


















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板

Milvus:A Purpose-Built Vector Data Management System
Milvus:A Purpose-Built Vector Data Management System
Milvus:A Purpose-Built Vector Data Management System
议题简介
Milvus 是全球最流行的开源向量数据库系统。MIlvus于2019年10月开源,并于2020 年 3 月正式通过技术委员会投票,成功加入 LF AI & Data(Linux AI 基金会)成为孵化项目。Milvus 项目蓬勃发展,被广泛应用于图片检索、视频内容分析、互联网搜索、推荐系统、虚拟助手、智能客服、网络安全、虚拟化合物筛选和基因序列分析等多个领域,在全球拥有超过1000家企业用户。2021年6月,Milvus通过技术委员会评审和投票,成为 LF AI & Data 基金会旗下毕业项目。相关代码开放在http://github.com/milvus-io/milvus
易小萌,Zilliz 高级研究员,研究团队负责人,华中科技大学计算系统结构博士。主要工作领域为向量近似搜索算法和分布式系统的资源调度,相关研究成果在 IEEE Network Magazine、IEEE/ACM TON、ACM SIGMOD、IEEE ICDCS、ACM TOMPECS 等计算机领域国际顶级会议与期刊上发表。他曾是华为云资源调度策略设计团队核心成员
展开查看详情
1 .
2 .Milvus: A Purpose-Built Vector Data Management System Jianguo Wang, Xiaomeng Yi, Rentong Guo, Hai Jin, Peng Xu, Shengjun Li, Xiangyu Wang, Xiangzhou Guo, Chengming Li, Xiaohai Xu, Kun Yu, Yuxing Yuan, Yinghao Zou, Jiquan Long, Yudong Cai, Zhenxiang Li, Zhifeng Zhang, Yihua Mo, Jun Gu, Ruiyi Jiang, Yi Wei, Charles Xie
3 .Unstructured Data are Dominating Image Int, float, Text Json video Domain specific String, … audio ABCDEFG 2021.04.10 Structured data Unstructured data 3
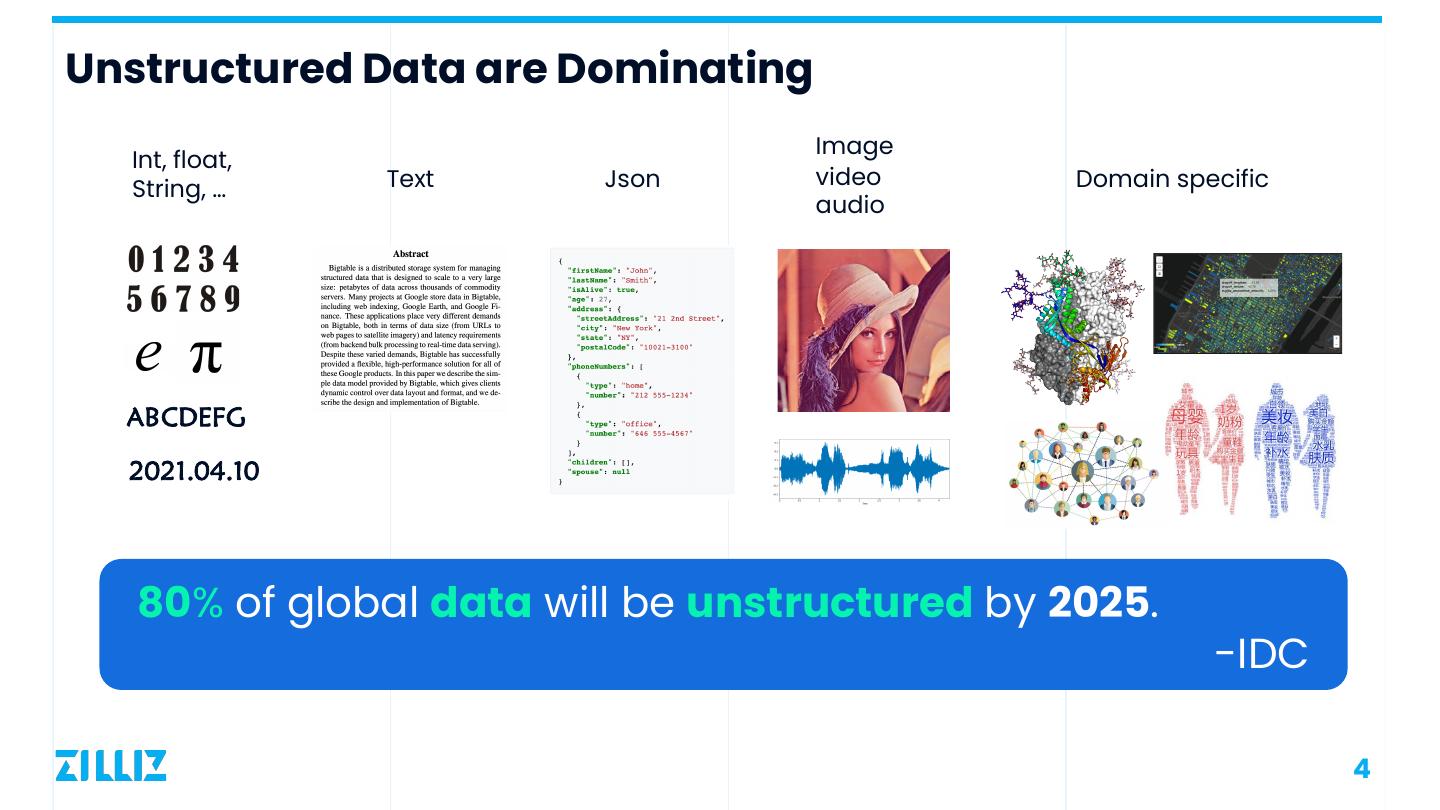
4 .Unstructured Data are Dominating Image Int, float, Text Json video Domain specific String, … audio ABCDEFG 2021.04.10 80% of global data will be unstructured by 2025. -IDC 4
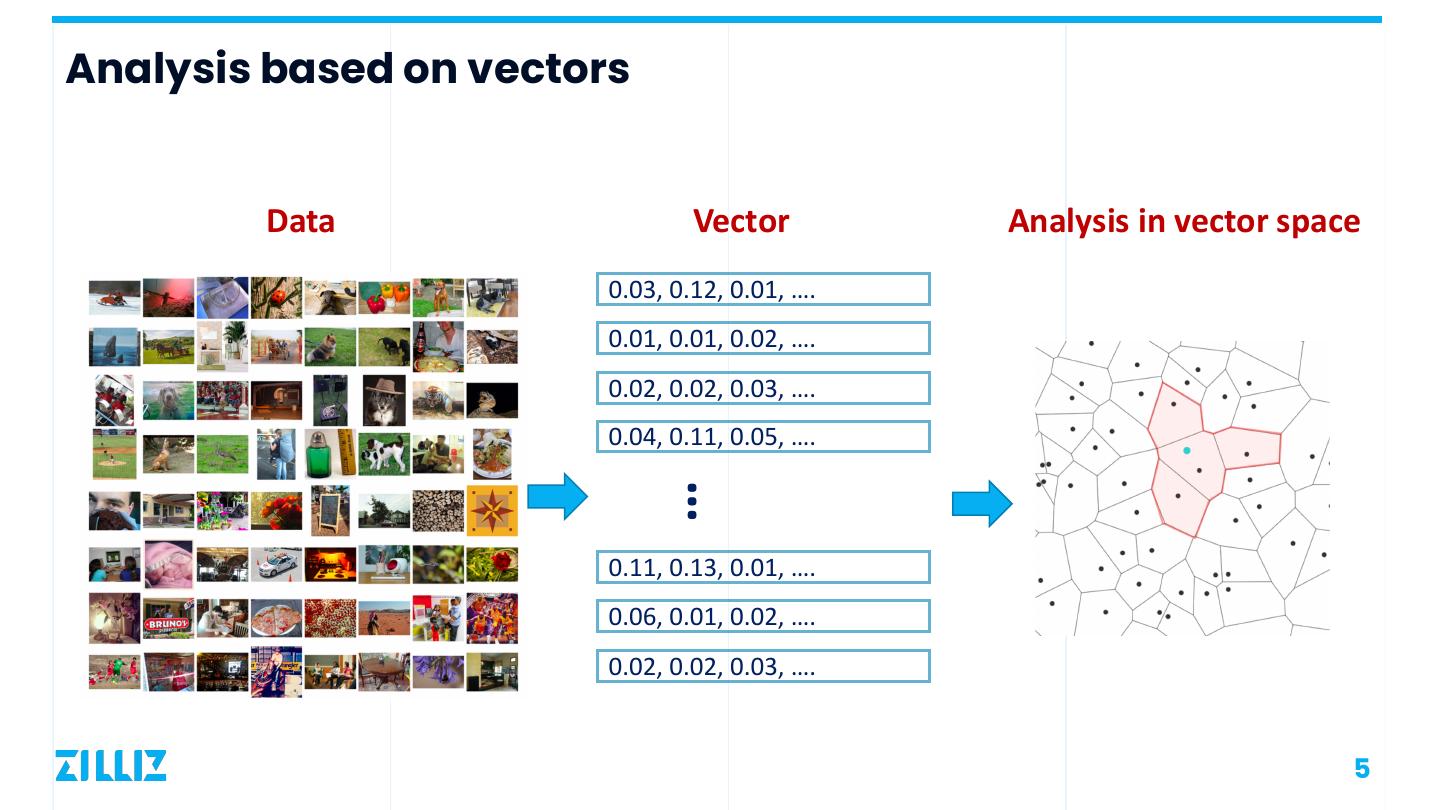
5 .Analysis based on vectors Data Vector Analysis in vector space 0.03, 0.12, 0.01, …. 0.01, 0.01, 0.02, …. 0.02, 0.02, 0.03, …. 0.04, 0.11, 0.05, …. … 0.11, 0.13, 0.01, …. 0.06, 0.01, 0.02, …. 0.02, 0.02, 0.03, …. 5
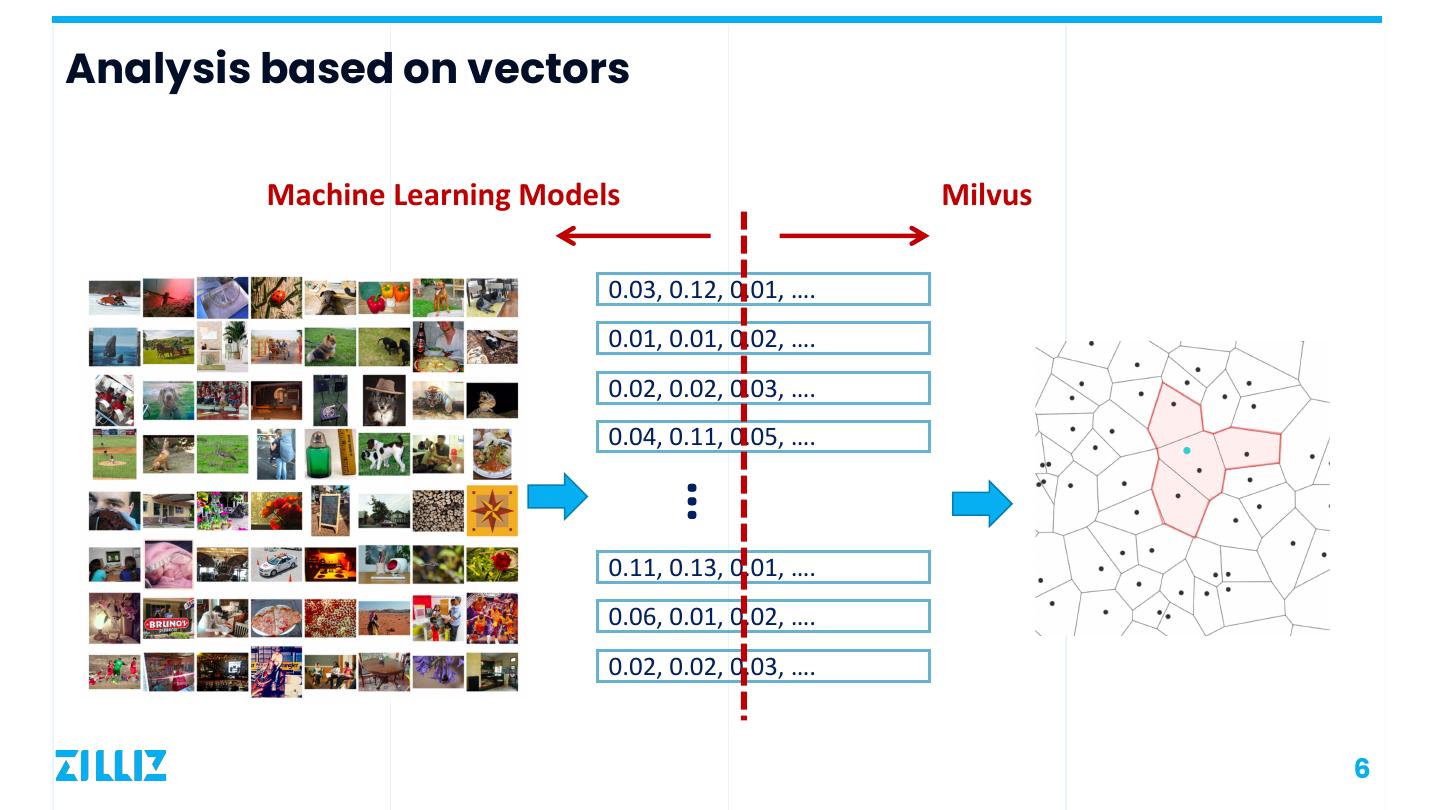
6 .Analysis based on vectors Machine Learning Models Milvus 0.03, 0.12, 0.01, …. 0.01, 0.01, 0.02, …. 0.02, 0.02, 0.03, …. 0.04, 0.11, 0.05, …. … 0.11, 0.13, 0.01, …. 0.06, 0.01, 0.02, …. 0.02, 0.02, 0.03, …. 6
7 .The open-source journey of Milvus 7.2K GitHub Stars 2018.10 2019.04 2019.06 2019.10 147 Contributors 1st The Milvus Open 1000+ Global Users Seed Idea 0.1 Source User 2021.06 2020.03 2020.10 2021.03 2021.06 1ST LF AI Joined LF AI & Commu nity Milvus &Data Gradua Milvus Data Confere nce 1.0 te Project 2.0 7
8 .Common User Requirements Efforts in Milvus Efficiency: § SIMD & Cache based optimization § Large data volume § Heterogenous computing § Dynamic data management § LSM tree § Snapshot isolation § Execution plan optimization Advanced query semantic: § Vector fusion § Vector similarity search § Iterative merging algorithm § Attribute filtering § Distributed data processing § Multi-vector search § Easy-to-use interfaces 8
9 .Agenda Design Overview Optimizations Advanced Query Processing System Implementation Example Applications Performance Evaluation 9
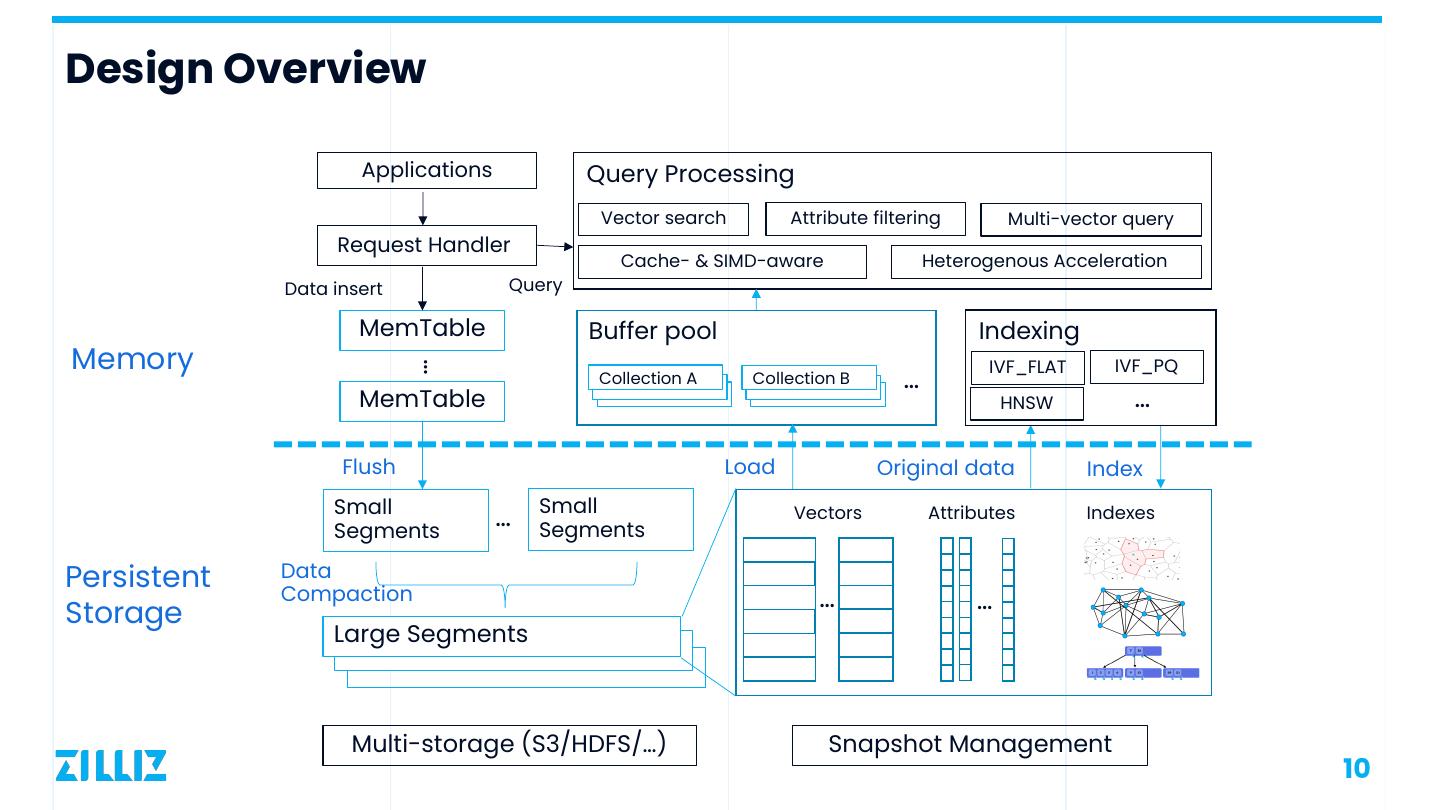
10 .Design Overview Applications Query Processing Vector search Attribute filtering Multi-vector query Request Handler Cache- & SIMD-aware Heterogenous Acceleration Data insert Query MemTable Buffer pool Indexing Memory IVF_FLAT IVF_PQ … Collection A Collection B … MemTable HNSW … Flush Load Original data Index Small Small Segments … Segments Vectors Attributes Indexes Persistent Data Compaction … … Storage Large Segments Multi-storage (S3/HDFS/…) Snapshot Management 10
11 .Agenda Design Overview Optimizations Advanced Query Processing System Implementation Example Applications Performance Evaluation 11
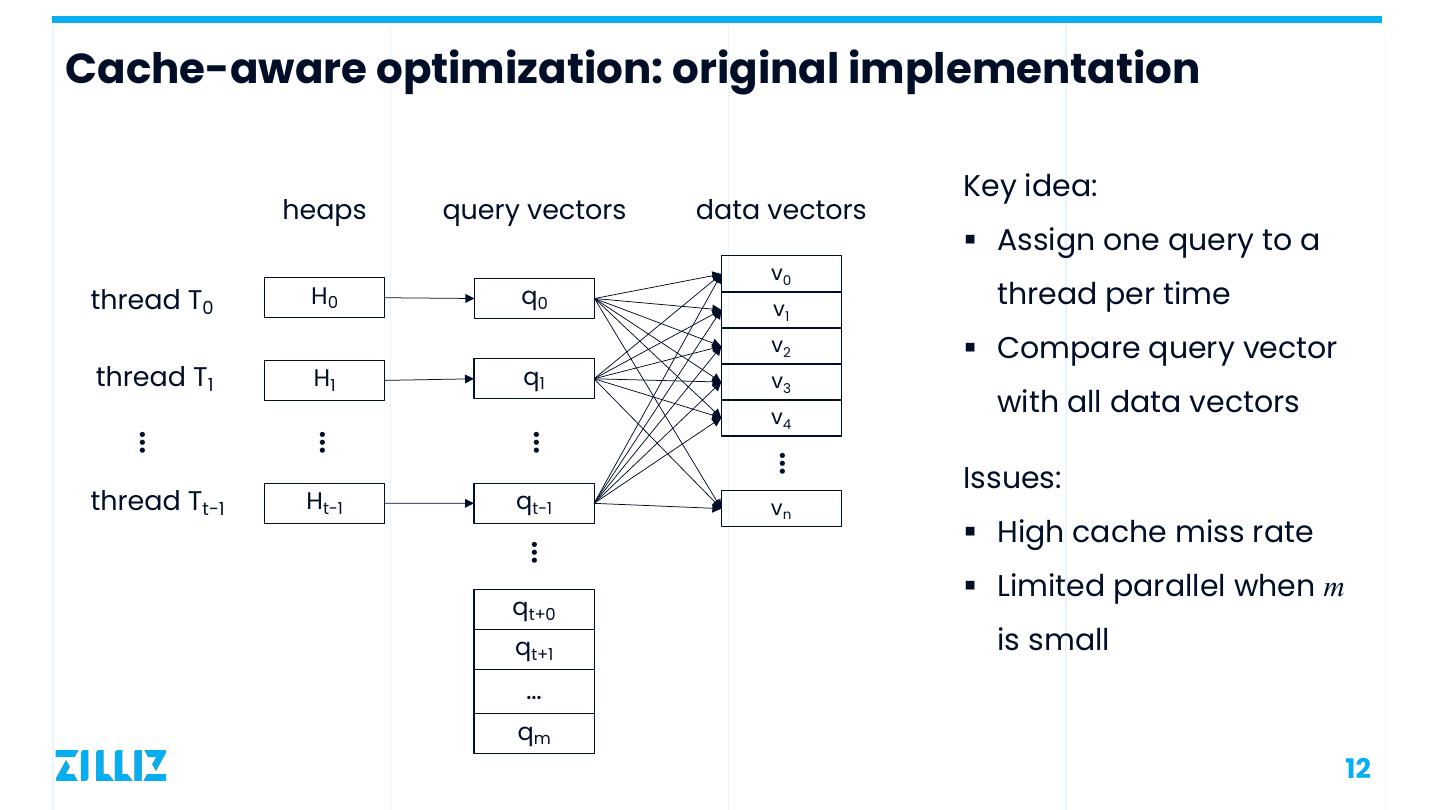
12 .Cache-aware optimization: original implementation Key idea: heaps query vectors data vectors § Assign one query to a v0 thread T0 H0 q0 v1 thread per time v2 § Compare query vector thread T1 H1 q1 v3 v4 with all data vectors … … … … Issues: thread Tt-1 Ht-1 qt-1 vn … § High cache miss rate § Limited parallel when m qt+0 qt+1 is small … qm 12
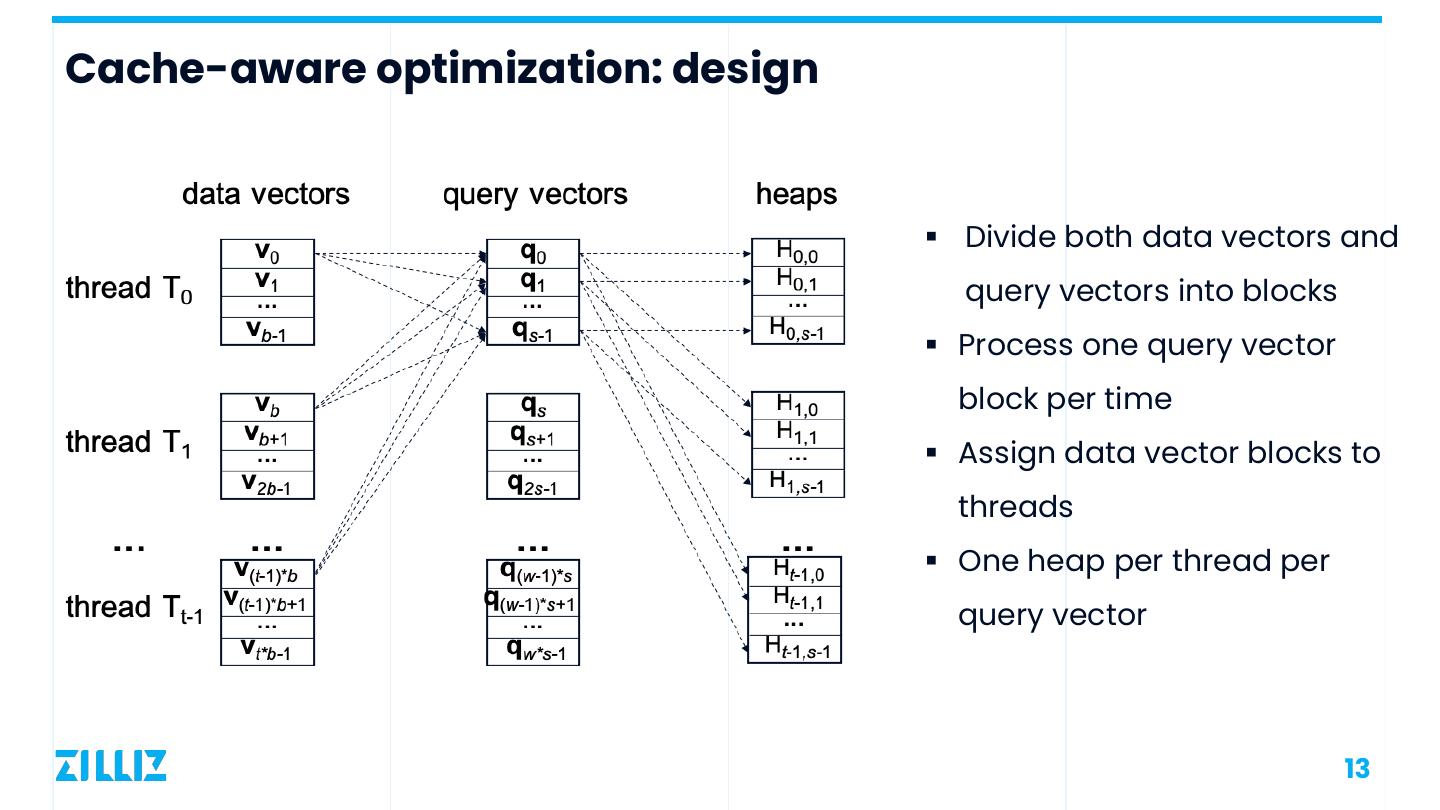
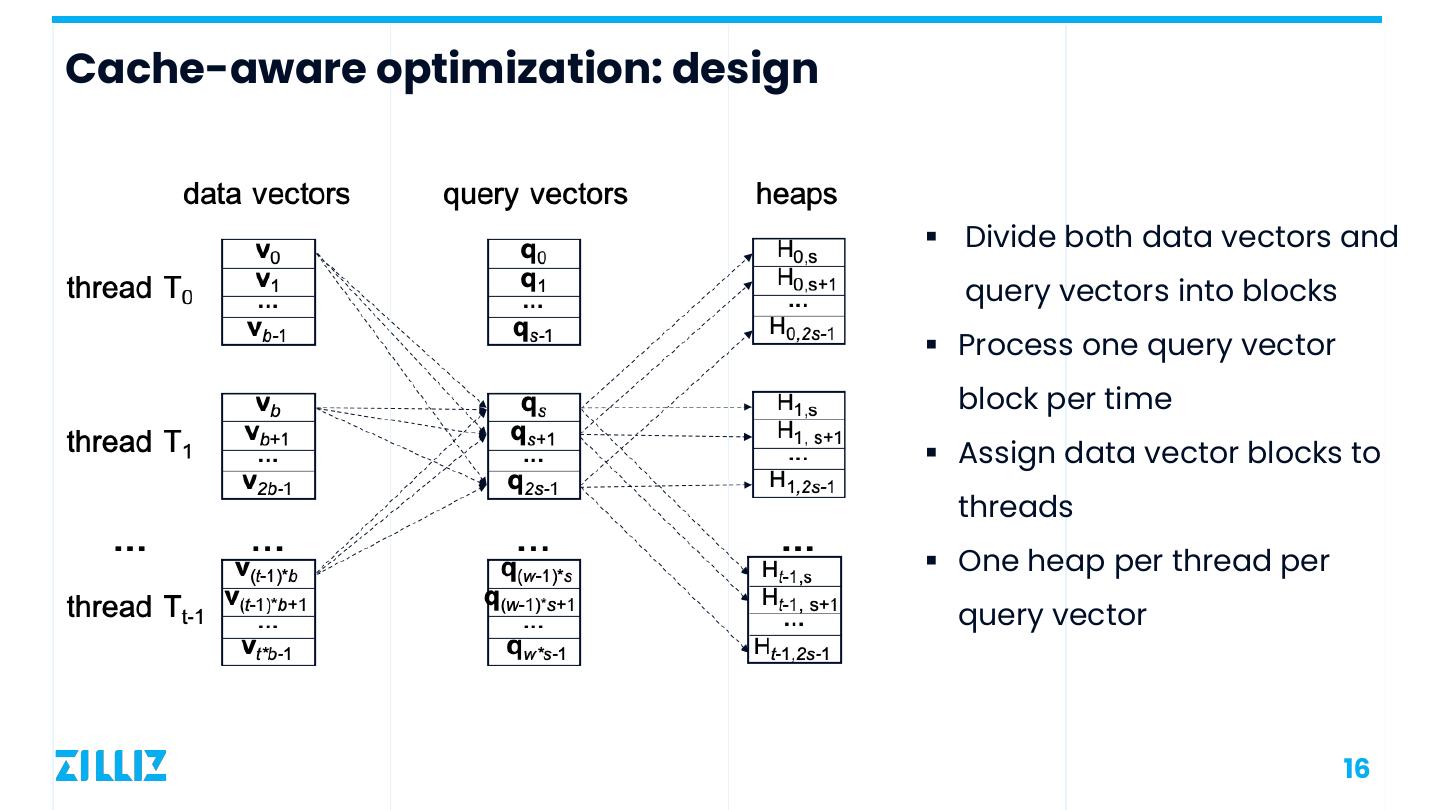
13 .Cache-aware optimization: design § Divide both data vectors and query vectors into blocks § Process one query vector block per time § Assign data vector blocks to threads § One heap per thread per query vector 13
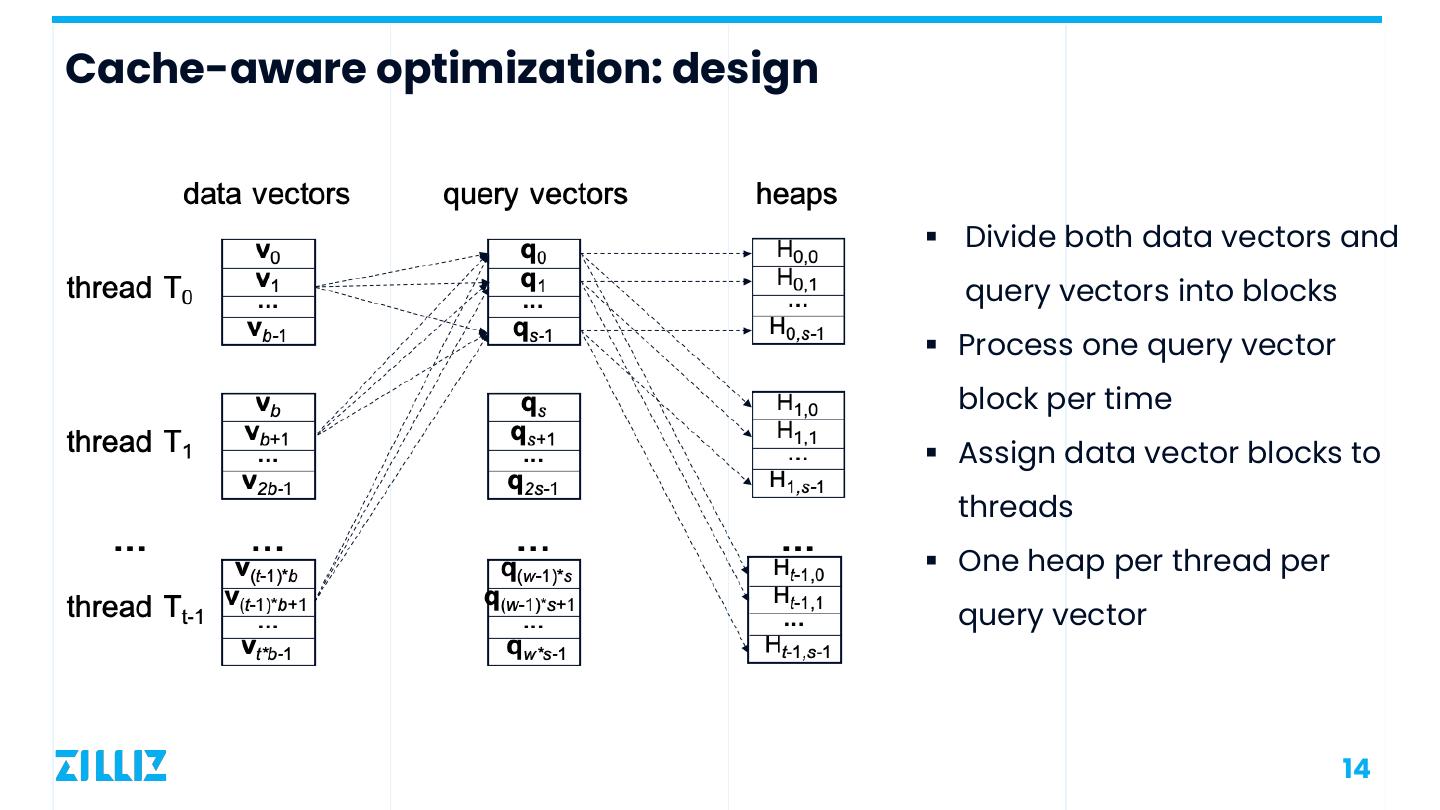
14 .Cache-aware optimization: design § Divide both data vectors and query vectors into blocks § Process one query vector block per time § Assign data vector blocks to threads § One heap per thread per query vector 14
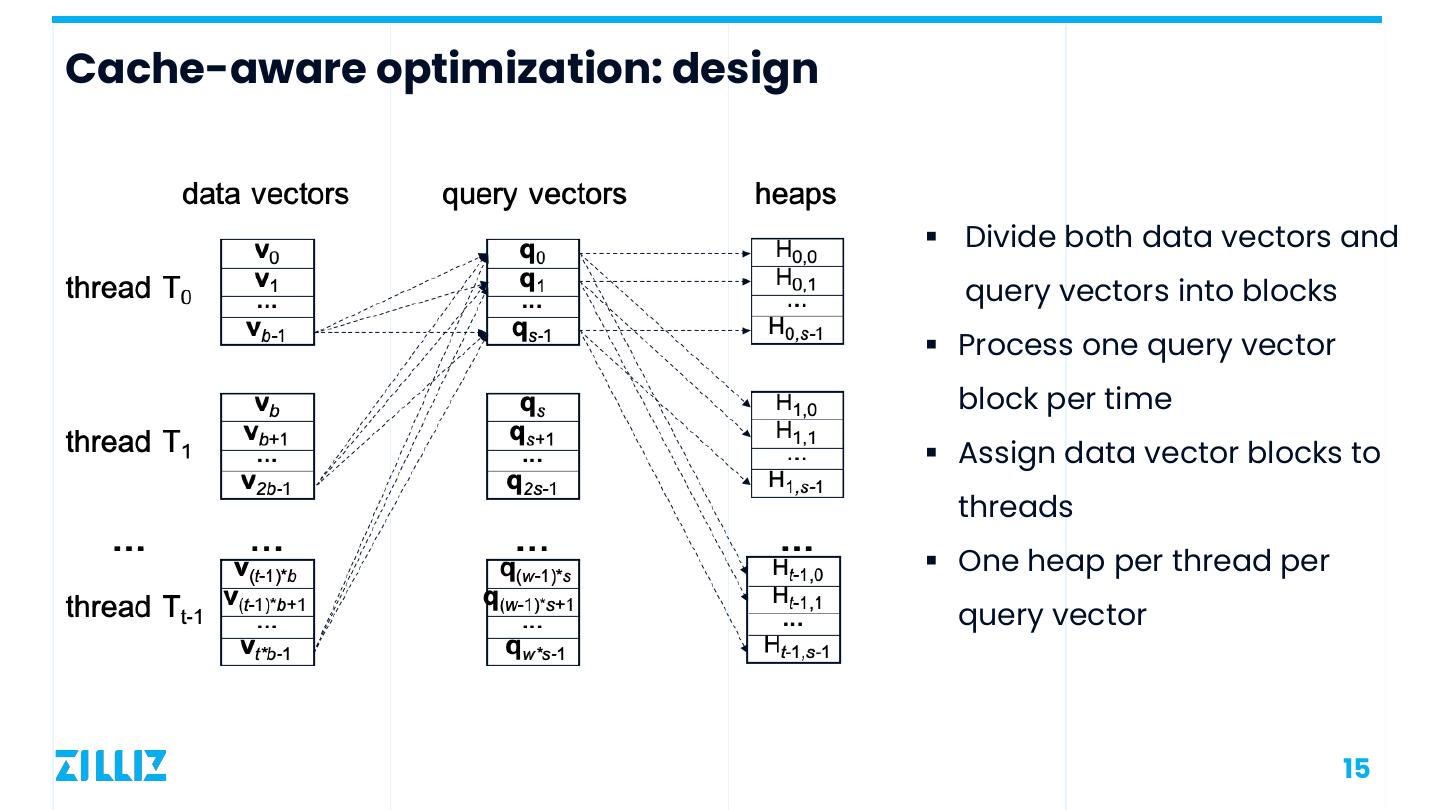
15 .Cache-aware optimization: design § Divide both data vectors and query vectors into blocks § Process one query vector block per time § Assign data vector blocks to threads § One heap per thread per query vector 15
16 .Cache-aware optimization: design § Divide both data vectors and query vectors into blocks § Process one query vector block per time § Assign data vector blocks to threads § One heap per thread per query vector 16
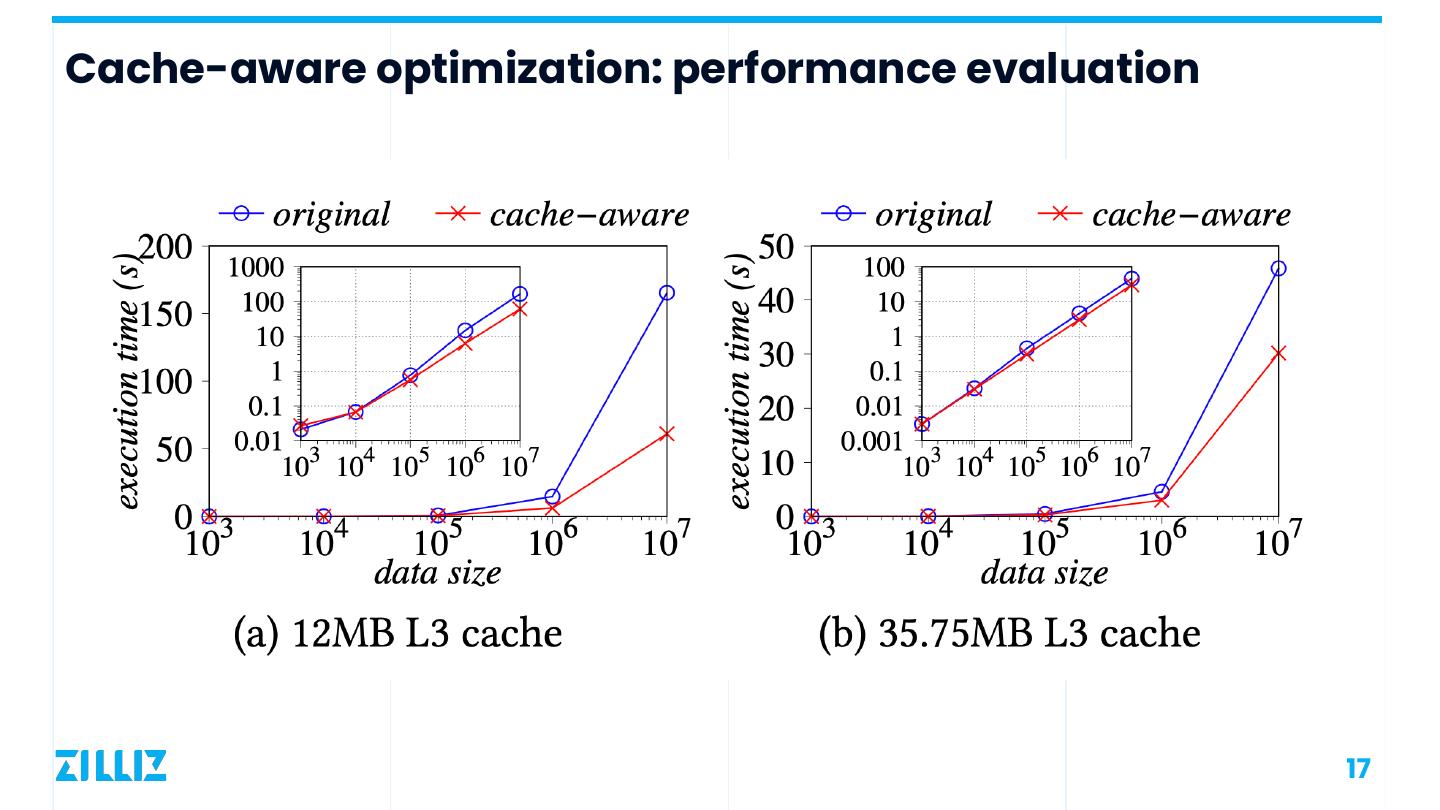
17 .Cache-aware optimization: performance evaluation 17
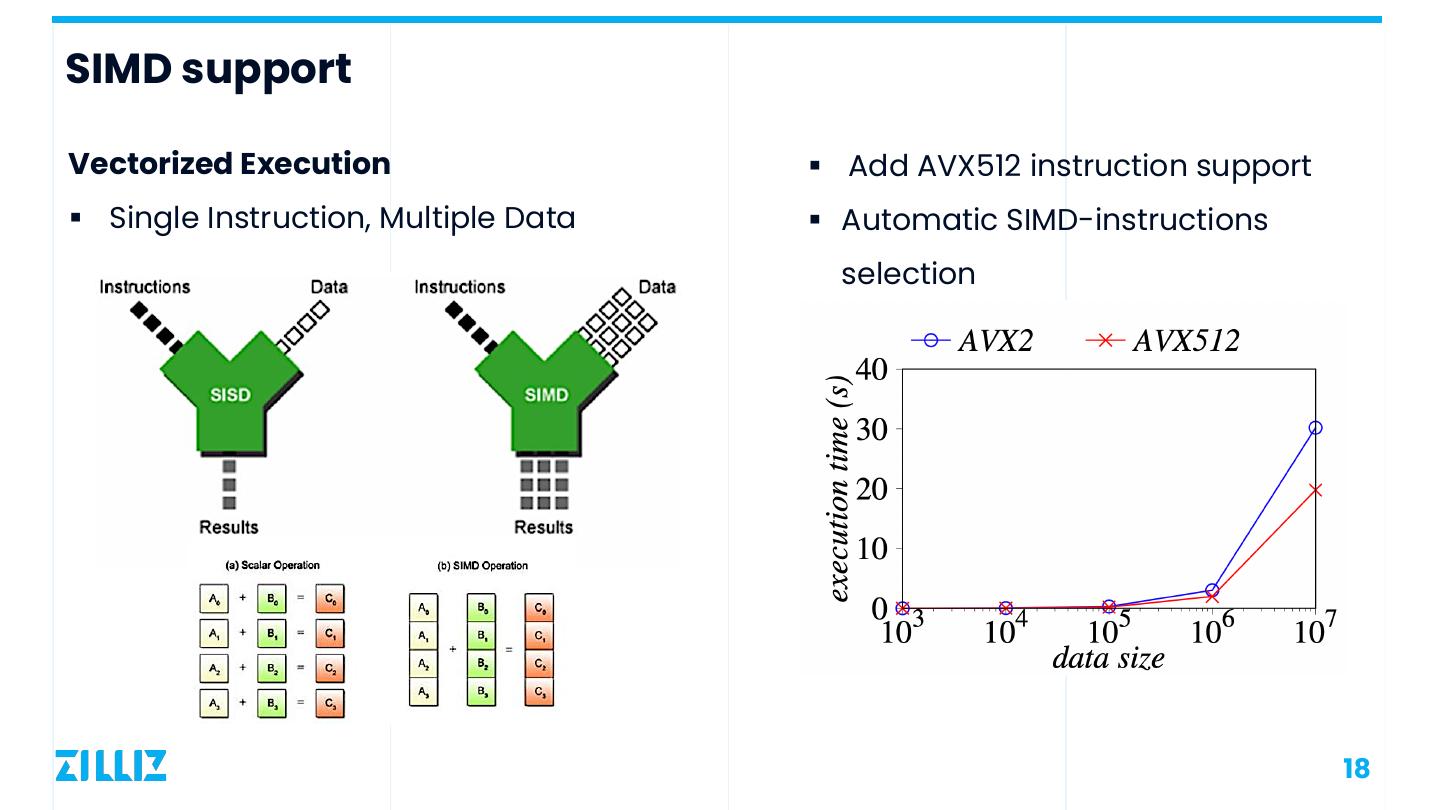
18 .SIMD support Vectorized Execution § Add AVX512 instruction support § Single Instruction, Multiple Data § Automatic SIMD-instructions selection 18
19 .GPU acceleration Issues: § Limited memory capacity § High data transfer cost § Underutilized PCIe bandwidth Solutions: § Bulk data transfer § Let most frequently used data resident in GPU memory § Data transfer for only computation-bound workloads 19
20 .Agenda Design Overview Optimizations Advanced Query Processing System Implementation Example Applications Performance Evaluation 20
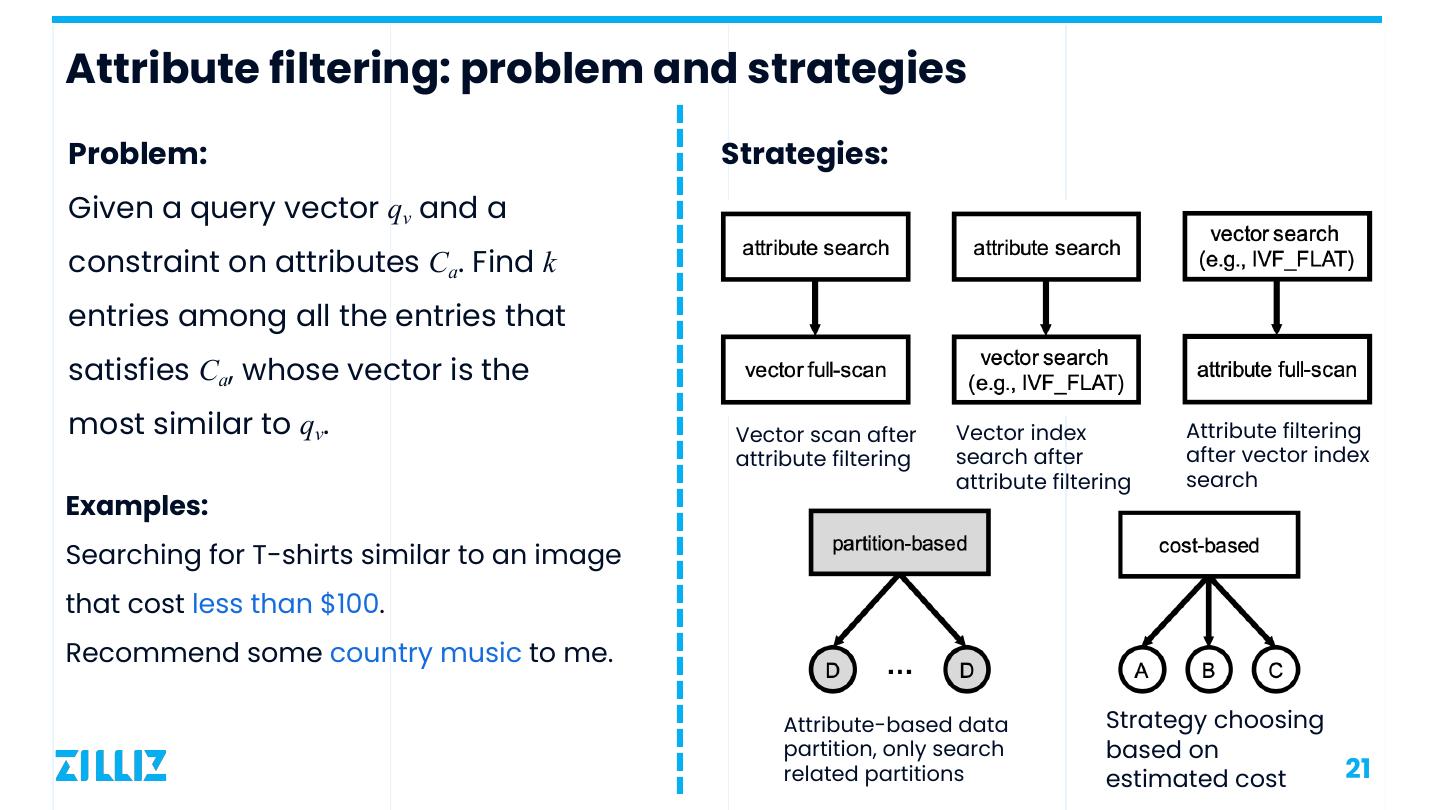
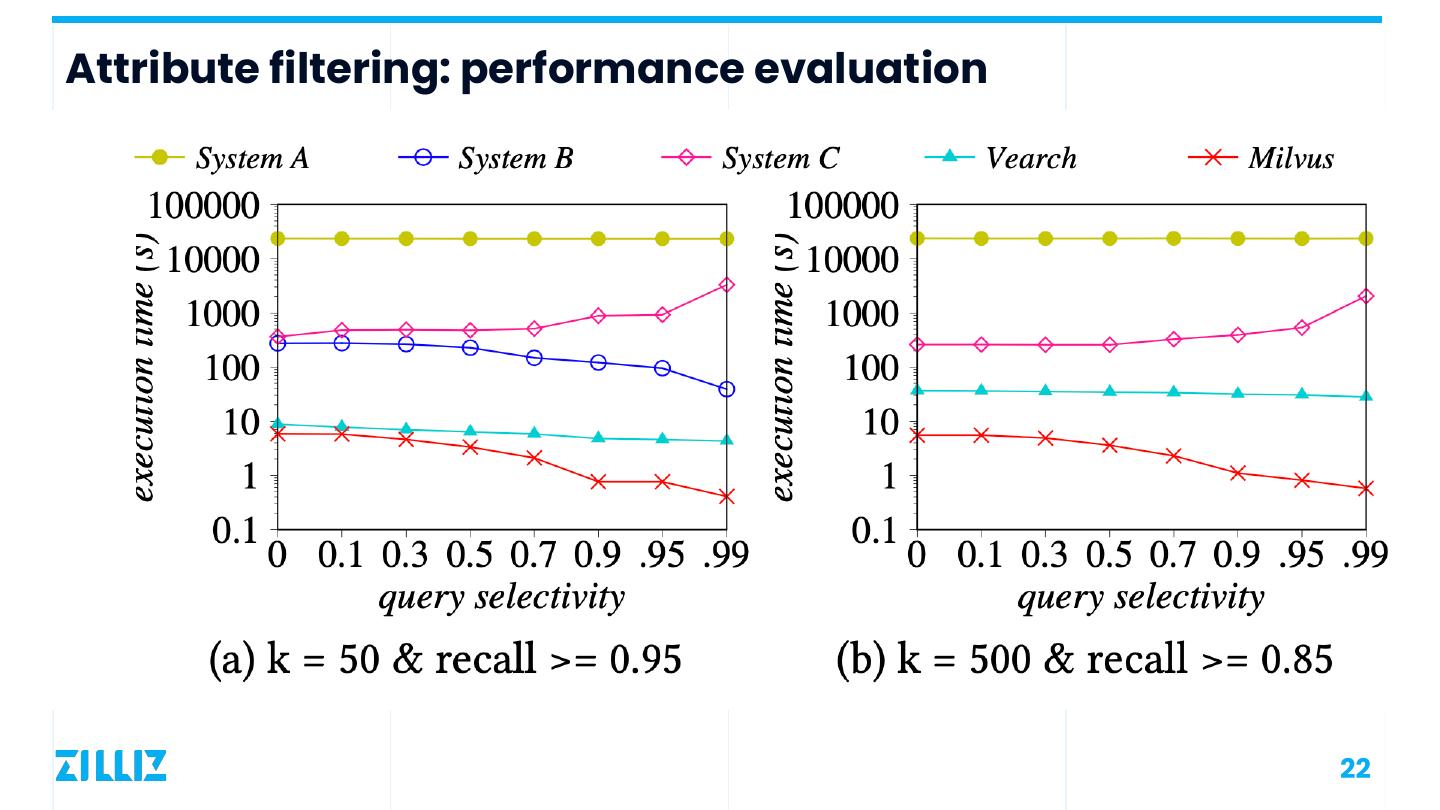
21 .Attribute filtering: problem and strategies Problem: Strategies: Given a query vector qv and a constraint on attributes Ca. Find k entries among all the entries that satisfies Ca, whose vector is the most similar to qv. Vector scan after Vector index Attribute filtering attribute filtering search after after vector index attribute filtering search Examples: Searching for T-shirts similar to an image that cost less than $100. Recommend some country music to me. Attribute-based data Strategy choosing partition, only search based on related partitions estimated cost 21
22 .Attribute filtering: performance evaluation 22
23 .Multi-vector search: problem and solutions Problem: Both data entries v and queries q contains µ vectors. Given a vector similarity function f and a score aggregation function g, find k entries with highest score value: 𝑔(𝑓 𝑣! , 𝑞! , 𝑓 𝑣" , 𝑞" , … , 𝑓(𝑣# , 𝑞# )) Decomposable cases: vector fusion General cases: iterative merging 𝑔 𝑓 𝑣! , 𝑞! , 𝑓 𝑣" , 𝑞" , … , 𝑓 𝑣# , 𝑞# Search top- k’ result for each vector = 𝑓 ℎ 𝑣! , … , 𝑣# , ℎ′ 𝑞! , … , 𝑞# Try to find result with NRA Example: if k results can be determined if then Return results f: inner product h: concatenation, Otherwise g: weighted sum h’: weighted Increase k’ and repeat concatenation 23
24 .Multi-vector search: performance evaluation 24
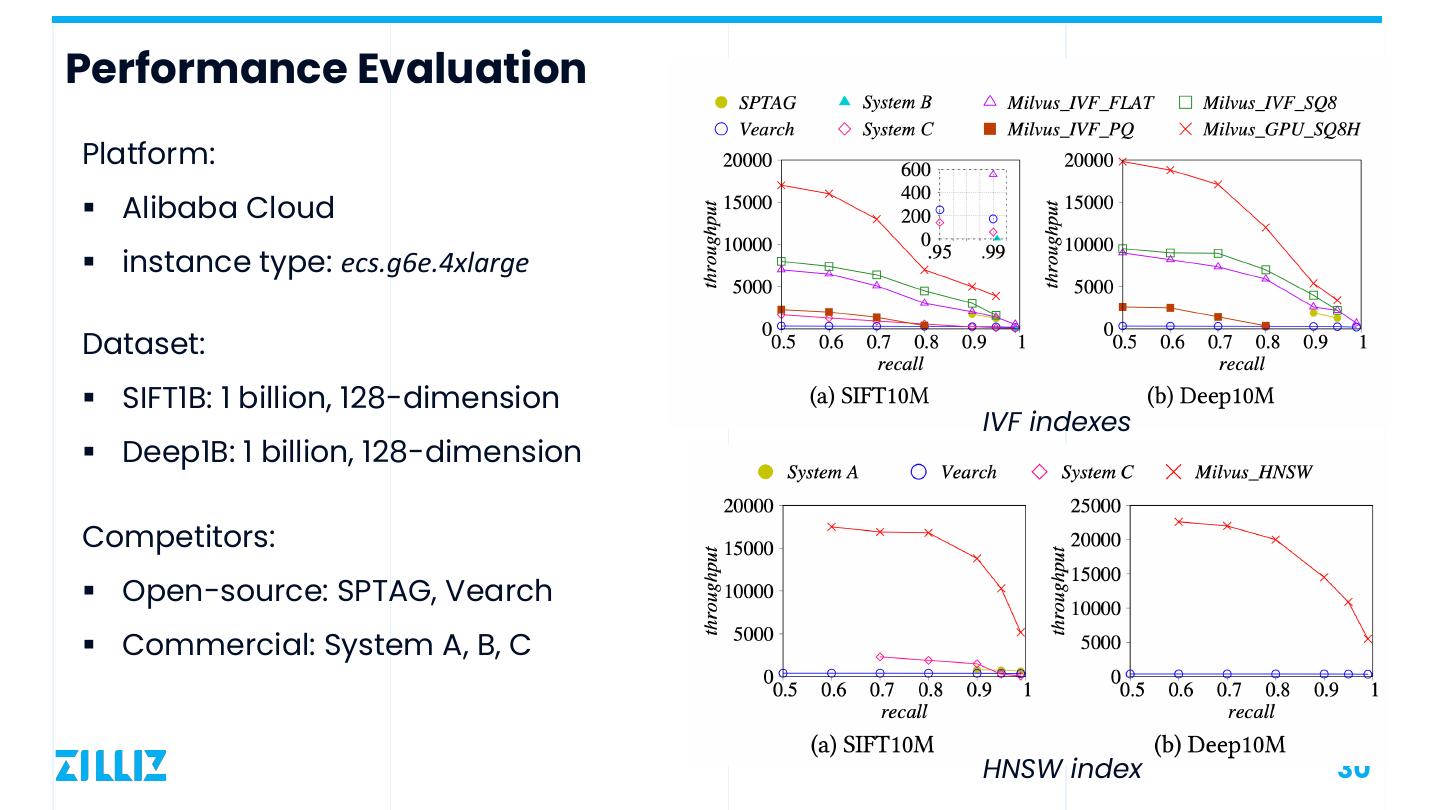
25 .Agenda Design Overview Optimizations Advanced Query Processing System Implementation Example Applications Performance Evaluation 25
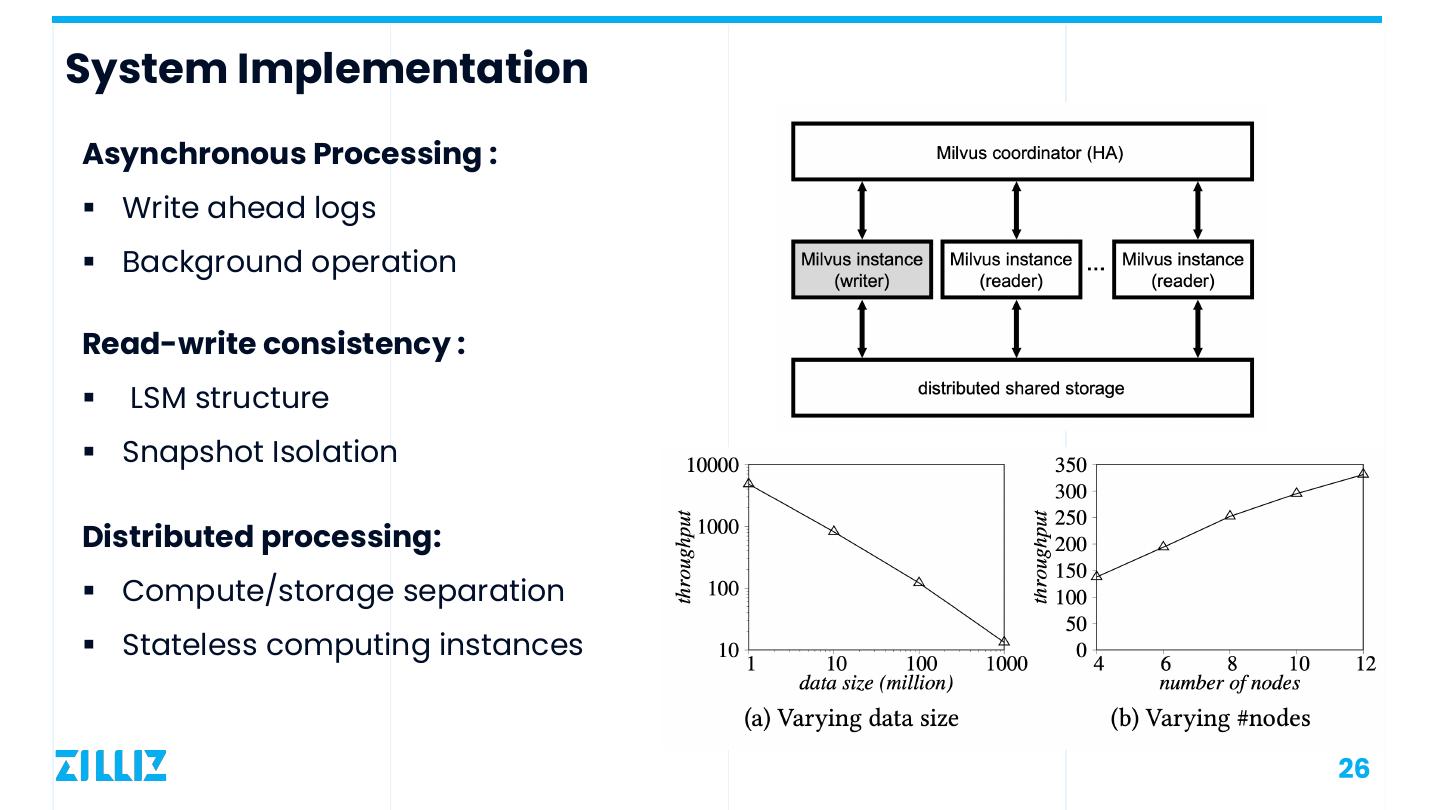
26 .System Implementation Asynchronous Processing : § Write ahead logs § Background operation Read-write consistency : § LSM structure § Snapshot Isolation Distributed processing: § Compute/storage separation § Stateless computing instances 26
27 .Agenda Design Overview Optimizations Advanced Query Processing System Implementation Example Applications Performance Evaluation 27
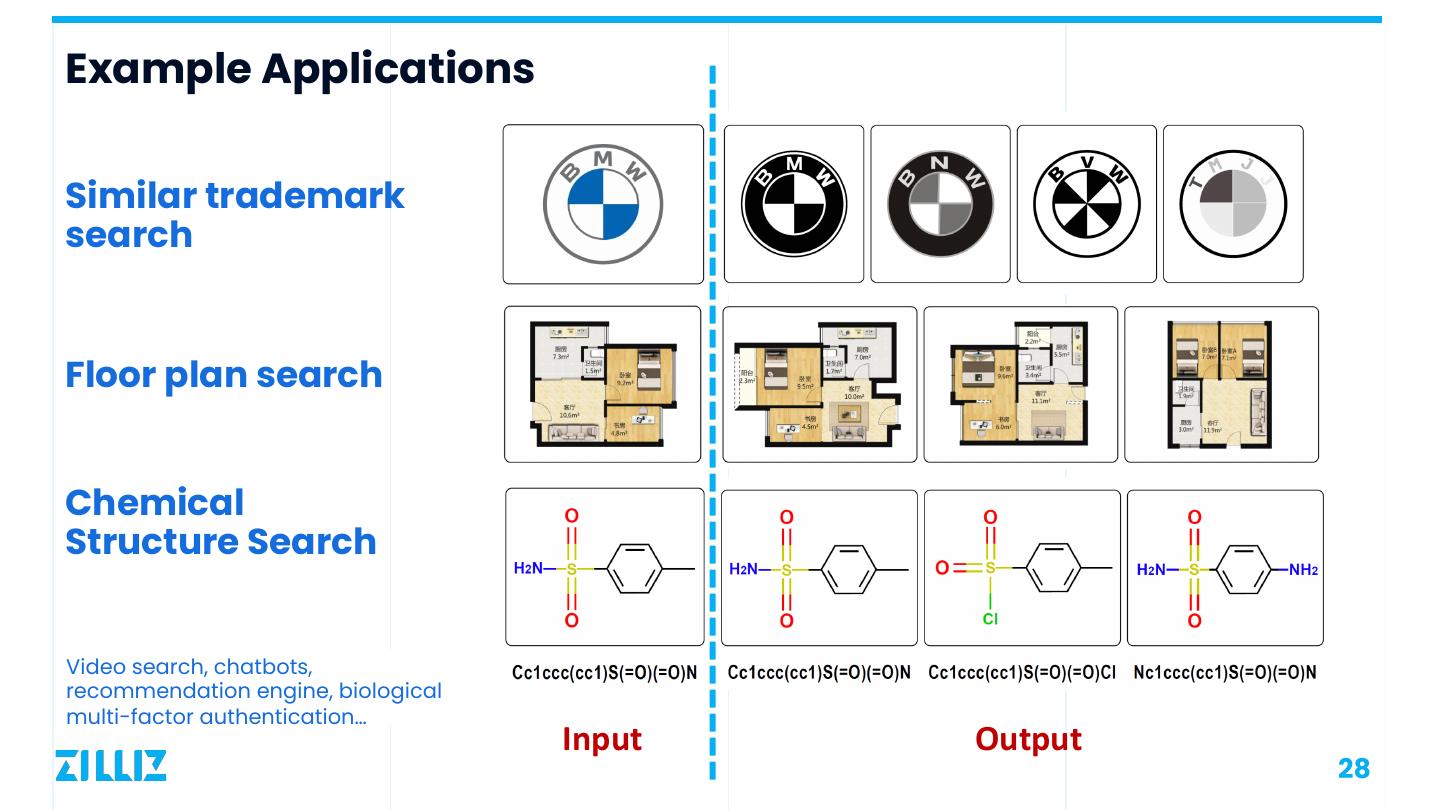
28 .Example Applications Similar trademark search Floor plan search Chemical Structure Search Video search, chatbots, recommendation engine, biological multi-factor authentication… Input Output 28
29 .Agenda Design Overview Optimizations Advanced Query Processing System Implementation Example Applications Performance Evaluation 29
3秒后跳转登录页面
去登陆

