展开查看详情
1 .TGIP-CN 026
Pulsar Flink 连接器的介绍与使⽤
赵建云
StreamNative
�
2 .Who am I
●赵建云( Jianyun Zhao )
●Apache Pulsar contributor
●StreamNative Software Engineer
�
3 .Pulsar Flink 连接器
- Pulsar介绍
- Flink介绍
- 连接器介绍
- 实战
�
4 . Pulsar
Apache Pulsar 是云原⽣的事件流平台
连接、存储、数据处理
• 连接:Pulsar clients,IO connectors,Protocol handlers
• 存储: Apache BookKeeper,Tiered storage
• 数据处理:
• Pulsar Function - 轻量⽆服务计算
• Spark、Flink - 统⼀数据处理
• Presto - SQL交互式查询
�
6 .Pulsar 有结构的数据
• 内置的Schema注册
• 在服务端的消息服务共识
• Topic级别的消息结构
• 直接产⽣、消费有结构的数据
• Pulsar进⾏消息验证
• ⽀持消息版本的演化
�
7 . Flink
Apache Flink 是⼀个在⽆界和有界数据流上进⾏状态计算的框架和分布式处理引擎。 Flink 可以在所有常⻅的集群环境中运
⾏,并以 in-memory 的速度和任意的规模进⾏计算。
�
8 . Flink
Flink 框架,⼤致可以分为三块内容,从左到右依次为:数据输⼊、Flink 数据处理、数据输出。
�
9 . X
Apache Flink是当下最流⾏的数据计算引擎,Apache Pulsar是消息订阅系统中的翘楚。当它们遇到⼀起时,会发⽣什么有趣
的事情呢?
�
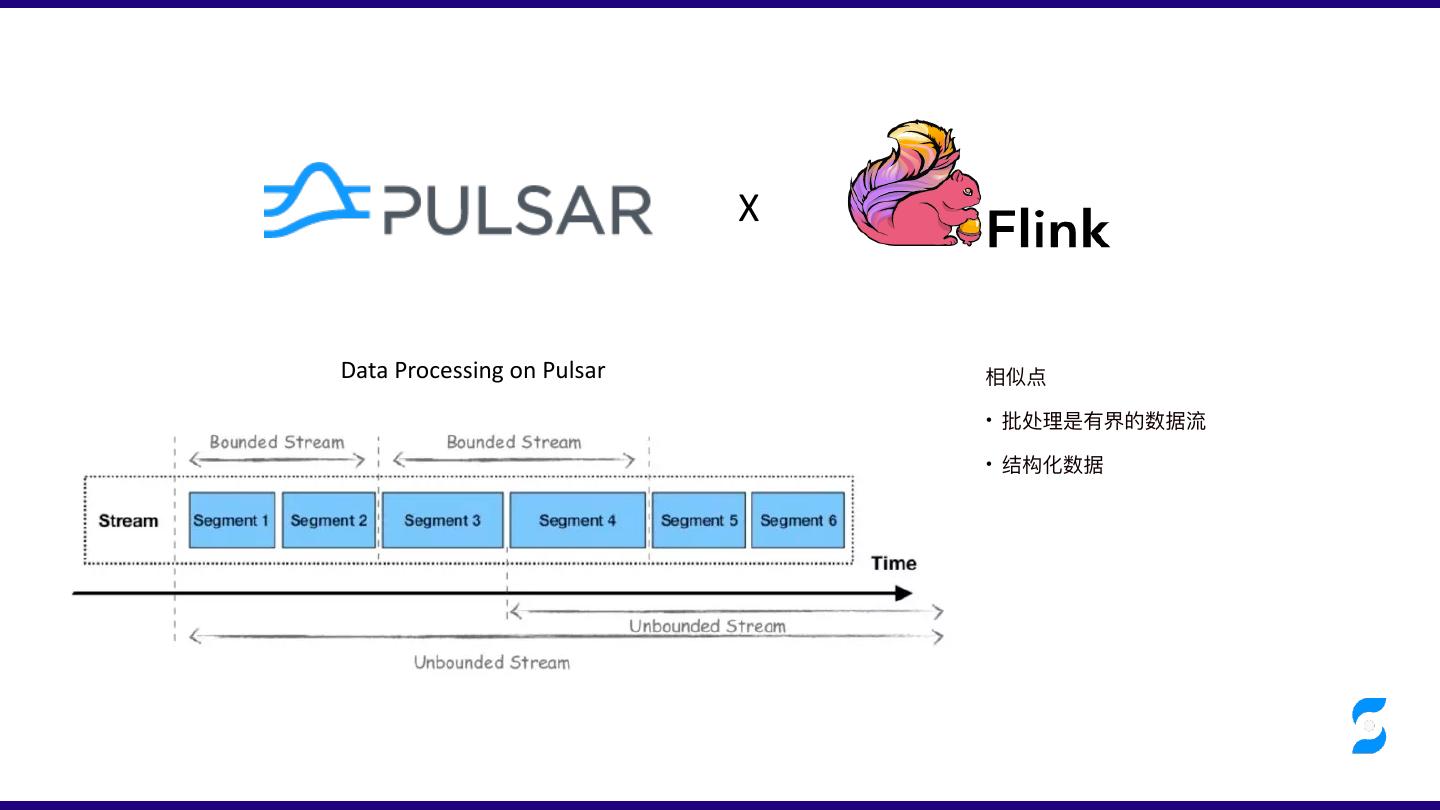
10 . X
Data Processing on Pulsar 相似点
• 批处理是有界的数据流
• 结构化数据
�
11 . X
Pulsar 能以不同的⽅式与 Apache Flink 融合,⼀些可⾏的融合包括:
• 使⽤流式连接器(Streaming Connectors)⽀持流式⼯作负载,
• 使⽤批式源连接器(Batch Source Connectors)⽀持批式⼯作负载。
• Pulsar 还提供了对 Schema 的原⽣⽀持,可以与 Flink 集成并提供对数据的结构化访问,例如,使⽤ Flink SQL 在 Pulsar
中查询数据。
从架构的⻆度来看,我们可以想象两个框架之间的融合,使⽤ Apache Pulsar 作为统⼀的数据层视图,使⽤ Apache Flink 作
为统⼀的计算、数据处理框架和 API。
�
12 .Pulsar Flink 连接器
https://github.com/streamnative/pulsar-flink
⽀持Flink 1.9或更⾼的版本
⽀持Flink Stream、Batch、Table、Catalog功能
exactly-once 语义的 Source 和 at-least-once 语义的 Sink
Pulsar Topic动态发现
Pulsar Schema⽀持
�
13 .Pulsar Flink 连接器
Pulsar Flink Connector 在使⽤上是⽐较简单的,由⼀个 Source 和⼀个 Sink 组成,Source 的功能就是将⼀个或多个主题下的消息传⼊
到 Flink 的Source中,Sink的功能就是从 Flink 的 Sink 中获取数据并放⼊到某些主题下,在使⽤⽅式上,如下所示:
StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
props.setProperty("topic", "test-source-topic");
props.setProperty("partitiondiscoveryintervalmillis", "5000");
FlinkPulsarSource<String> source = new FlinkPulsarSource<>(serviceUrl, adminUrl, new SimpleStringSchema(), props);
source.setStartFromEarliest();
DataStream<String> stream = see.addSource(source);
FlinkPulsarSink<Person> sink = new FlinkPulsarSink(
serviceUrl,
adminUrl,
Optional.of(topic), // mandatory target topic or use `Optional.empty()` if sink to different topics for each record
props,
TopicKeyExtractor.NULL, // replace this to extract key or topic for each record
Person.class,
RecordSchemaType.AVRO);
stream.addSink(sink);
�
14 .精确⼀次 Pulsar 中的 MessageId 是全局唯⼀且有序的,并且对应Pulsar 中
的实际物理存储,因此实现 Exactly Once, 只需要结合Flink 的
Checkpoint 机制,将 MessageId 存储到 Checkpoint即可。
对于连接器的 Source 任务,在每次触发 Checkpoint 的时候,会将
各个分区当前处理的 MessageId 保存到状态存储⾥⾯,这样在任务
重启的时候,每个分区都可以通过 Pulsar 提供的 Reader seek 接
⼝找到 MessageId 对应的消息位置,然后从这个位置之后读取消息
数据。
通过 Checkpoint 机制,还能够向存储数据的节点发送数据使⽤完毕
的通知,从⽽能准确删除过期的数据,做到存储的合理利⽤。
�
15 . Topic动态发现
流数据分析应⽤是⻓时间执⾏的,因此在分析应⽤执⾏期间,Topic 的分区或者⽤户订阅的 Topic 会动态增删。为了使我们的
流计算应⽤可以感知这种变化,可以启动⼀个定时任务,定期检查是否新增 Topic,并启动 reader 处理数据。
�
16 . Pulsar Schema⽀持
Pulsar ⽀持定义 Avro schema和写⼊消费 avro、json、protobuf等格式的Message,使得消息结构化。这样带来了Pulsar
SQL、Function等⽣态⽀持,⽤户可以在更多的系统中操作数据。Pulsar Flink 连接器中Source、Sink对于Pulsar Schema均
做了⽀持,使数据在Pulsar、Flink中流转,保持了⼀致结构化,⽽不是冰冷冷的bytes。
�
17 . 良好的拓展性 public FlinkPulsarSource(
String adminUrl,
ClientConfigurationData clientConf,
PulsarDeserializationSchema<T>
对于Source,我们通常不会满⾜Message中只拿到了value数 deserializer,
Properties properties) {
据,⽽是会希望能获取到Message的消息发布时间、扩展
\\ 初始化FlinkPulsarSource参数
Properties属性等。 Pulsar Flink连接器提供了⾃定义的数据解码 }
接⼝,⽤户选择可以实现PulsarDeserializationSchema来实现⾃ public FlinkPulsarSink(
String adminUrl,
⼰的需求。
Optional<String> defaultTopicName,
对于Sink,⽀持使⽤每条记录中的topic来输出消息 ClientConfigurationData clientConf,
Properties properties,
TopicKeyExtractor<T> topicKeyExtractor,
Class<T> recordClazz,
RecordSchemaType recordSchemaType) {
}
�
18 . Stream
Source⼯作模式
StreamExecutionEnvironment see =
StreamExecutionEnvironment.getExecutionEnvironment();
Properties props = new Properties();
props.setProperty("topic", "test-source-topic");
props.setProperty("partitiondiscoveryintervalmillis", "5000");
FlinkPulsarSource<String> source = new FlinkPulsarSource<>(serviceUrl,
adminUrl, new SimpleStringSchema(), props);
source.setStartFromEarliest();
DataStream<String> stream = see.addSource(source);
�
19 . Catalog
Flink会在当前⽬录和数据库中搜索表,视图和UDF。 要使⽤
Pulsar Catalog并将Pulsar中的topic作为Flink中的表对待,flink tableEnv.useCatalog("pulsarcatalog")
home中的 ./conf/sql-client-defaults.yaml 中定义pulsarcatalog。 tableEnv.useDatabase("public/default")
tableEnv.scan(“topic0")
catalogs:
- name: pulsarcatalog
type: pulsar Flink SQL> USE CATALOG pulsarcatalog;
default-database: public/default
service-url: "pulsar://localhost:6650" Flink SQL> USE `public/default`;
admin-url: "http://localhost:8080"
Flink SQL> select * from topic0;
注意:由于删除操作具有危险性,catalog中删除tenant/namespace、
操作不被⽀持。
Flink
�
20 . create table test_flink_sql(
SQL、DDL
`rip` VARCHAR,
`rtime` VARCHAR,
`uid` bigint,
`rchannel` VARCHAR,
`be_time` bigint,
`be_time` VARCHAR,
`activity_id` VARCHAR,
`country_code` VARCHAR,
`os` VARCHAR,
`recv_time` bigint,
`remark` VARCHAR,
`client_ip` VARCHAR,
`day` as TO_DATE(rtime),
`hour` as date_format(rtime, 'HH')
) with (
'connector.type' = 'pulsar',
'connector.version' = '1',
'connector.topic' = 'persistent://test/test-gray/test_flink_sql',
'connector.service-url' = 'pulsar://xxx',
'connector.admin-url' = 'http://xxx',
'connector.startup-mode' = 'external-subscription',
'connector.sub-name' = 'test_flink_sql_v1',
'connector.properties.0.key' = 'pulsar.reader.readerName',
'connector.properties.0.value' = 'test_flink_sql_v1',
'connector.properties.1.key' = 'pulsar.reader.subscriptionRolePrefix',
'connector.properties.1.value' = 'test_flink_sql_v1',
'connector.properties.2.key' = 'pulsar.reader.receiverQueueSize',
'connector.properties.2.value' = '1000',
'connector.properties.3.key' = 'partitiondiscoveryintervalmillis',
'connector.properties.3.value' = '5000',
'format.type' = 'json',
'format.derive-schema' = 'true',
'format.ignore-parse-errors' = 'true',
'update-mode' = 'append'
);
�
21 . 新特性
- Pulsar 的 key-shared 订阅模式,⽀持更细的粒度订阅消息。
- ⽀持Flink Batch,直接从BookKeeper获取数据,提⾼数据的处理效率和降低资源占⽤。
- Pulsar client Auth认证⽀持
�
22 . ⽬前动向
Pulsar Flink 连接器正在积极的合并回Flink社区。
�
23 .扫码⼊群!
Pulsar 中国社区等你加⼊
添加好友后,回复“进群”即可
�