























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Apache Spark + AI开源社区进展&实际案例分享
近年来,AI/ML领域有了长足发展,不断有新模型和算法在各种基准数据集上取得更好的成绩,工业界应用AI/ML的积极性也水涨船高。但要把AI/ML应用到生产,单单模型和算法好是远远不够的。从实验室模型到可扩展和健壮的工业级部署,这中间存在很多繁杂又易错的环节,经常导致很多实际的困难和问题,从而阻碍了AI/ML的大规模应用。这两年,为了构建更好用的、统一的分析和AI的平台,开源社区围绕Apache Spark及周边生态系统进行了一系列的工作。在这个报告中,我们会介绍近期开源社区的相关进展,包括Intel在开源社区中的相关工作,同时也会分享我们在搭建Spark + AI工业级应用中的经验和真实案例。
展开查看详情
1 . Distributed, High-Performance Unified Analytics + AI Platform Deep Learning Framework Distributed TensorFlow, Keras, PyTorch and BigDL for Apache Spark on Apache Spark https://github.com/intel-analytics/bigdl https://github.com/intel-analytics/analytics-zoo Accelerating Data Analytics + AI Solutions At Scale AI
2 . AI • Missing feature handling Shengsheng Huang Intel AnalyticsZoo team
3 . Agenda • Efforts for building unified data analytics + AI in production • Efforts to support emerging AI applications AI
4 . Agenda • Efforts for building unified data analytics + AI in production • Efforts to support emerging AI applications AI
5 . What’s new in spark + ai community Spark 3. 0 • Optimizations on SQL execution (adaptive query execution, dynamic partition pruning ) • DataSourceV2 • Project Hydrogen (Barrier execution mode, Accelerator-aware scheduling, optimized data exchange) • Spark Graph • Spark on Kubernetes • … All for Productivity MLFlow – ML lifecycle management • Tracking – log code, data, config, results of experiments, and compare & query • Projects – code packaging format for reproducible runs on any platform • Models – model packaging format for sending models to diverse deployment tools. Koalas – pandas API on Spark Delta Lake – ACID layer upon data lakes AI
6 . Rationale behind the efforts in community “Hidden Technical Debt in Machine Learning Systems”, Sculley et al., Google, NIPS 2015 Paper • Integration/Injection of heterogenous data models/sources, computation models, software/hardware components, … (e.g. DataSourceV2, Project Hydrogen, Spark Graph) • E2E Workflow, ML Lifecycle, Serving, Deployment, Orchestration, … (e.g. MLFlow, KubeFlow, Seldon, TFX) • Efficiency & Reliability (e.g. SQL-related optimizations, Delta Lake) • Friendly APIs (e.g. Koalas) AI
7 . AI on Big Data High-Performance Unified Analytics + AI Platform Deep Learning Framework Distributed TensorFlow*, PyTorch*, for Apache Spark Keras* and BigDL on Apache Spark software.intel.com/bigdl https://github.com/intel-analytics/analytics-zoo Accelerating DATA Analytics + AI Solutions DEPLOYMENT At SCALE *Other names and brands may be claimed as the property of others. AI
8 . Analytics Zoo Unified End-to-End Data Analytics + AI Platform Use case Recommendation Anomaly Detection Text Classification Text Matching Model Image Classification Object Detection Seq2Seq Transformer BERT Feature Engineering image 3D image text time series Integrated tfpark: Distributed TF on Spark Distributed Keras/PyTorch on Spark Analytics/AI nnframes: Spark Dataframes & ML Distributed Model Serving Pipelines (batch, streaming & online) Pipelines for Deep Learning TensorFlow Keras PyTorch BigDL NLP Architect Apache Spark Apache Flink Backend/ Library Ray MKLDNN OpenVINO Intel® Optane™ DCPMM DL Boost (VNNI) https://github.com/intel-analytics/analytics-zoo AI
9 . Distributed TensorFlow on Spark #pyspark code • Data wrangling and train_rdd = spark.hadoopFile(…).map(…) analysis using PySpark dataset = TFDataset.from_rdd(train_rdd,…) #tensorflow code import tensorflow as tf • Deep learning model slim = tf.contrib.slim images, labels = dataset.tensors development using with slim.arg_scope(lenet.lenet_arg_scope()): TensorFlow or Keras logits, end_points = lenet.lenet(images, …) loss = tf.reduce_mean( \ tf.losses.sparse_softmax_cross_entropy( \ logits=logits, labels=labels)) #distributed training on Spark • Distributed training / optimizer = TFOptimizer.from_loss(loss, Adam(…)) inference on Spark optimizer.optimize(end_trigger=MaxEpoch(5)) Write TensorFlow code inline in PySpark program AI
10 . Object Detection and Image Feature Extraction at JD.com* • Reuse existing Hadoop/Spark clusters for deep learning with no changes (image search, IP protection, etc.) • Efficiently scale out on Spark with superior performance (3.83x speed-up vs. GPU severs) as benchmarked by JD http://mp.weixin.qq.com/s/xUCkzbHK4K06-v5qUsaNQQ https://software.intel.com/en-us/articles/building-large-scale-image-feature-extraction-with-bigdl-at-jdcom *Other names and brands may be claimed as the property of others. AI
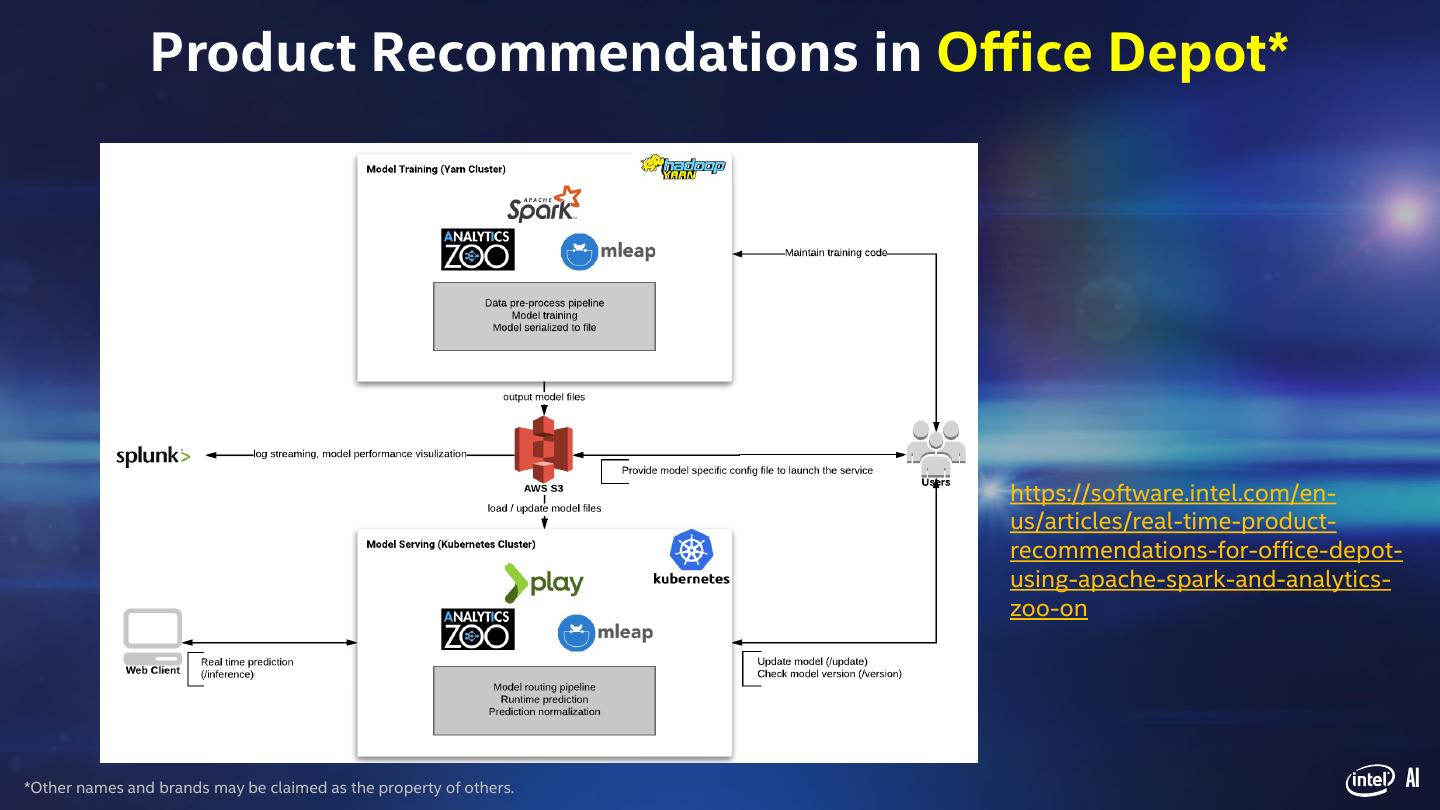
11 . Product Recommendations in Office Depot* https://software.intel.com/en- us/articles/real-time-product- recommendations-for-office-depot- using-apache-spark-and-analytics- zoo-on *Other names and brands may be claimed as the property of others. AI
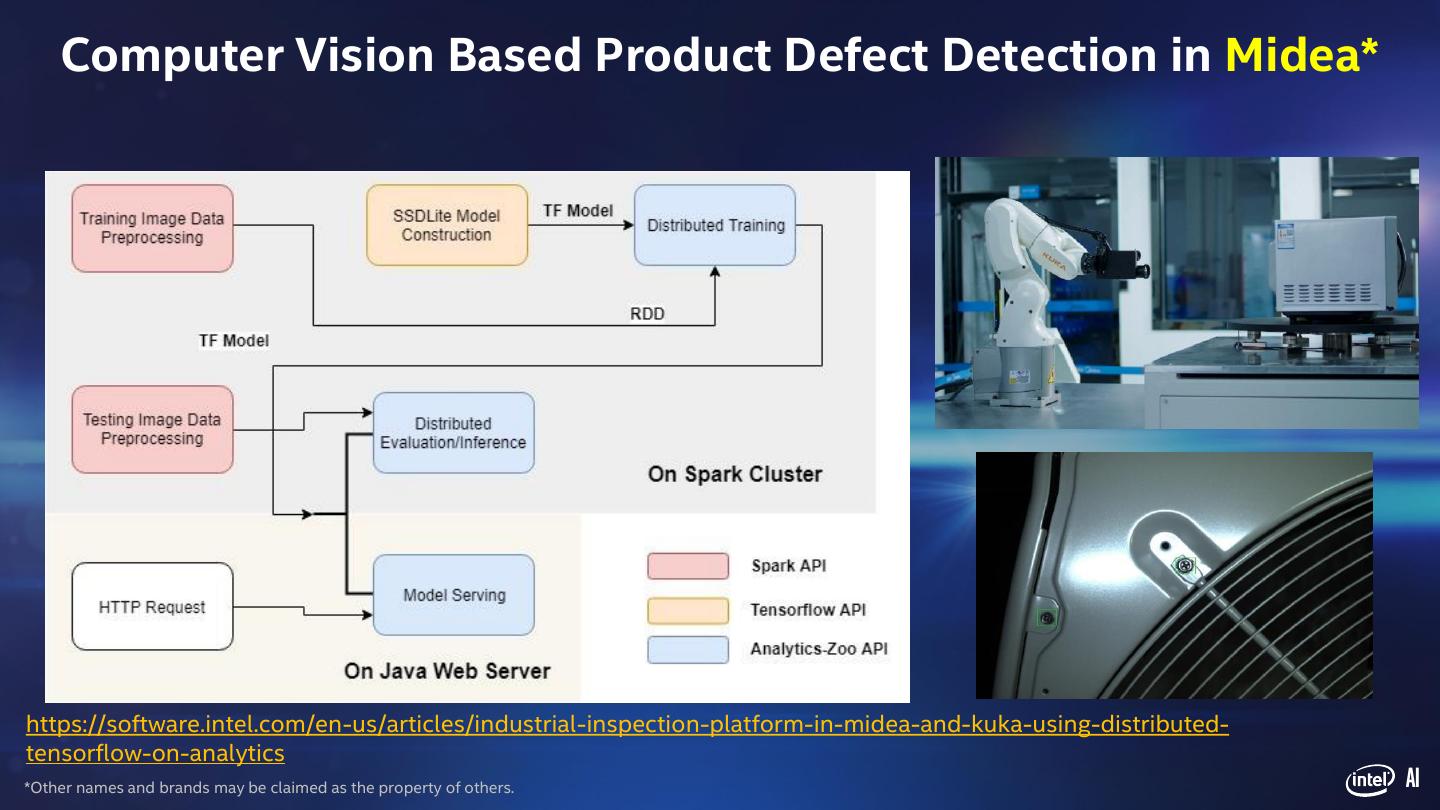
12 . Computer Vision Based Product Defect Detection in Midea* https://software.intel.com/en-us/articles/industrial-inspection-platform-in-midea-and-kuka-using-distributed- tensorflow-on-analytics *Other names and brands may be claimed as the property of others. AI
13 . Particle Classifier for High Energy Physics in CERN* Deep learning pipeline for physics data Model serving using Apache Kafka and Spark https://db-blog.web.cern.ch/blog/luca-canali/machine-learning-pipelines-high-energy-physics-using-apache-spark-bigdl https://databricks.com/session/deep-learning-on-apache-spark-at-cerns-large-hadron-collider-with-intel-technologies *Other names and brands may be claimed as the property of others. AI
14 . Wrap Up Community is making efforts to make Spark a unified Analytics + AI platform Analytics Zoo is also working towards similar goal, by • Seamless integration various components, e.g. Tensorflow, PyTorch, BigDL, etc. • Providing full-stack optimizations involving hardware/software (VNNI, MKL-DNN, OpenVINO, etc.) • Providing ease of use, end-to-end, from laptop to production platform We are both contributors and practitioners. We use, learn, and contribute. AI
15 . Agenda • Efforts for building unified data analytics + AI in production • Efforts to support emerging AI applications AI
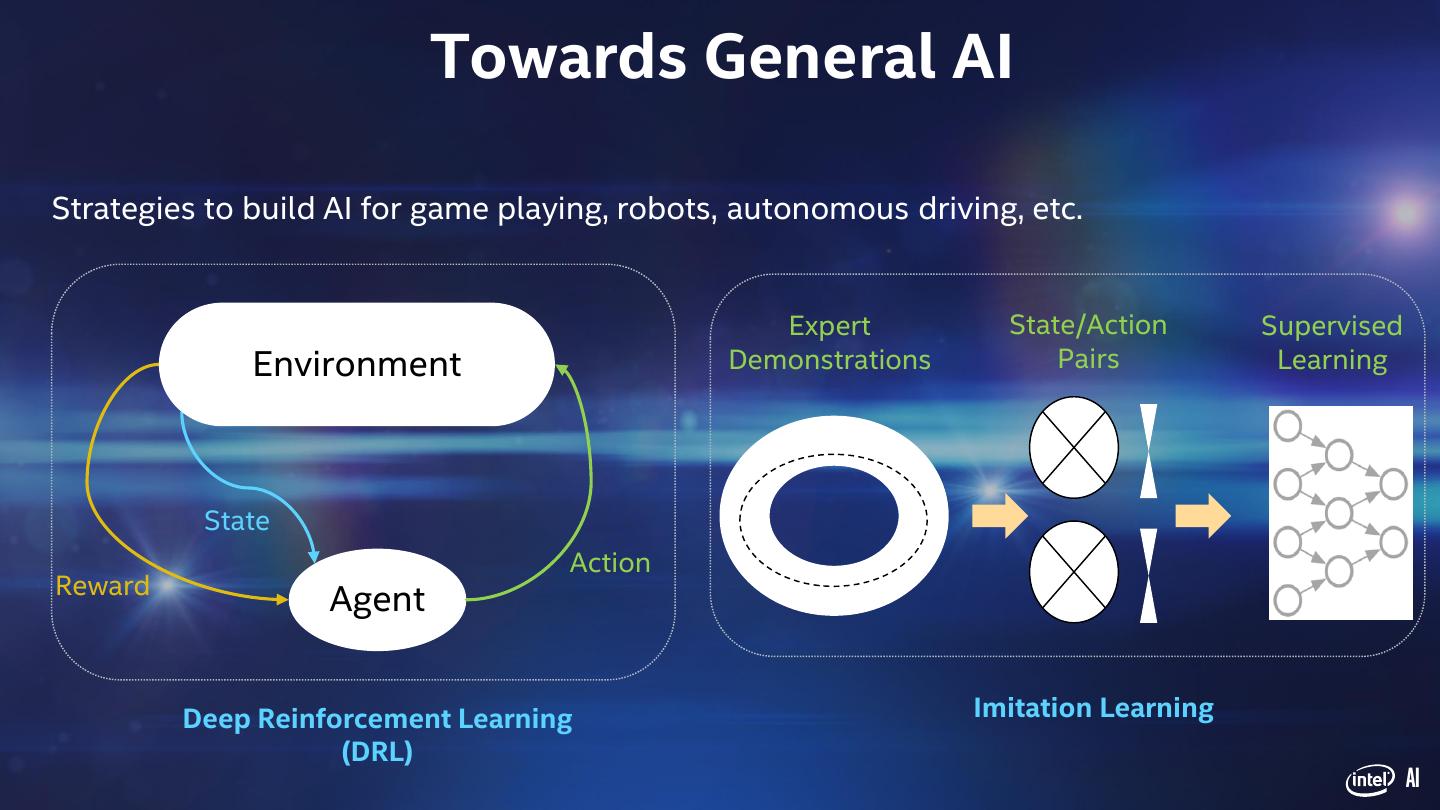
16 . Towards General AI Strategies to build AI for game playing, robots, autonomous driving, etc. Expert State/Action Supervised Environment Demonstrations Pairs Learning State Action Reward Agent Deep Reinforcement Learning Imitation Learning (DRL) AI
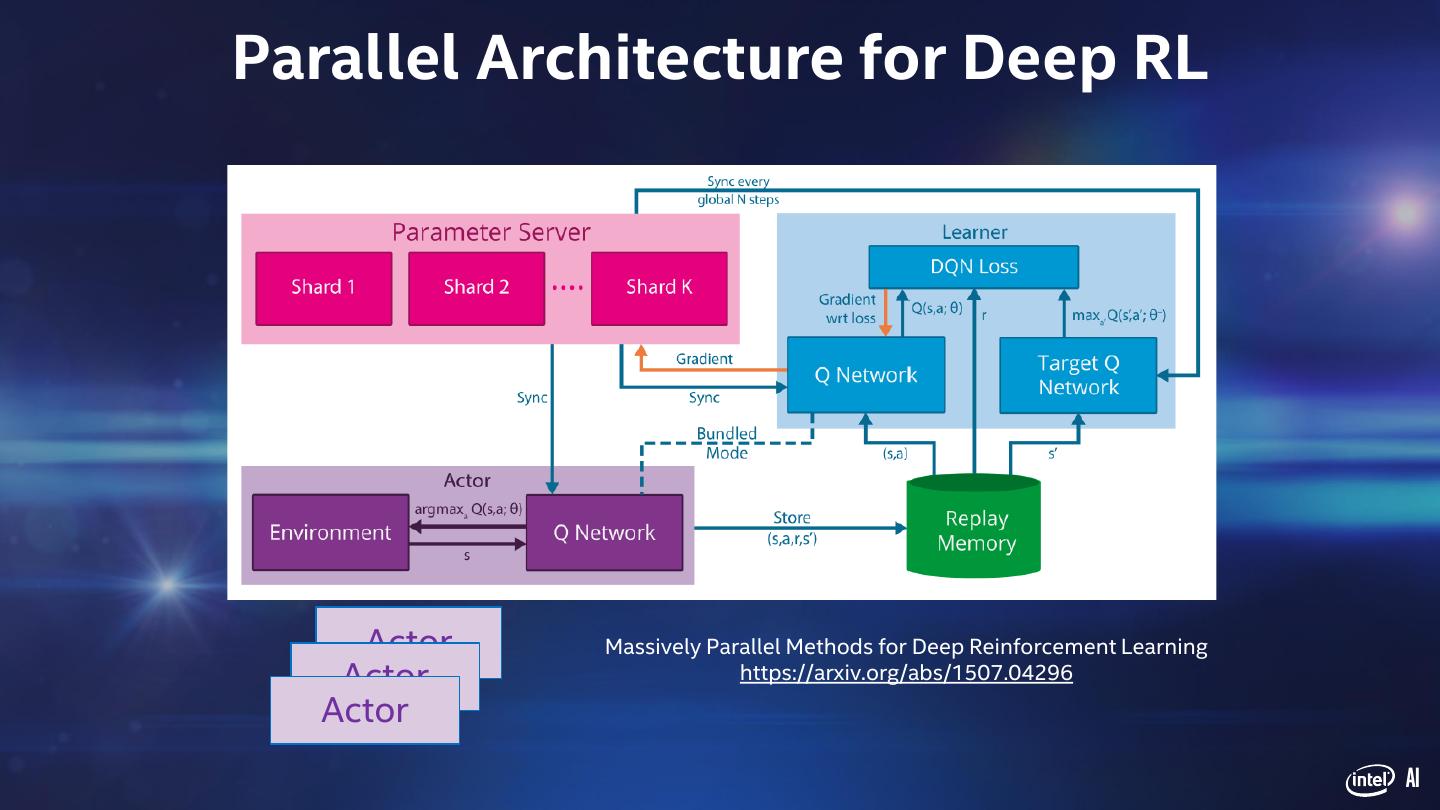
17 .Parallel Architecture for Deep RL Actor Massively Parallel Methods for Deep Reinforcement Learning Actor https://arxiv.org/abs/1507.04296 Actor AI
18 . Ray On Spark Ray • https://github.com/ray-project/ray • a distributed framework for emerging AI applications open-sourced by UC Berkeley RISELab RayOnSpark • a feature recently added to Analytic Zoo • allows users to directly run Ray programs on Apache Hadoop*/YARN https://medium.com/riselab/rayonspark-running-emerging- • Ray applications can be seamlessly integrated into ai-applications-on-big-data-clusters-with-ray-and-analytics- Spark pipeline and operate directly on Spark RDDs or zoo-923e0136ed6a DataFrames. *Other names and brands may be claimed as the property of others. AI
19 . Building AI to Play FIFA FIFA18* - A real-time 3D soccer simulation video game by Electronic Arts* Our Experiment Platform (collaborations w/ SJTU) • runs alongside FIFA game in a non-intrusive way • provides abstraction of game environment (observations, actions, rewards, scores, semantics, etc.) • Implemented agents: RL, IL, Hybrid (IL + RL) Future Work: Results on Shooting Bronze Scenario • Transfer between Google Research Football and FIFA? Score Goal Ratio • Train agents in massive scale w/ Ray & RayOnSpark master 10112.78 92% • Additional models/scenarios, etc. Human demonstrator 7284.98 84.96% IL 10345.18 92.54% https://www.slideshare.net/jason-dai/building-ai-to-play-the-fifa- video-game-using-distributed-tensorflow-on-analytics-zoo Agent RL (Policy Gradient) 5606.31 40.25% Hybrid (RL+IL) 10514.43 95.59% AI *Other names and brands may be claimed as the property of others.
20 . Scalable AutoML for Time Series Analysis AutoML Framework Time Series Forecasting w/ AutoML • Data processing and feature engineering • Neural network based (hybrid) models https://medium.com/riselab/scalable-automl-for-time-series- • Automated feature selection, model selection, hyper prediction-using-ray-and-analytics-zoo-b79a6fd08139 parameter tuning AI
21 . Wrap Up We’re extending the Spark stack to support emerging AI applications • RayOnSpark We’re building emerging AI applications • Building AI to play FIFA • Scalable AutoML for Time Series Analysis AI
22 . More Information on Analytics Zoo • Project website • https://github.com/intel-analytics/analytics-zoo • Tutorials • CVPR 2018: https://jason-dai.github.io/cvpr2018/ • AAAI 2019: https://jason-dai.github.io/aaai2019/ • “BigDL: A Distributed Deep Learning Framework for Big Data” • In proceedings of ACM Symposium on Cloud Computing 2019 (SOCC’19) • Use cases • Azure, CERN, MasterCard, Office Depot, Tencent, Midea, etc. • https://analytics-zoo.github.io/master/#powered-by/ AI
23 .
24 .Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations, and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit intel.com/performance. Intel does not control or audit the design or implementation of third-party benchmark data or websites referenced in this document. Intel encourages all of its customers to visit the referenced websites or others where similar performance benchmark data are reported and confirm whether the referenced benchmark data are accurate and reflect performance of systems available for purchase. Optimization notice: Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor- dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice. Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software, or service activation. Performance varies depending on system configuration. No computer system can be absolutely secure. Check with your system manufacturer or retailer or learn more at intel.com/benchmarks. Intel, the Intel logo, Intel Inside, the Intel Inside logo, Intel Atom, Intel Core, Iris, Movidius, Myriad, Intel Nervana, OpenVINO, Intel Optane, Stratix, and Xeon are trademarks of Intel Corporation or its subsidiaries in the U.S. and/or other countries. *Other names and brands may be claimed as the property of others. © Intel Corporation AI
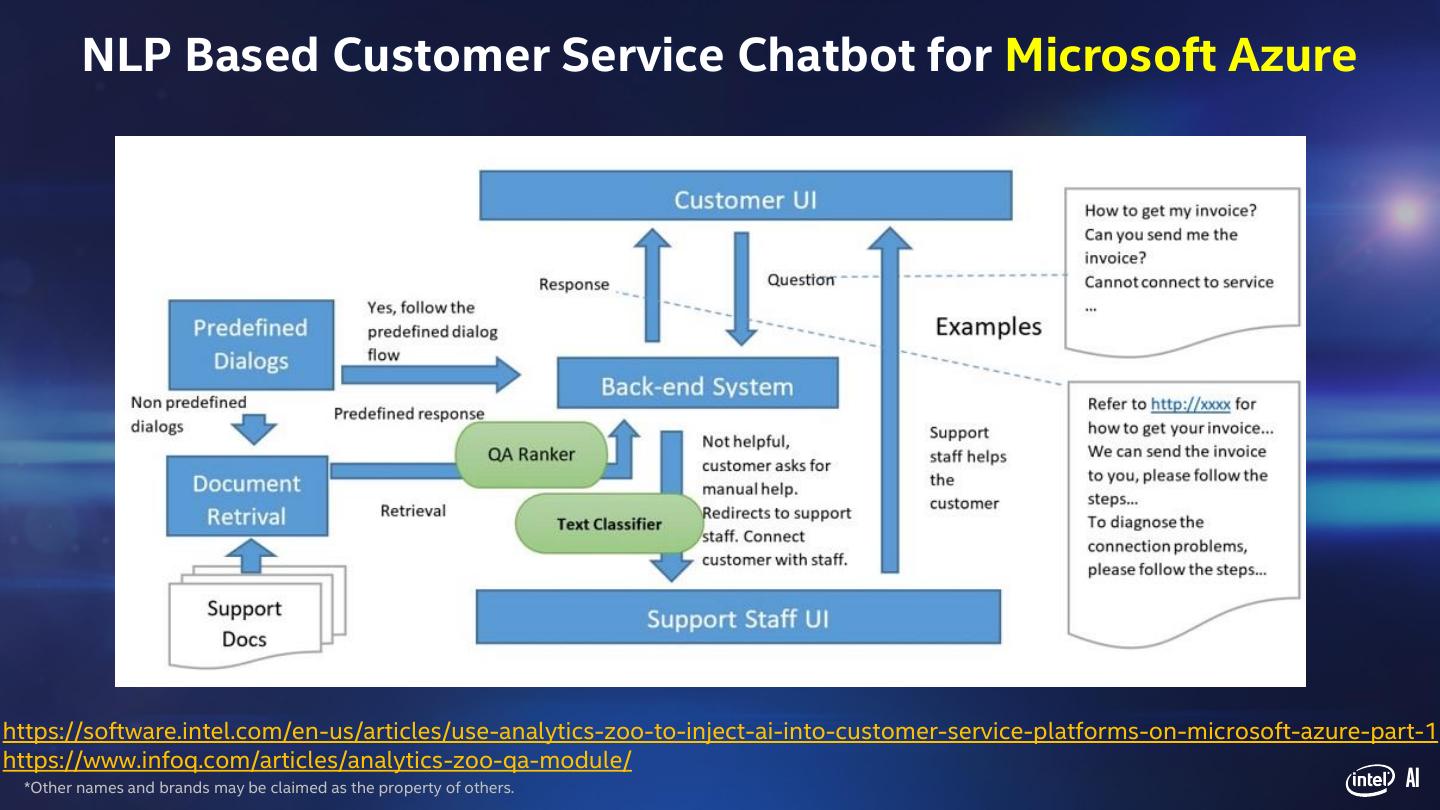
25 . NLP Based Customer Service Chatbot for Microsoft Azure https://software.intel.com/en-us/articles/use-analytics-zoo-to-inject-ai-into-customer-service-platforms-on-microsoft-azure-part-1 https://www.infoq.com/articles/analytics-zoo-qa-module/ *Other names and brands may be claimed as the property of others. AI
26 . Distributed, High-Performance Unified Analytics + AI Platform Deep Learning Framework Distributed TensorFlow, Keras, PyTorch and BigDL for Apache Spark on Apache Spark https://github.com/intel-analytics/bigdl https://github.com/intel-analytics/analytics-zoo Accelerating Data Analytics + AI Solutions At Scale AI
3秒后跳转登录页面
去登陆

