展开查看详情
2 .多模态视听融合的视觉显著性预测模型研究
朱丹丹
上海交通大学人工智能研究院
2021.11.12
�
4 . 研究方向
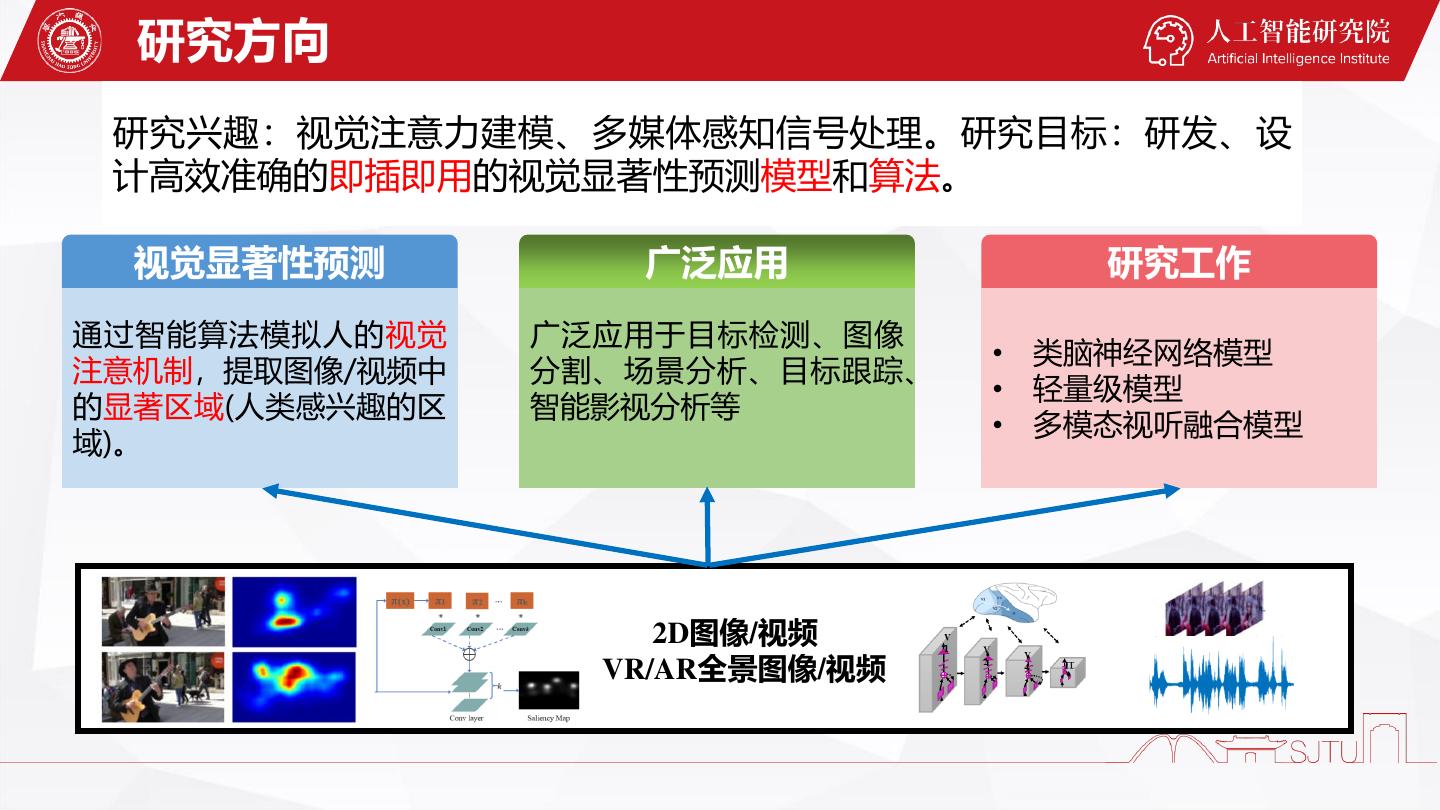
研究兴趣:视觉注意力建模、多媒体感知信号处理。研究目标:研发、设
计高效准确的即插即用的视觉显著性预测模型和算法。
视觉显著性预测 广泛应用 研究工作
通过智能算法模拟人的视觉 广泛应用于目标检测、图像
• 类脑神经网络模型
注意机制,提取图像/视频中 分割、场景分析、目标跟踪、
• 轻量级模型
的显著区域(人类感兴趣的区 智能影视分析等
• 多模态视听融合模型
域)。
2D图像/视频
VR/AR全景图像/视频
�
6 . 研究工作(一)
➢ 基于时空视听(Visual-Audio)融合的显著性预测模型
✓ 关键问题:视觉和听觉是人类从外界获取信息的主要来源,而多媒体系统(电影、手机短视频)
也通常包含视频和音频, 但当前的多媒体处理技术大多只聚焦于单一模态的信号,而忽略了音视
频多模态信号之间的相互影响。
✓ 创新方案:提出了一种时空视听显著性预测网络,该网络同时结合视觉和听觉特征,能够较好的
解决视频中的视觉注视点估计的问题。
同时考虑视觉、音频特征和只考虑视觉特征的效果对比图
�
7 . 研究工作(一)
➢ 基于时空视听(Visual-Audio)融合的显著性预测模型
✓ 模型结构:该模型是由时空视觉显著性估计模块、音频特征提取模块、声源定位模块和视听显著
性融合模块组成。
�
8 . 研究工作(一)
➢ 基于时空视听(Visual-Audio)融合的显著性预测模型
✓ 时空视觉显著性估计模块:由带有双向ConvLSTM的RFB(Receptive Field Block)模块构成。具体地,
使用改进的VGG16(将fc6和fc7转化为卷积层,移除fc8层)提取空间特征,然后送入双向ConvLSTM
单元学习时空特征。
(1)RFB模块:增强空间特征的表示能力;由两部分组成,第一部分是由不同卷积核大小的多分支
卷积层构成,第二部分是由具有不同dilation rates的膨胀卷积构成。
�
9 . 研究工作(一)
➢ 基于时空视听(Visual-Audio)融合的显著性预测模型
(2)双向ConvLSTM:由于单向ConvLSTM没有信息交换能力,更深层次的时空特征不能有效提取。
我们设计的双向ConvLSTM是通过级联、紧密连接的方式实现的。具体的,它是由两ConvLSTM
单元构成:前向、浅层和反向、深层。 我们将从RFB模块得到的特征送入前向ConvLSTM单元,
𝑓 𝑓 𝑓
𝑖𝑡 、𝑓𝑡 、𝑜𝑡 分别表示输入门、遗忘门和输出门。 ∗表示卷积操作,º表示哈达玛乘积操作,σ表示
sigmoid激活函数。ω表示学习参数,Ψ是偏置项。
�
10 . 研究工作(一)
➢ 基于时空视听(Visual-Audio)融合的显著性预测模型
由于前向ConvLSTM只能处理和记住过去序列的信息,但反向序列的信息对于预测视频显著性也非
常重要。因此,我们增加了反向ConvLSTM单元用来捕获双向时空特征。最后,将得到的前向时空特征
和反向时空特征融合得到最终深层的时空视觉特征:
𝑓𝑡𝑣 ∈ 𝑅28×28×28 表示最终深层的时空视觉特征。
(3)音频特征提取模块
a) 使用一个可分离卷积网络分别提取时域(time)和频域(frequency)的音频特征并将其进行融合;
b) 利用3种音频特征提取技术提取梅尔频率倒谱系数(MFCC),伽玛频率倒谱系数(GFCC)和常数
Q变换(CQT);
�
11 . 研究工作(一)
➢ 基于时空视听(Visual-Audio)融合的显著性预测模型
(3)音频特征提取模块
c) 可分离卷积网络由5个block组成,即Conv2D-Conv2D-Conv2D-Maxpool-BatchNorm。其中1×m
表示频域上的卷积核,n×1表示时域上的卷积核;
d) 可分离卷积网络可以显著地减少参数量,大大的提高运行速度。
�
12 . 研究工作(一)
➢ 基于时空视听(Visual-Audio)融合的显著性预测模型
(4)声源定位模块:引入DCCA(Deep Canonical Correlation Analysis)模块检索时空视觉特征和音频特
征之间的对应关系,这可以被看作一个空间声源定位问题。
a) 首先使用仿射变换将时空视觉特征和音频特征映射到
同一特征空间:
𝑧 𝑎 和𝑧 𝑣 表示的是变换的音频特征和时空视觉特征。
𝜗 𝑎 ,𝜗 𝑣 ,𝑏𝑎 ,𝑏 𝑣 表示仿射变换的系数。
DCCA的结构图
�
13 . 研究工作(一)
➢ 基于时空视听(Visual-Audio)融合的显著性预测模型
b) 我们将时空视觉特征和音频特征送入DCCA的三层卷积层中,分别获得f(𝑧 𝑎 , 𝜃1 )和f(𝑧 𝑣 , 𝜃2 );
c) DCCA的目标是最大化f(𝑧 𝑎 , 𝜃1 )和f(𝑧 𝑣 , 𝜃2 )的相关性:
其中𝐶𝑎𝑎 和𝐶𝑣𝑣 表示音频特征和时空视觉特征的协方差矩阵,𝐶𝑎𝑣 表示音频特征和时空视觉特征的互
协方差矩阵。
d) 通过相关性计算后,我们可以获得localization map(与音频和视觉信息流都有关)—spatial-temporal
auditory saliency map.
�
14 . 研究工作(一)
➢ 基于时空视听(Visual-Audio)融合的显著性预测模型
(5)视听显著性融合:使用线性加权融合的方法将时空视觉显著图与音频显著图进行融合获得最终
视听显著图:
其中𝜔𝑎 和𝜔𝑣 表示音频和时空视觉显著图的训练参数,𝑆 𝑎𝑣 表示最终视听的显著图。
�
15 . 研究工作(一)
➢ 基于时空视听(Visual-Audio)融合的显著性预测模型
✓ 实验分析
• 数据集:ETMD,AVAD, DIEM,Coutrot1,Coutrot2,SumMe;这些数据集包含动态自然场
景、user-made videos、电影等;
• 评价标准:normalized scanpath saliency (NSS), similarity metric (SIM), linear correlation
coefficient (CC), AUC-Judd (AUC-J) and shuffled AUC (s-AUC) ;
• 性能比较:比较的方法包括DINet、DVA、vavdvsm、SALICON、SalGAN、SAM、TBA、
Deepvs、ACLNet、TASED、SalEMA;前7种方法是静态图像的显著性预防方法,后3种是
视频的显著性预测方法。
�
16 . 研究工作(一)
➢ 基于时空视听(Visual-Audio)融合的显著性预测模型
✓ 实验分析
• 定性比较:
➢
我们的
结果
�
17 . 研究成果(四)
➢ 基于时空视听(Visual-Audio)融合的显著性预测模型
✓ Demo视频1:
�
18 . 研究成果(四)
➢ 基于时空视听(Visual-Audio)融合的显著性预测模型
✓ Demo视频2:
�
19 . 研究工作(一)
➢ 基于时空视听(Visual-Audio)融合的显著性预测模型
✓ 实验分析
• 定量比较:
➢
我们的
结果
在Coutrot1、Coutrot2和AVAD数据集上的定量比较
�
20 . 研究工作(一)
➢ 基于时空视听(Visual-Audio)融合的显著性预测模型
✓ 实验分析
• 定量比较:
➢
我们的
结果
在ETMD、SumMe和DIEM数据集上的定量比较
�
21 . 研究工作(一)
➢ 基于时空视听(Visual-Audio)融合的显著性预测模型
✓ 实验分析
• 消融分析: RFB、双向ConvLSTM、声源定位模块
�
22 . 研究工作(一)
➢ 基于时空视听(Visual-Audio)融合的显著性预测模型
✓ 实验分析
• 消融分析: RFB、双向ConvLSTM、声源定位模块
w/ & w/o RFB模块的定性比较 w/ & w/o音频特征表示模块的定性比较
w/ & w/o声源定位模块的定性比较 w/ & w/o双向ConvLSTM模块的定性比较
�
23 . 研究成果(一)
➢ 应用实践:将时空视听融合的显著性预测模型应用到智能观影分析系统
影视亮点分析
分析影视内容,预测内容热点,辅助后期制作,
降低宣发成本
• 影视热点分析(空间域、时间域、音视频
热点)
• 预告片及精彩片段自动化生成
• 基于视觉注意的智能广告植入
影视热点分析(空间域)
智能电影预告片
生成及精彩片段
剪辑
基于视觉注意
的智能广告植
影视热点分析(时间域)
入
�
24 . 研究工作(二)
➢ 多模态感知:基于全景视频的视觉显著性预测模型
✓ 关键问题:空间音频是全景视频(ODV)的重要组成部分,它可以通过让观众感知各个方向的声音
提供身临其境的体验。但目前大多数对ODV的视觉注意力建模仅关注视觉信息,很少考虑音频信
息。此外,已有的ODV视听显著性预测模型缺乏空间音频位置感知(sound source location-
agnostic)和音频内容属性可判别性(audio content attributes-agnostic)。
✓ 创新方案:提出一种具有空间音频位置感知和音频内容属性自适应的视听感知显著性预测模型,
从而能够较好地解决ODV中的视觉注视点预测问题。
�
25 . 研究工作(二)
➢ 多模态感知:基于全景视频的视觉显著性预测模型
✓ 模型结构:由时空视觉特征提取模块、空间音频定位模块、空间音频特征表示模块和视听特征融
合模块组成。
�
26 . 研究工作(二)
➢ 多模态感知:基于全景视频的视觉显著性预测模型
✓ 时空视觉特征提取模块
◆ 由带有E3D-LSTM(eidetic 3D LSTM)的p4-ResNet50(将ResNet50中的每一个卷积层替换为p4-
convolution)组成;
◆ p4-ResNet50可以利用群等变性(旋转不变性)处理将球面图像投影到2D平面上的投影失真问题;
◆ E3D-LSTM能够较好地捕获短期帧依赖(表象特征、运动特征)和长期高层次关系(加入自注意力机
制)。
�
27 . 研究工作(二)
➢ 多模态感知:基于全景视频的视觉显著性预测模型
✓ 空间音频定位模块
◆ 空间音频(环绕声)可以让观众在全景场景中全方位地体验声音并实时调整音频以匹配观看位置;
◆ 环绕声是一个球面坐标系下的音频信号,我们使用球谐分解使音频在2D平面展开形成一个能量谱。
假设音频信号f(𝜑, λ, t)在时刻t和方向𝜃 ‘ =(𝜑, λ)上,我们可以用 N 阶截断球谐展开来表示音频信号:
其中𝜑和λ分别表示纬度和经度。∅𝑚
𝑛 表示展开系数,𝑌𝑛 表示在阶数为n度数为m时的球谐函数。
𝑚
�
28 . 研究工作(二)
➢ 多模态感知:基于全景视频的视觉显著性预测模型
✓ 空间音频定位模块
为了简化表示,我们将∅𝑚
𝑛 和𝑌𝑛 叠加成向量∅𝑁 和𝑌𝑁 ,音频信号可以表示如下:
𝑚
在实际的全景场景中,给定l 个音频信号,具体的实现过程如下:
∅𝑁 表示𝐴𝑚𝑏𝑖𝑠𝑜𝑛𝑖𝑐𝑠通道,在我们的工作中𝑁设置为4。
�
29 . 研究工作(二)
➢ 多模态感知:基于全景视频的视觉显著性预测模型
✓ 空间音频定位模块
◆ 计算每帧AEM(audio energy map)。AEM可以表示为在时间间隔[𝑡0 , 𝑡0 + 𝑇]内沿着方向𝜃ˆ的声场能量:
在实践中,AEM被可视化为每帧上的热力图,颜色越深表示相应位置的音频能量越高。
�