展开查看详情
1 .PaddleX+OpenVINO高性能工业质
检方案
百度高级研发工程师:何礼祺
�
2 .目录 1 飞桨全流程开发工具PaddleX概览
Contents
2 高性能工业质检方案
�
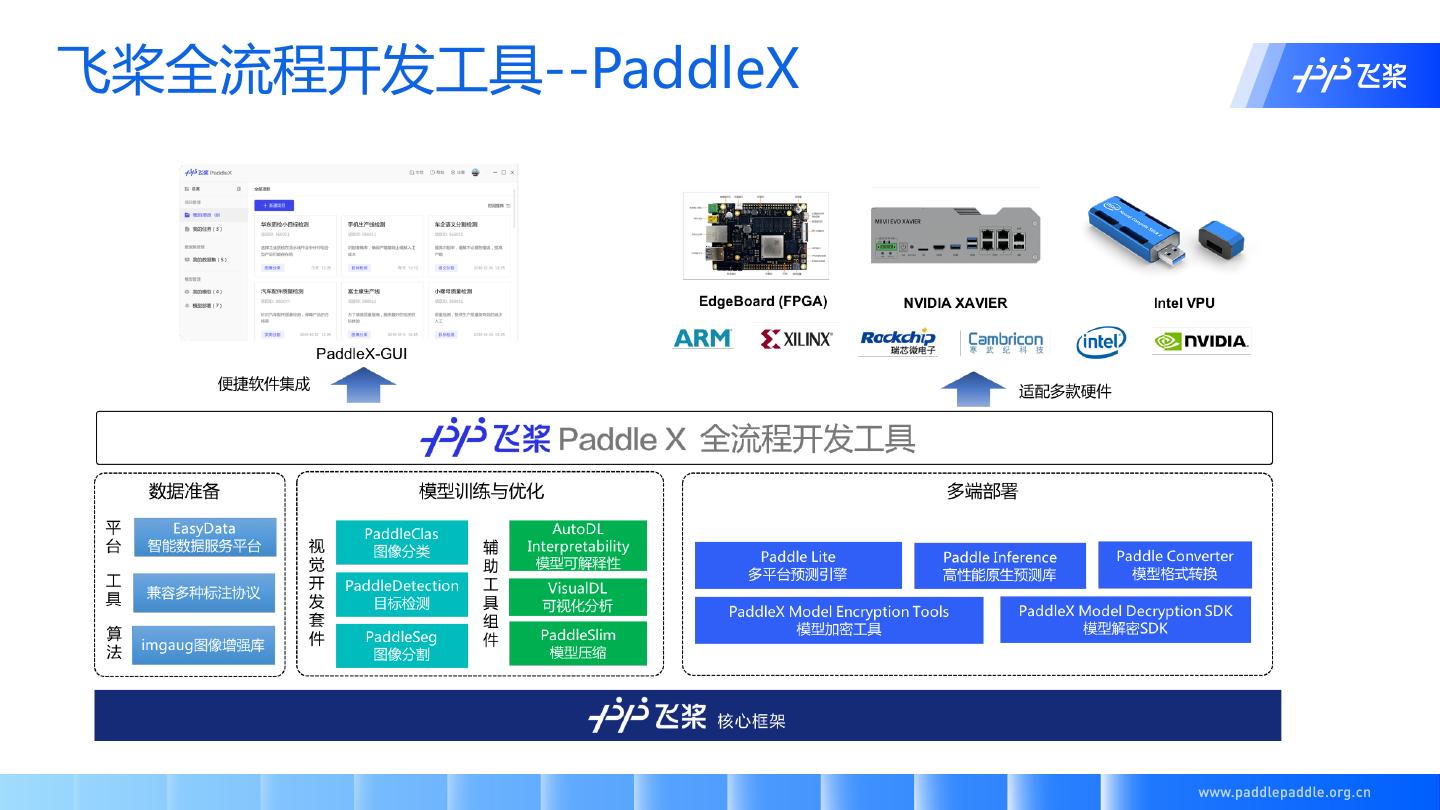
4 .深度学习工业视觉开发全流程
总共分4步
数据准备 模型训练 模型优化 推理部署
数据采集 PaddleClas PaddleSlim Paddle Lite
图像分类模型库 模型压缩工具库 轻量级推理框架
数据标注
PaddleDetection VisualDL Paddle Inference
飞桨提供全流程 目标检测模型库 可视化分析工具 推理引擎
深度学习算法开
发工具 PaddleSeg Paddle.js
图像分割模型库 Web深度学习框架
�
8 .自动工业质检场景介绍
u 价值
ü 通过计算机视觉技术,对工业产品的缺陷进行识别及分类,实现降本增效
u 应用场景
3C零部件缺陷检测 汽车零部件缺陷检测 电网设施缺陷检测
u 场景特点
ü 质检设备更偏边缘设备,大多只有CPU,且内存偏小
ü 传统工控机升级算力成本高昂
�
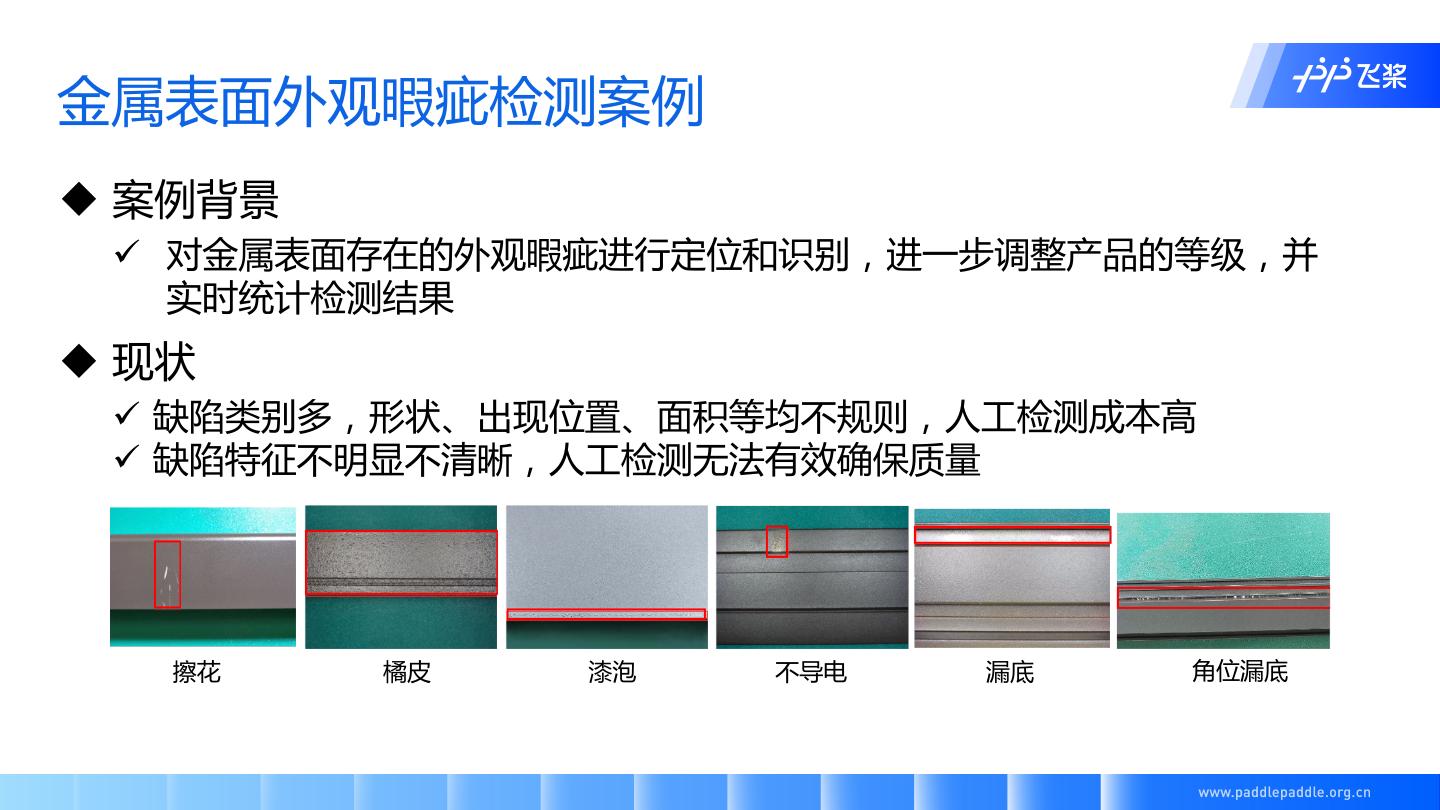
9 .金属表面外观暇疵检测案例
u 案例背景
ü 对金属表面存在的外观暇疵进行定位和识别,进一步调整产品的等级,并
实时统计检测结果
u 现状
ü 缺陷类别多,形状、出现位置、面积等均不规则,人工检测成本高
ü 缺陷特征不明显不清晰,人工检测无法有效确保质量
擦花 橘皮 漆泡 不导电 漏底 角位漏底
�
10 .外观质检方案—PaddleX+OpenVINO
u 模型训练
Ø 采用检测模型YOLOv3,骨干网络选择MobileNetv3-SSLD
Ø 加入背景图片对负样本进行优化
u 模型剪裁
Ø 对卷积通道数量进行剪裁
u 模型部署
Ø 使用OpenVINO在Intel CPU设备上部署模型
模型 VOC mAP (%) Inference Speed (ms/image)
ØYOLOv3-MobileNetv3_ssld
s 81.31 56.71
+ Model prune 78.60 34.50
检测精度78.60%,推理时间34.50ms,图像预处理38.69ms
( Intel(R) Core(TM) i9-9820X CPU @ 3.30GHz ,Windows)
�
11 .YOLOv3—飞桨高度优化
ü 骨干网络:可配置的骨干网络
ü 每个anchor预测单独的类别,即输出通道数由B*5+C增加为B*(5+C)
ü 3个尺度分别训练,提高召回率
ü 分类激活函数:用sigmoid代替softmax
BackBone 新增优化方法 COCO mAP FPS (V100)
YOLOv3(Paper) - 33.0 -
YOLOv3(优化后) 骨干网络、Sync BN 38.9 49.38
�
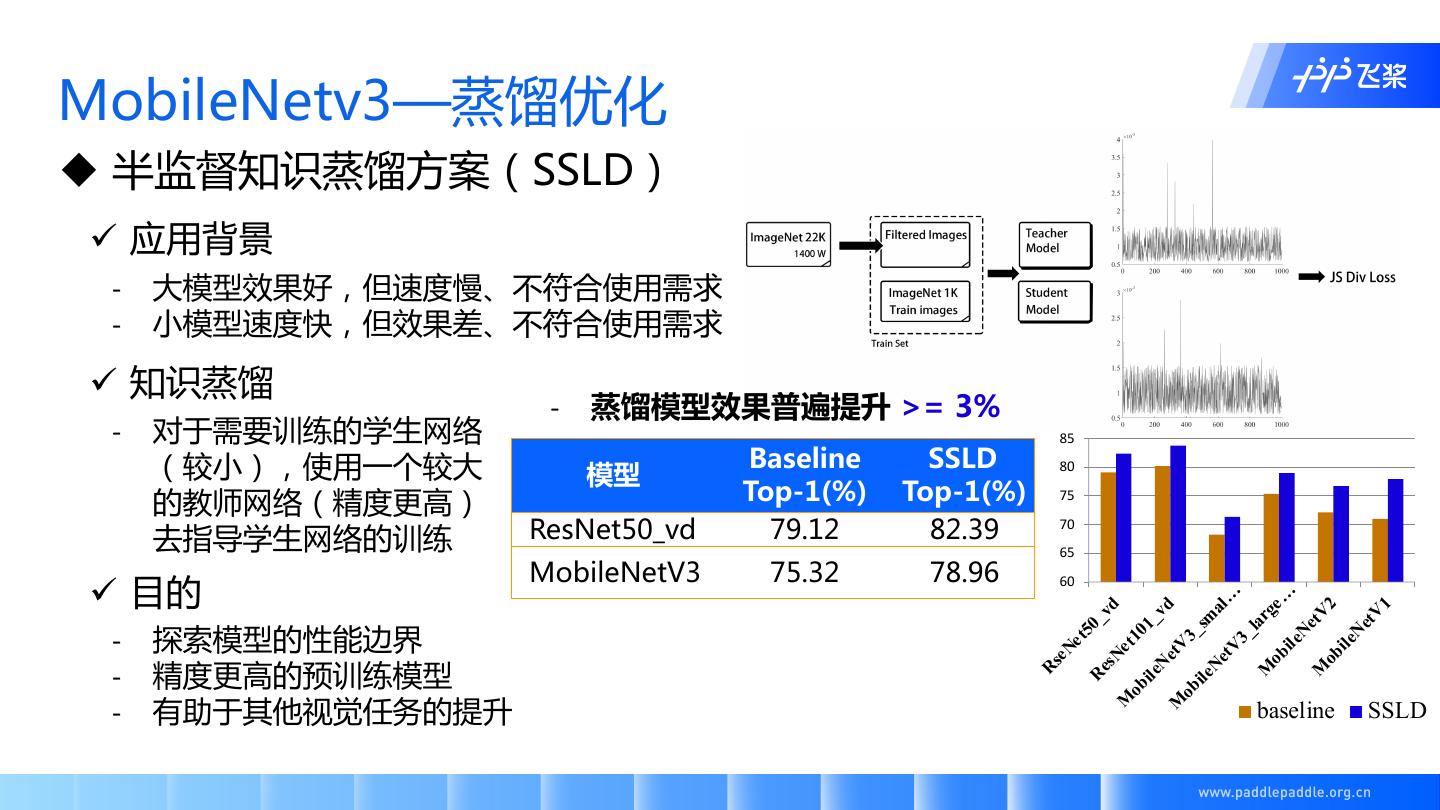
12 .MobileNetv3—蒸馏优化
u 半监督知识蒸馏方案(SSLD)
ü 应用背景
- 大模型效果好,但速度慢、不符合使用需求
- 小模型速度快,但效果差、不符合使用需求
ü 知识蒸馏
- 蒸馏模型效果普遍提升 >= 3%
- 对于需要训练的学生网络 85
(较小),使用一个较大 Baseline SSLD
模型 80
的教师网络(精度更高) Top-1(%) Top-1(%) 75
去指导学生网络的训练 ResNet50_vd 79.12 82.39 70
65
MobileNetV3 75.32 78.96
ü 目的
60
…
…
d
2
1
vd
al
e
rg
V
V
_v
sm
1_
探索模型的性能边界
et
et
la
-
50
3_
N
N
10
3_
t
il e
il e
Ne
V
t
V
Ne
et
ob
ob
et
精度更高的预训练模型
se
-
N
es
N
M
M
R
il e
il e
R
ob
ob
- 有助于其他视觉任务的提升
M
baseline SSLD
M
�
13 .模型剪裁—降本增效
u 卷积通道数剪裁
ü 应用背景
- 大模型效果好,但参数量多、
速度慢
ü 通道数剪裁
- 减少卷积层中卷积核的数
量,并相应减少其输出特 模型 压缩策略 GFLOPs 模型大小(MB) 精度(%)
征层的通道数量 baseline 20.64 95 29.3
YOLOv3-
ü 目的 MobileNetv3 剪裁 13.57(-34%) 67.60(-29%) 30.2(+0.9)
- 减少模型的存储大小 YOLOv3- baseline 44.71 176.82 39.1
- 降低模型的计算复杂度 ResNet50-vd-
dcn 剪裁 37.53(-16%) 149.49(-15%) 39.8(+0.7)
- 提升模型的性能
更多详情请参考PaddleX模型剪裁教程:https://paddlex.readthedocs.io/zh_CN/develop/slim/prune.html
�
14 .PaddleX 模型部署
u 支持多种推理引擎部署
ü Paddle Inference
ü OpenVINO
ü TensorRT
ü Paddle-Lite
ü Paddle.js
u 支持服务化部署
ü Paddle Serving
ü Triton
由于工业质检场景的工控机往往是CPU机器,对模型推理的性能要求较高。所以我们在外观质检
方案中选择了性能卓越的OpenVINO作为推理引擎进行部署。
�
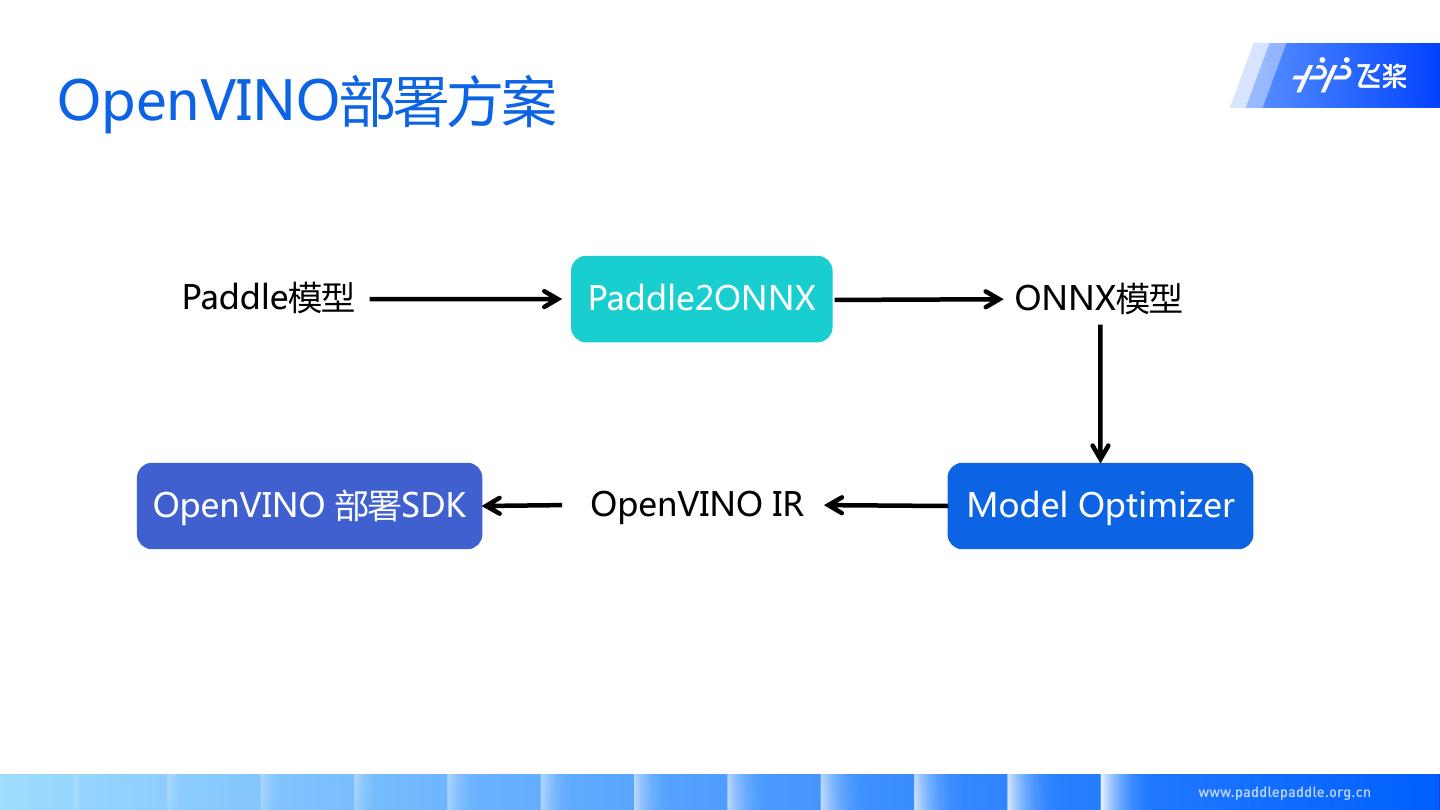
15 .OpenVINO部署方案
Paddle模型 Paddle2ONNX ONNX模型
OpenVINO 部署SDK OpenVINO IR Model Optimizer
�
16 .PaddleX+OpenVINO部署
u模型导出
Ø PaddleX内置脚本,一行指令或代码直接导出
u模型转换
Ø PaddleX内置提供脚本,一行指令将Paddle模型直接转为OpenVINO可加载的模型
u模型部署
Ø 打通多个硬件环境,内置集成OpenVINO。可直接运行推理,无需额外代码调用OpenVINO
�
17 .基于OpenVINO模型部署
PaddleX在不同环境下对OpenVINO的支持情况:
PaddleX里OpenVINO部署教程:https://paddlex.readthedocs.io/zh_CN/develop/deploy/openvino/index.html
�
18 .最终效果—部署性能满足落地需求
推理时间 推理时间
VOC mAP
模型 不含预处理 含预处理
(%)
(ms/image) (ms/image)
YOLOv3-MobileNetv3_ssld 81.31 56.71 95.4
+ Model prune 78.60 34.50 73.19
- 型号:Intel(R) Core(TM) i9-9820X@3.30GHz, Windows
�
20 .PaddleX 重磅升级
u全面支持飞桨2.0动态图,更易用的开发模式
u目标检测任务新增PP-YOLOv2, COCO test数据集精度达到49.5%、V100预测速
度达到68.9 FPS
u目标检测任务新增4.2MB的超轻量级模型PP-YOLO tiny
u语义分割任务新增实时分割模型BiSeNetV2
u训练新增在线量化功能
uC++部署模块全面升级
u PaddleInference部署适配2.0预测库
u 优化预处理模块,推理速度提升70%+
u 支持飞桨PaddleDetection、PaddleSeg、PaddleClas以及PaddleX的模型部署
u 新增基于PaddleInference的GPU多卡预测
u GPU部署新增基于ONNX的TensorRT高性能加速引擎部署方式
u GPU部署新增基于ONNX的Triton服务化部署方式
�
21 .PaddleX 传送门
• GitHub获取PaddleX开源代码
• https://github.com/PaddlePaddle/PaddleX
• 官网下载PaddleX可视化客户端,零代码开发深度学习模型
• https://www.paddlepaddle.org.cn/paddle/paddleX
• AI Studio《10分钟快速上手使用PaddleX》系列案例
• https://aistudio.baidu.com/aistudio/projectdetail/450925
• PaddleX使用文档,关于PaddleX, 你想要了解的都在里面
• https://paddlex.readthedocs.io
• 与PaddleX工程师交流,加入QQ交流群
• QQ群号 1045148026
�
22 .感谢观看!
扫码加入PaddleX交
流群!
�