展开查看详情
2 .https://github.com/WendongZh/SPL
�
3 .Problem Definition & Application
𝑓(𝑀, 𝐼𝑚 )
𝑀 𝐼𝑚 𝐼
Image Restoration1
1. Bringing Old Photos Back to Life, CVPR’20
�
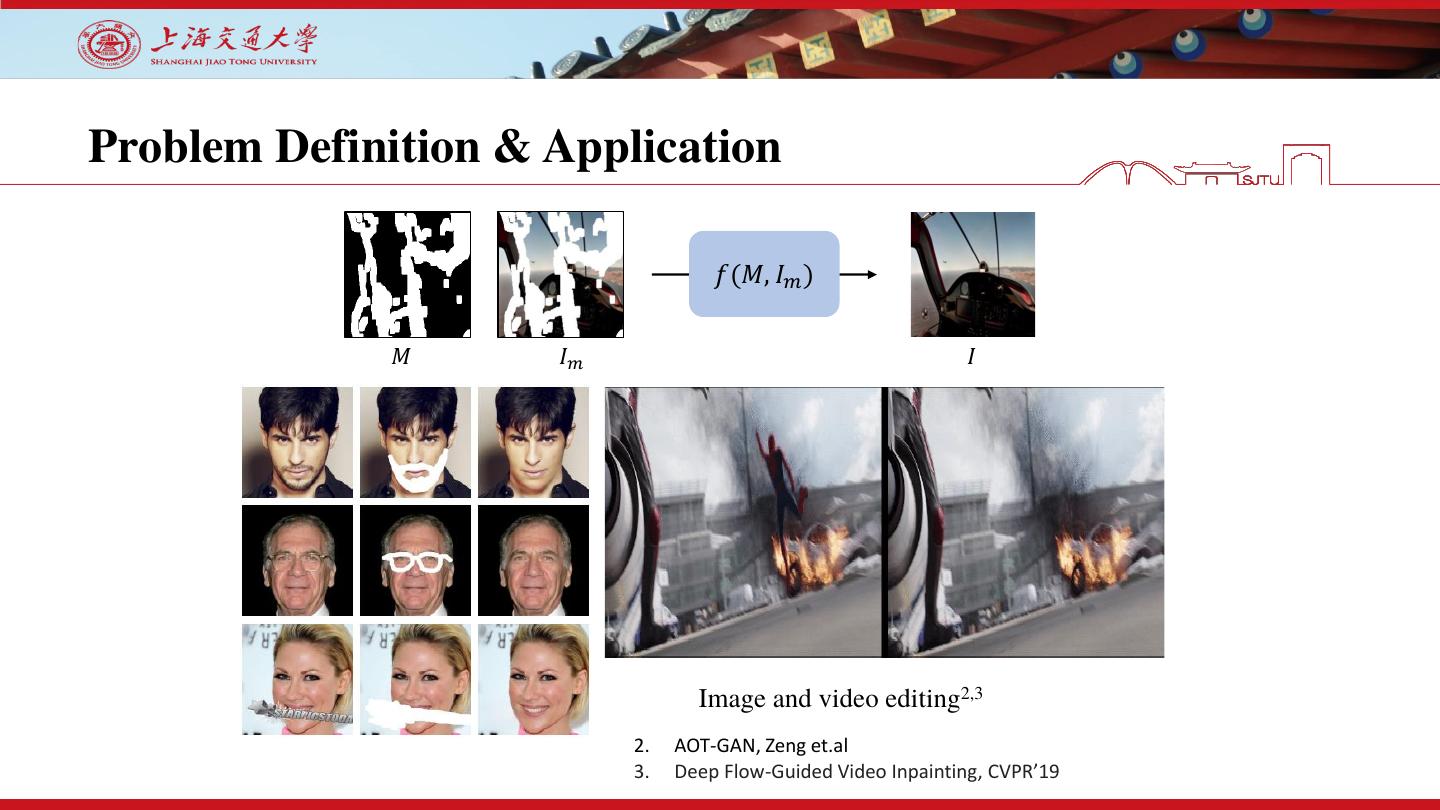
4 .Problem Definition & Application
𝑓(𝑀, 𝐼𝑚 )
𝑀 𝐼𝑚 𝐼
Image and video editing2,3
2. AOT-GAN, Zeng et.al
3. Deep Flow-Guided Video Inpainting, CVPR’19
�
5 .Problem Definition & Application
𝑓(𝑀, 𝐼𝑚 )
𝑀 𝐼𝑚 𝐼
Image and video editing4
4. Insta360 ONE X 相机
�
6 .Problem Definition & Application
𝑓(𝑀, 𝐼𝑚 )
𝑀 𝐼𝑚 𝐼
Image manipulation & detection5
5. Markpainting: Adversarial Machine Learning meets Inpainting, ICML’21
�
7 .Related Work
𝑓(𝑀, 𝐼𝑚 )
𝑀 𝐼𝑚 𝐼
Key Problem:
1. How to extract rich context information from valid pixels.
2. How to reduce the context ambiguities in missing regions
�
8 .Related Work
𝑓(𝑀, 𝐼𝑚 )
𝑀 𝐼𝑚 𝐼
VAE: Pluralistic Image Completion, CVPR’19
GAN: PD-GAN: Probabilistic Diverse GAN for Image Inpainting, CVPR’21
Probabilistic Auto-regressive: Generating Diverse Structure for Image Inpainting With Hierarchical VQ-VAE, CVPR’21
model StyleGAN based: Co-Modulated GAN, ICLR’21
Early work: Texture diffusion, Patch-based methods
Deterministic
model
�
9 . Related Work
DSNet, TIP’21
Operation
cell: AOT-GAN, Zeng et. al
PC Conv
RFR, CVPR’20
MRF, ICCV’21
Deep
learning Pipeline:
Generative image inpainting with contextual attention
SF, CVPR’19
Structure MFE, ECCV’20
enhance: CTSD, ICCV’21
EdgeConnect: Generative Image Inpainting with Adversarial Edge (EC)
�
10 .Motivation
➢ The context ambiguity is one of the major sticking points in restoring reasonable contents,
which cannot be well tackled with only local textures.
GT Input Out(RFR) GT Input Out(RFR)
➢ Low-level structure supervisions mainly focus on local texture consistency instead of
global context, which cannot handle more complicated structure restoration.
Input Out Edge(EC) Out(EC) Input Out Edge(EC) Out(EC)
�
11 .Motivation
Contributions:
1. We show that distilling high-level knowledge from specific pretext tasks can benefit
the understanding of global contextual relations and is meaningful to low-level image
inpainting
2. We propose SPL, a new model for context-aware image inpainting, which adaptively
incorporates the learned semantic priors and the local image features in a unified
generative network
�
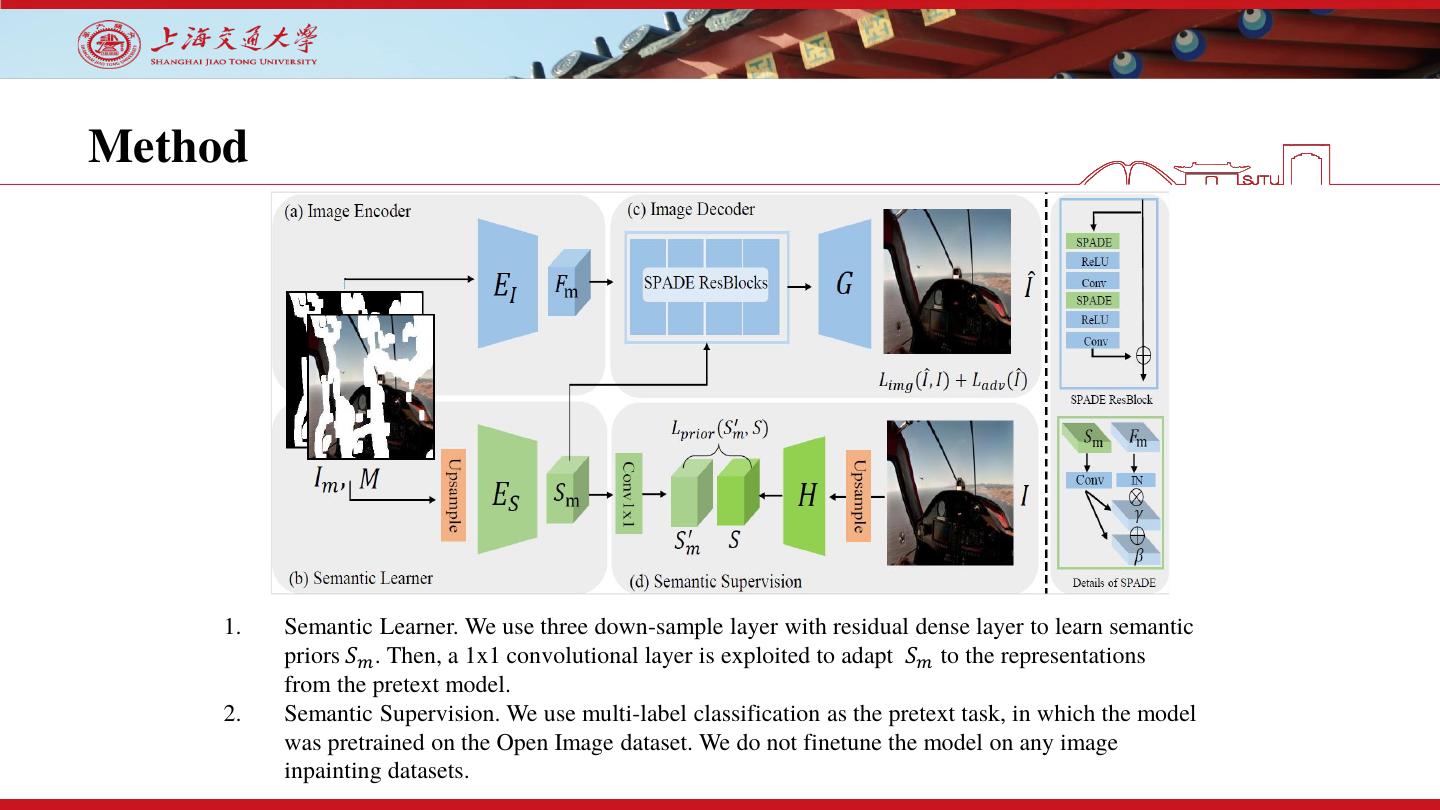
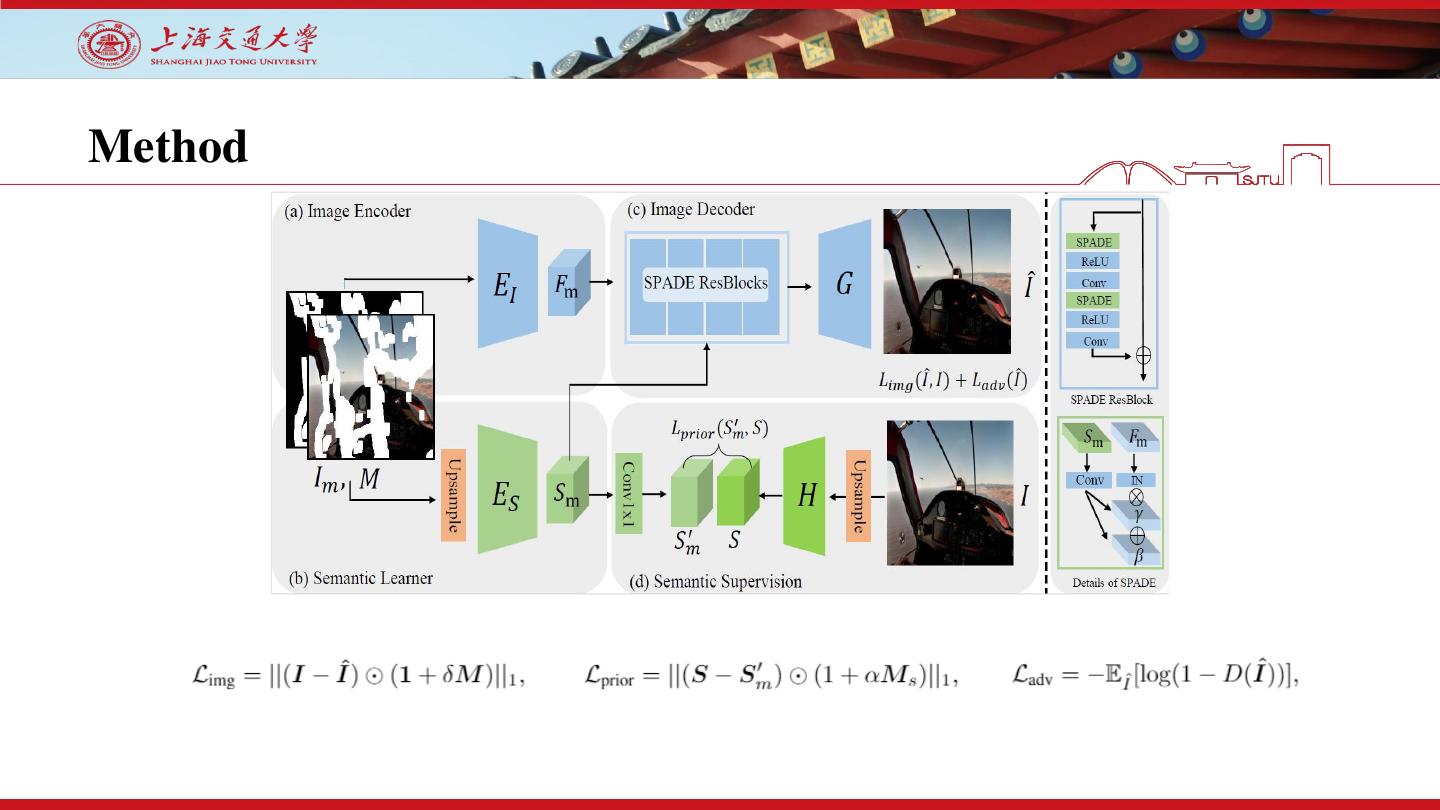
12 .Method
1. Semantic Learner. We use three down-sample layer with residual dense layer to learn semantic
priors 𝑆𝑚 . Then, a 1x1 convolutional layer is exploited to adapt 𝑆𝑚 to the representations
from the pretext model.
2. Semantic Supervision. We use multi-label classification as the pretext task, in which the model
was pretrained on the Open Image dataset. We do not finetune the model on any image
inpainting datasets.
�
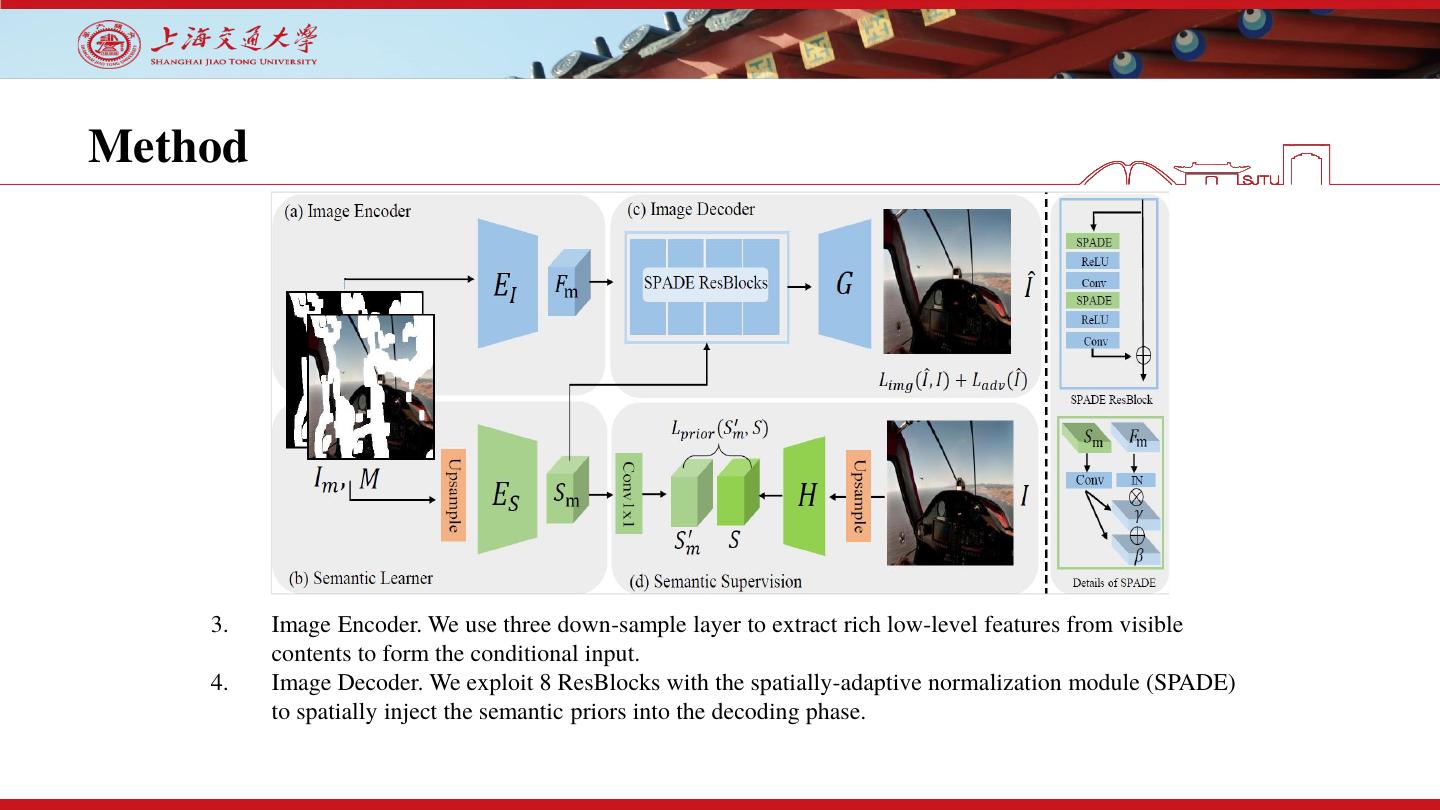
13 .Method
3. Image Encoder. We use three down-sample layer to extract rich low-level features from visible
contents to form the conditional input.
4. Image Decoder. We exploit 8 ResBlocks with the spatially-adaptive normalization module (SPADE)
to spatially inject the semantic priors into the decoding phase.
�
16 .Results
We evaluate our model on three popular datasets, including Places2, CelebA , and Paris StreetView.
�
17 .Results
More visual results of our method
GT Input Out GT Input Out
�
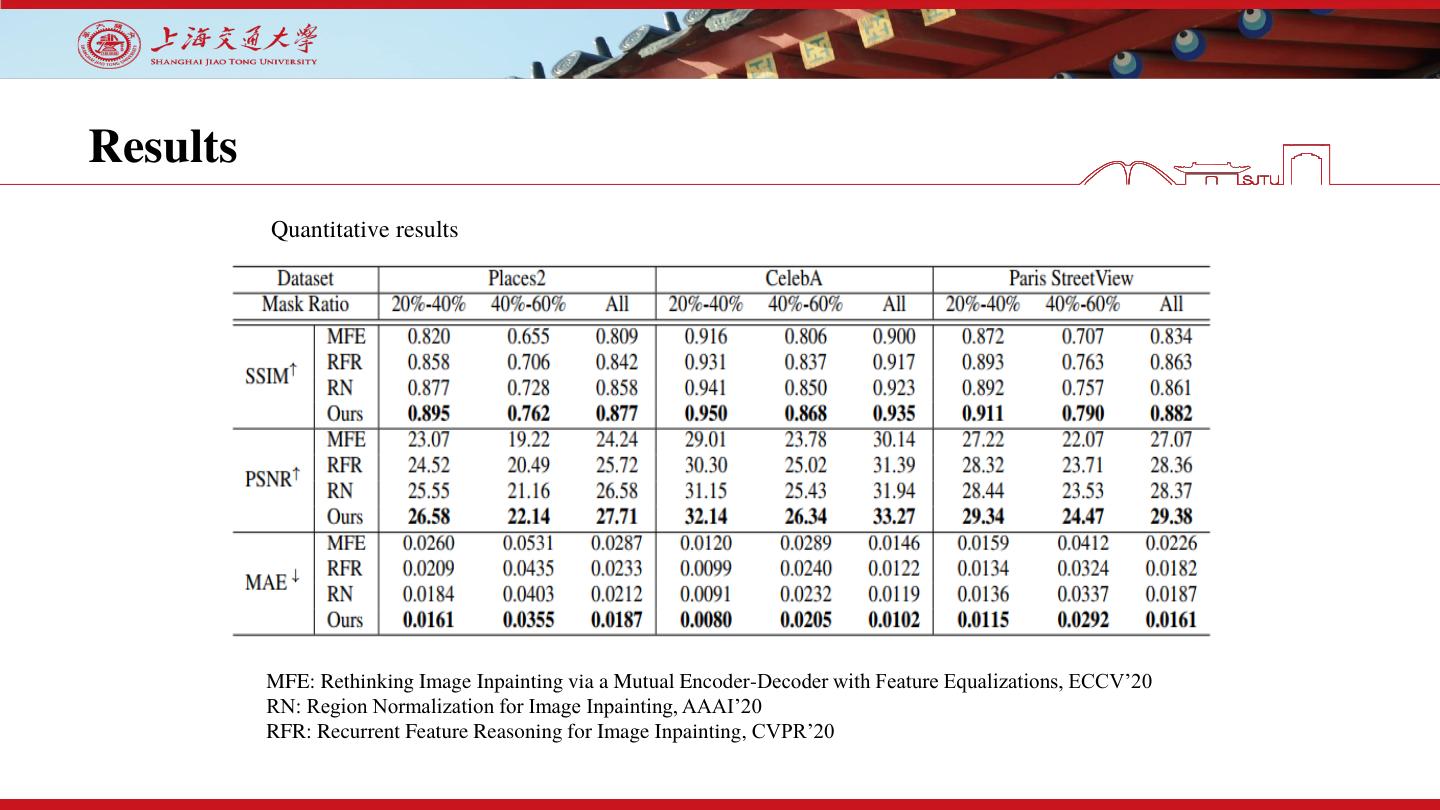
18 .Results
Quantitative results
MFE: Rethinking Image Inpainting via a Mutual Encoder-Decoder with Feature Equalizations, ECCV’20
RN: Region Normalization for Image Inpainting, AAAI’20
RFR: Recurrent Feature Reasoning for Image Inpainting, CVPR’20
�
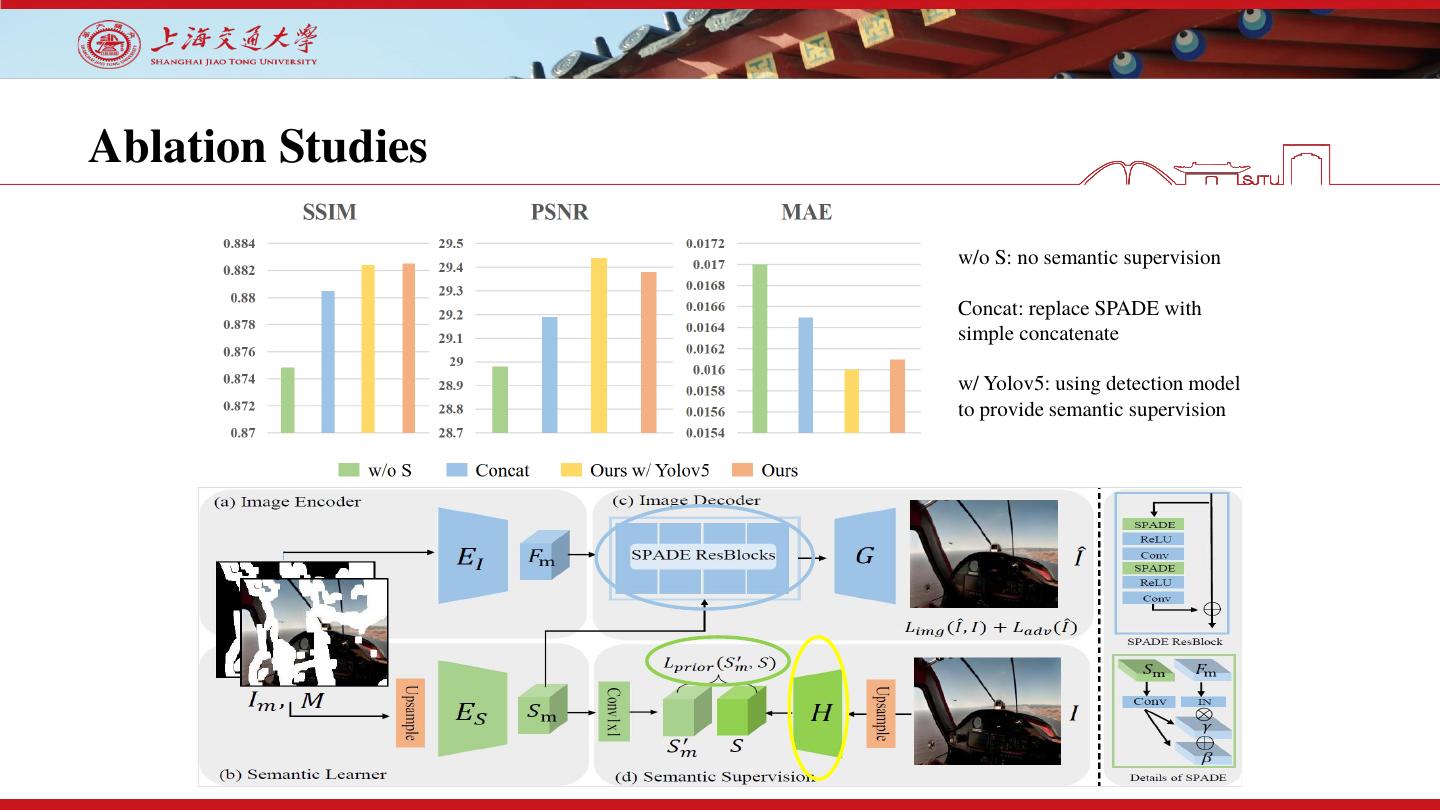
19 .Ablation Studies
w/o S: no semantic supervision
Concat: replace SPADE with
simple concatenate
w/ Yolov5: using detection model
to provide semantic supervision
�
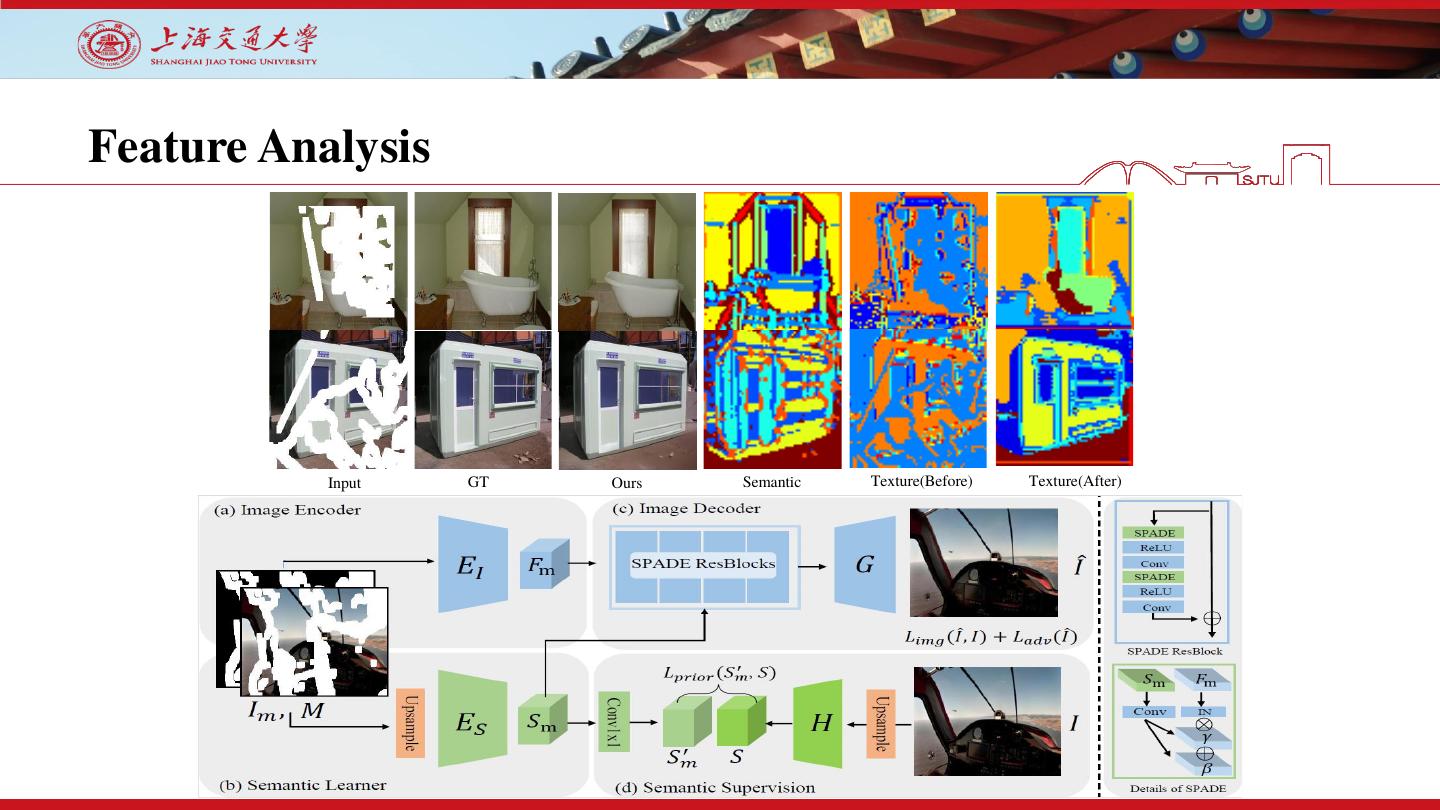
20 .Feature Analysis
We conduct the k-means algorithm
on the learned semantic priors and use
different colors to represent different
clusters.
We can see that the EC model
cannot restore reasonable structures for
complex scenes. Instead, the semantic
priors learned by our method reduce the
context ambiguities and provide explicit
guidance for both global and local
structure restoration
�
21 .Feature Analysis
Input GT Ours Semantic Texture(Before) Texture(After)
�
22 .Future Work
Key Problem:
1. How to (efficiently) extract rich context information from valid pixels.
2. How to reduce the context ambiguities in missing regions.
Future:
1. High-level semantic information can help image inpainting to what extend?
2. What about other low-level vision tasks?
3. Can low-level unsupervised learning incorporate with high-level unsupervised
learning
�
23 .Future Work
Future:
1. High-level semantic information can help image inpainting to what extend?
Cup, location, color ….
Table, location, color ….
……..
2. What about other low-level vision tasks?
3. Can low-level vision task incorporates with high-level task. Visiting the Invisible, IJCV’21
�