






















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
OpenVINO Intro
介绍英特尔OpenVINO开发工具套件的基本框架,以及模型推理部署和模型量化功能。
展开查看详情
1 .英特尔®分发版 OpenVINO™工具包产品介绍
2 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 议程 • 介绍英特尔®分发版 OpenVINO™工具包 – 当前深度学习应用开发与落地部署挑战 – 英特尔®分发版 OpenVINO™产品所包含组件 • 基于OpenVINO™的推理引擎开发人工智能应用 – 推理引擎API – 模型量化与加速 2
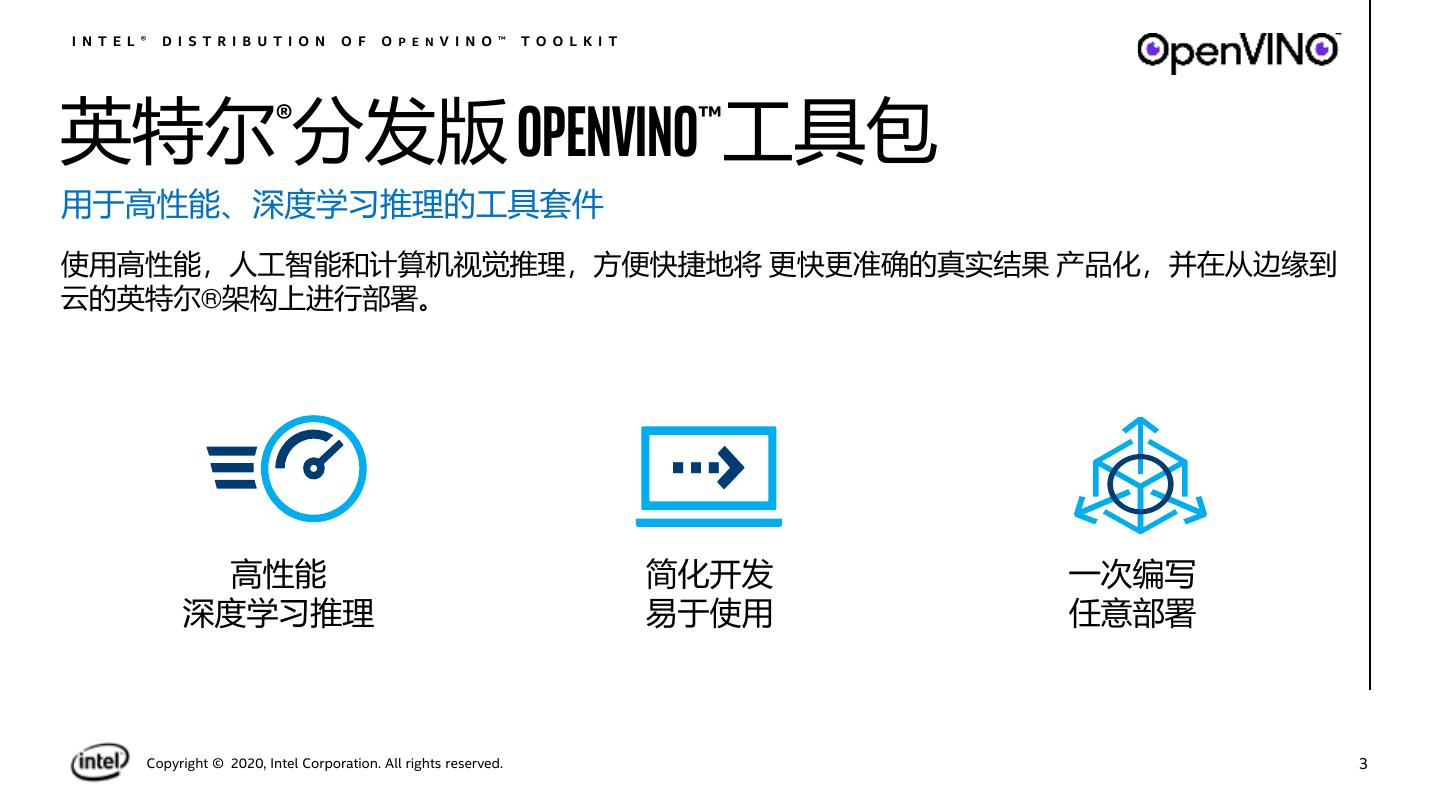
3 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 英特尔®分发版 OPENVINO™工具包 用于高性能、深度学习推理的工具套件 使用高性能,人工智能和计算机视觉推理,方便快捷地将 更快更准确的真实结果 产品化,并在从边缘到 云的英特尔®架构上进行部署。 高性能 简化开发 一次编写 深度学习推理 易于使用 任意部署 Copyright © 2020, Intel Corporation. All rights reserved. 3
4 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 英特尔®分发版 OPENVINO™工具包工作流 训练一个模型 运行模型优化器 中间表示 使用推理引擎部署 (Model Optimizer) (Intermediate Representation) (Inference Engine) 找一个训练好的模型 Intel® .bin, .xml GNA (IP) Copyright © 2020, Intel Corporation. All rights reserved. 4
5 . I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 使用英特尔®分发版 OPENVINO™工具包 简化深度学习部署 1. 构建 2. 优化 3. 部署 预训练模型 Read, Load, Infer CPU Plugin Model Optimizer 优化并转换使用支持的框架预训练 GPU Plugin 的模型 Intermediate IR Data Representation GNA Plugin (.xml, .bin) Inference Engine Myriad Plugin For Intel® NCS2 & 为不同的底层硬件提供统 NCS 一的编程接口 HDDL Plugin Post-Training Deep Learning Streamer Open Model Zoo Optimization Tool FGPA Plugin 100+ 开源优化的预训练模型 OpenCV OpenCL™ 80+ 公共模型 Deep Learning Deployment Manager Workbench Code Samples & Demos (e.g. Benchmark app, Accuracy Checker, Model Downloader) Copyright © 2020, Intel Corporation. All rights reserved. 5
6 . I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 模型优化器 (Model Optimizer) ▪ 基于Python开发的脚本,用于导入训练好 的模型并将其转换为中间表示 ▪ 通过模型拓扑转换优化性能及存储空间 ▪ 硬件无关的优化 FROM OPTIMIZATION TO Development Guide https://docs.openvinotoolkit.org/latest/_docs_MO_DG_Deep_Learning _Model_Optimizer_DevGuide.html 推理引擎 (Inference Engine) DEPLOYMENT ▪ 提供C/C++ 和 Python的推理运行时API ▪ 为不同的硬件提供统一接口,每个硬件类型以 动态加载插件的方式实现接口 ▪ 为不同硬件类型提供最佳性能,无需用户实现 和维护多个代码路径 Development Guide Optimization Notice Copyright © 2020, Intel Corporation. All rights reserved. https://docs.openvinotoolkit.org/latest/_docs_IE_DG_Deep_Learning_Infere 6 *Other names and brands may be claimed as the property of others. nce_Engine_DevGuide.html
7 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 英特尔®分发版 OPENVINO™工具包 通过插件式模块架构支持多个硬件平台 Applications Inference Engine runtime Inference Engine (Common API) Multi-device plugin (optional but recommended - for full system utilization) Myriad & mkl-dnn plugin clDNN plugin GNA plugin FPGA plugin HDDL plugins Plugin architecture Intrinsics OpenCL™ GNA API Movidius API DLA Intel® GNA (IP) Copyright © 2020, Intel Corporation. All rights reserved. 7
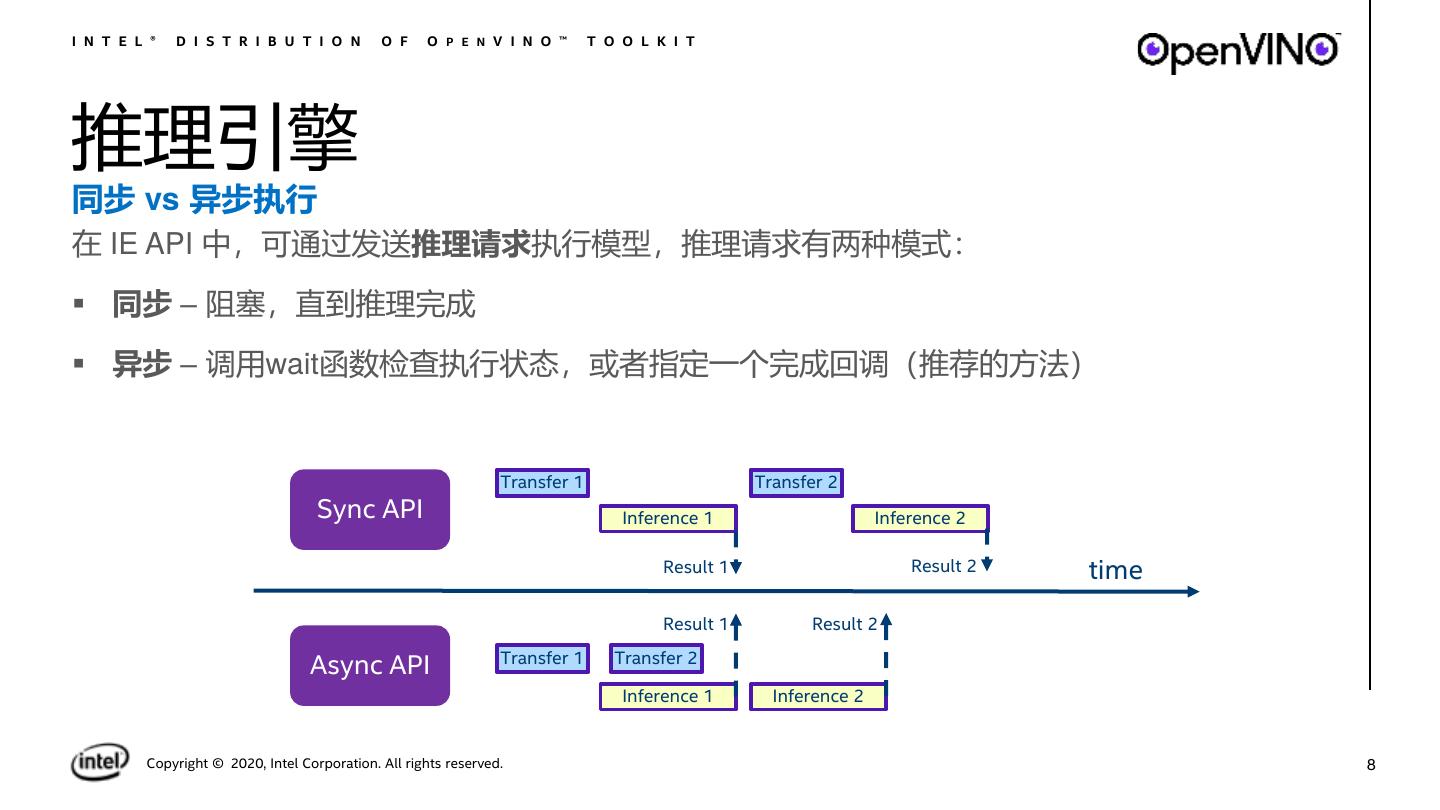
8 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 推理引擎 同步 vs 异步执行 在 IE API 中,可通过发送推理请求执行模型,推理请求有两种模式: ▪ 同步 – 阻塞,直到推理完成 ▪ 异步 – 调用wait函数检查执行状态,或者指定一个完成回调(推荐的方法) Transfer 1 Transfer 2 Sync API Inference 1 Inference 2 Result 1 Result 2 time Result 1 Result 2 Transfer 1 Transfer 2 Async API Inference 1 Inference 2 Copyright © 2020, Intel Corporation. All rights reserved. 8
9 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 推理引擎 CPU, iGPU和VPU的吞吐量模式 核心和设备资源被划分为执行“流” - 并行运行推断请求 Device resources 的部分 Infer Request 1 Execution stream 1 Infer Request 2 Execution stream 2 低延迟模式 – 允许推理引擎把所有执行流都用于少量推 Infer Request N Execution stream N 理请求,从而在尽量短的时间内完成推理请求 time 吞吐量模式 - 允许推理引擎有效地同时运行多个推断请 求,从而极大地提高推断的帧总数(FPS) Copyright © 2020, Intel Corporation. All rights reserved. 9
10 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 一次编写, 任意部署 异构支持 你可以在不同的硬件单元上执行不同的层 ▪ 将不支持的层卸载到备用设备: ▪ 默认的 affinity policy ▪ 手动设置 affinity (CNNLayer::affinity) ▪ 支持所有设备组合 (CPU, GPU, FPGA, MYRIAD, HDDL) ▪ Samples/demos 用法 “-d HETERO:FPGA,CPU” FPGA InferenceEngine::Core core; auto executable_network = core.LoadNetwork(reader.getNetwork(), "HETERO:FPGA,CPU"); CPU Copyright © 2020, Intel Corporation. All rights reserved. 10
11 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 一次编写, 任意部署 Multi-device 支持 Application 设备之间的自动负载平衡(推理请求级别), Device priority Infer requests 以实现完全的系统利用率 Inference Queue Manager ▪ 支持括号中设备的任意组合( CPU, iGPU, VPU, Engine CPU GPU VPU HDDL ) queue queue queue ▪ 使用简单,在示例或演示的命令行参数中使用 “-d MULTI:CPU,GPU” 即可 ▪ C++ example (Python类似) CPU GPU VPU Plugin Plugin Plugin Core ie; CPU GPU VPU etc ExecutableNetwork exec = ie.LoadNetwork(network,{{“DEVICE_PRIORITIES”, “CPU,GPU”}}, “MULTI”) Copyright © 2020, Intel Corporation. All rights reserved. 11
12 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 训练后优化工具(POT) ▪ 训练后优化工具(POT)集成了模型优化器、深度学 习工作台和精度检查工具,从而简化开发过程 预训练模型 使用支持的框 架预训练的模 数据集和标注 ▪ 使用深度学习模型转换技术,在无需重新训练的情 型 况下,将模型转换为低精度数据类型(如INT8), 从而减小模型大小 Statistics ▪ 减少模型大小的同时改善了延迟,模型精度损失很 精度和性能检查 & JSON 小,且无需重新训练模型。 Model Optimizer IR Post-training Accuracy 使用支持的框架转 Optimization Tool Checker 换并优化预训练模 全精度 IR 低精度量化模型以获取高性能 环境(硬件)规格 ▪ 支持不同的优化方法:量化算法,稀疏等。 型 的转换技术 JSON Performance Benchmarks IR https://docs.openvinotoolkit.org/latest/_docs_performance_int8_vs _fp32.html 优化后的 IR Inference Engine Copyright © 2020, Intel Corporation. All rights reserved. For public use – OK for non-NDA disclosure 12
13 . SUPPORTED HARDWARE I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 推理部分引入对 BFLOAT16 的支持 CPU ▪ 在精确度接近全精度(例如,FP32数据类型)的同时提高 igpu 性能 BF16的指数位数与FP32相同,但总长度为16位,这 意味着使用半精度计算(提高性能),同时精确度接 vp ▪ 在第三代英特尔®至强®可扩展处理器(以前代号为 近全精度 u Cooper Lake)上,引入对 Bfloat16 数据类型(BF16)的 fpga 支持,用于推理(特别是在云或数据中心用例中) gna ▪ 与FP32推理相比,BF16推理的理论峰值性能为其2倍,且 内存消耗减少了2倍 16 bits 16 bits SUPPORTED OS FP32 s 8 bit exp 23 bit mantissa ▪ 支持的层: 7 bit BF16 s 8 bit exp mantissa ▪ Convolution, Deconvolution, FullyConnected, Data movements FP16 s 5 bit 10 bit mantissa exp WIN 10 WIN Development Guide 性能 SERVE https://docs.openvinotoolkit.org/latest/openvino_docs_IE_DG_Bfloat16Inference.html 精确度 R LINUX MAC Copyright © 2020, Intel Corporation. All rights reserved.
14 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 加速测试周期和开发的工具 ▪ 方便地下载一些公共模型及英特尔预 ▪ 为部署生成一个最佳的、最小化的运 训练模型 行时包 Model Deployment Downloader Manager ▪ 与开发包相比,部署占用的空间更小 ▪ 度量模型的性能(吞吐量、延迟) ▪ 使用已知数据集检查IR模型(原始和 ▪ 获得每层和整体基础的性能指标 Accuracy 转换后)的准确性 Benchmark App Checker Get Started https://docs.openvinotoolkit.org/latest/_docs_IE_DG_Tools_Overview.html –or- by using the Deep Learning Workbench Copyright © 2020, Intel Corporation. All rights reserved. 14
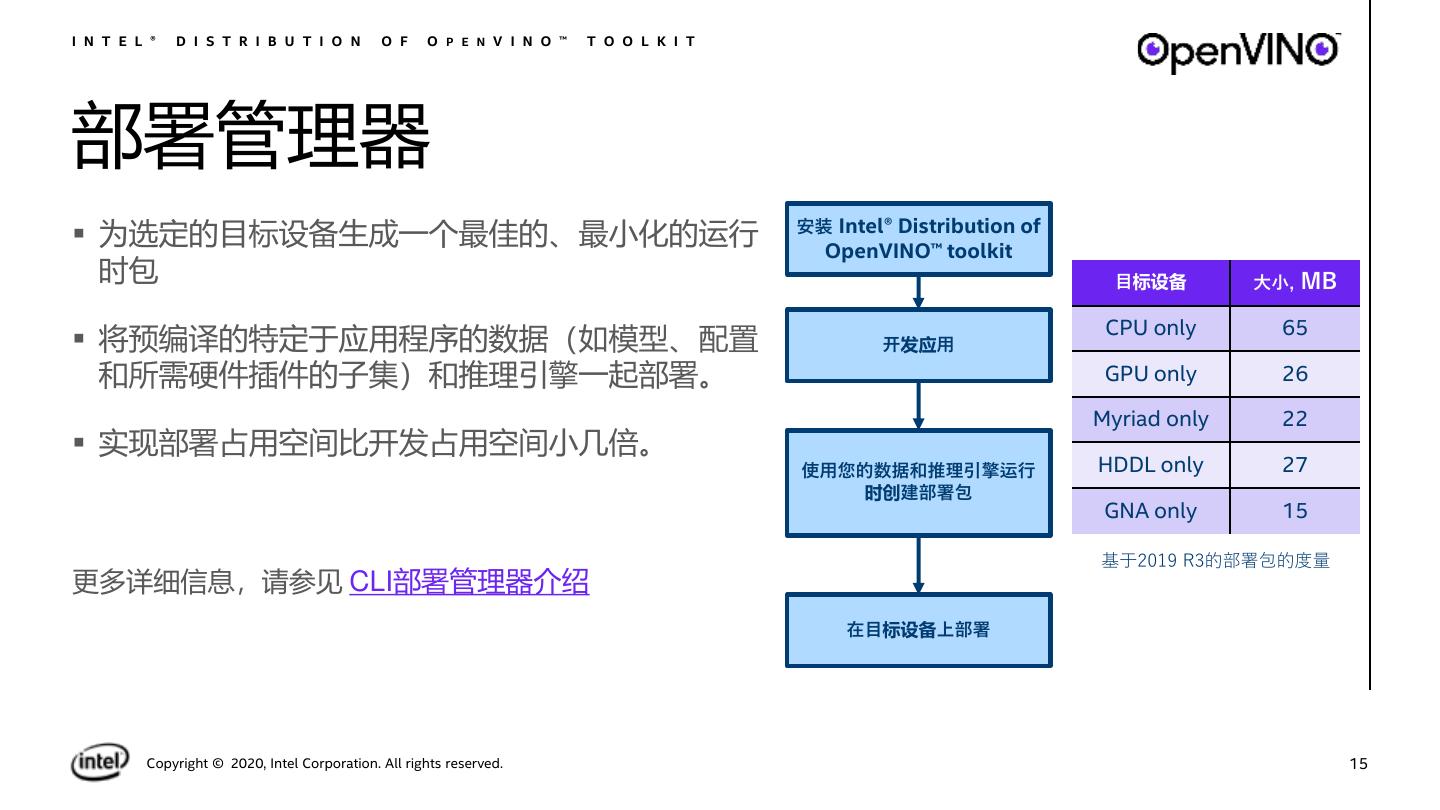
15 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 部署管理器 安装 Intel® Distribution of ▪ 为选定的目标设备生成一个最佳的、最小化的运行 OpenVINO™ toolkit 时包 目标设备 大小, MB CPU only 65 ▪ 将预编译的特定于应用程序的数据(如模型、配置 开发应用 和所需硬件插件的子集)和推理引擎一起部署。 GPU only 26 Myriad only 22 ▪ 实现部署占用空间比开发占用空间小几倍。 使用您的数据和推理引擎运行 HDDL only 27 时创建部署包 GNA only 15 基于2019 R3的部署包的度量 更多详细信息,请参见 CLI部署管理器介绍 在目标设备上部署 Copyright © 2020, Intel Corporation. All rights reserved. 15
16 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T DL WORKBENCH ▪ 英特尔® 分发版 OpenVINO™ 工具包中的,基于web的UI扩 展工具 ▪ 可视化拓扑和层的性能数据,以帮助进行模型分析 ▪ 自动分析最佳性能配置 (streams, batches, latency) ▪ 使用int8或Winograd校准进行实验,以获得最佳调优 ▪ 通过accuracy checker工具提供精确度信息 ▪ 可以直接访问 Open Model Zoo 中的模型 ▪ 实现远程分析,允许从多台不同的机器收集性能数据,而无 需任何其他设置。 Development Guide https://docs.openvinotoolkit.org/latest/_docs_Workbench_DG_Introduction.html Copyright © 2020, Intel Corporation. All rights reserved. For public use – OK for non-NDA disclosure 16
17 . I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 使用开源资源加速开发 开源的预训练模型、实例和演示 音频、语音、语言 其他 计算机视觉 (数据生成,强化学习) Object detection 3D reconstruction Language processing Object recognition Human pose estimation Speech to text Compressed models Reidentification Image processing Text detection Image retrieval Volumetric segmentation Action recognition Text recognition Natural Language Processing 更多模型….. Semantic segmentation Image super resolution Pre-trained models Instance segmentation https://github.com/opencv/open_model_zoo Copyright © 2020, Intel Corporation. All rights reserved. For public use – OK for non-NDA disclosure 17
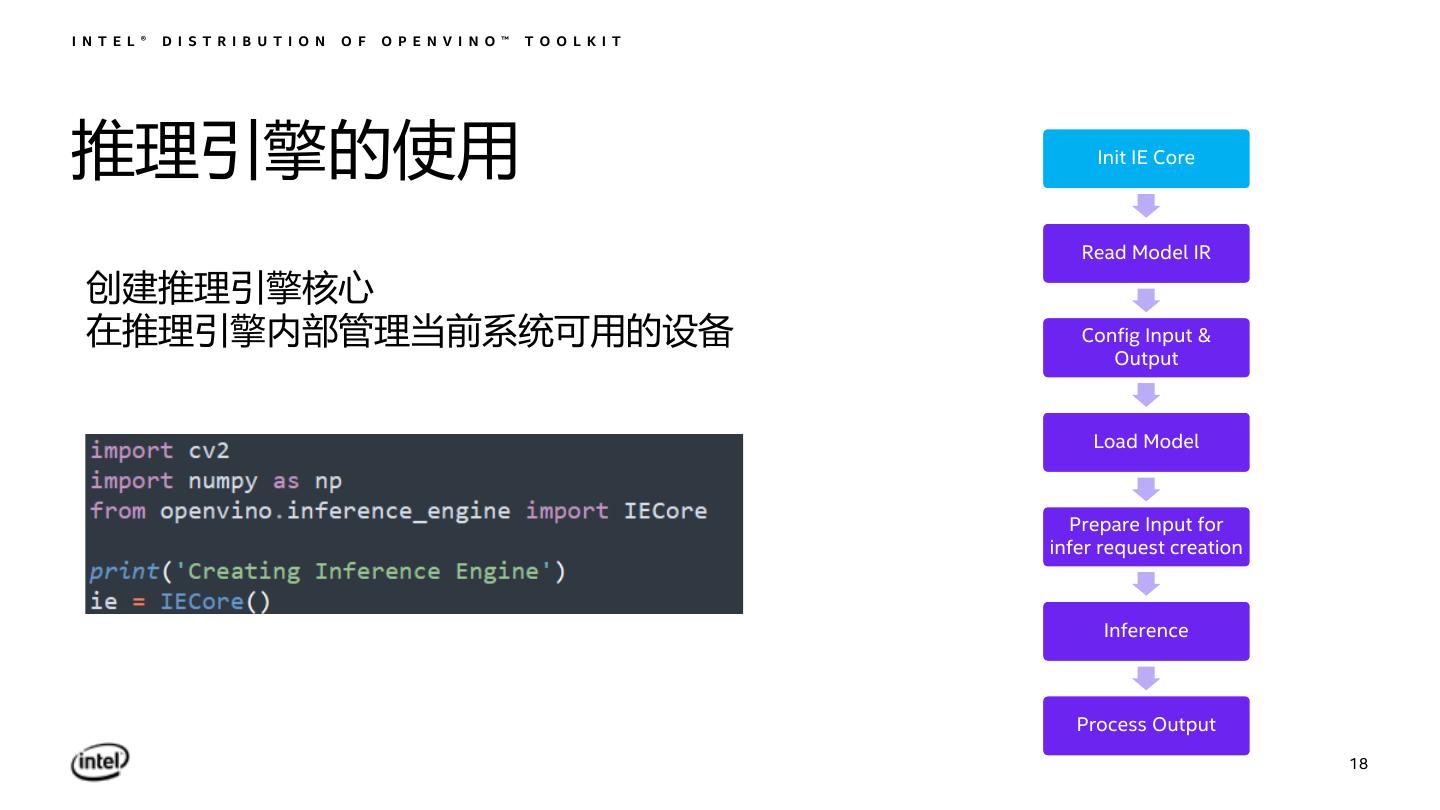
18 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 推理引擎的使用 Init IE Core Read Model IR 创建推理引擎核心 在推理引擎内部管理当前系统可用的设备 Config Input & Output Load Model Prepare Input for infer request creation Inference Process Output 18
19 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 推理引擎的使用 Init IE Core Read Model IR 从本地磁盘中读取一个IR模型 Config Input & Output Load Model Prepare Input for infer request creation Inference Process Output 19
20 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 推理引擎的使用 Init IE Core 从初始化好的神经网络对象net中得到输入 Read Model IR 层的名称,并且设置输出层的精度。 Config Input & Output Load Model Prepare Input for infer request creation Inference Process Output 20
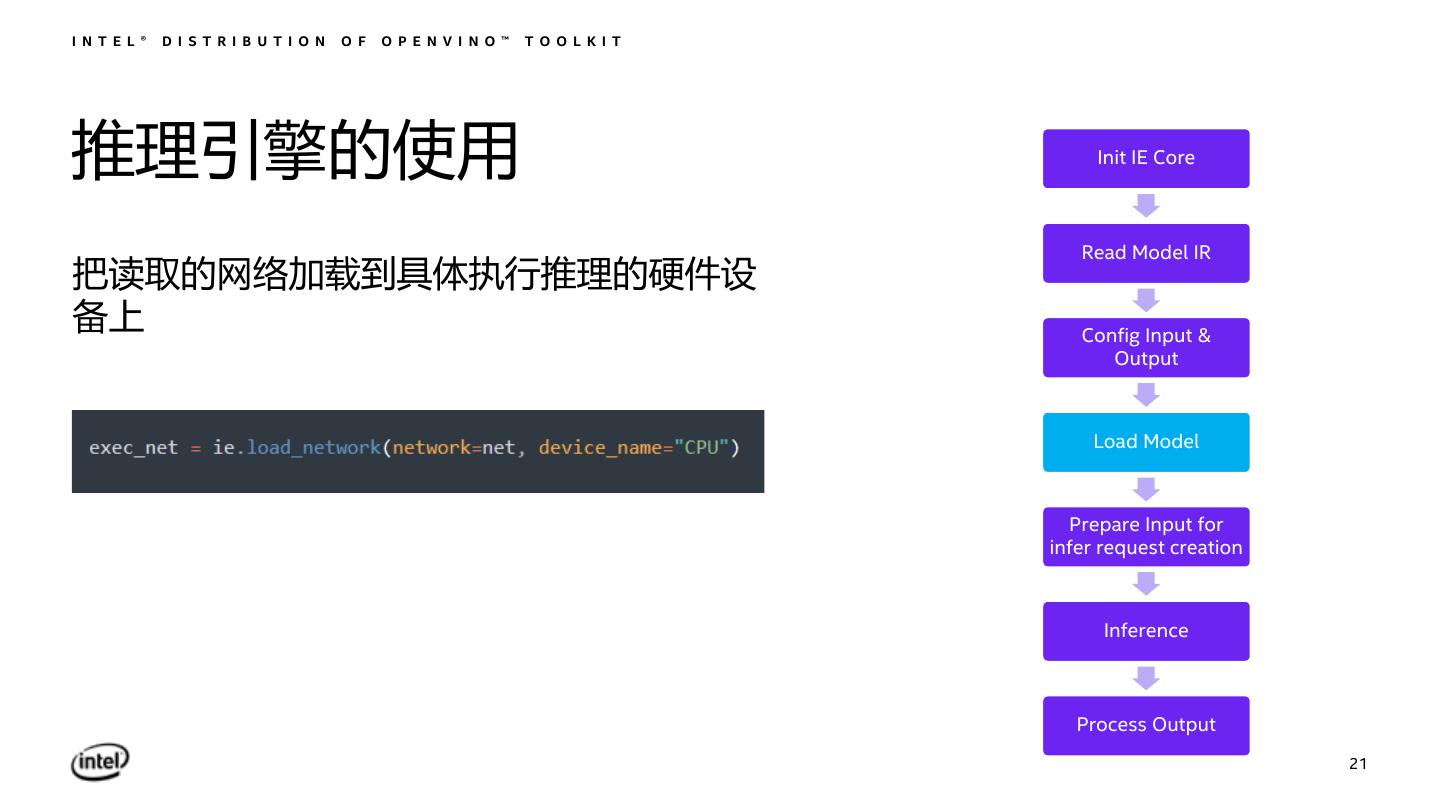
21 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 推理引擎的使用 Init IE Core Read Model IR 把读取的网络加载到具体执行推理的硬件设 备上 Config Input & Output Load Model Prepare Input for infer request creation Inference Process Output 21
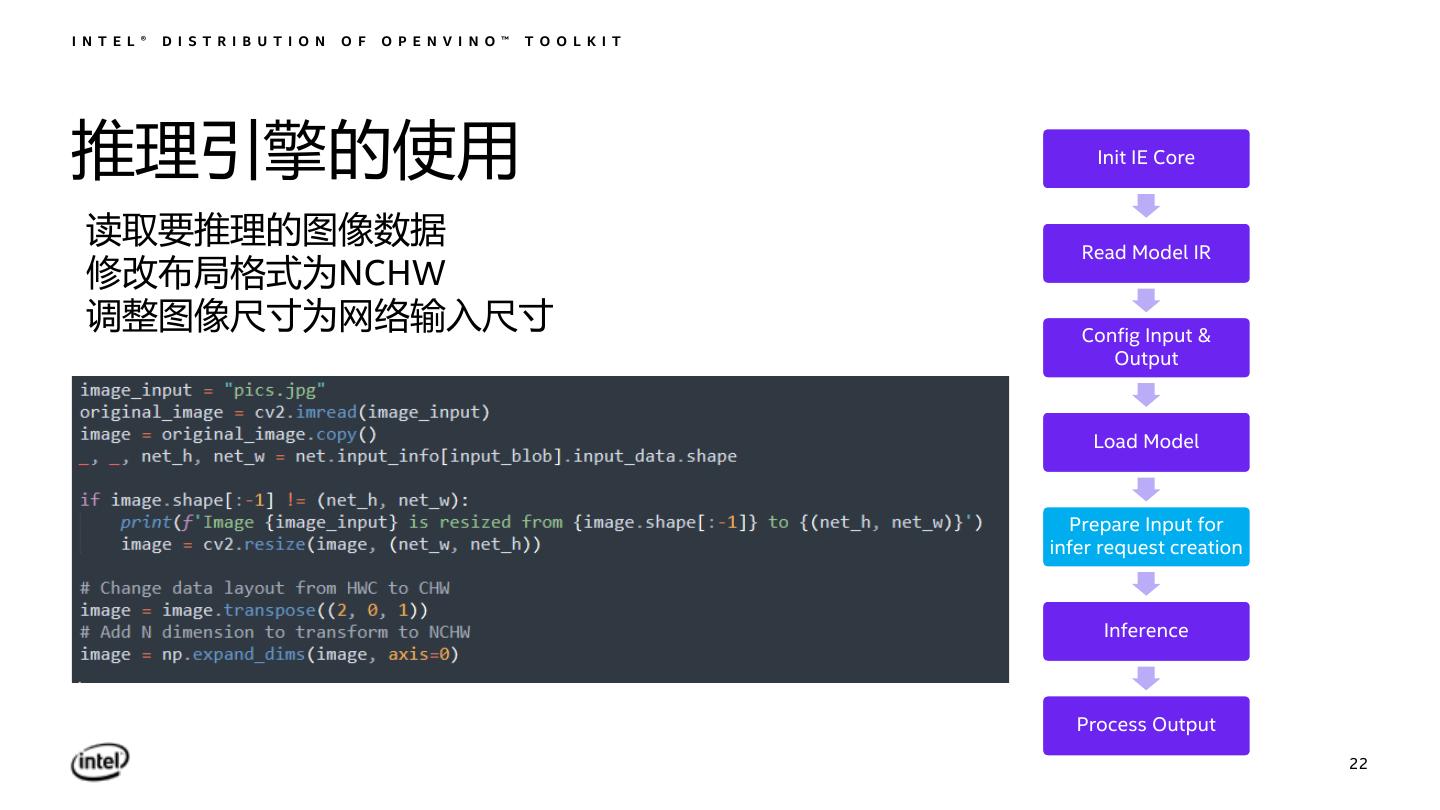
22 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 推理引擎的使用 Init IE Core 读取要推理的图像数据 Read Model IR 修改布局格式为NCHW 调整图像尺寸为网络输入尺寸 Config Input & Output Load Model Prepare Input for infer request creation Inference Process Output 22
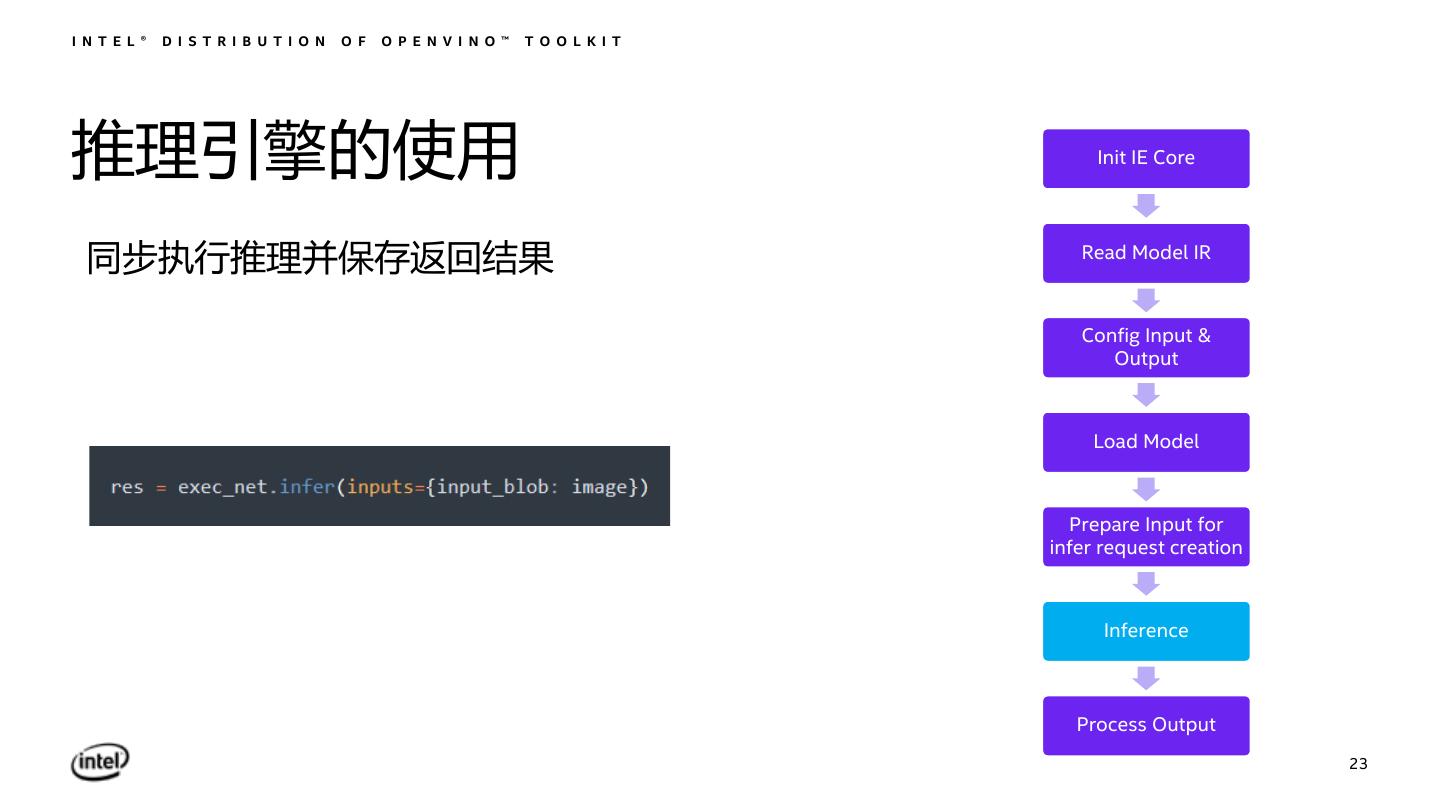
23 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 推理引擎的使用 Init IE Core 同步执行推理并保存返回结果 Read Model IR Config Input & Output Load Model Prepare Input for infer request creation Inference Process Output 23
24 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 推理引擎的使用 Init IE Core 对推理结果进行解析 Read Model IR Config Input & Output Load Model Prepare Input for infer request creation Inference Process Output 24
25 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T YOLOV3模型量化 1. Install and Set Up Post-Training Optimization Tool sudo <INSTALL_DIR>/deployment_tools/model_optimizer/install_prerequisites/install_prerequisites.sh python3 <INSTALL_DIR>/deployment_tools/open_model_zoo/tools/accuracy_checker/setup.py install python3 <INSTALL_DIR>/deployment_tools/tools/post_training_optimization_toolkit/setup.py install 2. Use Post-Training Optimization Command-Line Tool pot -c <path_to_config_file> https://docs.openvinotoolkit.org/latest/pot_README.html 25
26 .I N T E L ® D I S T R I B U T I O N O F O P E N V I N O ™ T O O L K I T 量化前后的YOLOV3网络性能比较 Test Code: /openvino/deployment_tools/open_m odel_zoo/demos/object_detection_de mo_yolov3_async Original Pre-trained Model: Darknet YOLOv3 Target: Intel(R) Xeon(R) Platinum 9242 CPU @ 2.30GHz Dataset: 100 images from MSCOCO 2017 26
27 .
3秒后跳转登录页面
去登陆

