






















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
阿里云基于Presto+Alluxio构建高性能数据湖分析引擎
马振林,阿里云数据库技术专家。多年大数据相关领域工作经验,目前在阿里云从事数据湖查询引擎的研发工作。
- 阿⾥云数据湖分析(DLA)介绍
- DLA Presto架构及痛点
- DLA Presto在OSS数据源上的优化
展开查看详情
1 .阿⾥云基于Presto+Alluxio构建 ⾼性能数据湖分析引擎 ⻢振林 | 阿⾥云数据库技术专家
2 .⽬录 01 阿⾥云数据湖分析(DLA)介绍 02 DLA Presto架构及痛点 03 DLA Presto在OSS数据源上的优化
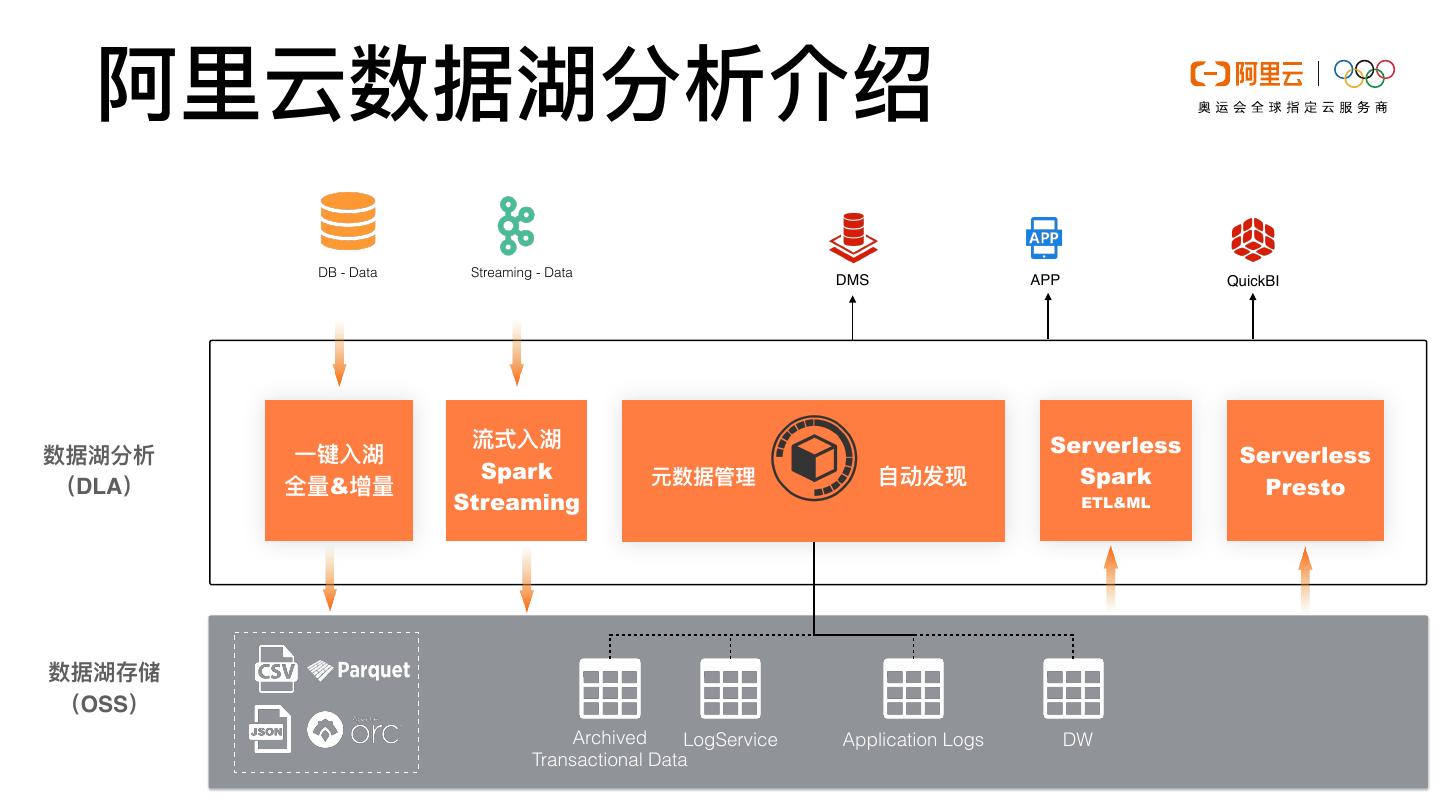
3 .阿⾥云数据湖分析介绍 云原⽣数据湖分析(简称DLA)是新⼀代⼤数据解决⽅案,采取计算与存储完全分离的架构,⽀持 数 据库(RDS\PolarDB\NoSQL)与消息实时归档建仓,提供弹性的Spark与Presto,满⾜在线交互式查 询、流处理、批处理、机器学习等诉求,也是传统Hadoop⽅案上云的有竞争⼒的解决⽅案。
4 . 阿⾥云数据湖分析介绍 DB - Data Streaming - Data DMS APP QuickBI 流式⼊湖 Serverless 数据湖分析 ⼀键⼊湖 Serverless Spark 元数据管理 ⾃动发现 Spark (DLA) 全量&增量 Presto Streaming ETL&ML 列存表 数据湖存储 (OSS) Archived LogService Application Logs DW Transactional Data
5 .DLA Presto能⼒ ⾼可⽤-多Coordinato ⽅便的数据摄⼊:⼀键⼊湖、元数据⾃动发现 内置企业级权限控制体系 成本:扫描量⽀持按照Query计费;CU 版本⽀持包年包⽉固定成本; Mysql兼容:⽀持MySQL协议访问,兼容部 分MySQL语法。⽀持⼤部分BI对接, 如QuickBI; 加速:CU版本内置Cache加速,⼤幅 提升性能; 多源:⽀持15+数据源,包括OSS、 ADB、OTS等; r
6 .DLA Presto产品形态
7 .⽬录 01 阿⾥云数据湖分析(DLA)介绍 02 DLA Presto架构及痛点 03 DLA Presto在OSS数据源上的优化
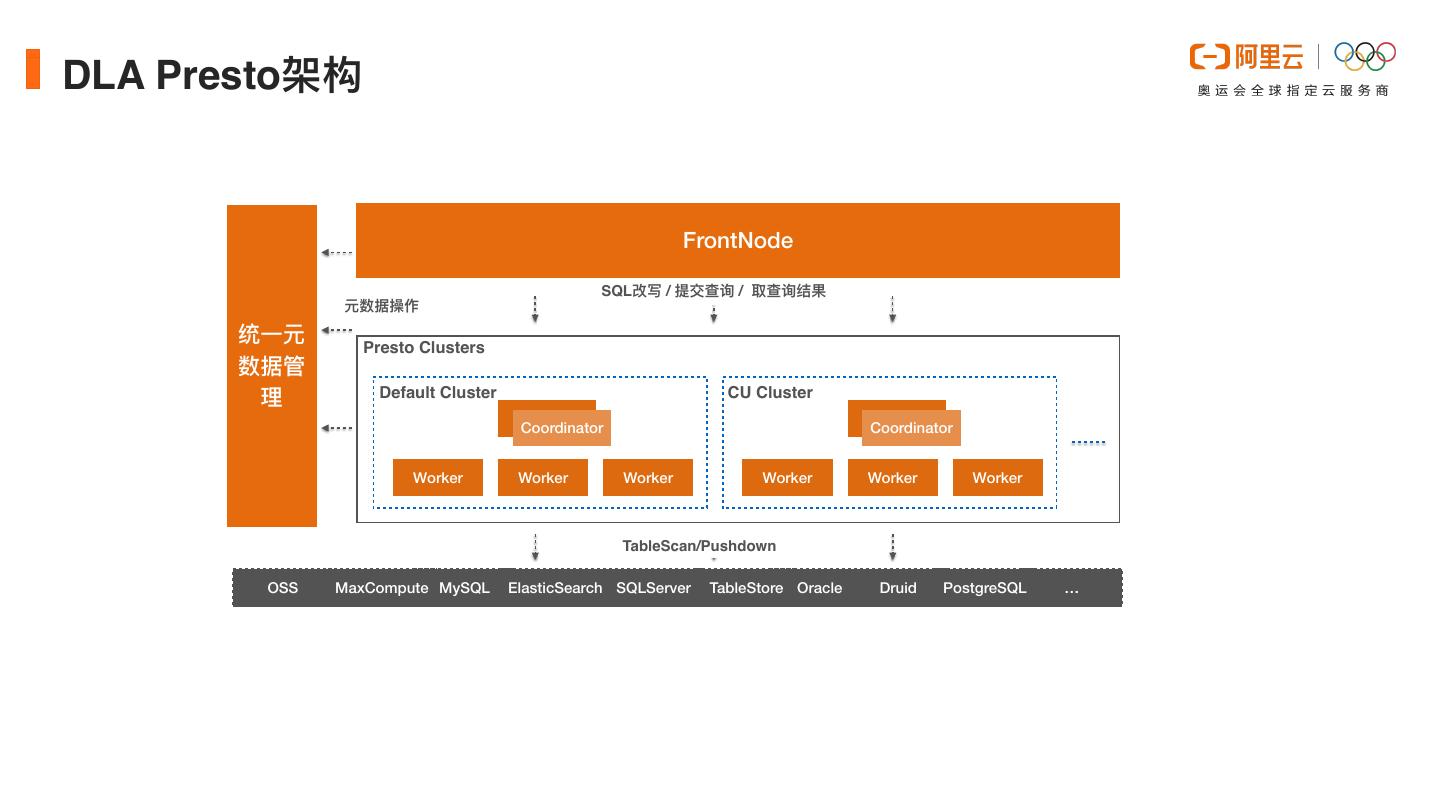
8 .DLA Presto架构 FrontNode SQL改写 / 提交查询 / 取查询结果 元数据操作 统⼀元 Presto Clusters 数据管 理 Default Cluster CU Cluster Coordinator Coordinator Worker Worker Worker Worker Worker Worker TableScan/Pushdown OSS MaxCompute MySQL ElasticSearch SQLServer TableStore Oracle Druid PostgreSQL …
9 .Presto简介 Presto是Facebook为了解决Hive做交互式查询慢的问题,⽽开发并开源的OLAP分析引擎,它的优势在 于全内存计算带 来的⾼性能、完整SQL语义⽀持、Connector机制带来的扩展能⼒、以及强⼤的社区。 全内存计算 ⽀持完整SQL语义 易⽤的插件机制 强⼤的社区 不⽤担⼼任何SQL 特别快!适合做Adhoc查询, 语法不 受⽀持⽽实 数据探索以及轻量级ETL。 现不了你的数 据分 析需求。
10 .Presto适⽤场景 Adho 数据探索 BI报表 轻量ETL 跨源联邦分析 数据分析 Presto全内存计算带来的⾼性能、完整SQL语义⽀持、Connector机制带来的扩展能⼒、以及强⼤的 社区使得⼴⼤⽤户可以放⼼ 使⽤Presto来做Adhoc分析、数据探索、BI报表、轻量ETL、跨源数据分 析等等各个场景。 c
11 .Presto中国社区 Alibaba是Presto基⾦会成员之⼀,云原⽣数据湖分析DLA作为代表积极推进 Presto社区的发展。 https://prestodb.io/join.html
12 .DLA Presto痛点 FrontNode SQL改写 / 提交查询 / 取查询结果 元数据操作 统⼀元 Presto Clusters 数据管 理 Default Cluster CU Cluster Coordinator Coordinator Worker Worker Worker Worker Worker Worker TableScan/Pushdown OSS MaxCompute MySQL ElasticSearch SQLServer TableStore Oracle Druid PostgreSQL …
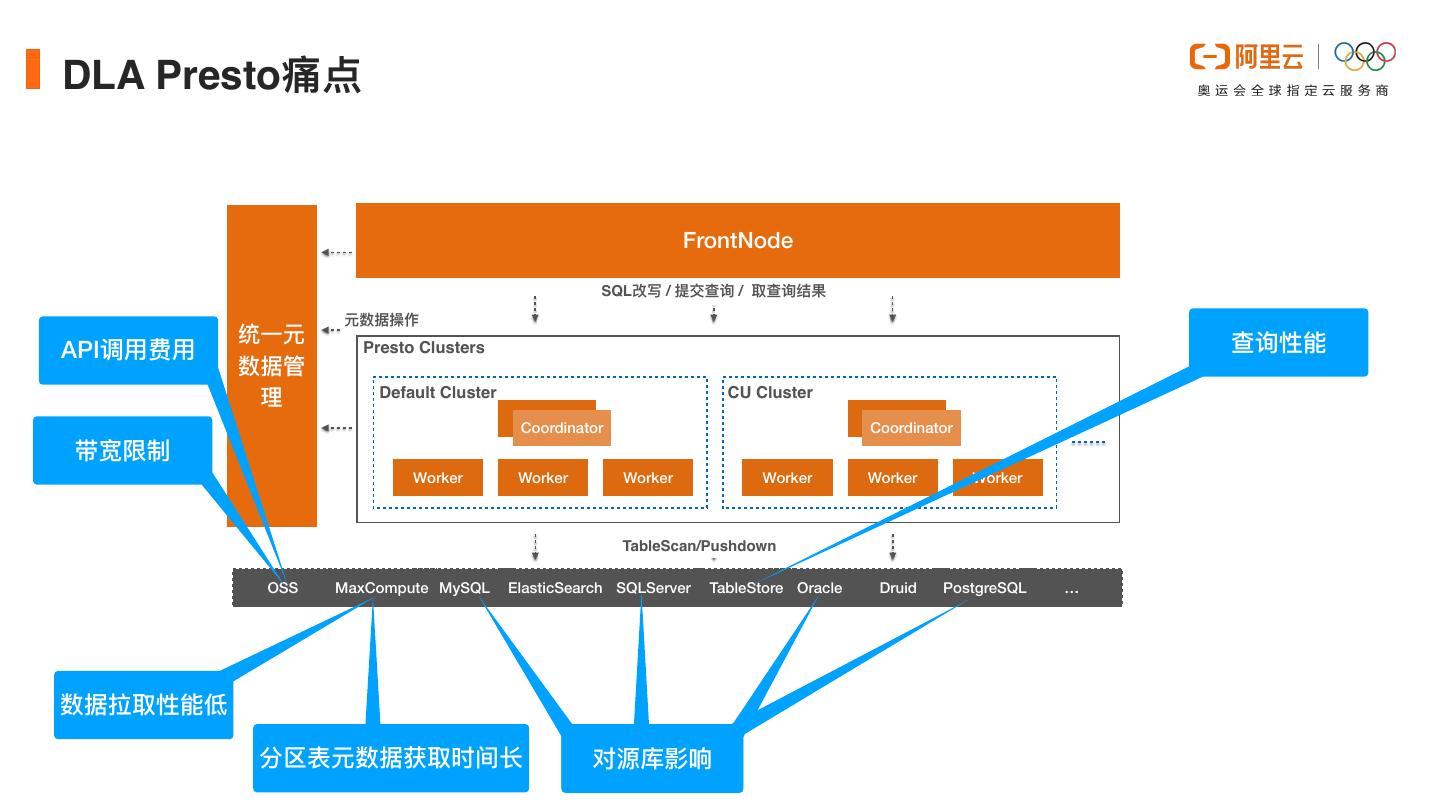
13 .DLA Presto痛点 FrontNode SQL改写 / 提交查询 / 取查询结果 元数据操作 统⼀元 查询性能 API调⽤费⽤ Presto Clusters 数据管 理 Default Cluster CU Cluster Coordinator Coordinator 带宽限制 Worker Worker Worker Worker Worker Worker TableScan/Pushdown OSS MaxCompute MySQL ElasticSearch SQLServer TableStore Oracle Druid PostgreSQL … 数据拉取性能低 分区表元数据获取时间⻓ 对源库影响
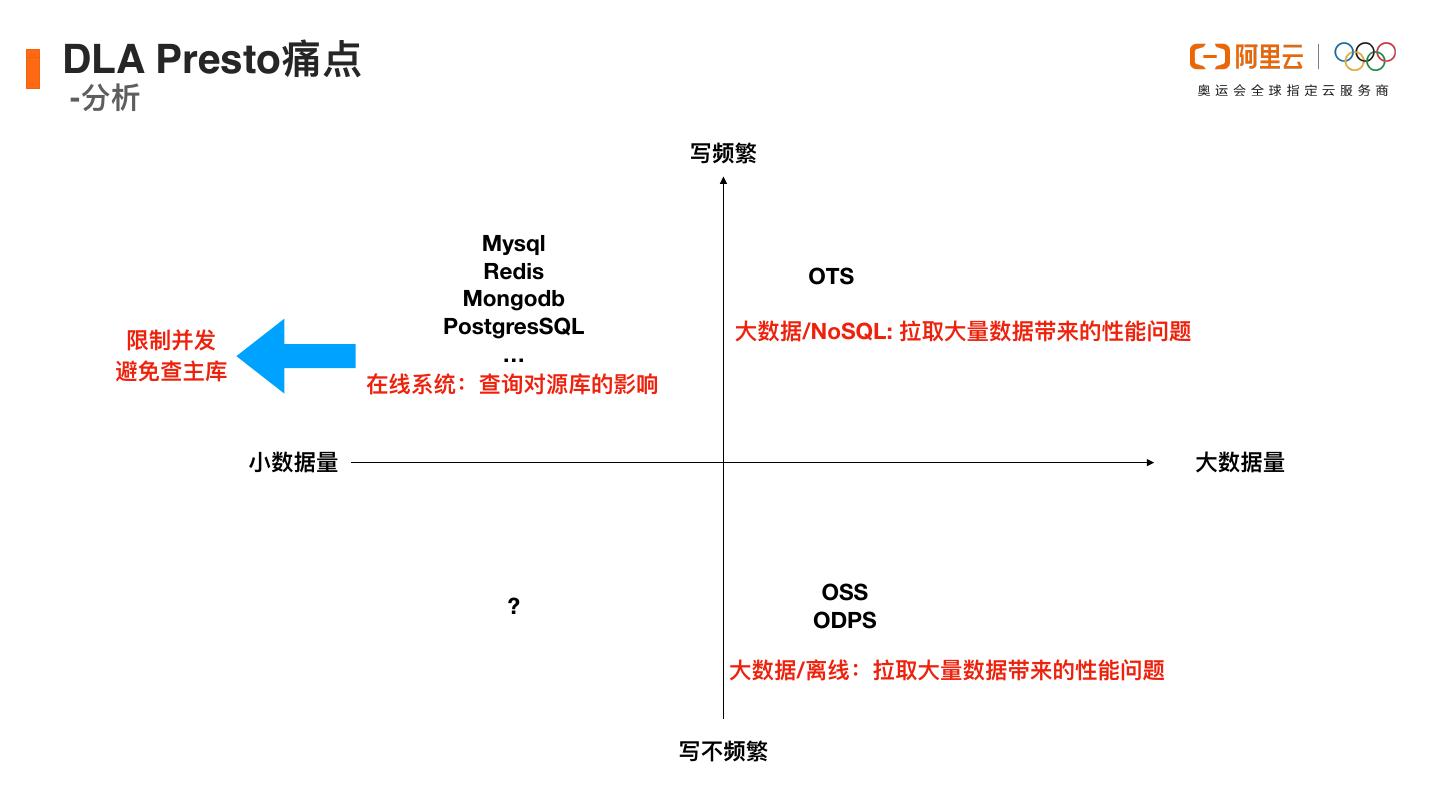
14 .DLA Presto痛点 -分析 写频繁 Mysql Redis OTS Mongodb PostgresSQL ⼤数据/NoSQL: 拉取⼤量数据带来的性能问题 … 在线系统:查询对源库的影响 ⼩数据量 ⼤数据量 OSS ? ODPS ⼤数据/离线:拉取⼤量数据带来的性能问题 写不频繁
15 .DLA Presto痛点 -分析 写频繁 Mysql Redis OTS Mongodb PostgresSQL ⼤数据/NoSQL: 拉取⼤量数据带来的性能问题 限制并发 … 避免查主库 在线系统:查询对源库的影响 ⼩数据量 ⼤数据量 OSS ? ODPS ⼤数据/离线:拉取⼤量数据带来的性能问题 写不频繁
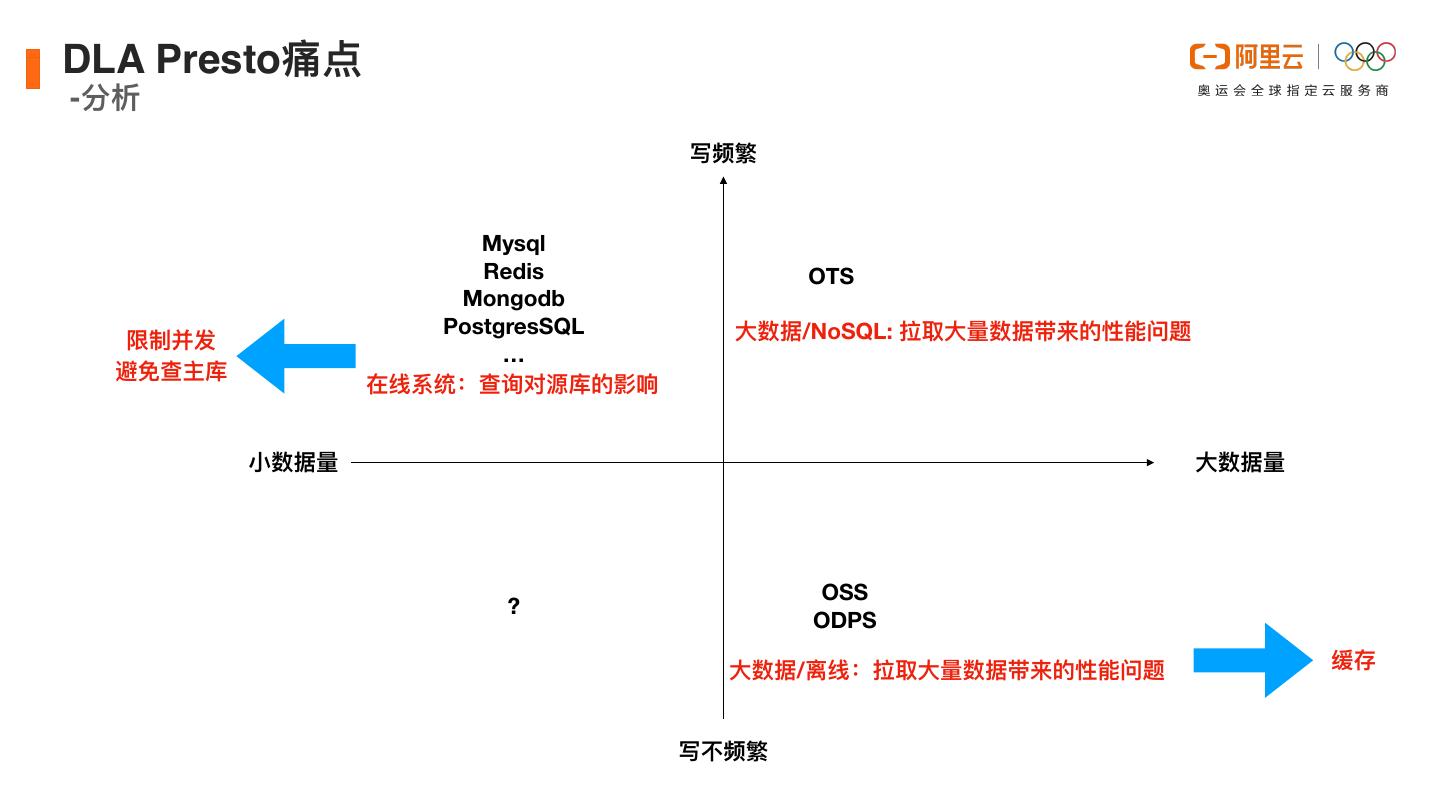
16 .DLA Presto痛点 -分析 写频繁 Mysql Redis OTS Mongodb PostgresSQL ⼤数据/NoSQL: 拉取⼤量数据带来的性能问题 限制并发 … 避免查主库 在线系统:查询对源库的影响 ⼩数据量 ⼤数据量 OSS ? ODPS ⼤数据/离线:拉取⼤量数据带来的性能问题 缓存 写不频繁
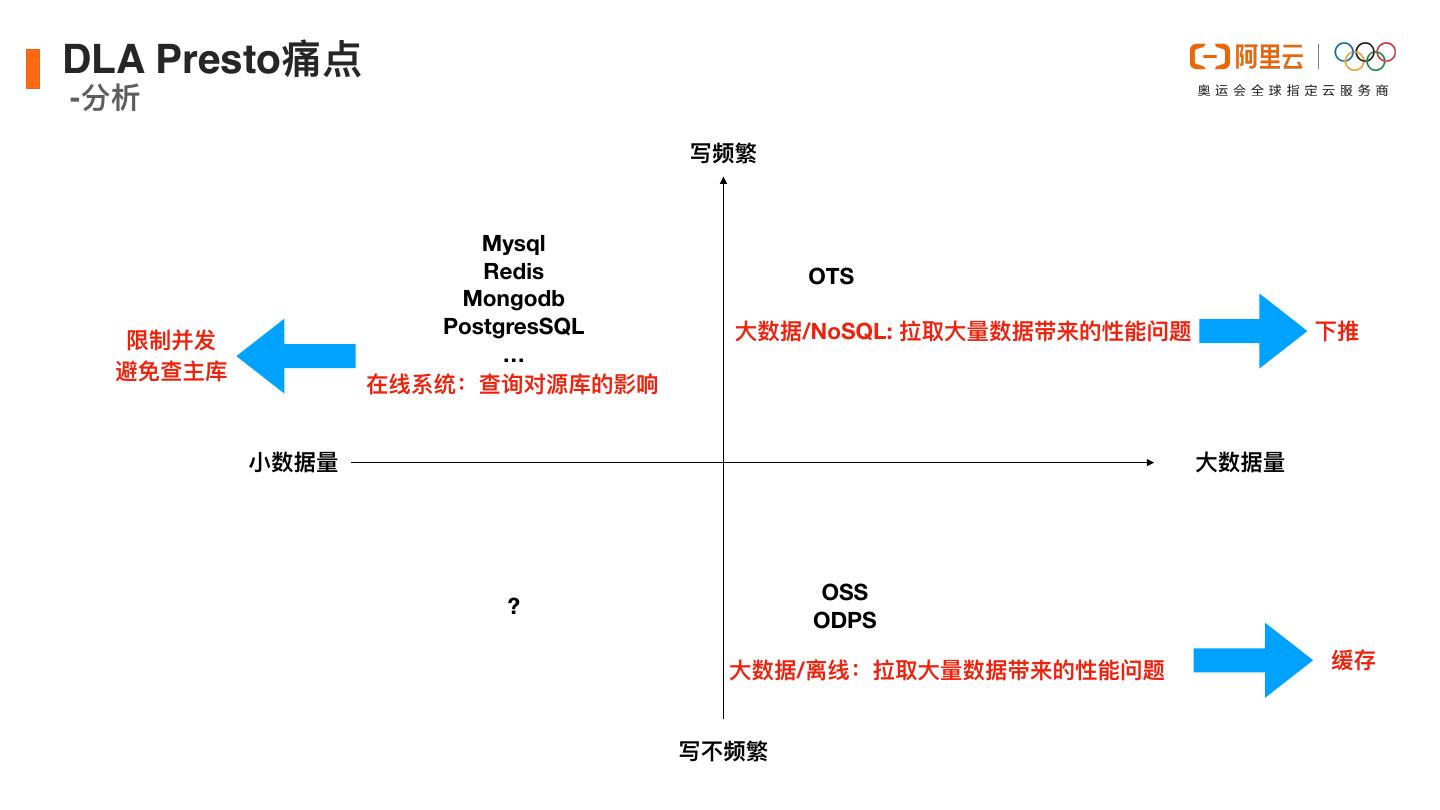
17 .DLA Presto痛点 -分析 写频繁 Mysql Redis OTS Mongodb PostgresSQL ⼤数据/NoSQL: 拉取⼤量数据带来的性能问题 下推 限制并发 … 避免查主库 在线系统:查询对源库的影响 ⼩数据量 ⼤数据量 OSS ? ODPS ⼤数据/离线:拉取⼤量数据带来的性能问题 缓存 写不频繁
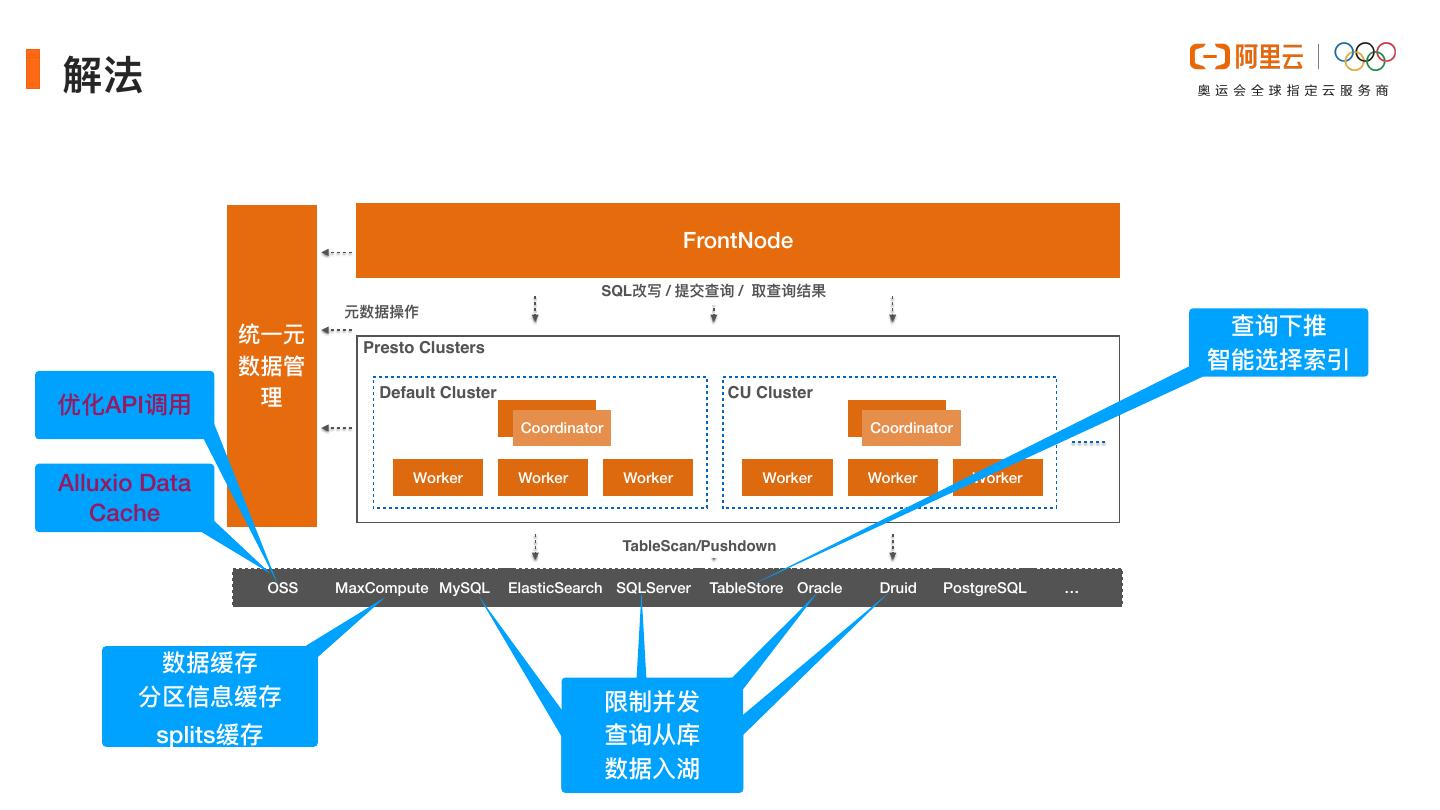
18 .解法 FrontNode SQL改写 / 提交查询 / 取查询结果 元数据操作 统⼀元 查询下推 Presto Clusters 数据管 智能选择索引 优化API调⽤ 理 Default Cluster CU Cluster Coordinator Coordinator Alluxio Data Worker Worker Worker Worker Worker Worker Cache TableScan/Pushdown OSS MaxCompute MySQL ElasticSearch SQLServer TableStore Oracle Druid PostgreSQL … 数据缓存 分区信息缓存 限制并发 splits缓存 查询从库 对源库影响 数据⼊湖
19 .⽬录 01 阿⾥云数据湖分析(DLA)介绍 02 DLA Presto架构及痛点 03 DLA Presto在OSS数据源上的优化
20 .DLA Presto在OSS数据源上的优化 优化1:降低OSS调⽤次数 优化2:Alluxio Data Cache
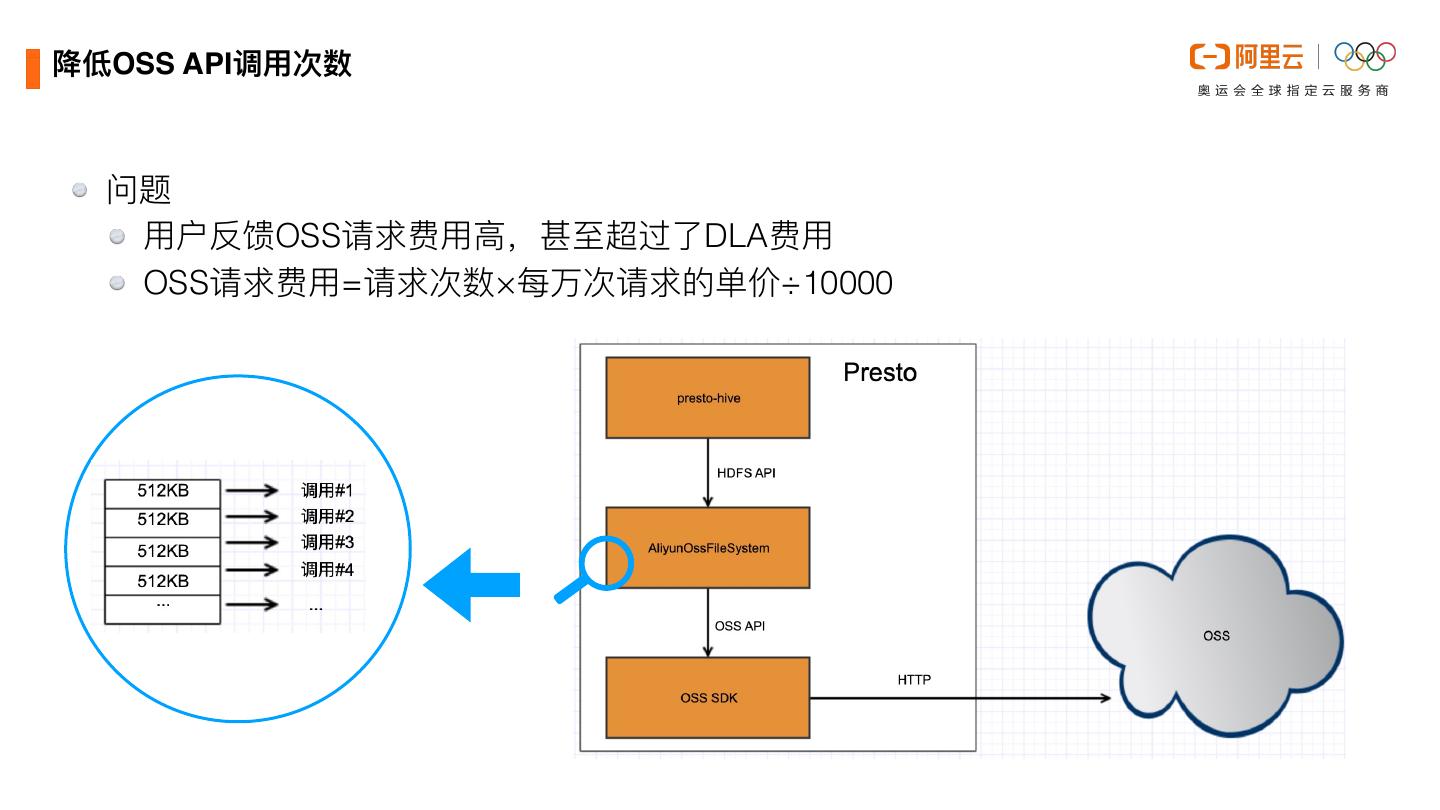
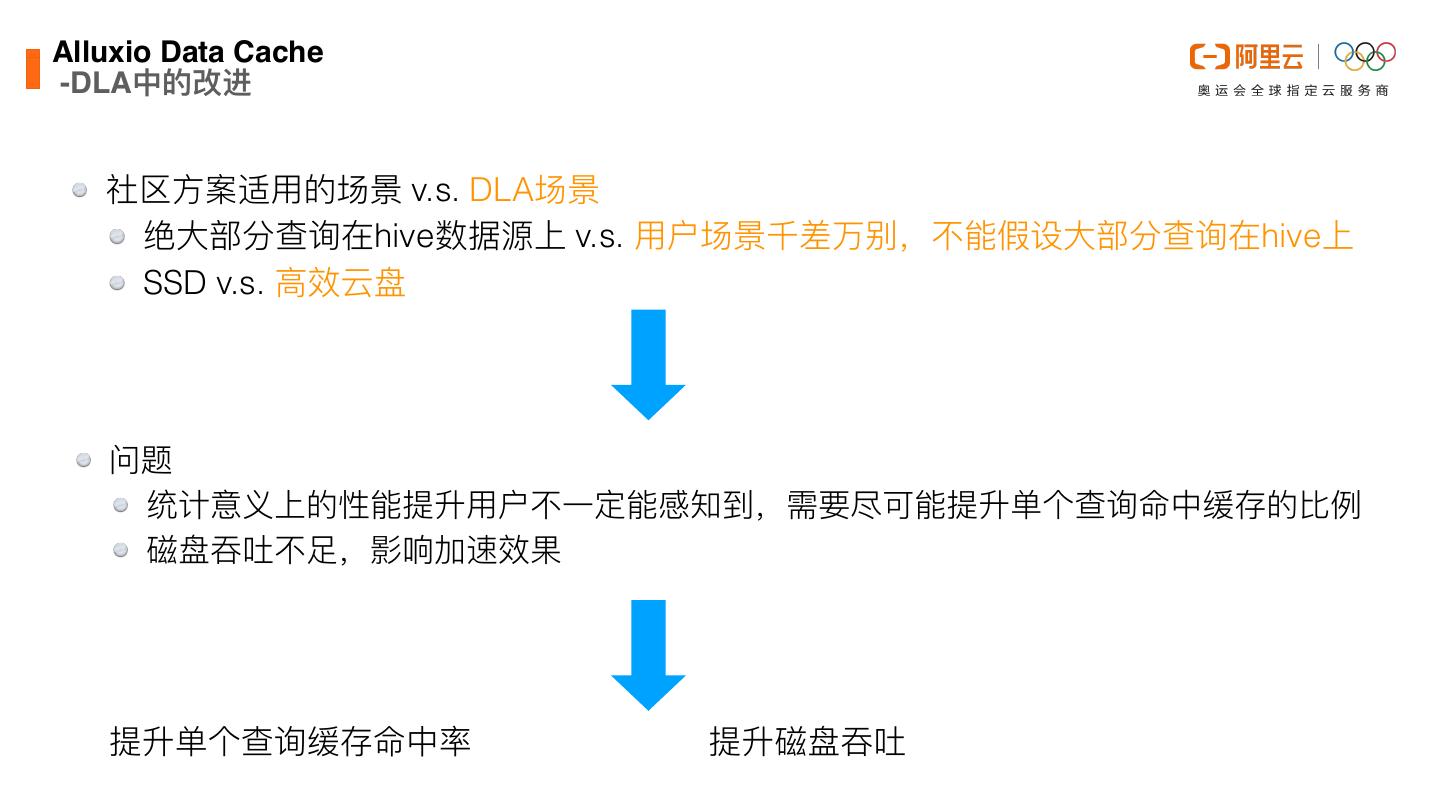
21 .降低OSS API调⽤次数 问题 ⽤户反馈OSS请求费⽤⾼,甚⾄超过了DLA费⽤ OSS请求费⽤=请求次数×每万次请求的单价÷10000
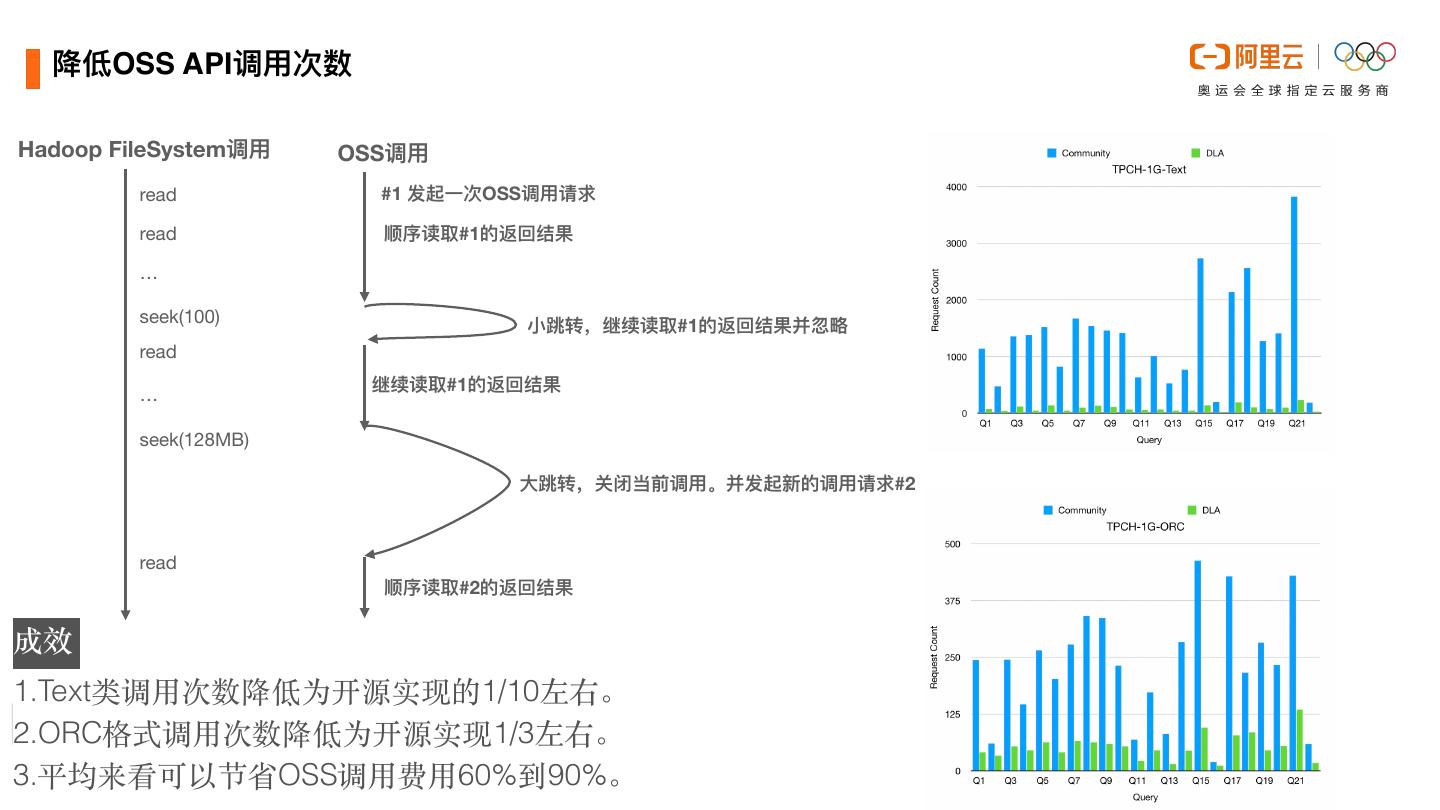
22 . 降低OSS API调⽤次数 Hadoop FileSystem调⽤ OSS调⽤ read #1 发起⼀次OSS调⽤请求 read 顺序读取#1的返回结果 … seek(100) ⼩跳转,继续读取#1的返回结果并忽略 read 继续读取#1的返回结果 … seek(128MB) ⼤跳转,关闭当前调⽤。并发起新的调⽤请求#2 read 顺序读取#2的返回结果 成效 1.Text类调⽤次数降低为开源实现的1/10左右。 2.ORC格式调⽤次数降低为开源实现1/3左右。 3.平均来看可以节省OSS调⽤费⽤60%到90%。
23 .Alluxio Data Cach -Why Alluxio 社区成熟⽅案 ⾼性能 完善的监控指标 Facebook/⽹易 ⽀持⾼并发 ⽅便监控和问 /京东⽣产环境 缓存异步写⼊ 题排查 验证 e
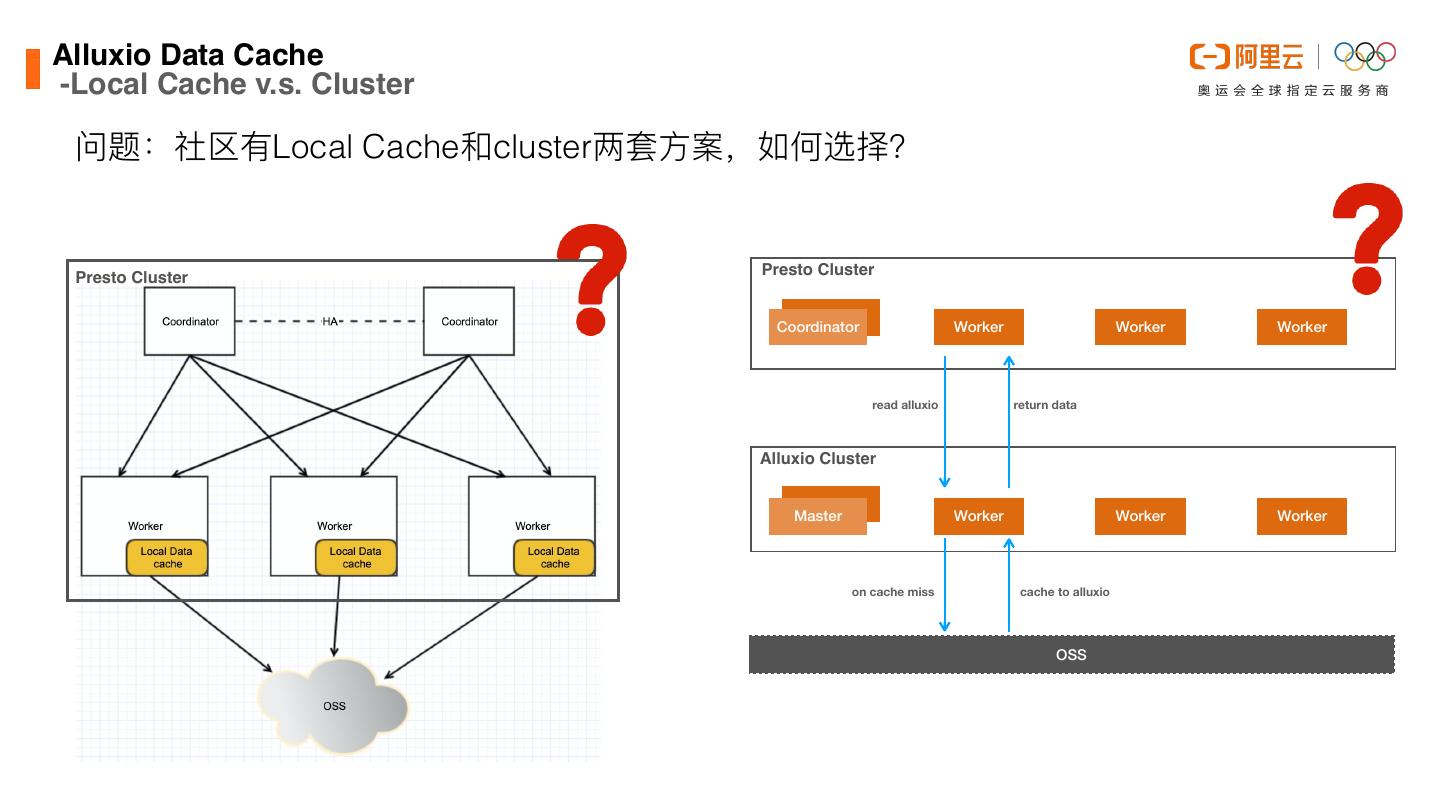
24 .Alluxio Data Cach -Local Cache v.s. Cluster 问题:社区有Local Cache和cluster两套⽅案,如何选择? Presto Cluster Presto Cluster Coordinator Worker Worker Worker read alluxio return data Alluxio Cluster Master Worker Worker Worker on cache miss cache to alluxio OSS e
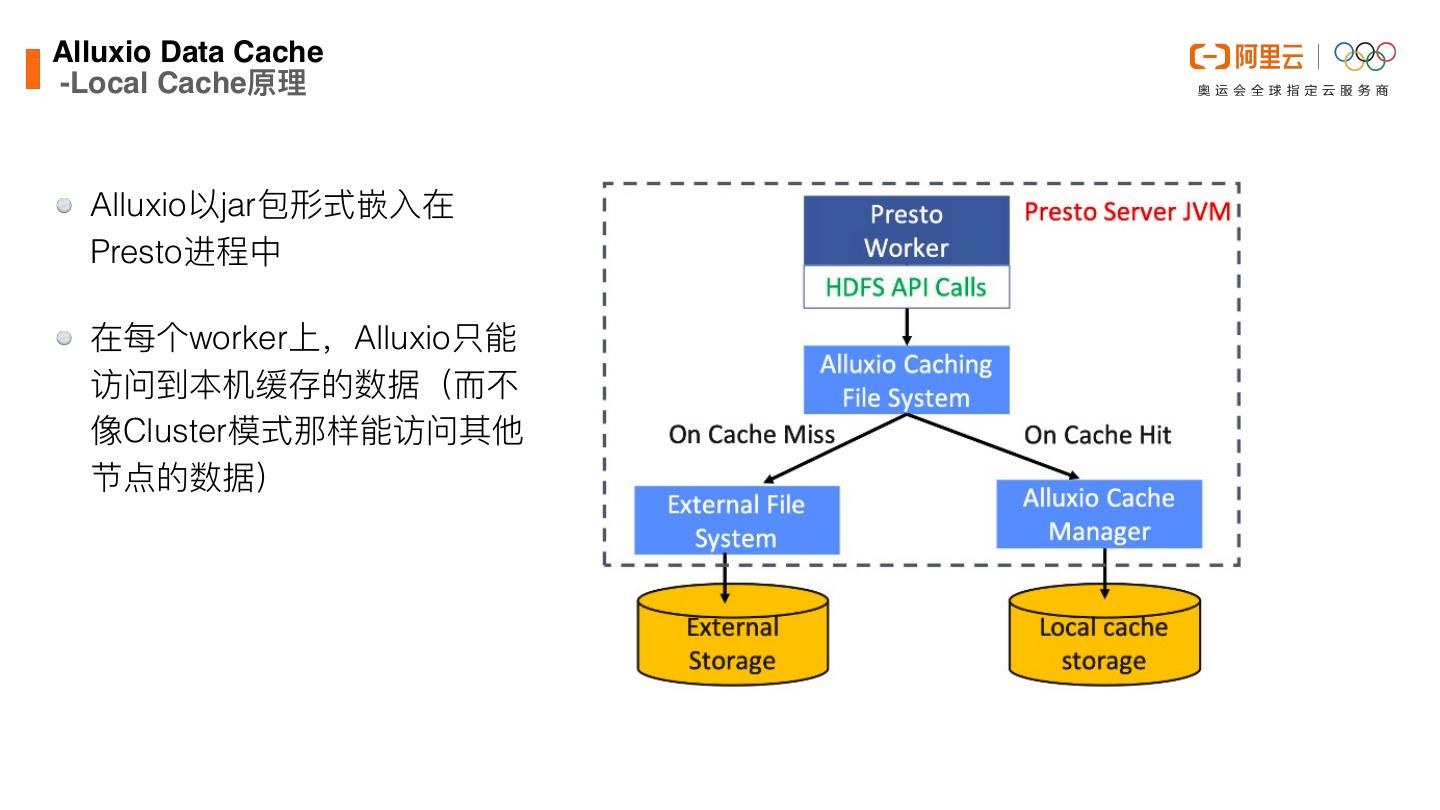
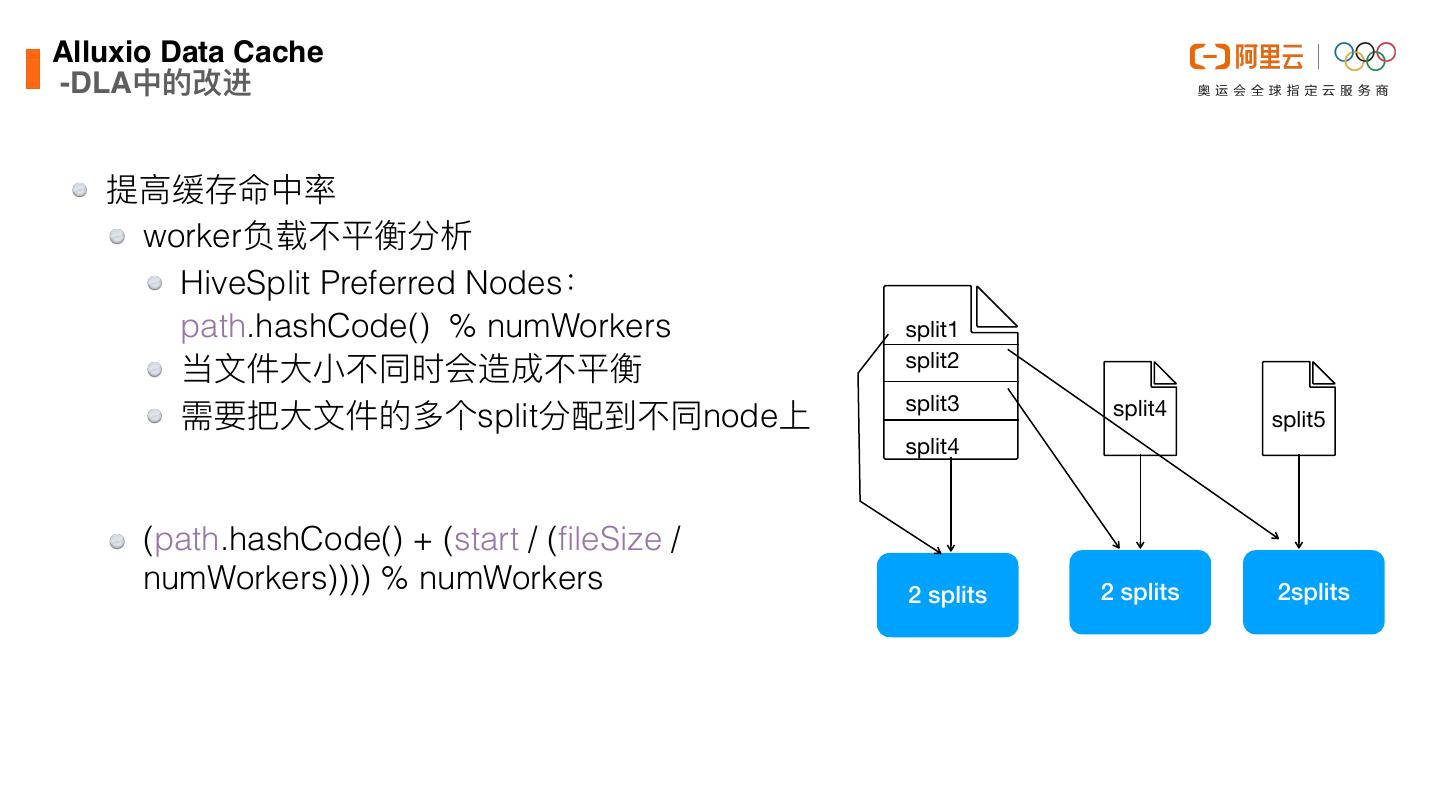
25 .Alluxio Data Cach -Local Cache原理 Alluxio以jar包形式嵌⼊在 Presto进程中 在每个worker上,Alluxio只能 访问到本机缓存的数据(⽽不 像Cluster模式那样能访问其他 节点的数据) e
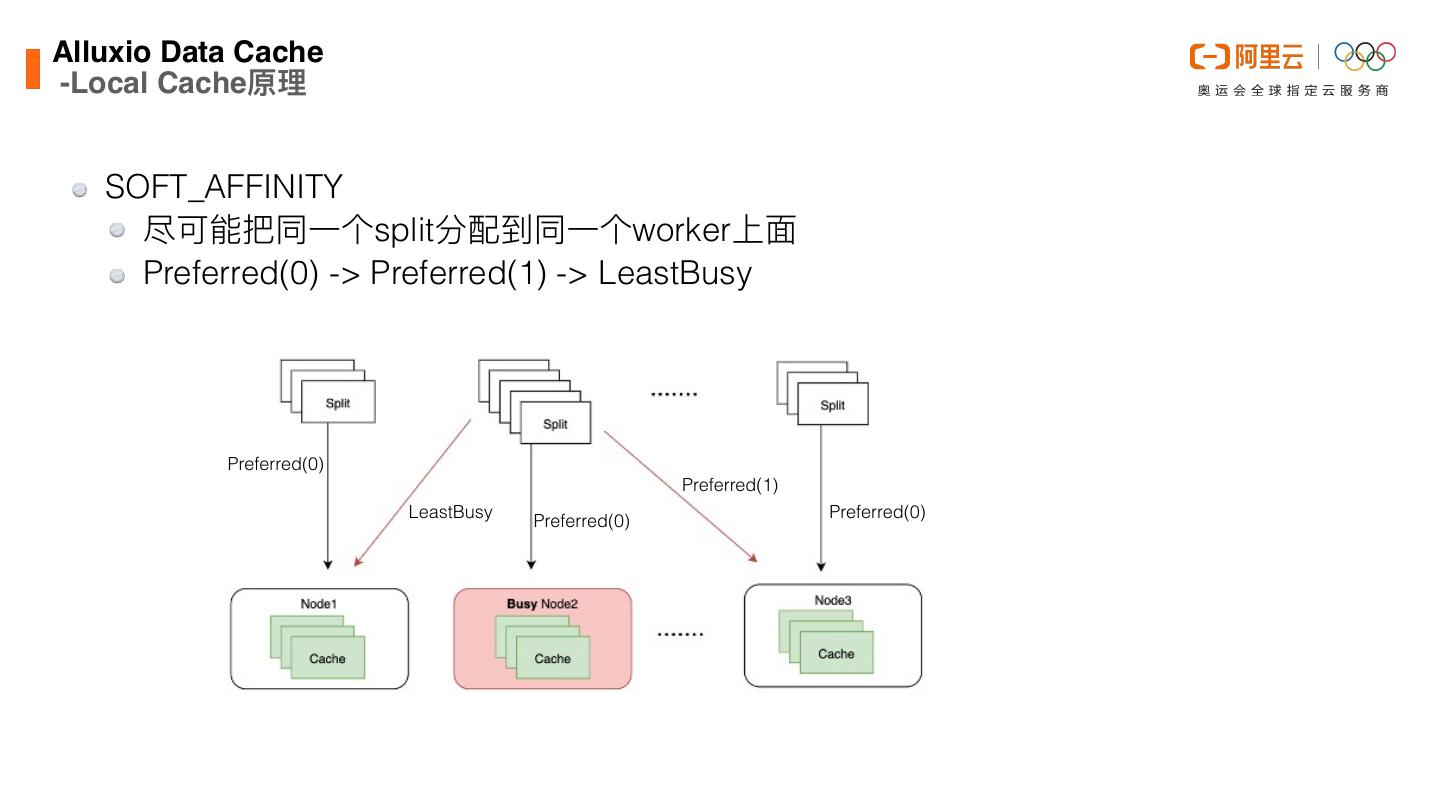
26 .Alluxio Data Cach -Local Cache原理 SOFT_AFFINITY 尽可能把同⼀个split分配到同⼀个worker上⾯ Preferred(0) -> Preferred(1) -> LeastBusy Preferred(0) Preferred(1) LeastBusy Preferred(0) Preferred(0) e
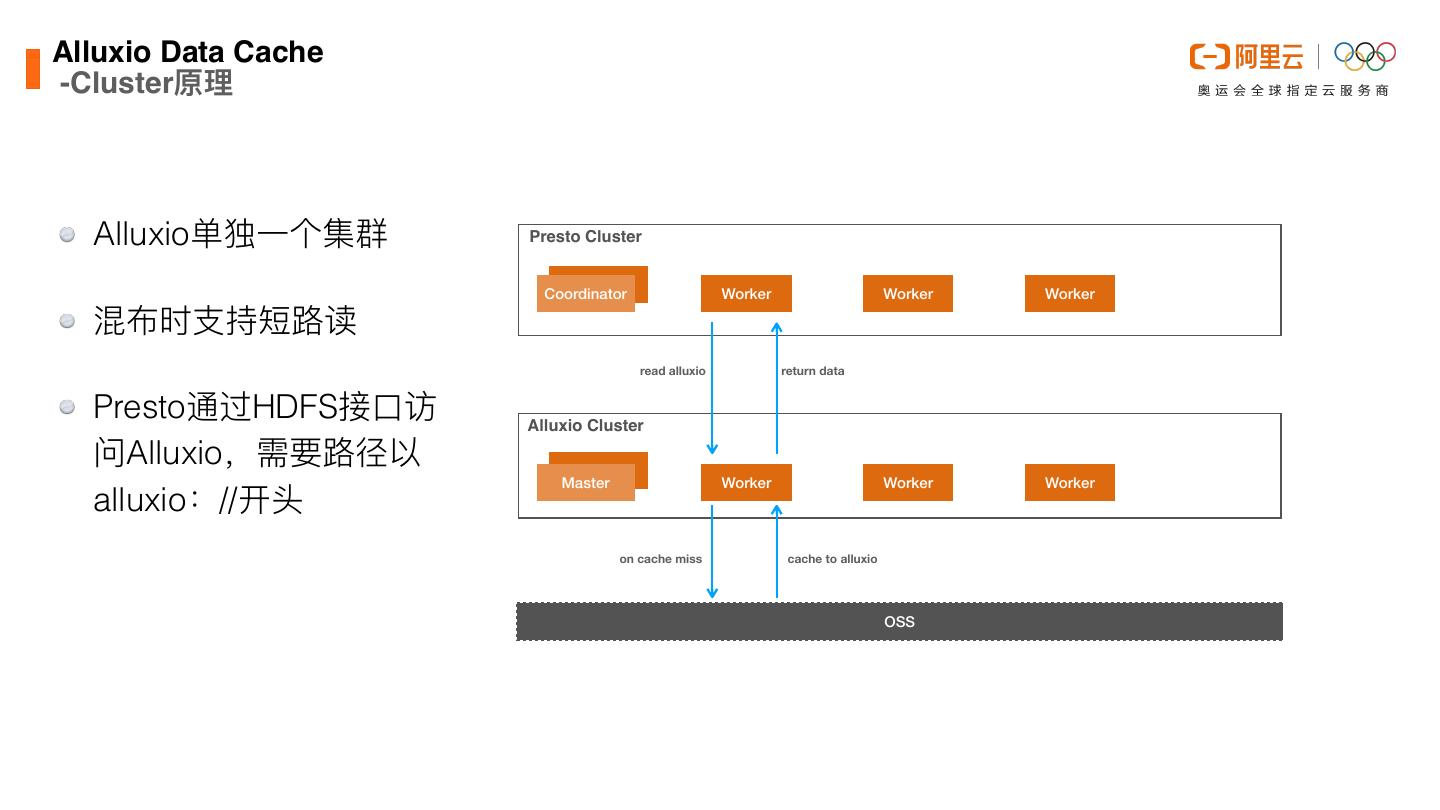
27 .Alluxio Data Cach -Cluster原理 Alluxio单独⼀个集群 Presto Cluster Coordinator Worker Worker Worker 混布时⽀持短路读 read alluxio return data Presto通过HDFS接⼝访 Alluxio Cluster 问Alluxio,需要路径以 Master Worker Worker Worker alluxio://开头 on cache miss cache to alluxio OSS e
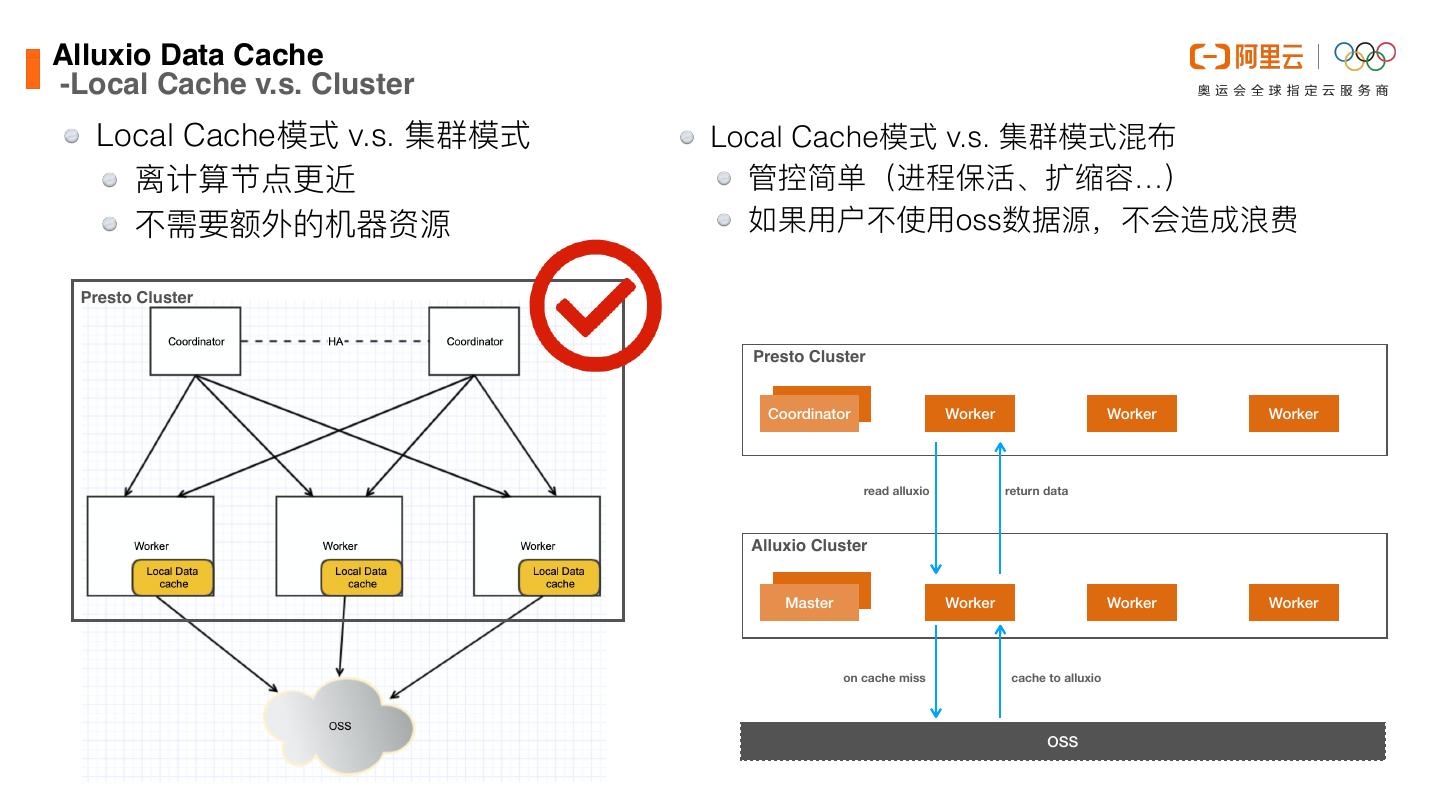
28 .Alluxio Data Cach -Local Cache v.s. Cluster Local Cache模式 v.s. 集群模式 Local Cache模式 v.s. 集群模式混布 离计算节点更近 管控简单(进程保活、扩缩容…) 不需要额外的机器资源 如果⽤户不使⽤oss数据源,不会造成浪费 Presto Cluster Presto Cluster Coordinator Worker Worker Worker read alluxio return data Alluxio Cluster Master Worker Worker Worker on cache miss cache to alluxio OSS e
29 .Alluxio Data Cach -Local Cache v.s. Cluster Local Cache模式 v.s. 集群模式 离计算节点更近 不需要额外的机器资源 Local Cache模式 v.s. 集群模式混布 管控简单(进程保活、扩缩容…) 如果⽤户不使⽤oss数据源,不会造成浪费 e
3秒后跳转登录页面
去登陆

