Hudi在字节跳动推荐系统中的实践-管梓越
分享
点赞
0
收藏
1
下载 33
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
视频嵌入链接
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
Hudi在字节跳动推荐系统中的实践
本次分享会涉及在搜索推荐广告等机器学习系统中两个场景下的数据湖应用。首先是在离线特征工程迭代场景中,实现离线样本数据的流式/批式插入,更新,删除,merge,从而支持模型训练场景中的样本拼接,特征回溯,数据退场等需求。除此之外,在推荐系统中,大量使用了LSM Tree型的存储引擎来作为数据存储,为了能够方便得在离线批式场景中高效使用这些数据,我们使用数据湖来承接这类存储引擎的CDC需求,从而降低这类数据的获取和消费门槛,提高了使用效率。在这过程中,我们还会分享在应对高吞吐,复杂数据模型和多种数据语义等性能挑战的一些实践。
管梓越,大数据开发工程师, 现就职于字节跳动推荐架构部门。专注于hudi在机器学习场景下的开发与应用。支持抖音,今日头条等产品的机器学习场景下的架构工作
展开查看详情
1 .HUDI 在字节跳动推荐系统中的实践
管梓越
�
2 .ByteDance
目录
01 02 03 04 05
场景需求 设计选型 功能支持 性能调优 未来展望
�
3 .01 场景需求
BigTable CDC
特征工程
�
4 .场景需求
用户日志/其他日志
应用 埋点 展现 外部数据源
instance
推荐引擎 触发 召回 粗排 精排 重排
CDC
数据服务 正排 倒排 profile 向量库 参数服务
近线处理 增量建库 状态变更 统计服务 特征生成 模型训练
状态存储:Tbase
离线/实时存储 样本数据 用户日志 文章数据 离线挖掘
�
5 .场景需求
BigTable
特征工程
CDC
• 获取宽表型存储的CDC • Instance和label的拼接
• 提供高效的OLAP查询 • 提供高效IO减枝的访问
• 提供线上无感的数据同步 • 高维复杂数据(万列,嵌套类型,稀疏)
• 数据不规整(大小,格式) • 高吞吐近实时写入(百GB/s)
• 需求不统一 • EB级存储
�
6 .02 设计选型
多种数据湖引擎
MOR or COW
索引类型
计算引擎
�
7 .设计选型
Iceberg: 良好的数据抽象和优秀的接口设计
数据湖选型 Hudi: 灵活的接口实现,全局索引,MOR
DeltaLake: 和spark强绑定
实时写入 COW or MOR
索引类型 Simple Bloom HbaseIndex
计算引擎 Spark or Flink | RDD API or DataSource API
�
8 .03 功能支持
MVCC
Schema注册系统
�
9 .MVCC
Payload 自定义数据结构 时间戳 视图访问 Append
�
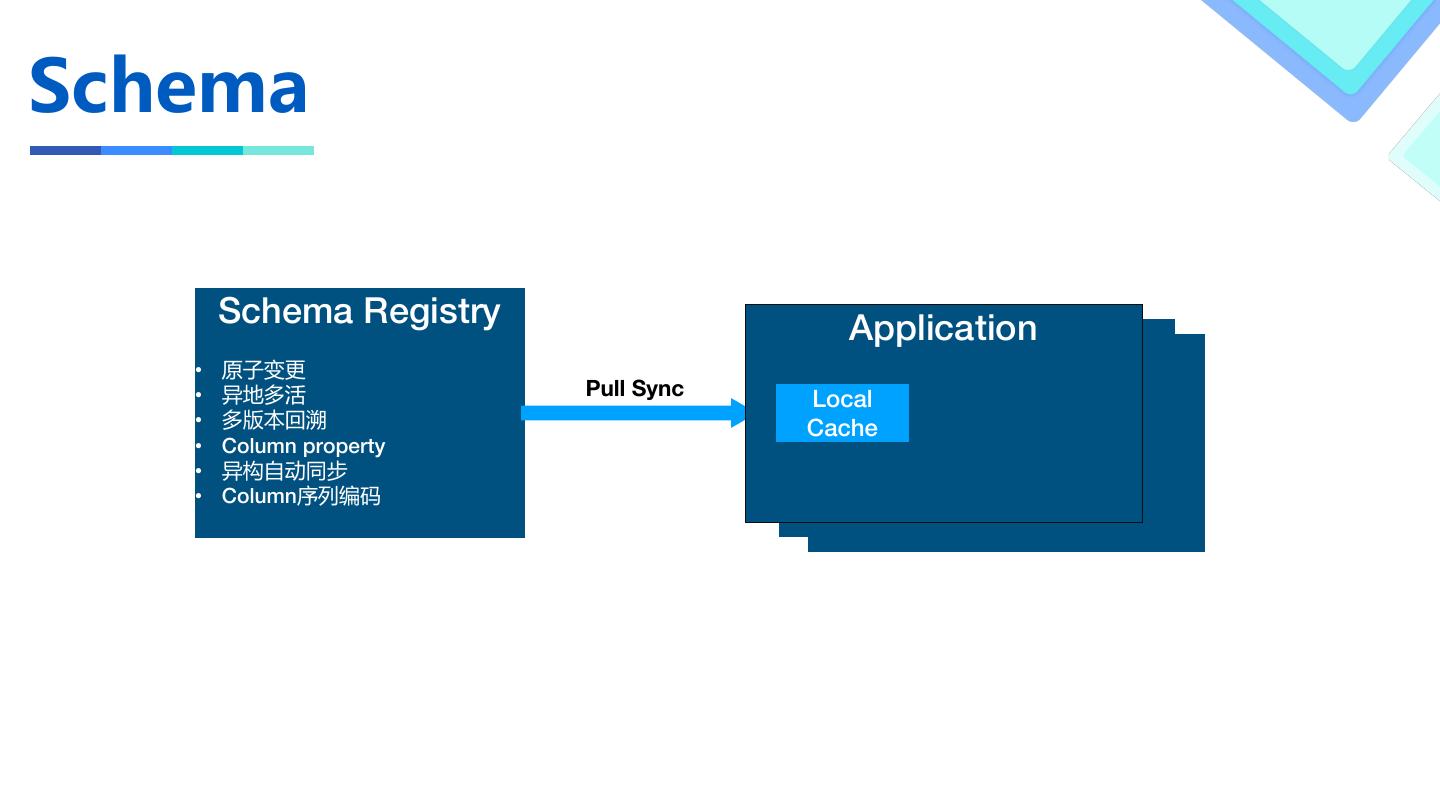
10 .Schema
Schema Registry Application
Application
Application
• 原子变更
• 异地多活 Pull Sync Local
• 多版本回溯 Cache
• Column property
• 异构自动同步
• Column序列编码
�
11 .04 性能调优
序列化
Compaction
HDFS SLA
流程优化
�
12 . 序列化
现状
• 1000-10000+列
• 平均列名20字符
• 单行10MB+
• Resolver 4G+
• 序列化时间30%+
1 2 3
列名id化 减少反序列化次数 PreCompile Implementation*
schema对象全局单例 GC 调优 Fix code length exceed
https://github.com/linkedin/avro-util *
�
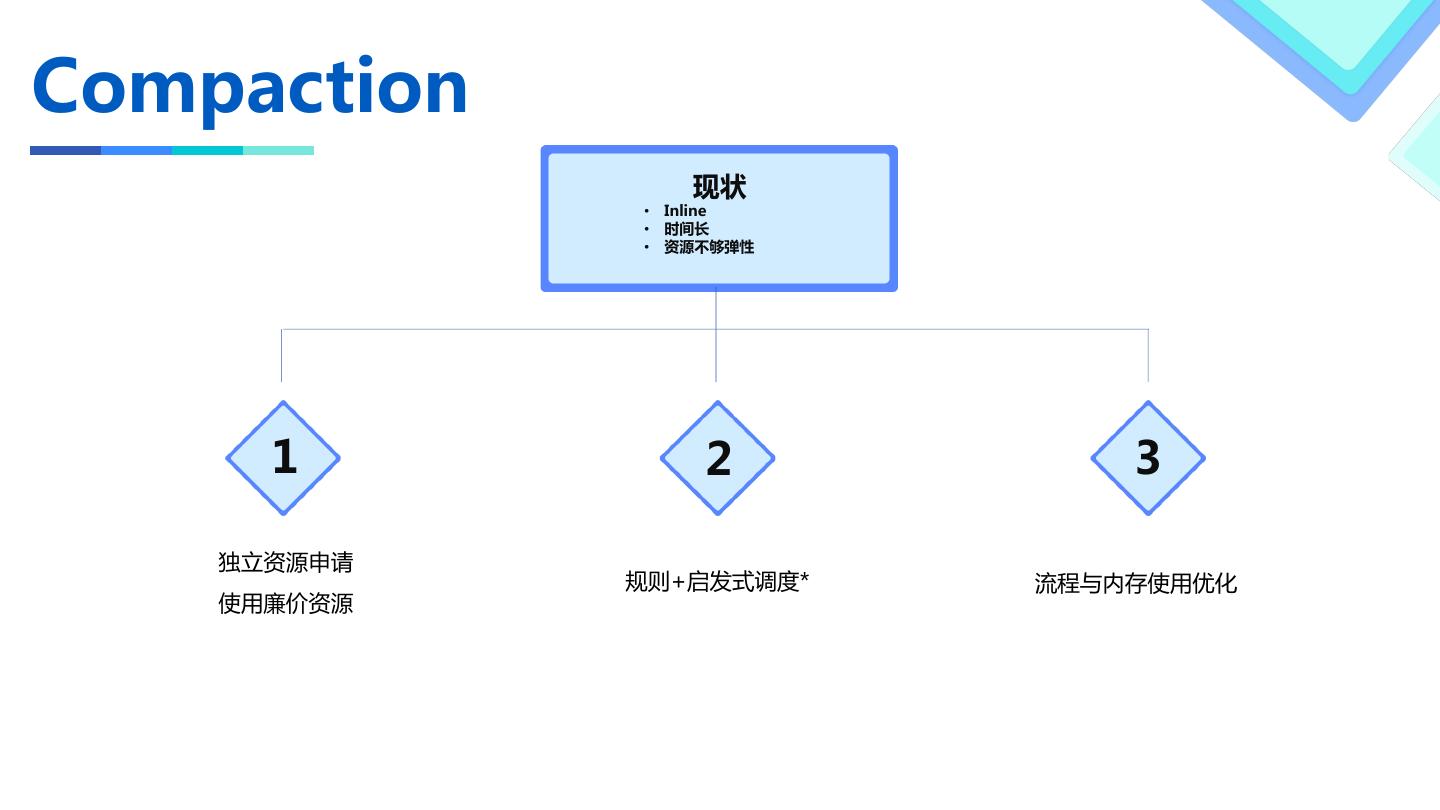
13 .Compaction
现状
• Inline
• 时间长
• 资源不够弹性
1 2 3
独立资源申请
规则+启发式调度* 流程与内存使用优化
使用廉价资源
�
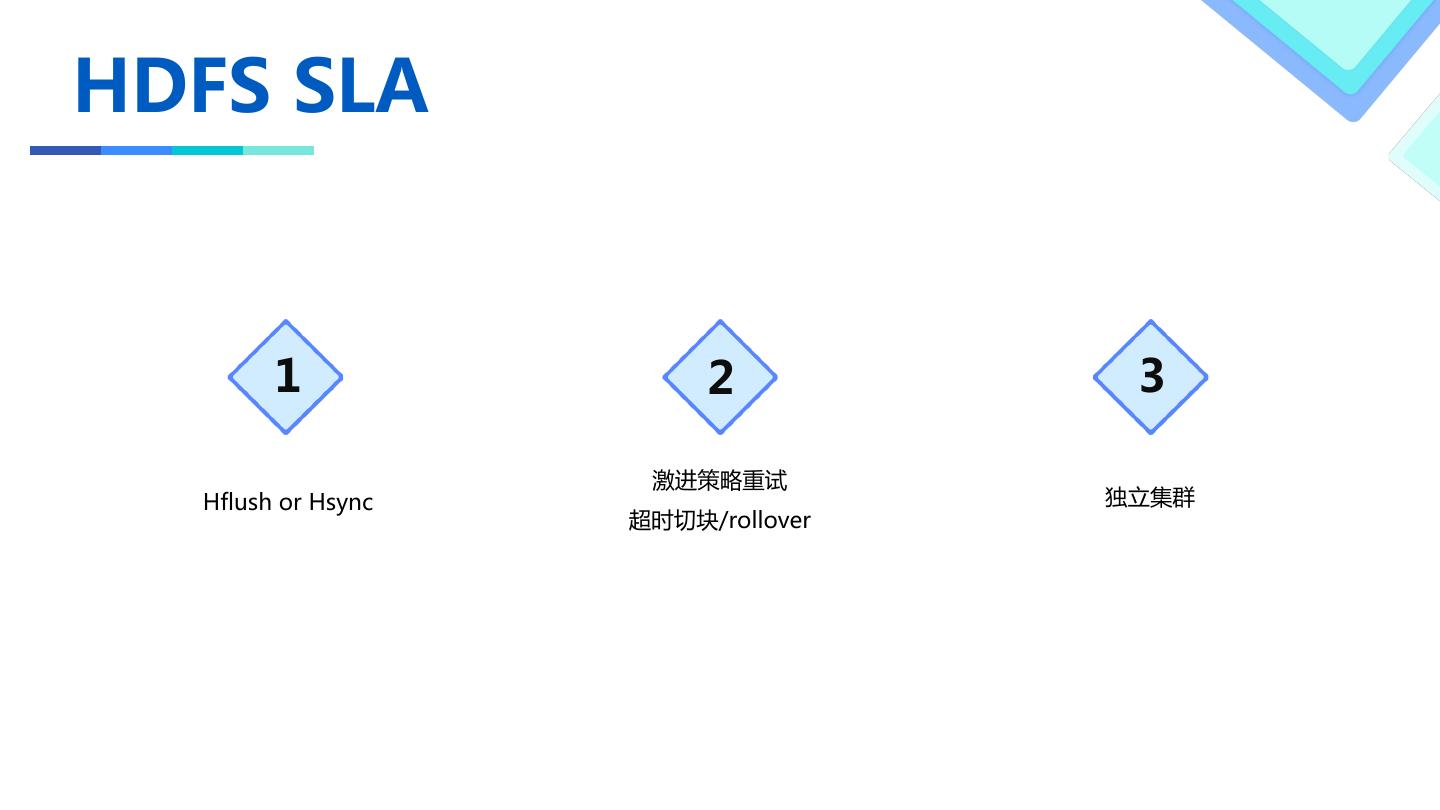
14 .HDFS SLA
1 2 3
激进策略重试
Hflush or Hsync 独立集群
超时切块/rollover
�
15 .流程优化
一些琐碎的流程优化与bug fix
• 避免rewrite操作
• 插件式的record size评估
• 基于row count的小文件评估
• 简易的adaptive execution 规避写入倾斜
• 自定义partitioner 优化shuffle
• Bulkinsert 索引bulkload
• Timeline缓存不一致更新
• ….
�
16 .05 未来展望
产品化
生态对接
成本优化
性能优化
存储语义
�
17 .未来展望
1 2 3 4 5
产品化 生态对接 成本优化 性能优化 存储语义
用户友好编程 Flink 存储冷热分层 快设备 增量触发
可运维性 跨语言跨框架格式 序列化优化 向量化 Mutate
简化调优 通用访问 混部潮汐计算 新格式索引 点查与scan
内部生态完善 优化compaction方式 流程重构 数据重整
�
19 .We are hiring!
团队目前招聘以下岗位:
字节跳动推荐架构团队
• 大数据开发工程师
- 负责抖音、今日头条、西瓜视频等产品的推荐架构
深入了解大数据生态组件的原理
的设计和开发,保障系统稳定和高可用;
• 存储研发工程师
- 负责在线服务、离线数据流性能优化,解决系统瓶
熟悉rocksdb/Hbase, 熟悉分布式存储
颈,降低成本开销;
• 推荐/搜索/广告相关推荐架构工程师、后端
- 抽象系统通用组件和服务,建设推荐中台、数据中
开发工程师
台,支撑新产品快速孵化以及为ToB赋能;
• 深度学习框架研发
- 设计和实现高并发、高吞吐的服务框架、RPC框
• devops/研发效能/编译优化
架,为业务提供快速构建服务以及高性能在线
• 网络通信组件/rpc开发
serving能力;
• 运维工程师
- 实现灵活可扩展的高性能存储系统和计算模型,打
通离在线数据流,构建统一的数据中台,支持推荐
工作地点:北京/上海/杭州/新加坡/山景城
/搜索/广告;
欢迎自荐&推荐,岗位相关问题欢迎私戳微信
或将简历投递至邮箱
guanziyue.gzy@bytedance.com
�