9 . HPC + AI 在英特尔® 架构上开发应用
HPC AI
Applications
Productivity
Framework
Performance Intel® Math Kernel
Library (MKL)
Intel® Performance
Primitives (IPP)
Intel Python
Distribution
Intel® Data Analytics
Acceleration Library
Intel® nGraph
library (DAAL)
Intel® Math Kernel Library
(MKL, MKL-DNN)
hardware +
Compute
*Future FPGA Movidius Intel® GNA* Autonomous
VPU Driving
Memory & Storage Networking
9
�
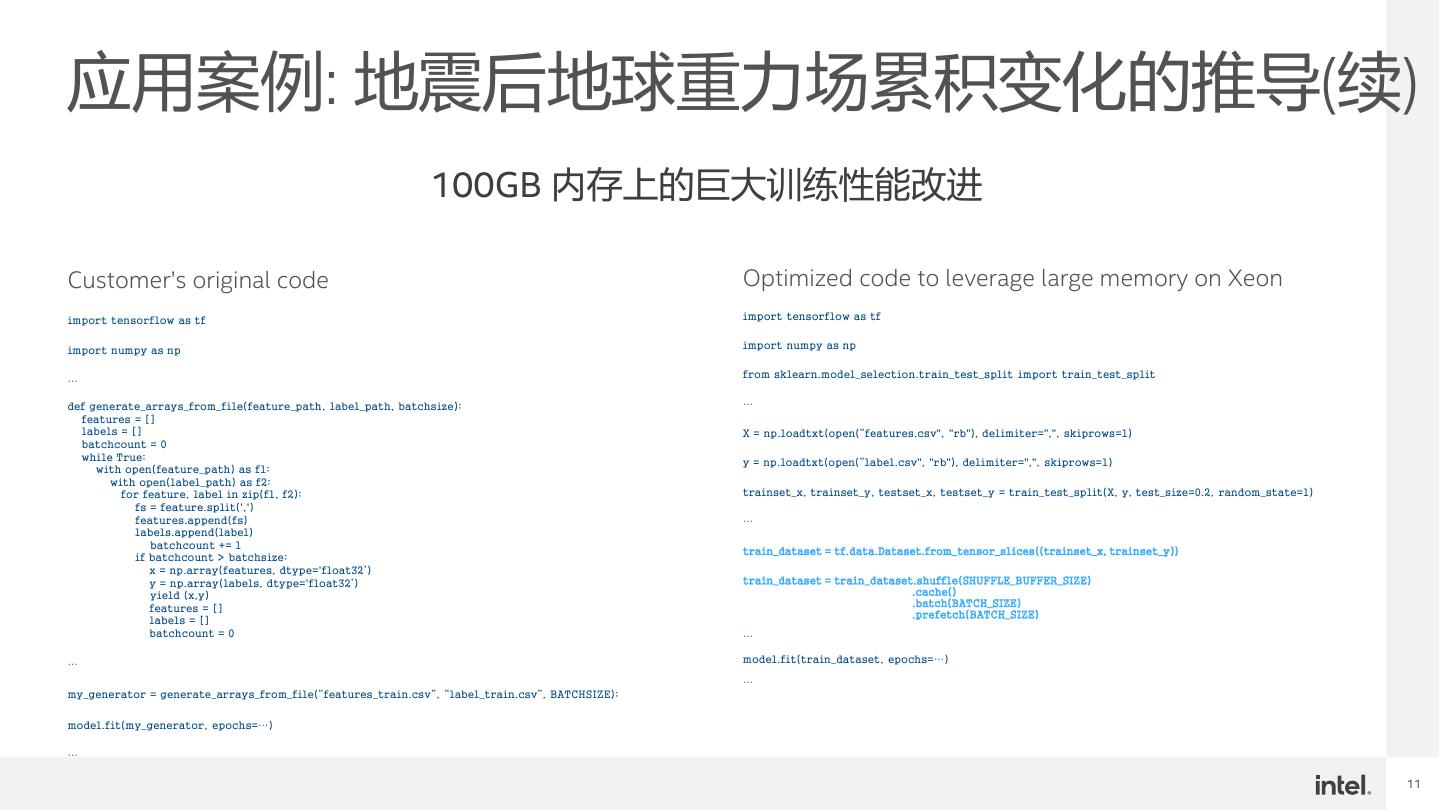
11 .应用案例: 地震后地球重力场累积变化的推导(续)
100GB 内存上的巨大训练性能改进
Customer’s original code Optimized code to leverage large memory on Xeon
import tensorflow as tf import tensorflow as tf
import numpy as np
import numpy as np
from sklearn.model_selection.train_test_split import train_test_split
…
def generate_arrays_from_file(feature_path, label_path, batchsize): …
features = []
labels = [] X = np.loadtxt(open(“features.csv", "rb"), delimiter=",", skiprows=1)
batchcount = 0
while True:
y = np.loadtxt(open(“label.csv", "rb"), delimiter=",", skiprows=1)
with open(feature_path) as f1:
with open(label_path) as f2:
for feature, label in zip(f1, f2): trainset_x, trainset_y, testset_x, testset_y = train_test_split(X, y, test_size=0.2, random_state=1)
fs = feature.split(',')
features.append(fs) …
labels.append(label)
batchcount += 1
train_dataset = tf.data.Dataset.from_tensor_slices((trainset_x, trainset_y))
if batchcount > batchsize:
x = np.array(features, dtype='float32’)
y = np.array(labels, dtype='float32’) train_dataset = train_dataset.shuffle(SHUFFLE_BUFFER_SIZE)
yield (x,y) .cache()
.batch(BATCH_SIZE)
features = []
.prefetch(BATCH_SIZE)
labels = []
batchcount = 0 …
… model.fit(train_dataset, epochs=…)
…
my_generator = generate_arrays_from_file(“features_train.csv”, “label_train.csv”, BATCHSIZE):
model.fit(my_generator, epochs=…)
…
11
�