展开查看详情
1 .Intel BigDL-Nano在智能制造应用案例
�
2 .目录
▪ 智能制造企业挑战
▪ 基于Intel Xeon平台的端边云架构智能工厂应用案例
▪ 端边云架构对应的软件栈
▪ Intel BigDL-Nano在端边云架构实践
▪ AutoML参数选择
▪ 加速模型训练
▪ 加速模型推理
▪ 总结
�
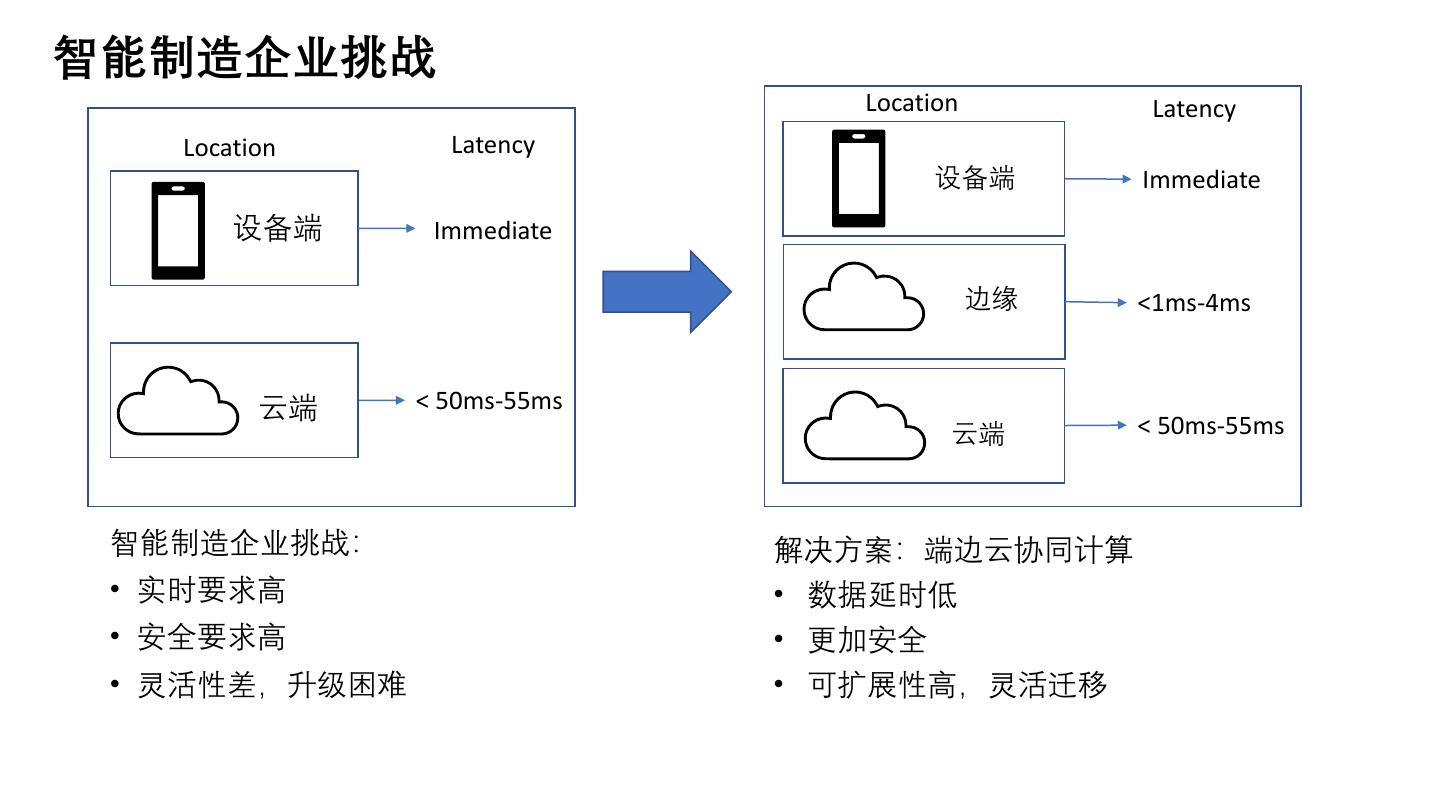
3 .智能制造企业挑战
Location Latency
Location Latency
设备端 Immediate
设备端 Immediate
边缘 <1ms-4ms
云端 < 50ms-55ms
云端 < 50ms-55ms
智能制造企业挑战: 解决方案:端边云协同计算
• 实时要求高 • 数据延时低
• 安全要求高 • 更加安全
• 灵活性差,升级困难 • 可扩展性高,灵活迁移
�
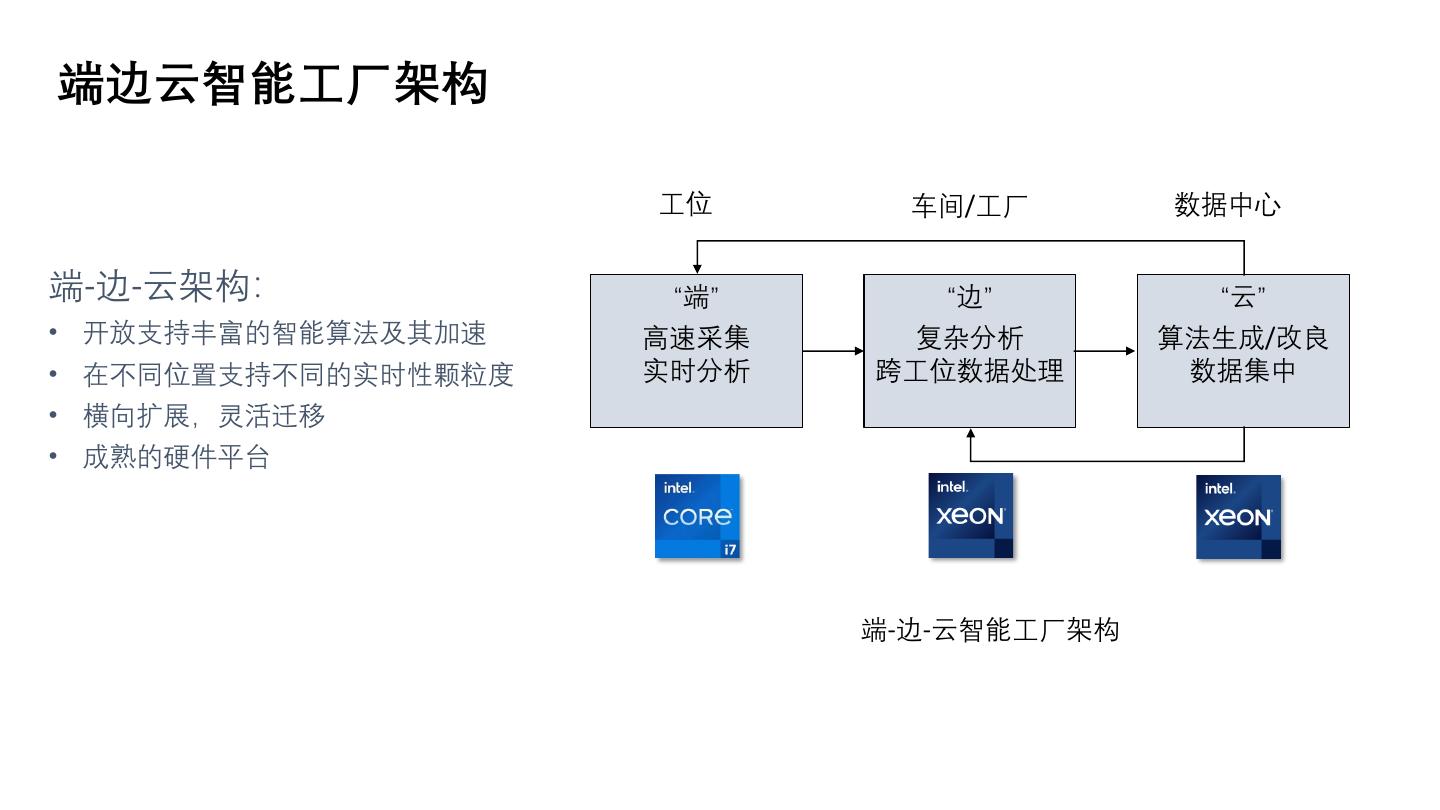
4 .端边云智能工厂架构
工位 车间/工厂 数据中心
端-边-云架构: “端” “边” “云”
• 开放支持丰富的智能算法及其加速 高速采集 复杂分析 算法生成/改良
• 在不同位置支持不同的实时性颗粒度 实时分析 跨工位数据处理 数据集中
• 横向扩展,灵活迁移
• 成熟的硬件平台
端-边-云智能工厂架构
�
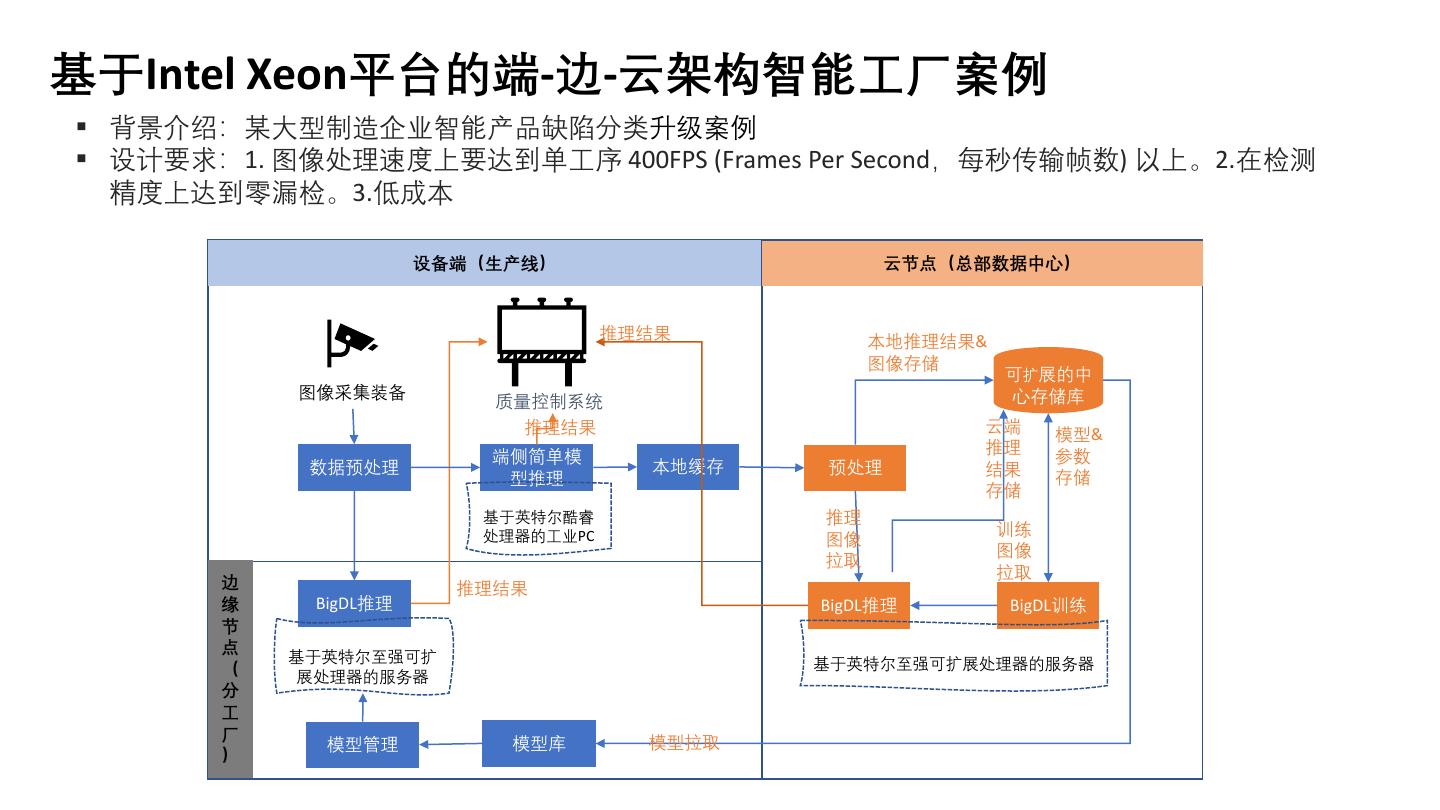
5 .基于Intel Xeon平台的端-边-云架构智能工厂案例
▪ 背景介绍:某大型制造企业智能产品缺陷分类升级案例
▪ 设计要求:1. 图像处理速度上要达到单工序 400FPS (Frames Per Second,每秒传输帧数) 以上。2.在检测
精度上达到零漏检。3.低成本
设备端(生产线) 云节点(总部数据中心)
推理结果 本地推理结果&
图像存储
可扩展的中
图像采集装备 心存储库
质量控制系统
推理结果 云端 模型&
推理 参数
端侧简单模
数据预处理 本地缓存 预处理 结果
型推理 存储
存储
基于英特尔酷睿 推理
处理器的工业PC 训练
图像
图像
拉取
拉取
边 推理结果
缘 BigDL推理 BigDL推理 BigDL训练
节
点 基于英特尔至强可扩
( 基于英特尔至强可扩展处理器的服务器
展处理器的服务器
分
工
厂 模型拉取
模型管理 模型库
)
�
6 .参考设计软件栈
推理@端 模型训练和推理@边缘&云 远程控制管理
Edge Insights Platform Model Zoo 应用服务 可视化界面
图像分析 支持的模型 标注服务 边缘管理服务
目标分类 数据存储服务 MySQL
Visualizer 应用的部署
OpenVINO 物体检测 数据的标注 CVAT
InfluxDB 实例分割 应用
训练服务
预训练模型 训练应用
ML Framework
数据的注入 迁移学习
Keras Tensorflow 标注应用
Injection
OpenCV 推理服务
Engine
BigDL Pytorch 远程控制推理任务 Dashboard
Trigger Driver GigE Driver
UI
Spark
基础设施 Container / Kubernetes
硬件
视觉控制器 AI边缘服务器 云
�
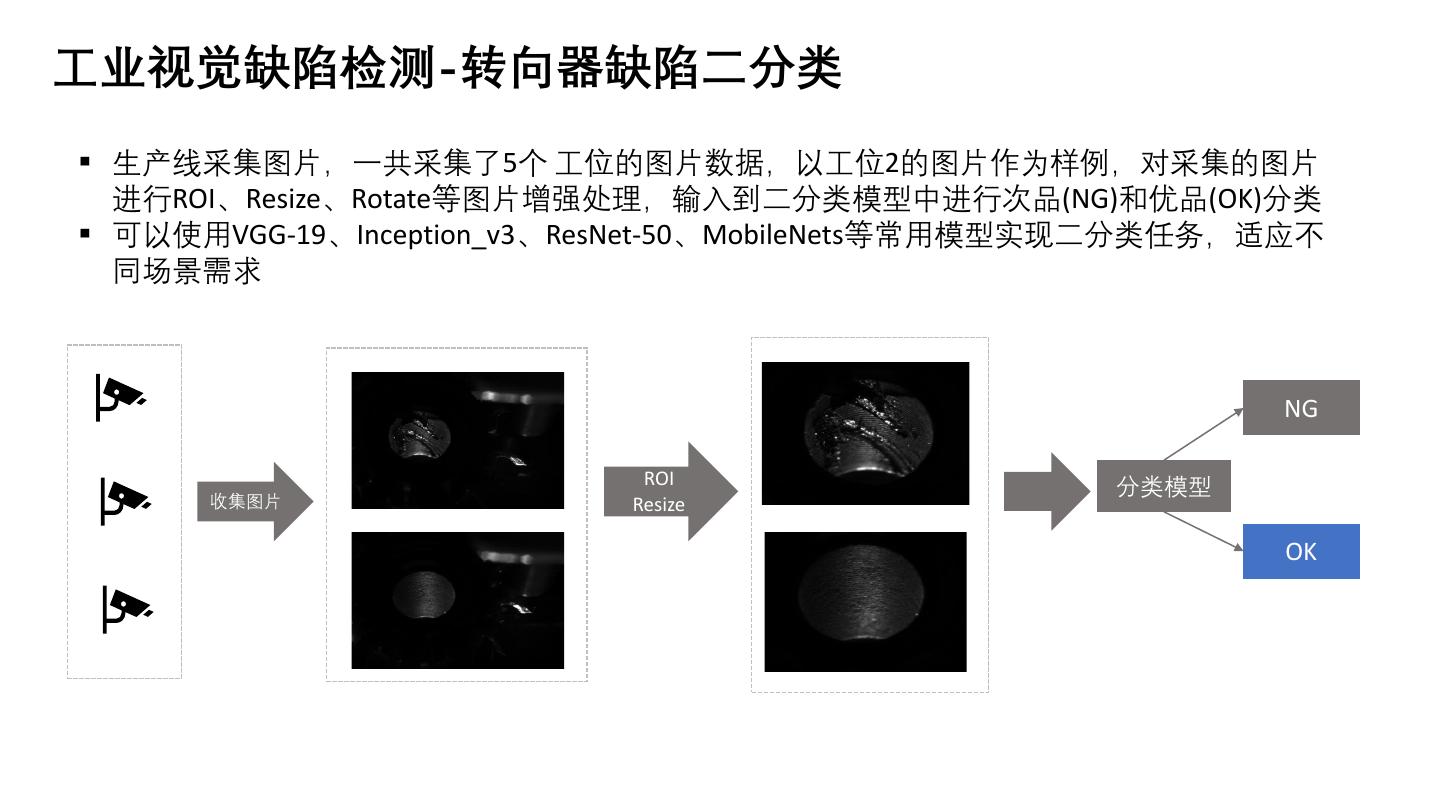
7 .工业视觉缺陷检测-转向器缺陷二分类
▪ 生产线采集图片,一共采集了5个 工位的图片数据,以工位2的图片作为样例,对采集的图片
进行ROI、Resize、Rotate等图片增强处理,输入到二分类模型中进行次品(NG)和优品(OK)分类
▪ 可以使用VGG-19、Inception_v3、ResNet-50、MobileNets等常用模型实现二分类任务,适应不
同场景需求
NG
ROI 分类模型
收集图片 Resize
OK
�
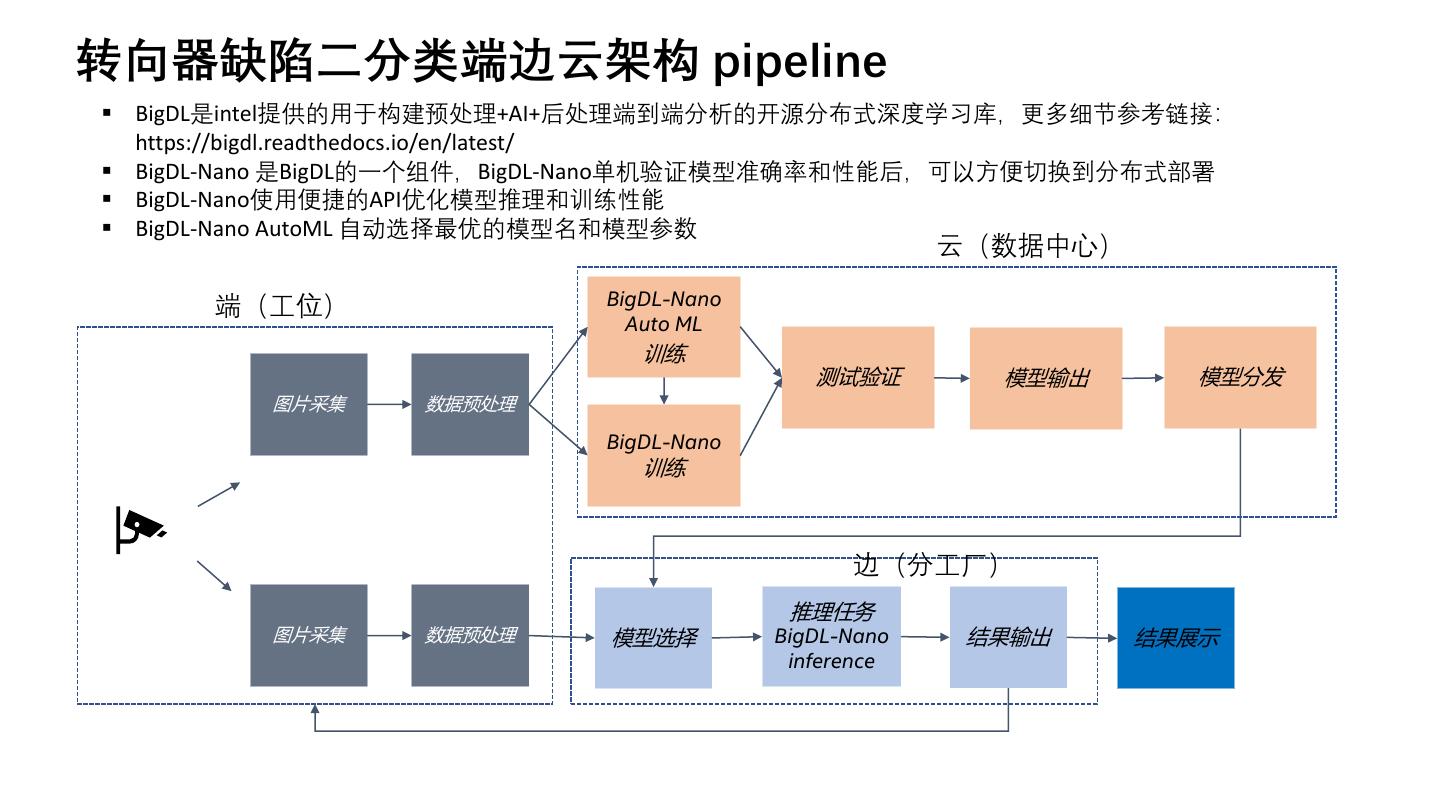
8 .转向器缺陷二分类端边云架构 pipeline
▪ BigDL是intel提供的用于构建预处理+AI+后处理端到端分析的开源分布式深度学习库,更多细节参考链接:
https://bigdl.readthedocs.io/en/latest/
▪ BigDL-Nano 是BigDL的一个组件,BigDL-Nano单机验证模型准确率和性能后,可以方便切换到分布式部署
▪ BigDL-Nano使用便捷的API优化模型推理和训练性能
▪ BigDL-Nano AutoML 自动选择最优的模型名和模型参数
云(数据中心)
端(工位) BigDL-Nano
Auto ML
训练
测试验证 模型输出 模型分发
图片采集 数据预处理
BigDL-Nano
训练
边(分工厂)
推理任务
图片采集 数据预处理 模型选择 BigDL-Nano 结果输出 结果展示
inference
�
9 .BigDL-Nano AutoML模型和参数选择
▪ Batch_size/learning_rate/model_name/image_augmentation
▪ 支持TorchLight模块,暂不支持nn.Module
▪ 降低深度学习门槛,用户只需要提供数据,AutoML可以完成深度学习模型的构建
model = MyModel(
model_name = space.Categorical("resnet50", "inception"),
batch_size = space.Categorical(32, 16), 搜索参数
augmentation_randomResizedCrop = space.Categorical(True, False)
)
from bigdl.nano.pytorch import Trainer
trainer = Trainer(max_epochs = 55, use_hpo=True)
best_model = trainer.search(
model,
target_metric='val_acc', 评价策略
direction='maximize',
n_trials= 5,
尝试次数
max_epochs = 55
)
输出
study = trainer.search_summary()
�
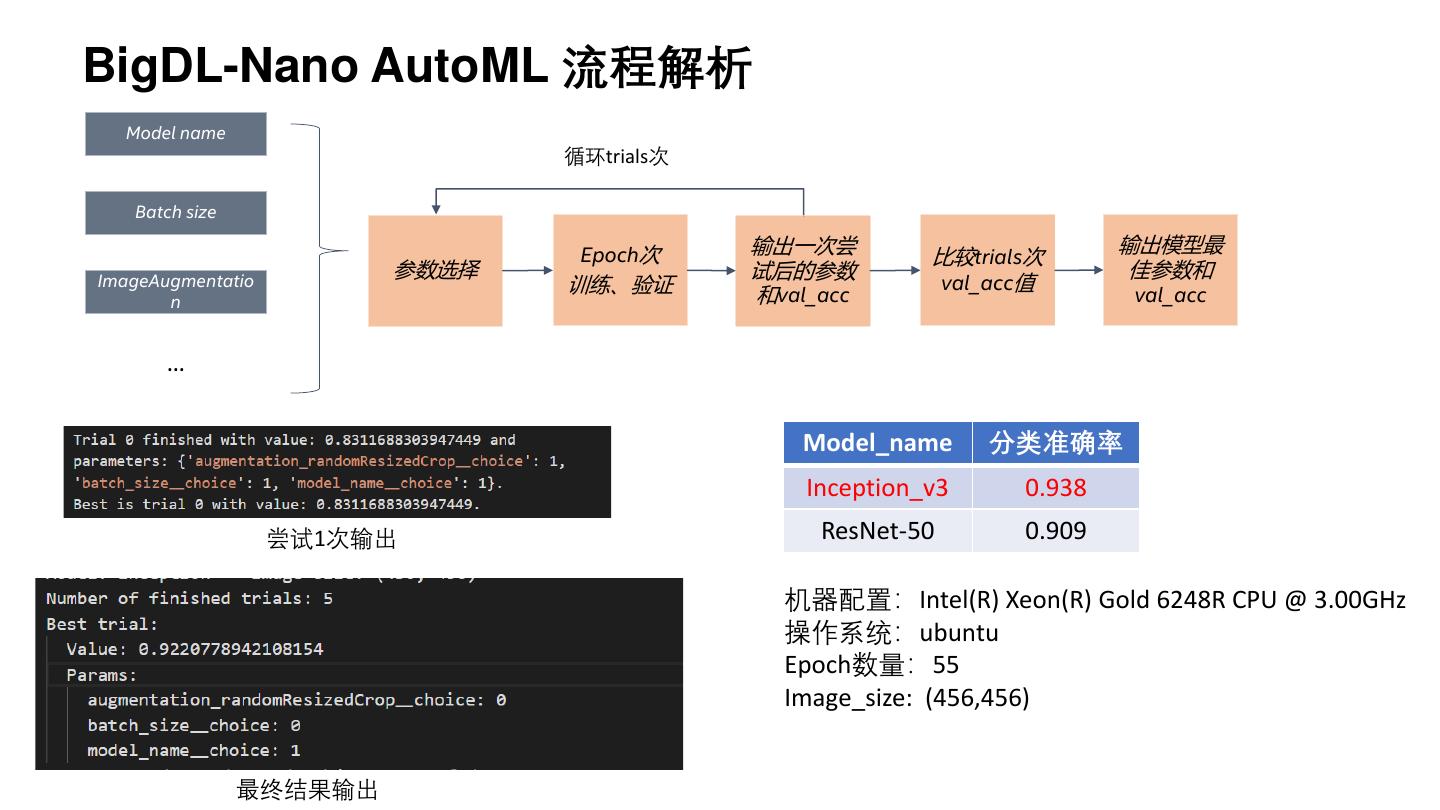
10 .BigDL-Nano AutoML 流程解析
Model name
循环trials次
Batch size
Epoch次 输出一次尝 输出模型最
比较trials次
参数选择 试后的参数 佳参数和
ImageAugmentatio 训练、验证 val_acc值
n 和val_acc val_acc
…
Model_name 分类准确率
Inception_v3 0.938
尝试1次输出 ResNet-50 0.909
机器配置:Intel(R) Xeon(R) Gold 6248R CPU @ 3.00GHz
操作系统:ubuntu
Epoch数量:55
Image_size: (456,456)
最终结果输出
�
11 .BigDL-Nano training 优化
class Trainer(object): from bigdl.nano.pytorch.torch_nano import TorchNano
def train(self): class Trainer(TorchNano):
… def train(self):
hist = Trainer().train() …
hist = Trainer(use_ipex=True, channels_last=True, num_processes=4).train()
source bigdl-nano-init
Setting OMP_NUM_THREADS...
Setting OMP_NUM_THREADS specified for pytorch...
Setting KMP_AFFINITY... ResNet-50 Inception_v3
Setting KMP_BLOCKTIME... original 23m 58s 22m 59s
Setting MALLOC_CONF...
使用BigDL nano加速 15m 53s 17m 49s
+++++ Env Variables +++++
LD_PRELOAD=./../lib/libjemalloc.so speed 1.52x 1.29x
MALLOC_CONF=oversize_threshold:1,background_threa
d:true,metadata_thp:auto,dirty_decay_ms:-
1,muzzy_decay_ms:-1 ▪ 系统级和运行时优化
OMP_NUM_THREADS=48 ▪ 加速模型单机训练性能
KMP_AFFINITY=granularity=fine,compact,1,0
KMP_BLOCKTIME=1
TF_ENABLE_ONEDNN_OPTS=
+++++++++++++++++++++++++
Complete.
�
12 .BigDL-Nano inference 优化
▪ 不指定加速器时,可以自动获取延时最低的模型
▪ 可以指定具体的加速器优化,如onnxruntime、openvino、JIT等
from bigdl.nano.pytorch import InferenceOptimizer 导入包
inference_opt = InferenceOptimizer()
def accuracy(pred, target):
pred = torch.sigmoid(pred)
target = target.view((-1, 1)).type_as(pred).int()
return Accuracy()(pred, target) 模型
inference_opt.optimize(model=model_ft, 数据集
training_data=loader,
validation_data=loader,
metric=accuracy, 评测准确率
direction=“max”,
search_mode="all") 获取延时最低的模型
model_ft, option = inference_opt.get_best_model()
�
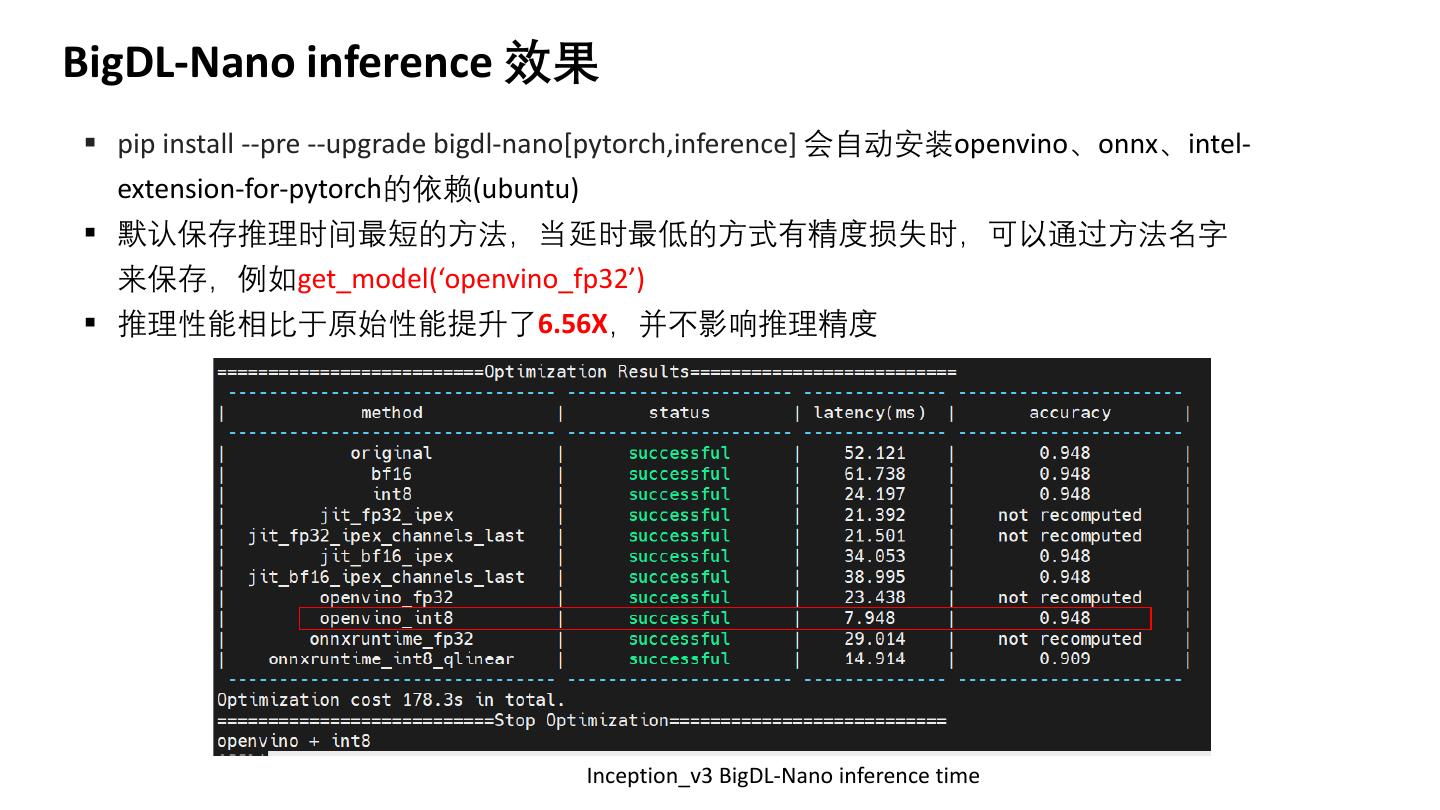
13 .BigDL-Nano inference 效果
▪ pip install --pre --upgrade bigdl-nano[pytorch,inference] 会自动安装openvino、onnx、intel-
extension-for-pytorch的依赖(ubuntu)
▪ 默认保存推理时间最短的方法,当延时最低的方式有精度损失时,可以通过方法名字
来保存,例如get_model(‘openvino_fp32’)
▪ 推理性能相比于原始性能提升了6.56X,并不影响推理精度
Inception_v3 BigDL-Nano inference time
�
14 .BigDL-Nano AutoML + Inference
▪ 选择最佳参数后的best_model可以进一步推理,模型保存Nano自定义格式: yaml
存储元数据,pt存储权重文件
trainer.save(best_model.model, "best_model_nano") 模型保存
loaded_model = best_model.load(“best_model_nano”) (yaml/pt)
from bigdl.nano.pytorch import InferenceOptimizer
模型加载
opt = InferenceOptimizer()
opt.optimize(loaded_model,
training_data = best_model.train_dataloader(), # if you are in
a new session, define a train dataloader or train sample first
excludes=None) # if some method is too slow, you can skip it
by "excludes"
acce_model,option = opt.get_best_model()
排除某些推理方法
# acce_model = opt.get_model(method_name="name")
y = acce_model(input_sample)
�
15 .总结
▪ 端边云架构解决智能制造企业难点
▪ Intel提供了开放的端边云架构软硬件组件,助力制造企业
构建智能制造应用
▪ Intel开源的BigDL提供单机到分布式集群的开发和部署体验
▪ 大量实战案例链接:
▪ 更多智能制造创新合作,请联系intel业务代表: leon.lu@intel.com
�