




































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
使用英特尔 oneAPI AI 分析工具包提升AI应用性能
议题介绍
此课程帮助开发者全面了解英特尔® oneAPI AI 分析工具包。该工具包为数据科学家、人工智能开发人员和研究人员提供了熟悉的 Python* 工具和AI框架,用以加速英特尔®架构上的端到端数据科学和分析能力。oneAPI 组件由一些 oneAPI高性能库构建,包括了底层硬件优化,可以最大限度地提高机器学习预处理的性能,并为高效的模型开发,部署提供高效的解决方案。
胡英,博士,英特尔高级软件工程师
展开查看详情
1 .应用Intel® AI 分析工具加速AI 落地 Boosting AI Workload Performance with Intel® oneAPI AI Analytics Toolkit Ying Hu November 2021 1
2 .Agenda • Intel® oneAPI & AI Analytics Toolkit Overview • Machine Learning Products Introduction • Deep Learning Products Introduction 2
3 .Intel’s oneAPI Ecosystem ▪ Built on Intel’s Rich Heritage of CPU Tools Expanded to XPUs oneAPI Application Workloads Need Diverse Hardware ▪ A cross-architecture language Middleware & Frameworks (Powered by oneAPI) based on C++ and SYCL ... standards ▪ Powerful libraries designed for Intel® oneAPI Product acceleration of domain-specific Libraries functions oneMKL oneTBB oneVPL oneDPL Analysis & Debug Compatibility Tool Languages Tools ▪ A complete set of advanced oneDAL oneDNN oneCCL compilers, libraries, and porting, Low-Level Hardware Interface analysis and debugger tools XPUs CPU GPU FPGA Other accelerators Visit software.intel.com/oneapi for more details Some capabilities may differ per architecture and custom-tuning will still be required. Other accelerators to be supported in the future. 33
4 .Intel® oneAPI DPC++/C++ Compiler Parallel Programming Productivity & Performance oneAPI DPC++/C++ Compiler and Runtime Compiler to deliver uncompromised parallel programming DPC++ Source Code productivity and performance across CPUs and accelerators ▪ Allows code reuse across hardware targets, while permitting custom tuning for a Clang/LLVM specific accelerator ▪ Open, cross-industry alternative to single architecture proprietary language DPC++ is based on ISO C++ and Khronos SYCL DPC++ Runtime ▪ Delivers C++ productivity benefits, using common and familiar C and C++ constructs ▪ Incorporates SYCL from The Khronos Group to support data parallelism and heterogeneous programming Builds upon Intel’s decades of experience in architecture CPU GPU FPGA and high-performance compilers There will still be a need to tune for each architecture. 4
5 .5 Intel® DPC++ Compatibility Tool Minimizes Code Migration Time Assists developers migrating code Intel DPC ++ Compatibility Tool Usage Flow written in CUDA to DPC++ once, generating human readable code Complete Coding & wherever possible Tune to Desired 80-90% Performance ~80-90% of code typically migrates Transformed automatically Human Readable DPC++ with inline Inline comments are provided Comments to help developers finish porting the Developer’s CUDA Compatibility DPC++ application Source Code Tool Source Code 5
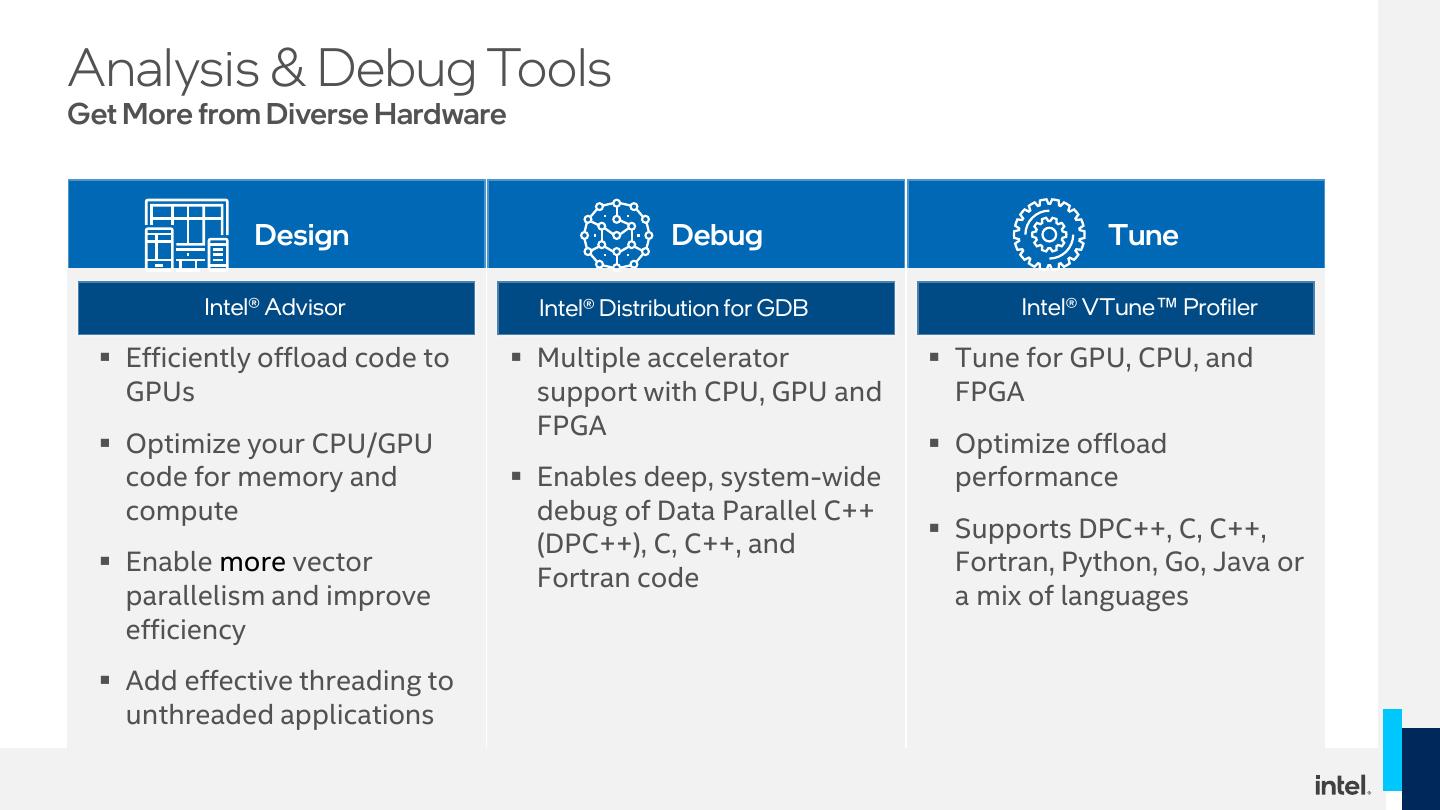
6 .Analysis & Debug Tools Get More from Diverse Hardware Design Debug Tune Intel® Advisor Intel® Distribution for GDB Intel® VTune™ Profiler ▪ Efficiently offload code to ▪ Multiple accelerator ▪ Tune for GPU, CPU, and GPUs support with CPU, GPU and FPGA FPGA ▪ Optimize your CPU/GPU ▪ Optimize offload code for memory and ▪ Enables deep, system-wide performance compute debug of Data Parallel C++ ▪ Supports DPC++, C, C++, (DPC++), C, C++, and ▪ Enable more vector Fortran, Python, Go, Java or Fortran code parallelism and improve a mix of languages efficiency ▪ Add effective threading to unthreaded applications 6
7 .Intel® oneAPI Toolkits A complete set of proven developer tools expanded from CPU to XPU A core set of high-performance tools for building C++, Data Parallel C++ applications & oneAPI library-based applications Native Code Developers Intel® oneAPI Intel® oneAPI Intel® oneAPI Rendering Tools for HPC Tools for IoT Toolkit Deliver fast Fortran, Build efficient, reliable Create performant, OpenMP & MPI solutions that run at high-fidelity visualization applications that network’s edge applications scale Specialized Workloads Intel® AI Analytics Intel® Distribution of Toolkit OpenVINO™ Toolkit Accelerate machine learning & data Deploy high performance science pipelines with optimized DL inference & applications from frameworks & high-performing Toolkit edge to cloud Python libraries Data Scientists & AI Developers Latest version is 2021.1 7
8 .Intel® oneAPI Toolkits Free Availability Run the tools locally Run the tools in the Cloud Downloads Get Started Quickly Code Samples, Quick-start Guides, Webinars, Training Repositories DevCloud software.intel.com/oneapi Containers 8
9 .oneAPI Resources software.intel.com/oneapi Learn and Get Started Industry Initiative ▪ software.intel.com/oneapi ▪ oneAPI.com ▪ Training ▪ oneAPI Industry Specification ▪ Documentation ▪ Open Source Implementations ▪ Code Samples Ecosystem ▪ Community Forums ▪ Academic Program ▪ Intel® DevMesh Innovator Projects 9
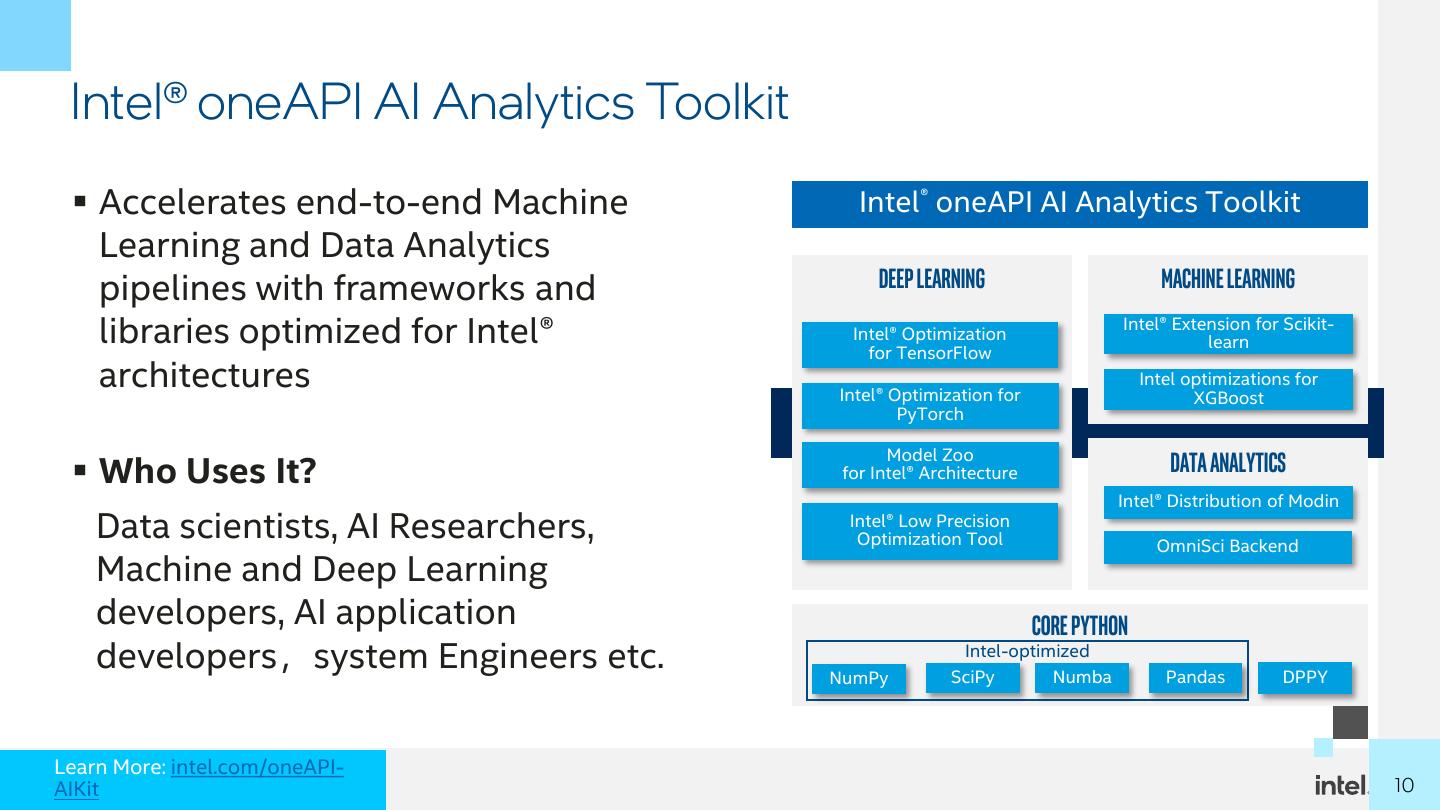
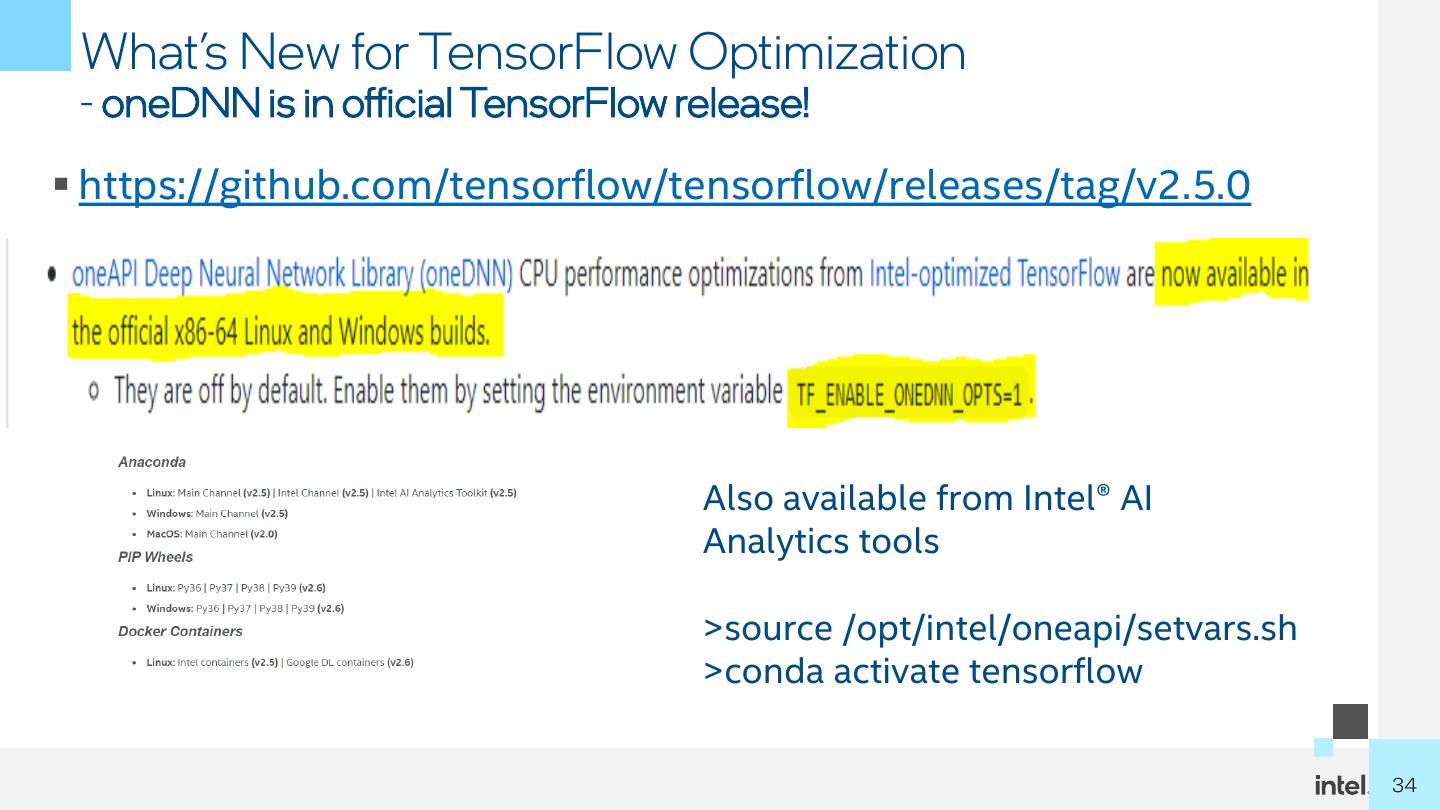
10 . Intel® oneAPI AI Analytics Toolkit ▪ Accelerates end-to-end Machine Intel® oneAPI AI Analytics Toolkit Learning and Data Analytics pipelines with frameworks and Deep Learning Machine learning libraries optimized for Intel® Intel® Optimization for TensorFlow Intel® Extension for Scikit- learn architectures Intel® Optimization for Intel optimizations for XGBoost PyTorch Model Zoo ▪ Who Uses It? for Intel® Architecture Data Analytics Intel® Distribution of Modin Data scientists, AI Researchers, Intel® Low Precision Optimization Tool OmniSci Backend Machine and Deep Learning developers, AI application Core Python developers,system Engineers etc. NumPy Intel-optimized SciPy Numba Pandas DPPY Learn More: intel.com/oneAPI- AIKit 1010
11 .AI Software Stack for Intel XPUs Intel offers a Robust Software Stack to Maximize Performance of Diverse Workloads E2E Intel® Low Model Zoo Workloads Precision Open DL/ML Tools for Intel® (Census, NYTaxi, Optimization Model Zoo Mortgage…) Architecture Tool panda nump Scikit- s y learn DL/ML numb a xgboost TensorFlow PyTorch Model Optimizer Middleware & daal4P & Frameworks Modin scipy y Inference Engine Libraries & DPC++ oneMK oneDA oneDN oneTBB oneCCL oneVPL Compiler / DPPY L L N Part of the Intel® oneAPI Base Toolkit 11
12 .AI Software Stack for Intel XPUs Intel offers a Robust Software Stack to Maximize Performance of Diverse Workloads E2E Intel® Low Model Zoo Workloads Precision Open DL/ML Tools for Intel® (Census, NYTaxi, IntelOptimization ® oneAPI Architecture Intel Model ® Zoo Mortgage…) AI AnalyticsTool Toolkit OpenVINO ™ Toolkit Develop DL models in Frameworks, panda s y ML &Scikit- nump Analytics in Python learn Model Deploy DL DL/ML numb Optimizer xgboost TensorFlow PyTorch models Middleware & a Inference daal4P Frameworks Modin scipy y Engine DPC++ oneMK Intel oneDAoneAPI Base Toolkit ® oneDN Libraries & oneTBB oneCCL oneVPL / DPPY Kernel L Selection, L Write, Customize Kernels N Compiler Full Set of Intel oneAPI cross-architecture AI ML & DL Software Solutions 12
13 .Getting Started with Intel® oneAPI AI Analytics Toolkit Overview Installation Hands on Learning Support ▪ Visit Intel® oneAPI AI ▪ Download the AI Kit ▪ Code Samples ▪ Machine Learning & ▪ Ask questions and Analytics Toolkit (AI from Intel, Anaconda Analytics Blogs share information ▪ Build, test and Kit) for more details or any of your favorite with others through remotely run ▪ Intel AI Blog site and up-to-date package managers the Community workloads on the product information ▪ Webinars & articles Forum ▪ Get started quickly Intel® DevCloud for ▪ Release Notes with the AI Kit Docker free. No software ▪ Discuss with experts Container downloads. No at AI Frameworks configuration steps. Forum ▪ Installation Guide No installations. ▪ Utilize the Getting Started Guide Download Now 13
14 .14 Speed Up Development with open AI software Model Machine learning Deep learning TOOLKITs Model App Developers Zoo Intel® Data Intel® Modin Intel Optimized Frameworks libraries Analytics Acceleration Distribution for Python* * Data Scientists Library (Sklearn*, (oneDAL) Pandas*, More framework optimizations in progress… xgboost, etc) Intel® oneAPI Kernels Intel® Math Kernel Library Collective Deep Neural Networks Library Communication (Intel® oneDNN) Library (Intel® MKL) Developers Library (Intel® oneCCL) Visit: www.intel.ai/technology CPU ▪︎ GPU 1 An open source version is available at: 01.org/openvinotoolkit *Other names and brands may be claimed as the property of others. Developer personas show above represent the primary user base for each row, but are not mutually-exclusive All products, computer systems, dates, and figures are preliminary based on current expectations, and are subject to change without notice. Optimization Notice 14
15 .Machine Learning Products 15
16 .Intel® Distribution for Python Intel® Distribution for Python ▪ Develop fast, performant Python code with this set of essential computational packages Numeric & Scientific Packages NumPy SciPy Numba ▪ Who Uses It? Machine Learning Packages ▪ Machine Learning Developers, Data Scientists, and Scikit-Learn XGBoost* daal4py Analysts can implement performance-packed, Dataframe Packages production-ready scikit-learn algorithms Modin Pandas SDC ▪ Numerical and Scientific Computing Developers can accelerate and scale the compute-intensive Python Runtimes packages NumPy, SciPy, and mpi4py OpenCL DPC++ ▪ High-Performance Computing (HPC) Developers can unlock the power of modern hardware to speed up Supported Hardware Architectures your Python applications CPU GPU Hardware support varies by individual tool. Architecture support will be expanded over Initial GPU support enabled with Data Parallel Python time. Other names and brands may be claimed as the property of others. 1616
17 .Installing Intel® Distribution for Python* Standalone Download full installer from Installer https://software.intel.com/en-us/intel-distribution-for-python 2.7 & 3.6 & > conda config --add channels intel 3.7 Anaconda.org > conda install intelpython3_full Anaconda.org/intel channel > conda install intelpython3_core > pip install intel-numpy > pip install intel-scipy + Intel library Runtime packages PyPI > pip install mkl_fft + Intel development packages > pip install mkl_random Docker Hub docker pull intelpython/intelpython3_full Access for yum/apt: YUM/APT https://software.intel.com/en-us/articles/installing-intel-free- libs-and-python 17
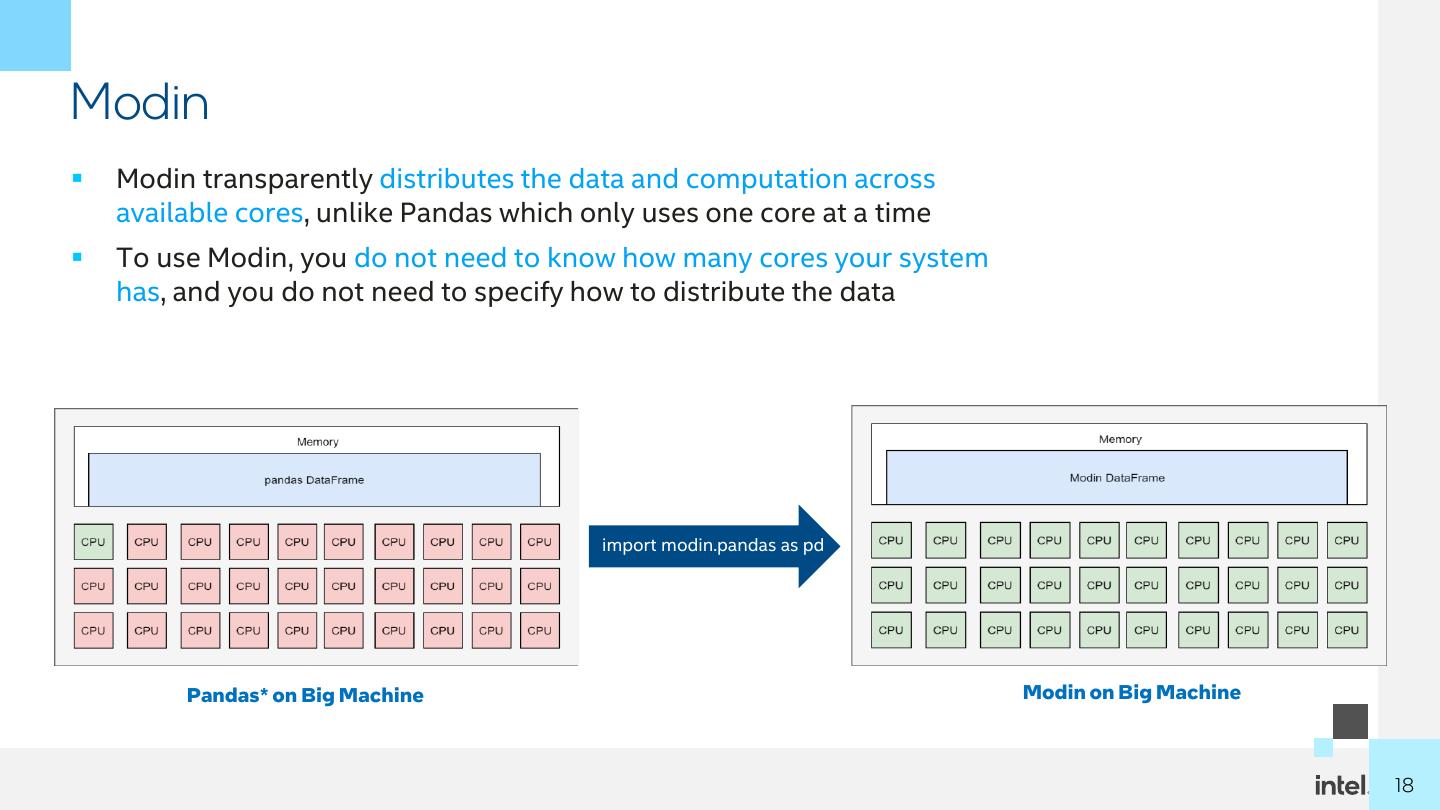
18 .Modin ▪ Modin transparently distributes the data and computation across available cores, unlike Pandas which only uses one core at a time ▪ To use Modin, you do not need to know how many cores your system has, and you do not need to specify how to distribute the data import modin.pandas as pd Pandas* on Big Machine Modin on Big Machine 1818
19 .Single Line Code Change for Infinite Scalability ▪ No need to learn a new API to use Modin ▪ As of 0.9 version, Modin supports 100% of Pandas API ▪ Integration with the rest Python* ecosystem (use NumPy, XGBoost, Scikit-Learn*, etc. as normal) ▪ In the backend, Intel Distribution of Modin is supported by OmniSci*, a performant framework for end-to-end analytics that has been optimized to harness the computing power of existing and emerging Intel® hardware 1919
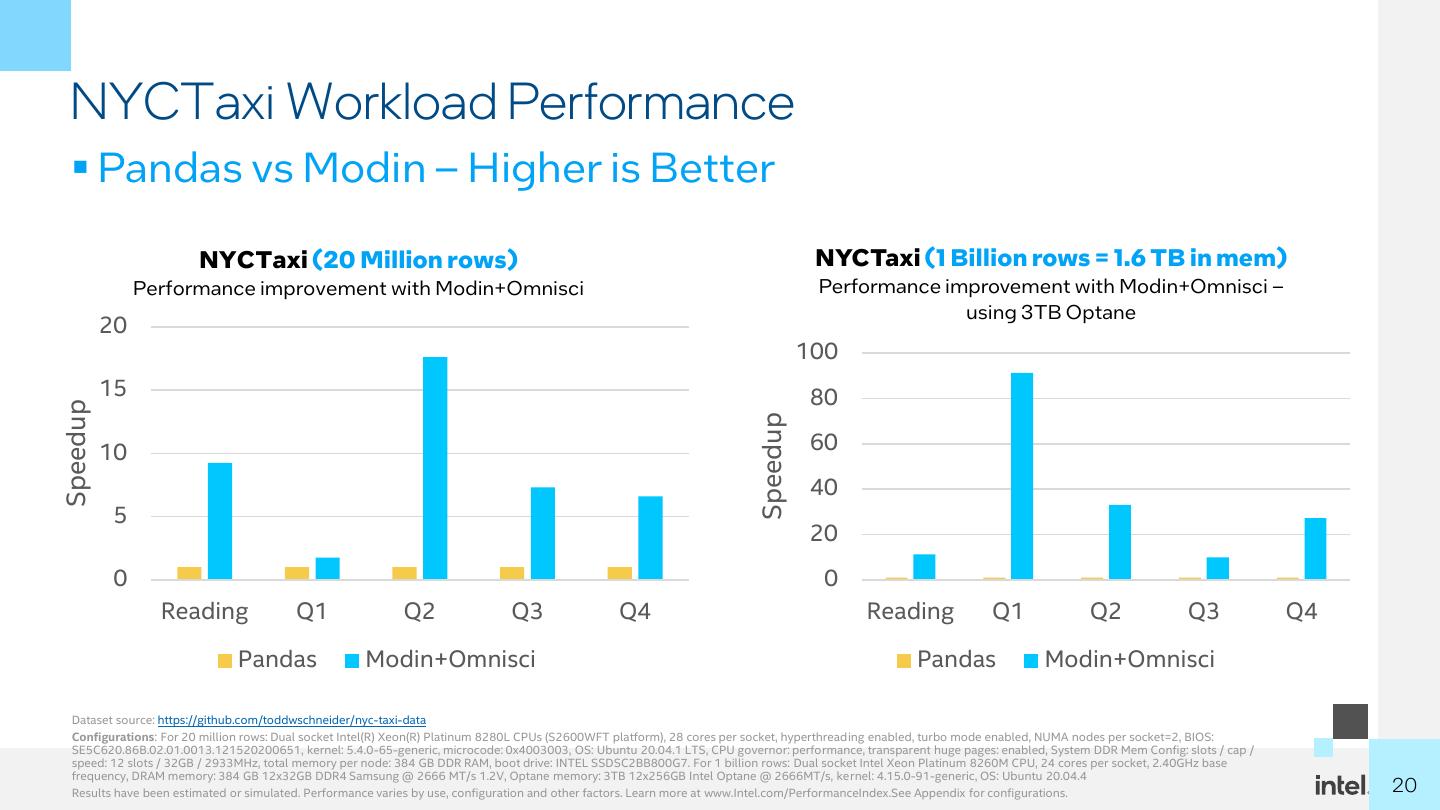
20 . NYCTaxi Workload Performance ▪ Pandas vs Modin – Higher is Better NYCTaxi (20 Million rows) NYCTaxi (1 Billion rows = 1.6 TB in mem) Performance improvement with Modin+Omnisci Performance improvement with Modin+Omnisci – using 3TB Optane 20 100 15 80 Speedup Speedup 10 60 40 5 20 0 0 Reading Q1 Q2 Q3 Q4 Reading Q1 Q2 Q3 Q4 Pandas Modin+Omnisci Pandas Modin+Omnisci Dataset source: https://github.com/toddwschneider/nyc-taxi-data Configurations: For 20 million rows: Dual socket Intel(R) Xeon(R) Platinum 8280L CPUs (S2600WFT platform), 28 cores per socket, hyperthreading enabled, turbo mode enabled, NUMA nodes per socket=2, BIOS: SE5C620.86B.02.01.0013.121520200651, kernel: 5.4.0-65-generic, microcode: 0x4003003, OS: Ubuntu 20.04.1 LTS, CPU governor: performance, transparent huge pages: enabled, System DDR Mem Config: slots / cap / speed: 12 slots / 32GB / 2933MHz, total memory per node: 384 GB DDR RAM, boot drive: INTEL SSDSC2BB800G7. For 1 billion rows: Dual socket Intel Xeon Platinum 8260M CPU, 24 cores per socket, 2.40GHz base frequency, DRAM memory: 384 GB 12x32GB DDR4 Samsung @ 2666 MT/s 1.2V, Optane memory: 3TB 12x256GB Intel Optane @ 2666MT/s, kernel: 4.15.0-91-generic, OS: Ubuntu 20.04.4 Results have been estimated or simulated. Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex.See Appendix for configurations. 20 20
21 . Intel® oneAPI Data Analytics Library (oneDAL) ▪ Boost Machine Learning & Data Analytics Performance What’s New in the oneDAL Release ▪ Helps applications deliver better predictions faster New GPU support for the following Algorithms: ▪ Optimizes data ingestion & algorithmic compute together for highest ▪ Statistical: Correlation, Low-order moments* performance ▪ Classification: Linear Regression*, Logistic Regression*, KNN, SVM ▪ Supports offline, streaming & distributed usage models to meet a ▪ Unsupervised Learning: K-means clustering, DBSCAN range of application needs ▪ Classification & Regression: Random Forest ▪ Split analytics workloads between edge devices and cloud to optimize overall application throughput ▪ Dimensionality Reduction: PCA Learn More: software.intel.com/oneAPI/oneDAL Pre-processing Transformation Analysis Modeling Validation Decision Making Decompression, Aggregation, Summary Statistics Machine Learning (Training) Hypothesis Testing Forecasting Filtering, Normalization Dimension Reduction Clustering, etc. Parameter Estimation Model Errors Decision Trees, etc. Simulation 2121
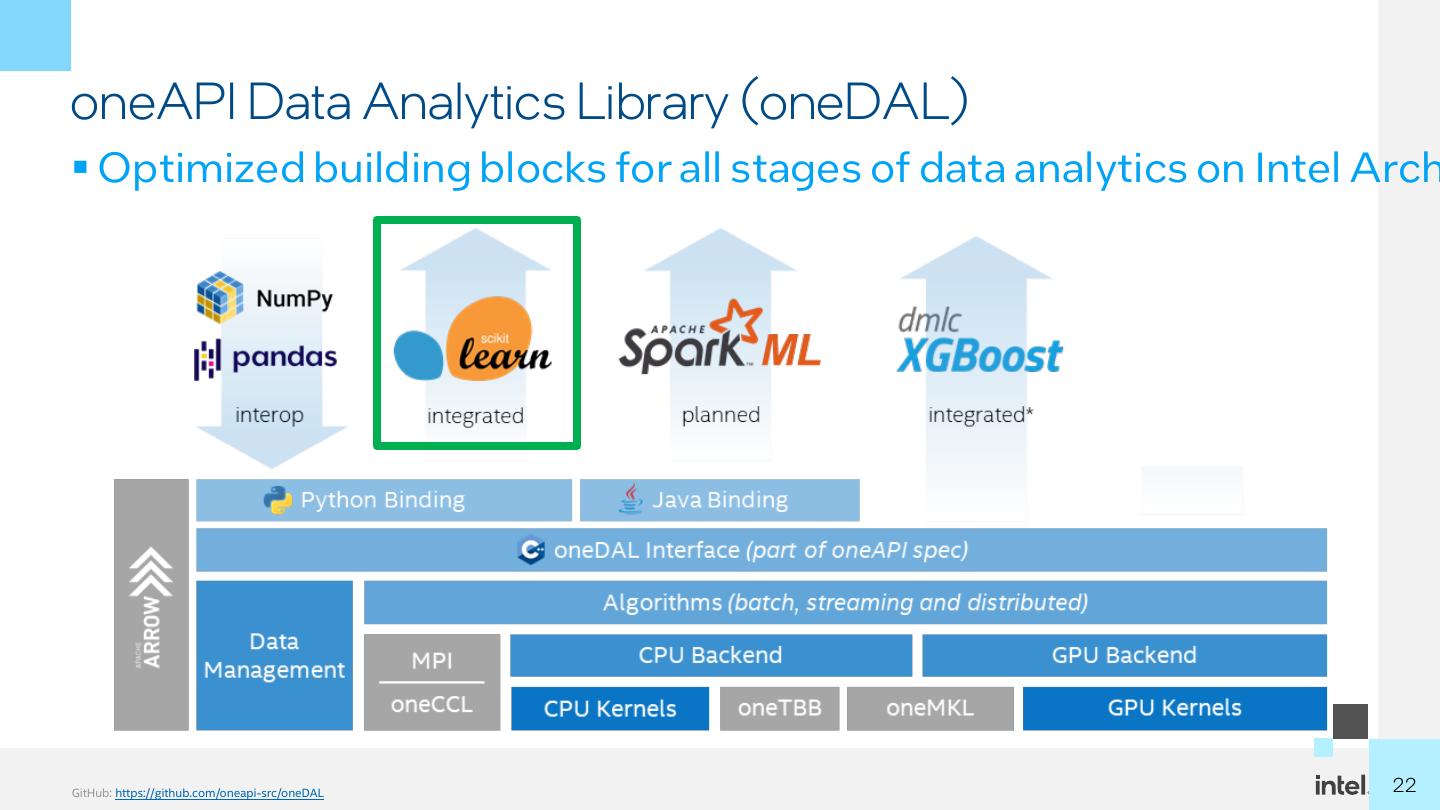
22 .oneAPI Data Analytics Library (oneDAL) ▪ Optimized building blocks for all stages of data analytics on Intel Arch GitHub: https://github.com/oneapi-src/oneDAL 2222
23 .Intel Extension for Scikit-Learn* Common Scikit-learn Scikit-learn with Intel CPU opts Same Code, from sklearnex import patch_sklearn Same Behavior patch_sklearn() ▪ from sklearn.svm import SVC from sklearn.svm import SVC ▪ X, Y = get_dataset() X, Y = get_dataset() • Scikit-learn, not scikit-learn-like • Scikit-learn conformance ▪ clf = SVC().fit(X, y) (mathematical equivalence) clf = SVC().fit(X, y) defined by Scikit-learn ▪ res = clf.predict(X) res = clf.predict(X) Consortium, continuously vetted by public CI Scikit-learn mainline Available through Intel conda (conda install scikit-learn-intelex -c intel) Monkey-patch any scikit-learn* on the command-line 23 23
24 . Intel optimizations for Scikit-Learn* Speedup of Intel® oneDAL powered Scikit-Learn over the original Scikit-Learn K-means fit 1M x 20, k=1000 44.0 K-means predict, 1M x 20, k=1000 PCA fit, 1M x 50 3.6 Same Code, 4.0 PCA transform, 1M x 50 27.2 Same Behavior Random Forest fit, higgs1m 38.3 Random Forest predict, higgs1m 55.4 Ridge Reg fit 10M x 20 53.4 Linear Reg fit 2M x 100 91.8 LASSO fit, 9M x 45 50.9 SVC fit, ijcnn 29.0 • Scikit-learn, not scikit-learn-like SVC predict, ijcnn 95.3 SVC fit, mnist 82.4 • Scikit-learn conformance SVC predict, mnist 221.0 (mathematical equivalence) DBSCAN fit, 500K x 50 17.3 defined by Scikit-learn train_test_split, 5M x 20 9.4 Consortium, kNN predict, 100K x 20, class=2, k=5 131.4 continuously vetted by public CI kNN predict, 20K x 50, class=2, k=5 113.8 0.0 50.0 100.0 150.0 200.0 250.0 HW: Intel Xeon Platinum 8276L CPU @ 2.20GHz, 2 sockets, 28 cores per socket; Details: https://medium.com/intel-analytics-software/accelerate-your-scikit-learn-applications-a06cacf44912 24 24
25 . XGBoost CPU acceleration – gain sources Pseudocode for XGBoost v0.81 (baseline): Pseudocode for optimized XGBoost: Memory prefetching to mitigate irregular memory access Nested parallelism by dtree nodes Training stage Usage uint8 instead of uint32 Advanced parallelism for samples partitioning, reducing seq loops SIMD instructions instead of scalar code Usage of AVX-512, vcompress instruction (from Skylake) Legend: Released in XGB 0.9 Released in XGB 1.0 Released XGB 1.1 Future scope 25 25
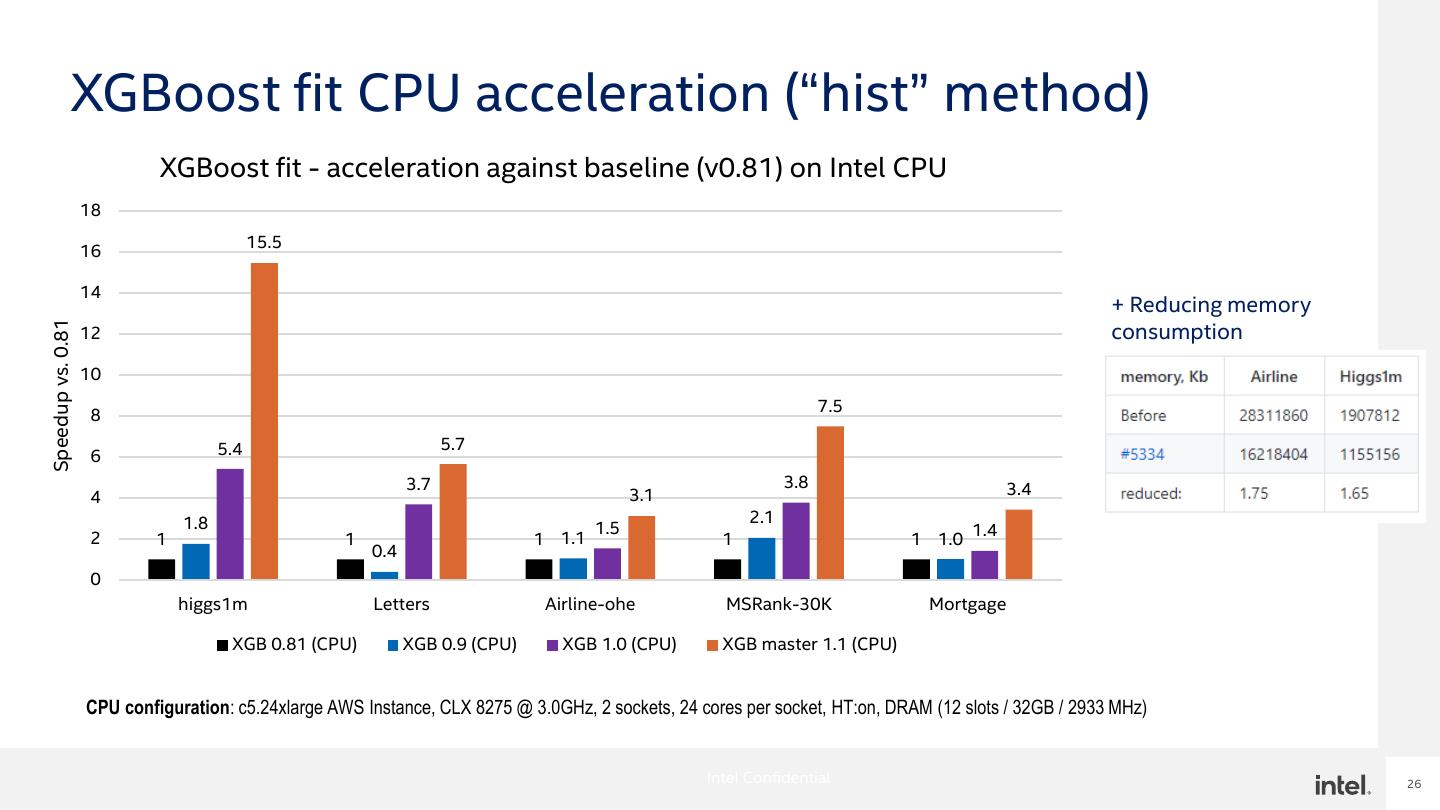
26 . XGBoost fit CPU acceleration (“hist” method) XGBoost fit - acceleration against baseline (v0.81) on Intel CPU 18 16 15.5 14 + Reducing memory consumption Speedup vs. 0.81 12 10 8 7.5 5.4 5.7 6 3.7 3.8 3.4 4 3.1 1.8 2.1 1.5 2 1 1 1 1.1 1 1 1.0 1.4 0.4 0 higgs1m Letters Airline-ohe MSRank-30K Mortgage XGB 0.81 (CPU) XGB 0.9 (CPU) XGB 1.0 (CPU) XGB master 1.1 (CPU) CPU configuration: c5.24xlarge AWS Instance, CLX 8275 @ 3.0GHz, 2 sockets, 24 cores per socket, HT:on, DRAM (12 slots / 32GB / 2933 MHz) Intel Confidential 26
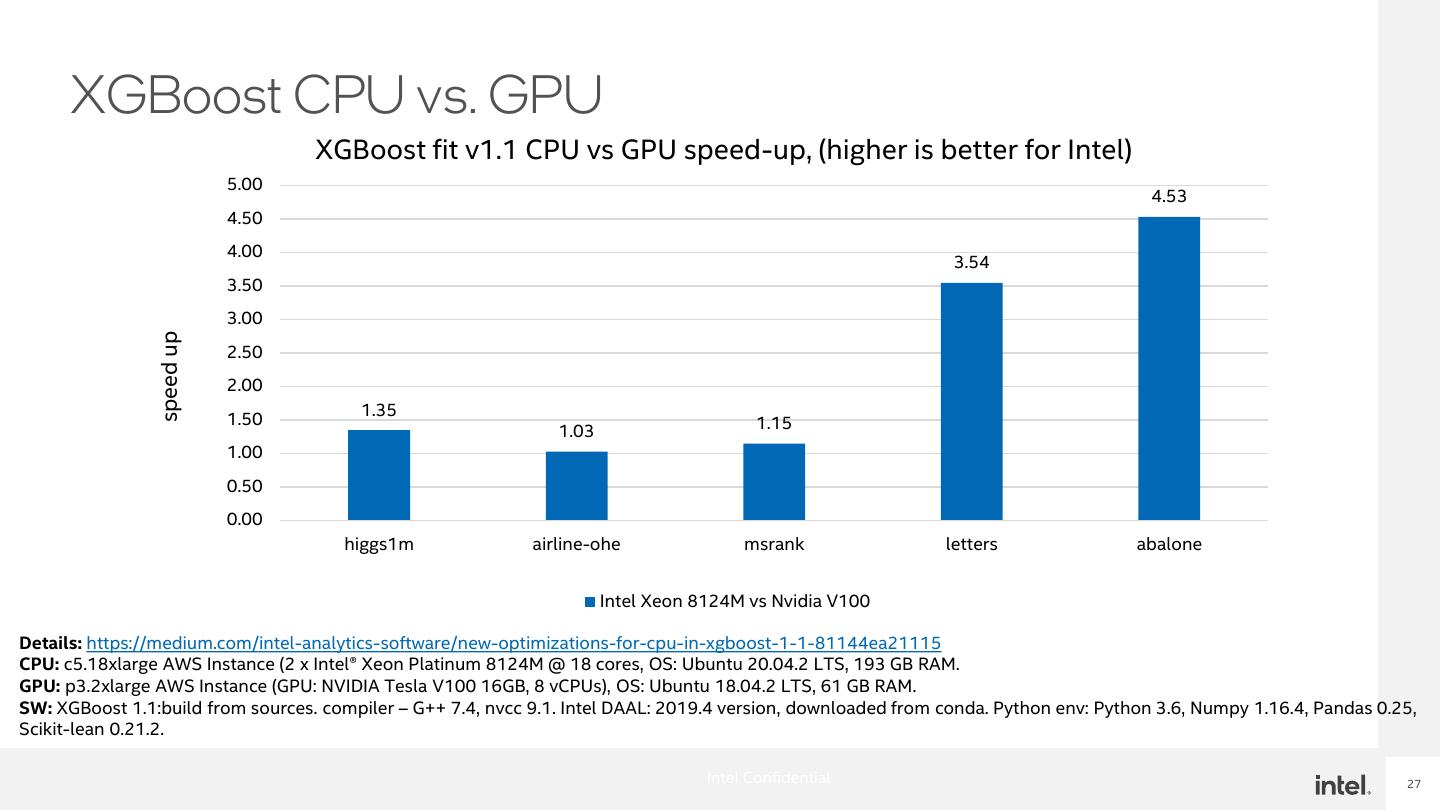
27 . XGBoost CPU vs. GPU XGBoost fit v1.1 CPU vs GPU speed-up, (higher is better for Intel) 5.00 4.53 4.50 4.00 3.54 3.50 3.00 speed up 2.50 2.00 1.35 1.50 1.15 1.03 1.00 0.50 0.00 higgs1m airline-ohe msrank letters abalone Intel Xeon 8124M vs Nvidia V100 Details: https://medium.com/intel-analytics-software/new-optimizations-for-cpu-in-xgboost-1-1-81144ea21115 CPU: c5.18xlarge AWS Instance (2 x Intel® Xeon Platinum 8124M @ 18 cores, OS: Ubuntu 20.04.2 LTS, 193 GB RAM. GPU: p3.2xlarge AWS Instance (GPU: NVIDIA Tesla V100 16GB, 8 vCPUs), OS: Ubuntu 18.04.2 LTS, 61 GB RAM. SW: XGBoost 1.1:build from sources. compiler – G++ 7.4, nvcc 9.1. Intel DAAL: 2019.4 version, downloaded from conda. Python env: Python 3.6, Numpy 1.16.4, Pandas 0.25, Scikit-lean 0.21.2. Intel Confidential 27
28 . Productivity with Performance via Intel® Distribution for Python* Modin is part of Intel AI Analytics Toolkit!, but separate from Intel Distribution for Python! Intel® Distribution for Python* mpi4py smp daal4py tbb4py Data acquisition & Numerical/Scientific computing & Composable Distributed preprocessing machine learning multi-threading parallelism Learn More: software.intel.com/distribution-for-python https://www.anaconda.com/blog/developer-blog/parallel-python-with-numba-and-parallelaccelerator/ 28 28
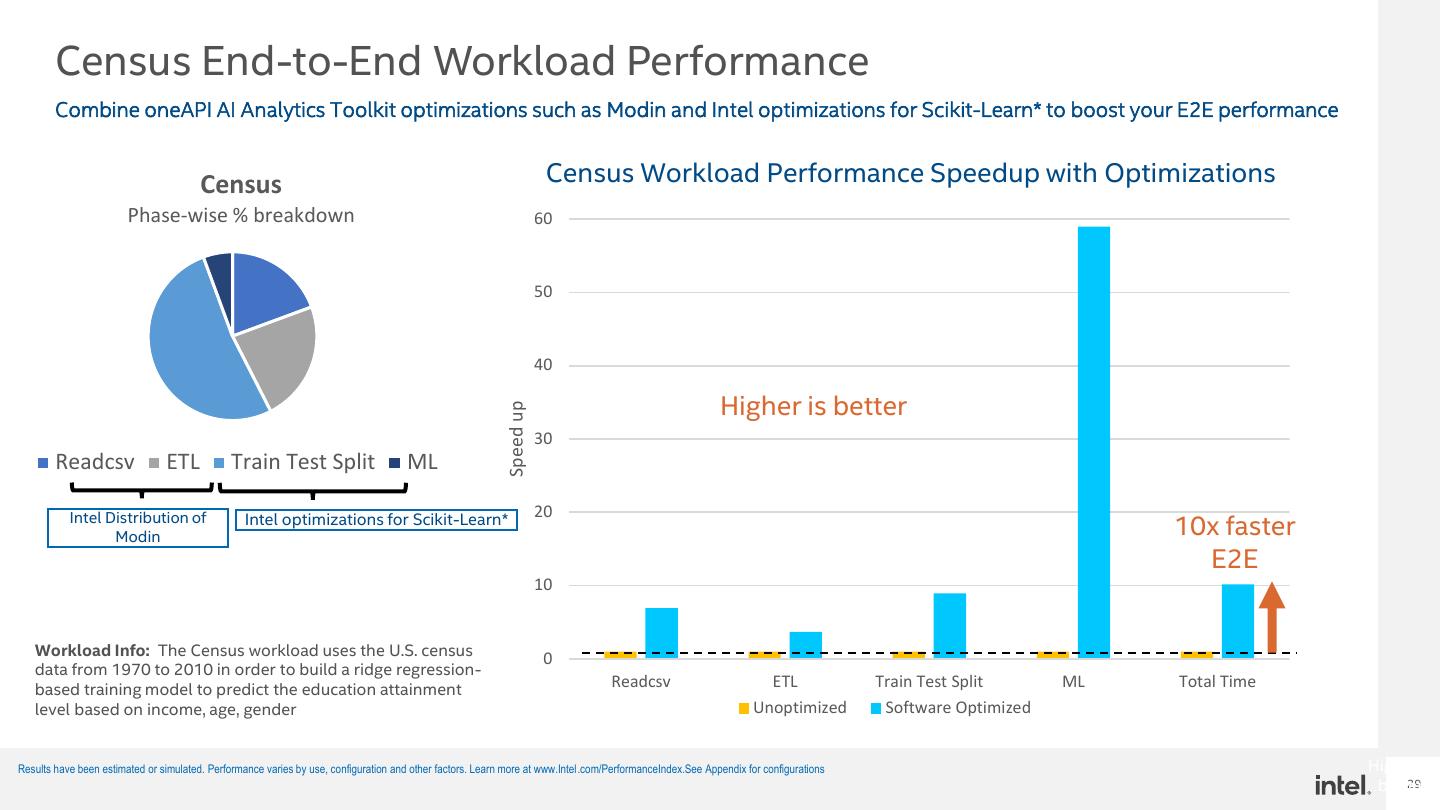
29 . Census End-to-End Workload Performance Combine oneAPI AI Analytics Toolkit optimizations such as Modin and Intel optimizations for Scikit-Learn* to boost your E2E performance Census Census Workload Performance Speedup with Optimizations Phase-wise % breakdown 60 50 40 Higher is better Speed up 30 Readcsv ETL Train Test Split ML Intel Distribution of Intel optimizations for Scikit-Learn* 20 Modin 10x faster E2E 10 Workload Info: The Census workload uses the U.S. census 0 data from 1970 to 2010 in order to build a ridge regression- based training model to predict the education attainment Readcsv ETL Train Test Split ML Total Time level based on income, age, gender Unoptimized Software Optimized Results have been estimated or simulated. Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex.See Appendix for configurations Higher is better 29
3秒后跳转登录页面
去登陆

