • 总结及展望 Intel Labs | The Future Begins Here 3
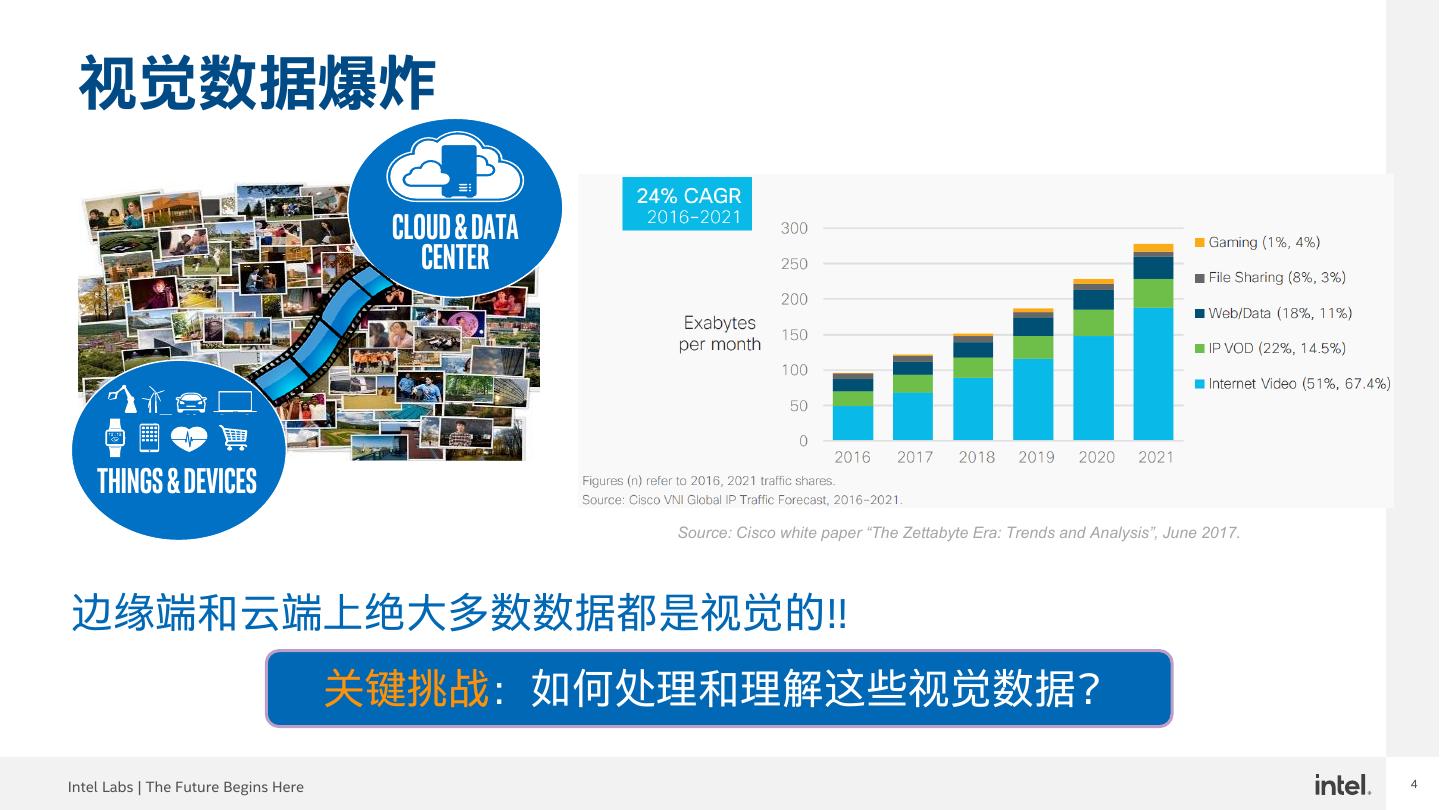
4 .4 视觉数据爆炸 Cloud & DATA Center Things & devices Source: Cisco white paper “The Zettabyte Era: Trends and Analysis”, June 2017. 边缘端和云端上绝大多数数据都是视觉的!! 关键挑战:如何处理和理解这些视觉数据? Intel Labs | The Future Begins Here 4
5 .5 视觉识别:深度学习的突破 30 28 152 160 26 140 25 ConvNets: Convolutional Neural ~40% Networks (CNNs) 120 20 Top-5 Error (%) 16.4 100 # Layers 15 80 11.7 60 10 7.3 6.7 40 5 22 3.57 19 shallow 8 8 20 0 0 2010 2011 2012 2013 2014 2014 2015 AlexNet FinerAlexNet VGG GoogleNet ResNet ImageNet Large Scale Visual Recognition Challenge (ILSVRC): 1000-catg Object Classification “ 卷积神经网络(CNNs)目前已几乎成为所有识别和检测任务的主流方法, 并在一些任务中接近人类水平。” LeCun, Bengio, Hinton, 深度学习,《自然》,2015年5月 Intel Labs | The Future Begins Here 5
6 .6 深度学习计算与存储挑战 600 25 500 548 528 Parameter Memory (MB) 20 20 400 16 15 GFLOPs 300 11 10 200 233 230 8 5 100 110 512 0 0.727 0 AlexNet VGG-16 VGG-19 GoogleNet ResNet-152 DenseNet-161 Image Classification DNN Burden 部署挑战:主流DNNs都是计算和存储密集型的!很难部署到边缘 及嵌入式设备上 Intel Labs | The Future Begins Here 6
7 .7 议程 • 简介 • 高效CNN算法设计及实际应用 • 深度模型压缩优化及技术落地 • 以人为中心的视觉分析与合成 • 总结及展望 Intel Labs | The Future Begins Here 7
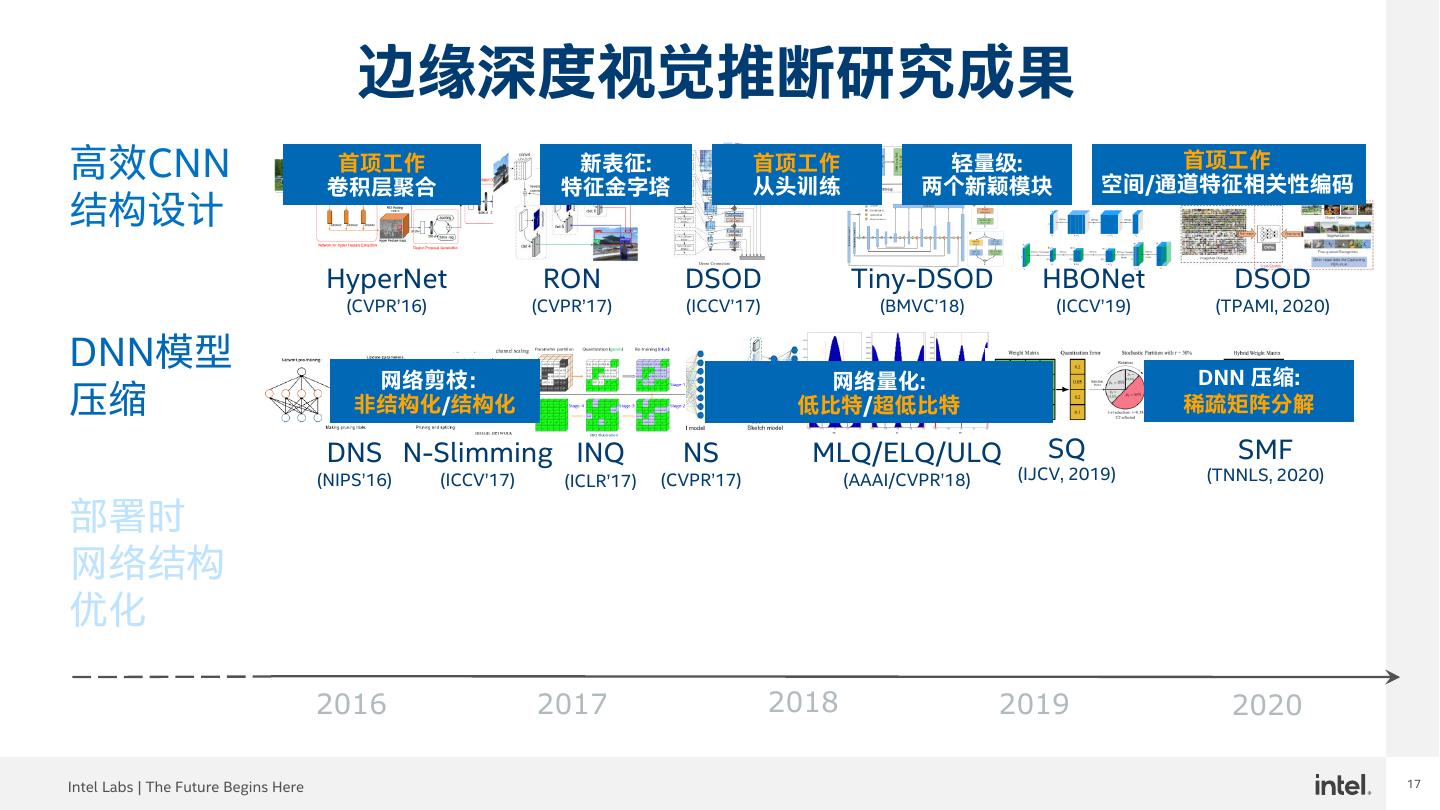
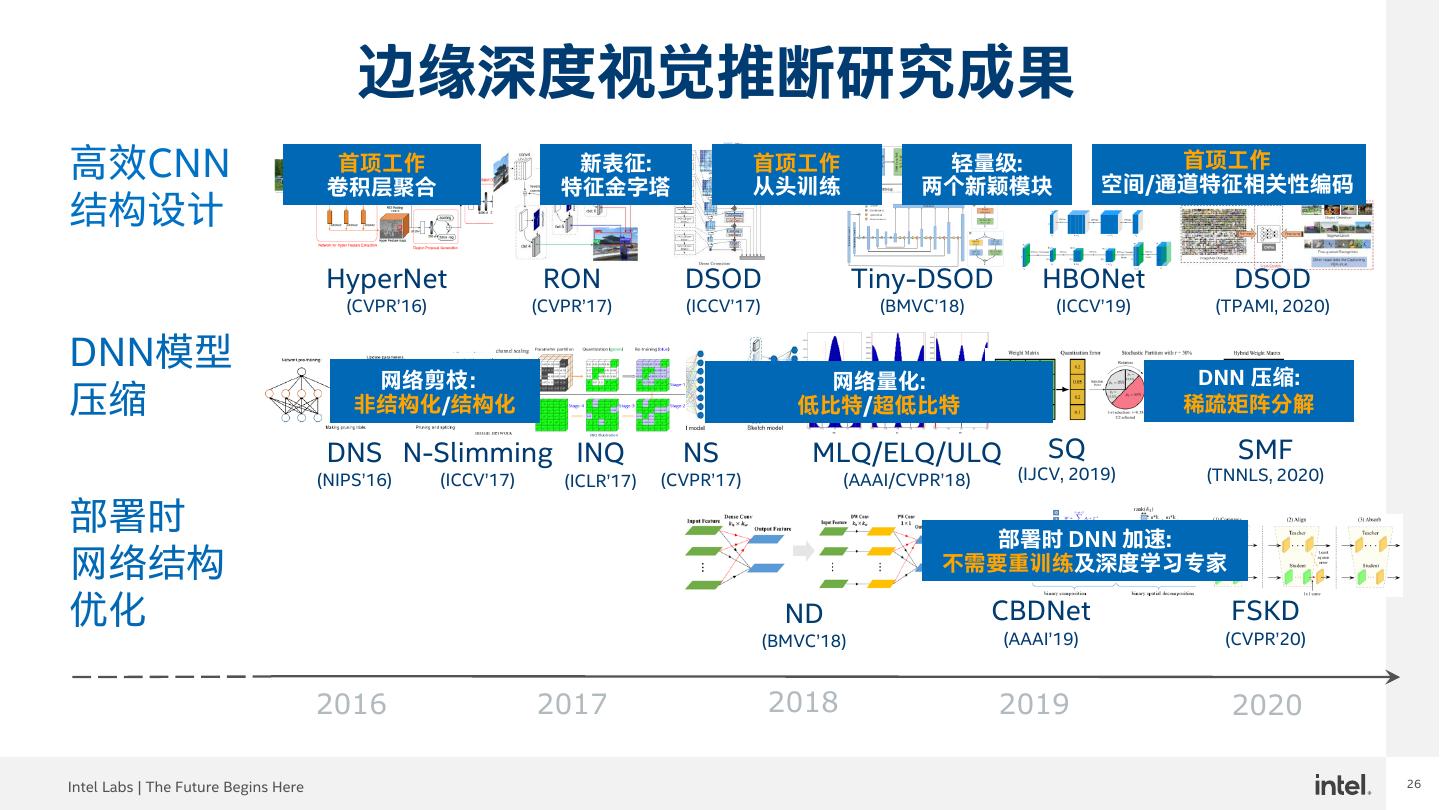
8 .8 边缘深度视觉推断研究成果 高效CNN 首项工作 卷积层聚合 新表征: 特征金字塔 首项工作 从头训练 轻量级: 两个新颖模块 首项工作 空间/通道特征相关性编码 结构设计 HyperNet RON DSOD Tiny-DSOD HBONet DSOD (CVPR’16) (CVPR’17) (ICCV’17) (BMVC’18) (ICCV’19) (TPAMI, 2020) DNN模型 压缩 部署时 网络结构 优化 2016 2017 2018 2019 2020 Intel Labs | The Future Begins Here 8
9 .9 DSOD:深度监督物体检测器 首项从头开始训练的物体检测工作 (ICCV17/TPAMI, 2020) • 无需 ImageNet 上百万张图像的预训练 • 只需数万张标注图像 先进准确率和效率 • 模型参数:½ SSD, ¼ R-FCN, 1/10 Faster-RCNN • 准确率比SSD/YOLOv2好 (PASCAL VOC/MS COCO) • 速度:20fps (GPU,无特殊代码优化) 物体检测器设计更多可能性 • 针对特定问题的有限数据集训练 • 其它领域,如深度、医学、多光谱图像网络设计 Z. Shen, Z. Liu, J. Li, Y. Jiang, Y. Chen, X. Xue, “DSOD: Learning Deeply Supervised Object Detectors from Scratch”, ICCV 2017. Z. Shen, Z. Liu, J. Li, Y. Jiang, Y. Chen, X. Xue, “Object Detection from Scratch with Deep Supervision”, TPAMI, Feb 2020. Intel Labs | The Future Begins Here 9
10 .10 Tiny-DSOD:轻量级物体检测器 16 15.12 73.6 75 两个创新模块 (BMVC18) 14 12 68 70.9 72.1 73 71 69 • DDB: 深度稠密模块 #Params (M) 10 mAP (%) 64.3 67 8 65 • D-FPN: 深度特征金字塔网络 6 5.5 5.5 5.98 5.9 63 61 4 更好平衡准确率和计算资源需求 57.1 59 2 0.95 57 0 55 • 1/6 模型参数(<1M)和1/5 FLOPs(1 GFLOPs) 实现 DSOD-small 相似准确率 • 超越先进高效解决方案 (Skull Canyon上达到 60FPS) DDB D-FPN Y. Li, J. Li, W. Lin, J. Li, “Tiny-DSOD: Lightweight Object Detection for Resource-Restricted Usages”, BMVC 2018. Intel Labs | The Future Begins Here 10
11 .11 智能会议室 英特尔Unite无线会议 PanaCast全景视频会议 解决方案 系统 占用率检测和人数统计应用需求 • IP干净、准确率>VGG-SSD、4K检测距离30英尺、IoU<33%可分、>25FPS 基于Tiny-DSOD的人体检测及人数统计技术已成功应用于英特尔Unite无线会议 解决方案和Altia PanaCast全景视频会议系统 Intel Labs | The Future Begins Here 11
12 .HBONet: 两个正交维度上的和谐瓶颈 HBO设计(ICCV’19) 两个互反的空间收缩-扩展和通道扩展-收缩组件嵌套在双边对称结构中,通过同 时编码空间和通道维度上的特征相互依赖性在保持相似计算复杂性的同时改善瓶 颈表示性能 D. Li, A. Zhou, and A. Yao. “HBONet: Harmonious Bottleneck on Two Orthogonal Dimensions”, ICCV 2019. Intel Labs | The Future Begins Here 12 12
13 .HBONet 视觉识别结果 在各种任务中及不同级别计算预算下显示出领先性能 ImageNet Classification Accuracy ImageNet Classification MFLOPs 80 320 280 70 240 Top-1 Acc. (%) MFLOPs 60 200 160 50 6.6% MobileNetV2 MobileNetV2 120 HBONet HBONet 40 80 40 30 0 0.1 0.25 0.35 0.5 0.75/0.8 1 0.1 0.25 0.35 0.5 0.75/0.8 1 Width Multiplier Width Multiplier PASCAL VOC Object Detection Market1501 Person Re-identification 80 80 70 70 mAP (%) 60 mAP (%) MobileNetV2 60 50 6.3% 5.0% MobileNetV2 SSD320 50 40 HBONet HBONet 30 SSD320 40 0.1 0.25 0.5 1 0.1 0.25 0.5 1 Width Multiplier Width Multiplier Intel Labs | The Future Begins Here 13 13
14 .智能笔记本 基于视觉感知的方案 • 基于人脸和头部姿态估计来分析用户行为 • 优化PC运行以实现省电,提高安全性和私密性 Intel Labs | The Future Begins Here 14 14
15 . 超高效头部姿态估计 图示结果 使用场景要求 基于HBO的结果 低计算资源 内存 50 KB 堆栈大小 38 KB 模型大小 512 KB 嵌入RAM 150 KB 推断内存需求 MFLOPs < 5.0 MFLOPs 2.2~2.5 MFLOPs 高准确率 < 5.0 度 2.5 度平均误差 Intel Labs | The Future Begins Here 15 15
16 .16 议程 • 简介 • 高效CNN算法设计及实际应用 • 深度模型压缩优化及技术落地 • 以人为中心的视觉分析与合成 • 总结及展望 Intel Labs | The Future Begins Here 16
17 .17 边缘深度视觉推断研究成果 高效CNN 首项工作 卷积层聚合 新表征: 特征金字塔 首项工作 从头训练 轻量级: 两个新颖模块 首项工作 空间/通道特征相关性编码 结构设计 HyperNet RON DSOD Tiny-DSOD HBONet DSOD (CVPR’16) (CVPR’17) (ICCV’17) (BMVC’18) (ICCV’19) (TPAMI, 2020) DNN模型 DNN 压缩: 网络剪枝: 网络量化: 压缩 非结构化/结构化 低比特/超低比特 稀疏矩阵分解 DNS N-Slimming INQ NS MLQ/ELQ/ULQ SQ SMF (NIPS’16) (ICCV’17) (ICLR’17) (CVPR’17) (AAAI/CVPR’18) (IJCV, 2019) (TNNLS, 2020) 部署时 网络结构 优化 2016 2017 2018 2019 2020 Intel Labs | The Future Begins Here 17
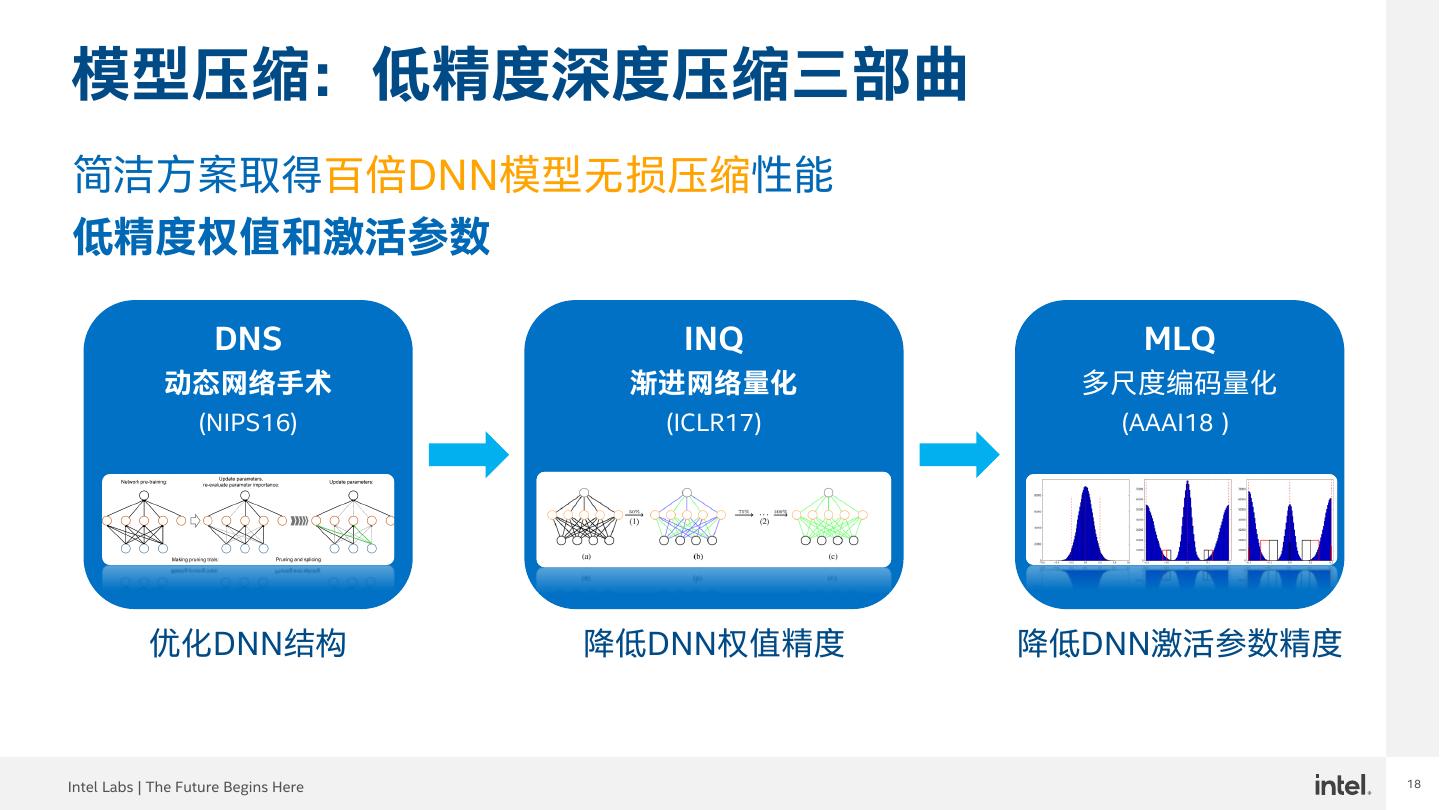
18 .18 模型压缩:低精度深度压缩三部曲 简洁方案取得百倍DNN模型无损压缩性能 低精度权值和激活参数 DNS INQ MLQ 动态网络手术 渐进网络量化 多尺度编码量化 (NIPS16) (ICLR17) (AAAI18) 优化DNN结构 降低DNN权值精度 降低DNN激活参数精度 Intel Labs | The Future Begins Here 18
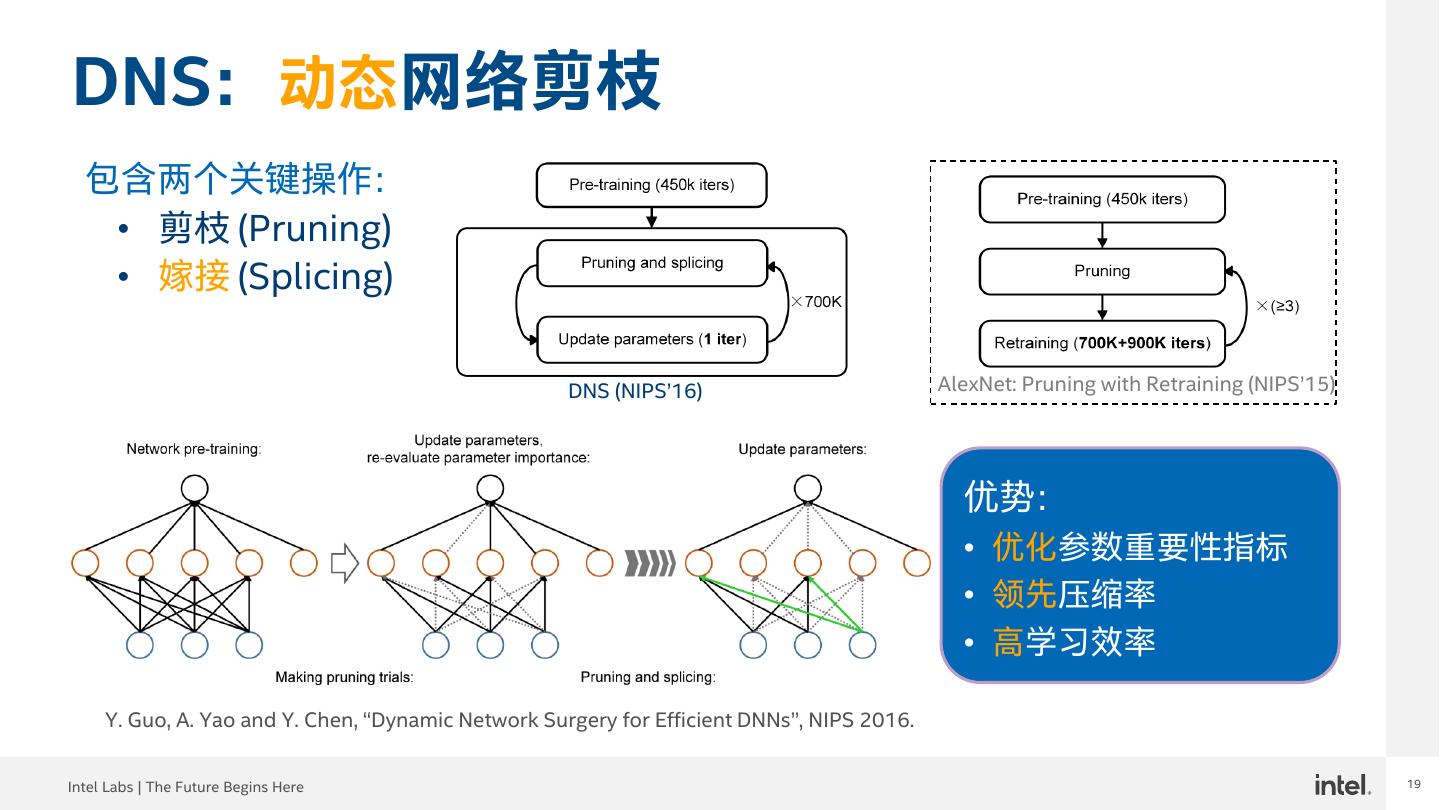
19 .19 DNS:动态网络剪枝 包含两个关键操作: • 剪枝 (Pruning) • 嫁接 (Splicing) DNS (NIPS’16) AlexNet: Pruning with Retraining (NIPS’15) 优势: • 优化参数重要性指标 • 领先压缩率 • 高学习效率 Y. Guo, A. Yao and Y. Chen, “Dynamic Network Surgery for Efficient DNNs”, NIPS 2016. Intel Labs | The Future Begins Here 19
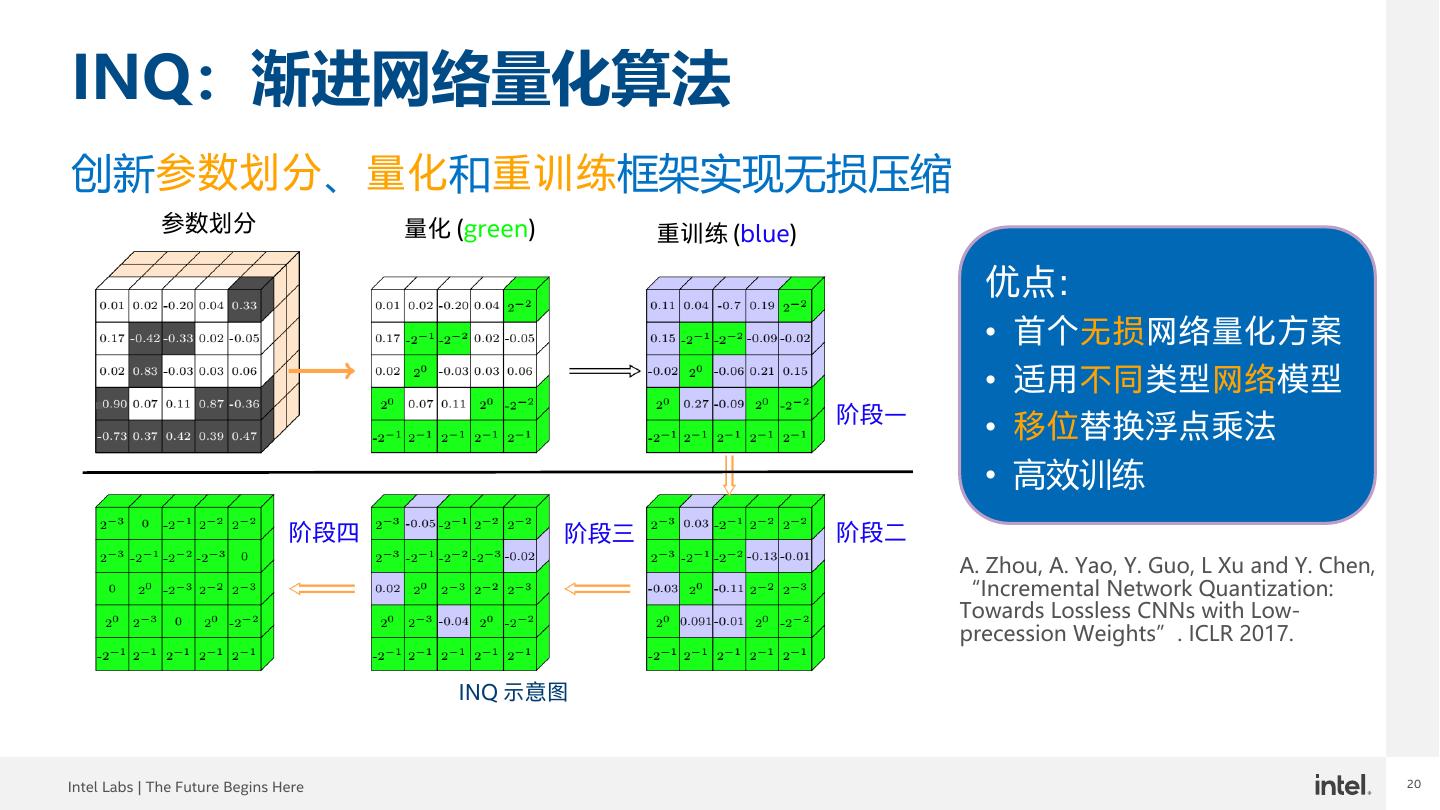
20 .20 INQ:渐进网络量化算法 创新参数划分、量化和重训练框架实现无损压缩 参数划分 量化 (green) 重训练 (blue) 优点: • 首个无损网络量化方案 • 适用不同类型网络模型 阶段一 • 移位替换浮点乘法 • 高效训练 阶段四 阶段三 阶段二 A. Zhou, A. Yao, Y. Guo, L Xu and Y. Chen, “Incremental Network Quantization: Towards Lossless CNNs with Low- precession Weights”. ICLR 2017. INQ 示意图 Intel Labs | The Future Begins Here 20
21 .21 INQ效果显著 对于主流DNN网络,5-bit 量化提高识别准确率, 在超低精度(2/3-bit) 时仍可取得接近全精度模型识别准确率 5-bit 量化结果 更低bit量化结果 A. Zhou, A. Yao, Y. Guo, L Xu and Y. Chen, “Incremental Network Quantization: Towards Lossless CNNs with Low-precession Weights”. ICLR 2017. Intel Labs | The Future Begins Here 21
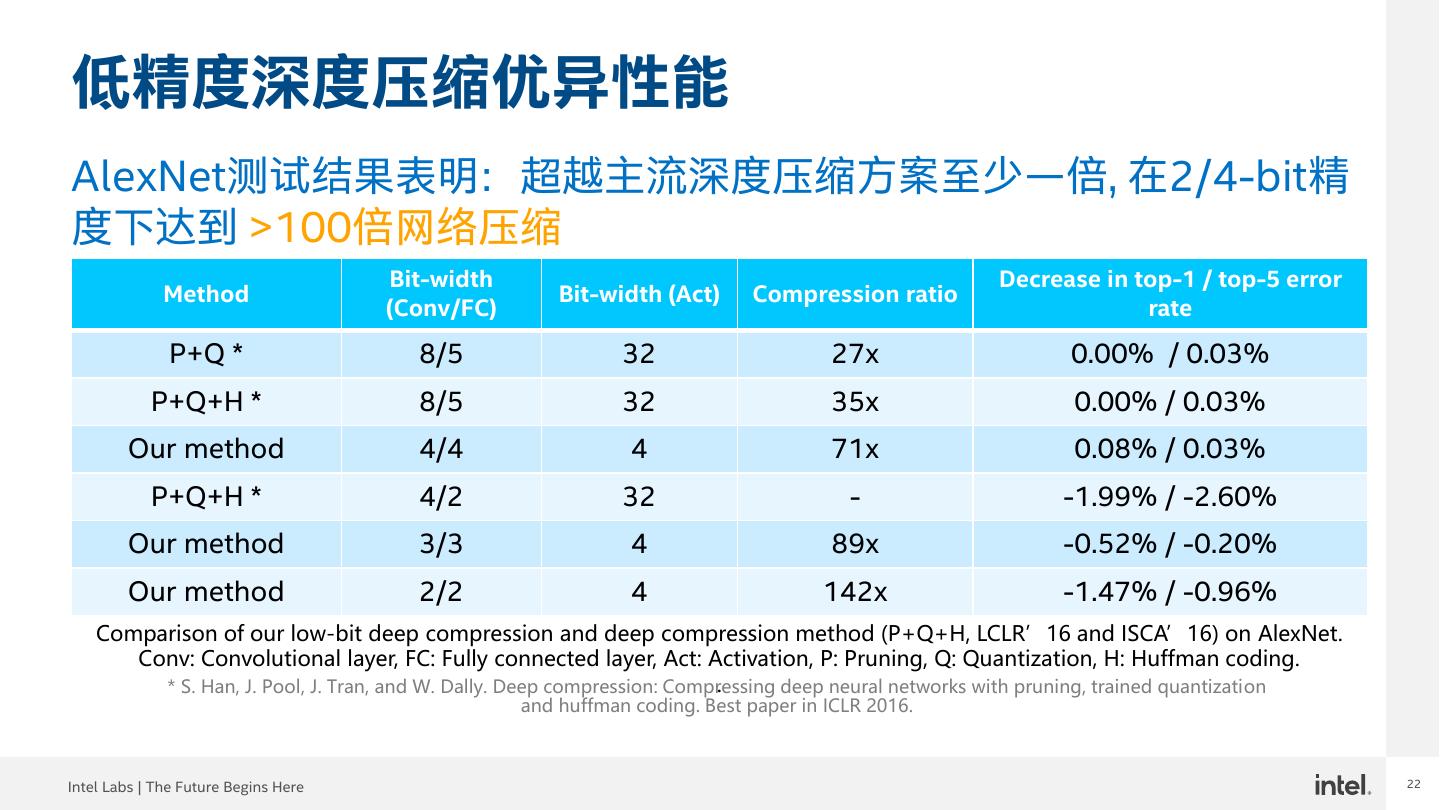
22 .22 低精度深度压缩优异性能 AlexNet测试结果表明:超越主流深度压缩方案至少一倍, 在2/4-bit精 度下达到 >100倍网络压缩 Bit-width Decrease in top-1 / top-5 error Method Bit-width (Act) Compression ratio (Conv/FC) rate P+Q * 8/5 32 27x 0.00% / 0.03% P+Q+H * 8/5 32 35x 0.00% / 0.03% Our method 4/4 4 71x 0.08% / 0.03% P+Q+H * 4/2 32 - -1.99% / -2.60% Our method 3/3 4 89x -0.52% / -0.20% Our method 2/2 4 142x -1.47% / -0.96% Comparison of our low-bit deep compression and deep compression method (P+Q+H, LCLR’16 and ISCA’16) on AlexNet. Conv: Convolutional layer, FC: Fully connected layer, Act: Activation, P: Pruning, Q: Quantization, H: Huffman coding. . * S. Han, J. Pool, J. Tran, and W. Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. Best paper in ICLR 2016. Intel Labs | The Future Begins Here 22
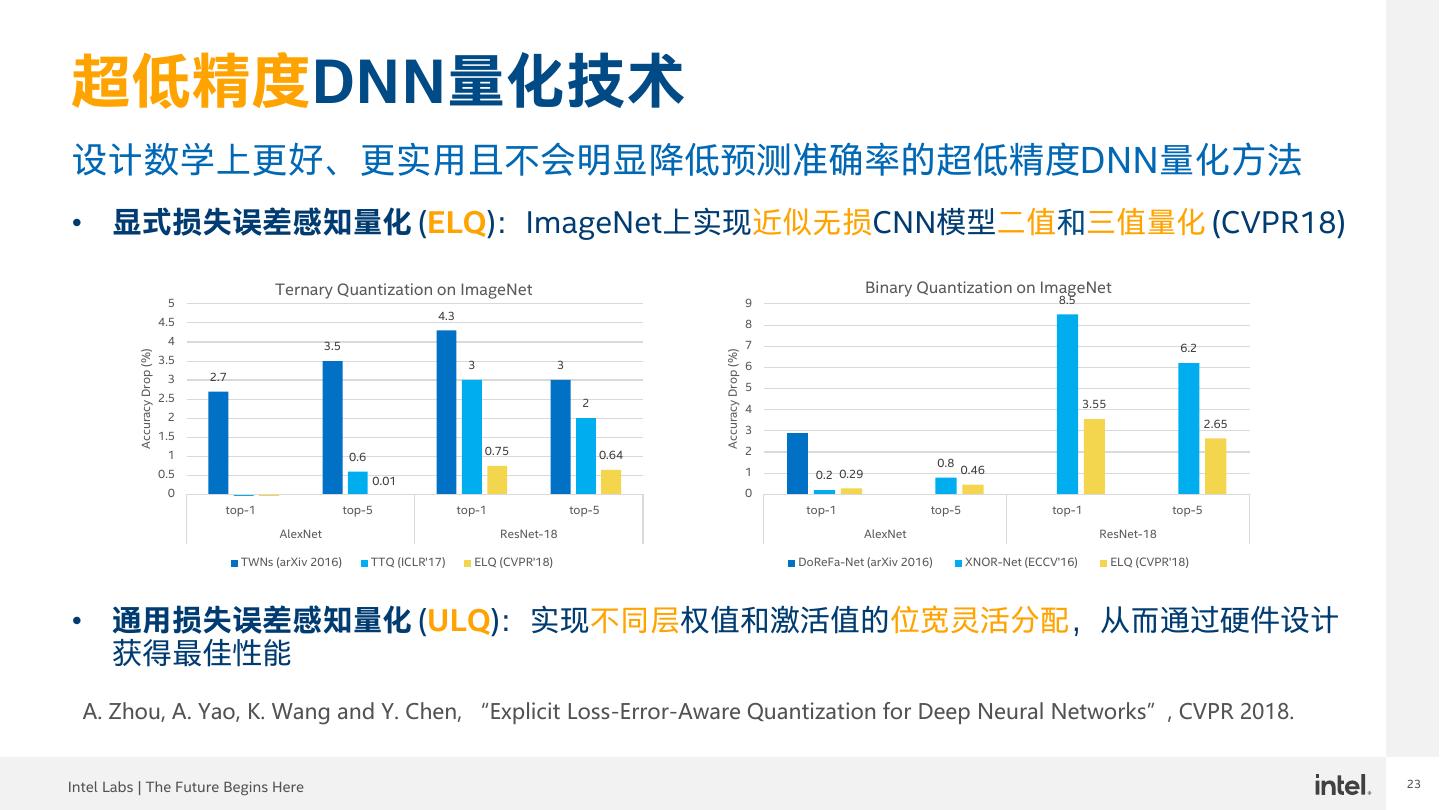
23 .23 超低精度DNN量化技术 设计数学上更好、更实用且不会明显降低预测准确率的超低精度DNN量化方法 • 显式损失误差感知量化 (ELQ):ImageNet上实现近似无损CNN模型二值和三值量化 (CVPR18) Ternary Quantization on ImageNet Binary Quantization on ImageNet 5 9 8.5 4.5 4.3 8 4 3.5 7 6.2 Accuracy Drop (%) Accuracy Drop (%) 3.5 3 3 6 3 2.7 5 2.5 2 4 3.55 2 2.65 3 1.5 1 0.6 0.75 0.64 2 0.8 0.5 1 0.2 0.29 0.46 0.01 0 0 top-1 top-5 top-1 top-5 top-1 top-5 top-1 top-5 AlexNet ResNet-18 AlexNet ResNet-18 TWNs (arXiv 2016) TTQ (ICLR'17) ELQ (CVPR'18) DoReFa-Net (arXiv 2016) XNOR-Net (ECCV'16) ELQ (CVPR'18) • 通用损失误差感知量化 (ULQ):实现不同层权值和激活值的位宽灵活分配,从而通过硬件设计 获得最佳性能 A. Zhou, A. Yao, K. Wang and Y. Chen, “Explicit Loss-Error-Aware Quantization for Deep Neural Networks”, CVPR 2018. Intel Labs | The Future Begins Here 23
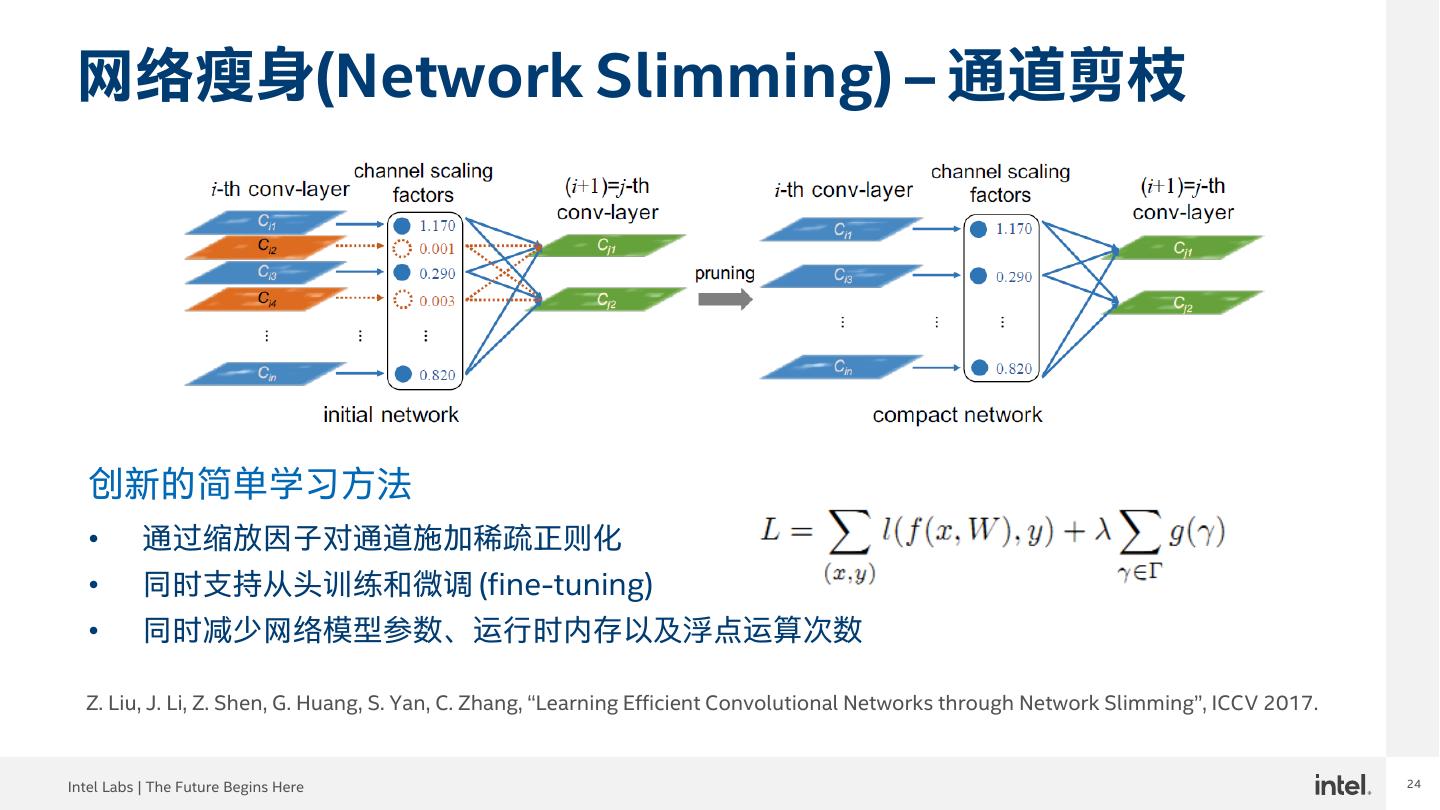
24 .24 网络瘦身(Network Slimming) – 通道剪枝 创新的简单学习方法 • 通过缩放因子对通道施加稀疏正则化 • 同时支持从头训练和微调 (fine-tuning) • 同时减少网络模型参数、运行时内存以及浮点运算次数 Z. Liu, J. Li, Z. Shen, G. Huang, S. Yan, C. Zhang, “Learning Efficient Convolutional Networks through Network Slimming”, ICCV 2017. Intel Labs | The Future Begins Here 24
25 .25 边缘视觉推断软硬件加速 超/低精度DNN量化和稀疏化技术配合英特尔低功耗硬件和软件工具,可为边缘 计算提供深度学习推断软硬件加速能力 Intel FPGAs 视觉推断和神经网络优化 Intel Labs | The Future Begins Here 25
26 .26 边缘深度视觉推断研究成果 高效CNN 首项工作 卷积层聚合 新表征: 特征金字塔 首项工作 从头训练 轻量级: 两个新颖模块 首项工作 空间/通道特征相关性编码 结构设计 HyperNet RON DSOD Tiny-DSOD HBONet DSOD (CVPR’16) (CVPR’17) (ICCV’17) (BMVC’18) (ICCV’19) (TPAMI, 2020) DNN模型 DNN 压缩: 网络剪枝: 网络量化: 压缩 非结构化/结构化 低比特/超低比特 稀疏矩阵分解 DNS N-Slimming INQ NS MLQ/ELQ/ULQ SQ SMF (NIPS’16) (ICCV’17) (ICLR’17) (CVPR’17) (AAAI/CVPR’18) (IJCV, 2019) (TNNLS, 2020) 部署时 部署时 DNN 加速: 网络结构 不需要重训练及深度学习专家 优化 ND CBDNet FSKD (BMVC’18) (AAAI’19) (CVPR’20) 2016 2017 2018 2019 2020 Intel Labs | The Future Begins Here 26
27 .27 部署时网络结构优化 一组在部署时优化DNN速度及减少资源消耗的技术,它无需重训练和微调,无需 完整训练数据集,无需深度学习专家参与 • 网络解耦 (ND,BMVC’18) • 复合二进制分解 (CBDNet,AAAI’19) • 小样本知识蒸馏 (FSKD,CVPR’20) 在边缘计算应用场景推广深度学习 (DL) • 优化 DL 解决方案 • DL 加速或硬件设计的工具链 • DL 软件框架插件或编译器 深度学习推断加速和减少更多资源消耗的一键式解决方案 Intel Labs | The Future Begins Here 27
28 .28 议程 • 简介 • 高效CNN算法设计及实际应用 • 深度模型压缩优化及技术落地 • 以人为中心的视觉分析与合成 • 总结及展望 Intel Labs | The Future Begins Here 28
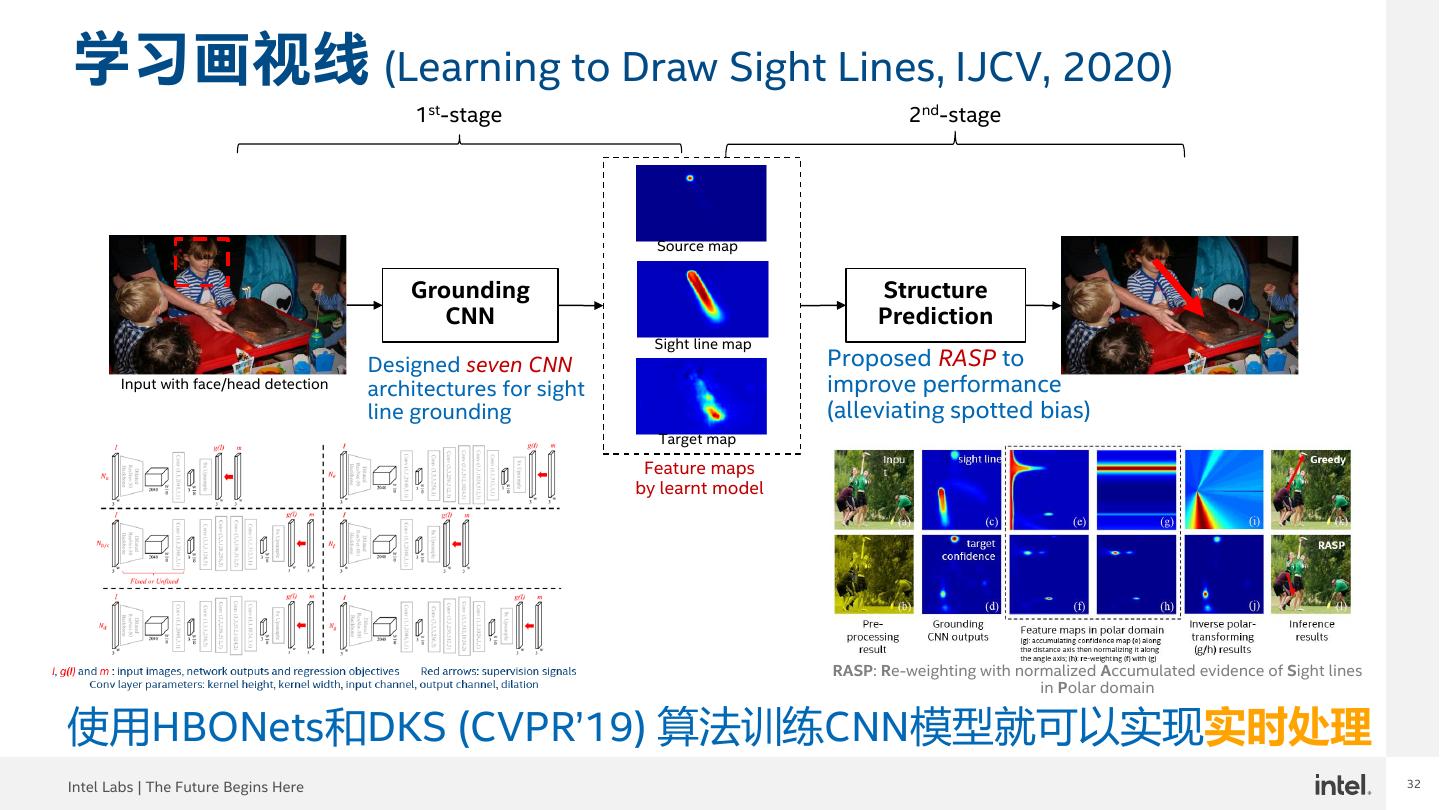
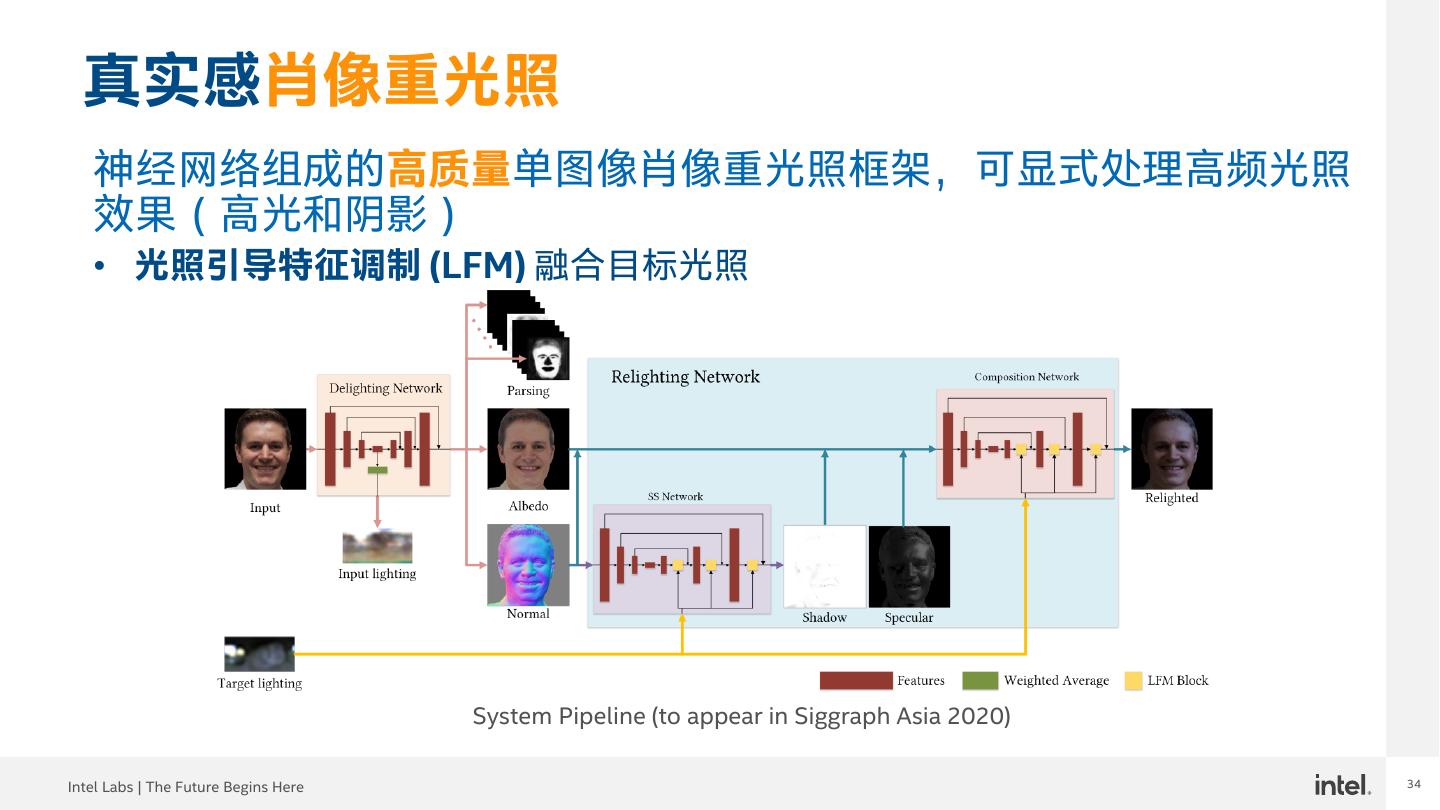
29 .COVID-19的影响 以人为中心视觉析与合成增强在线办公室/活动, 教育和医疗保健的虚拟参与度… Intel Labs | The Future Begins Here 29
3秒后跳转登录页面
去登陆

