























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Cluster-Serving-Presentation
ClusterServing是基于开源平台AnalyticsZoo实现的高吞吐,低延迟,多兼容的在线serving。本次分享将为大家介绍:ClusterServing如何利用AnalyticsZoo以及其他的大数据平台的内部实现,以及在医疗影像分析中的实际案例。
展开查看详情
1 . What is Analytics Zoo Distributed, High-Performance Unified Analytics + AI Platform Deep Learning Framework Distributed TensorFlow, Keras, PyTorch and BigDL for Apache Spark on Apache Spark https://github.com/intel-analytics/bigdl https://github.com/intel-analytics/analytics-zoo Accelerating Data Analytics + AI Solutions At Scale
2 .Cluster Serving 2020/06/12
3 .Overview
4 . What’s Analytics Zoo Analytics + AI Platform Distributed TensorFlow*, Keras*, PyTorch* and BigDL on Apache Spark* https://github.com/intel-analytics/analytics-zoo Accelerating Data Analytics + AI Solutions At Scale *Other names and brands may be claimed as the property of others.
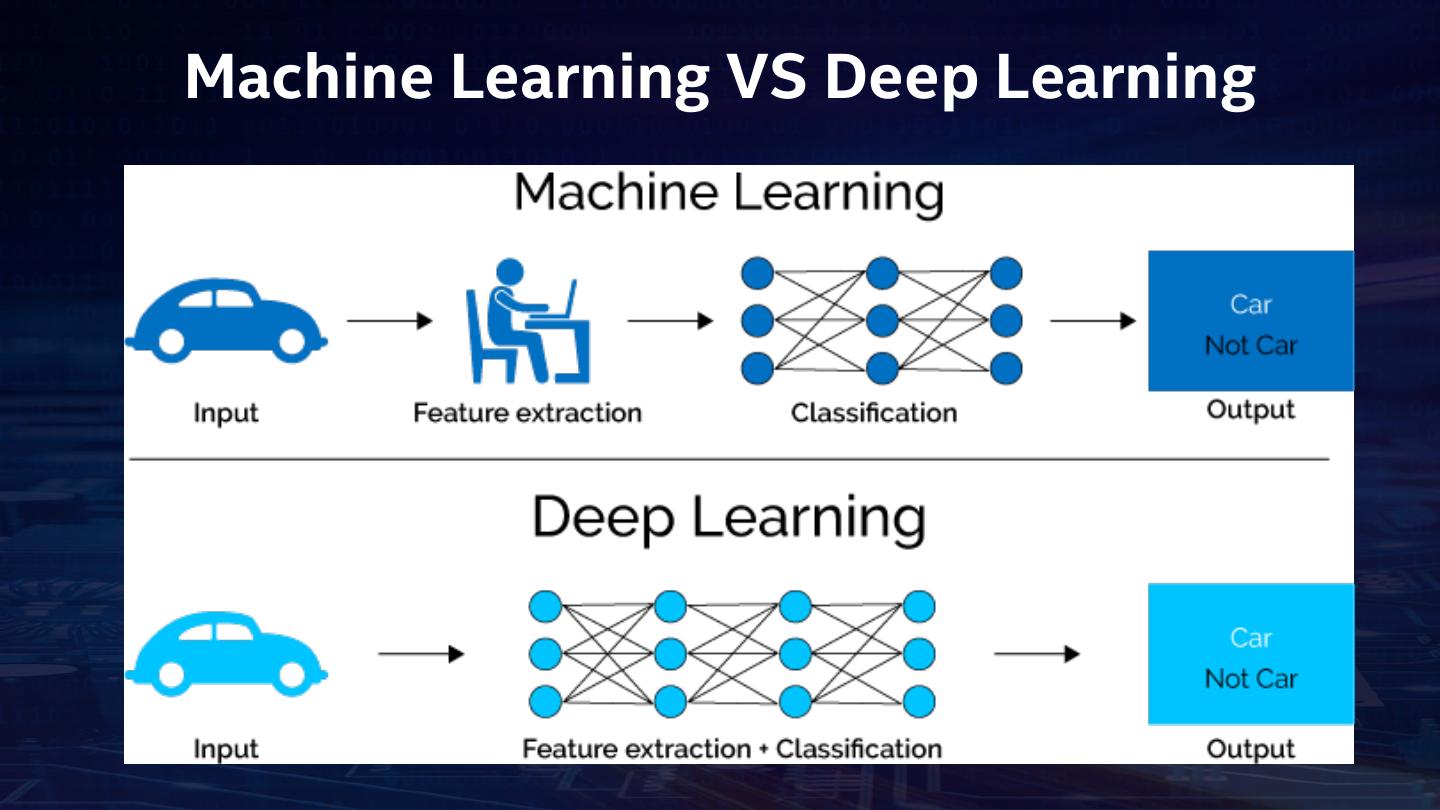
5 .Machine Learning VS Deep Learning
6 .Feature Visualization
7 .Data & Performance Relationship “Machine Learning Yearning”, Andrew Ng, 2016
8 .Real-World ML/DL Applications Are Complex Data Analytics Pipelines “Hidden Technical Debt in Machine Learning Systems”, Sculley et al., Google, NIPS 2015 Paper
9 . Data Analytics Pipeline from production perspective
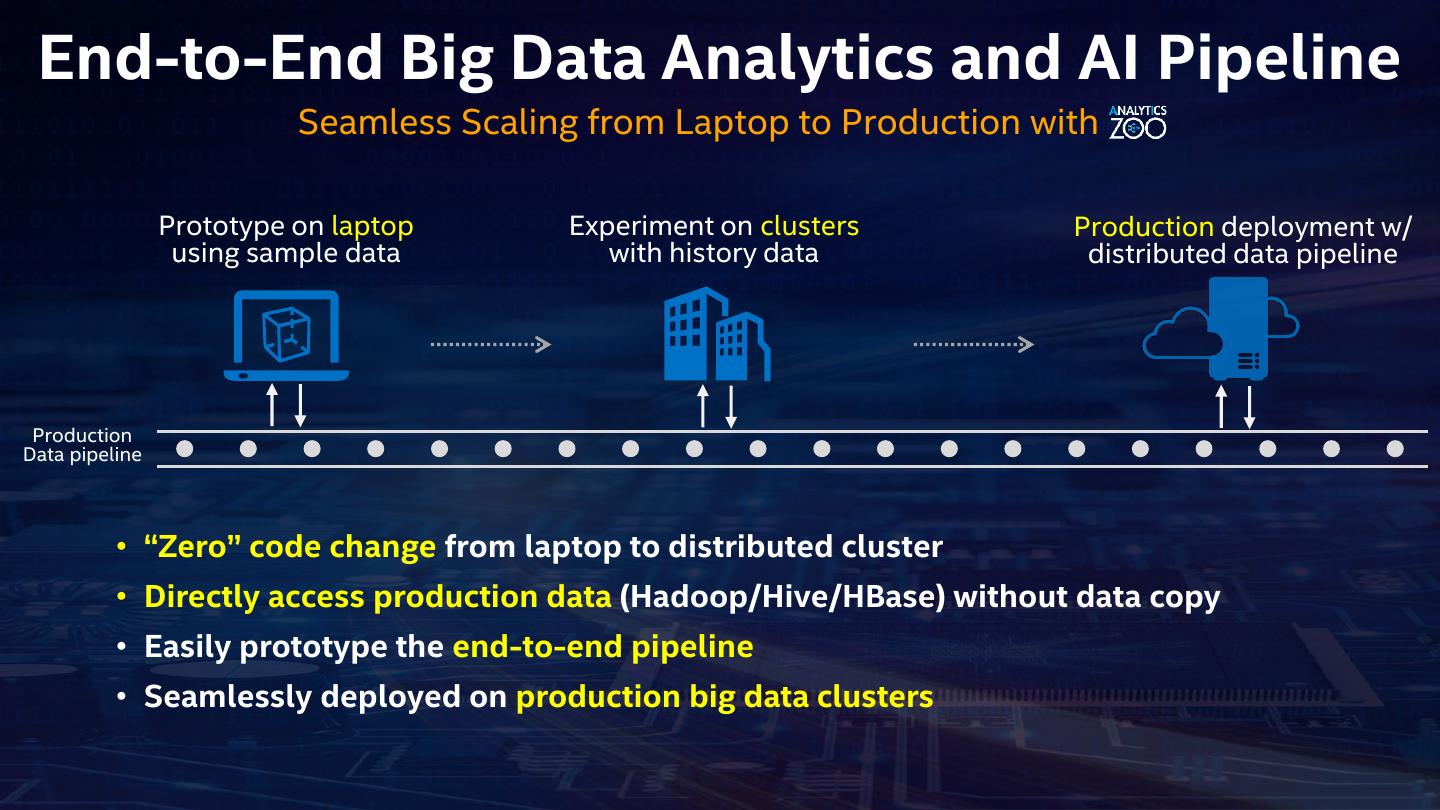
10 . End-to-End Big Data Analytics and AI Pipeline Seamless Scaling from Laptop to Production with Prototype on laptop Experiment on clusters Production deployment w/ using sample data with history data distributed data pipeline Production Data pipeline • “Zero” code change from laptop to distributed cluster • Directly access production data (Hadoop/Hive/HBase) without data copy • Easily prototype the end-to-end pipeline • Seamlessly deployed on production big data clusters
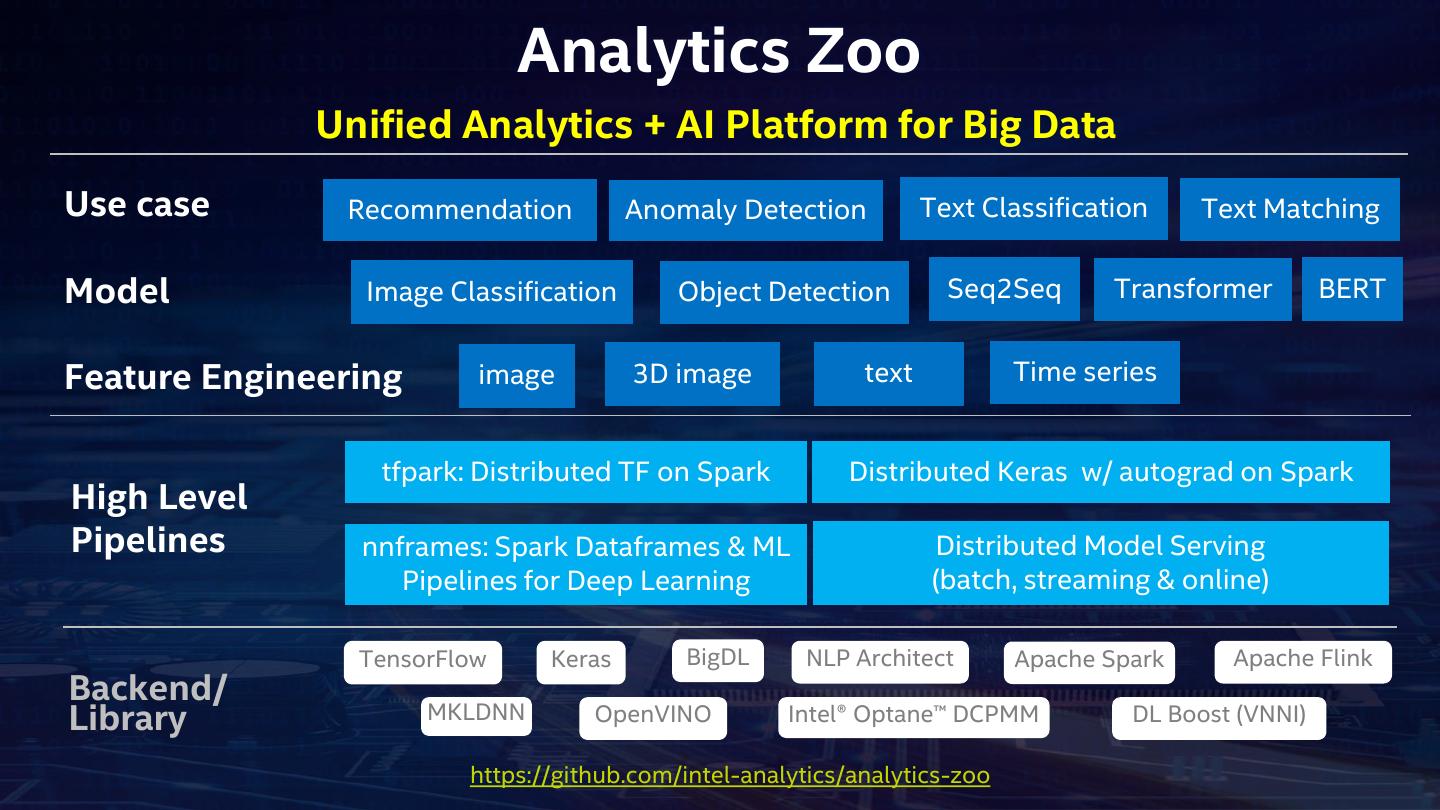
11 . Analytics Zoo Unified Analytics + AI Platform for Big Data Use case Recommendation Anomaly Detection Text Classification Text Matching Model Image Classification Object Detection Seq2Seq Transformer BERT Feature Engineering image 3D image text Time series tfpark: Distributed TF on Spark Distributed Keras w/ autograd on Spark High Level Pipelines nnframes: Spark Dataframes & ML Distributed Model Serving Pipelines for Deep Learning (batch, streaming & online) TensorFlow Keras BigDL NLP Architect Apache Spark Apache Flink Backend/ Library MKLDNN OpenVINO Intel® Optane™ DCPMM DL Boost (VNNI) https://github.com/intel-analytics/analytics-zoo
12 . What’s Analytics Zoo Analytics + AI Platform Distributed TensorFlow*, Keras*, PyTorch* and BigDL on Apache Spark* https://github.com/intel-analytics/analytics-zoo Accelerating Data Analytics + AI Solutions At Scale *Other names and brands may be claimed as the property of others.
13 . What’s Serving model Input Data Preprocessing Predict Postprocessing Result
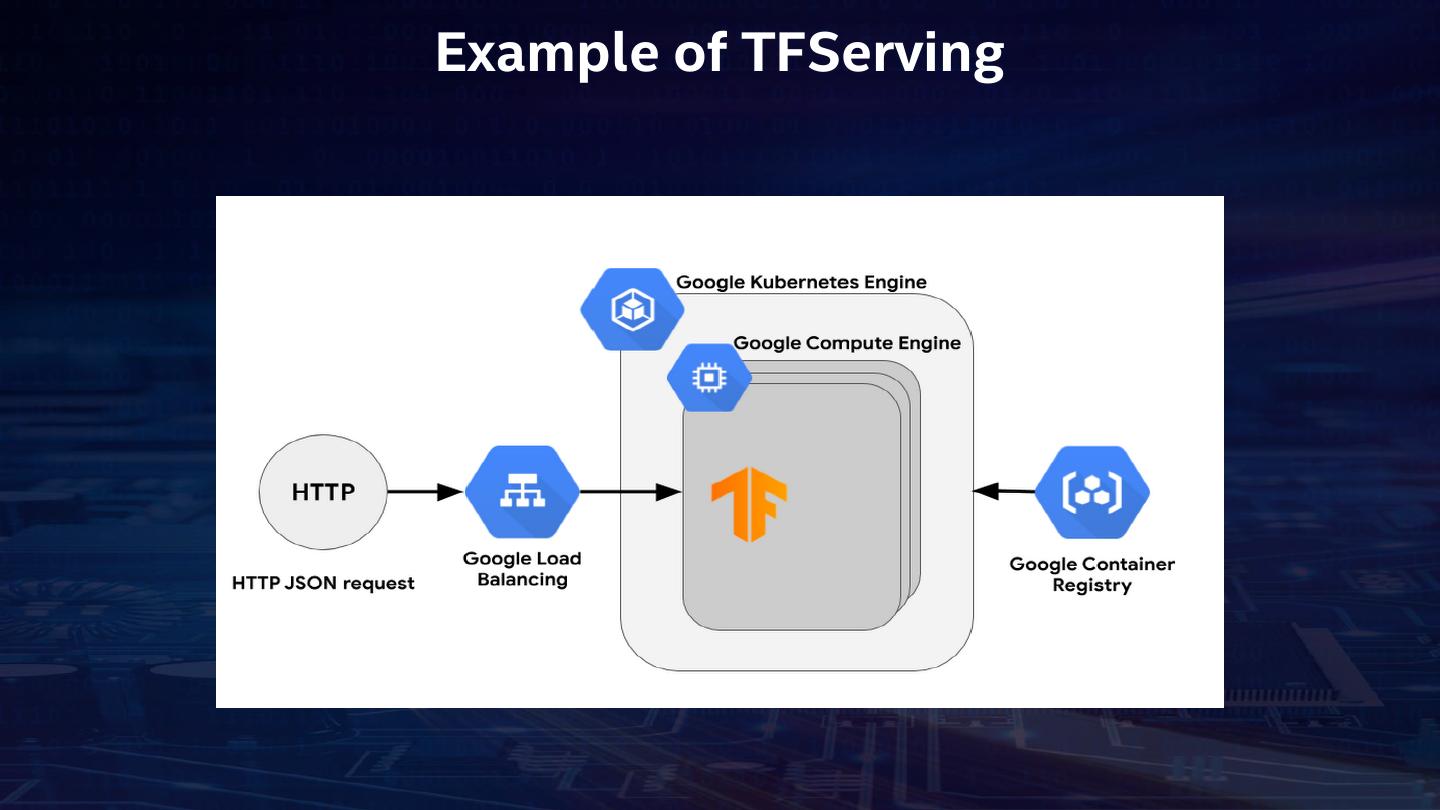
14 .Example of TFServing
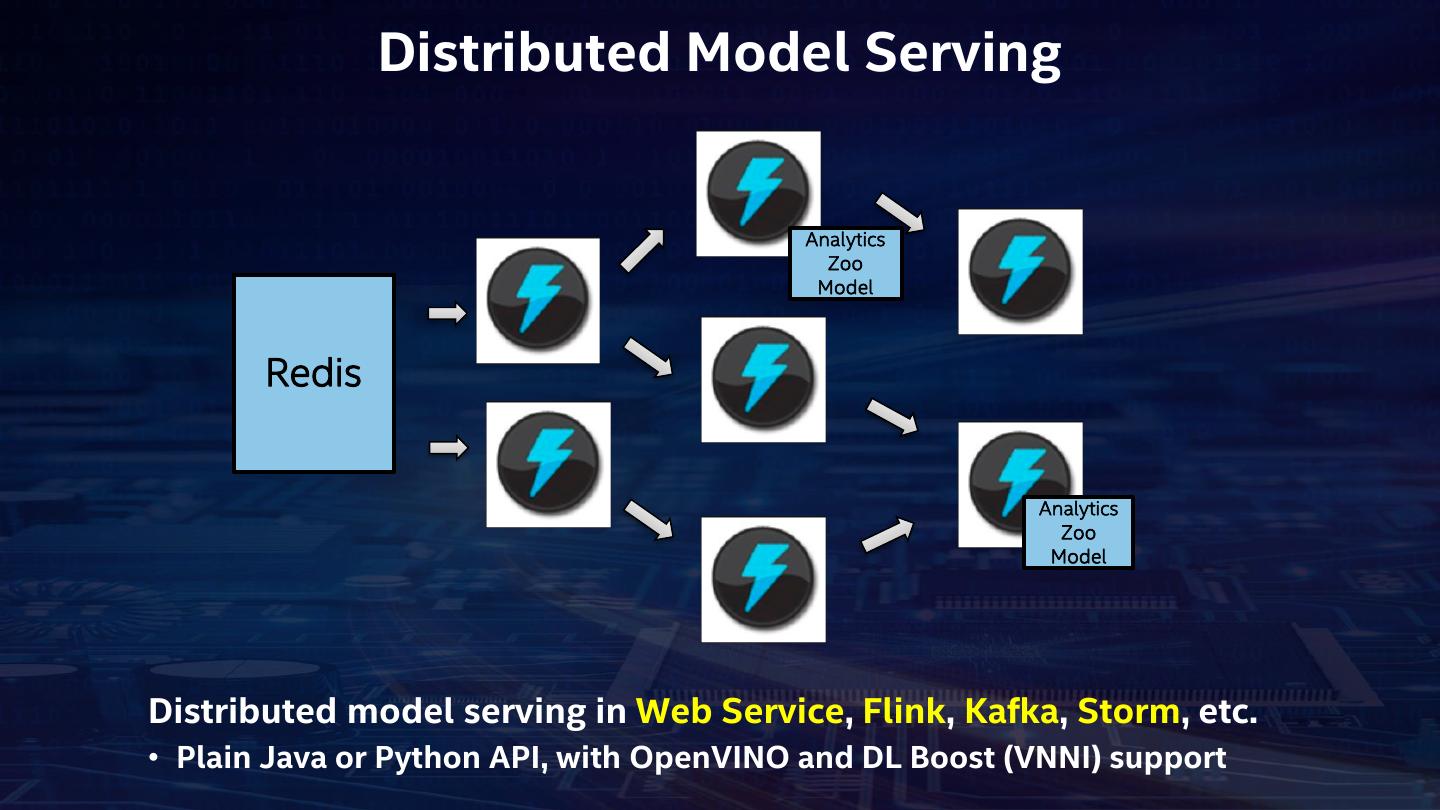
15 . Distributed Model Serving Analytics Zoo Model Redis Analytics Zoo Model Distributed model serving in Web Service, Flink, Kafka, Storm, etc. • Plain Java or Python API, with OpenVINO and DL Boost (VNNI) support
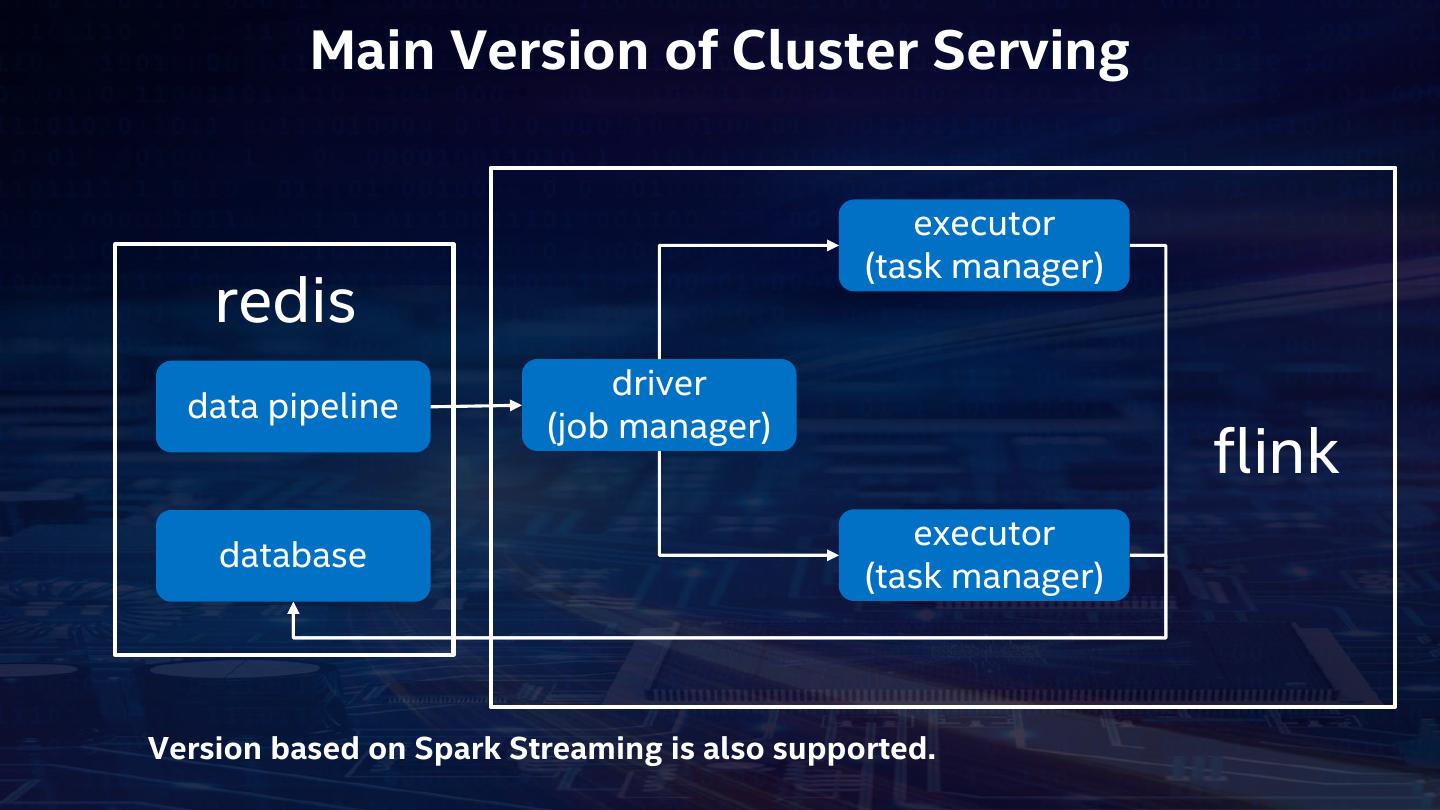
16 . Main Version of Cluster Serving executor (task manager) redis driver data pipeline (job manager) flink executor database (task manager) Version based on Spark Streaming is also supported.
17 . Data pipeline User Perspective Input Queue for requests Model R5 R3 R1 R4 R2 Network connection P1 P3 P5 P2 P4 Local node or Simple Output Queue (or files/DB tables) Docker container Python Hadoop/Yarn (or K8s) cluster for prediction results script
18 . Deploy Your Own Cluster Serving One command to pull docker image, and customize your config, then call cluster-serving-start to start your serving example of config: ## Analytics-zoo Cluster Serving model: # model path must be set path: resources data: # redis address src: XXXXXX:6379 …
19 . API Introductions http API data are represented by json format, and call http post method to enqueue your data into pipeline (http API is compatible with TFServing) python API data are represented by ndarray, and call python method to enqueue your data into pipeline
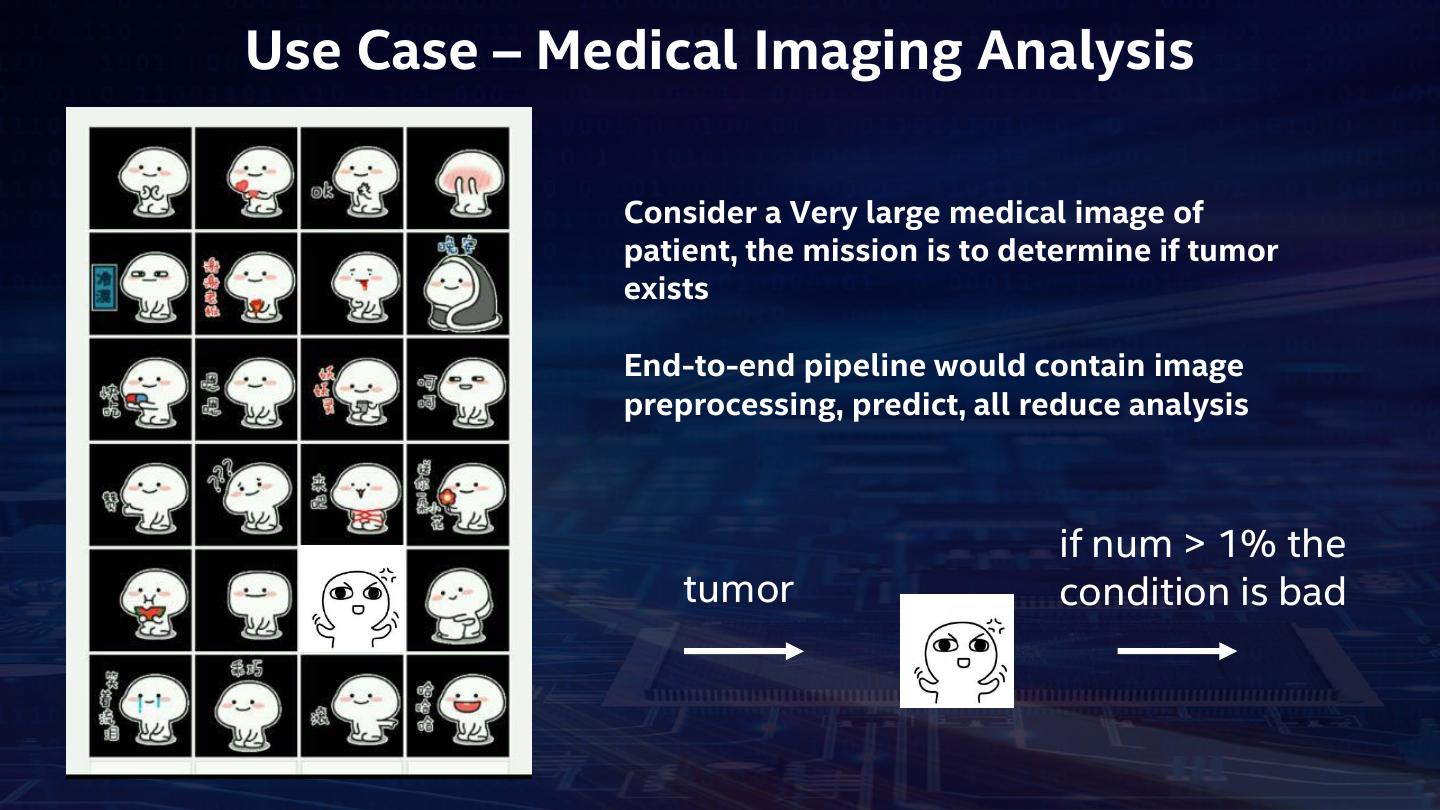
20 .Use Case – Medical Imaging Analysis Consider a Very large medical image of patient, the mission is to determine if tumor exists End-to-end pipeline would contain image preprocessing, predict, all reduce analysis if num > 1% the tumor condition is bad
21 . Advantages Wide Range Deep Learning model support Tensorflow, Caffe, OpenVINO, Pytorch, BigDL Low Latency Continuous Streaming pipeline is supported by Apache Flink, also Spark version is supported for users who are more familiar. High Throughput & Scalability Optimization of multithread control, and could easily scale out to clusters.
22 .Very Quick Start
23 . End-to-End Big Data and AI Pipelines Seamless Scaling from Laptop to Production Unified Analytics + AI Platform Distributed TensorFlow*, Keras*, PyTorch* & BigDL on Apache Spark* https://github.com/intel-analytics/analytics-zoo *Other names and brands may be claimed as the property of others.
24 . https://github.com/intel-analytics/analytics- zoo/blob/master/docs/docs/ClusterServingGuide/ProgrammingGuide.md Unified Analytics + AI Platform Distributed TensorFlow*, Keras*, PyTorch* & BigDL on Apache Spark* https://github.com/intel-analytics/analytics-zoo *Other names and brands may be claimed as the property of others.
25 . What is Analytics Zoo Distributed, High-Performance Unified Analytics + AI Platform Deep Learning Framework Distributed TensorFlow, Keras, PyTorch and BigDL for Apache Spark on Apache Spark https://github.com/intel-analytics/bigdl https://github.com/intel-analytics/analytics-zoo Accelerating Data Analytics + AI Solutions At Scale
26 .
27 .Legal Disclaimers • Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Learn more at intel.com, or from the OEM or retailer. • No computer system can be absolutely secure. • Tests document performance of components on a particular test, in specific systems. Differences in hardware, software, or configuration will affect actual performance. Consult other sources of information to evaluate performance as you consider your purchase. For more complete information about performance and benchmark results, visit http://www.intel.com/performance. Intel, the Intel logo, Xeon, Xeon phi, Lake Crest, etc. are trademarks of Intel Corporation in the U.S. and/or other countries. *Other names and brands may be claimed as the property of others. © 2019 Intel Corporation
28 . What is Analytics Zoo Distributed, High-Performance Unified Analytics + AI Platform Deep Learning Framework Distributed TensorFlow, Keras, PyTorch and BigDL for Apache Spark on Apache Spark https://github.com/intel-analytics/bigdl https://github.com/intel-analytics/analytics-zoo Accelerating Data Analytics + AI Solutions At Scale
3秒后跳转登录页面
去登陆

