



















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
人工智能产业讲坛第三期:基于OpenVINO的前端开发
如今,机器学习(尤其是深度学习)变得越来越重要,并广泛应用于许多应用程序中,例如计算机视觉,语音识别,噪声消除。随着对机器学习工作负载的计算需求呈指数级增长,硬件体系结构的创新正在飞速发展,大量新的专用机器学习加速器正在涌现,例如NPU,VPU和DSP。这些专用的加速器不仅有助于优化性能,而且降低功耗。
OpenVINO是英特尔基于自身现有的硬件平台开发的一款可以加快高性能计算机视觉和深度学习视觉应用开发速度工具的套件。Web 是最普遍存在的开放计算平台,凭借 HTML5 标准的普及,Web 应用程序能够使用 HTML5 视频标签播放在线视频,通过 WebRTC API 捕获网络摄像头视频,Web 开发人员可以借助 JavaScript 实现各种图像和视觉处理算法,但是无法利用专用的硬件来加速性能和降低功耗。WebNN就是为了解决浏览器运用能利用专用的机器学习硬件来加速推演和降低功耗,我们已经在Chromium浏览器中实现了原型,对MobileNet用FP32精度推演可以比Wasm提高8倍性能,量化模型后可以提高16倍性能。
付俊伟,英特尔软件工程师,负责W3C Web machine Learning 标准的实现
展开查看详情
1 .Machine Learning on Web with OpenVINO Team – Junwei, Ningxin, Belem
2 .Agenda 机器学习的运用场景 前端 JavaScript ML 的演进与问题 OpenVINO overview • OpenVINO工作流程 • Inference Engine推理引擎 • NGraph core Solution Architecture • WebNN架构 • 编程接口 Standards and Developer Insights • Update on WebNN Spec Demo / Workload
3 .运用场景 无人超市 Zoom 视频会议 物体检测,人脸识别 背景去除,背景替换,实时字幕,声音降噪
4 .前端 JavaScript ML 的优势 延迟 成本 客服端的计算意味着不需要服务 访问本地资源的浏览器推理 器算力的支持 可用性 共享 初始资源缓存并离线后,不再需 在浏览中运行,不需要额外安装, 要依赖网络 易于使用 隐私 跨平台 数据在本地 可以在所有平台上运行
5 .前端 JavaScript ML 框架的挑战 性能 设备中的机器学习推理需要高性能的计算能力 Wasm WebGL
6 .The JS ML frameworks and AI Web apps AI Features of Object Semantic Speech Noise Web Apps Detection Segmentation Recognition Suppression JS ML Frameworks ONNX.js TensorFlow.js Paddle.js OpenCV.js Web Browser WebAssembly WebGL/WebGPU Hardware CPU GPU
7 .The purpose-built ML hardware AI Features of Object Semantic Speech Noise Web Apps Detection Segmentation Recognition Suppression JS ML Frameworks ONNX.js TensorFlow.js Paddle.js OpenCV.js Web Browser WebAssembly WebGL/WebGPU Hardware CPU ML Ext. GPU ML Ext. NPU VPU DSP
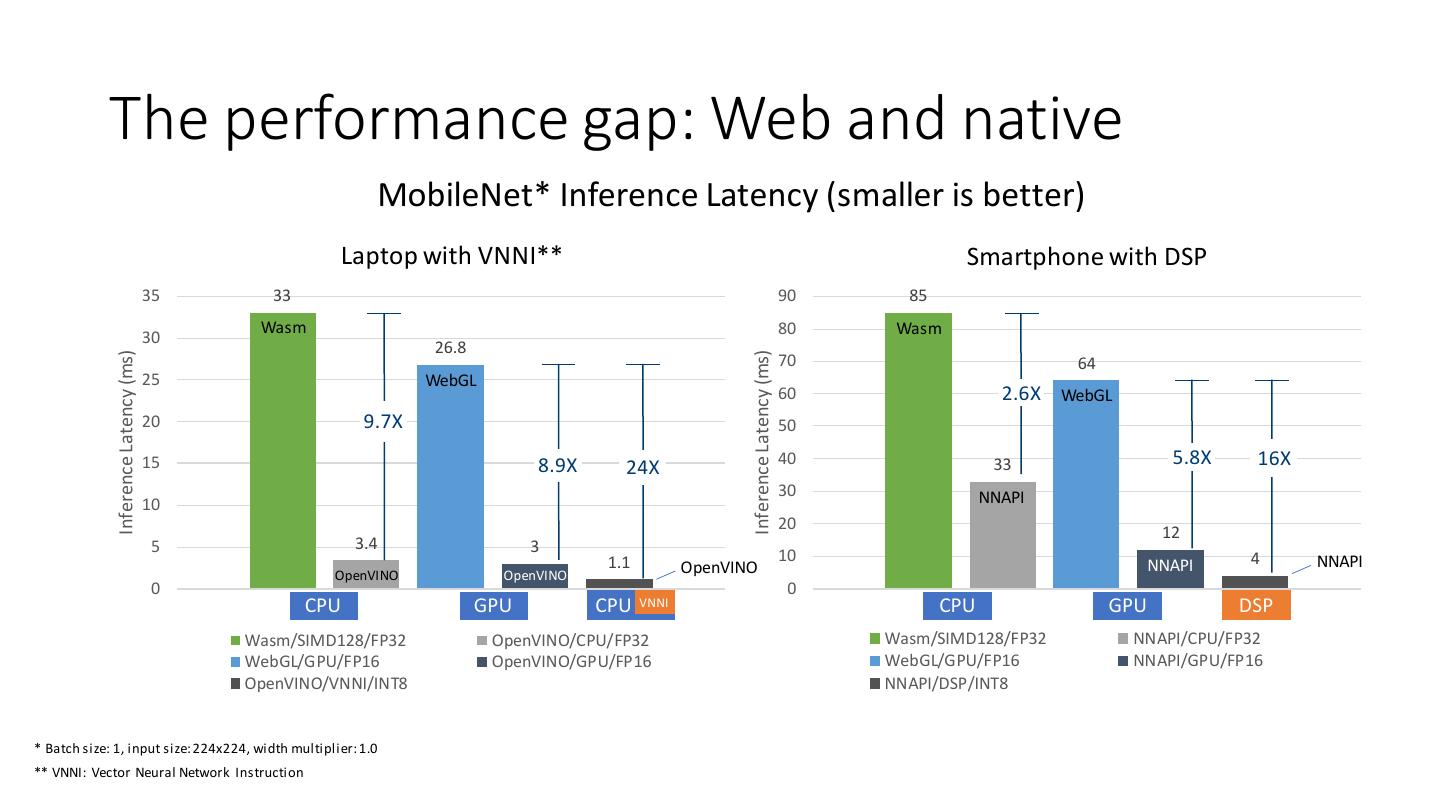
8 . The performance gap: Web and native MobileNet* Inference Latency (smaller is better) Laptop with VNNI** Smartphone with DSP 35 33 90 85 Wasm 80 Wasm 30 26.8 Inference Latency (ms) Inference Latency (ms) 70 64 25 WebGL 60 2.6X WebGL 20 9.7X 50 15 8.9X 24X 40 33 5.8X 16X 30 NNAPI 10 20 12 5 3.4 3 1.1 10 4 NNAPI OpenVINO NNAPI OpenVINO OpenVINO 0 0 CPU GPU CPU VNNI CPU GPU DSP Wasm/SIMD128/FP32 OpenVINO/CPU/FP32 Wasm/SIMD128/FP32 NNAPI/CPU/FP32 WebGL/GPU/FP16 OpenVINO/GPU/FP16 WebGL/GPU/FP16 NNAPI/GPU/FP16 OpenVINO/VNNI/INT8 NNAPI/DSP/INT8 * Batch size: 1, input size: 224x224, width multiplier: 1.0 ** VNNI: Vector Neural Network Instruction
9 .The Web is disconnected from ML hardware AI Features of Object Semantic Speech Noise Web Apps Detection Segmentation Recognition Suppression JS ML Frameworks ONNX.js TensorFlow.js Paddle.js OpenCV.js Web Browser WebAssembly WebGL/WebGPU ? Hardware CPU ML Ext. GPU ML Ext. NPU VPU DSP
10 .WebNN: the architecture view ONNX Models TensorFlow Models Other Models Web App JS ML frameworks TensorFlow.js, ONNX.js etc., Web Browser WebGL/WebGPU WebNN WebAssembly ML Compute DirectML NN API OpenVINO Native ML API macOS/iOS Windows Android Linux/Windows ML Ext. ML Ext. Hardware CPU GPU ML Accelerators
11 . OpenVINO Overview • 开发高性能深度学习(计算机视觉,音频降噪,语言识别)的工具 • 模型优化器将模型转换为中间表示(IR)。这些文件描述了网络拓扑,并包括权重和偏差数据。 Step 4: deploy Step 1: Select a Model Step 2: Generator IR Step 3: Inference Find or Train a Run Model Run Inference Integrate to Optimizer model convert Acceptable? application Model Engine on model Modify the model Try advanced tuning of post-training the IR model Work? Work?
12 .Inference Engine • OpenVINO中很重要的组件, 用来对输入数据在CPU, GPU, VPU, GNA 等硬件上推演结 果 • C++是主要的实现语言,支持C和Python接口
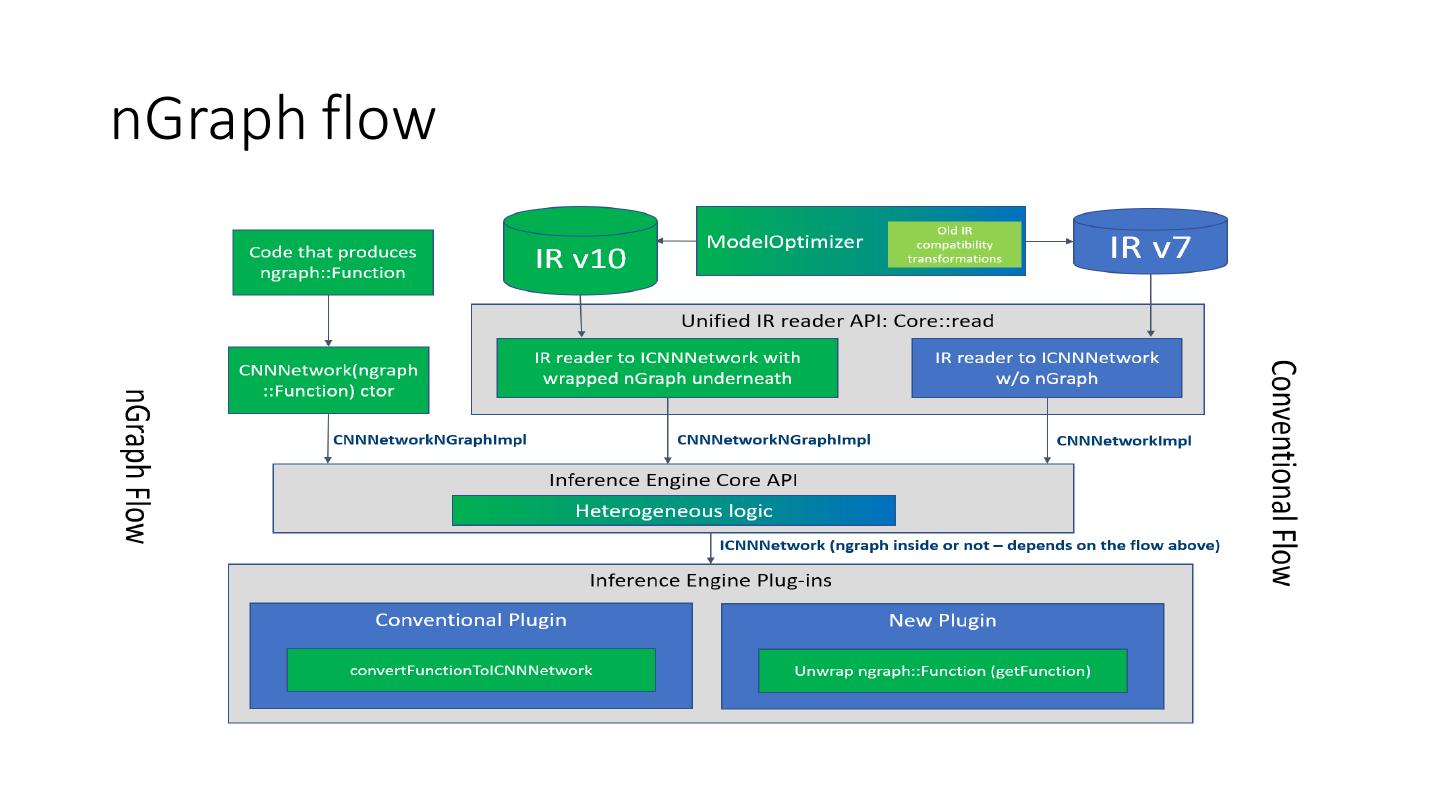
13 .nGraph flow
14 .nGraph API #include "ngraph/opsets/opset.hpp" #include "ngraph/opsets/opset1.hpp" using namespace std; using namespace ngraph; auto arg0 = make_shared<opset1::Parameter>(element::f32, Shape{7}); auto arg1 = make_shared<opset1::Parameter>(element::f32, Shape{7}); // Create an 'Add' operation with two inputs 'arg0' and 'arg1' auto add0 = make_shared<opset1::Add>(arg0, arg1); // Run shape inference on the nodes NodeVector ops{arg0, arg1, add0}; validate_nodes_and_infer_types(ops); // Create a graph with one output (add0) and four inputs (arg0, arg1) auto ng_function = make_shared<Function>(OutputVector{add0}, ParameterVector{arg0, arg1}); CNNNetwork net (ng_function);
15 .WebNN: the programming model
16 . Integrate Inference Engine to WebNN • 在创建模型的时候,通过WebNN定义好的操作数来构造Graph • 转化创建好的Graph到plugin可以执行的Neural Network
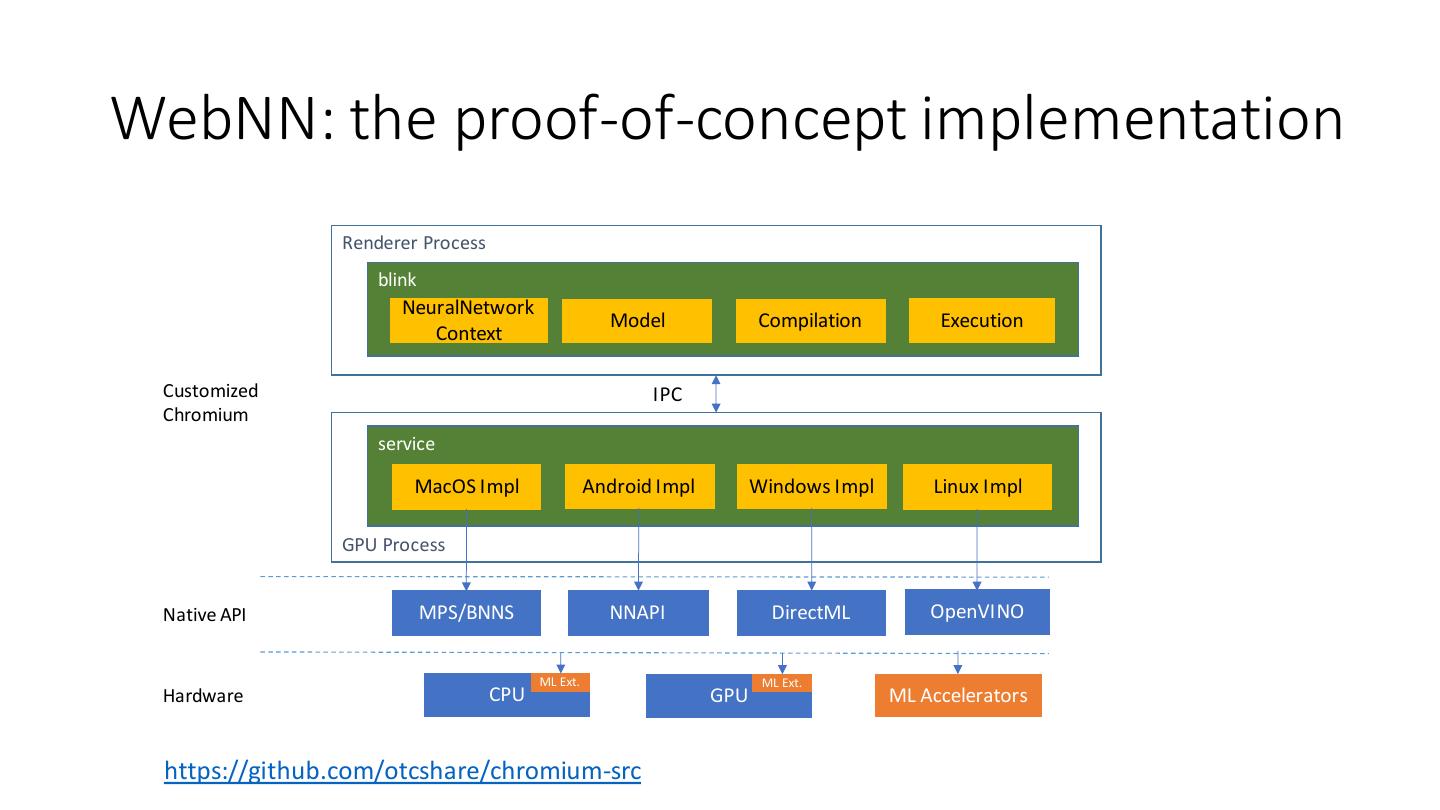
17 .WebNN: the proof-of-concept implementation Renderer Process blink NeuralNetwork Model Compilation Execution Context Customized IPC Chromium service MacOS Impl Android Impl Windows Impl Linux Impl GPU Process Native API MPS/BNNS NNAPI DirectML OpenVINO ML Ext. ML Ext. Hardware CPU GPU ML Accelerators https://github.com/otcshare/chromium-src
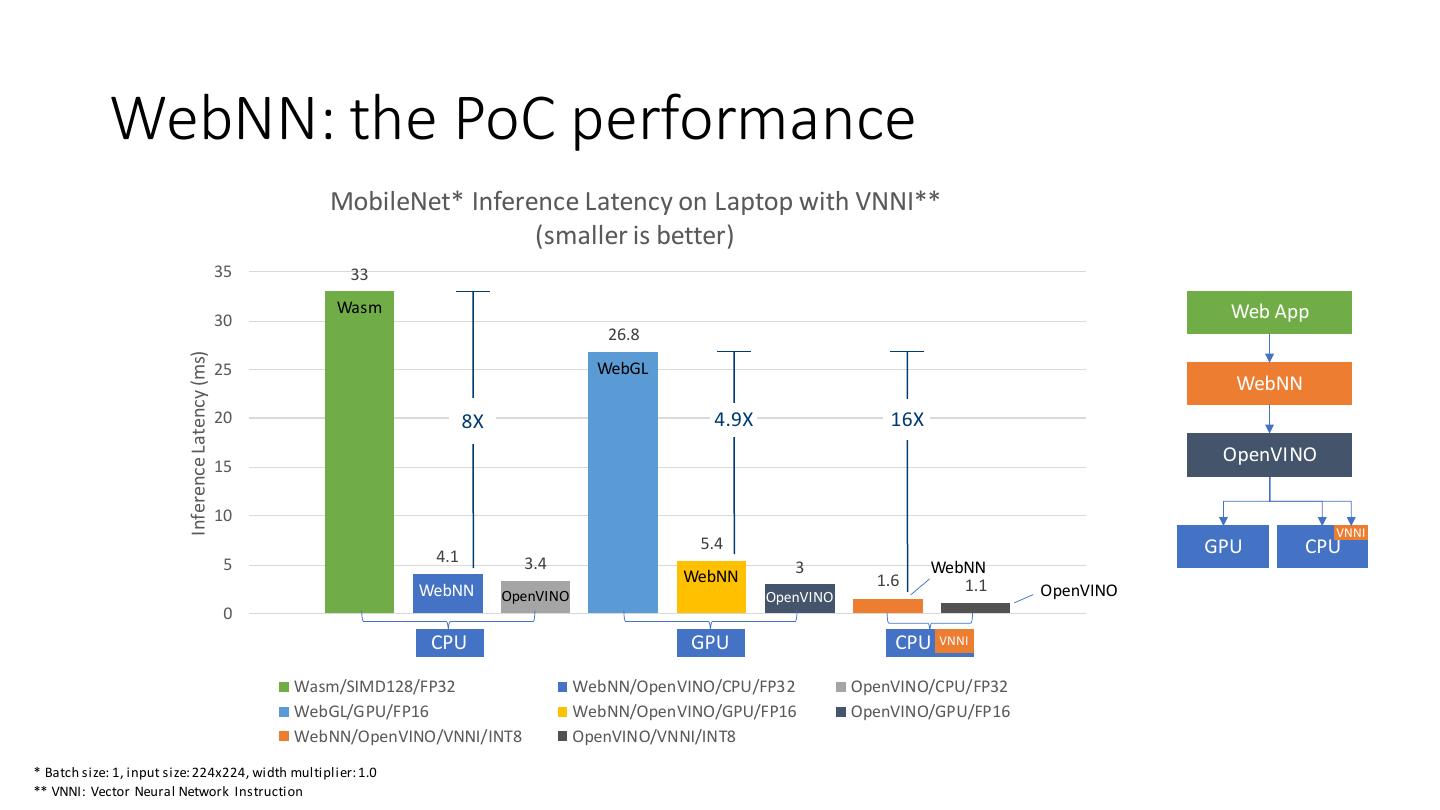
18 . WebNN: the PoC performance MobileNet* Inference Latency on Laptop with VNNI** (smaller is better) 35 33 Wasm Web App 30 26.8 Inference Latency (ms) 25 WebGL WebNN 20 8X 4.9X 16X OpenVINO 15 10 VNNI 5.4 GPU CPU 5 4.1 3.4 3 WebNN WebNN 1.6 WebNN 1.1 OpenVINO OpenVINO OpenVINO 0 CPU GPU CPU VNNI Wasm/SIMD128/FP32 WebNN/OpenVINO/CPU/FP32 OpenVINO/CPU/FP32 WebGL/GPU/FP16 WebNN/OpenVINO/GPU/FP16 OpenVINO/GPU/FP16 WebNN/OpenVINO/VNNI/INT8 OpenVINO/VNNI/INT8 * Batch size: 1, input size: 224x224, width multiplier: 1.0 ** VNNI: Vector Neural Network Instruction
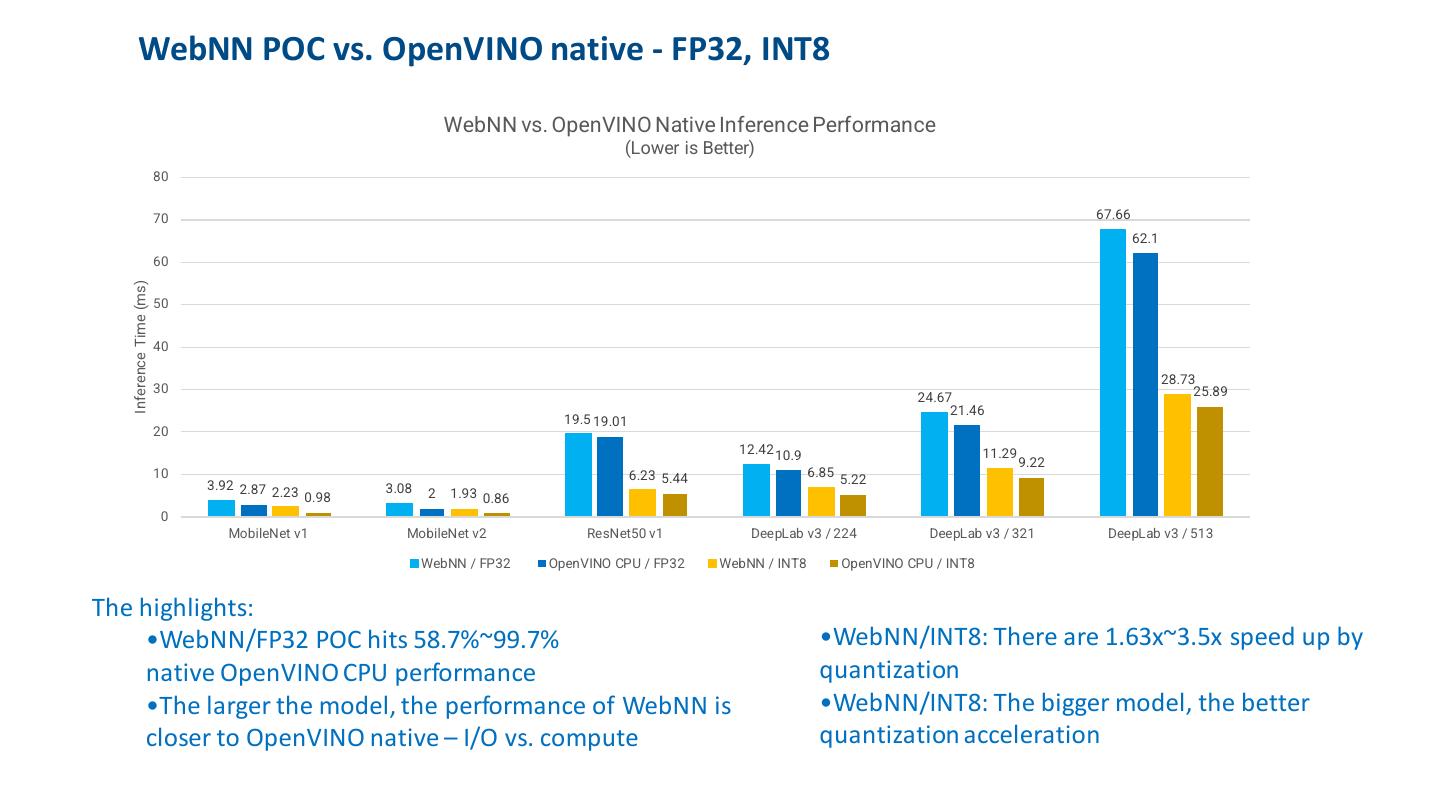
19 . WebNN POC vs. OpenVINO native - FP32, INT8 WebNN vs. OpenVINO Native Inference Performance (Lower is Better) 80 70 67.66 62.1 60 Inference Time (ms) 50 40 28.73 30 25.89 24.67 21.46 19.5 19.01 20 12.42 10.9 11.29 9.22 10 6.23 5.44 6.85 3.92 2.87 5.22 2.23 0.98 3.08 2 1.93 0.86 0 MobileNet v1 MobileNet v2 ResNet50 v1 DeepLab v3 / 224 DeepLab v3 / 321 DeepLab v3 / 513 WebNN / FP32 OpenVINO CPU / FP32 WebNN / INT8 OpenVINO CPU / INT8 The highlights: •WebNN/FP32 POC hits 58.7%~99.7% •WebNN/INT8: There are 1.63x~3.5x speed up by native OpenVINO CPU performance quantization •The larger the model, the performance of WebNN is •WebNN/INT8: The bigger model, the better closer to OpenVINO native – I/O vs. compute quantization acceleration
20 .Case Study: Conv2D on Web Wasm vs. WebNN WebAssembly: WebNN: DL specific primitives general purpose primitives for (int batch = 0; batch < batches; ++batch) { for (int out_y = 0; out_y < output_height; ++out_y) { // define the graph for (int out_x = 0; out_x < output_width; ++out_x) { Const builder = new MLGraphBuilder(context); for (int out_channel = 0; out_channel < output_depth; ++out_channel) { const int in_x_origin = (out_x * stride_width) - pad_width; const input = builder.input(float32TensorType); const int in_y_origin = (out_y * stride_height) - pad_height; const filter = builder.constant(float32TensorType, filterData); float total = 0.f; for (int filter_y = 0; filter_y < filter_height; ++filter_y) { const output = builder.conv2d(input, filter); for (int filter_x = 0; filter_x < filter_width; ++filter_x) { for (int in_channel = 0; in_channel < input_depth; ++in_channel) { const graph = await builder.build([output]); const int in_x = in_x_origin + dilation_width_factor * filter_x; // execute the graph const int in_y = in_y_origin + dilation_height_factor * filter_y; const outputs = await graph.compute(‘fast-answer’); // If the location is outside the bounds of the input image, // use zero as a default value. if ((in_x >= 0) && (in_x < input_width) && (in_y >= 0) && (in_y < input_height)) { float input_value = input_data[Offset( input_shape, batch, in_y, in_x, in_channel)]; float filter_value = filter_data[Offset(filter_shape, out_channel, filter_y, filter_x, in_channel)]; filter total += (input_value * filter_value); } conv2d } } output } x float bias_value = 0.0f; if (bias_data) { bias_value = bias_data[out_channel]; } output_data[Offset(output_shape, batch, out_y, out_x, out_channel)] = ActivationFunctionWithMinMax(total + bias_value, input constant output Operation output_activation_min, output_activation_max); } } } } Live coding: https://webmachinelearning.github.io/webnn-samples/code/
21 .WebNN Status • 成立W3C Web Machine Learning 工作组 • 支持了第一批模型 • SqueezeNet, MobileNet, ResNet, TinyYOLO, RNNoise, NSNet • 定义了51ops (as Mar. 2021) • 41 语言级别的操作数 • Tensor ops: conv2d, matmul, poolings etc., • Element-wise binary and unary: add/sub/mul/div/exp/log etc., • Activations: clamp, relu, sigmoid, tanh etc., • Reduction ops: reduceMin/Max/Mean/Sum/Product etc., • Layout: concat, reshape, transpose, slice etc., • 10 高级别的操作数,可以由语言级别的操作数组成 • gemm, gruCell, gru, batchNormalization, instanceNormalization, softmax etc.,
22 .WebNN: demos WebNN 语义分割 https://intel.github.io/webml-polyfill/examples/image_classification
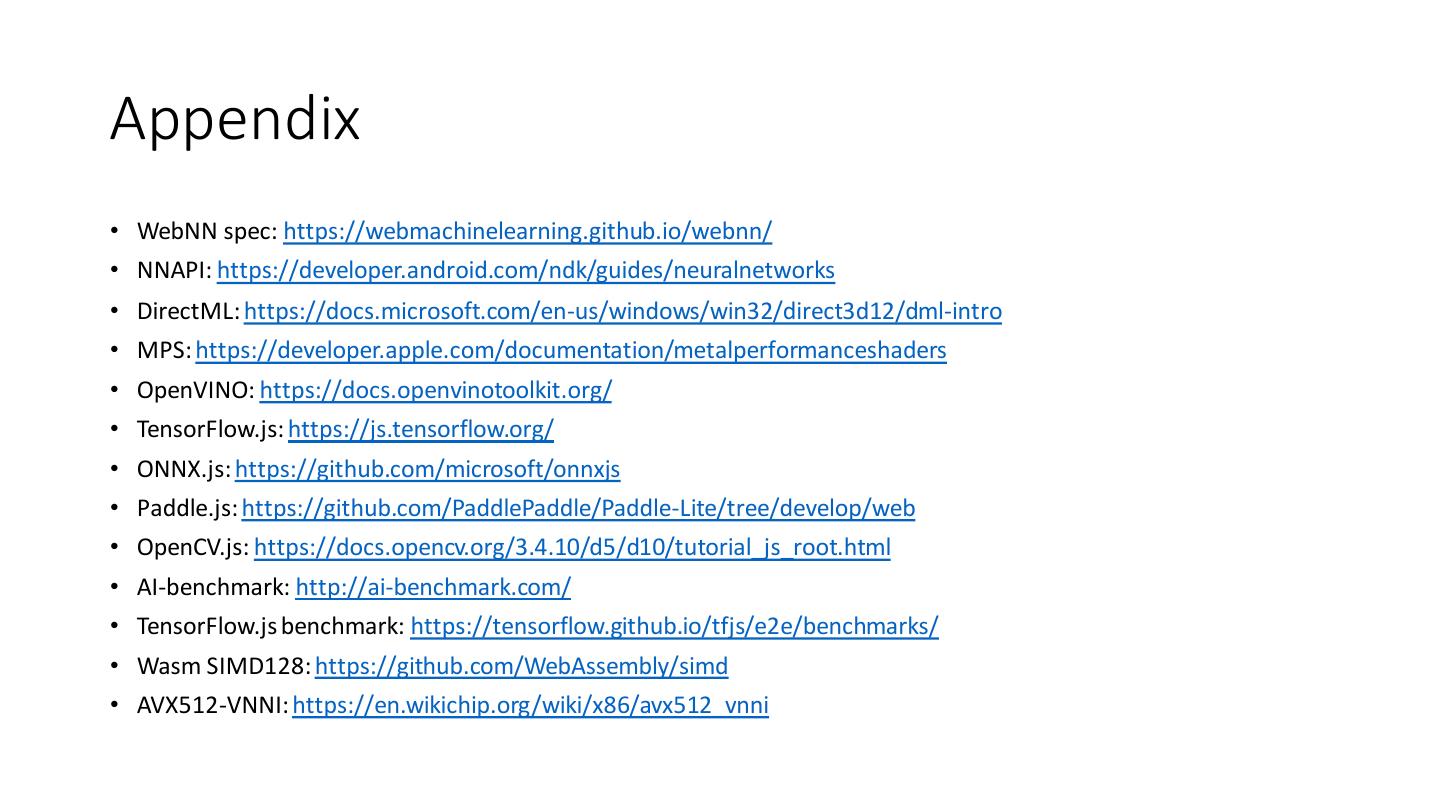
23 .Appendix • WebNN spec: https://webmachinelearning.github.io/webnn/ • NNAPI: https://developer.android.com/ndk/guides/neuralnetworks • DirectML: https://docs.microsoft.com/en-us/windows/win32/direct3d12/dml-intro • MPS: https://developer.apple.com/documentation/metalperformanceshaders • OpenVINO: https://docs.openvinotoolkit.org/ • TensorFlow.js: https://js.tensorflow.org/ • ONNX.js: https://github.com/microsoft/onnxjs • Paddle.js: https://github.com/PaddlePaddle/Paddle-Lite/tree/develop/web • OpenCV.js: https://docs.opencv.org/3.4.10/d5/d10/tutorial_js_root.html • AI-benchmark: http://ai-benchmark.com/ • TensorFlow.js benchmark: https://tensorflow.github.io/tfjs/e2e/benchmarks/ • Wasm SIMD128: https://github.com/WebAssembly/simd • AVX512-VNNI: https://en.wikichip.org/wiki/x86/avx512_vnni
24 .Thanks
3秒后跳转登录页面
去登陆

