展开查看详情
1 .Building High-Performance, Concurrent &
Scalable Filesystem Metadata Services
Featuring gRPC, Raft, and RocksDB
范斌 @ Alluxio
顾荣@南京大学
�
2 . Bin Fan
About Me
● PhD CS@CMU
● Founding Member, VP of Open Source @ Alluxio
● Email: binfan@alluxio.com
�
3 . 顾荣
About Me
● 南京大学 计算机系 特任副研究员,博士
● Alluxio PMC&Maintainer
● Email: gurong@nju.edu.cn
�
4 .Alluxio Overview
• Open source data orchestration
• Commonly used for data analytics such as OLAP on Hadoop
• Deployed at Huya, Walmart, Tencent, and many others
• Largest deployments of over 1000 nodes
�
5 .Fast Growing Developer Community
1080
Started as Haoyuan Li’s PhD project “Tachyon”
750
Open sourced in under Apache 2.0 License
210
3 70
1
v0.1 v0.2 v0.6 v1.0 v1.8 v2.1
Dec ‘12 Apr Mar Feb Jul Nov
‘13 ‘15 ‘16 ‘18 ‘19
�
6 .Deployed in Hundreds of Companies
Financial Services Retail & Entertainment Data & Analytics Technology
Services
Consumer Telco & Media Travel & Transportation
�
7 .Deployed at Scale in Different Environment
On-Prem Single Cloud Hybrid Cloud
• Huya: 1300+ nodes • Bazaarvoice: AWS • DBS Bank
• Sogou: 1000+ nodes • Ryte: AWS • ING Bank
• Momo: 850 nodes • Walmart Labs: GCP • Comcast
�
8 .Agenda
1 Architecture
2 Challenges
3 Solutions
�
11 .Alluxio Master
• Responsible for storing and serving metadata in Alluxio
• What is Filesystem Metadata
• Data structure of the Filesystem Tree (namespace)
■ Can include mounts of other file system namespaces
■ The size of the tree can be very large!
• Data structure to map files to blocks and their locations
■ Very dynamic in Alluxio
• Who is the primary master
■ One primary + several standby masters
�
13 .Metadata Storage Challenges
• Storing the raw metadata becomes a problem with a large number
of files
• On average, each file takes 1KB of on-heap storage
• 1 billion files would take 1 TB of heap space!
• A typical JVM runs with < 64GB of heap space
• GC becomes a big problem when using larger heaps
�
14 .Metadata Storage Challenges
• Durability for the metadata is important
• Need to restore state after planned or unplanned restarts or machine loss
• The speed at which the system can recover determines the amount
of downtime suffered
• Restoring a 1TB sized snapshot takes a nontrivial amount of time!
�
15 .Metadata Serving Challenges
• Common file operations (ie. getStatus, create) need to be fast
• On heap data structures excel in this case
• Operations need to be optimized for high concurrency
• Generally many readers and few writers for large-scale analytics
�
16 .Metadata Serving Challenges
• The metadata service also needs to sustain high load
• A cluster of 100 machines can easily host over 5k concurrent clients!
• Connection life cycles need to be managed well
• Connection handshake is expensive
• Holding an idle connection is also detrimental
�
17 .Solutions: Combining Different Open-
Source Technologies as Building
Blocks
�
18 .Solving Scalable Metadata
Storage Using RocksDB
�
19 .RocksDB
• https://rocksdb.org/
• RocksDB is an embeddable
persistent key-value store for
fast storage
�
20 .Tiered Metadata Storage
• Uses an embedded RocksDB to store inode tree
• Solves the storage heap space problem
• Developed new data structures to optimize for storage in RocksDB
• Internal cache used to mitigate on-disk RocksDB performance
• Solves the serving latency problem
• Performance is comparable to previous on-heap implementation
• [In-Progress] Use tiered recovery to incrementally make the
namespace available on cold start
• Solves the recovery problem
�
21 . Tiered Metadata Storage => 1 Billion Files
Alluxio Master
On Heap
● Inode Cache RocksDB (Embedded)
● Mount Table ● Inode Tree
● Locks ● Block Map
● Worker Block Locations
Local Disk
21
�
22 .Working with RocksDB
• Abstract the metadata storage layer
• Redesign the data structure representation of the Filesystem Tree
• Each inode is represented by a numerical ID
• Edge table maps <ID,childname> to <ID of child> Ex: <1foo, 2>
• Inode table maps <ID> to <Metadata blob of inode> Ex: <2, proto>
• Two table solution provides good performance for common
operations
• One lookup for listing by using prefix scan
• Path depth lookups for tree traversal
• Constant number of inserts for updates/deletes/creates
�
23 .Example RocksDB Operations
• To create a file, /s3/data/june.txt:
• Look up <rootID, s3> in the edge table to get <s3ID>
• Look up <s3ID, data> in the edge table to get <dataID>
• Look up <dataID> in the inode table to get <dataID metadata>
• Update <dataID, dataID metadata> in the inode table
• Put <june.txtID, june.txt metadata> in the inode table
• Put <dataId, june.txt> in the edge table
• To list children of /:
• Prefix lookup of <rootId> in the edge table to get all <childID>s
• Look up each <childID> in the inode table to get <child metadata>
�
24 .Effects of the Inode Cache
• Generally can store up to 10M inodes
• Caching top levels of the Filesystem Tree greatly speeds up read
performance
• 20-50% performance loss when addressing a filesystem tree that does not
mostly fit into memory
• Writes can be buffered in the cache and are asynchronously flushed
to RocksDB
• No requirement for durability - that is handled by the journal
�
25 .Self-Managed Quorum for
Leader Election and Journal
Fault Tolerance Using Raft
�
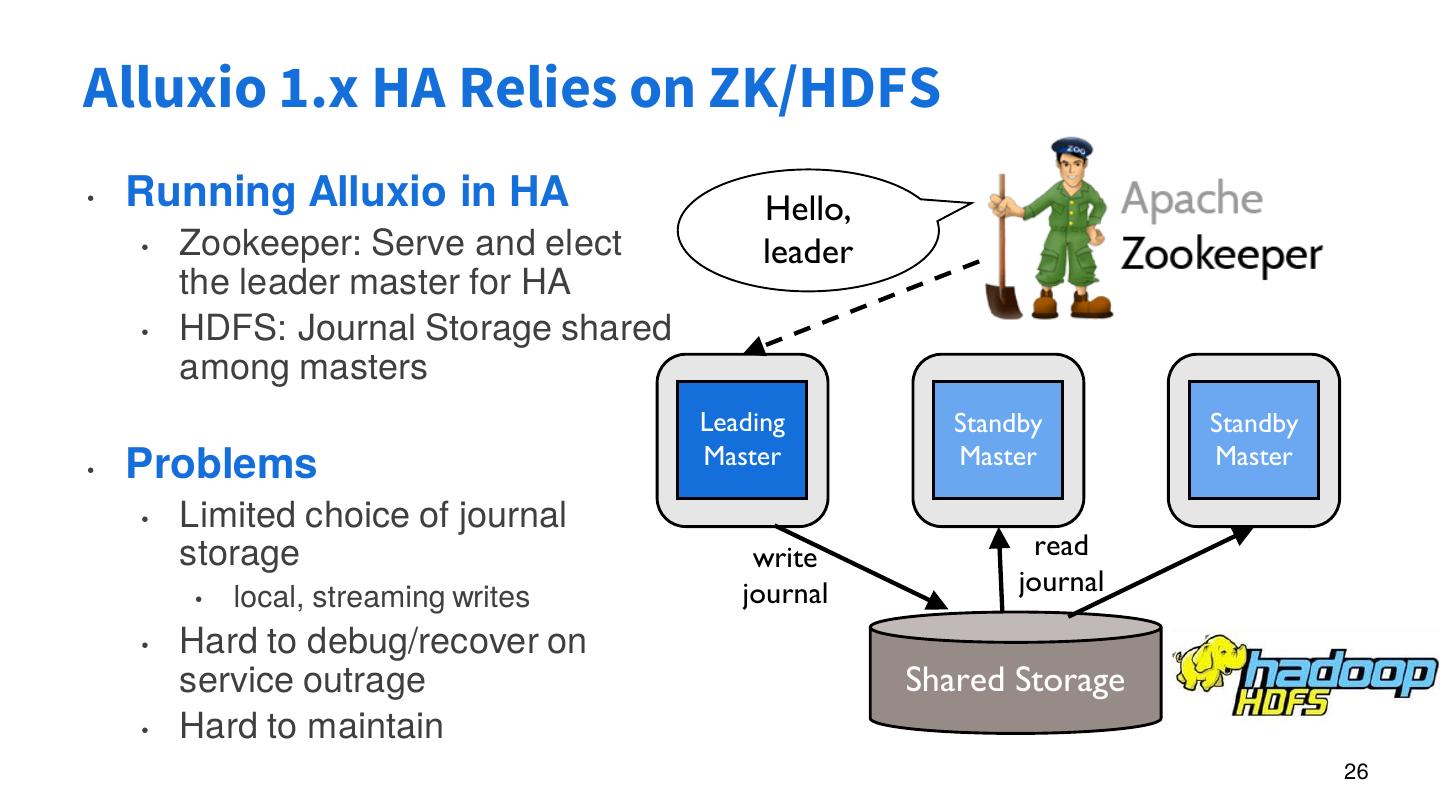
26 .Alluxio 1.x HA Relies on ZK/HDFS
• Running Alluxio in HA Hello,
• Zookeeper: Serve and elect leader
the leader master for HA
• HDFS: Journal Storage shared
among masters
Leading Standby Standby
• Problems Master Master Master
• Limited choice of journal
storage write read
journal journal
• local, streaming writes
• Hard to debug/recover on
service outrage Shared Storage
• Hard to maintain
26
�
27 .RAFT
• https://raft.github.io/
• Raft is a consensus algorithm that is
designed to be easy to understand.
It's equivalent to Paxos in fault-
tolerance and performance.
• Implemented by
https://github.com/atomix/copycat
�
28 .Built-in Fault Tolerance
• Alluxio Masters are run as a quorum for journal fault tolerance
• Metadata can be recovered, solving the durability problem
• This was previously done utilizing an external fault tolerance storage
• Alluxio Masters leverage the same quorum to elect a leader
• Enables hot standbys for rapid recovery in case of single node failure
�
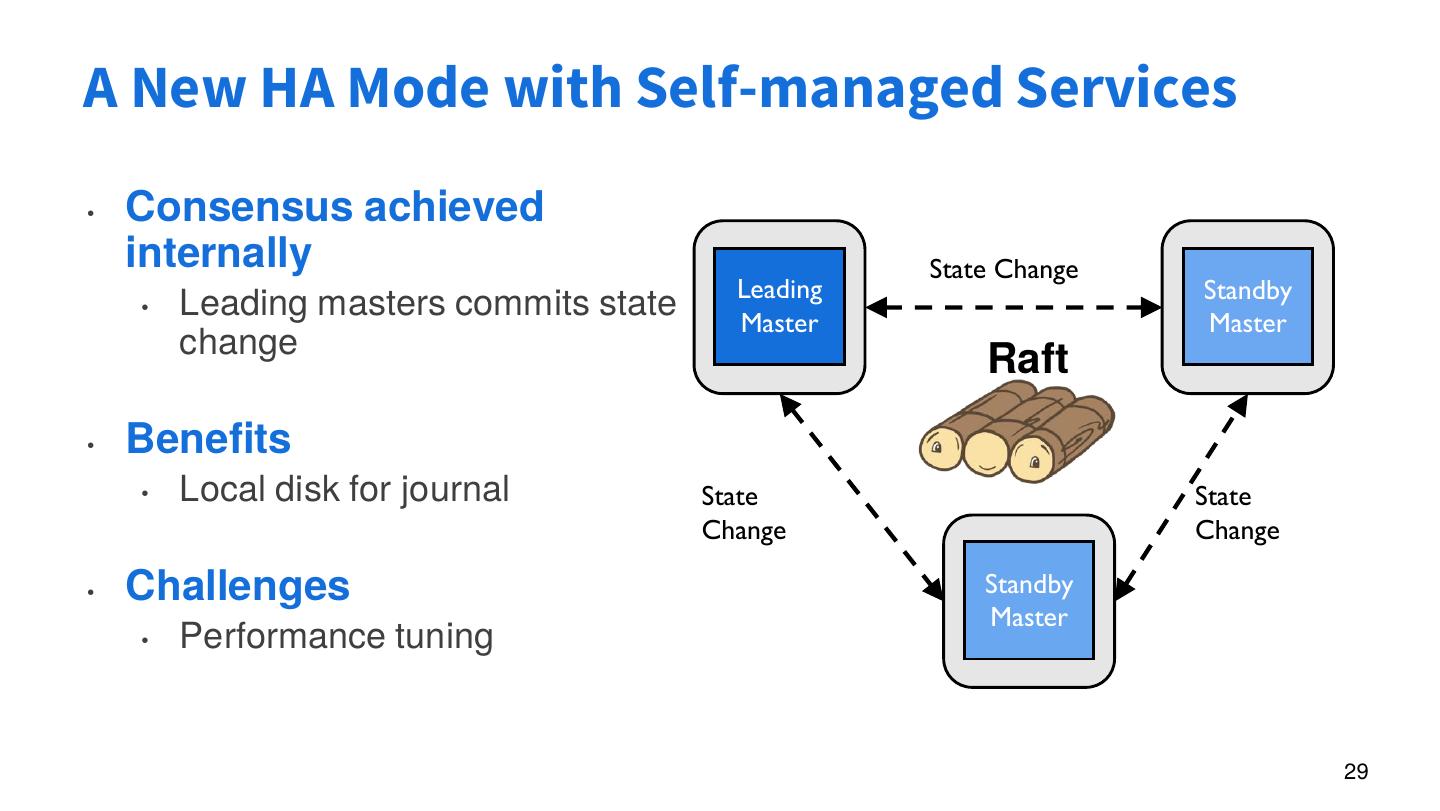
29 .A New HA Mode with Self-managed Services
• Consensus achieved
internally State Change
Leading Standby
• Leading masters commits state Master Master
change
Raft
• Benefits
• Local disk for journal State State
Change Change
• Challenges Standby
Master
• Performance tuning
29
�