






















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
英特尔低精度量化原理与方法
本课程介绍深度学习推理中低精度量化加速的原理,英特尔提供的软硬件支持。最后通过动手练习,学习使用英特尔低精度优化工具对Tensorflow模型进行量化,从而加速深度学习推理。
展开查看详情
1 .Tian, Feng <feng.tian@intel.com> Software Architect Machine Learning Performance Group Intel Architecture, Graphics and Software
2 . 法律声明 英特尔技术的特性和优势取决于系统配置,并需要借助兼容的硬件、软件或服务来实现。实际性能可能因系统配置的不同而有所差异。任何计算机系统都无法保证 绝对安全。请咨询您的系统制造商或零售商,也可登录 intel.cn 获取更多信息。 在特定系统中通过特殊测试对组件的文档性能进行测试。硬件、软件或配置的任何不同都会影响实际性能。考虑购买时,请查阅其他信息来源以评估性能。有关性 能和基准测试结果的更完整的信息,请访问 http://www.intel.cn/content/www/cn/zh/benchmarks/intel-product-performance.html。 在性能检测过程中涉及的软件及其性能只有在英特尔® 微处理器的架构下方能得到优化。诸如 SYSmark* 和 MobileMark* 等性能测试均系基于特定计算机系统、组 件、软件、操作及功能。上述任何要素的变动均有可能导致测试结果的变化。您应该参考其他信息和性能测试以帮助您全面评估您正在考虑的采购,包括产品在与 其他产品结合使用时的性能。 更多信息请访问 http://www.intel.com/content/www/cn/zh/benchmarks/intel-product-performance.html。 所描述的降低成本方案仅用作示例,表明某些基于英特尔的产品在特定环境和配置下会如何影响未来的成本,并节约成本。 环境各不相同。 英特尔不保证任何成本 和成本的节约。 本文包含尚处于开发阶段的产品、服务和/或流程的信息。 此处提供的所有信息可随时更改,恕不另行通知。请联系您的英特尔代表,了解最新的预测、时间表、规 格和路线图。 本文件不构成对任何知识产权的授权,包括明示的、暗示的,也无论是基于禁止反言的原则或其他。 本文中涉及的本季度、本年度和未来的英特尔规划和预期的陈述均为前瞻性陈述,包含许多风险和不确定性。英特尔 SEC 报告中包含关于可能影响英特尔结果和计划 的因素的详细讨论,包括有关 10-K 报表的年度报告。 所有指定的产品、计算机系统、日期和数字信息均为依据当前期望得出的初步结果,可随时更改,恕不另行通知。所述产品可能包含设计缺陷或错误(已在勘误表 中注明),这可能会使产品偏离已经发布的技术规范。英特尔提供最新的勘误表备索。 英特尔不控制或审计本文提及的第三方基准测试数据或网址。您应访问引用的网站,确认参考资料准确无误。 © 英特尔公司版权所有。英特尔、英特尔标识、Intel Inside 标记和标识、Arria、Cyclone、英特尔至强、MAX、Quartus 和 Stratix 是英特尔在美国和/或其他国家的商 标。 *其他商标和品牌可能是其他所有者的资产。 英特尔、英特尔标识和其他标识是英特尔公司在美国和/或其他国家的商标。 Altera、Arria、Cyclone、Enpirion、Max、Megcore、Nios、Quartus 和 Stratix 字眼和标识是 Altera 的商标,在美国专利及商标局和其他国家进行了注册。 * 文中涉及的其它名称及商标属于各自所有者资产。 Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Copyright ©, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
3 . 目录 • 深度学习推理量化技术基础 • 第二代英特尔®至强®可扩展平台对低精度的支持 • Intel Low Precision Optimization Tool介绍 Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Copyright ©, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
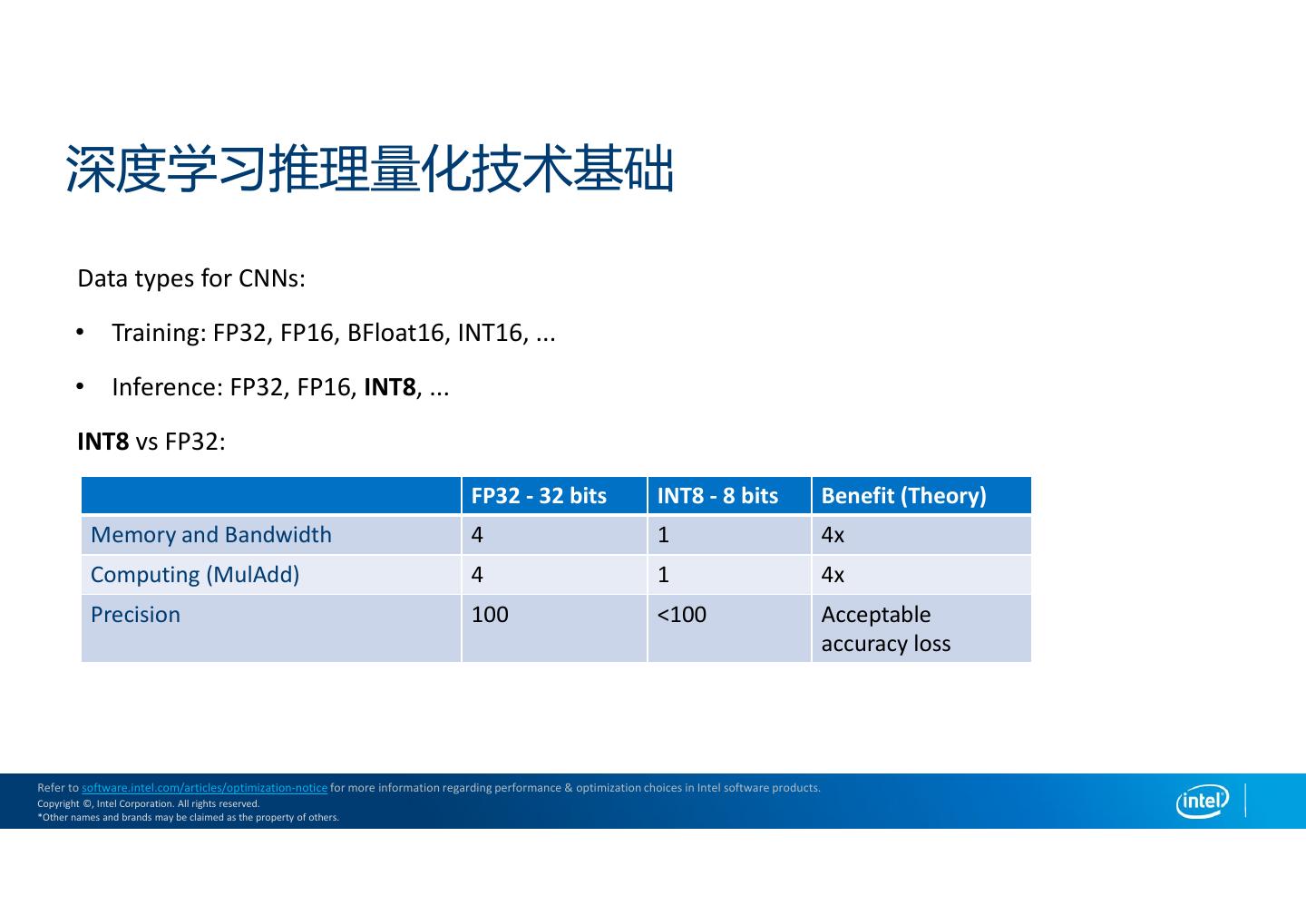
4 . 深度学习推理量化技术基础 Data types for CNNs: • Training: FP32, FP16, BFloat16, INT16, ... • Inference: FP32, FP16, INT8, ... INT8 vs FP32: FP32 - 32 bits INT8 - 8 bits Benefit (Theory) Memory and Bandwidth 4 1 4x Computing (MulAdd) 4 1 4x Precision 100 <100 Acceptable accuracy loss Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Copyright ©, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
5 . 第二代英特尔®至强®可扩展平台上的深度学习推理量 化VNNI加速 AVX512 FMA Instructions VNNI FMA Instruction AVX512: VPMADDUBSW υ8×s8→s16 mul ples, VPMADDWD broadcast1 s16→s32, and VPADDD s32→s32 adds the result to accumulator. This allows for 4x more input over fp32 at the cost of 3x more instructions or 33.33% more compute and ¼ the memory requirement. AVX512_VNNI:8-bit multiplies with 32-bit accumulates with 1 instruction u8×s8→s32 providing a theore cal peak compute gain of 4x int8 OPS over fp32 OPS. Pictures above are from https://en.wikichip.org/wiki/x86/avx512vnni Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Intel Copyright Internal ©, Intel Audit Corporation. All rights reserved. 5 *Other names and brands may be claimed as the property of others.
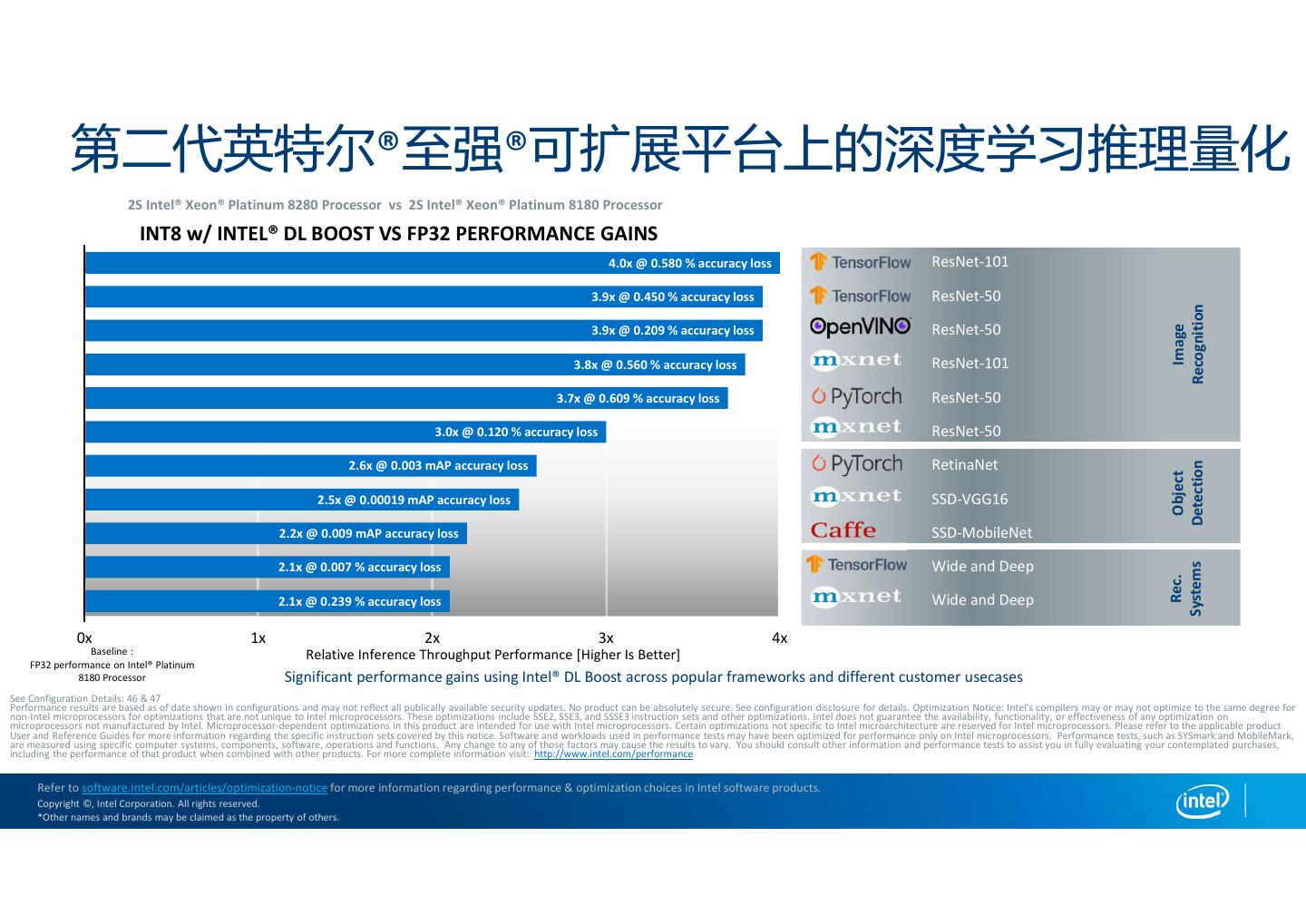
6 . 第二代英特尔®至强®可扩展平台上的深度学习推理量化 2S Intel® Xeon® Platinum 8280 Processor vs 2S Intel® Xeon® Platinum 8180 Processor INT8 w/ INTEL® DL BOOST VS FP32 PERFORMANCE GAINS 4.0x @ 0.580 % accuracy loss ResNet-101 3.9x @ 0.450 % accuracy loss ResNet-50 Recognition 3.9x @ 0.209 % accuracy loss ResNet-50 Image 3.8x @ 0.560 % accuracy loss ResNet-101 3.7x @ 0.609 % accuracy loss ResNet-50 3.0x @ 0.120 % accuracy loss ResNet-50 2.6x @ 0.003 mAP accuracy loss RetinaNet Detection Object 2.5x @ 0.00019 mAP accuracy loss SSD-VGG16 2.2x @ 0.009 mAP accuracy loss SSD-MobileNet 2.1x @ 0.007 % accuracy loss Wide and Deep Systems Rec. 2.1x @ 0.239 % accuracy loss Wide and Deep 0x 1x 2x 3x 4x Baseline : Relative Inference Throughput Performance [Higher Is Better] FP32 performance on Intel® Platinum 8180 Processor Significant performance gains using Intel® DL Boost across popular frameworks and different customer usecases See Configuration Details: 46 & 47 Performance results are based as of date shown in configurations and may not reflect all publically available security updates. No product can be absolutely secure. See configuration disclosure for details. Optimization Notice: Intel's compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit: http://www.intel.com/performance Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Copyright ©, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
7 . oneDNN介绍 开源仓库: – https://github.com/oneapi-src/oneDNN 特性: – 开源矩阵运算库,针对Intel硬件有专门的优化。 – C及C++实现以追求极致性能 – 支持Linux, Windows和MacOS – 丰富线程库支持: OpenMP和Intel TBB Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Copyright ©, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
8 . oneDNN术语 Primitive – abstraction for an operation Convolution, ReLU, pooling, reorder, etc Memory – abstraction for a tensor Engine – abstraction for an execution device Acts as an identifier for HW Stream – abstraction for an execution context Has an associated engine Executes primitives Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Copyright ©, Intel Corporation. All rights reserved. 8 *Other names and brands may be claimed as the property of others.
9 . oneDNN使用例子 // Create a CPU engine auto eng = engine(engine::cpu, 0); // Create memory with user-provided memory float data[1 * 1 * 2 * 2] = { -1, 2, -3, 4 }; auto tz = memory::dims{ 1, 1, 2, 2 }; auto mem_d = memory::desc({ tz }, memory::data_type::f32, memory::format::nchw); auto mem_pd = memory::primitive_desc(mem_d, eng); auto mem = memory(mem_pd, data); // Create ReLU primitive auto relu_d = eltwise_forward::desc(prop_kind::forward, algorithm::eltwise_relu, mem_d, 0.0f); auto relu_pd = eltwise_forward::primitive_desc(relu_d, eng); auto relu = eltwise_forward(relu_pd, mem, mem); // Create a stream and execute ReLU primitive auto s = stream(eng); s.submit({ relu }); s.wait(); // Output the result (should be [0, 2, 0, 4]) printf("data: [%f, %f, %f, %f]\n", data[0], data[1], data[2], data[3]); Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Copyright ©, Intel Corporation. All rights reserved. 9 *Other names and brands may be claimed as the property of others.
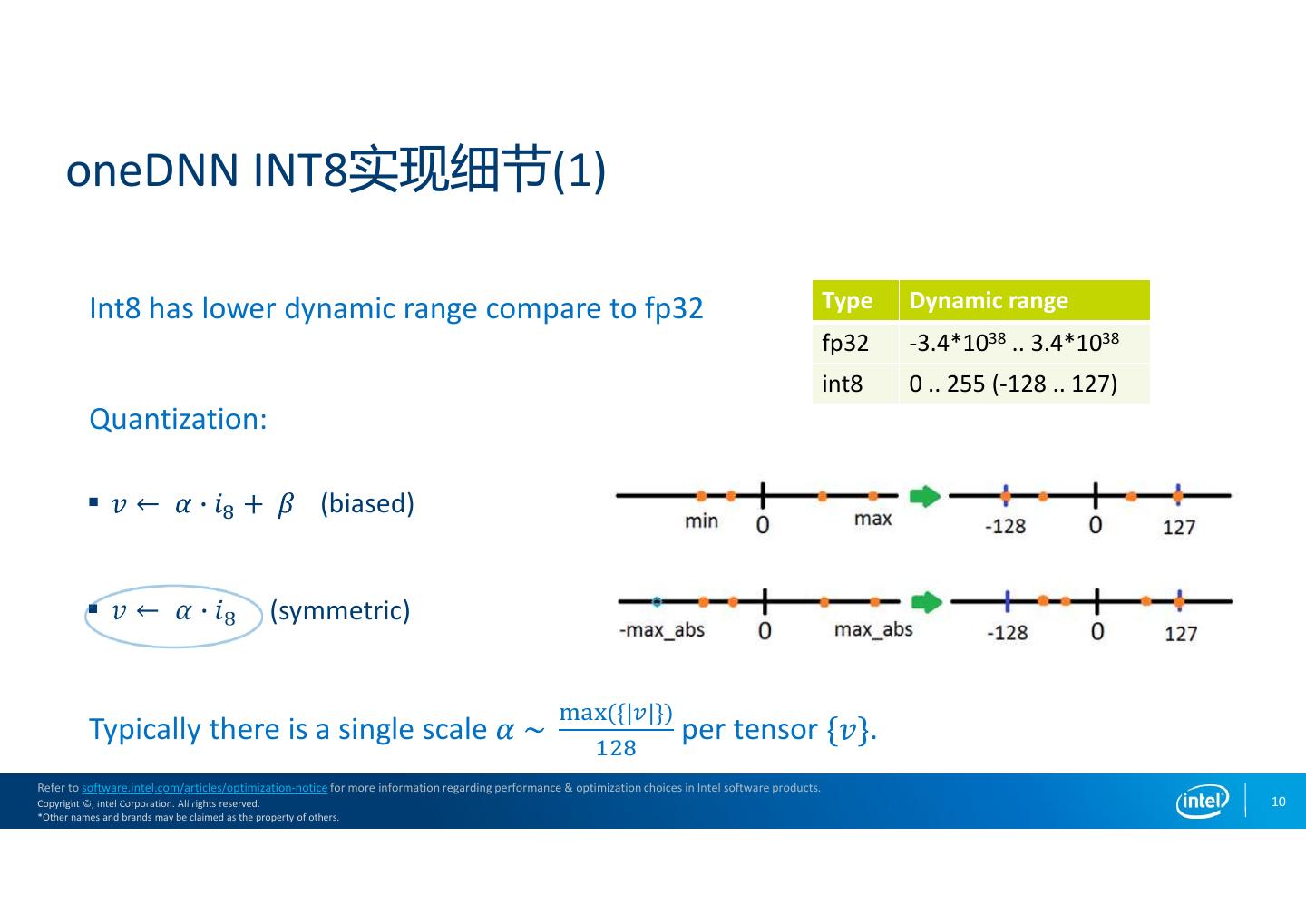
10 . oneDNN INT8实现细节(1) Int8 has lower dynamic range compare to fp32 Type Dynamic range fp32 -3.4*1038 .. 3.4*1038 int8 0 .. 255 (-128 .. 127) Quantization: (biased) (symmetric) ({| |}) Typically there is a single scale per tensor . Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Intel Copyright Internal ©, Intel Audit Corporation. All rights reserved. 10 *Other names and brands may be claimed as the property of others.
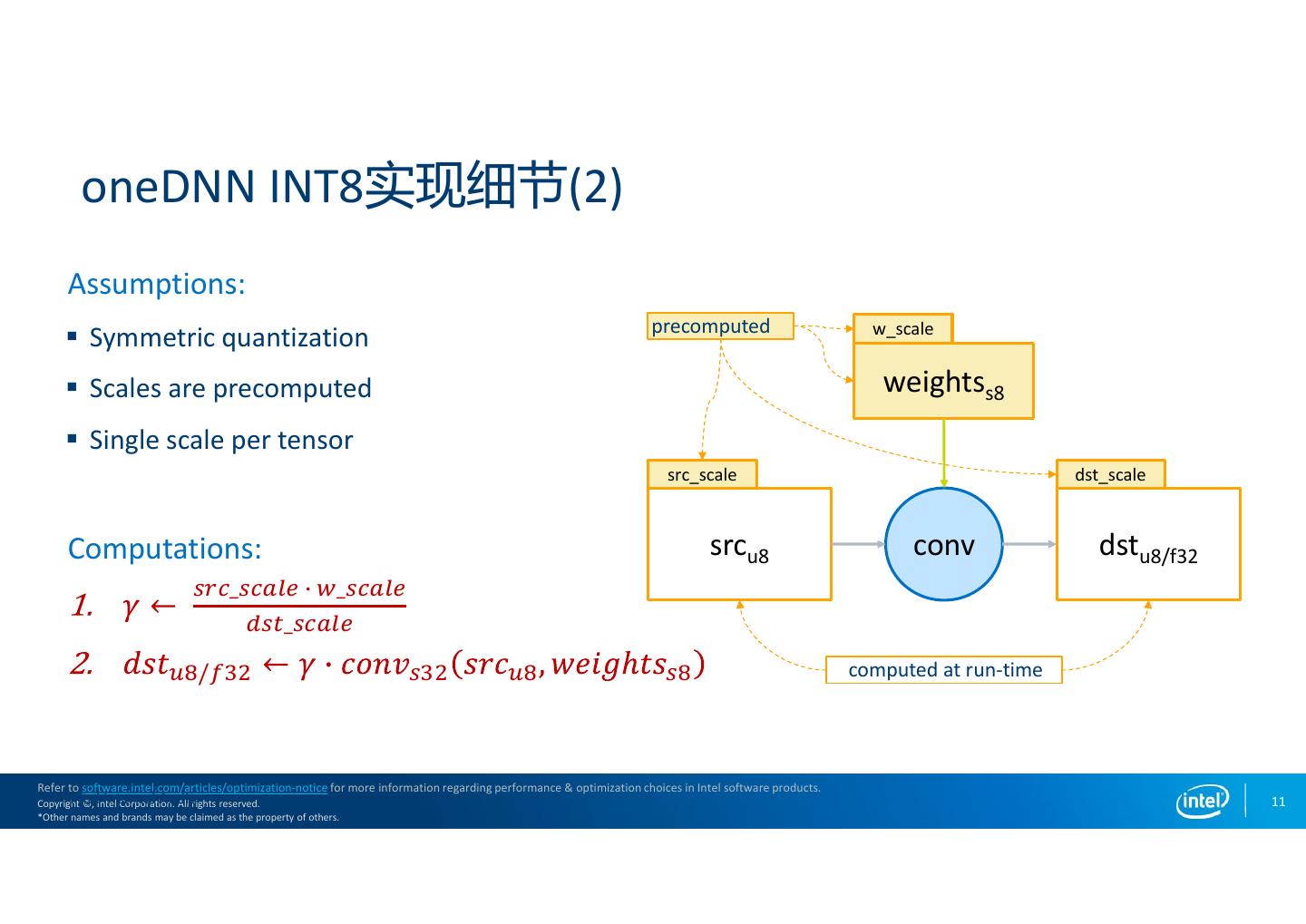
11 . oneDNN INT8实现细节(2) Assumptions: precomputed w_scale Symmetric quantization Scales are precomputed weightss8 Single scale per tensor src_scale dst_scale Computations: srcu8 conv dstu8/f32 _ _ _ / computed at run-time Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Intel Copyright Internal ©, Intel Audit Corporation. All rights reserved. 11 *Other names and brands may be claimed as the property of others.
12 . oneDNN INT8 卷积数学公式(1): One scale for activation dst = conv( src, wei ) (scaledst, dstu8[:]) = conv( (scalesrc, srcu8[:]), (scalewei, weis8[:]) ) dstu8[:] = scalesrc * scalewei / scaledst * conv( srcu8[:], weis8[:] ) dstu8[:] = scale * convs32( srcu8[:], weis8[:] ) dstu8[:] = (u8) scale * { (f32) convs32( srcu8[:], weis8[:] ) + biaf32 } Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Intel Copyright Internal ©, Intel Audit Corporation. All rights reserved. 12 *Other names and brands may be claimed as the property of others.
13 . oneDNN INT8卷积数学公式(2): Multiple scales per weights tensor dst = conv( src, wei ) (scaledst, dstu8[oc, :]) = conv( (scalesrc, srcu8[:]), (scalewei[oc], weis8[oc, :]) ) dstu8[oc, :] = scalesrc * scalewei[oc] / scaledst * conv( srcu8[:], weis8[oc, :] ) dstu8[] = scale[oc] * convs32( srcu8[:], weis8[oc, :] ) dstu8[oc, :] = (u8) scale[oc] * { (f32) convs32( srcu8[:], weis8[oc, :] ) + biaf32[oc] } Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Intel Copyright Internal ©, Intel Audit Corporation. All rights reserved. 13 *Other names and brands may be claimed as the property of others.
14 . oneDNN算子融合: Fusing Op conv dst = scale[c]*(src_u8*wei_s8 + bia_f32) conv.acc(beta) dst = beta*dst + scale[c]*(src_u8*wei_s8 + bia_f32) conv.eltwise(gamma) dst = gamma*eltwise(scale[c]*(src_u8*wei_s8 + bia_f32)) conv.acc(beta).eltwise(gamma) dst = gamma*eltwise(scale[c]*(src_u8*wei_s8 + bia_f32) + beta*dst) conv.eltwise(gamma).acc(beta) dst = beta*dst + gamma*eltwise(scale[c]*(src_u8*wei_s8 + bia_f32)) reorder dst = scale*reorder(src) reorder.acc(beta) dst = beta*dst + scale*reorder(src) Note: for f32 scale = beta = gamma = 1. Note: for int8 all intermediate computations are in f32 (except for src_u8*wei_s8) Note: for int8 for relu and some other alg_kinds gamma = 1. Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Intel Copyright Internal ©, Intel Audit Corporation. All rights reserved. 14 *Other names and brands may be claimed as the property of others.
15 . INT8 算子使用方法总结: Basic INT8 Policy Convolution: INT8 in, INT8 out (not suitable for sum), S32 bias FC (non-classification): INT8 in, INT8 out Pooling (Max & Average): INT8 in, INT8 out Constant folding: convolution + Batch Normalization Advanced INT8 Policy Depthwise convolution: channel-wise scaling factor (based on MKL-DNN primitive) Convolution in inception block: concatenation convolution with INT8 output FC and Conv (classification): INT8 in, FP32 out Fusion: convolution and ReLU; convolution and element-wise sum in residual block S8S8 convolution: first convolution and other convolution after non-ReLU activation Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Intel Copyright Internal ©, Intel Audit Corporation. All rights reserved. 15 *Other names and brands may be claimed as the property of others.
16 . BatchNorm Folding: Batch Normalization (BN) at inference is not needed as it can be absorbed by its preceding layer by scaling the weight values and modifying the bias. Picture above is from ://software.intel.com/en-us/articles/lower-numerical-precision-deep-learning-inference- Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Intel Internal Audit 16 Copyright ©, Intel Corporation. and-training All rights reserved. *Other names and brands may be claimed as the property of others.
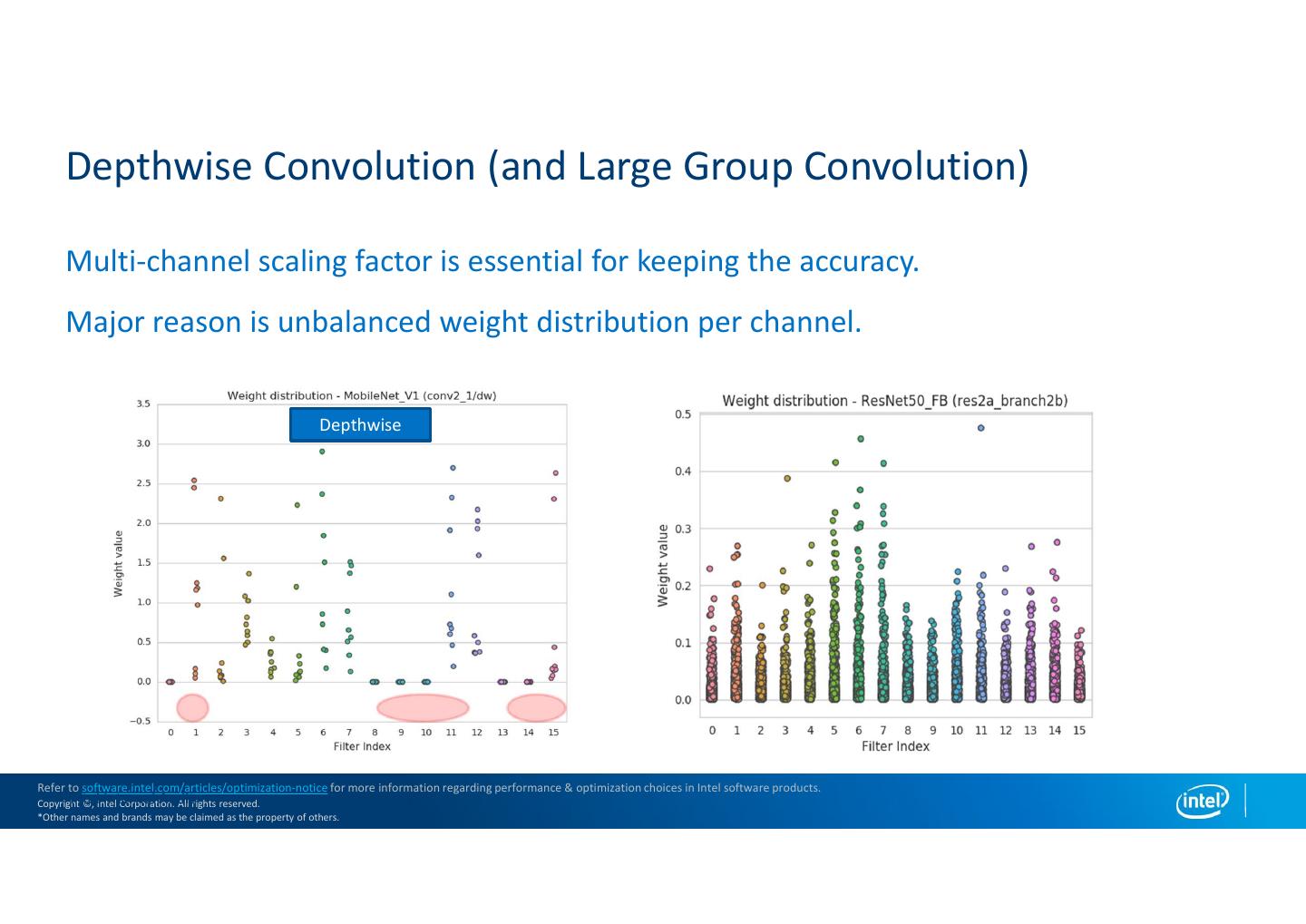
17 . Depthwise Convolution (and Large Group Convolution) Multi-channel scaling factor is essential for keeping the accuracy. Major reason is unbalanced weight distribution per channel. Depthwise Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Intel Copyright Internal ©, Intel Audit Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
18 . Convolutions in Inception Block Inception-block becomes widely-used pattern and filter concatenation is key component among them. Concat does not contribute the computation directly but needs to handle different scaling factors of different inputs. Our practice is to select the minimal scaling factor (255 / the maximal absolute activation value). Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Intel Copyright Internal ©, Intel Audit Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
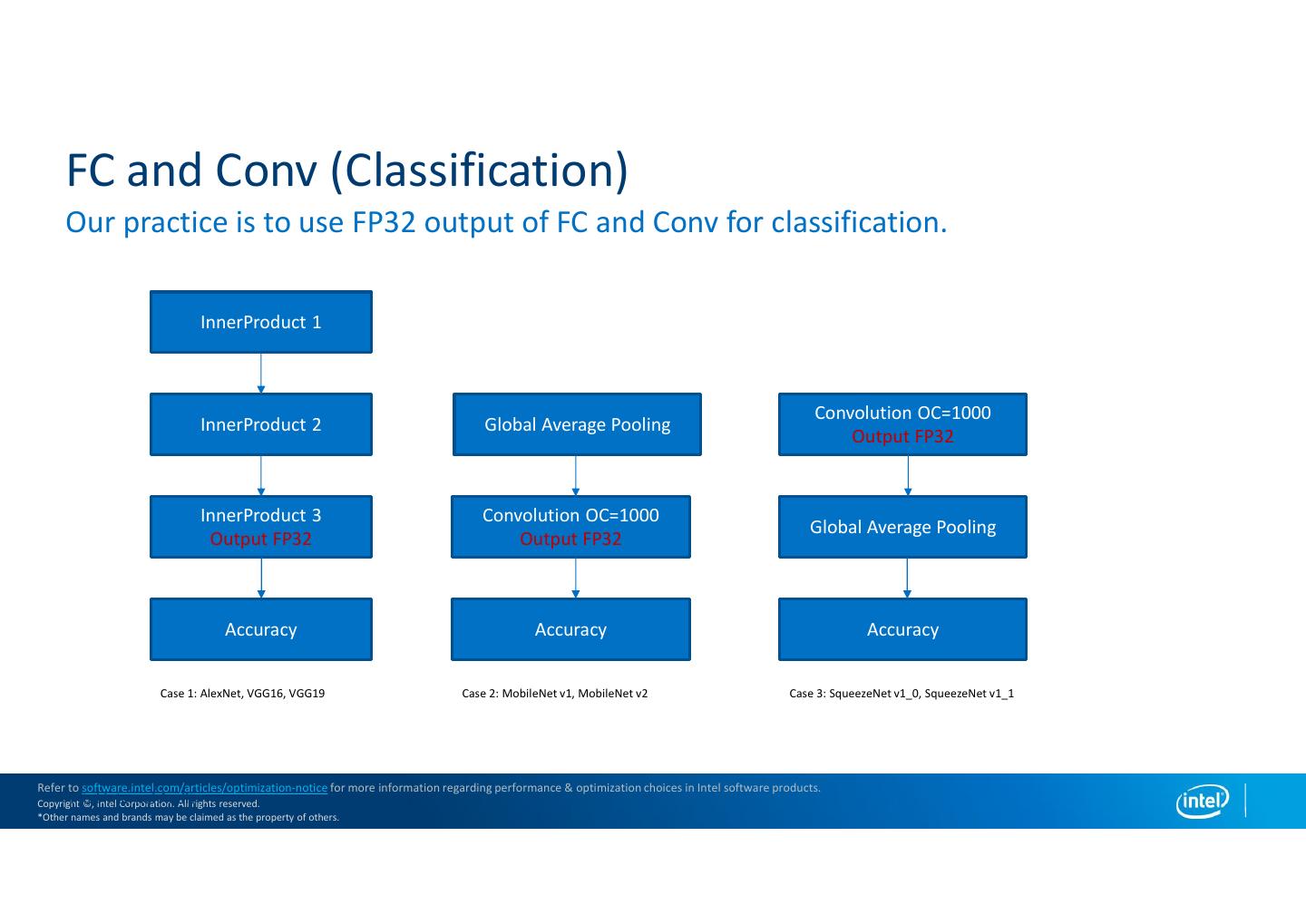
19 . FC and Conv (Classification) Our practice is to use FP32 output of FC and Conv for classification. InnerProduct 1 Convolution OC=1000 InnerProduct 2 Global Average Pooling Output FP32 InnerProduct 3 Convolution OC=1000 Global Average Pooling Output FP32 Output FP32 Accuracy Accuracy Accuracy Case 1: AlexNet, VGG16, VGG19 Case 2: MobileNet v1, MobileNet v2 Case 3: SqueezeNet v1_0, SqueezeNet v1_1 Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Intel Copyright Internal ©, Intel Audit Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
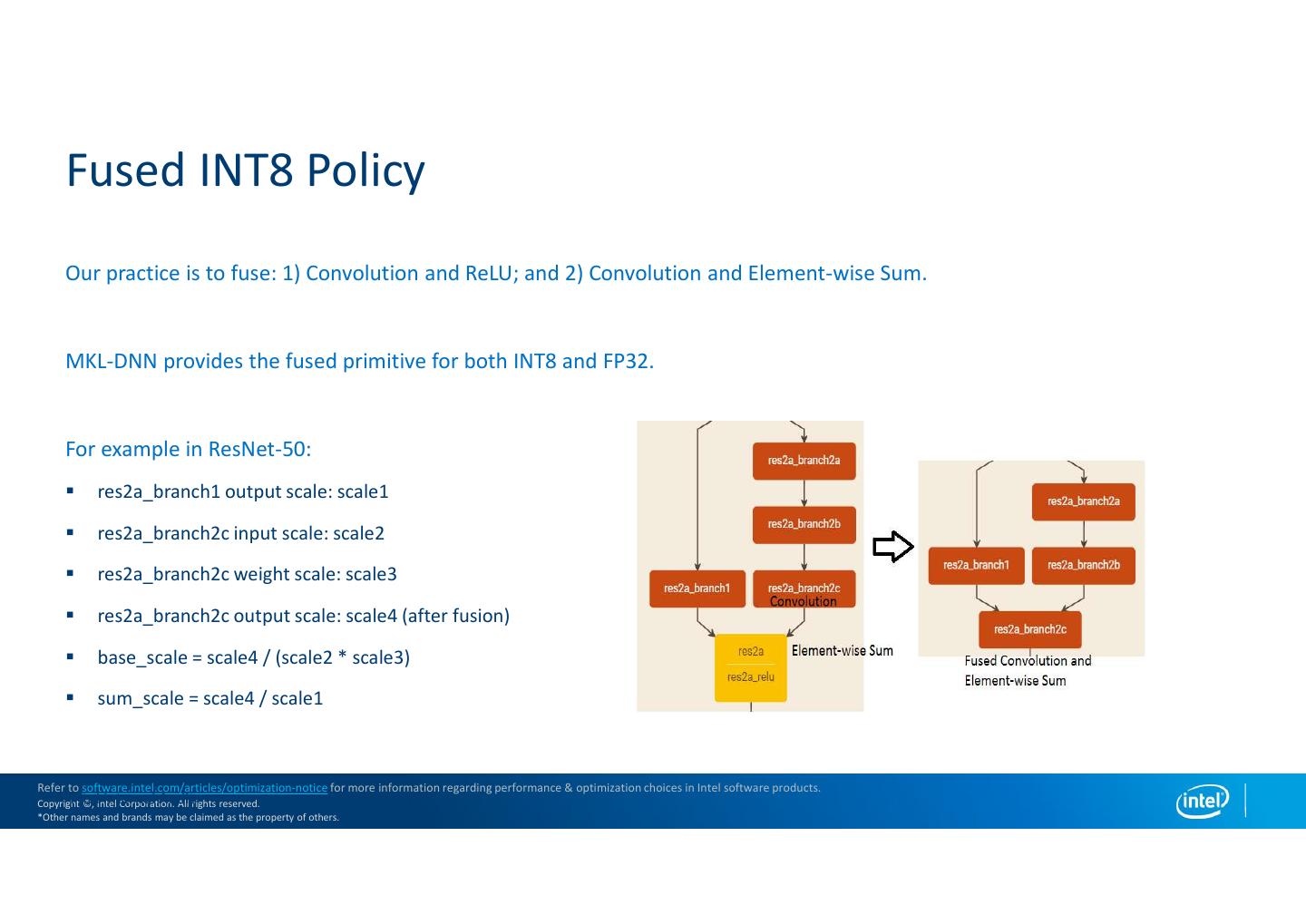
20 . Fused INT8 Policy Our practice is to fuse: 1) Convolution and ReLU; and 2) Convolution and Element-wise Sum. MKL-DNN provides the fused primitive for both INT8 and FP32. For example in ResNet-50: res2a_branch1 output scale: scale1 res2a_branch2c input scale: scale2 res2a_branch2c weight scale: scale3 res2a_branch2c output scale: scale4 (after fusion) base_scale = scale4 / (scale2 * scale3) sum_scale = scale4 / scale1 Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Intel Copyright Internal ©, Intel Audit Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
21 . S8S8卷积介绍 • S8S8 math equation: • 𝐶𝑜𝑛𝑣 𝐼, 𝑊 = ∑ ∈ 𝐼 ∗ 𝑊 = ∑ ∈ 𝐼 + 128 ∗ 𝑊 − 128 ∗ ∑ ∈ 𝑊 • S8S8 convolution performance is little lower than U8S8 convolution due to lack of h/w instruction support. • Shift inputs from S8 to U8 for VNNI • Add compensation 128 ∗ ∑ ∈ 𝑊 before convolution stores • Compute zero-padded areas Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Intel Copyright Internal ©, Intel Audit Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
22 . 不同Calibration方法对最终精度的影响 We checked the accuracy from different calibrations Sampling iteration 1 and 2 Single scale per weight tensor (S) or Multiple scales per output channel (M) Calibration algorithm: min-max (Direct) and KL Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Intel Copyright Internal ©, Intel Audit Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
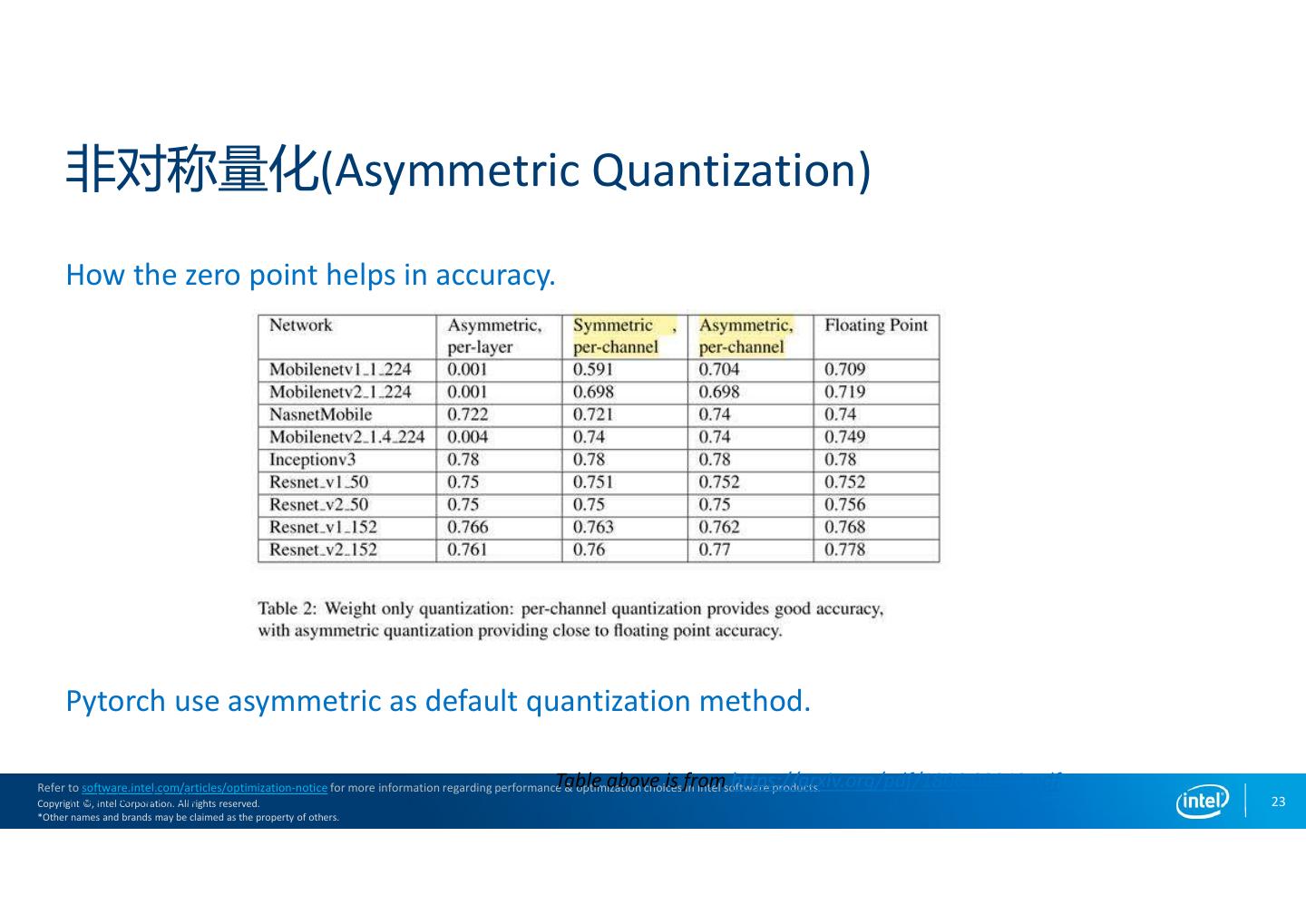
23 . 非对称量化(Asymmetric Quantization) How the zero point helps in accuracy. Pytorch use asymmetric as default quantization method. Table above is from https://arxiv.org/pdf/1806.08342.pdf Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Intel Copyright Internal ©, Intel Audit Corporation. All rights reserved. 23 *Other names and brands may be claimed as the property of others.
24 . BF16指令集介绍 BF16: Brain FloatingPoint16 Same range with FP32, precision is lower than FP32 Advantages over FP16: 1. Better range (8 bits vs 5 bits) => better convergence properties 2. Easy integration to framework 3. Very little impact on hyper-parameter Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Copyright ©, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
25 . AVX512_BF16 New Instructions on CPX Only three new instructions VCVTNE2PS2BF16 dest, src1, src2 VCVTNEPS2BF16 dest, src – Two fp32 to bf16 conversion instructions (just the operators are different) – Fp32 denormal to bf16 0, fp32 normal to bf16 with rounding to even. VDPBF16PS srcdest, src1, src2 – bf16 dot product – Input is bf16, intermediate is fp32 to do multiply-add, Output is fp32 Any operations which couldn’t utilize VDPBF16PS to boost perf up have to fallback to FP32 AVX instructions! Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Copyright ©, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
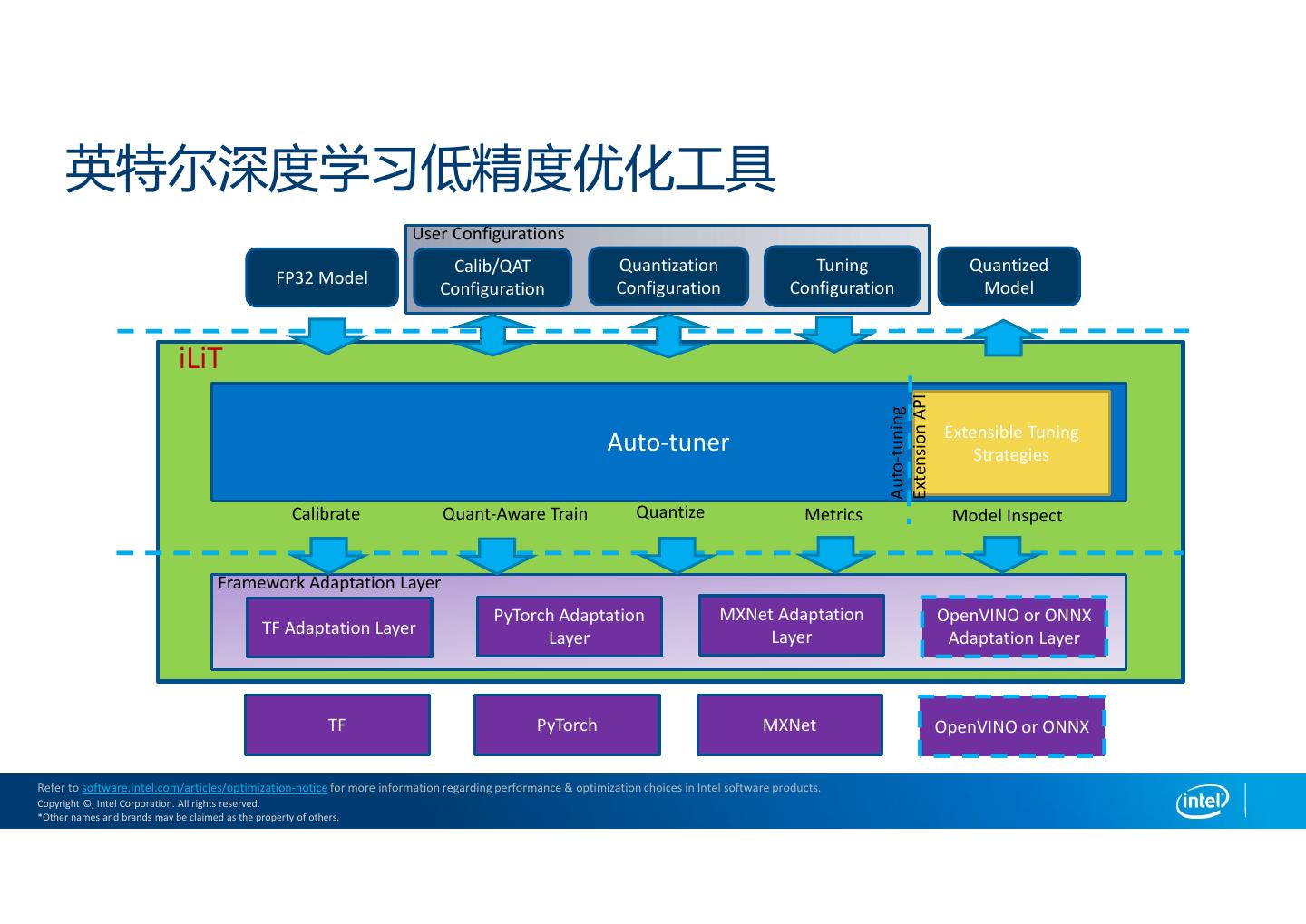
26 . 英特尔深度学习低精度优化工具介绍 开源仓库: – https://github.com/intel/lp-opt-tool 特性: – 开源Python库,提供跨神经网络开发框架的统一的低精度量化API入口 – 支持TensorFlow, PyTorch和MXNet – 以精度驱动的自动tuning工具 – 丰富的tuning策略(MSE, Bayesian, Exhaustive, Random) Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Copyright ©, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
27 . 英特尔深度学习低精度优化工具 User Configurations Calib/QAT Quantization Tuning Quantized FP32 Model Configuration Configuration Configuration Model iLiT Extension API Auto-tuning Extensible Tuning Auto-tuner Strategies Calibrate Quant-Aware Train Quantize Metrics Model Inspect Framework Adaptation Layer PyTorch Adaptation MXNet Adaptation OpenVINO or ONNX TF Adaptation Layer Layer Layer Adaptation Layer TF PyTorch MXNet OpenVINO or ONNX Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Copyright ©, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
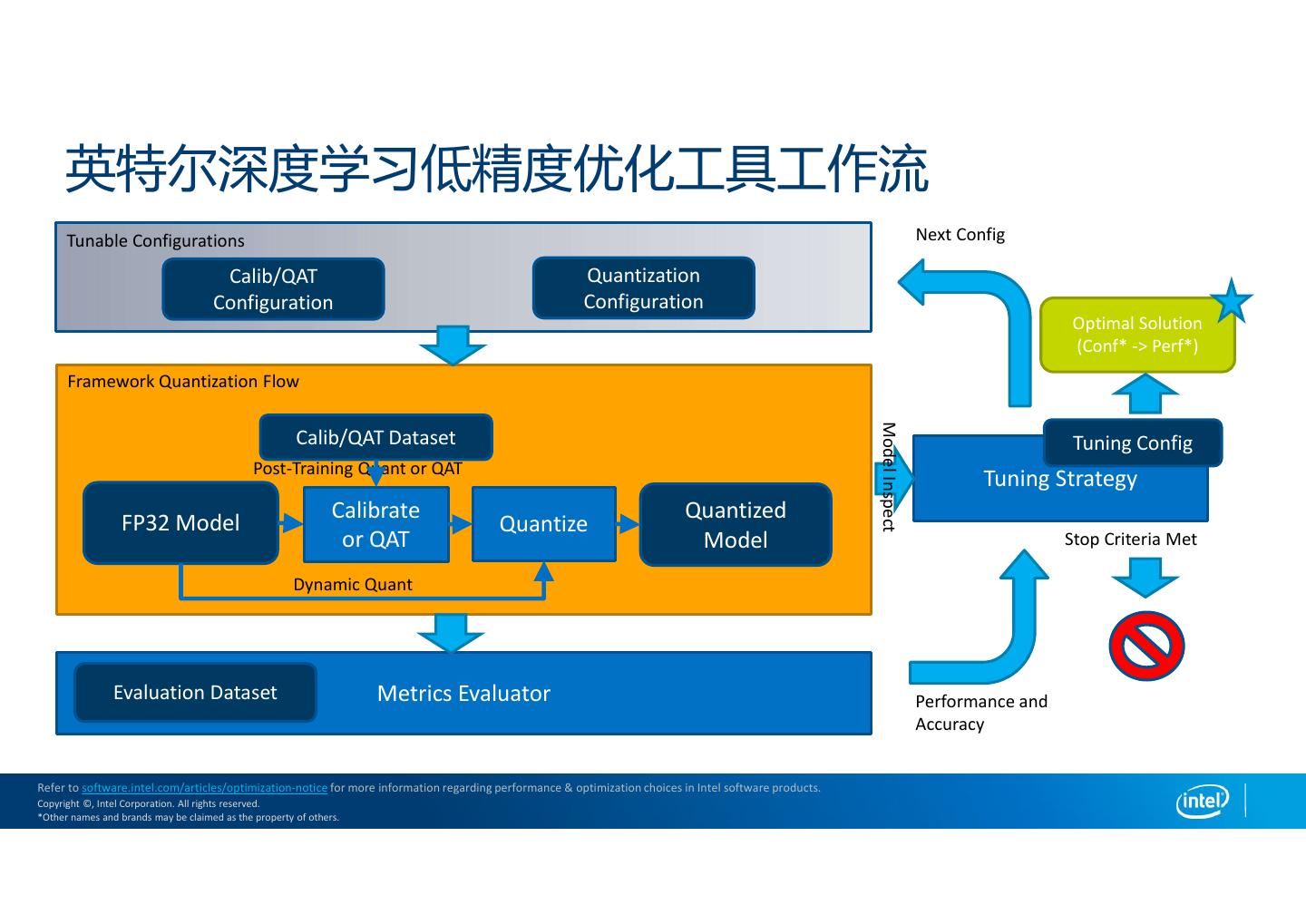
28 . 英特尔深度学习低精度优化工具工作流 Tunable Configurations Next Config Calib/QAT Quantization Configuration Configuration Optimal Solution (Conf* -> Perf*) Framework Quantization Flow Model Inspect Calib/QAT Dataset Tuning Config Post-Training Quant or QAT Tuning Strategy Calibrate Quantized FP32 Model Quantize or QAT Model Stop Criteria Met Dynamic Quant Evaluation Dataset Metrics Evaluator Performance and Accuracy Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Copyright ©, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
29 . 英特尔深度学习低精度优化工具API使用案例 #config.yaml def eval_inference(self, infer_graph): framework: … - name: tensorflow image_np = data_sess.run(images) inputs: input_tensor infer_sess.run([output_tensor], feed_dict={input_tensor: image_np}) outputs: softmax_tensor … np_accuracy1, np_accuracy5 = accu_sess.run([accuracy1, accuracy5]) calibration: - iterations: 5, 10 # optional, default is 1 +return np_accuracy1 algorithm: activation: minmax # optional, if specified, override f/w capability +import ilit to reduce tune space +tuner = ilit.Tuner(self.args.config) +dataset = Dataset(self.args.data_location, 'validation', self.args.image_size, self.args.image_size, tuning: accuracy_criterion: + 1, self.args.num_cores, self.args.resize_method, - relative: 0.01 # tuning target of relative accuracy loss : 1% + [self.args.r_mean,self.args.g_mean,self.args.b_mean], self.args.label_adjust) timeout: 0 # tuning timeout (seconds) +dataloader = tuner.dataloader(dataset, batch_size=self.args.batch_size) random_seed: 9527 +q_model = tuner.tune(self.args.input_graph, q_dataloader=dataloader,eval_func=self.eval_inference) Refer to software.intel.com/articles/optimization-notice for more information regarding performance & optimization choices in Intel software products. Copyright ©, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others.
3秒后跳转登录页面
去登陆

