

















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板

2.使用RayDP-Spark on Ray构建端到端的大数据分析和人工智能应用-Carson Wang
2.使用RayDP-Spark on Ray构建端到端的大数据分析和人工智能应用-Carson Wang
2.使用RayDP-Spark on Ray构建端到端的大数据分析和人工智能应用-Carson Wang
使用RayDP-Spark on Ray构建端到端的大数据分析和人工智能应用-Carson Wang
对于一个复杂的端到端数据分析和人工智能应用,通常需要用到多个分布式的框架,比如使用Apache Spark来做数据的预处理,使用XGBoost,PyTorch,Tensorflow等框架来做分布式的模型训练。一个常规的做法是使用独立的大数据集群和模型训练的集群,将整个工作流中的不同阶段分别提交到不同的集群上,并且使用胶水代码来连接它们。其它的方案包括使用Apache Spark作为统一的平台来运行数据处理和模型训练,使用任务调度框架来连接一个工作流中不同阶段等。这些做法都有他们各自的局限性。在本次分享中,我们将介绍使用Ray作为一个统一的分布式平台,使用RayDP在Ray上运行Spark的程序,并且通过Ray的分布式内存存储,高效地和Ray上的机器学习框架进行数据交换。我们将演示通过RayDP和Ray生态中的其它组件,如何在一个Python程序中高效地开发复杂的端到端的数据分析和人工智能应用。
Carson Wang 英特尔高性能数据分析研发团队负责人,专注于研发和优化开源大数据,分布式机器学习框架,开发大数据和人工智能融合解决方案。他目前领导以下一些开源项目包括RayDP-Spark on Ray, OAP MLlib-高性能版Spark机器学习算法库。此前,他主导研发了Spark SQL自适应执行引擎,HiBench-大数据基准测试工具等项目。
展开查看详情
1 .使用RayDP-Spark on Ray构建端 到端的大数据分析和人工智能应 用 Carson Wang Intel
2 .Agenda • Big Data & AI Background • RayDP Overview • RayDP Deep Dive • RayDP Examples
3 .Big Data & AI Background
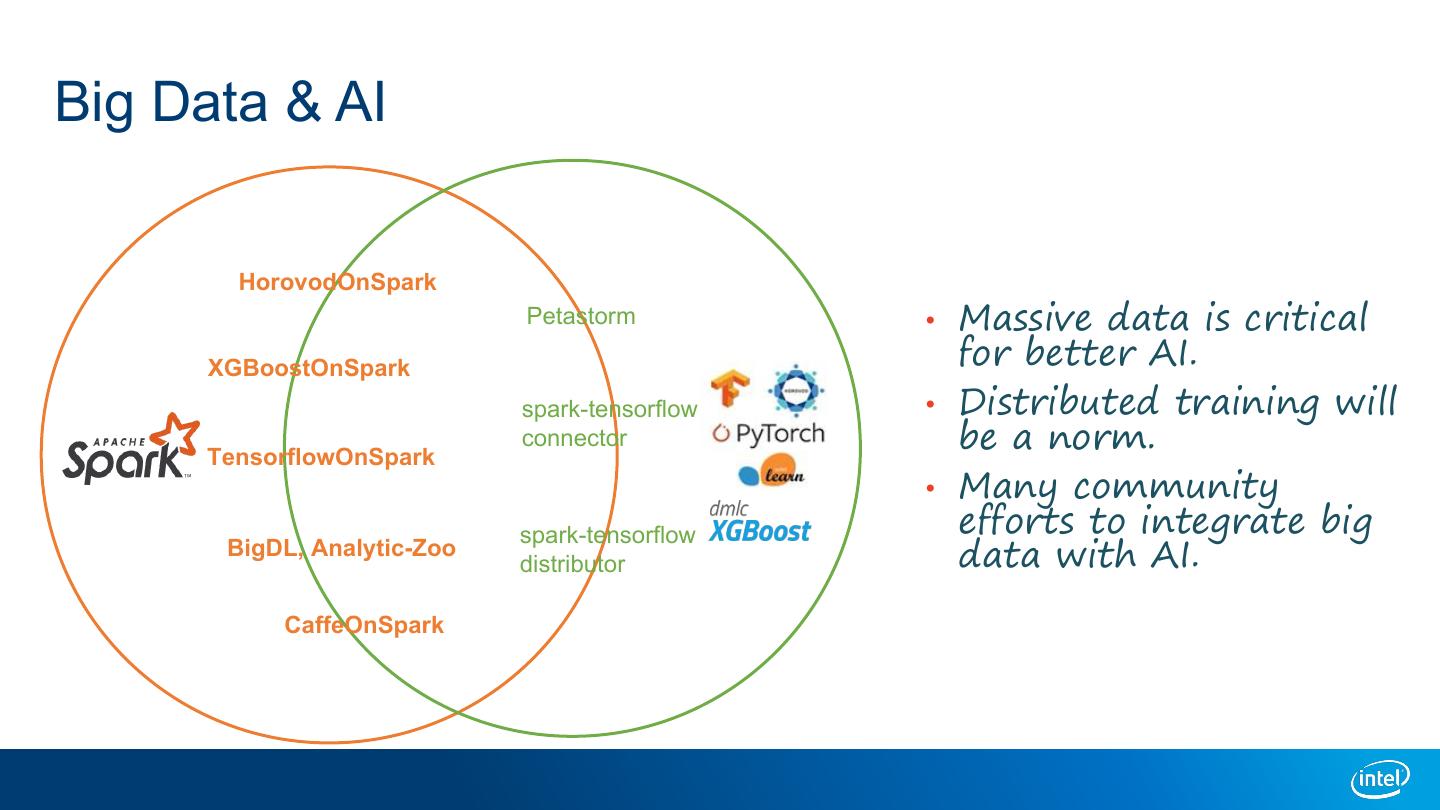
4 .Big Data & AI HorovodOnSpark Petastorm • Massive data is critical XGBoostOnSpark for better AI. spark-tensorflow • Distributed training will TensorflowOnSpark connector be a norm. • Many community spark-tensorflow efforts to integrate big BigDL, Analytic-Zoo distributor data with AI. CaffeOnSpark
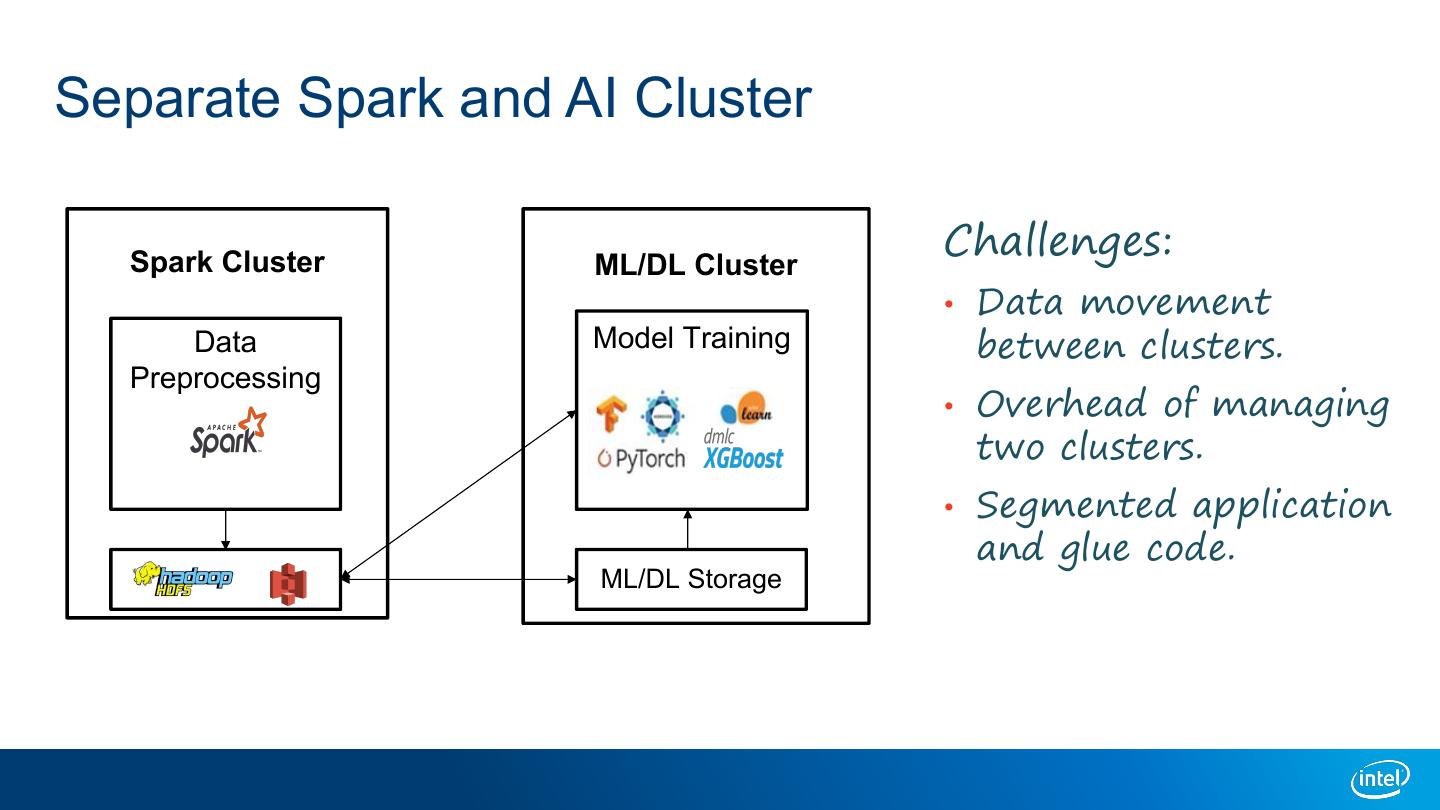
5 .Separate Spark and AI Cluster Spark Cluster ML/DL Cluster Challenges: • Data movement Data Model Training between clusters. Preprocessing • Overhead of managing two clusters. • Segmented application and glue code. ML/DL Storage
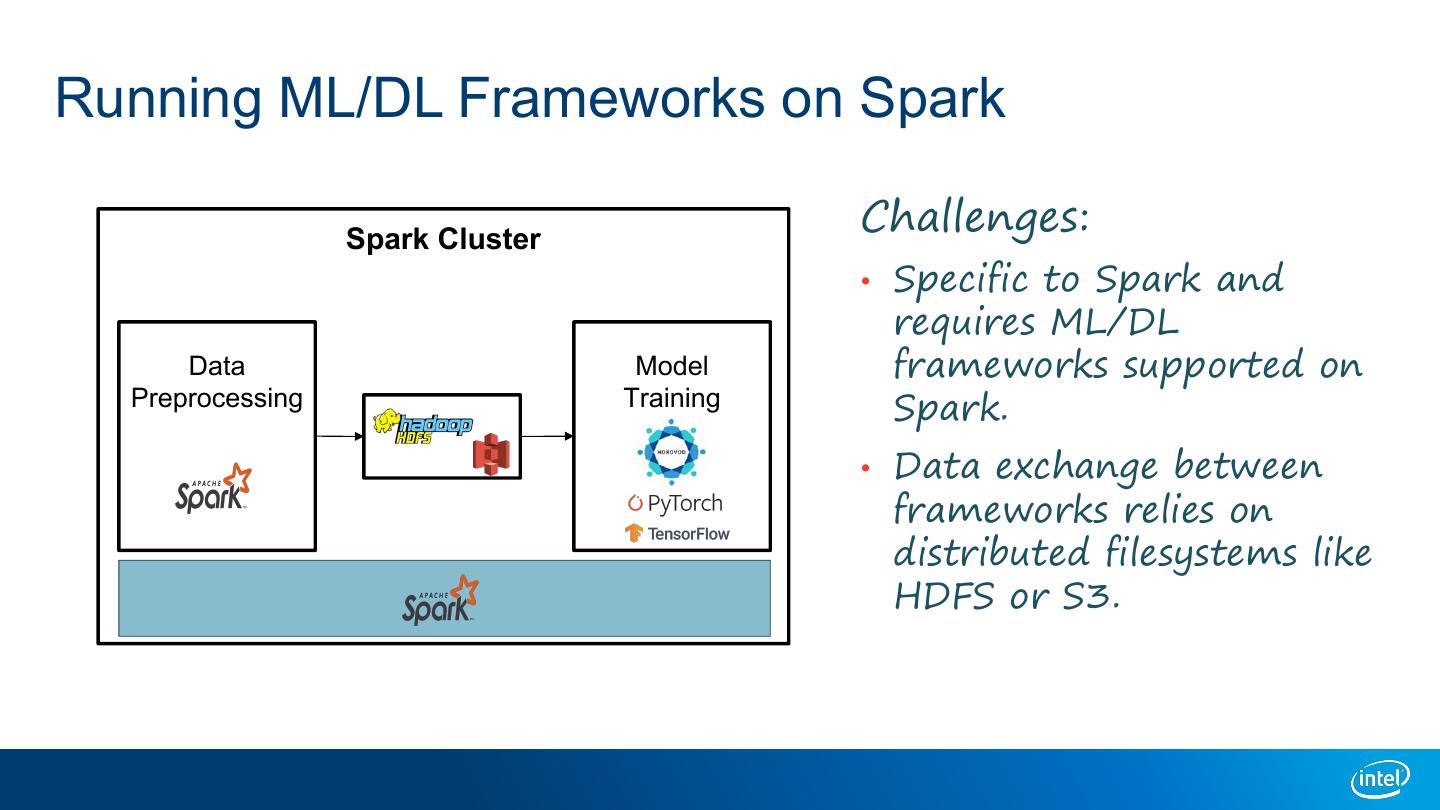
6 .Running ML/DL Frameworks on Spark Spark Cluster Challenges: • Specific to Spark and requires ML/DL Data Model frameworks supported on Preprocessing Training Spark. • Data exchange between frameworks relies on distributed filesystems like HDFS or S3.
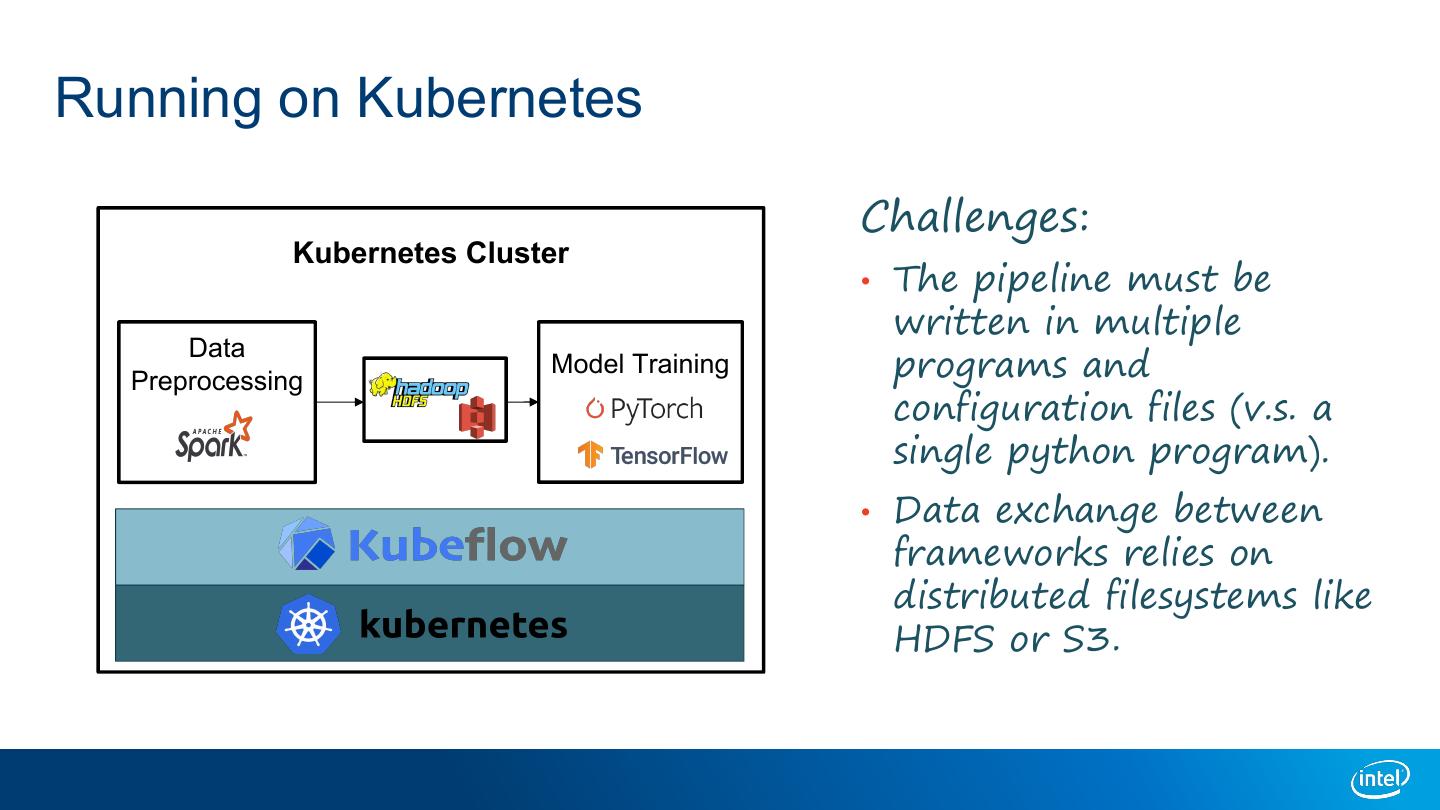
7 .Running on Kubernetes Challenges: Kubernetes Cluster • The pipeline must be written in multiple Data Preprocessing Model Training programs and configuration files (v.s. a single python program). • Data exchange between frameworks relies on distributed filesystems like HDFS or S3.
8 .RayDP Overview
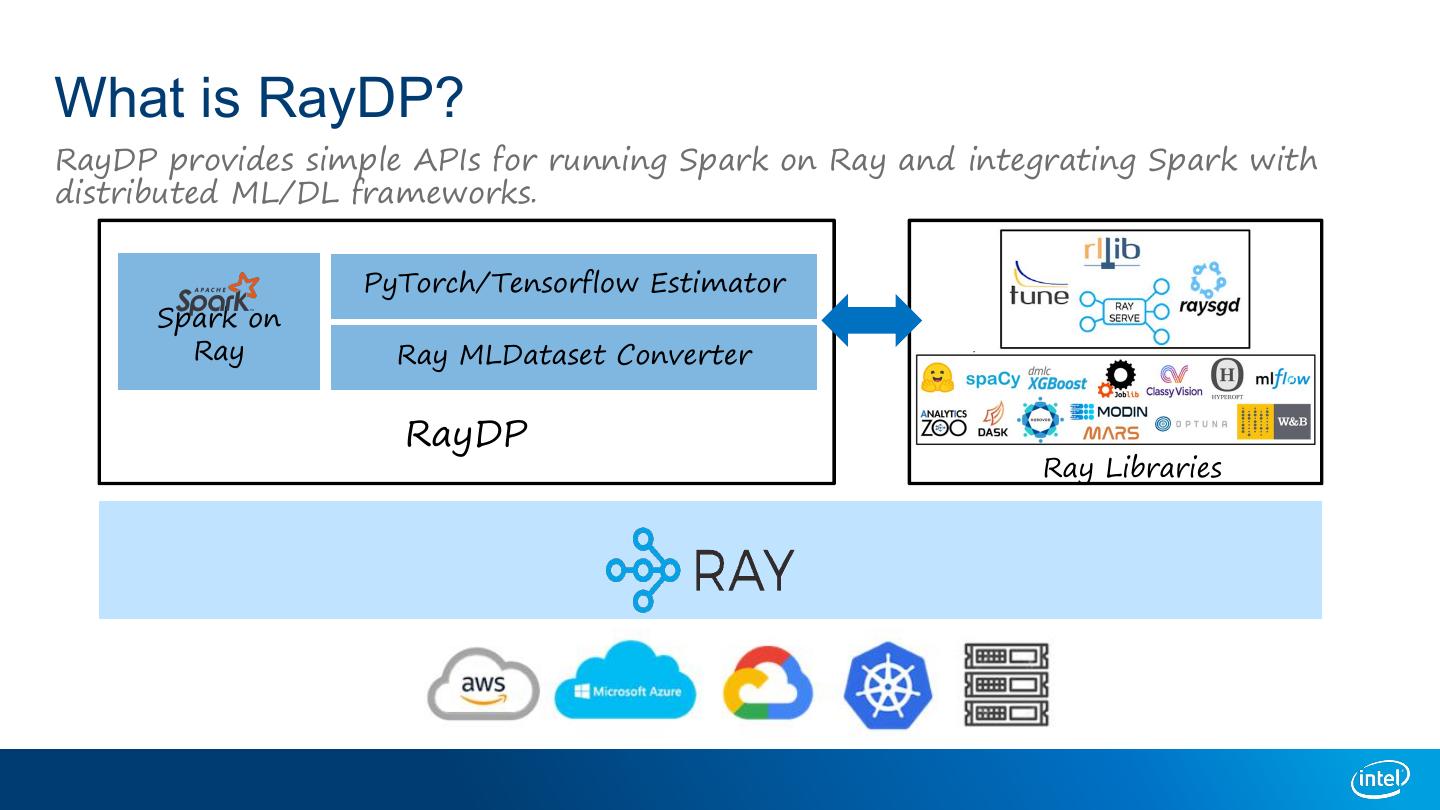
9 .What is RayDP? RayDP provides simple APIs for running Spark on Ray and integrating Spark with distributed ML/DL frameworks. PyTorch/Tensorflow Estimator Spark on Ray Ray MLDataset Converter RayDP Ray Libraries
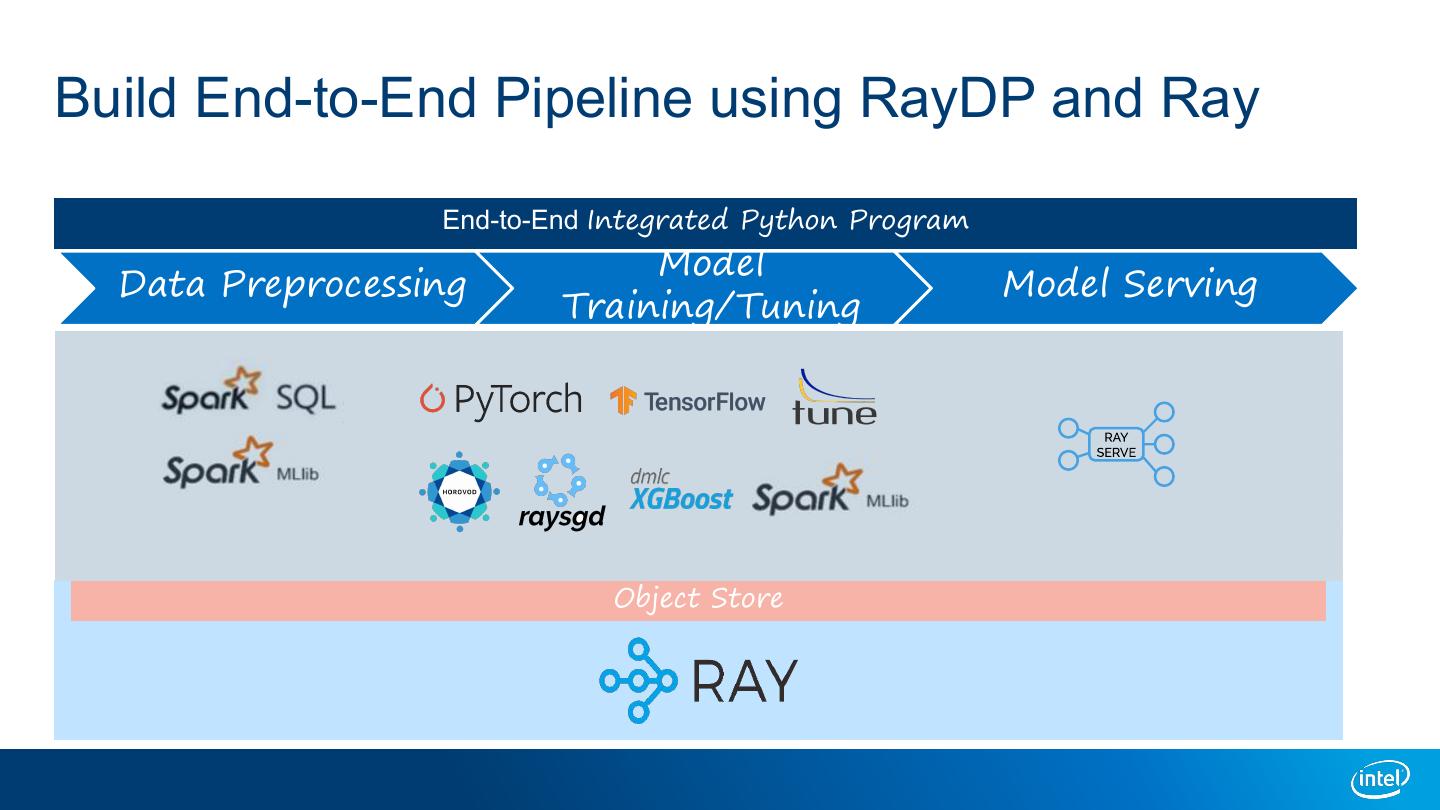
10 .Build End-to-End Pipeline using RayDP and Ray End-to-End Integrated Python Program Model Data Preprocessing Model Serving Training/Tuning Object Store
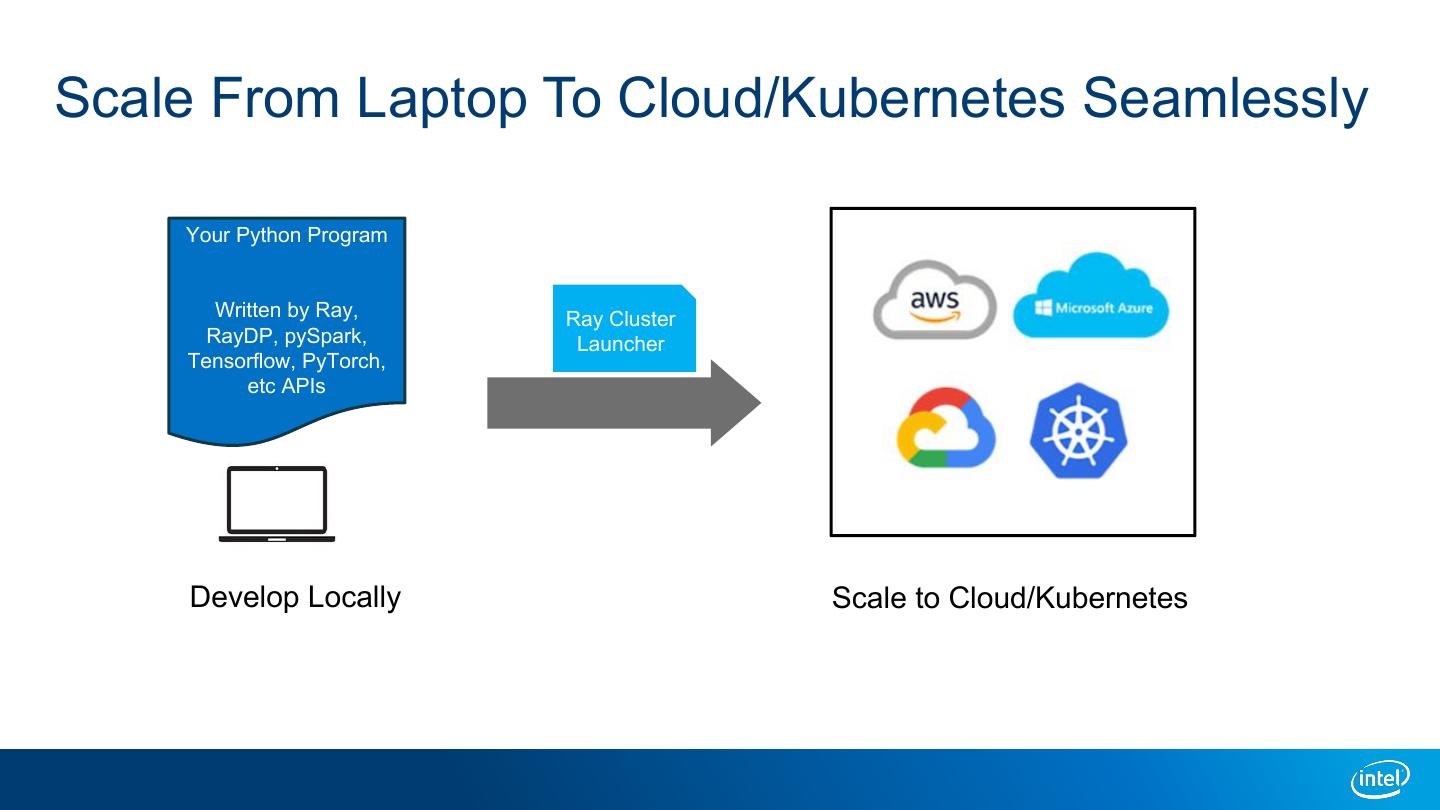
11 .Scale From Laptop To Cloud/Kubernetes Seamlessly Your Python Program Written by Ray, Ray Cluster RayDP, pySpark, Launcher Tensorflow, PyTorch, etc APIs Develop Locally Scale to Cloud/Kubernetes
12 .Why RayDP? Increased Productivity § Simplify how to build and manage end-to-end pipeline. Write Spark, Xgboost, Tensorflow, PyTorch, Horovod code in a single python program. Better Performance § In-memory data exchange. § Built-in Spark optimization. Increased Resource Utilization § Auto scaling at the cluster level and the application level.
13 .RayDP Deep Dive
14 .Spark on Ray API import ray import raydp ray.init(address='auto') • Use raydp.init_spark spark = raydp.init_spark(app_name='Spark on Ray', to start a Spark job on a Ray cluster. num_executors=2, executor_cores=2, • Use raydp.stop_spark executor_memory='1G’, to stop the job and release the resource. configs=None) df = spark.read.parquet(…) raydp.stop_spark()
15 .Spark on Ray Architecture 3 2 Driver Spark 1 AppMaster Spark Executor Worker Spark • One Ray actor for (Java Actor) Worker Executor Spark AppMaster to Driver (Java Actor) (Java Actor) 2 3 start/stop Spark executors. ObjectStore ObjectStore ObjectStore Raylet Raylet Raylet • All Spark executors are in Ray Java actors. • Leverage object store for data exchange GCS Web UI between Spark and GCS GCS Debugging Tools other Ray libraries. Profiling Tools
16 .PyTorch/Tensorflow Estimator estimator = TorchEstimator(num_workers=2, model=your_model, • Create an Estimator optimizer=optimizer, with parameters like loss=criterion, model, optimizer, loss feature_columns=features, function, etc. label_column="fare_amount", batch_size=64, • Fit the estimator with Spark dataframes num_epochs=30) directly. estimator.fit_on_spark(train_df, test_df)
17 . Ray MLDataset Converter Operations from raydp.spark import Planning Execution RayMLDataset Phase 1 Phase 2 spark_df = … Spark PyTorch torch_ds = RayMLDataset Spark Datafra ML ML ML Datafram Dataset e .from_spark(spar me Datase Datase Datase Spark Actor PyTorch Actor k_df, …) t transform t to_torch t .transform(func) 1. from_spark .to_torch(…) from_sparkt MLDataset 2. transform torch_dataloader = Actor + to_torch DataLoader(torch_ds.get_shard(shar MLDataset Shard d_index), …) Object Object Object 1 2 3 Build Operation Graph Transformations are lazy, executed in Object Store pipeline Ray Scheduler • Create from Spark dataframe, In- memory objects, etc • Transform using user defined functions • Convert to PyTorch/Tensorflow Dataset
18 .RayDP Examples
19 .Spark + XGBoost on Ray End-to-End Integrated Python Program Data Preprocessing Model Training import ray import raydp ray.init(address='auto') from xgboost_ray import RayDMatrix, train, RayParams spark = raydp.init_spark('Spark + XGBoost', dtrain = RayDMatrix(train_dataset, label='fare_amount') num_executors=2, dtest = RayDMatrix(test_dataset, label='fare_amount’) RayDP … executor_cores=4, bst = train( config, executor_memory='8G') dtrain, evals=[(dtest, "eval")], evals_result=evals_result, df = spark.read.csv(...) ray_params=RayParams(…) ... RayDP num_boost_round=10) train_df, test_df = random_split(df, [0.9, 0.1]) train_dataset = RayMLDataset.from_spark(train_df, ...) test_dataset = RayMLDataset.from_spark(test_df, ...)
20 .Spark + Horovod on Ray End-to-End Integrated Python Program import ray Data Preprocessing Model Training import raydp #PyTorch Model class My_Model(nn.Module): ray.init(address='auto') … spark = raydp.init_spark('Spark + Horovod', #Horovod on Ray num_executors=2, def train_fn(dataset, num_features): RayDP hvd.init() executor_cores=4, rank = hvd.rank() train_data = dataset.get_shard(rank) executor_memory=‘8G’) ... from horovod.ray import RayExecutor df = spark.read.csv(...) executor = RayExecutor(settings, num_hosts=1, ... num_slots=1, cpus_per_slot=1) executor.start() RayDP torch_ds= RayMLDataset.from_spark(df, …) executor.run(train_fn, args=[torch_ds, num_features]) .to_torch(...)
21 .Spark + Horovod + RayTune on Ray End-to-End Integrated Python Program Data Preprocessing Model Training/Tuning import ray #PyTorch Model import raydp class My_Model(nn.Module): … ray.init(address='auto') #Horovod on Ray + Ray Tune spark = raydp.init_spark(‘Spark + Horovod', def train_fn(config: Dict): RayDP ... num_executors=2, trainable = DistributedTrainableCreator( train_fn, num_slots=2, use_gpu=use_gpu) executor_cores=4, analysis = tune.run( trainable, executor_memory=‘8G’) num_samples=2, config={ df = spark.read.csv(...) "epochs": tune.grid_search([1, 2, 3]), ... "lr": tune.grid_search([0.1, 0.2, 0.3]), } RayDP torch_ds= RayMLDataset.from_spark(df, …) ) .to_torch(...) print(analysis.best_config)
22 .Summary • Ray is a general-purpose framework that can be used as a single substrate for end-to-end data analytics and AI pipelines. • RayDP provides simple APIs for running Spark on Ray and integrating Spark with distributed ML/DL frameworks. • For more information, please visit https://github.com/oap-project/raydp
23 .THANK You
3秒后跳转登录页面
去登陆

