


























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
CarbonData2.0介绍
CarbonData 2.0新特性
• 数据接入: – Flink流入库
– DB实时数据同步
– Hive入库, Presto入库(2.1) – Spark insert入库性能提升1倍,时间减半
– 支持一张表内混合格式: CSV, TXT, JSON, Parquet, ORC, CarbonFile
• 数据查询:
– 支持Spark Extension
– 统一索引语法,新增index server,新增SI索引,新增Geo索引
– 统一MV语法,新增支持时序数据,支持Parquet/ORC表格
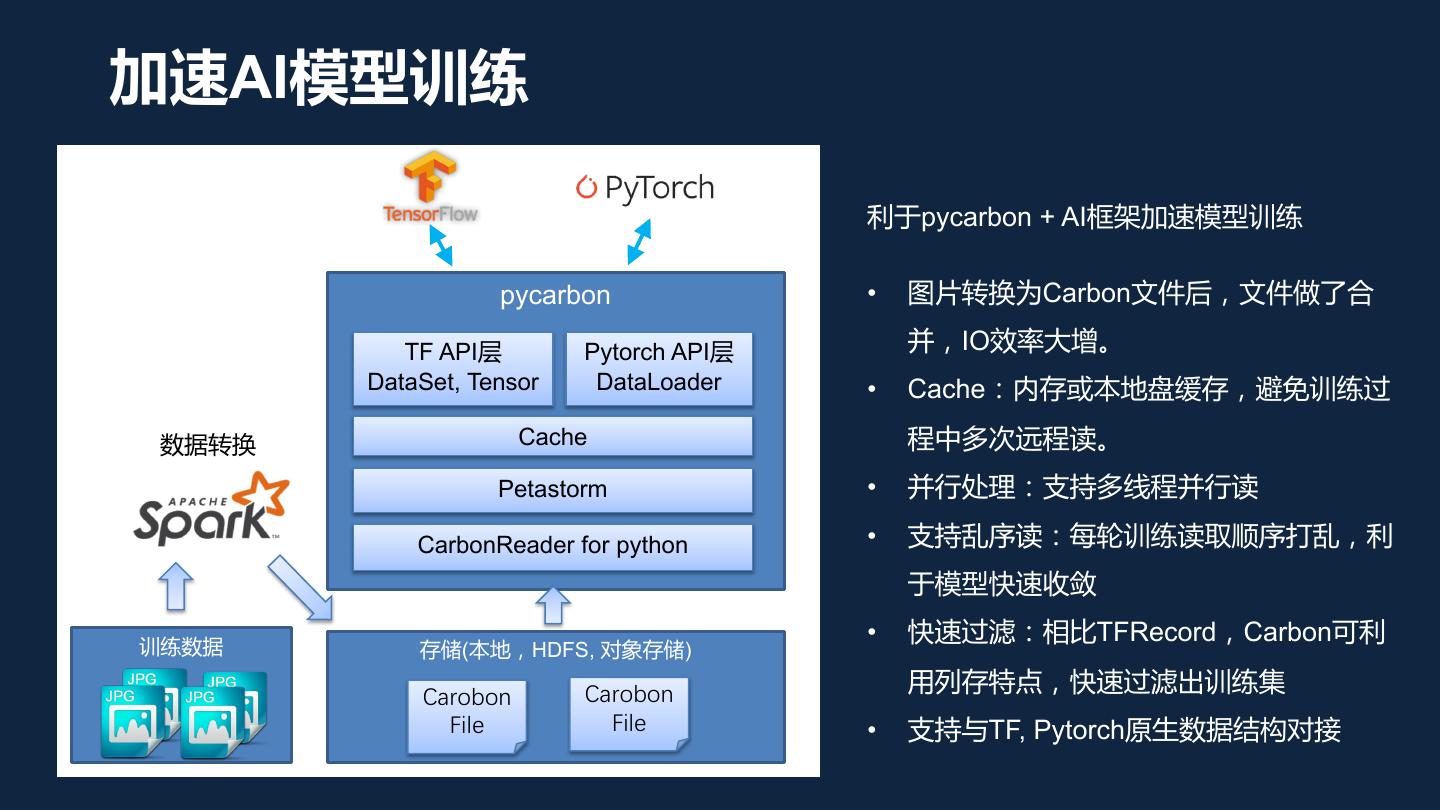
– 支持非结构化数据,对接TensorFlow, pytorch深度神经网络模型训练
展开查看详情
1 .Apache CarbonData 2.0介绍 2020-6
2 .目录 • CarbonData背景介绍 • 2.0新特性介绍 – 数据接入 – 数据分析 • 升级建议
3 .Apache CarbonData • 2014年~2016年:内部研发 • 2016~2017年:进入Apache孵化器,成为当年优秀孵化器项目 • 2017年6月:成为Apache顶级项目; • 2018至今:PB级大型企业/ISV上线 > 50;最大单表规模 > 15万亿记录 • 贡献者来自:
4 .典型的数据分析场景 运维 数据洞察 BI报表 明细查询 交互式分析 批处理计算 查询性能和数据接入问题 ① 日志分析:问题定位 特点:按用户ID、设备ID点查询,实时数据 数据 ② 交互式分析:产生洞察和预测 特点:多维度,模式不固定,计算灵活,海量数据 ③ 报表计算:BI报表 特点:周期性汇总统计,业务数据变更,DB数据同步 生产库 App日志 交易、事务
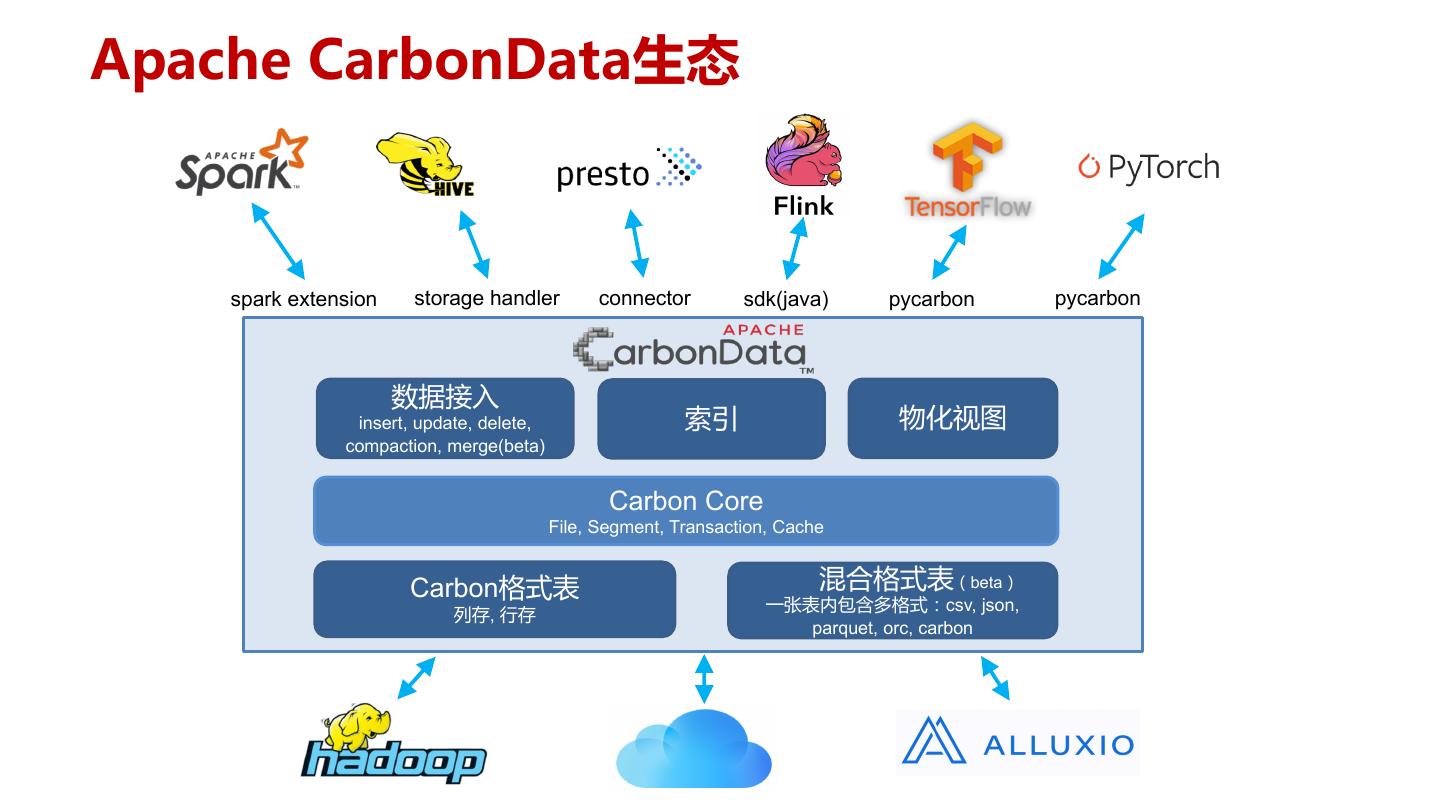
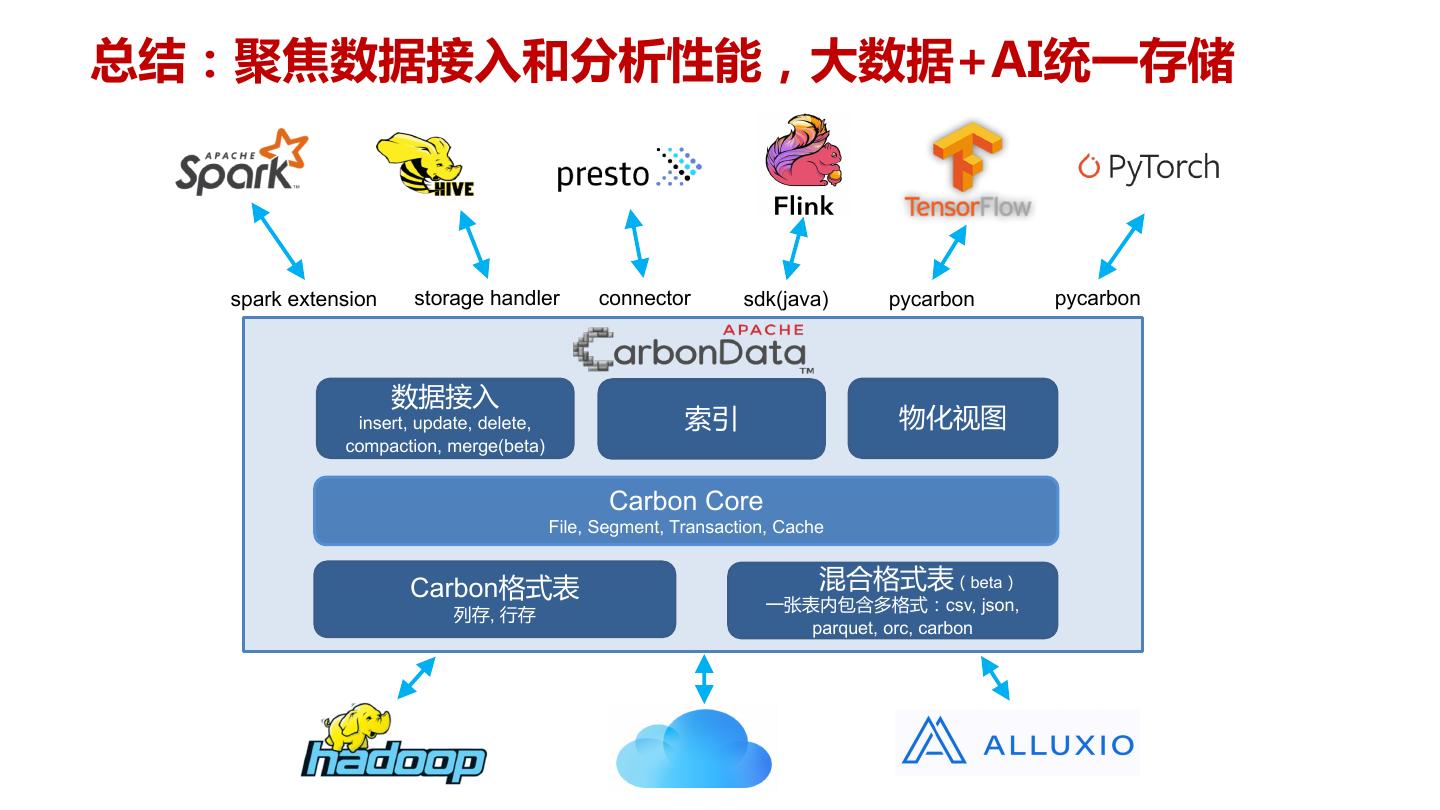
5 .Apache CarbonData生态 spark extension storage handler connector sdk(java) pycarbon pycarbon 数据接入 insert, update, delete, 索引 物化视图 compaction, merge(beta) Carbon Core File, Segment, Transaction, Cache Carbon格式表 混合格式表(beta) 一张表内包含多格式:csv, json, 列存, 行存 parquet, orc, carbon
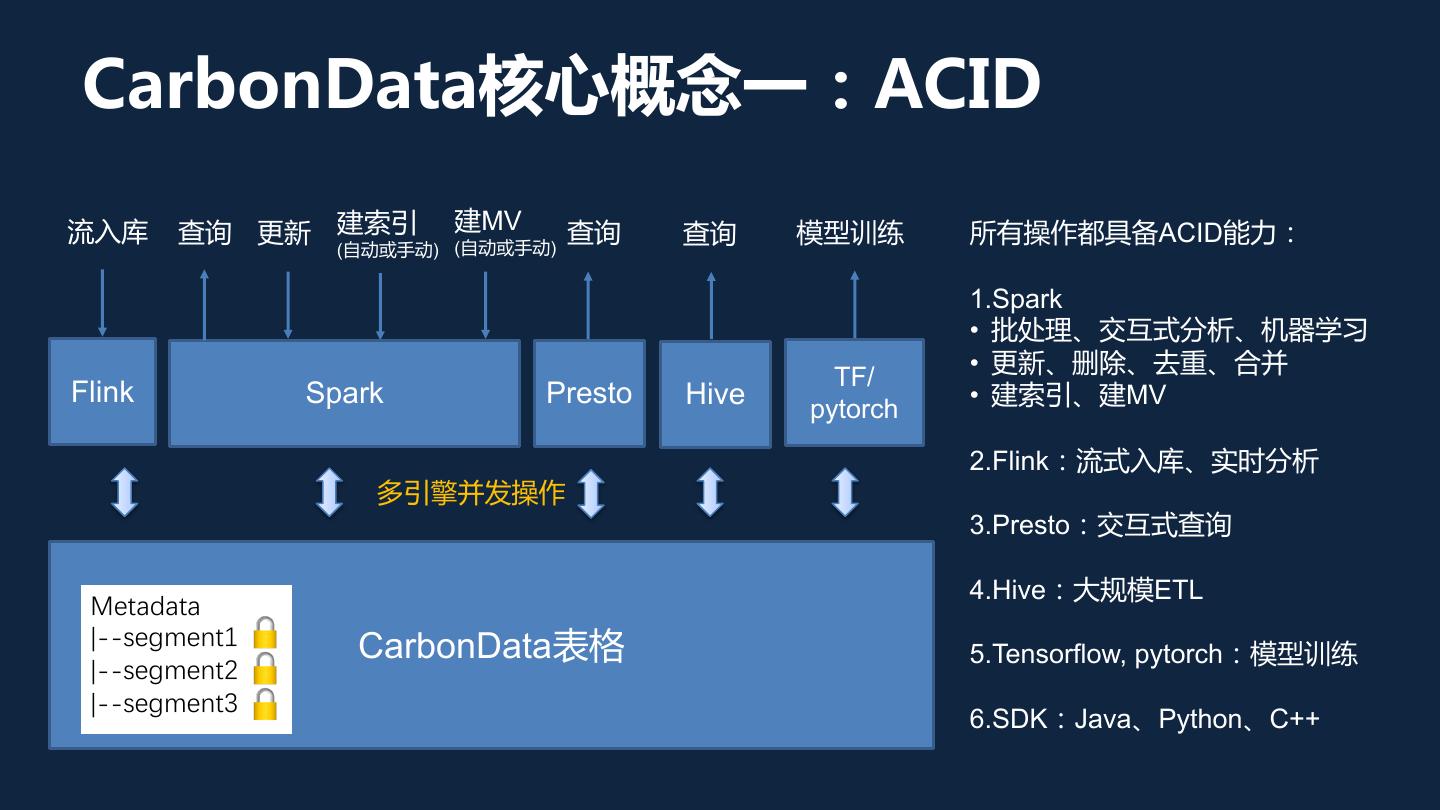
6 .CarbonData核心概念一:ACID 流入库 查询 更新 建索引 建MV 查询 模型训练 所有操作都具备ACID能力: (自动或手动) (自动或手动) 查询 1.Spark • 批处理、交互式分析、机器学习 • 更新、删除、去重、合并 TF/ Flink Spark Presto Hive • 建索引、建MV pytorch 2.Flink:流式入库、实时分析 多引擎并发操作 3.Presto:交互式查询 4.Hive:大规模ETL Metadata |--segment1 CarbonData表格 5.Tensorflow, pytorch:模型训练 |--segment2 |--segment3 6.SDK:Java、Python、C++
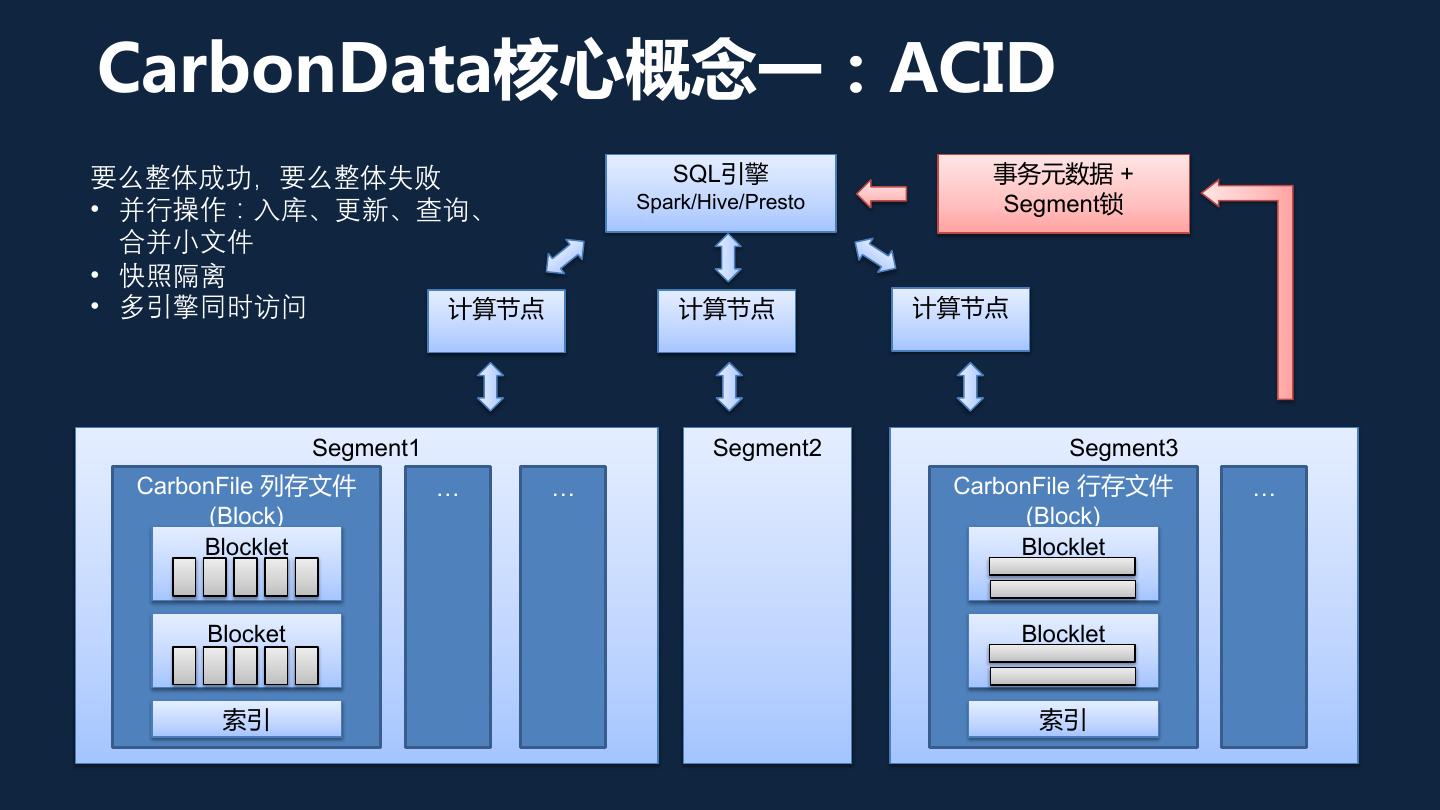
7 .CarbonData核心概念一:ACID 要么整体成功,要么整体失败 SQL引擎 事务元数据 + • 并行操作:入库、更新、查询、 Spark/Hive/Presto Segment锁 合并小文件 • 快照隔离 • 多引擎同时访问 计算节点 计算节点 计算节点 Segment1 Segment2 Segment3 CarbonFile 列存文件 … … CarbonFile 行存文件 … (Block) (Block) Blocklet Blocklet Blocket Blocklet 索引 索引
8 .CarbonData核心概念二:查询加速 索引,物化视图 索引 SQL引擎 • 通过索引跳过不需 Spark/Hive/Presto 文件过滤 SQL改写 要扫描的文件 物化视图 计算节点 计算节点 计算节点 • 通过SQL改写重用 预计算结果 Segment1 Segment2 Segment3 Carbon列存文件 … … Carbon行存文件 … (Block) (Block) Blocklet Blocklet Blocket Blocklet 索引 索引
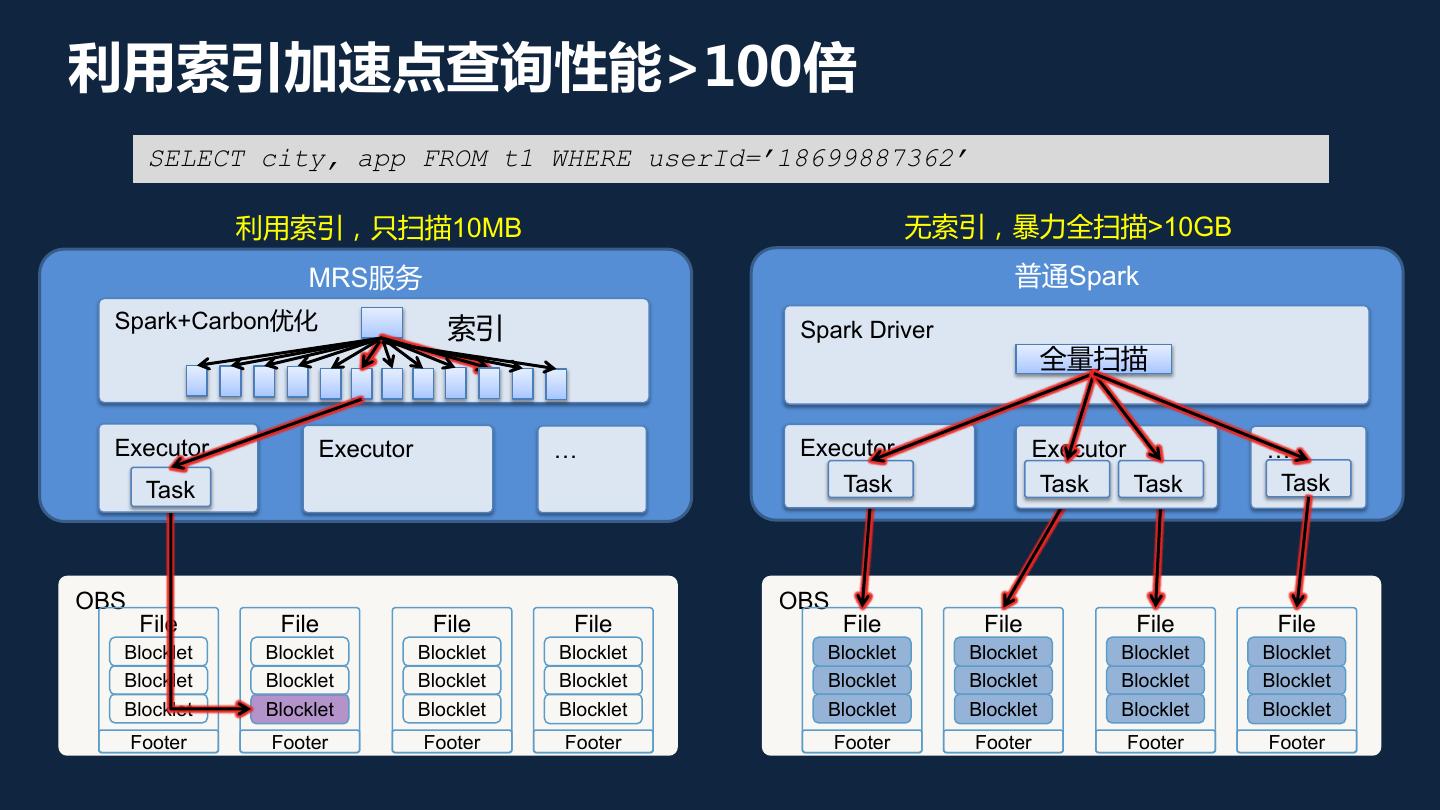
9 .利用索引加速点查询性能>100倍 SELECT city, app FROM t1 WHERE userId=’18699887362’ 利用索引,只扫描10MB 无索引,暴力全扫描>10GB MRS服务 普通Spark Spark+Carbon优化 索引 Spark Driver 全量扫描 Executor Executor … Executor Executor … Task Task Task Task Task OBS OBS File File File File File File File File Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Blocklet Footer Footer Footer Footer Footer Footer Footer Footer
10 .目录 • CarbonData背景介绍 • 2.0新特性介绍 – 数据接入 – 数据分析 • 升级建议
11 . CarbonData 2.0新特性 • 数据接入: – Flink流入库 – DB实时数据同步 – Hive入库, Presto入库(2.1) – Spark insert入库性能提升1倍,时间减半 – 支持一张表内混合格式: CSV, TXT, JSON, Parquet, ORC, CarbonFile • 数据查询: – 支持Spark Extension – 统一索引语法,新增index server,新增SI索引,新增Geo索引 – 统一MV语法,新增支持时序数据,支持Parquet/ORC表格 – 支持非结构化数据,对接TensorFlow, pytorch深度神经网络模型训练
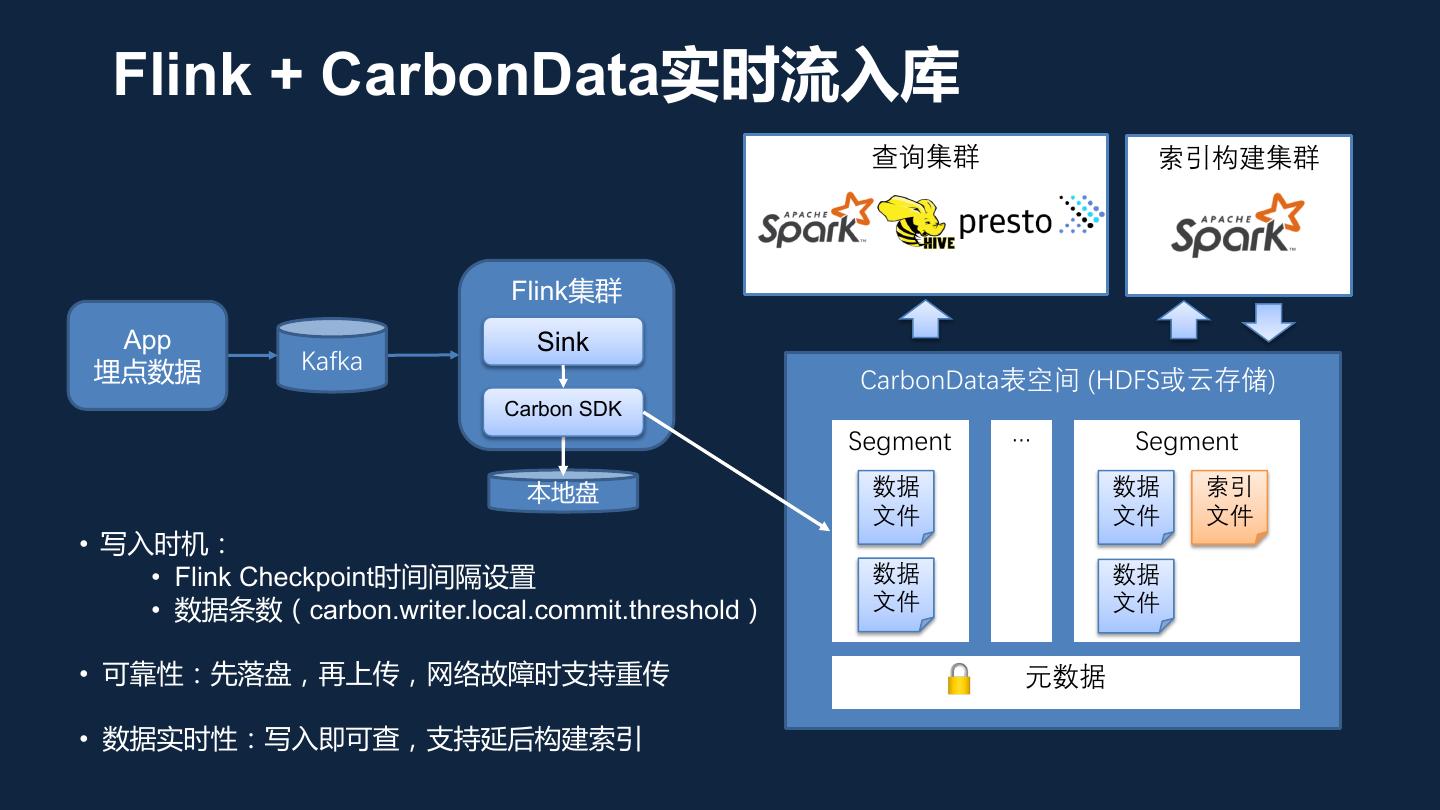
12 . Flink + CarbonData实时流入库 查询集群 索引构建集群 Flink集群 App Sink 埋点数据 Kafka CarbonData表空间 (HDFS或云存储) Carbon SDK Segment … Segment 本地盘 数据 数据 索引 文件 文件 文件 • 写入时机: • Flink Checkpoint时间间隔设置 数据 数据 • 数据条数(carbon.writer.local.commit.threshold) 文件 文件 • 可靠性:先落盘,再上传,网络故障时支持重传 元数据 • 数据实时性:写入即可查,支持延后构建索引
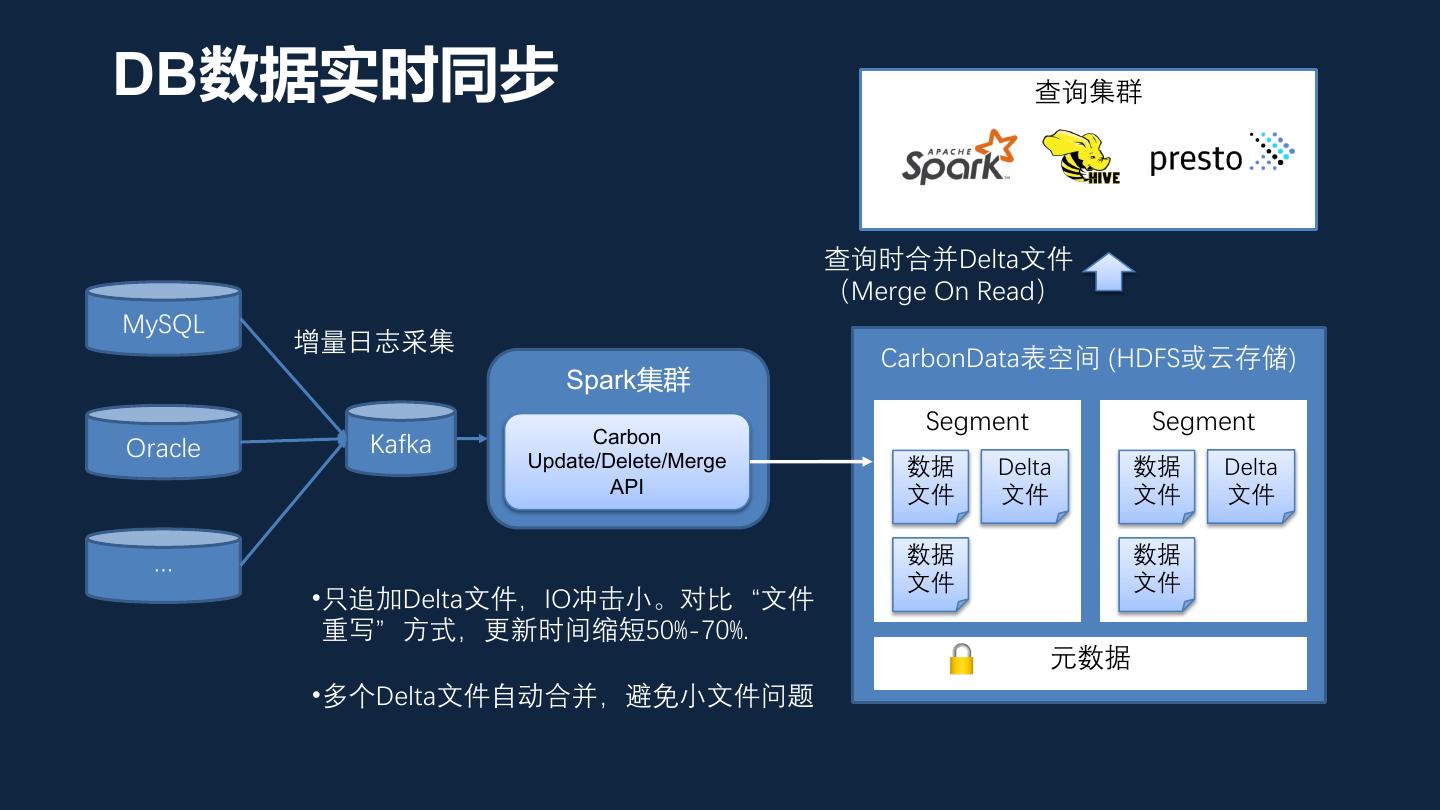
13 .DB数据实时同步 查询集群 查询时合并Delta文件 (Merge On Read) MySQL 增量日志采集 CarbonData表空间 (HDFS或云存储) Spark集群 Segment Segment Kafka Carbon Oracle Update/Delete/Merge 数据 Delta 数据 Delta API 文件 文件 文件 文件 数据 数据 … 文件 文件 •只追加Delta文件,IO冲击小。对比“文件 重写”方式,更新时间缩短50%-70%. 元数据 •多个Delta文件自动合并,避免小文件问题
14 .Merge API举例 change表 更新后的target表 target表 id change_type value id value id value 101 D 100 U ‘amy’ merge 100 101 ‘bob’ ‘jack’ = 100 102 ‘amy’ ‘tony’ 102 I ‘tony’ // 将change表的数据合并到target表 targetDataFrame.as("A") .merge(changeDataFrame.as("B"), "A.id = B.id") .whenMatched("B.change_type = 'D'") .delete() .whenMatched("B.change_type = 'U'") .updateExpr(Map("id" -> "B.id", "value" -> "B.value")) .whenNotMatched("B.change_type = 'I'") .insertExpr(Map("id" -> "B.id", "value" -> "B.value")) .execute()
15 .Hive、Presto入库Carbon表 • Hive写入Carbon表格: – 非事务表(与普通Hive一样),不支持ACID。 CREATE TABLE hive_table (…) STORED BY ‘org.apache.carbondata.hive.CarbonStorageHandler’ INSERT INTO hive_table SELECT * FROM source SELECT * FROM hive_table • Presto写入Carbon表格: – 开发中,计划版本2.1 – 支持事务表和非事务表
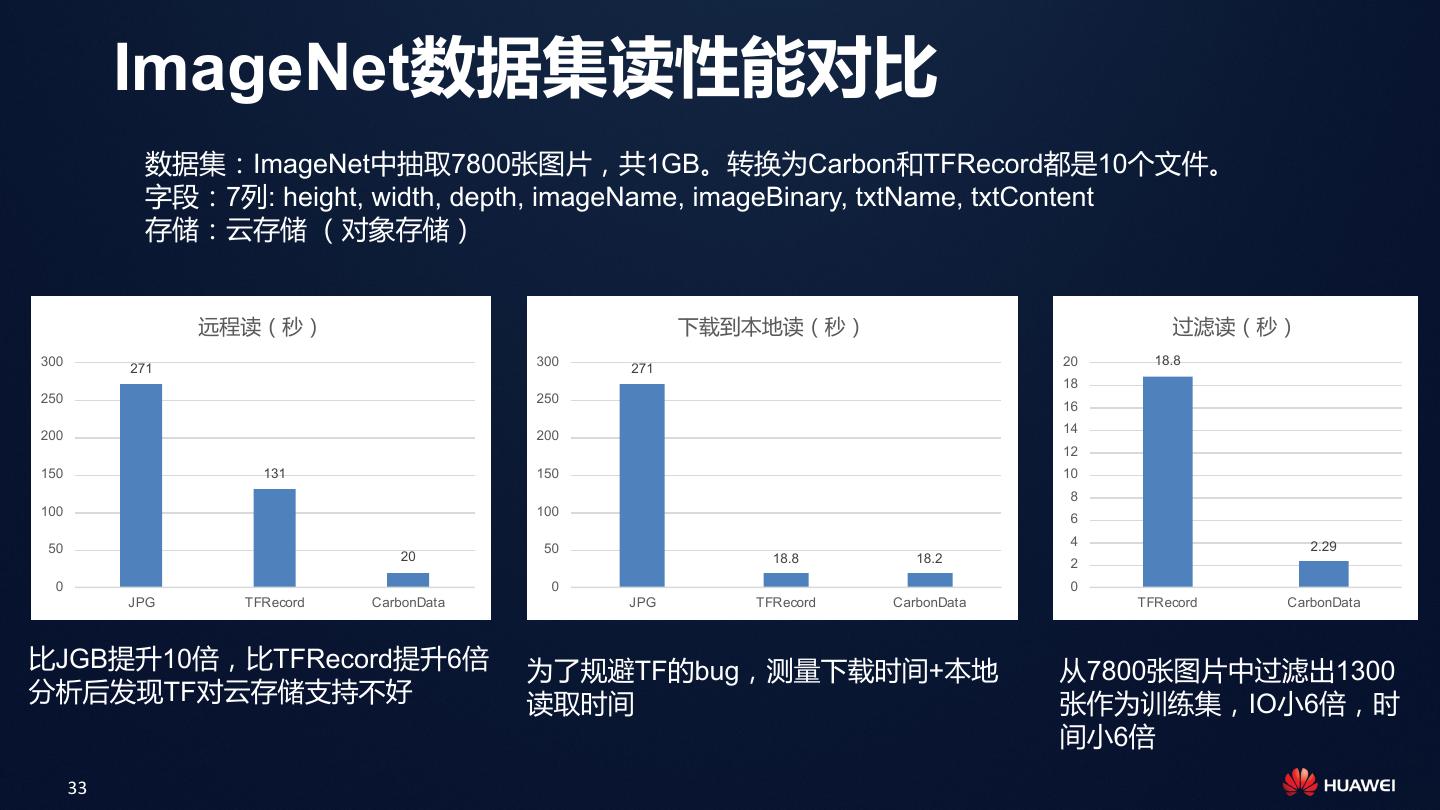
16 .Spark Insert入库Carbon表性能提升1倍 • 性能提升点: – 避免Spark InternalRow到Carbon Row的转换 – 处理Bad Record时,避免多次数据转换 – 构建索引时,避免列顺序调整 • 支持所有类型的Carbon表格 – 有索引,无索引 – 有分区,无分区 – 事务表,非事务表 – MV的入库 – Flink流数据入库 场景(15GB) 1.6.1 版本 2.0.1 版本 从Parquet表插入到 800 秒 420 秒 Carbon表
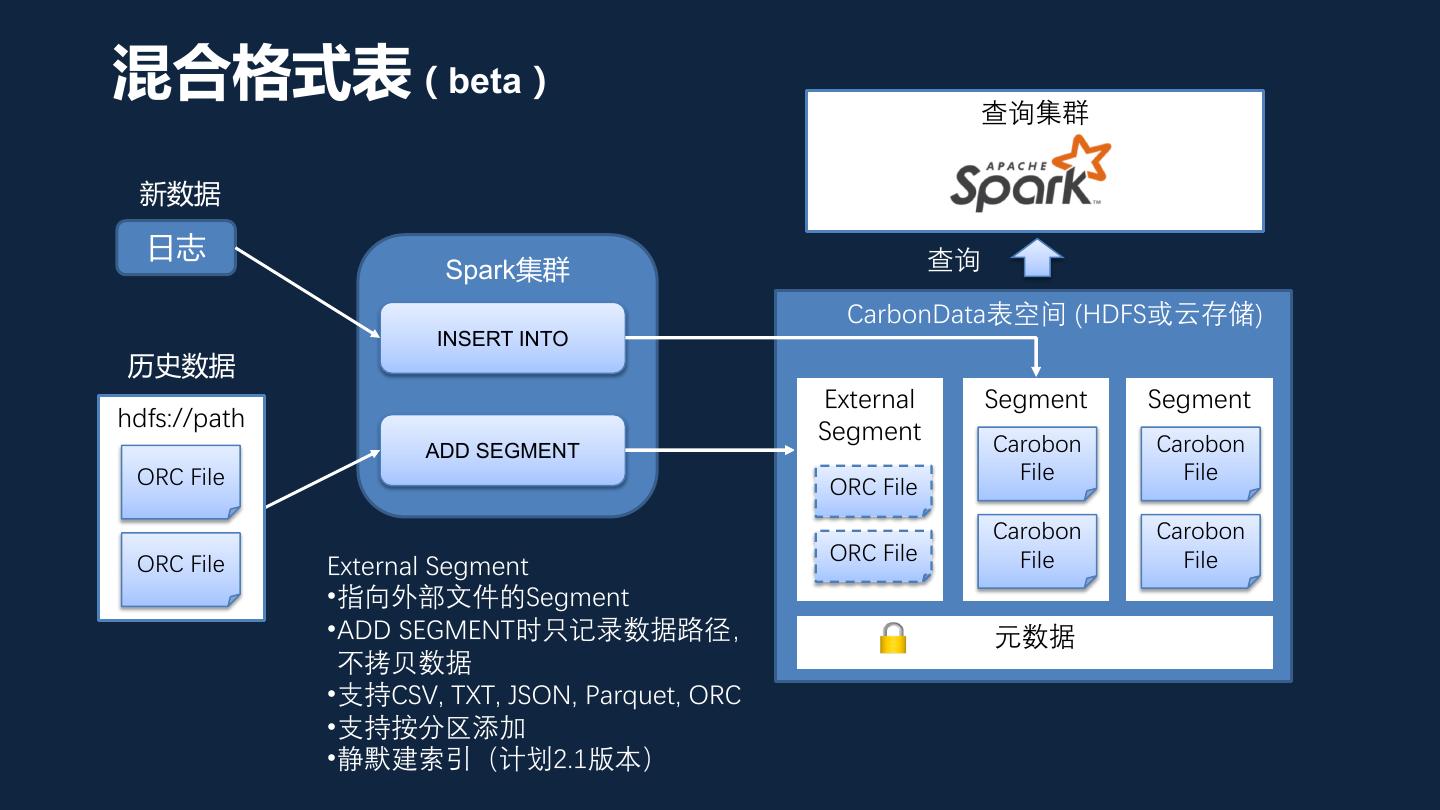
17 .混合格式表(beta) 查询集群 新数据 日志 查询 Spark集群 CarbonData表空间 (HDFS或云存储) INSERT INTO 历史数据 External Segment Segment hdfs://path Segment ADD SEGMENT Carobon Carobon ORC File File File ORC File Carobon Carobon ORC File ORC File File File External Segment •指向外部文件的Segment •ADD SEGMENT时只记录数据路径, 元数据 不拷贝数据 •支持CSV, TXT, JSON, Parquet, ORC •支持按分区添加 •静默建索引(计划2.1版本)
18 . CarbonData 2.0新特性 • 数据接入: – Flink流入库 – DB实时数据同步 – Hive入库, Presto入库(2.1) – Spark insert入库性能提升1倍,时间减半 – 支持一张表内混合格式: CSV, TXT, JSON, Parquet, ORC, CarbonFile • 数据查询: – 支持Spark Extension – 统一索引语法,新增index server,新增SI索引,新增Geo索引 – 统一MV语法,新增支持时序数据,支持Parquet/ORC表格 – 支持非结构化数据,对接TensorFlow, pytorch深度神经网络模型训练
19 . Spark Extension • 支持Spark社区的标准扩展方式 // CarbonData 1.x版本 import org.apache.spark.sql.CarbonSession._ val spark = SparkSession .builder() .master(masterUrl) .enableHiveSupport() .getOrCreateCarbonSession() // CarbonData 2.0版本 支持所有CarbonSession特性 val spark = SparkSession • 注入Parser .builder() • 注入优化规则 .master(masterUrl) • 注入物理计划Planner .enableHiveSupport() .config("spark.sql.extensions", "org.apache.spark.sql.CarbonExtensions") 2.0中仍然支持CarbonSession, .getOrCreate () 但不建议再使用 (未来计划废弃)
20 .Index Service Index Service (索引集群) 查询集群 索引服务 索引 索引 索引 节点 节点 节点 CarbonData表空间 (HDFS或云存储) Segment Segment 分布式索引缓存 数据 索引 数据 索引 • 解决Driver侧索引内存太大 文件 文件 文件 文件 • 解决多集群共享一份索引 • 在YARN上部署 数据 数据 文件 文件 索引预加载: • 解决首次查询慢 元数据 • 数据入库后即自动预加载
21 .二级索引 • 加速对高基数列的查询,主表的主索引是用户ID,但 对手机号码查询性能不好,则用SI对手机号码做索引 • SI上也有索引,加速SI的处理 查询集群 索引集群 Carbon优化规则: + 利用block_id做pruning CarbonData表空间 (HDFS或云存储) 主表 二级索引表 (SI) 索引列 索引列 block_id block_id Segment1 Segment2 Segment1 Segment2 min max min max 数据 索引 数据 索引 数据 索引 数据 索引 13860001 13860005 f3 f4 文件f1 文件 文件f3 文件 文件 文件 文件 文件 索引列 block_id 数据 数据 (手机号码) 文件f2 文件f4 13860001 f4 13860004 f3 元数据 元数据 13860005 f3 … …
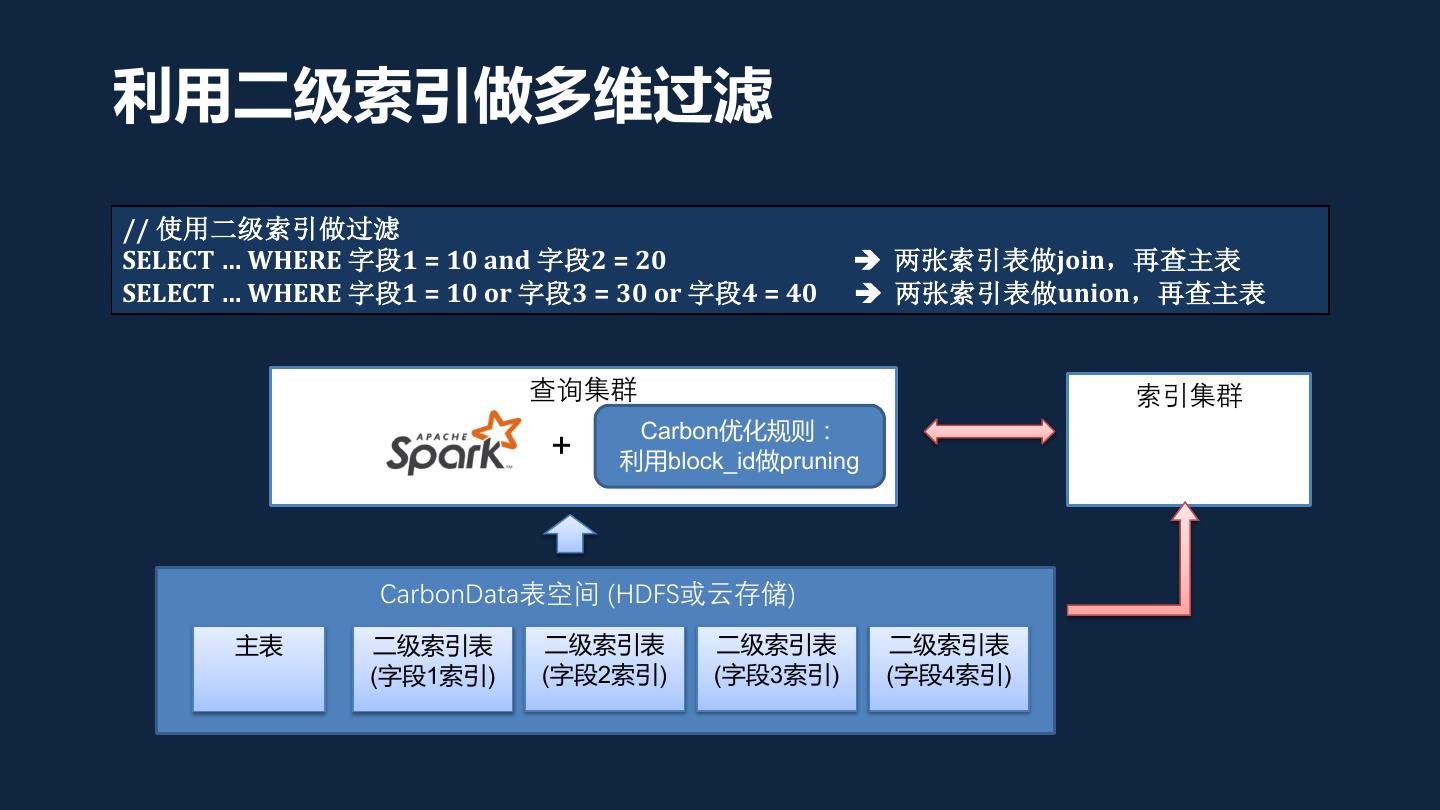
22 .利用二级索引做多维过滤 // 使用二级索引做过滤 SELECT … WHERE 字段1 = 10 and 字段2 = 20 è 两张索引表做join,再查主表 SELECT … WHERE 字段1 = 10 or 字段3 = 30 or 字段4 = 40 è 两张索引表做union,再查主表 查询集群 索引集群 Carbon优化规则: + 利用block_id做pruning CarbonData表空间 (HDFS或云存储) 主表 二级索引表 二级索引表 二级索引表 二级索引表 (字段1索引) (字段2索引) (字段3索引) (字段4索引)
23 .二级索引的限制和使用建议 限制 1. 当前只支持STRING, 不支持复杂类型和数值类型 使用建议 1. 二级索引列的选择: 1. 主索引过滤效果不好的列 2. 基数高的列(可以通过索引定位少量文件),例如ID类 2. 哪些列不要建二级索引 1. 主表的SORT_COLUMN列,分区列 2. 大部分文件都含有所有值的列,例如性别,年龄 3. 多列索引 VS 多个单列索引:判断查询条件是否经常一起出现 字段1 和 字段2 经常同时做过滤 è 建一个二级索引,多列组合索引 (字段1, 字段2) 字段1 和 字段2 经常独立做过滤 è 建两个二级索引 (字段1) , (字段2) 4. 如果发现使用二级索引后,某语句变慢 // 使用NI提示不要使用二级索引 SELECT … WHERE 字段1 = 10 and NI(字段3 = 30 or 字段4 = 40) è 只使用字段1的二级索引
24 .二级索引的待优化点 未来优化点(2.1及之后版本): 1. 支持更多数据类型 2. SI表做Segment级join,避免全局shuffle 3. block_id存储优化 4. 支持row级别的二级索引 5. 支持延迟构建 欢迎贡献:使用方式改进,方案讨论,代码贡献
25 .索引语法统一,与Hive保持一致 // 创建索引 CREATE INDEX [IF NOT EXISTS] index_name ON TABLE table_name (column_name, ...) AS index_provider [WITH DEFERRED REFRESH] [PROPERTIES ('key'='value')] index_provide := bloomfilter | lucene | carbondata // 显示索引 SHOW INDEXES on table_name // 删除索引 DROP INDEX [IF EXISTS] index_name on table_name // 刷新索引(可按segment刷新) REFRESH INDEX index_name ON table_ame [WHERE SEGMENT.ID IN (segment_id, ...)]
26 .MV语法统一,与Hive保持一致 // 创建物化视图 CREATE MATERIALIZED VIEW [IF NOT EXISTS] mv_name [WITH DEFERRED REFRESH] AS select_statement // 例子 CREATE MATERIALIZED VIEW mv1 AS select a.city, max(b.gdp) from a join b on a.id = b.id group by a.city // 显示物化视图 SHOW MATERIALIZED VIEW // 删除物化视图 DROP MATERIALIZED VIEW [IF EXISTS] mv_name // 刷新索引(会自动判断需要刷新的Segment,做增量刷新) REFRESH MATERIALIZED VIEW mv_name
27 .MV支持时间序列 入库集群 查询集群 Carbon MV Carbon MV + 优化规则 + 优化规则 入库主表时自动完成 查询主表时,自动选择合适 各周期表的预汇聚 的周期表进行上卷(Rollup) 表空间 (HDFS或云存储) 主表 MV表 – 分钟表 MV表 – 天表 时戳, 维度, 度量 MV表 – 小时表 MV表 – 月表
28 .时间序列MV举例 Granularity year // 创建物化视图 month CREATE MATERIALIZED VIEW avg_sales_minute AS SELECT timeseries(order_time, 'minute'), avg(price) week FROM sales day GROUP BY timeseries(order_time, 'minute') hour // 如下查询语句会利用物化视图 thirty_minute SELECT timeseries(order_time, ‘hour'), avg(price) fifteen_minute FROM sales GROUP BY timeseries(order_time, ‘hour') ten_minute five_minute minute 限制:时间序列MV不支持带Join语句,使用普通MV代替 second
29 .MV支持非Carbon格式表格 查询集群 除了加速Carbon表格,也可以加速 Parquet, ORC表格。 Carbon MV + 优化规则 限制:由于无Segment概念,只支持全 量刷新MV,无法增量刷新 表空间 (HDFS或云存储) CarbonData表 Spark Spark Hive表 Datasource表 Datasource表 Segment Segment Parquet ORC Parquet 数据 数据 文件 文件 文件 文件 文件 Parquet ORC Parquet 数据 数据 文件 文件 文件 文件 文件 元数据
3秒后跳转登录页面
去登陆

