

























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
4.使用Ray作为Spark SQL UDF的执行引擎-祝威廉
使用Ray作为Spark SQL UDF的执行引擎-祝威廉
这次分享我们会重点介绍如何基于Ray使用Python实现Spark SQL UDF函数,进一步的,我们使用该技术实现有状态的UDF函数,从而能够将常见的Python算法模型转换成 SQL UDF函数进而被更广泛的使用。利用Ray强大的分布式编程能力,我们完美解决算法模型包装成SQL函数面临的两大难题,1. 函数需要一个初始化过程,2. 函数有一定的python环境要求。
祝威廉 现就职于Kyligence,资深数据架构师,拥有10+年研发经验。最近六年专注于数据管理,商业分析,机器学习的统一平台的设计和开发。个人热衷于开源产品的设计和研发,MLSQL(mlsql.tech)为其主要开源作品。
展开查看详情
1 .使用Ray 作为Spark SQL UDF的执行引擎 祝威廉 Kyligence
2 . u MLSQL 是怎么支持Python的 Agenda u 为什么要整合Ray u 整合Ray的两种模式 u 如何使用Ray作为UDF执行引擎
3 .MLSQL 是如何支持Python的 1. MLSQL 语法扩展插件,能 够执行Python代码 2. Python在MLSQL中作为文 本片段存在 3. Python是沙箱,输入输出 都必须是表,我们提供了API供 交互 © Kyligence Inc. 2021, Confidential.
4 .MLSQL对应到后端代码层面-PyJava原理 Python Daemo Python n Worker Java Executor Python Daemo Python n Worker 1. Python Deamon主要由Python版本+ 环境变量决定 2. Python Worker 由Python Daemon管理 3. 双方主要通过输入输出流进行数据交换 4. 数据传输格式为Arrow © Kyligence Inc. 2021, Confidential.
5 .现有模式的局限 Node 1 Python 1. Python / Java 混合部署,互相干扰,难以隔 Daemo Python n Worker Java 离,运维困难(Python环境需要多份) Executor 2. 无法实现GPU等多种资源的调度 Python Daemo Python 3. 不同Python Worker无法实现交互互通 n Worker 4. 基于这套架构使用Python实现一个简单的PS结 构都难以做到,不具备分布式编程能力,仅能进行 Node 2 Python 分布式数据处理。 Daemo Python n Worker Java Executor Python Daemo Python n Worker © Kyligence Inc. 2021, Confidential.
6 .怎么办? 引入Ray! © Kyligence Inc. 2021, Confidential.
7 .新模式 Ray Client 角色转换,只负责提交代码,真实任务在Ray集群执行 一个Python Deamon对应 无需安装如Tensorflow,Pytorch等机器学习库 一套不同Python环境 Node N Python Daemo Python n Worker 1. Ray 支持真正的Python分布式编程,能 Java Executor 力强大 2. 多Ray集群,用户可以选择连接不同 Python Daemo Python Python环境 n Ray Cluster Worker 3. 充分利用Ray的硬件识别和调度能力,如 基于GPU ,CPU,内存进行调度。 © Kyligence Inc. 2021, Confidential.
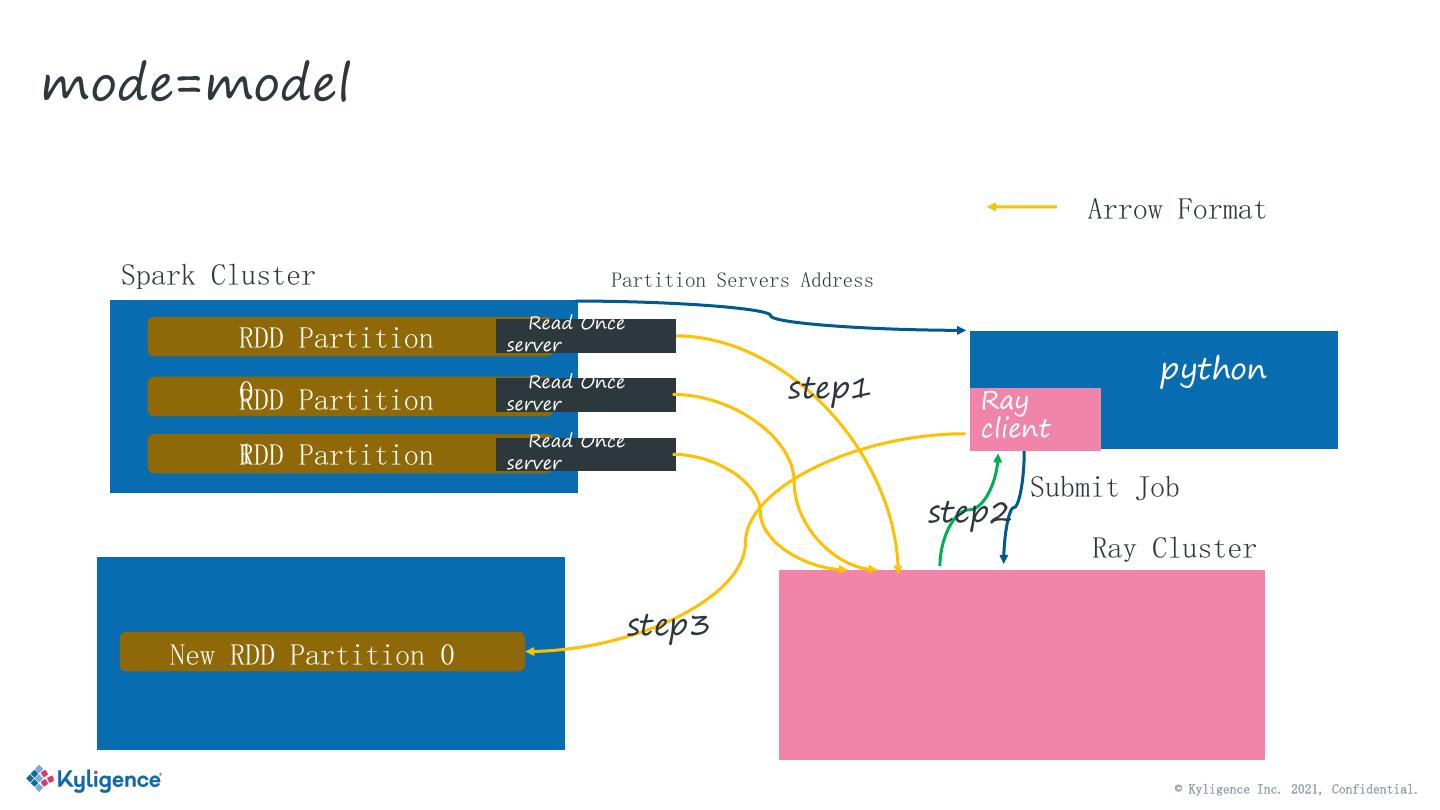
8 .存在两种交互模式 mode=model Ray client 返回数据(机器学习场景) mode=Data Ray client 返回数据地址(ETL场景) © Kyligence Inc. 2021, Confidential.
9 .mode=model Arrow Format Spark Cluster Partition Servers Address Read Once RDD Partition server python 0 Read Once step1 RDD Partition server worker Ray Read Once client 1 RDD Partition server Submit Job 2 step2 Ray Cluster step3 New RDD Partition 0 © Kyligence Inc. 2021, Confidential.
10 .mode=model 对应MLSQL代码 Ray client端会返回数据, 比如模型二进制目录或者路径 © Kyligence Inc. 2021, Confidential.
11 .mode=data Arrow Format Spark Cluster Partition Servers Address Read Once RDD Partition server Read Once python 0 RDD Partition server worker Ray Read Once client 1 RDD Partition server Submit Job 2 Actor Servers Address Ray Cluster New RDD Partition 0 Read Once Actor 0 server New RDD Partition 1 Read Once Actor 1 server New RDD Partition 2 Read Once Actor 2 server © Kyligence Inc. 2021, Confidential.
12 .mode=data 对应MLSQL代码 Ray client端会返回数据地址而非数据 © Kyligence Inc. 2021, Confidential.
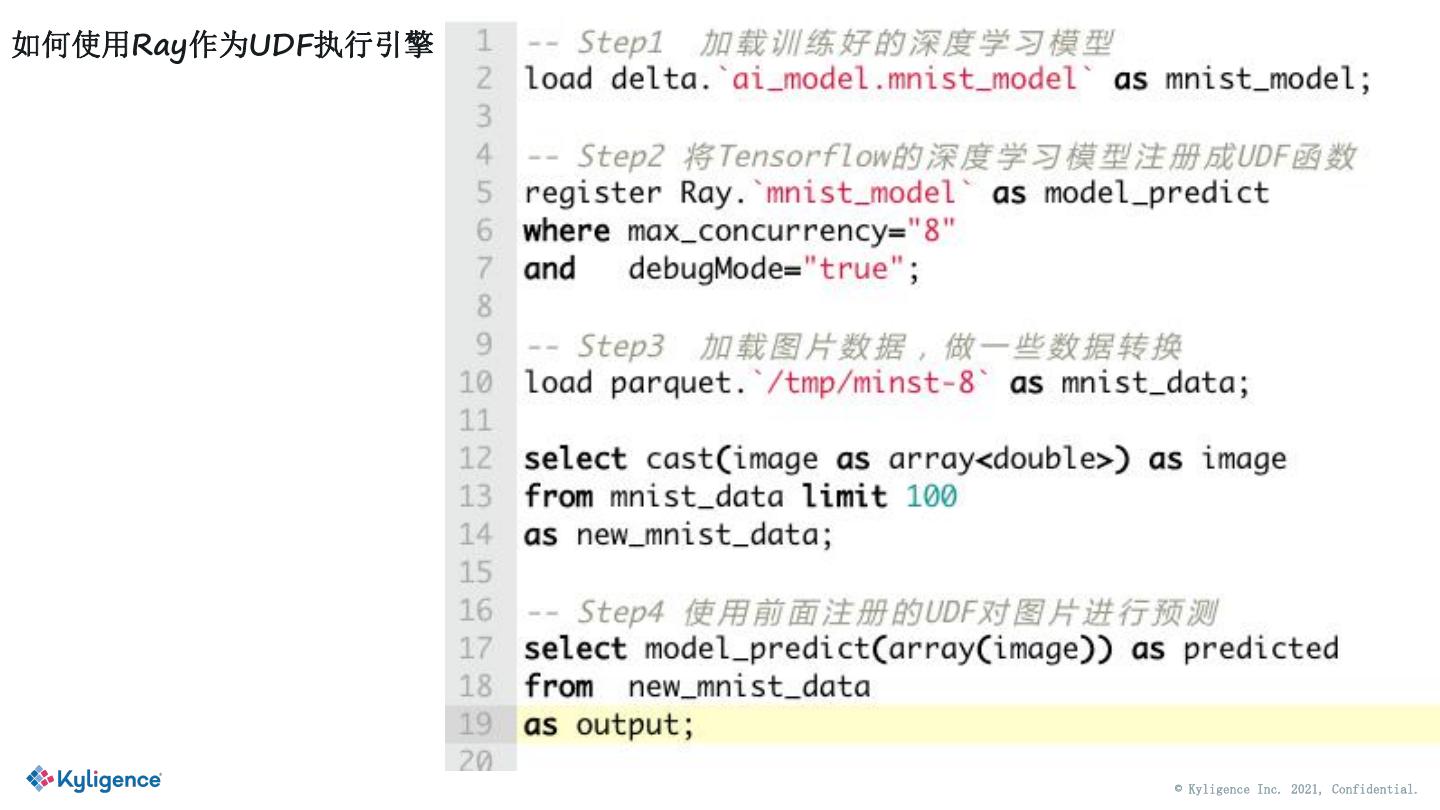
13 .如何使用Ray作为UDF执行引擎 © Kyligence Inc. 2021, Confidential.
14 .如何使用Ray作为UDF执行引擎 © Kyligence Inc. 2021, Confidential.
15 .Python UDF 的几个点 在Java中 执行Python代码 传统做法:先序列化python函数,然后丢到python worker中 执行 无状态UDF函数 MLSQL(PyJava)做法:Python代码直接丢到 python worker 中 加载模型 有状态UDF函数 怎么实现? 使用模型进行预测 © Kyligence Inc. 2021, Confidential.
16 .有状态UDF函数实现初步设想 HTTP UDF UDF Worker Worker UDF UDF Worker Worker 本质是启动一个ML Serving集群,提供 PRC, HTTP支持 UDF UDF Worker Worker RPC © Kyligence Inc. 2021, Confidential.
17 .此前难以落地 难以维护,譬 难以自动化 如需要网关,资 部署 源等等 UDF 侧需要 针对http/rpc 开发成本高 编程 © Kyligence Inc. 2021, Confidential.
18 .天降大Ray © Kyligence Inc. 2021, Confidential.
19 .实现基本原理 • 创建一个detached actor(UDFMaster),名称为udf名 • UDFMaster根据配置(初始化,预测逻辑),启动N个UDFWorker(也是actor) 注册 • 创建Spark UDF函数,该函数会通过pyjava 执行python 代码 仅用96行Ray代码 • 被pyjava执行的python函数会通过udf名获取UDFMaster • 通过UDFMaster 获取可用的UDFWorker 预测 • 调用UDFWorker的apply方法执行实际预测逻辑 Incredible 3连 • 用户可以在Ray dashboard可视化管理 UDF集群 • 用户可以通过MLSQL插件管理UDF 集群 管理 © Kyligence Inc. 2021, Confidential.
20 .用户可自定义注册和预测部分实现 提供模型加载以及预测代码 此时会根据这些信息启动UDF Cluster 使用Python预测代码创建 Spark UDF © Kyligence Inc. 2021, Confidential.
21 .UDF 注册逻辑图 Spark Cluster PyJava(Driver) Ray Cluster UDF UDF Cluster Worker 创建一个 UDF Master-Slave Cluser UDF Worker UDF Master UDF Worker © Kyligence Inc. 2021, Confidential.
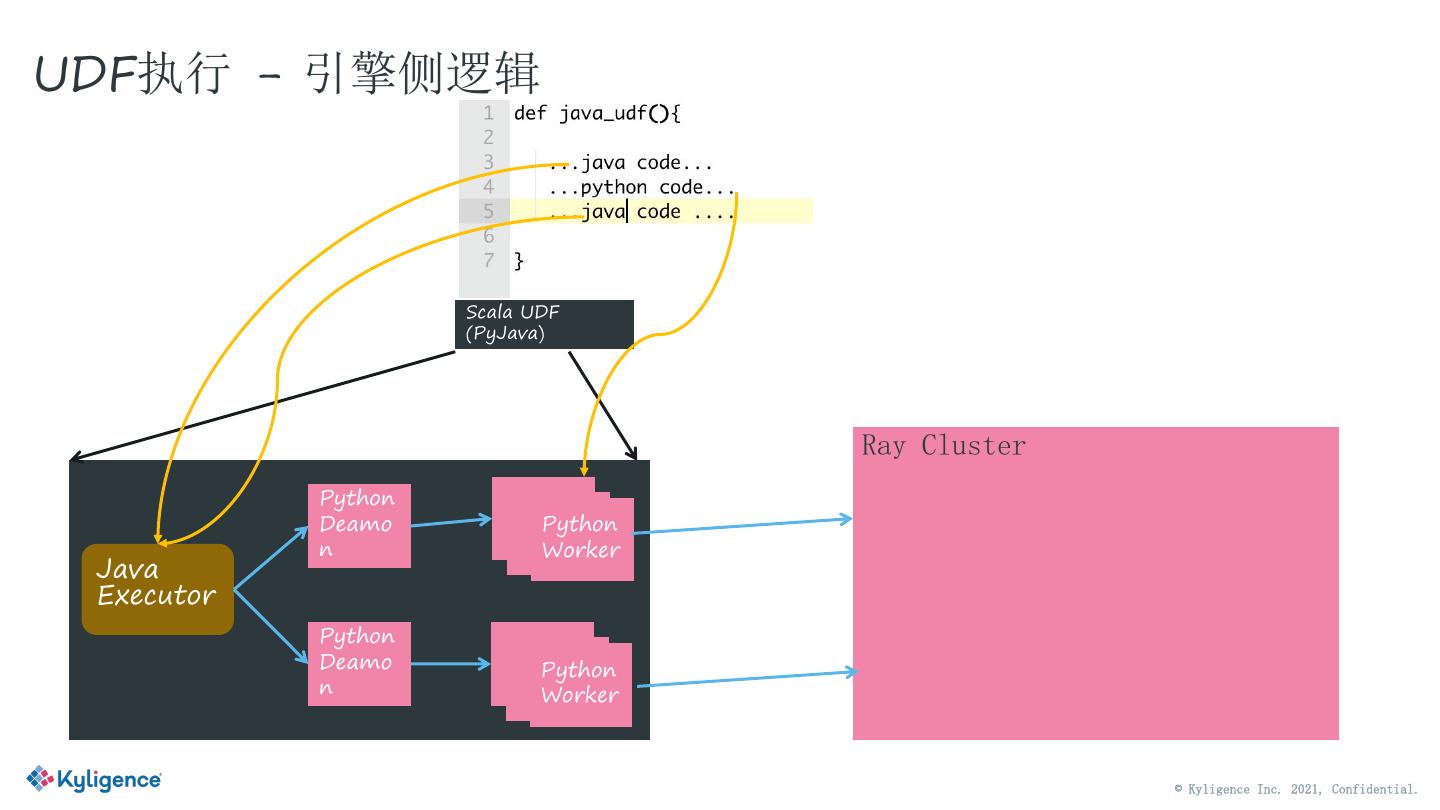
22 .UDF执行 - 引擎侧逻辑 Scala UDF (PyJava) Ray Cluster Python Deamo Python n Worker Java Executor Python Deamo Python n Worker © Kyligence Inc. 2021, Confidential.
23 .UDF 执行- 全局逻辑 Spark Cluster Scala UDF Step2 UDF Worker DF Partition 0 (PyJava) 执行实际逻辑 Scala UDF DF Partition 1 (PyJava) Scala UDF DF Partition 2 (PyJava) Step1: 获取 可用worker Ray Cluster UDF Worker Python Deamo Python UDF n Worker Java Worker Executor UDF Master Python UDF Deamo Python Worker n Worker © Kyligence Inc. 2021, Confidential.
24 .价值 Python/内置算法-三板斧完美闭环 模型训练 Train 模型变函数, 批流,HTTP/RPC皆可用 Register Predict 批量预测,吞吐优先 © Kyligence Inc. 2021, Confidential.
25 .欢迎加入 mlsql.ai 社区 © Kyligence Inc. 2021, Confidential.
26 .Contact Us Kyligence Inc Apache Kylin u http://kyligence.io u http://kylin.apache.org u info@kyligence.io u dev@kylin.apache.org u Twitter: @Kyligence u Twitter: @ApacheKylin © Kyligence Inc. 2021, Confidential.
27 .© Kyligence Inc. 2021, Confidential.
3秒后跳转登录页面
去登陆

