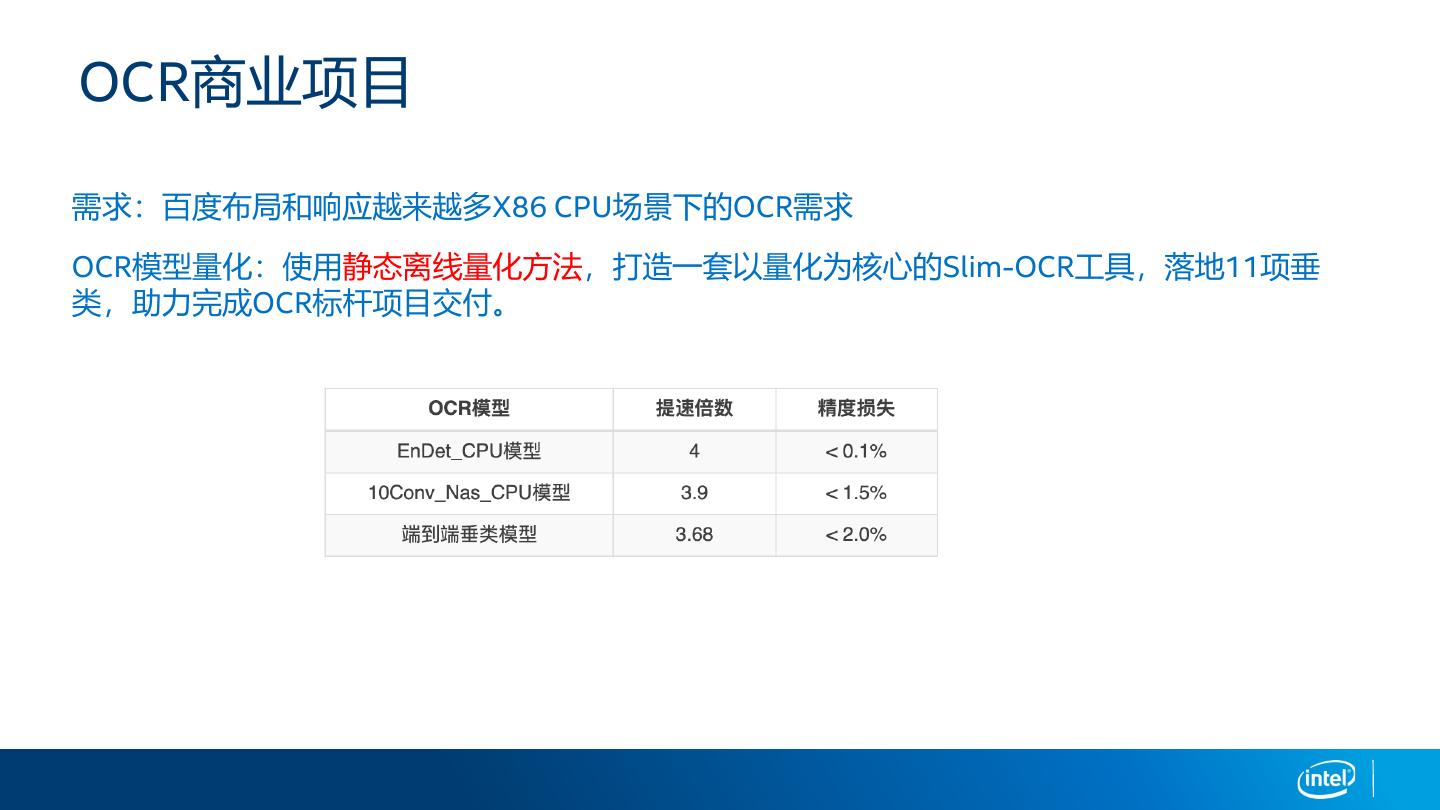
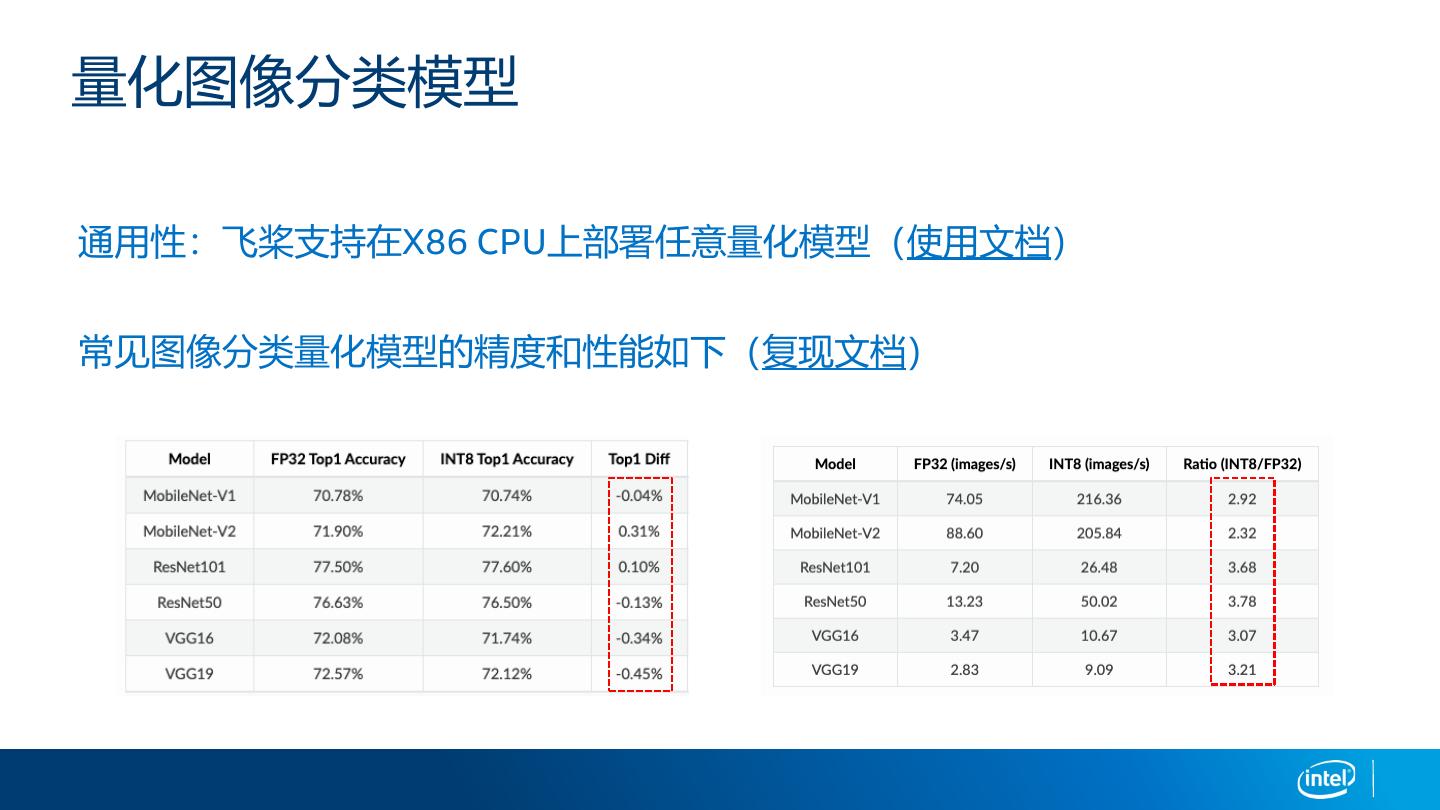
展开查看详情
1 .李丹青 (Danqing Li)
Deep Learning Software Engineer
Intel Cloud & Enterprise Solutions Group
September 2021
�
2 .Agenda
➢ Intel Deep Learning Boost on Xeon
➢ Optimization Methodology
➢ Integrate DL Boost VNNI for PaddlePaddle INT8 inference
➢ Integrate DL Boost BF16 for PaddlePaddle BF16 inference
➢ PaddlePaddle AI models speedup on Xeon
2
�
3 .Intel Deep Learning Boost on Xeon
3
�
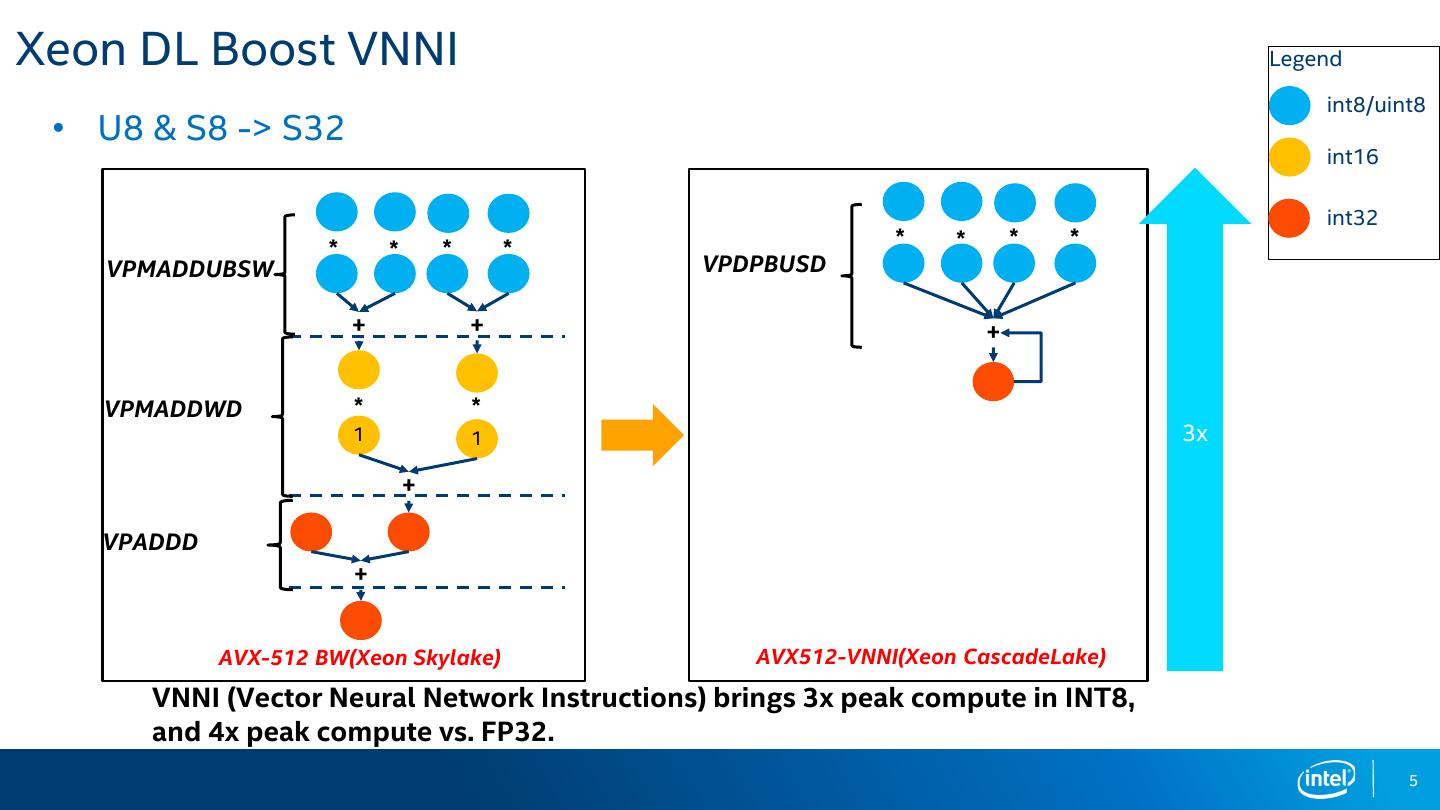
5 .Xeon DL Boost VNNI Legend
int8/uint8
• U8 & S8 -> S32
int16
int32
* * * * * * * *
VPMADDUBSW VPDPBUSD
+ + +
VPMADDWD * *
1 1 3x
+
VPADDD
+
AVX-512 BW(Xeon Skylake) AVX512-VNNI(Xeon CascadeLake)
VNNI (Vector Neural Network Instructions) brings 3x peak compute in INT8,
and 4x peak compute vs. FP32.
5
�
6 . Xeon DL Boost BF16 𝑎−(2𝑒𝑥𝑝𝑜𝑛𝑒𝑛𝑡_𝑏𝑖𝑡 −1)
±1. 𝑥 ∗ 2
sign mantissa exponent
31 0
FP32
8 bits exponent 23 bits mantissa
15 0
Data Dynamic Range Precision
BF16
Type
8 bits exponent 7 bits mantissa FP32 -3.4x1038~3.4x1038 7x10-46
15
BF16 -3.4x1038~3.4x1038 3.05x10-5
6
�
9 .PaddlePaddle integrated oneDNN INT8 ops
Currently, PaddlePaddle integrated oneDNN INT8 ops
- conv2d
- depthwise_conv2d
- fc
- matmul
- pool2d
- gru
- lstm
- elementwise_add
- reshape2
- transpose2
- concat
PaddlePaddle integrated INT8 ops list. [Link]
9
�
10 .PaddlePaddle integrated oneDNN BF16 ops
Currently, PaddlePaddle integrated oneDNN BF16 ops
• sum • cast
• ew_add + grad • scale
• ew_mul + grad • SGD
• matmul + grad • fill_constant
• reduce_mean + grad • uniform_random
• reduce_sum + grad • save
• reshape2 + grad • load
PaddlePaddle integrated BF16 ops list [Link]
10
�
11 .Optimization Methodology
11
�
12 .Xeon AI Inference Optimization Methods (1)
➢ Graph Optimization
• sub-graph transformation
• Operator fusion/folding (minimize memory traffic, minimize inter op framework overhead(like TF))
➢ Operator Kernel Optimization
• Best leverage Intel performance primitives to unleash AVX-512/VNNI/BFP16: oneDNN, MKL etc.
• SIMD (Single instruction multiple data) intrinsic + OpenMP
➢ Lower Precision
• INT8 (VNNI) – model calibration needed
• BFP16 – model calibration free
�
13 .Xeon AI Inference Optimization Methods (2)
➢ Runtime Optimization
• System knobs
• NUMA, Turbo, HT
• Pipelining
• data io & inference
• Multi-instance
�
14 .Integrate DL Boost VNNI for PaddlePaddle INT8
inference
14
�
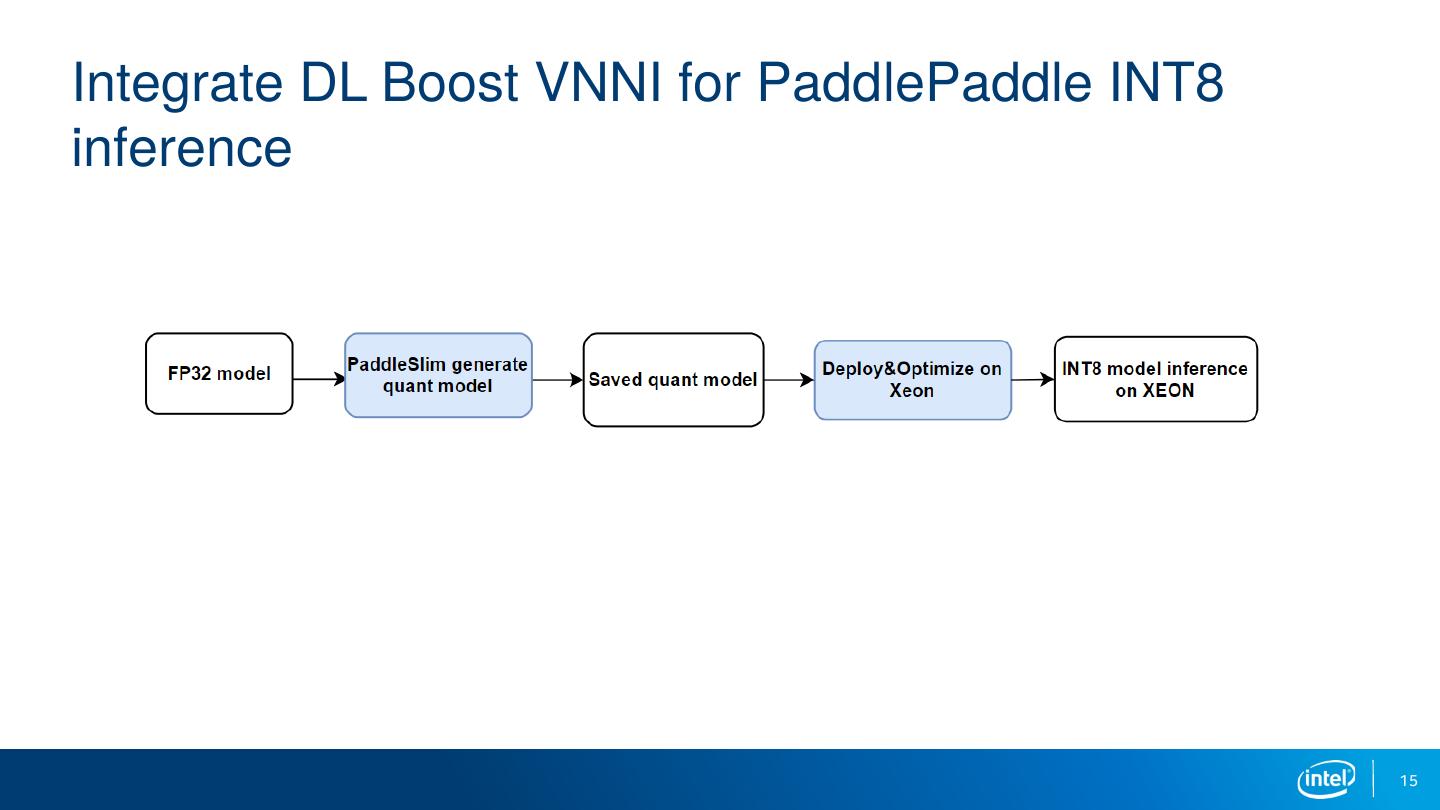
15 .Integrate DL Boost VNNI for PaddlePaddle INT8
inference
15
�
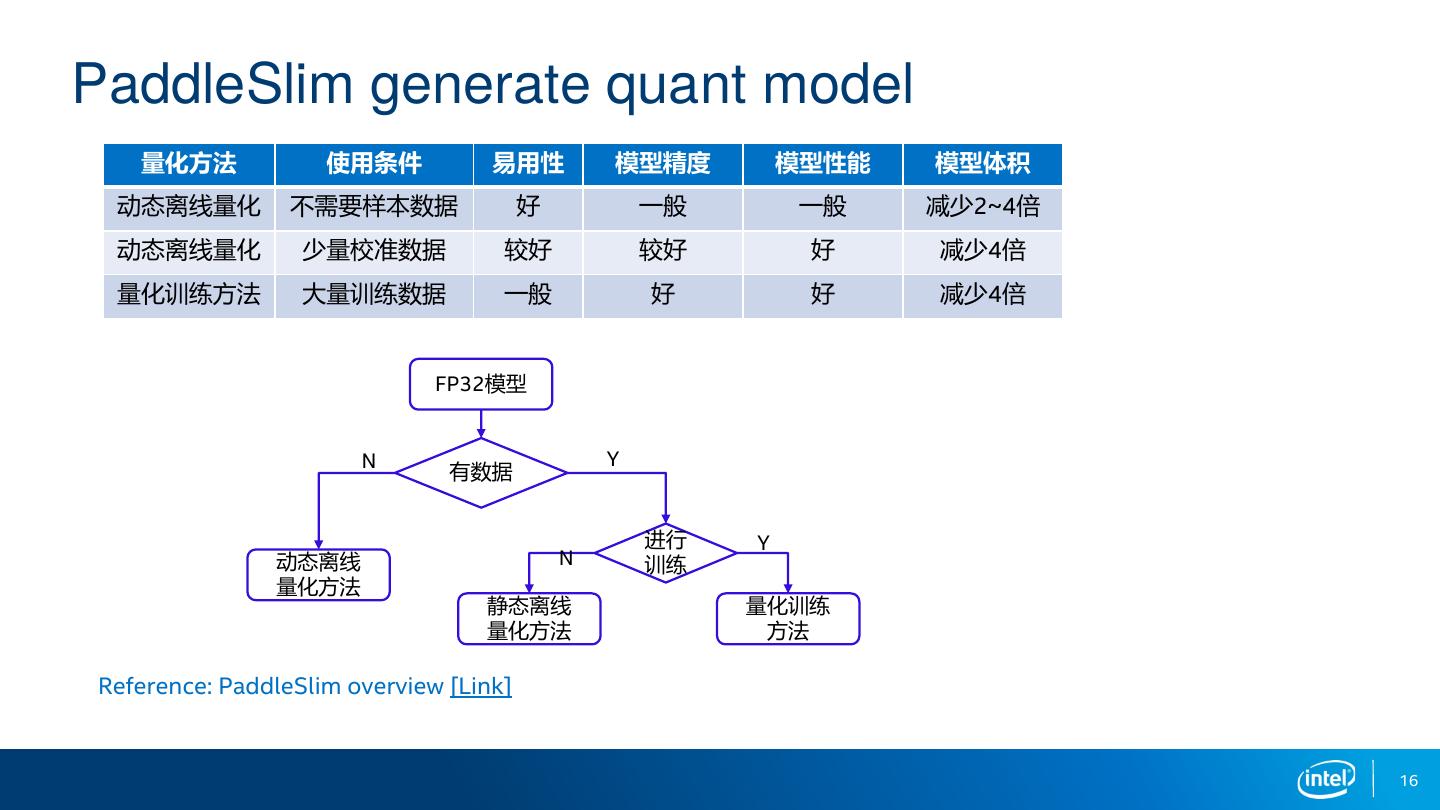
16 .PaddleSlim generate quant model
量化方法 使用条件 易用性 模型精度 模型性能 模型体积
动态离线量化 不需要样本数据 好 一般 一般 减少2~4倍
动态离线量化 少量校准数据 较好 较好 好 减少4倍
量化训练方法 大量训练数据 一般 好 好 减少4倍
FP32模型
N Y
有数据
进行 Y
动态离线 N 训练
量化方法
静态离线 量化训练
量化方法 方法
Reference: PaddleSlim overview [Link]
16
�
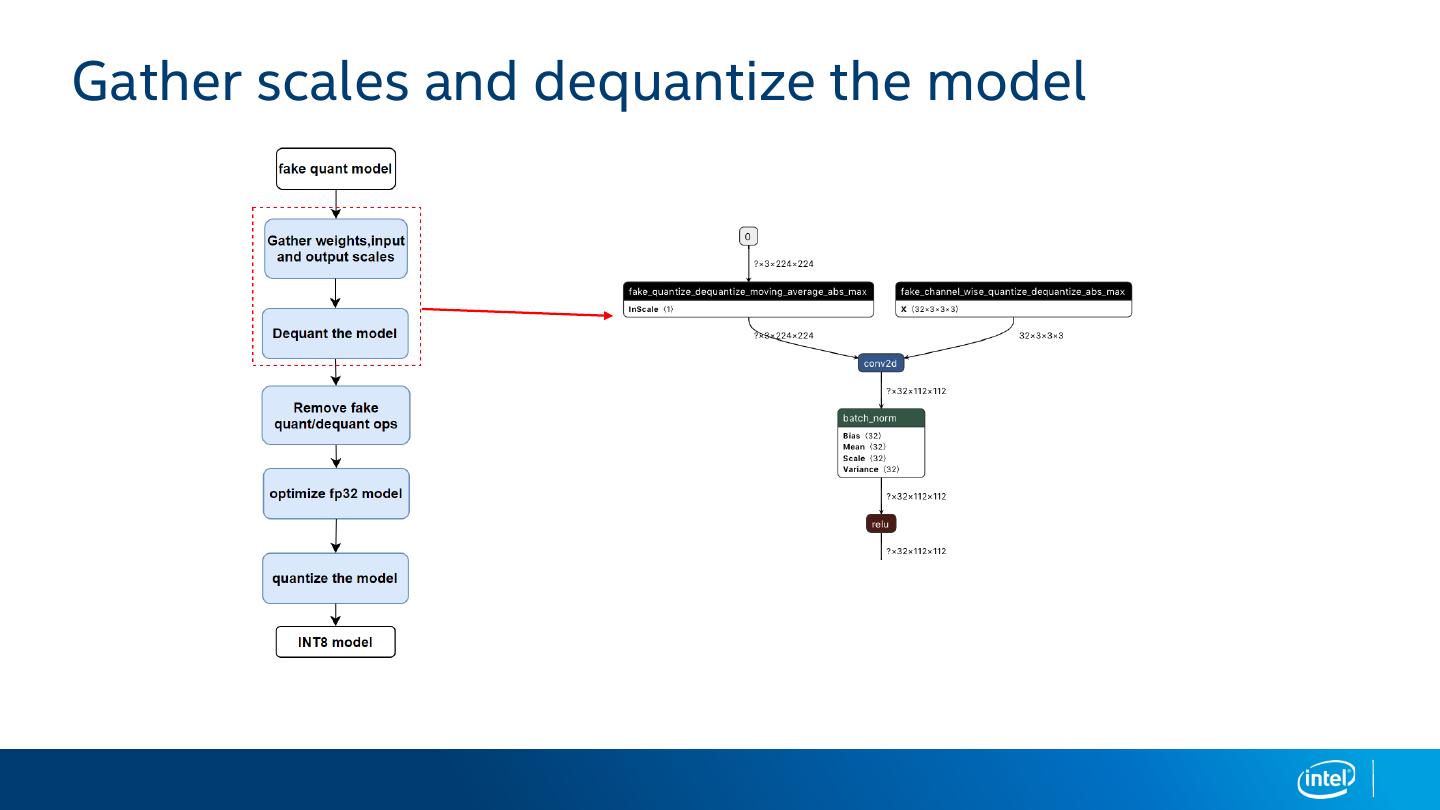
17 .Deploy quant models to INT8 model on XEON
To transform and optimize fake-quantized model to oneDNN INT8 model, following steps are
taken
• Collect the scales from the fake-quantized model
• Dequantize the model to fp32 model using the scales
• Optimize the fp32 model by applying oneDNN fp32 op kernels, apply fusions etc.
• Quantize the optimized model with scales and oneDNN INT8 op kernels.
• Save the final real INT8 model and test on Xeon.
Enable INT8 ops and inference on Xeon
• Integrated oneDNN INT8 ops will be used
• Other ops may remain FP32, but we are continuously working on supporting more INT8 ops
17
�
18 .Gather scales and dequantize the model
�
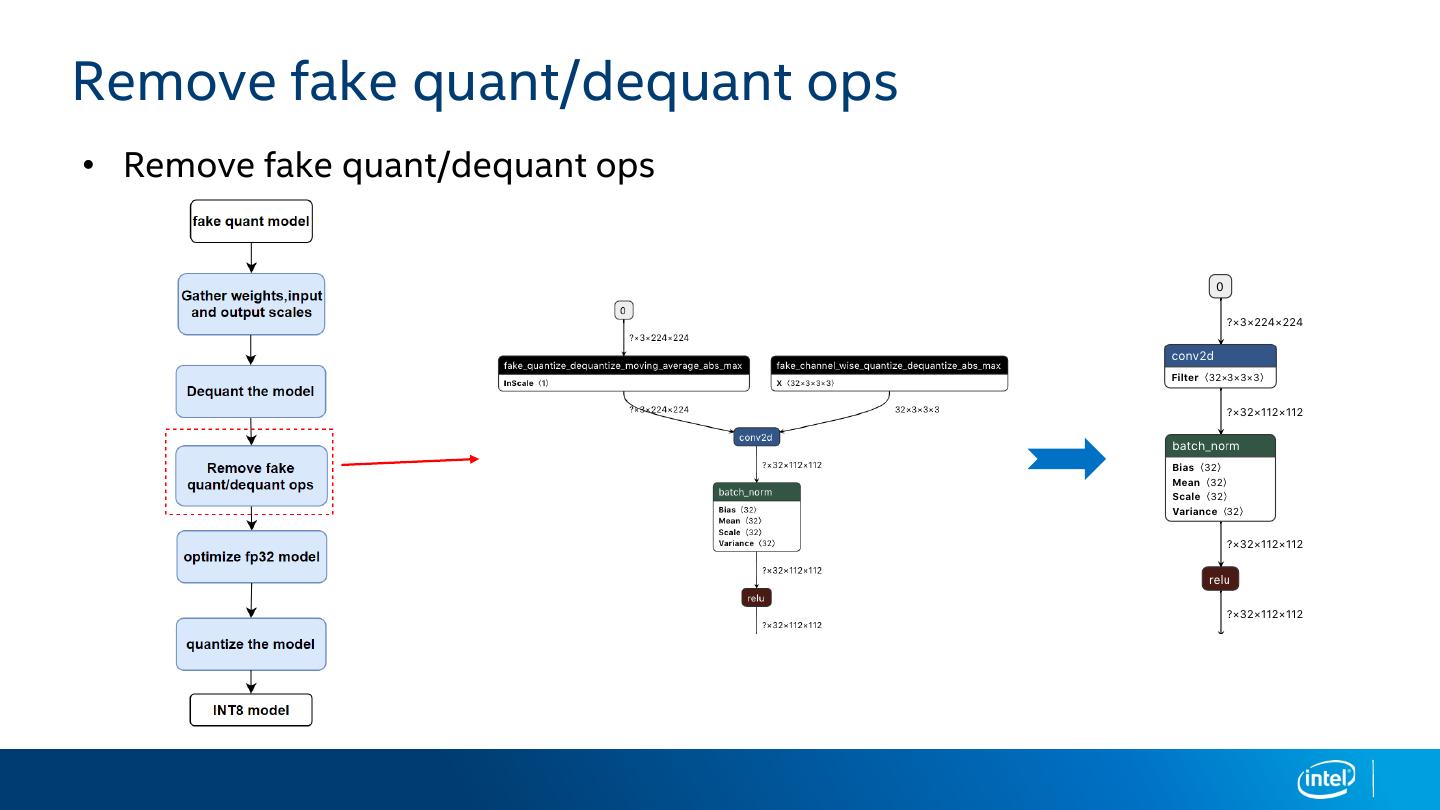
19 .Remove fake quant/dequant ops
• Remove fake quant/dequant ops
�
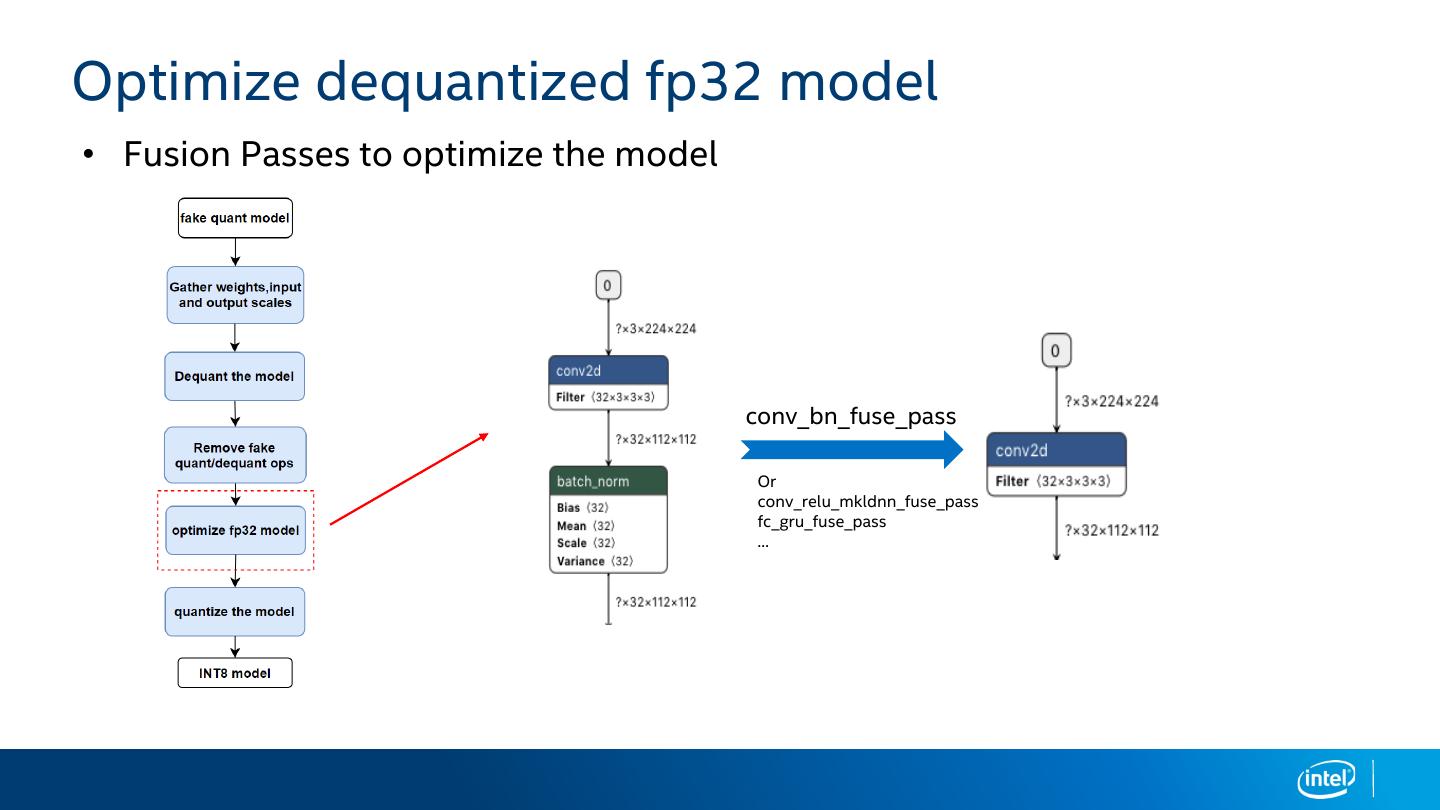
20 .Optimize dequantized fp32 model
• Fusion Passes to optimize the model
conv_bn_fuse_pass
Or
conv_relu_mkldnn_fuse_pass
fc_gru_fuse_pass
…
�
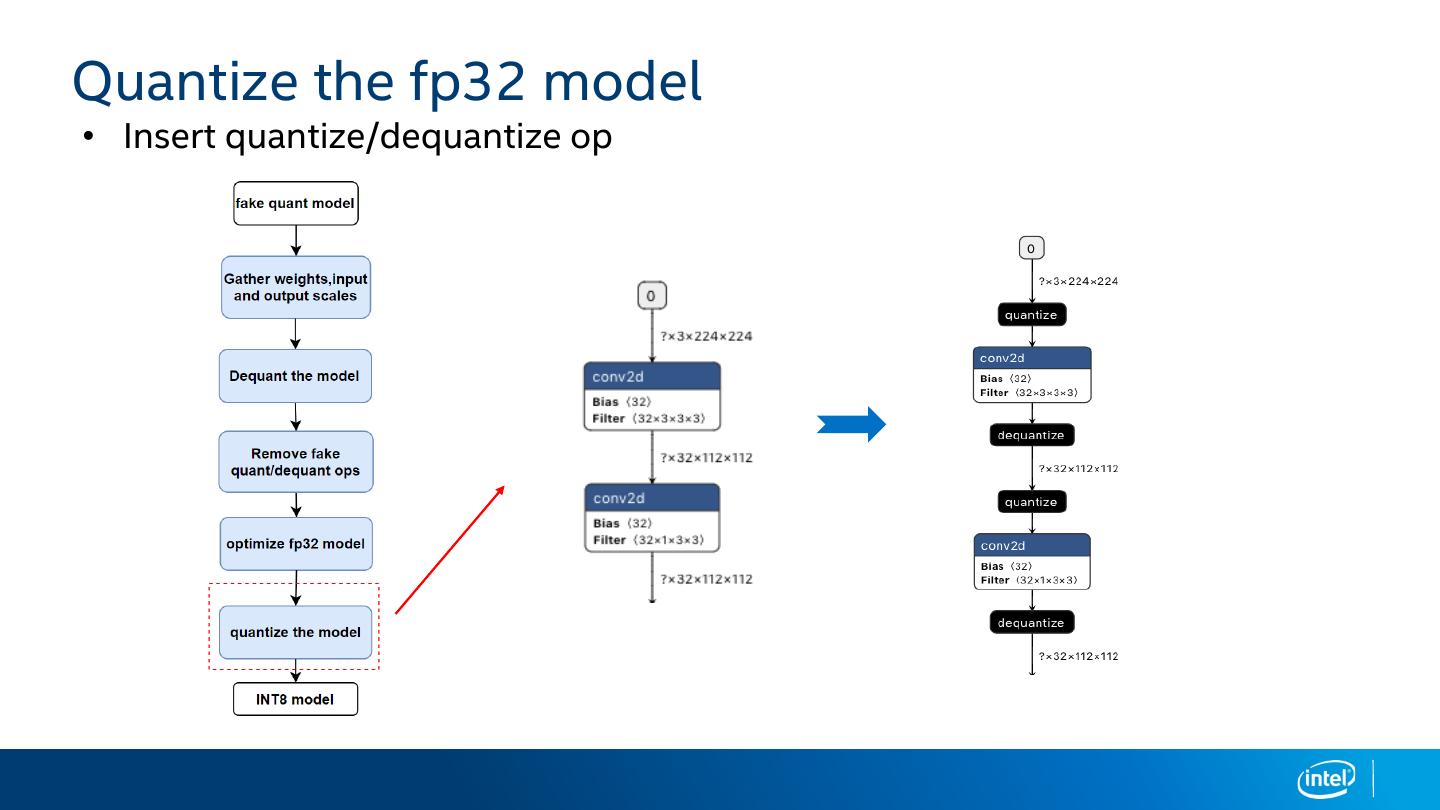
21 .Quantize the fp32 model
• Insert quantize/dequantize op
�
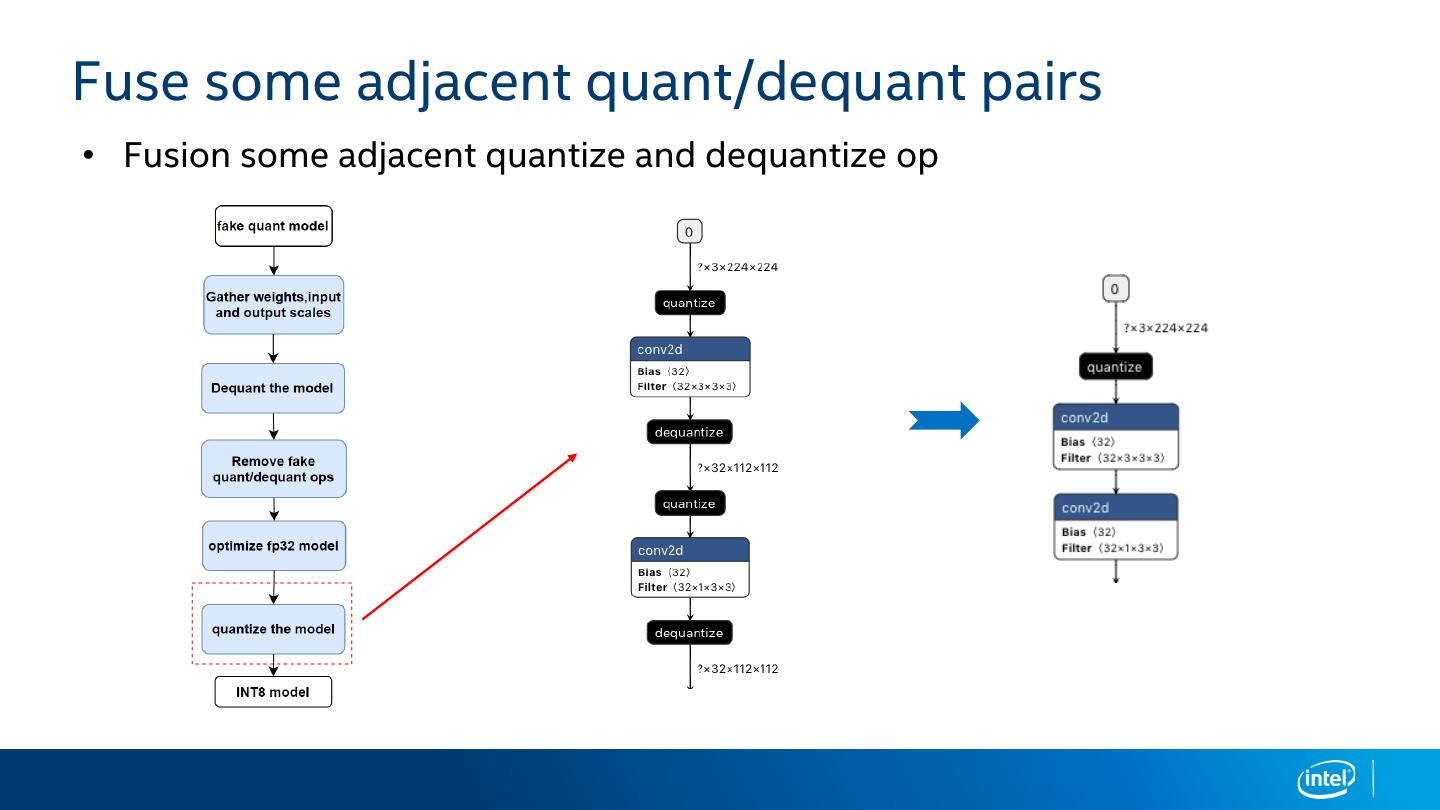
22 .Fuse some adjacent quant/dequant pairs
• Fusion some adjacent quantize and dequantize op
�
23 .PaddlePaddle integrated oneDNN INT8 ops
Currently, PaddlePaddle integrated oneDNN INT8 ops
- conv2d
- depthwise_conv2d
- fc
- matmul
- pool2d
- gru
- elementwise_add
- reshape2
- transpose2
- concat
PaddlePaddle integrated INT8 ops list. [Link]
23
�
24 .User Manual: How to deploy INT8 models on Xeon
- PaddleSlim generate quant model
- Quant-aware training
- Dynamic: paddleslim.QAT
- Static: paddleslim.quant.quant_aware
- PTQ Static: paddleslim.quant.quant_post_static
- PTQ Dynamic: paddleslim.quant.quant_post_dynamic
- Save real INT8 model on Intel Xeon
- python save_quant_model.py --quant_model_path= --int8_model_save_path= --ops_to_quantize=
- Execute INT8 model on Xeon
- Refer to PaddleInference: prepare Predictor, config and then run
Deploy INT8 inference in PaddlePaddle on Xeon[Link]
24
�
25 .Integrate DL Boost BF16 for PaddlePaddle
BF16 inference
25
�
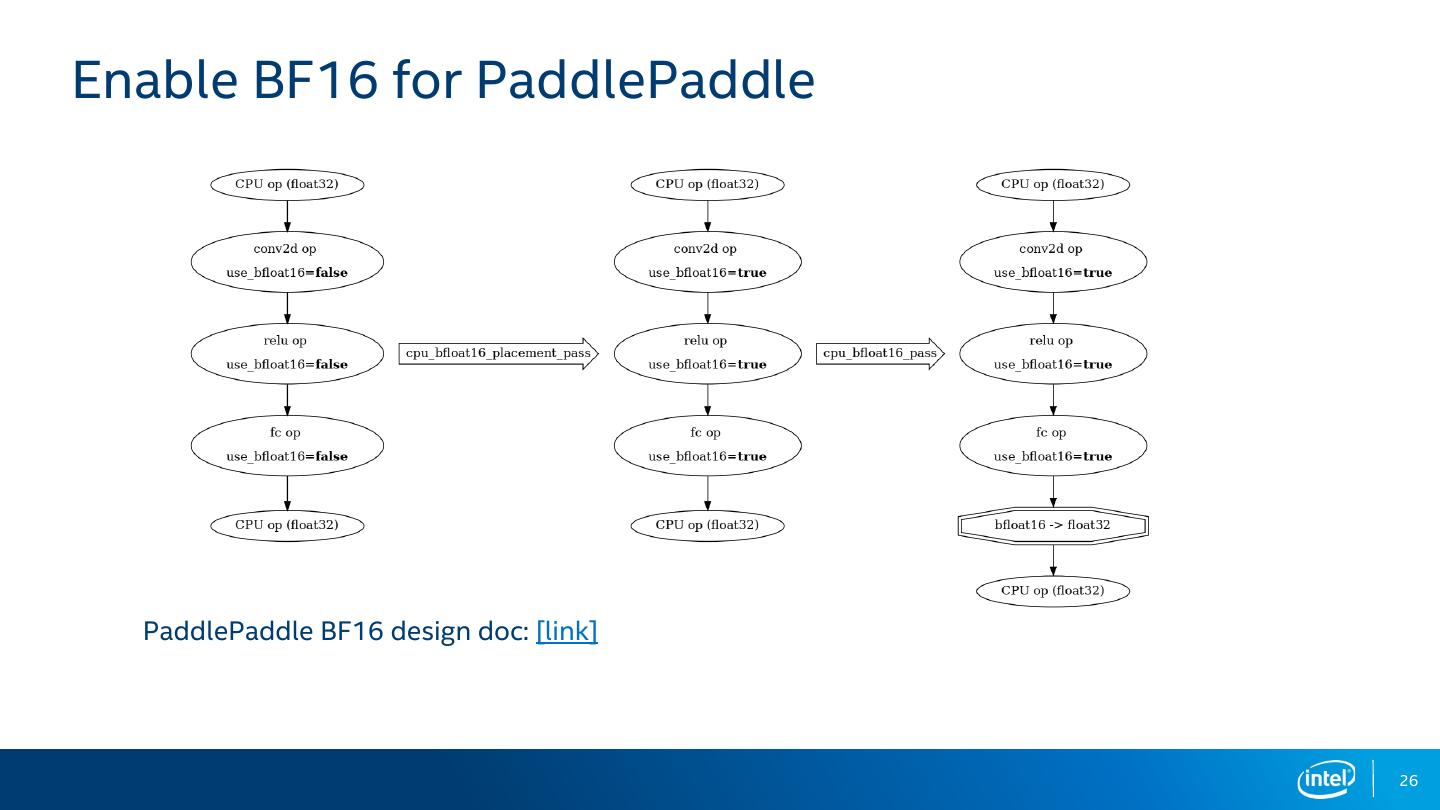
26 .Enable BF16 for PaddlePaddle
PaddlePaddle BF16 design doc: [link]
26
�
27 .PaddlePaddle integrated oneDNN BF16 ops
Currently, PaddlePaddle integrated oneDNN BF16 ops
• sum • cast
• ew_add + grad • scale
• ew_mul + grad • SGD
• matmul + grad • fill_constant
• reduce_mean + grad • uniform_random
• reduce_sum + grad • save
• reshape2 + grad • load
PaddlePaddle integrated BF16 ops. [Link]
27
�
28 .PaddlePaddle AI models speedup on Xeon
28
�
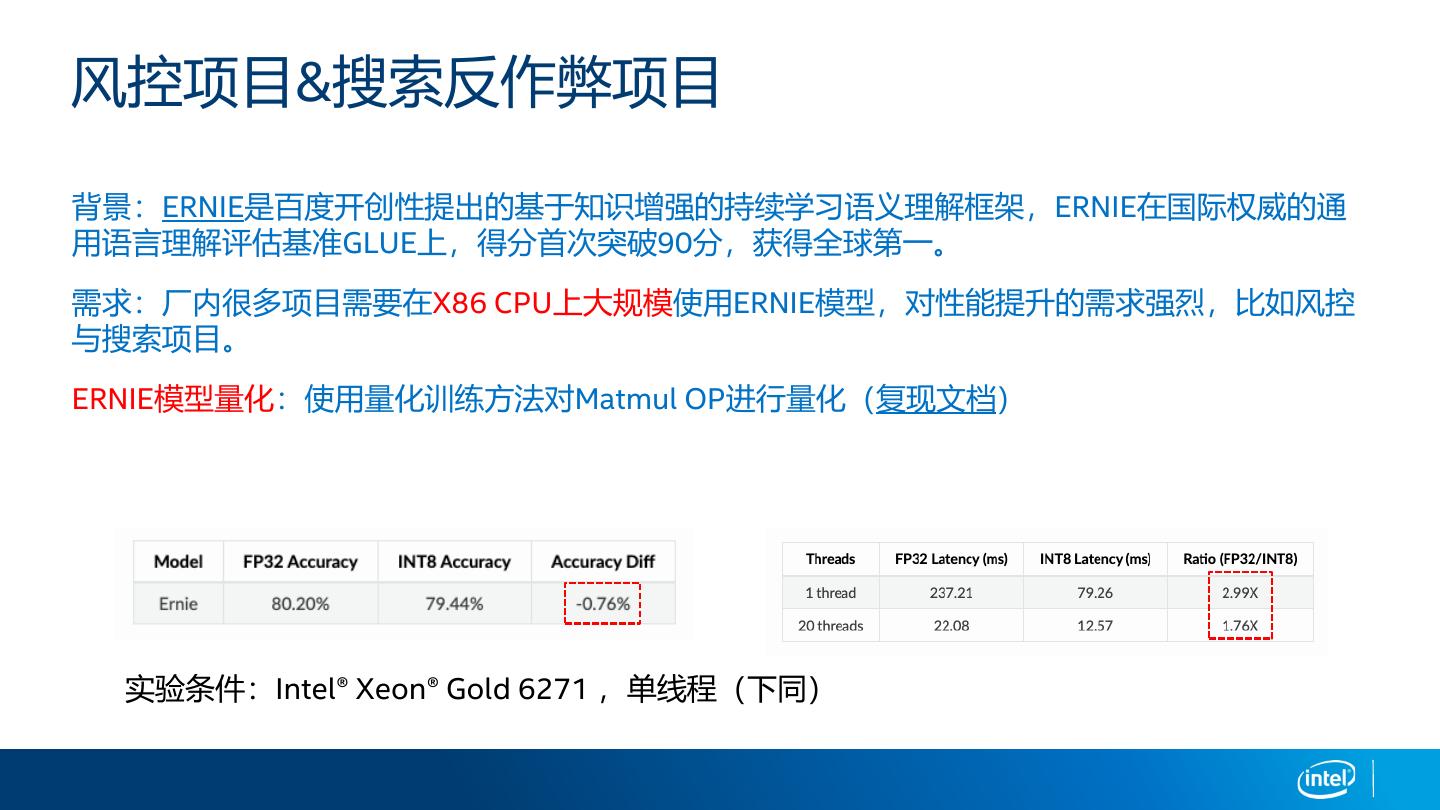
29 .风控项目&搜索反作弊项目
背景:ERNIE是百度开创性提出的基于知识增强的持续学习语义理解框架,ERNIE在国际权威的通
用语言理解评估基准GLUE上,得分首次突破90分,获得全球第一。
需求:厂内很多项目需要在X86 CPU上大规模使用ERNIE模型,对性能提升的需求强烈,比如风控
与搜索项目。
ERNIE模型量化:使用量化训练方法对Matmul OP进行量化(复现文档)
实验条件:Intel® Xeon® Gold 6271 ,单线程(下同)
�