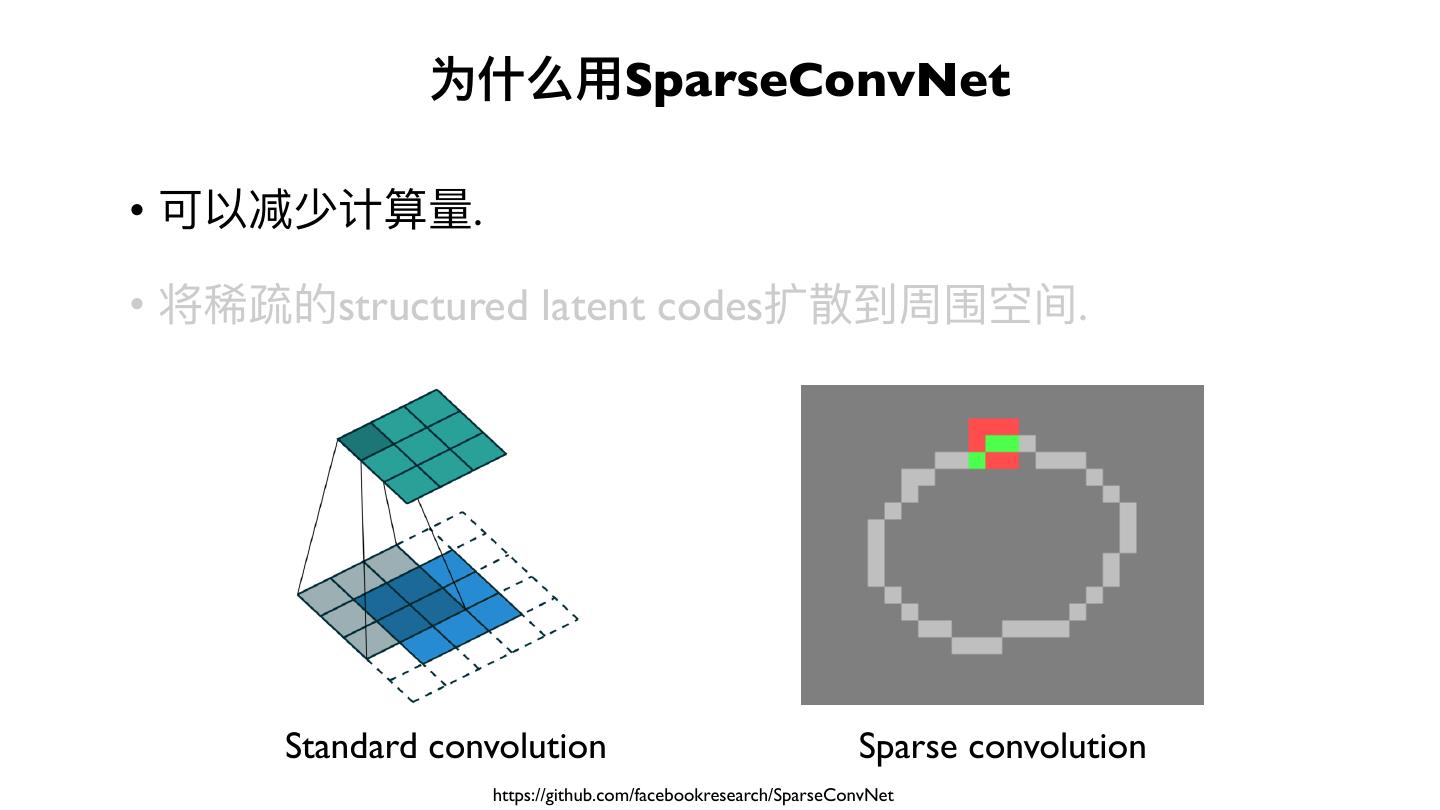
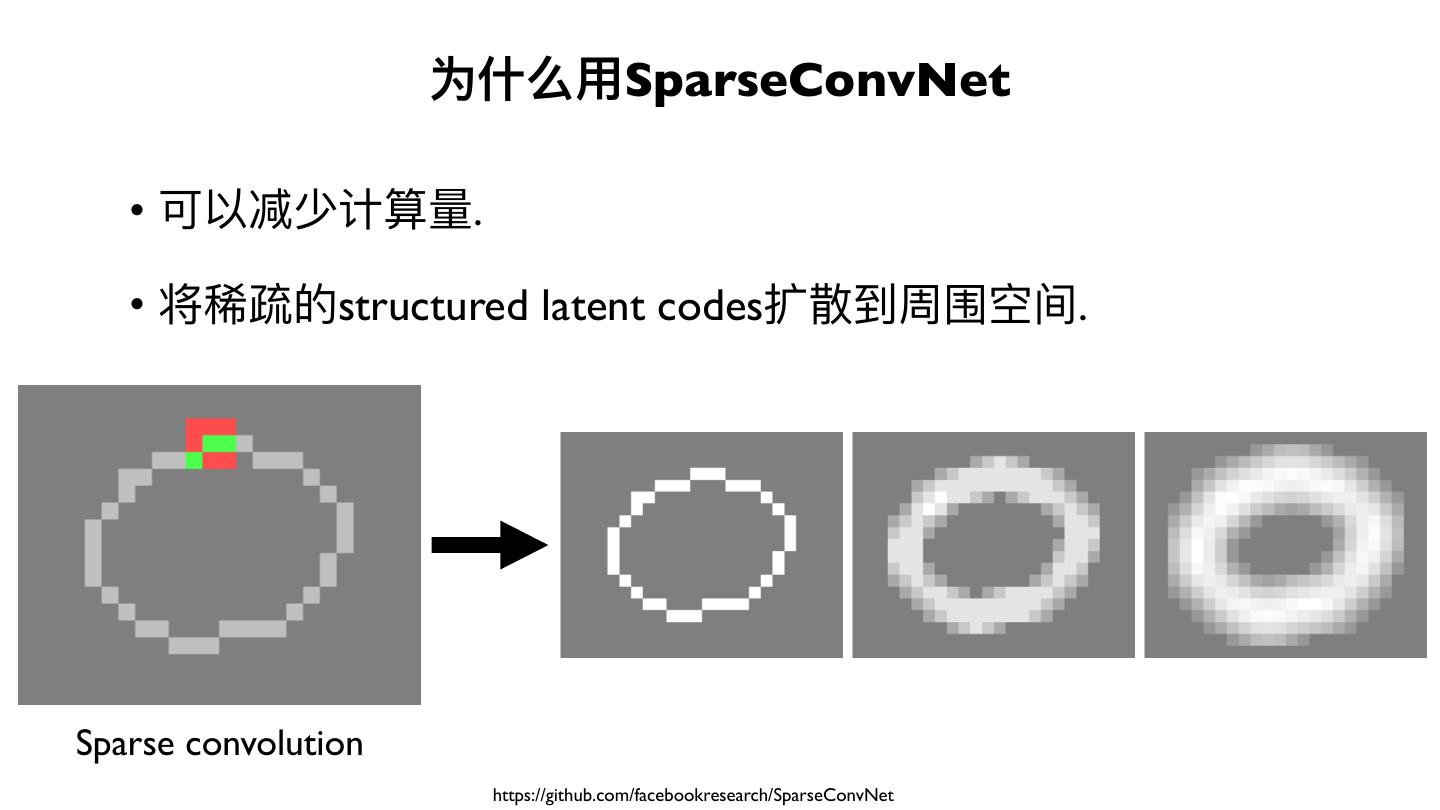
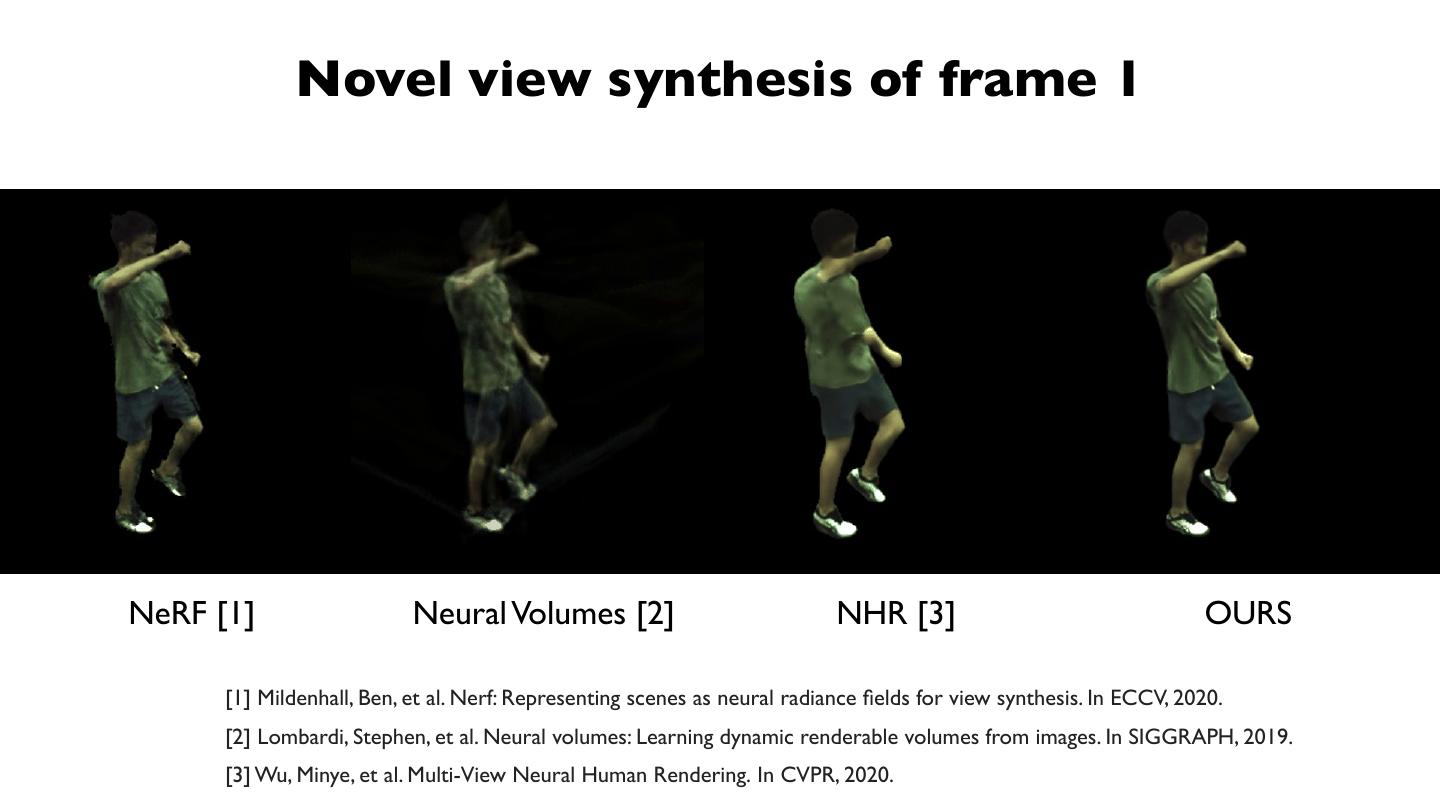
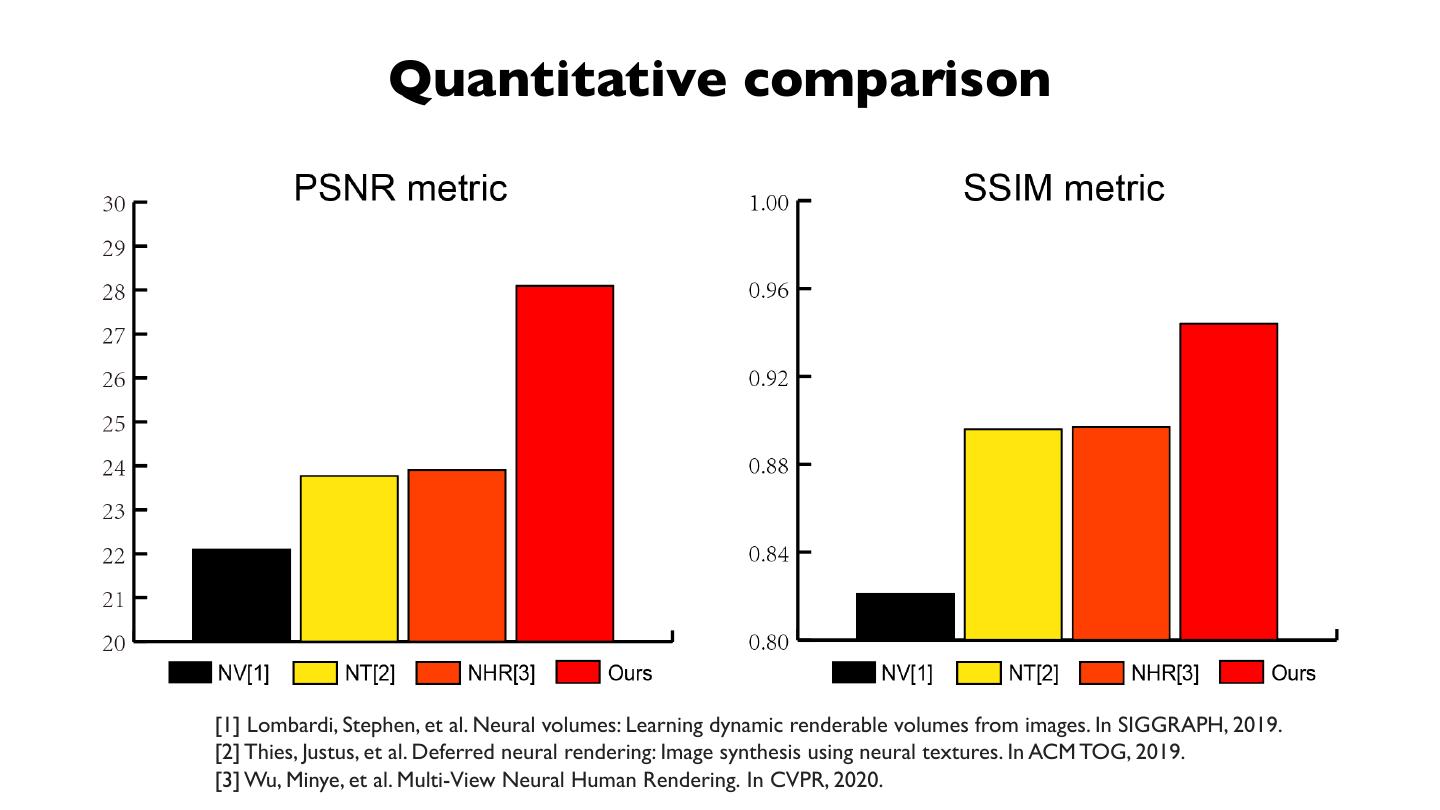
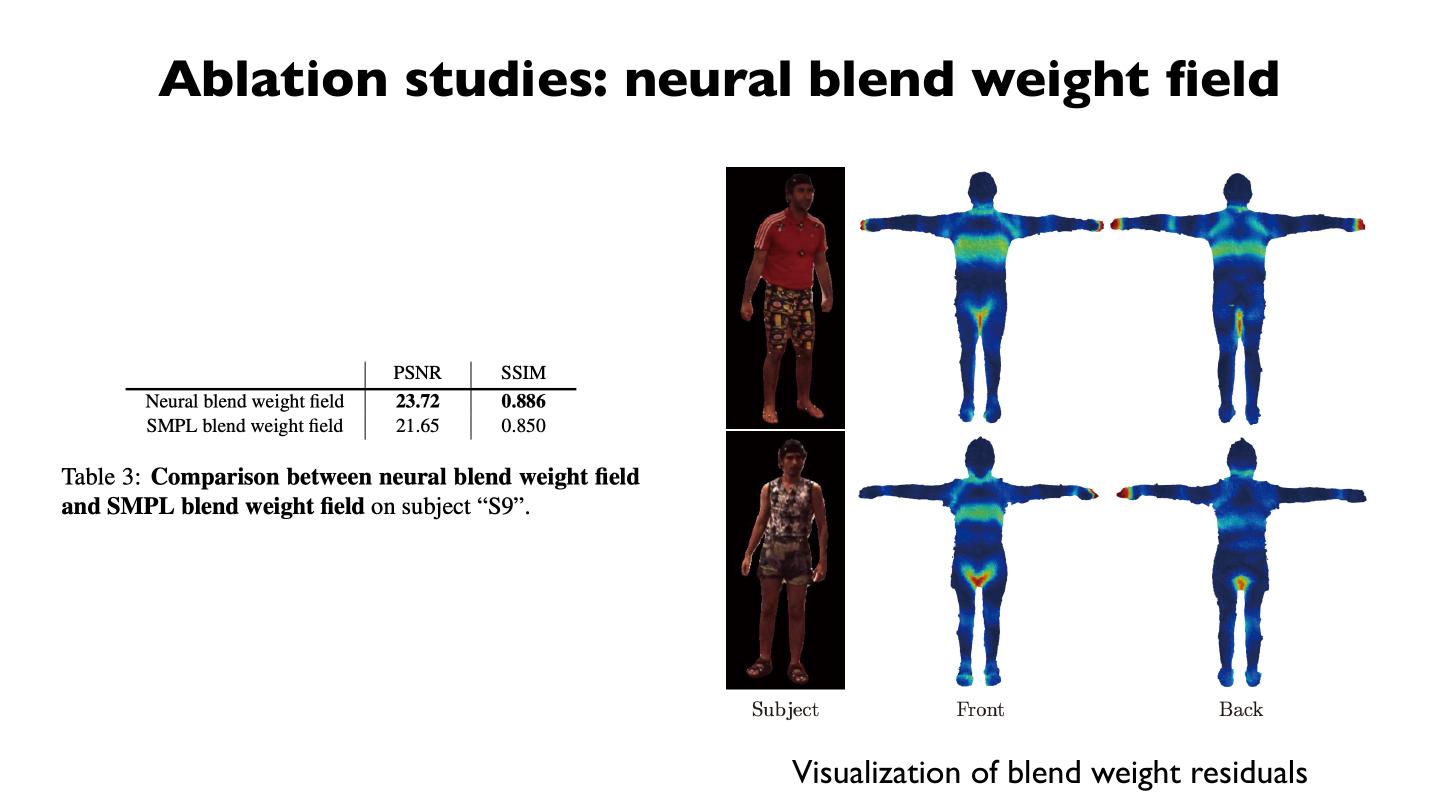
展开查看详情
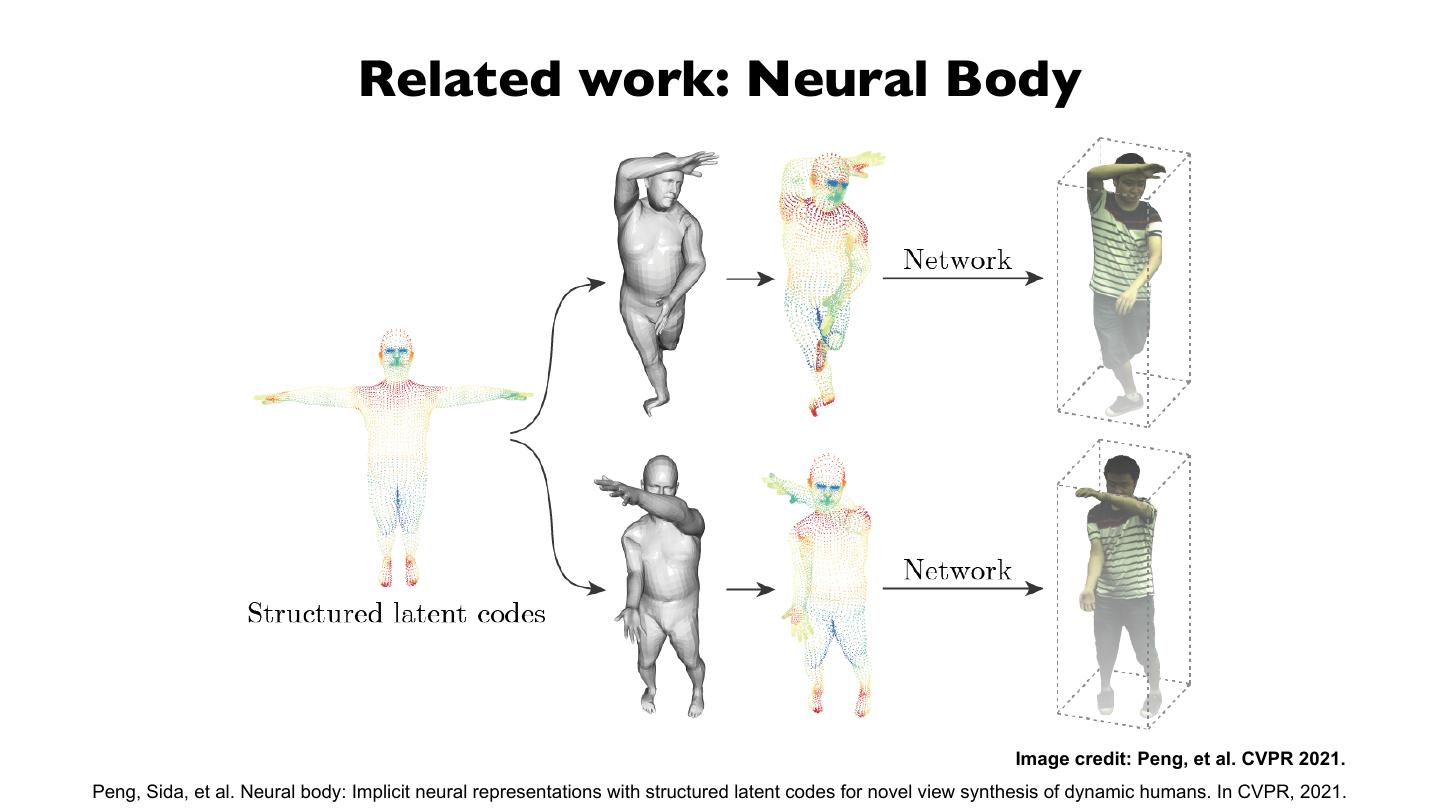
1 .Neural Body: Implicit Neural Representations with Structured Latent Codes
for Novel View Synthesis of Dynamic Humans
Sida Peng, Yuanqing Zhang, Yinghao Xu, Qianqian Wang
Qing Shuai, Hujun Bao, Xiaowei Zhou
Input: a sparse multi-view video Output: 3D geometry and appearance
Frame 1 Frame 150 Frame 300 Novel view synthesis 3D reconstruction
�
2 .Problem statement: 什什么是novel view synthesis
Input views Novel view synthesis
Mildenhall, Ben, et al. Nerf: Representing scenes as neural radiance fields for view synthesis. In ECCV, 2020.
�
3 .Problem statement: 什什么是novel view synthesis
Input views Novel view synthesis
Mildenhall, Ben, et al. Nerf: Representing scenes as neural radiance fields for view synthesis. In ECCV, 2020.
�
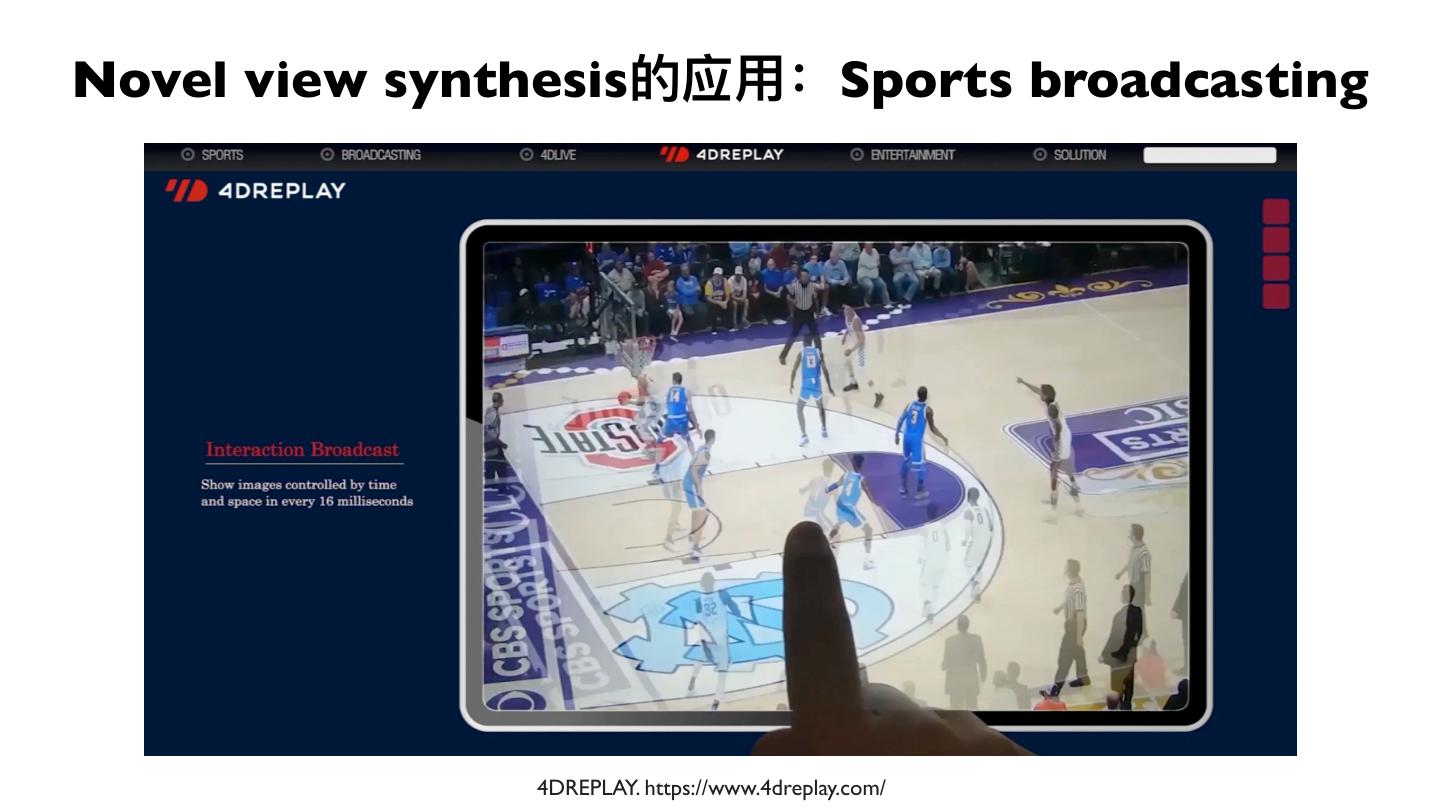
4 .Novel view synthesis的应⽤用:Sports broadcasting
4DREPLAY. https://www.4dreplay.com/
�
5 .Novel view synthesis的应⽤用:Telepresence
https://www.youtube.com/watch?v=Q13CishCKXY
�
6 .Novel view synthesis的应⽤用:Telepresence
https://www.youtube.com/watch?v=Q13CishCKXY
�
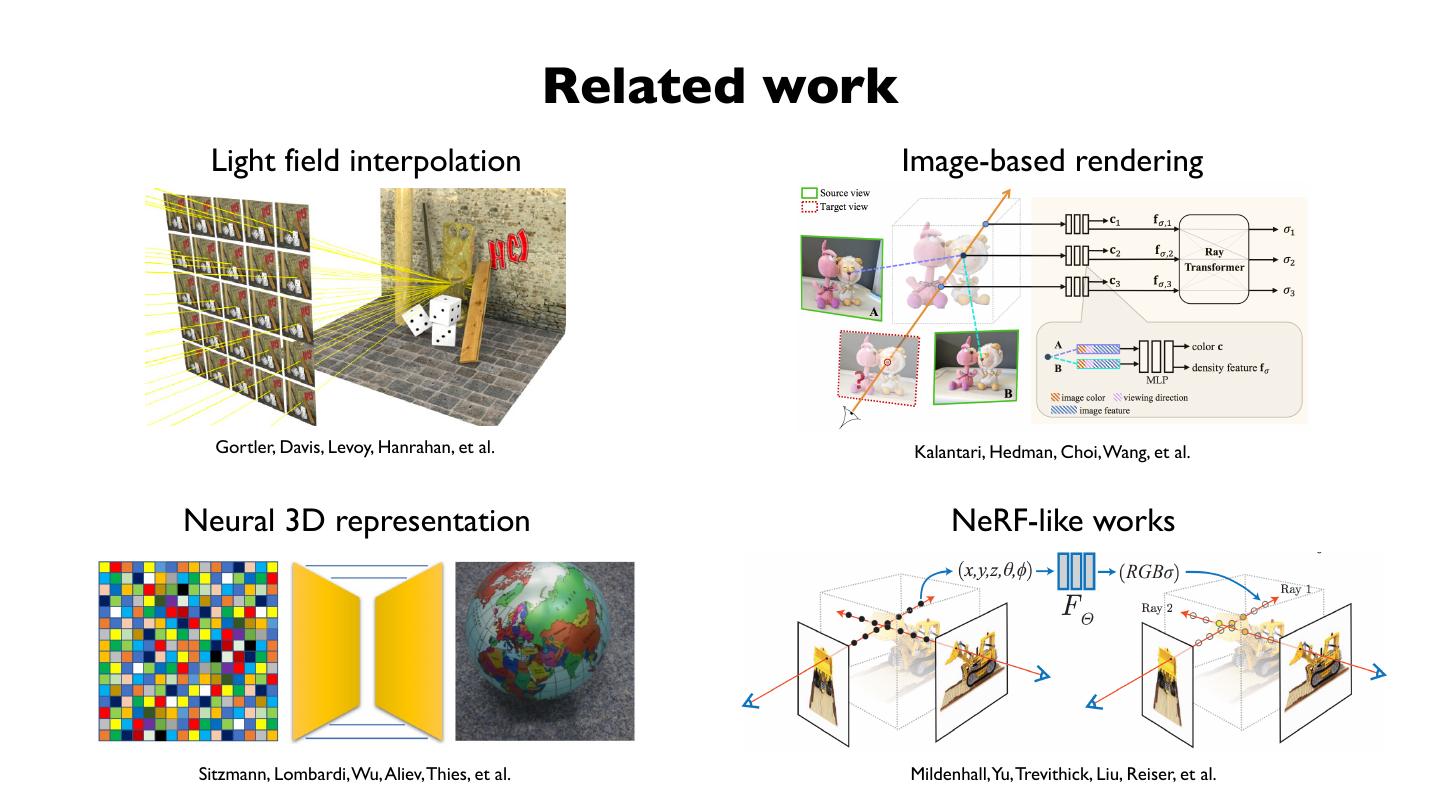
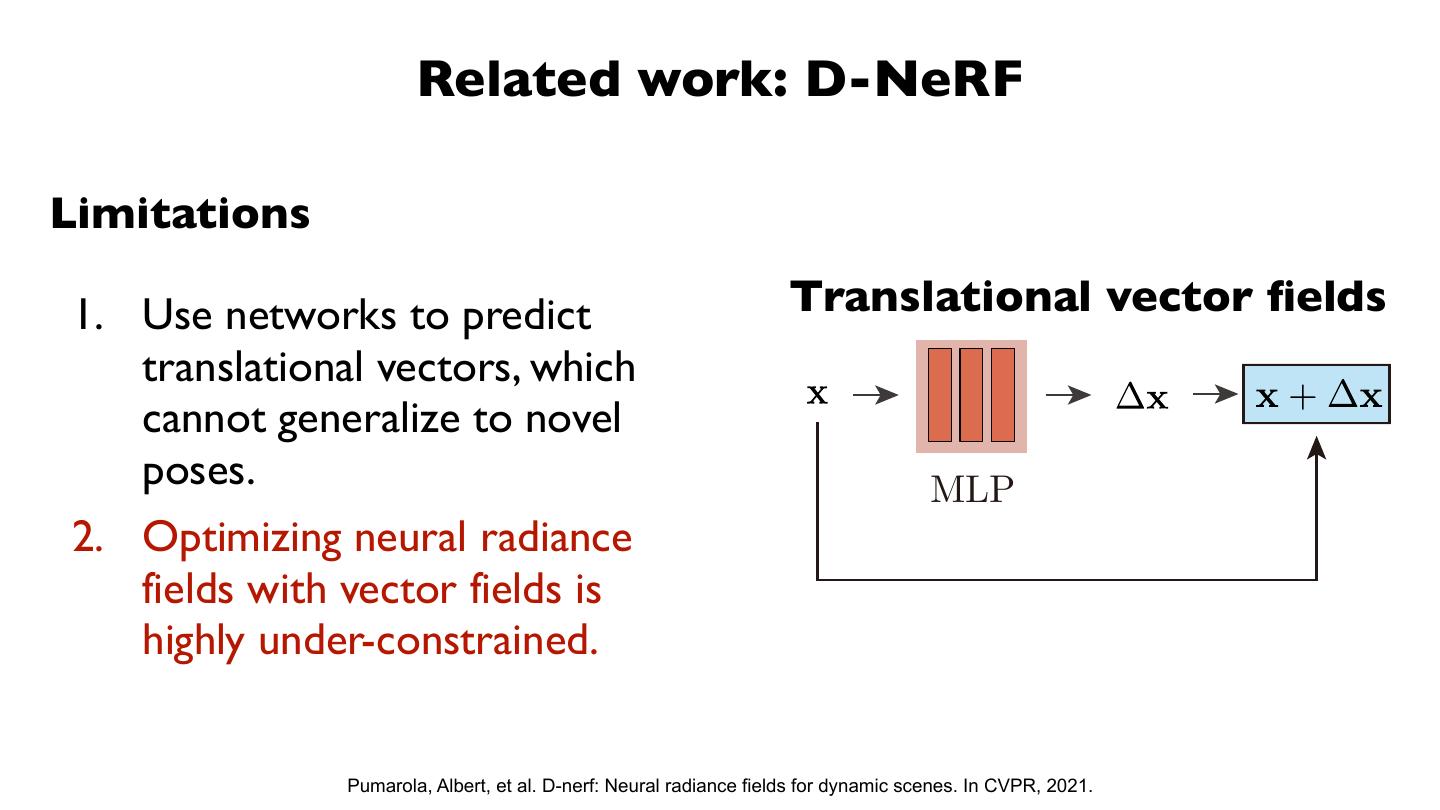
7 . Related work
Light field interpolation Image-based rendering
Gortler, Davis, Levoy, Hanrahan, et al. Kalantari, Hedman, Choi, Wang, et al.
Neural 3D representation NeRF-like works
Sitzmann, Lombardi, Wu, Aliev, Thies, et al. Mildenhall,Yu, Trevithick, Liu, Reiser, et al.
�
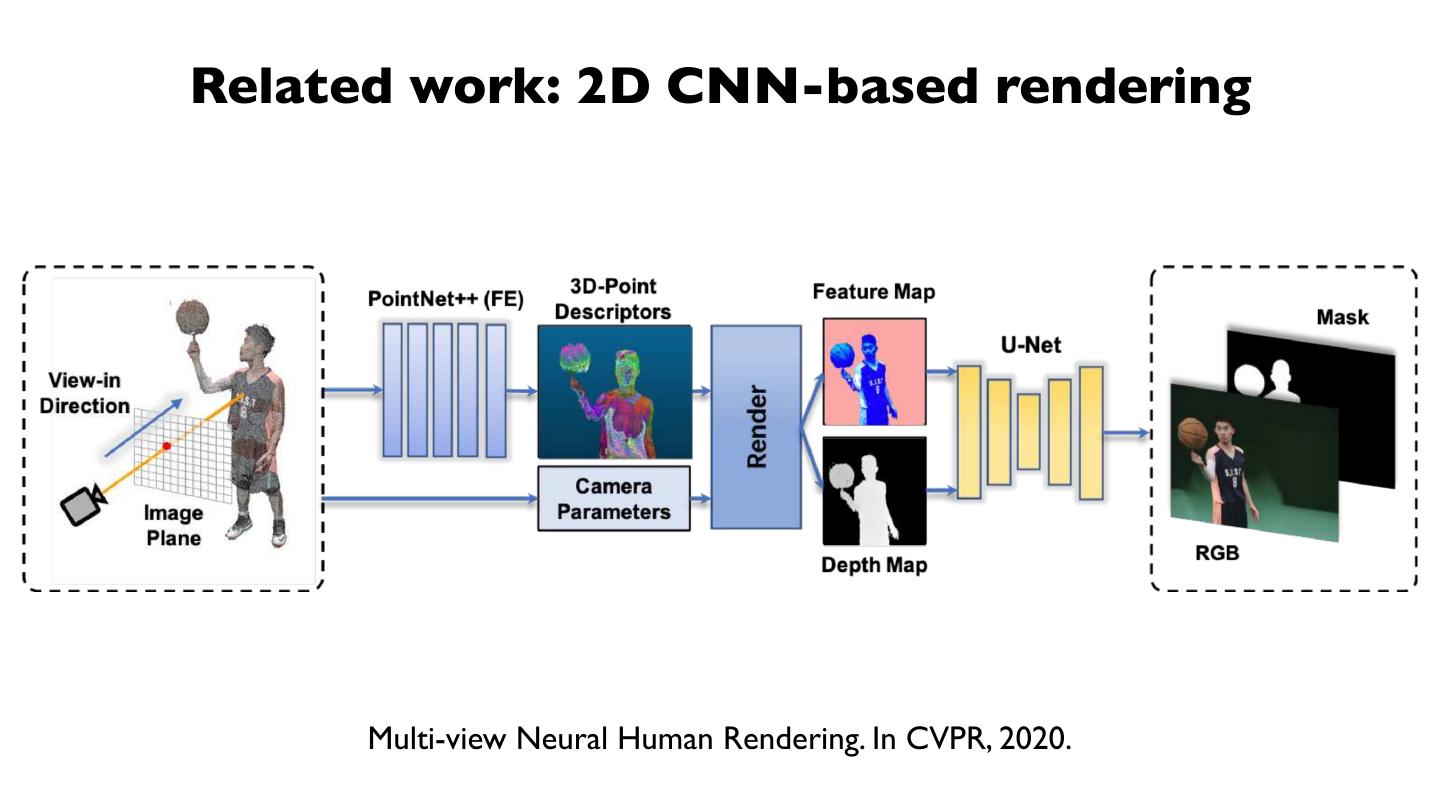
8 .Related work: 2D CNN-based rendering
Multi-view Neural Human Rendering. In CVPR, 2020.
�
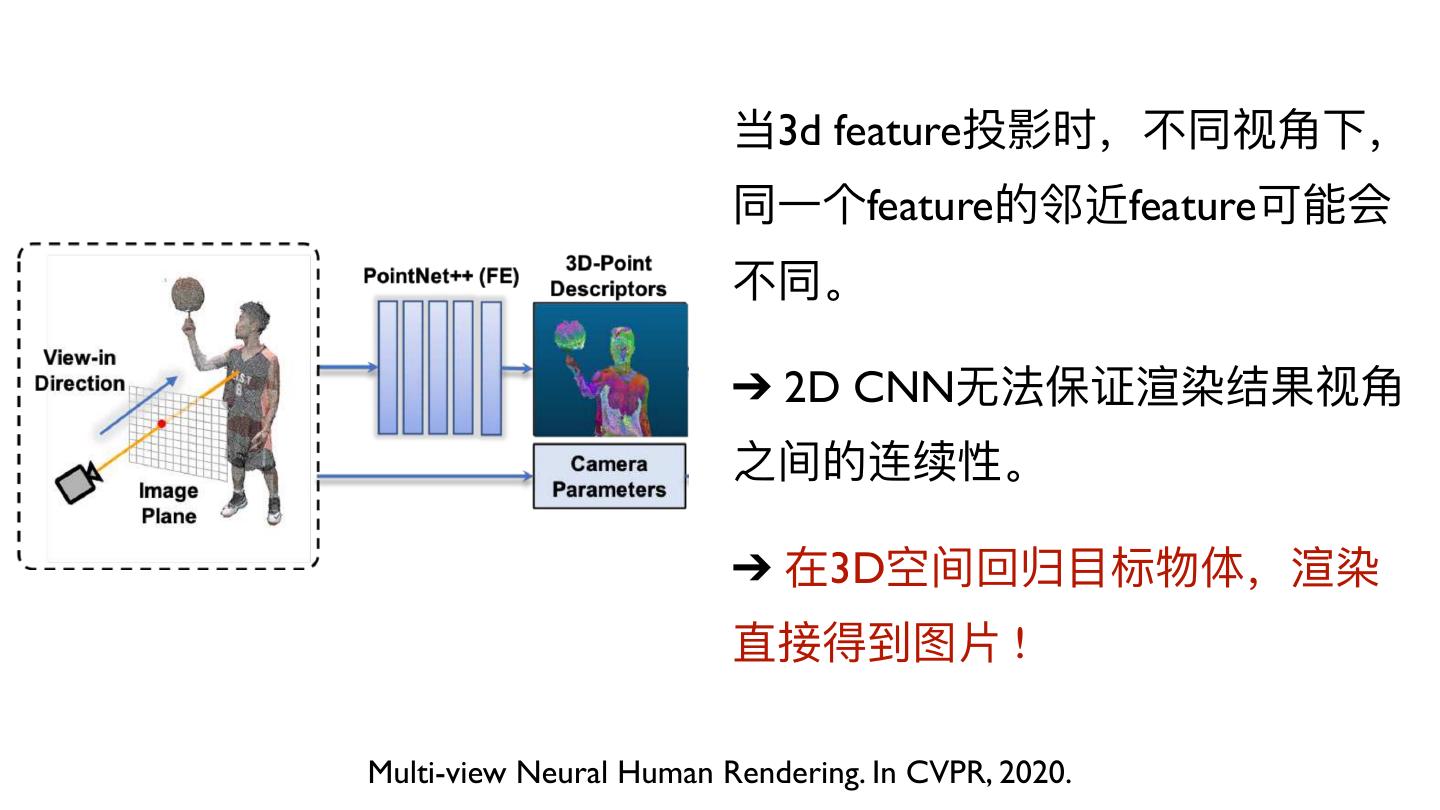
9 . 当3d feature投影时,不不同视⻆角下,
同⼀一个feature的邻近feature可能会
不不同。
➔ 2D CNN⽆无法保证渲染结果视⻆角
之间的连续性。
➔ 在3D空间回归⽬目标物体,渲染
直接得到图⽚片 !
Multi-view Neural Human Rendering. In CVPR, 2020.
�
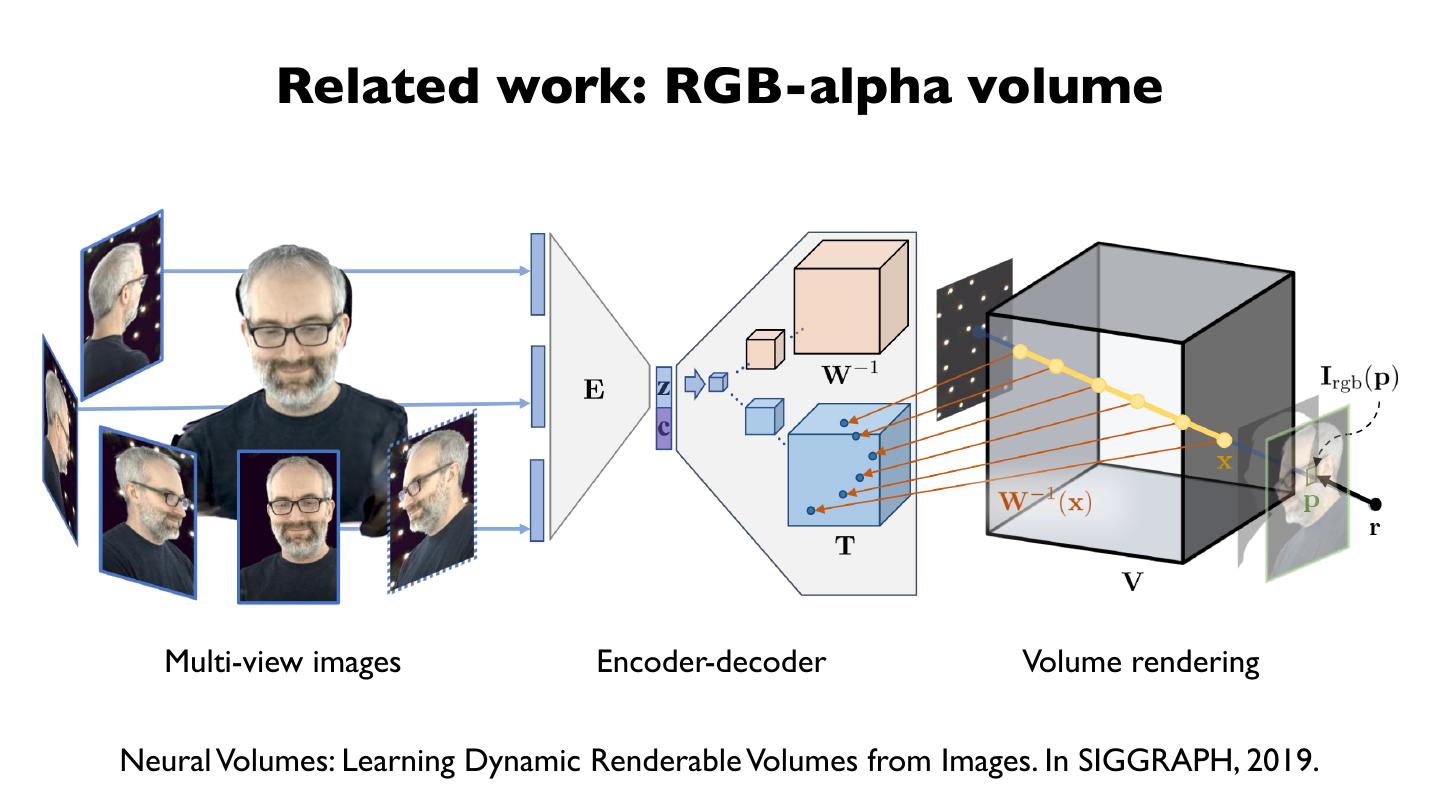
10 . Related work: RGB-alpha volume
Multi-view images Encoder-decoder Volume rendering
Neural Volumes: Learning Dynamic Renderable Volumes from Images. In SIGGRAPH, 2019.
�
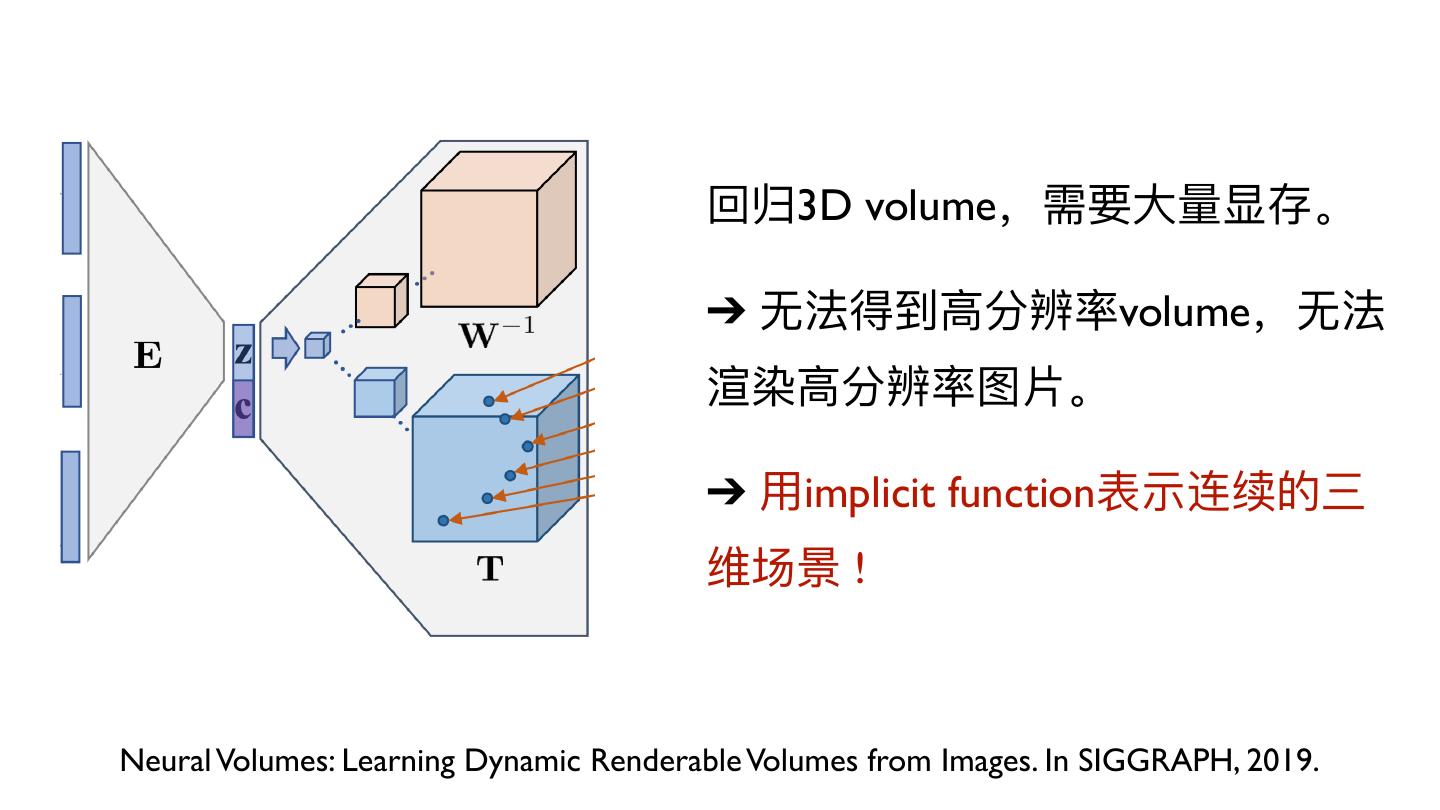
11 . 回归3D volume,需要⼤大量量显存。
➔ ⽆无法得到⾼高分辨率volume,⽆无法
渲染⾼高分辨率图⽚片。
➔ ⽤用implicit function表示连续的三
维场景 !
Neural Volumes: Learning Dynamic Renderable Volumes from Images. In SIGGRAPH, 2019.
�
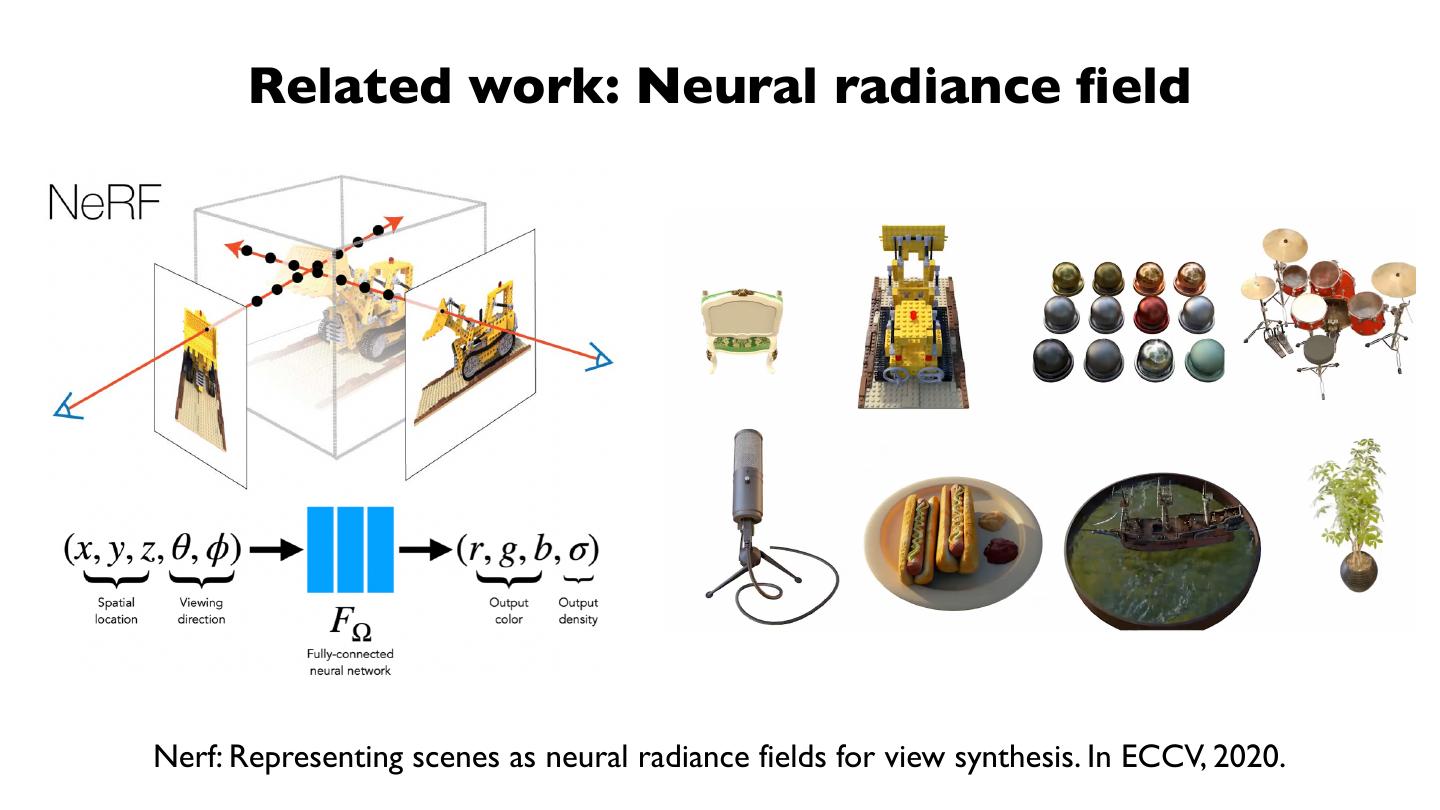
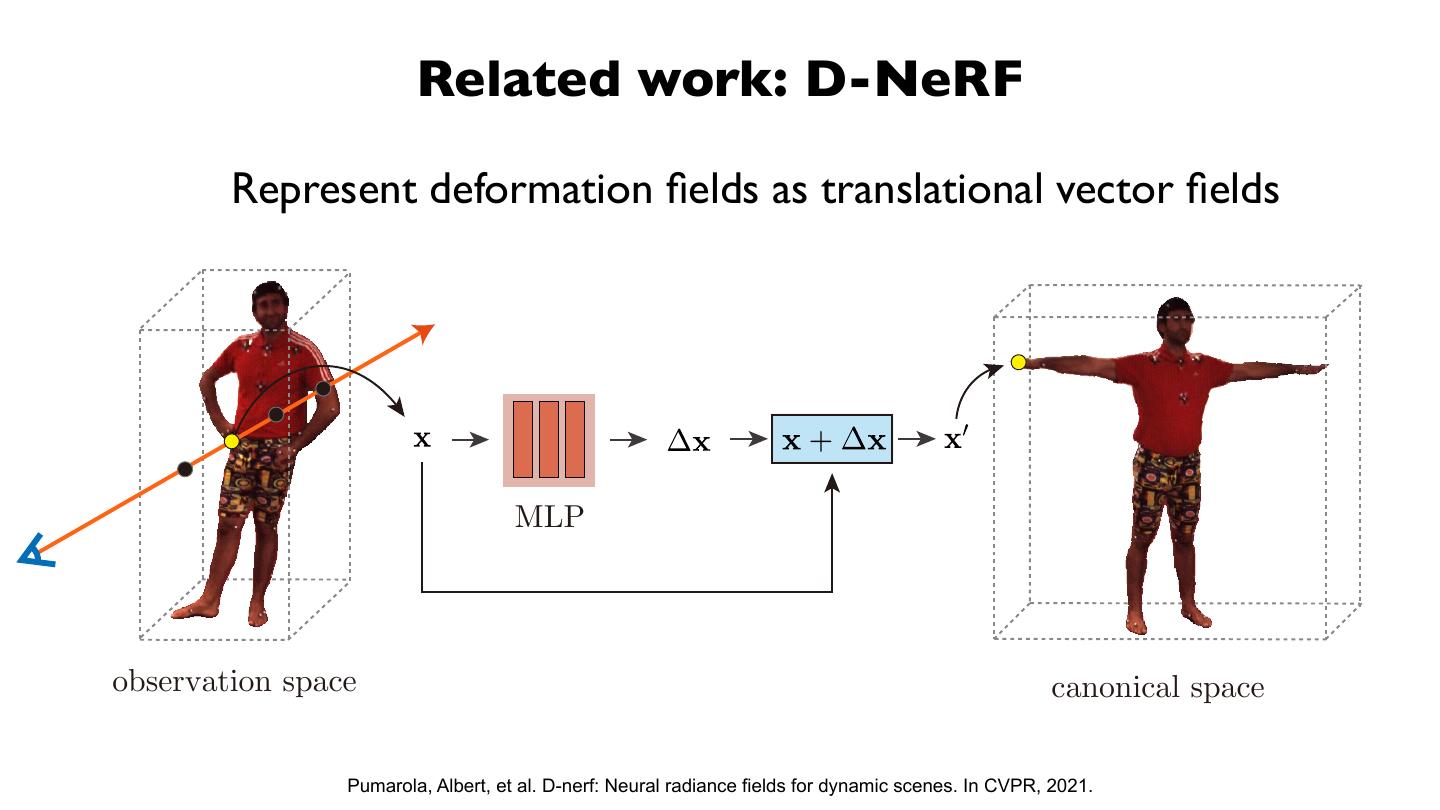
12 . Related work: Neural radiance field
Nerf: Representing scenes as neural radiance fields for view synthesis. In ECCV, 2020.
�
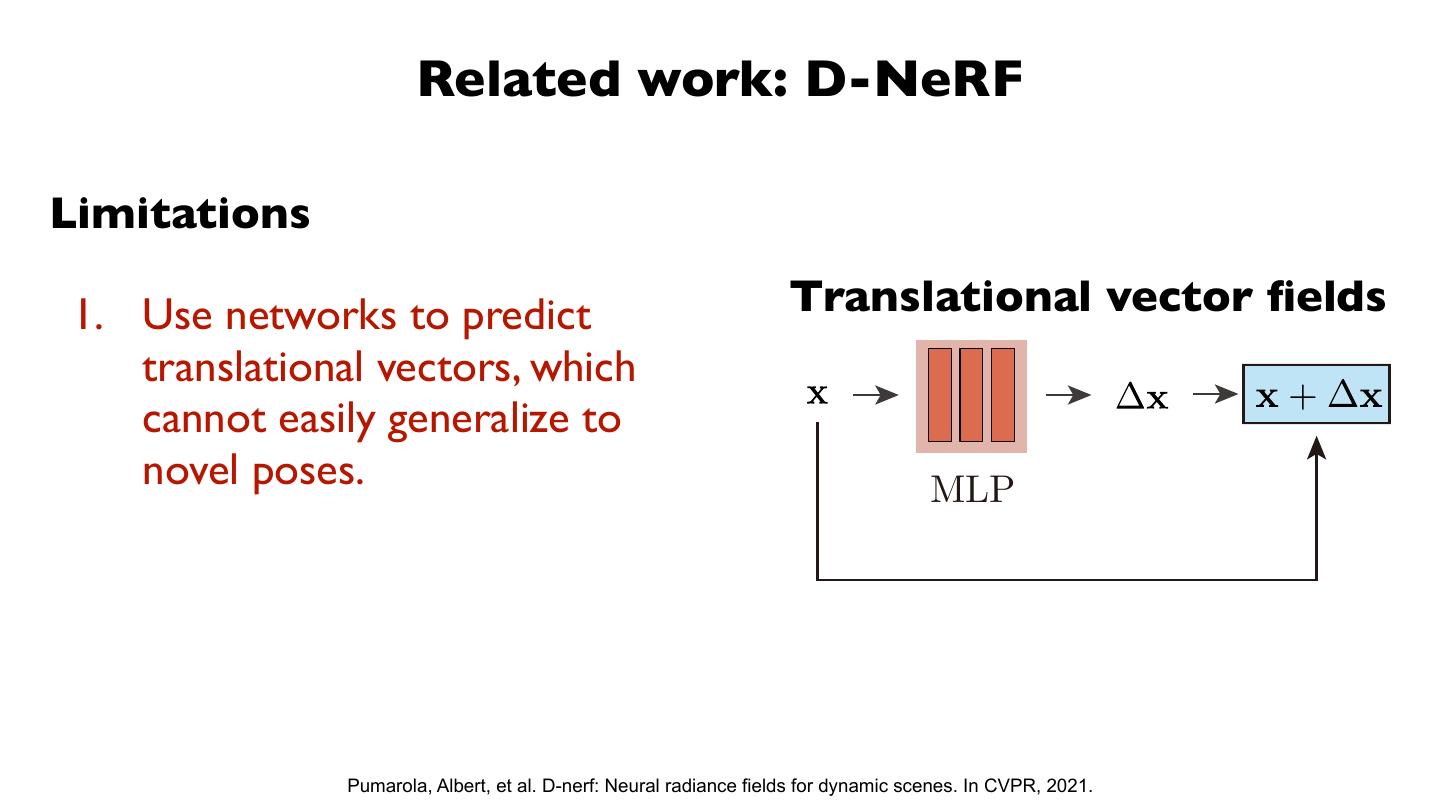
13 . Challenges for NeRF
• Cannot handle dynamic scenes.
• Require dense input views.
�
14 . Challenges for NeRF
• Cannot handle dynamic scenes.
• Require dense input views.
�
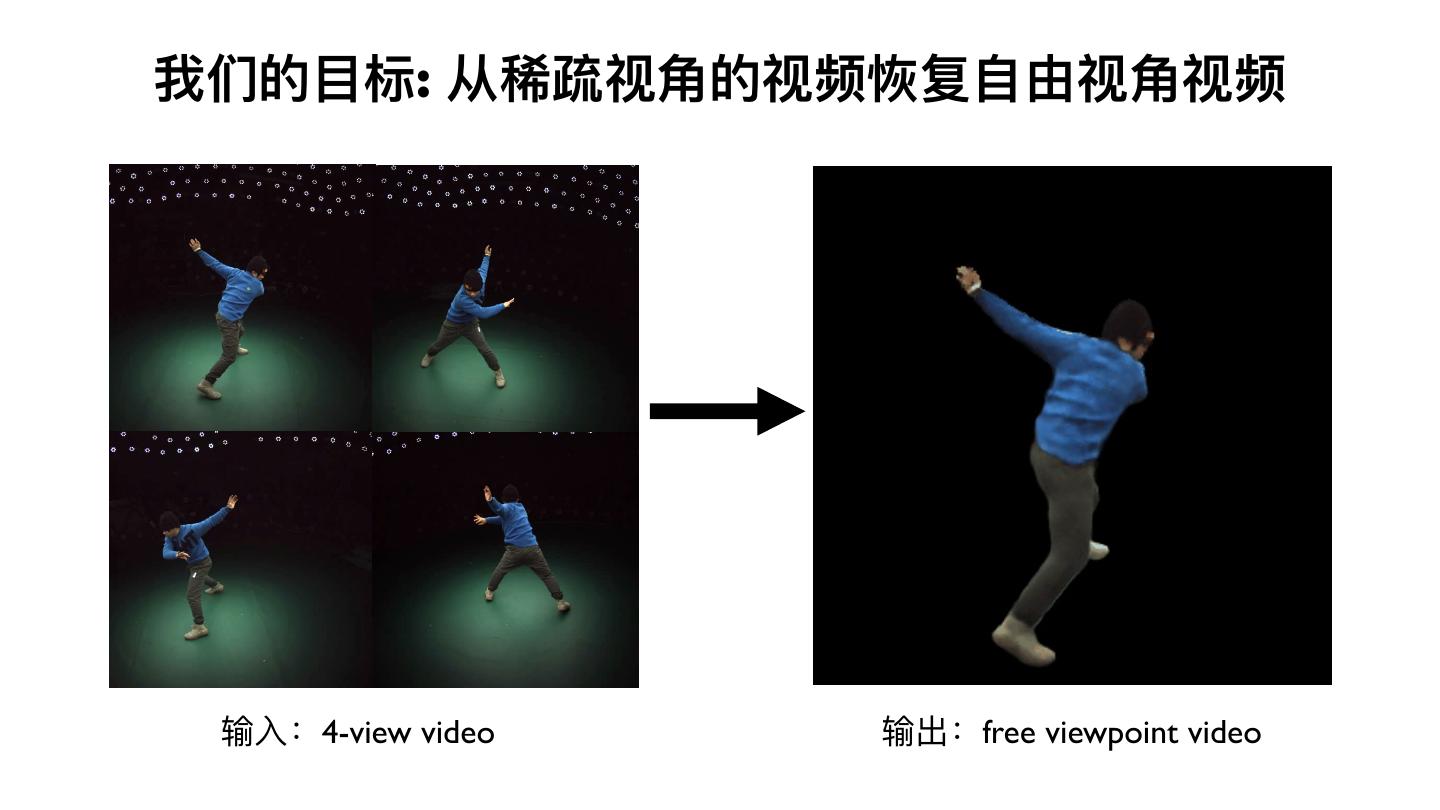
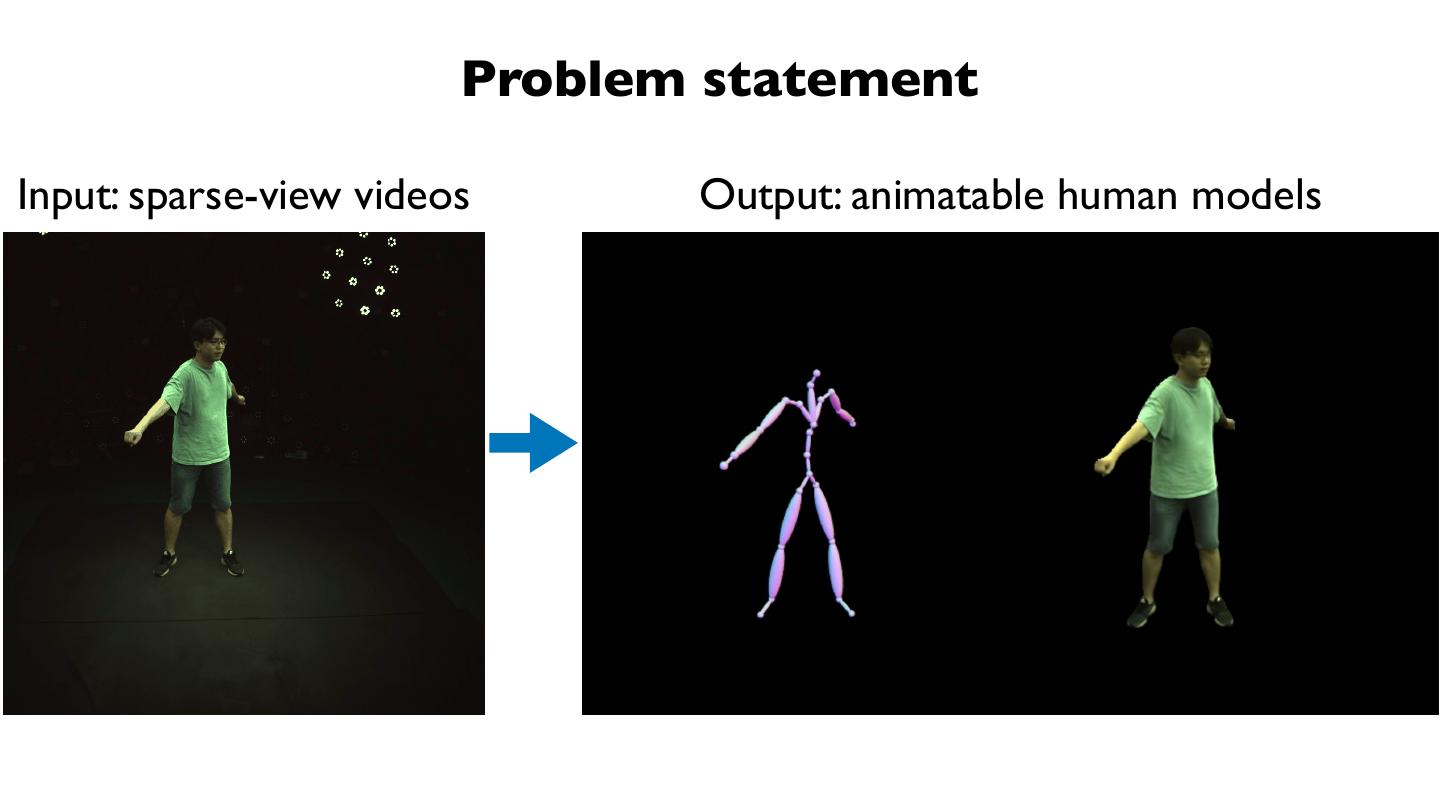
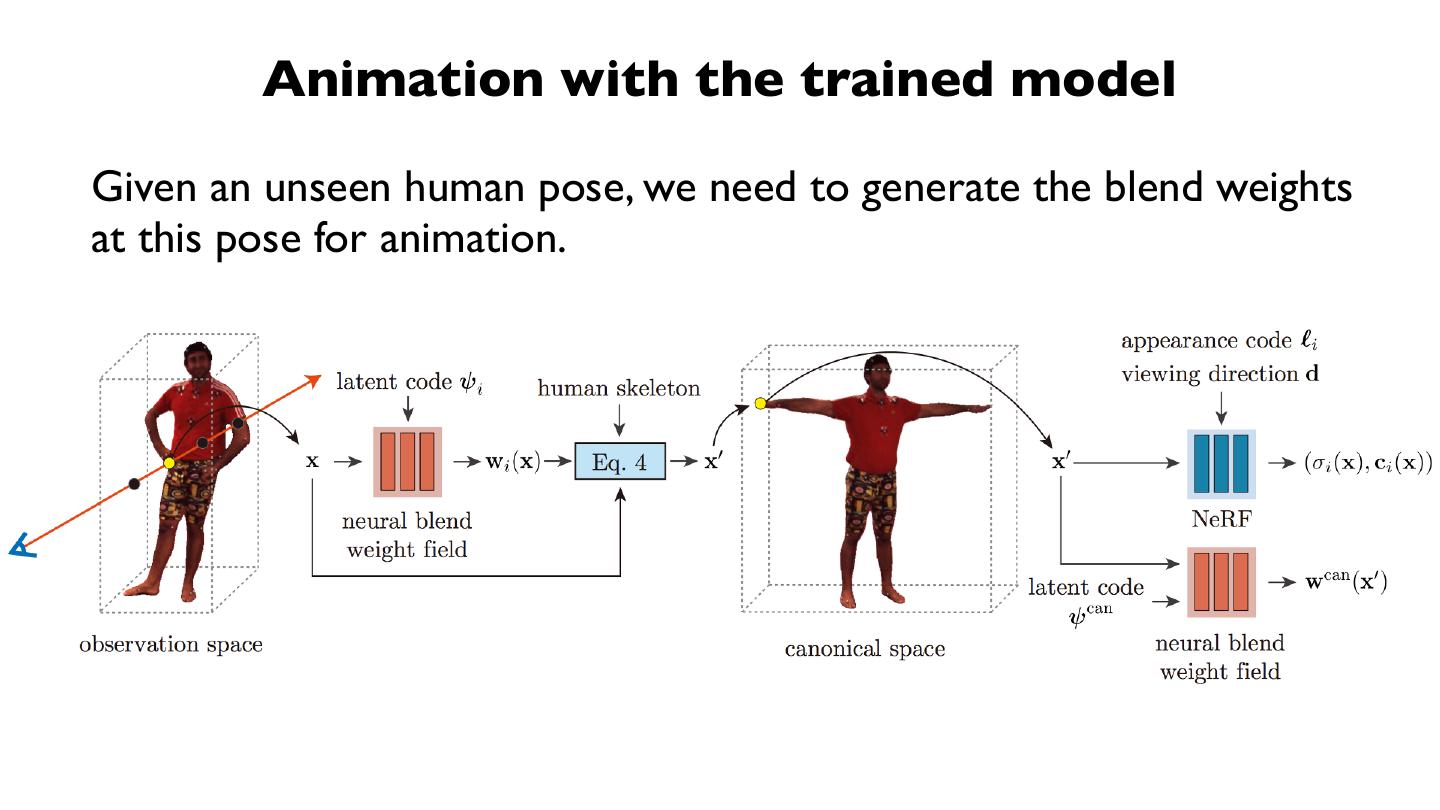
15 .我们的⽬目标: 从稀疏视⻆角的视频恢复⾃自由视⻆角视频
输⼊入:4-view video 输出:free viewpoint video
�
16 . 我们的⽬目标: 从稀疏视⻆角的视频恢复⾃自由视⻆角视频
Motivation: 整合时序信息来获得⾜足够的3d shape observation
输⼊入:4-view video 输出:free viewpoint video
�
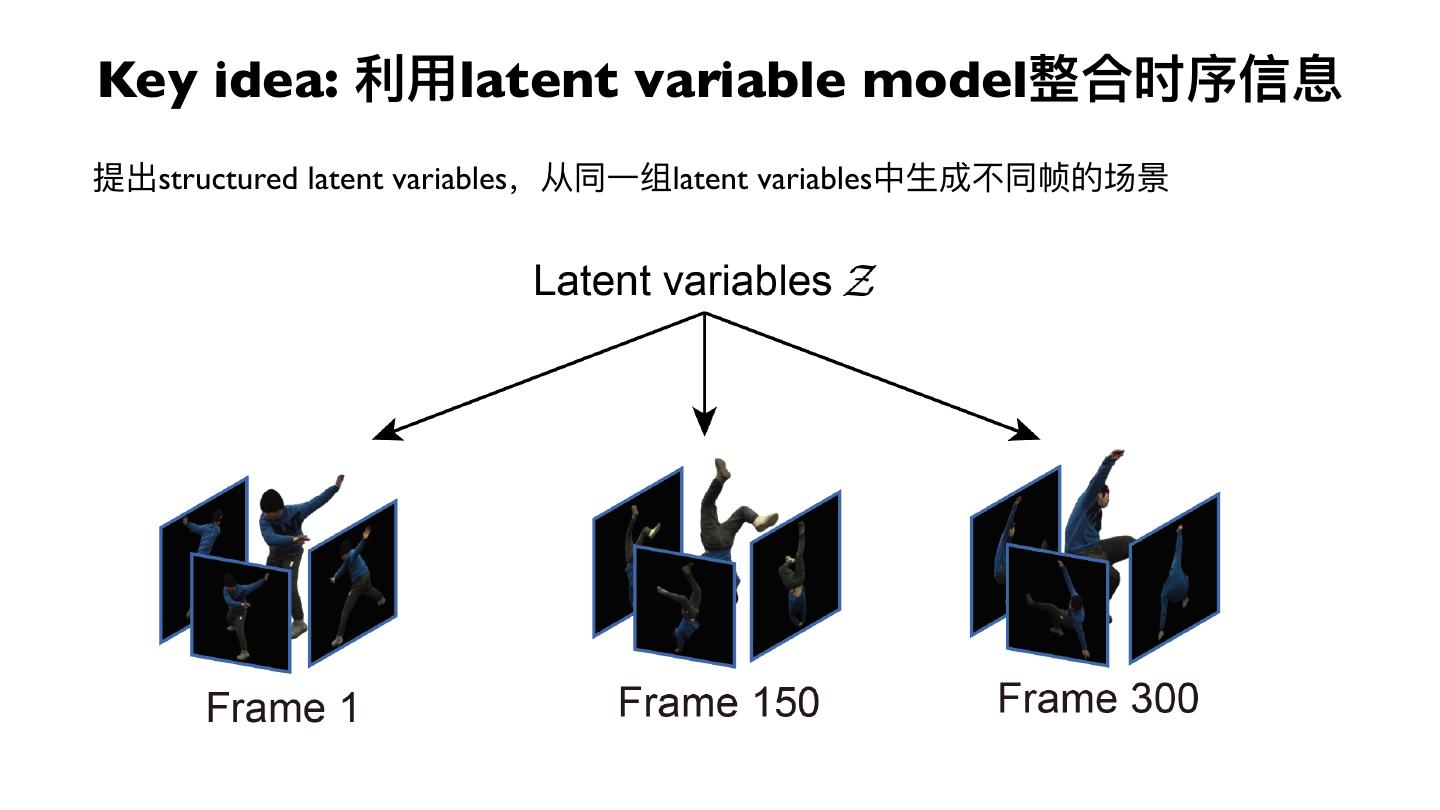
17 .Key idea: 利利⽤用latent variable model整合时序信息
提出structured latent variables,从同⼀一组latent variables中⽣生成不不同帧的场景
�
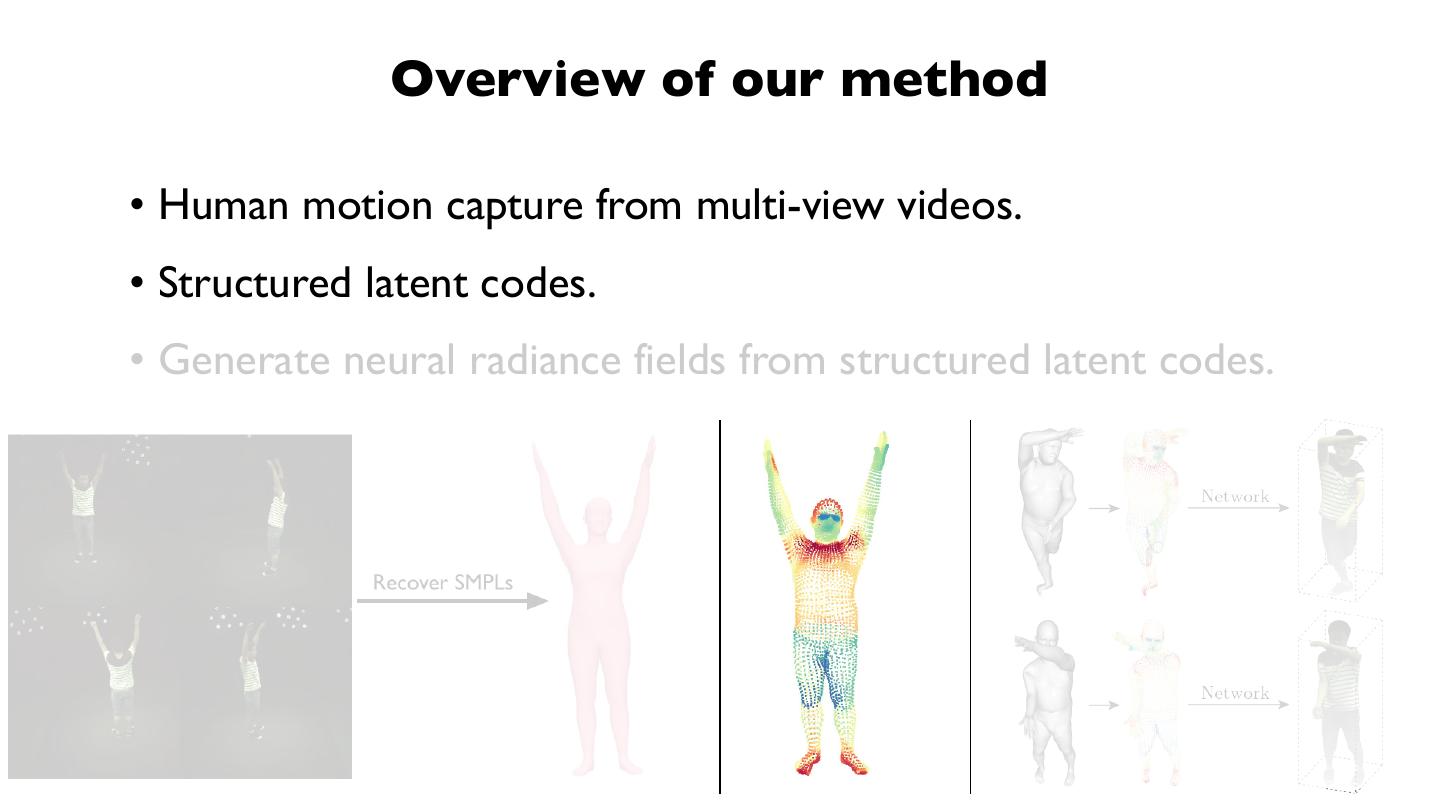
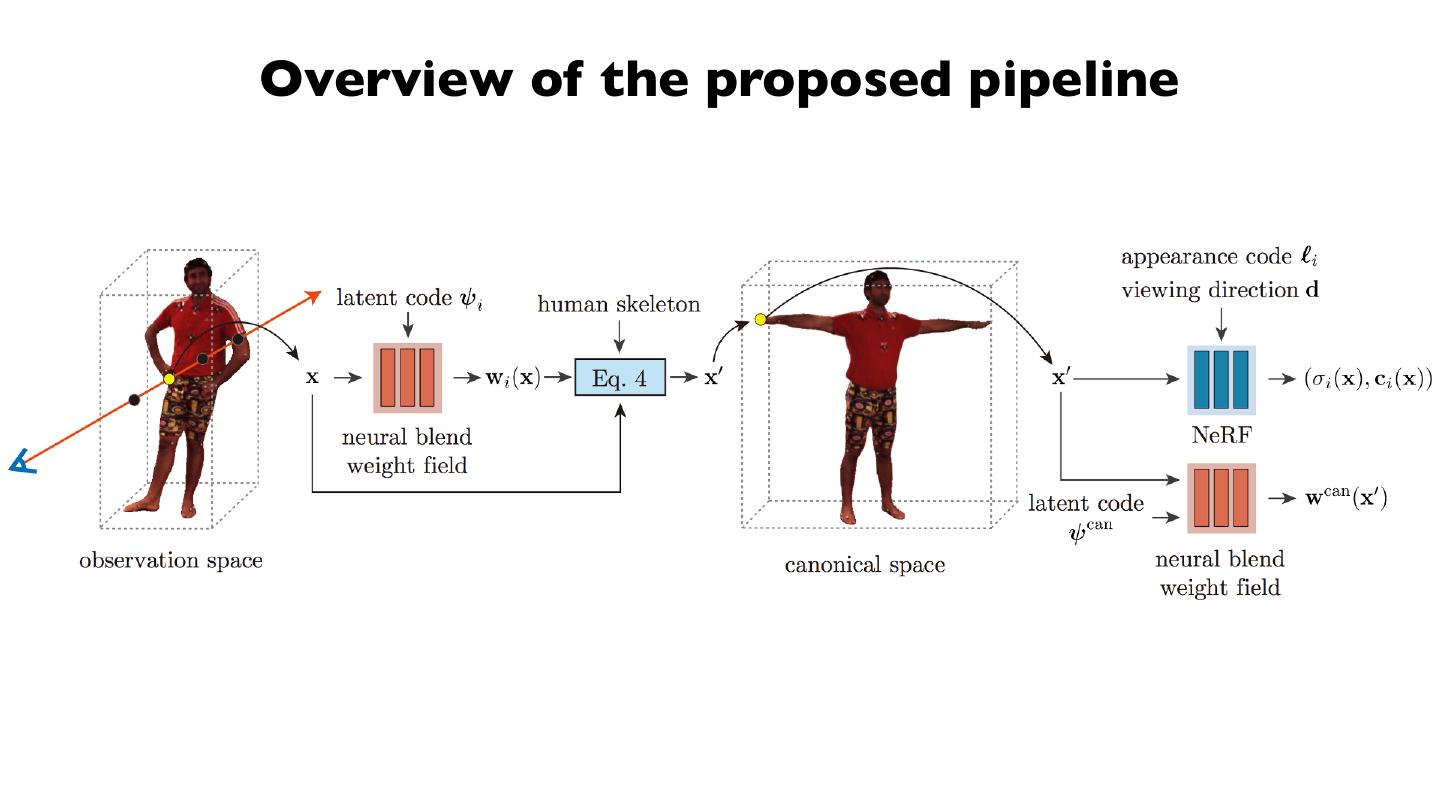
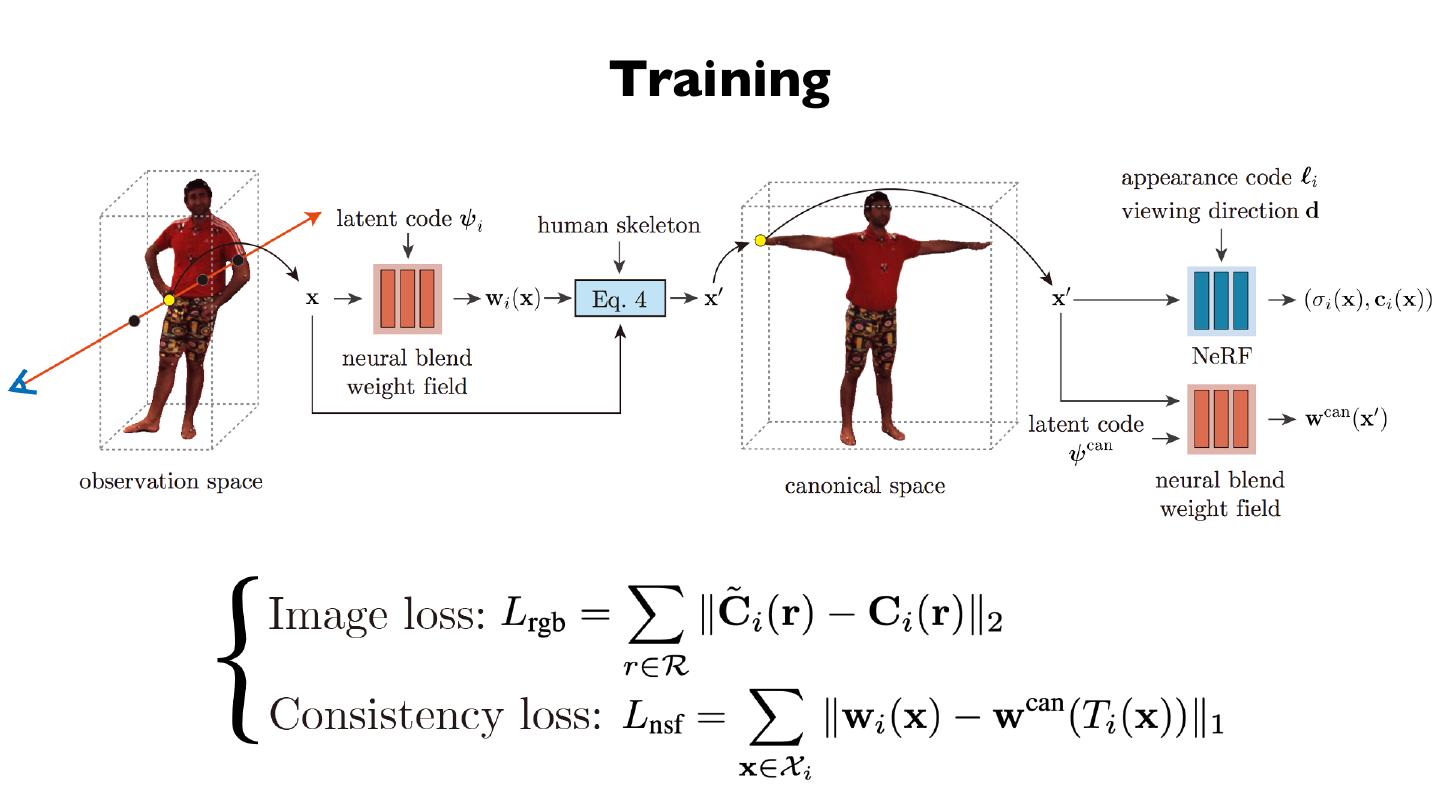
18 . Overview of our method
• Human motion capture from multi-view videos.
• Structured latent codes.
• Generate neural radiance fields from structured latent codes.
Recover SMPLs
�
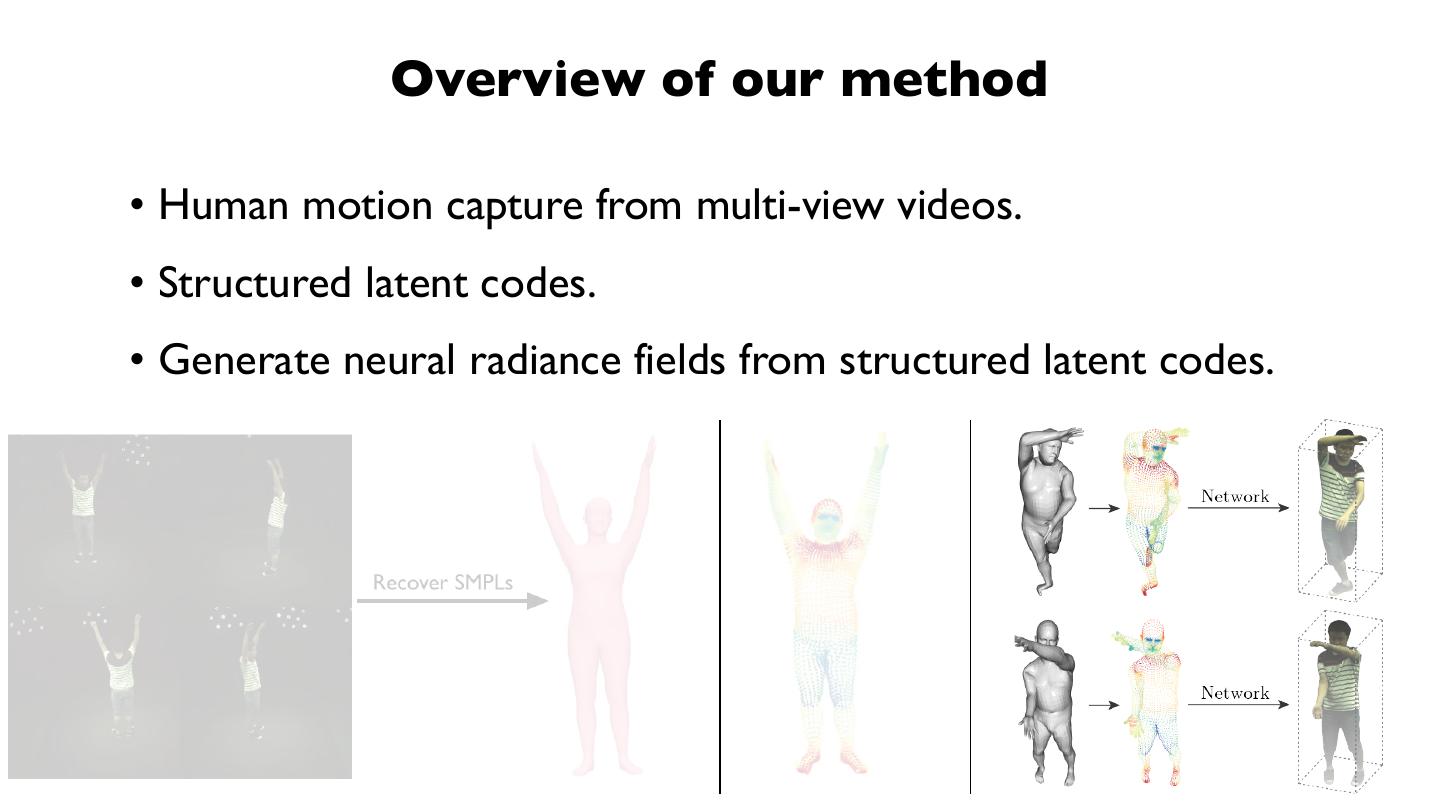
19 . Overview of our method
• Human motion capture from multi-view videos.
• Structured latent codes.
• Generate neural radiance fields from structured latent codes.
�
20 . Overview of our method
• Human motion capture from multi-view videos.
• Structured latent codes.
• Generate neural radiance fields from structured latent codes.
�
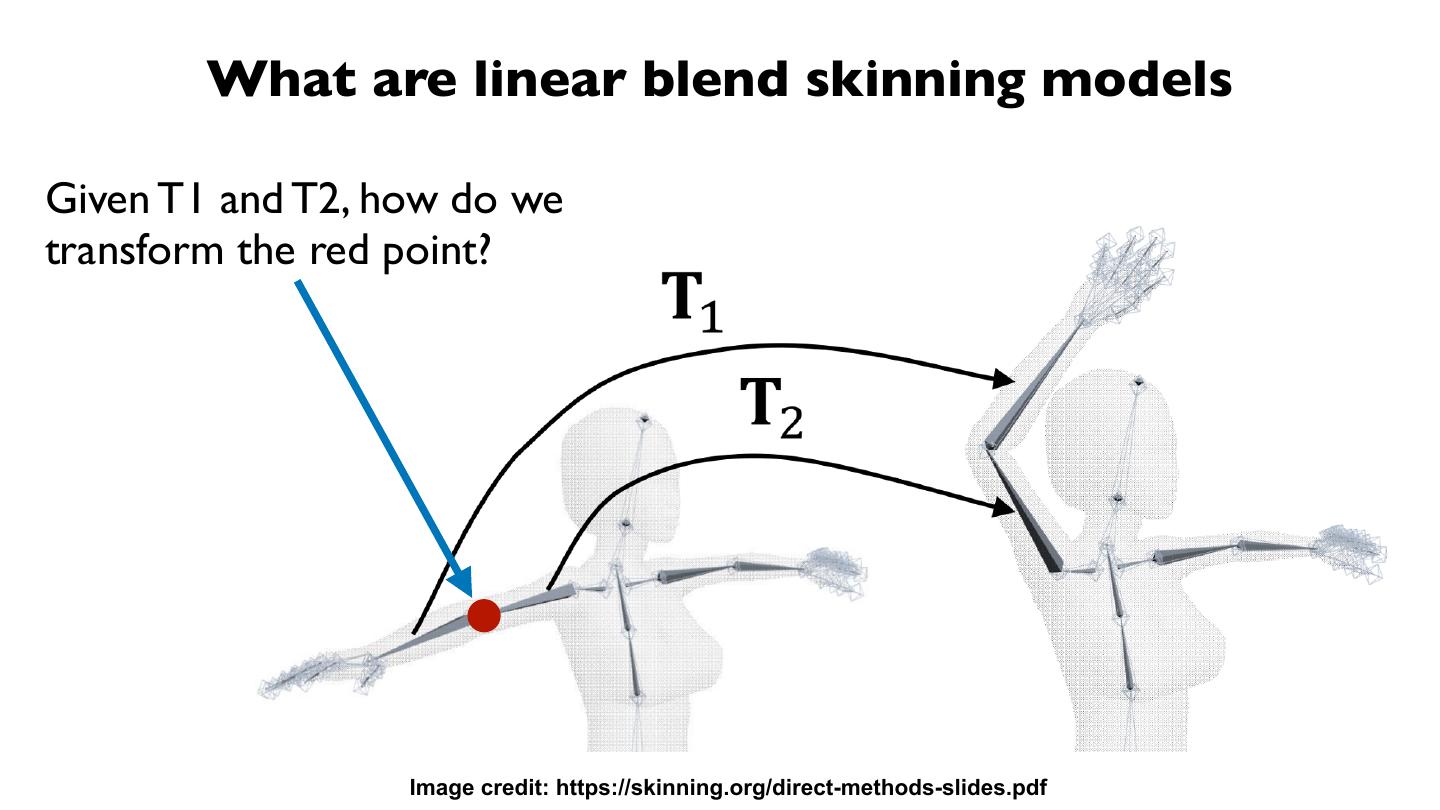
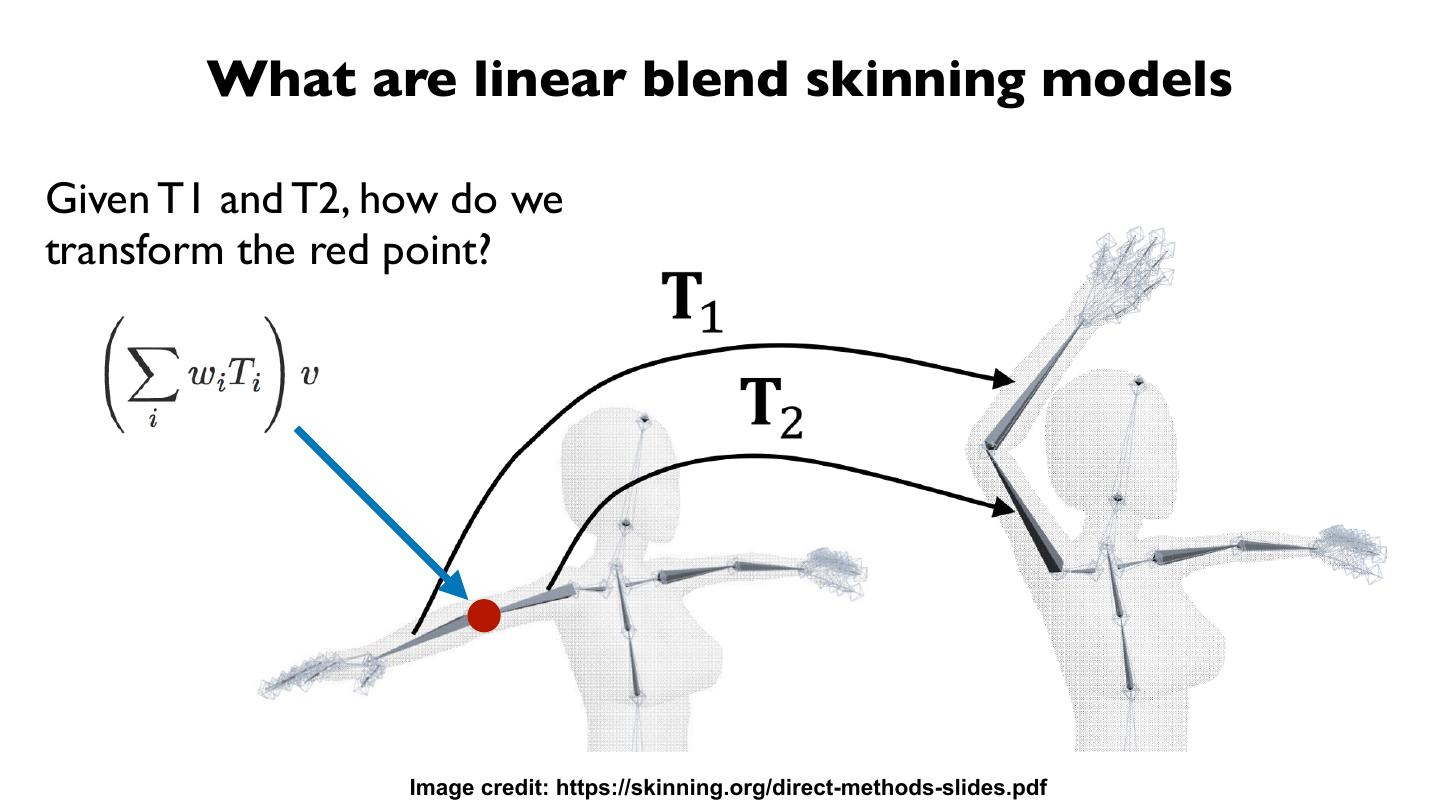
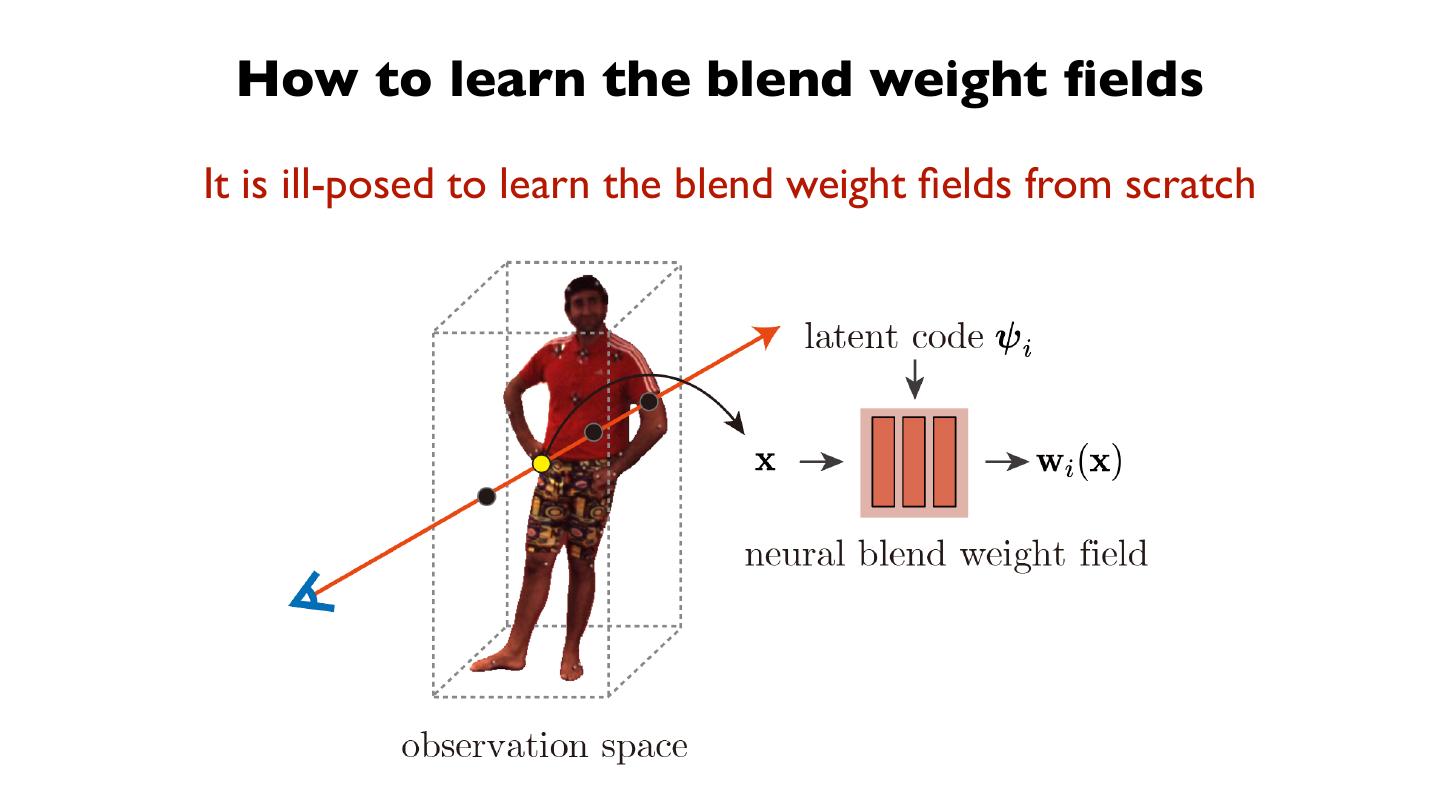
21 . Method: 1) Human motion capture
整合时序信息,需要在视频帧之间建⽴立关联。
➔ 需要建⽴立correspondence。
➔ 需要proxy geometry。
➔ SMPL model !
�
22 .SMPL可以从稀疏视⻆角图⽚片中准确恢复
https://www.youtube.com/watch?v=kuBlUyHeV5U
�
23 . Method: 1) Human motion capture
Capture human motion using https://github.com/zju3dv/EasyMocap
Recover SMPLs
�
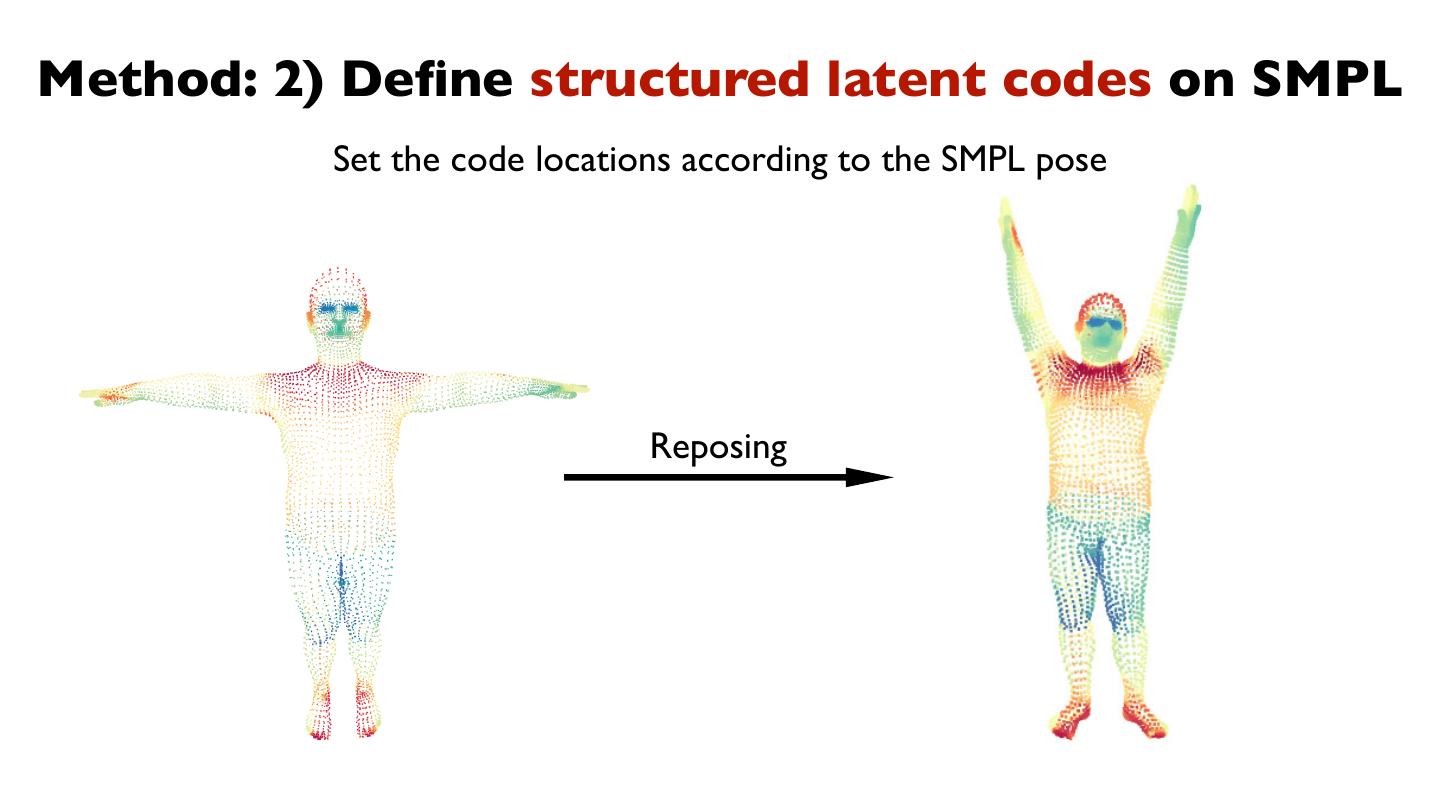
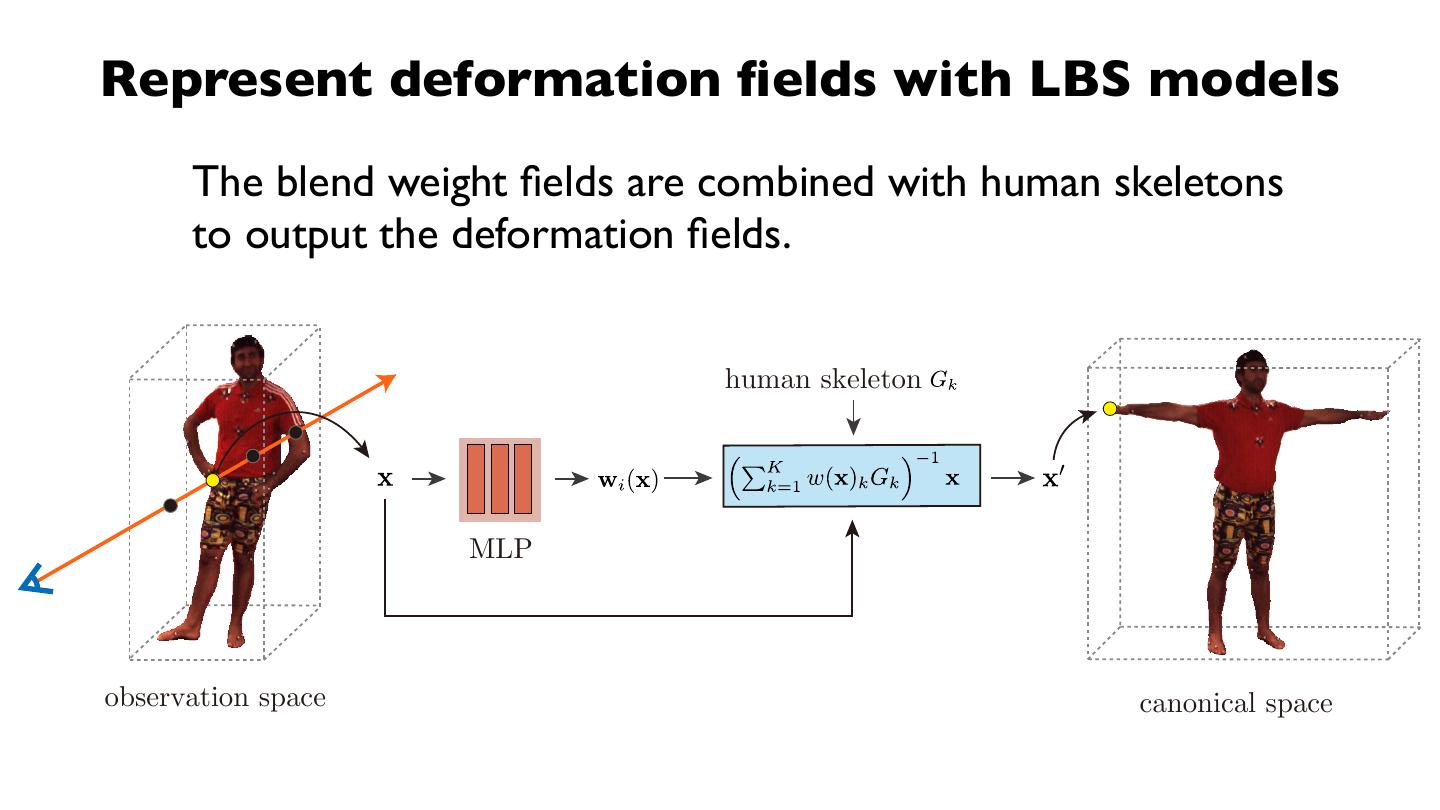
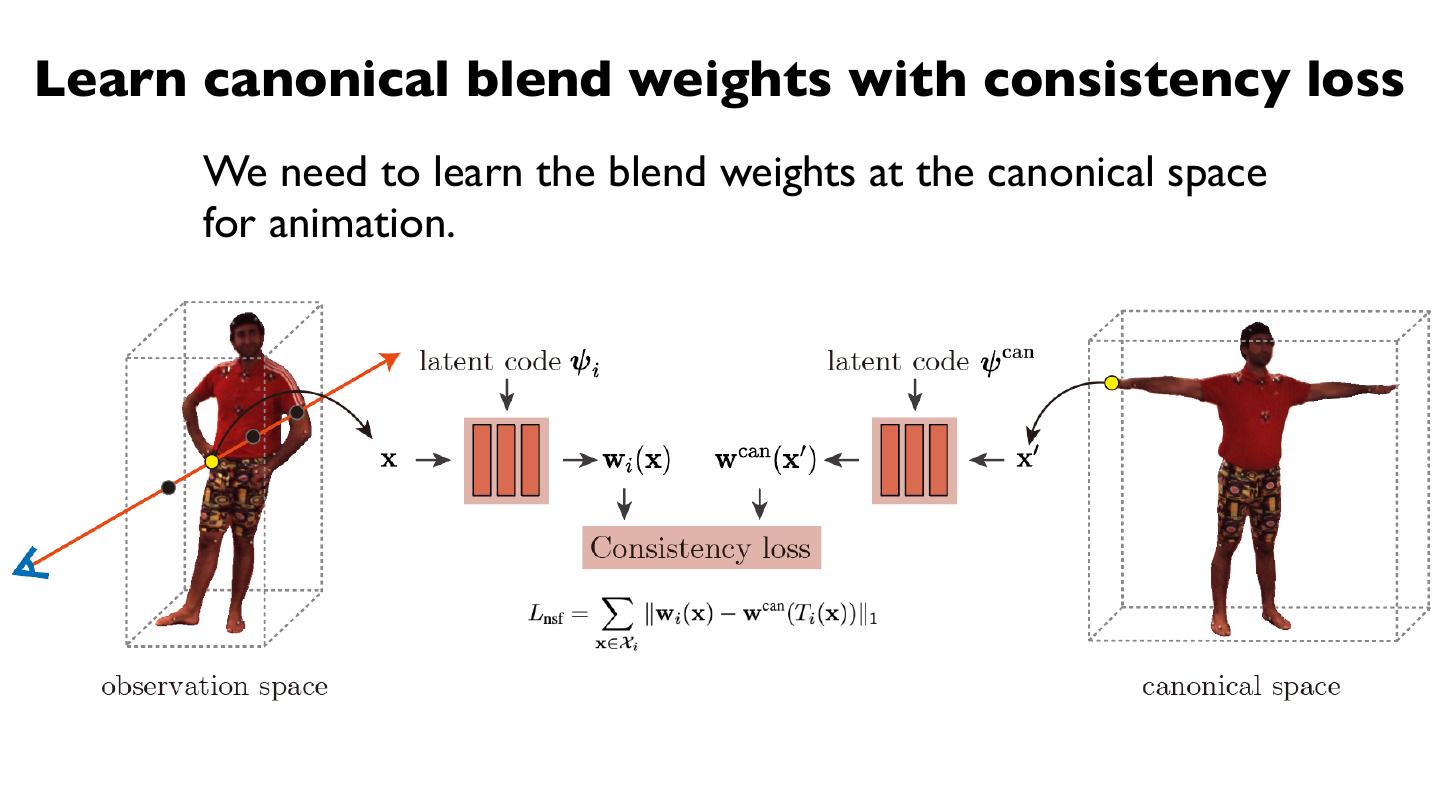
24 .Method: 2) Define structured latent codes on SMPL
For each SMPL vertex, we assign a learnable latent code
�
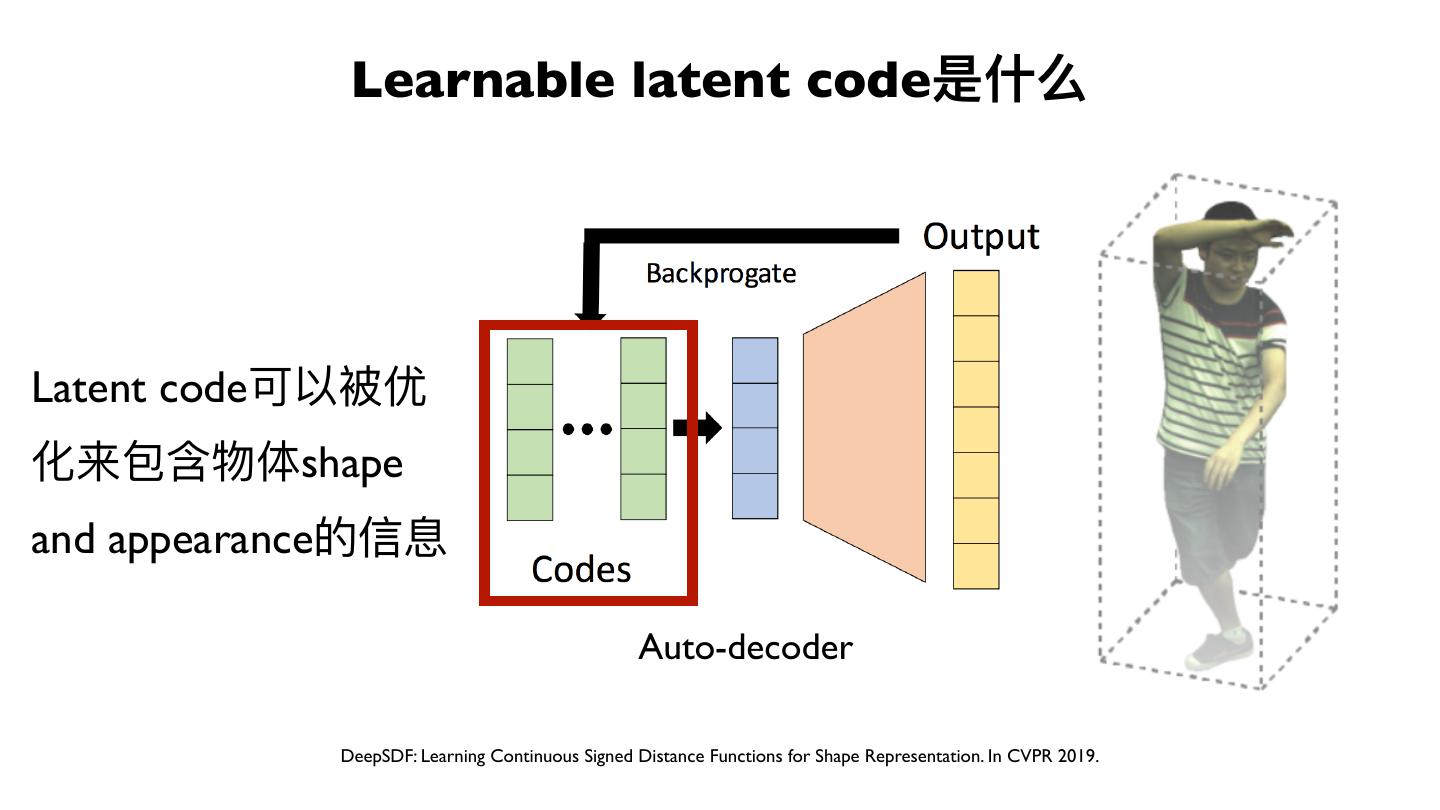
25 . Learnable latent code是什什么
Auto-encoder Auto-decoder
DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation. In CVPR 2019.
�
26 . Learnable latent code是什什么
Latent code可以被优
化来包含物体shape
and appearance的信息
Auto-decoder
DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation. In CVPR 2019.
�
27 .Method: 2) Define structured latent codes on SMPL
Set the code locations according to the SMPL pose
Reposing
�
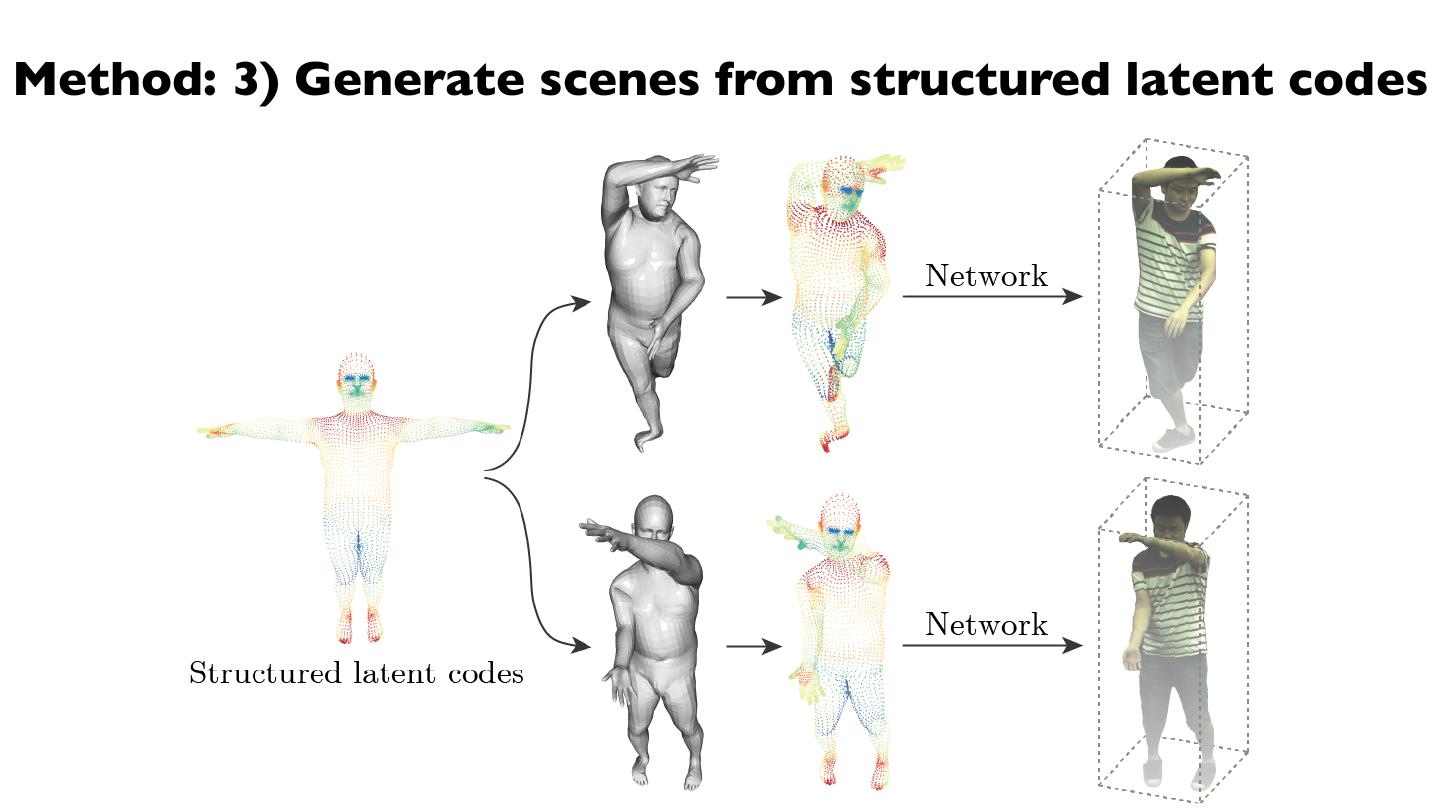
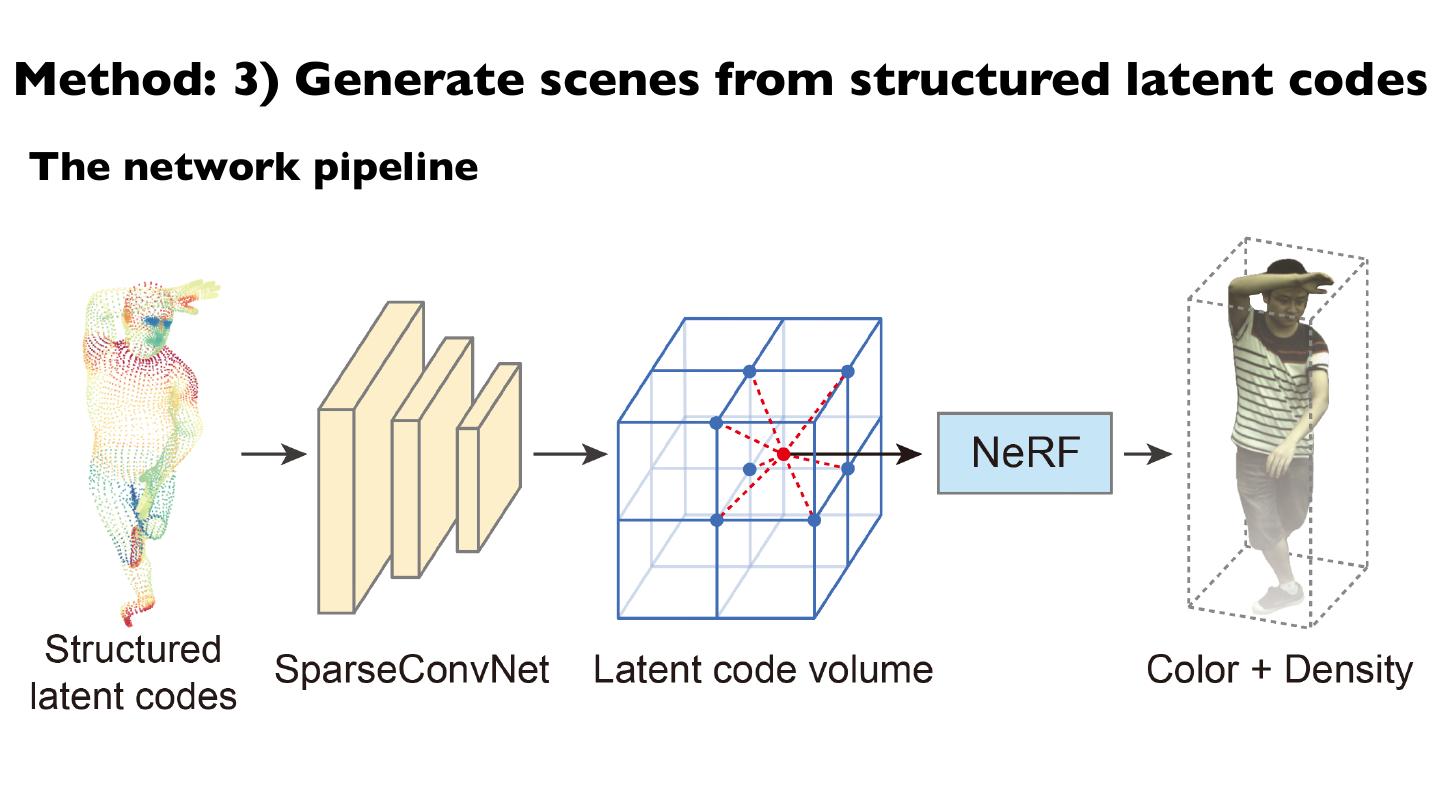
28 .Method: 3) Generate scenes from structured latent codes
�
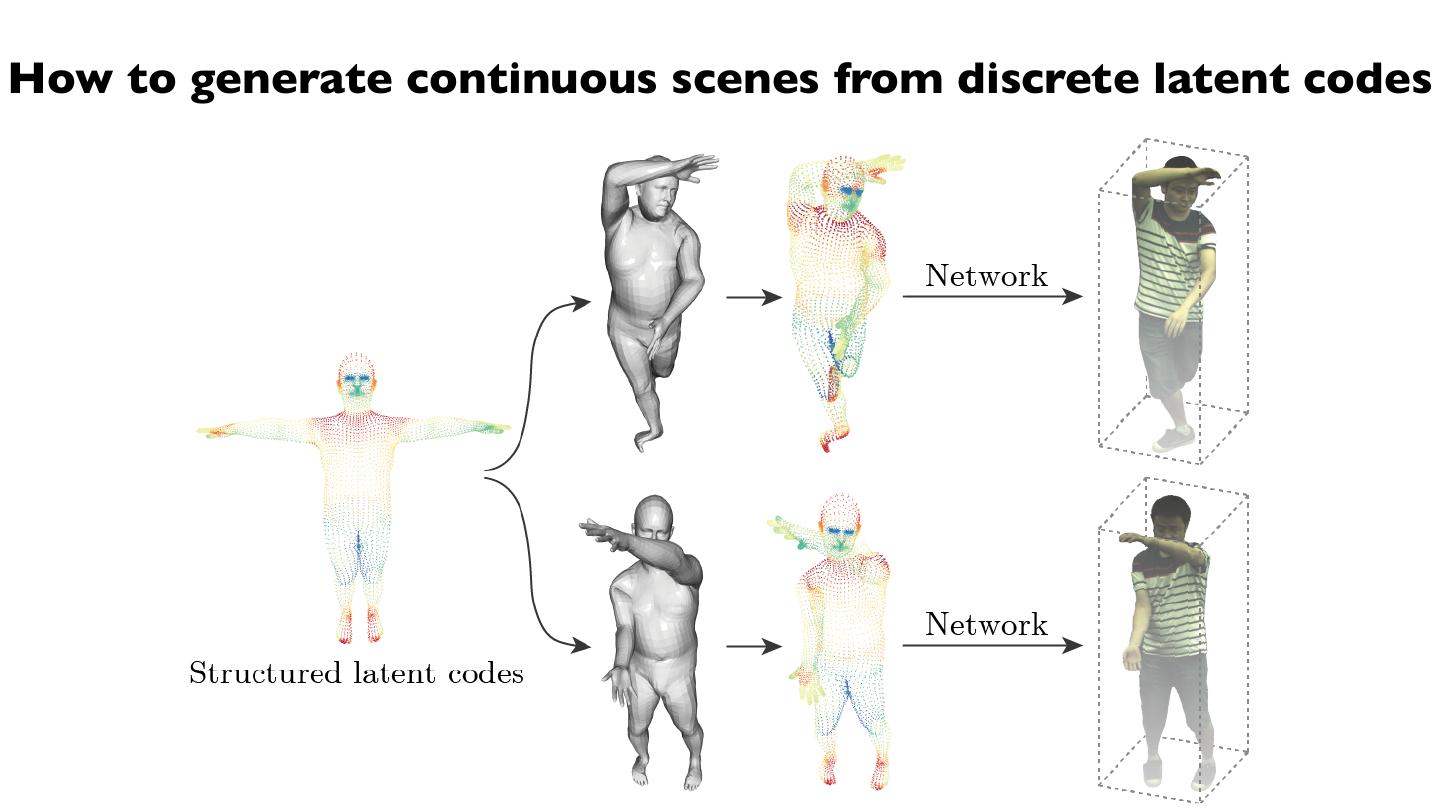
29 .How to generate continuous scenes from discrete latent codes
�