
























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
2.深度学习模型向Intel Habana加速卡的迁移和优化
- Habana AI 软件解决方案概述
- PyTorch 模型迁移实例
- PyTorch 混精度训练实例
- 多卡/多节点扩展训练实例
- 性能优化
康乐天 ,英特尔人工智能软件方案工程师,主要从事高性能计算,异构计算和AI解决方案相关方面的工作。
展开查看详情
1 . Training with Habana Accelerator Card Letian Kang Habana Labs – Confidential Information 1
2 . Contents ❑General overview ❑Migration PyTorch model to HPU ❑PyTorch Mixed Precision Training on HPU ❑PyTorch Distributed Training with HPU ❑Profiling & Performance Optimization Habana Labs – Confidential Information 2
3 . Contents ❑General overview ❑Migration PyTorch model to HPU ❑PyTorch Mixed Precision Training on HPU ❑PyTorch Distributed Training with HPU ❑Profiling & Performance Optimization Habana Labs – Confidential Information 3
4 . General overview - SynapseAI® Software Suite ❑Use apt-get install or yum install ❑habanalabs-dkms – installs the PCIe driver ❑habanalabs-thunk ❑habanalabs-firmware ❑habanalabs-graph ❑habanalabs-firmware-tools ❑habanalabs-container-runtime ❑habanalabs-qual ❑Get via docker image ❑docker pull vault.habana.ai/gaudi-docker/1.6.1/{$OS}/habanalabs/tensorflow- installer-tf-cpu-${TF_VERSION}:latest ❑docker pull vault.habana.ai/gaudi-docker/1.6.1/{$OS}/habanalabs/pytorch- installer-1.12.0:latest Habana Labs – Confidential Information 4
5 . General overview - Supported Framworks ❑Tensorflow https://github.com/HabanaAI/Setup_and_Install/blob/main/installation_scripts/Tens orFlow/tensorflow_installation.sh ❑PyTorch https://github.com/HabanaAI/Setup_and_Install/blob/main/installation_scripts/PyTo rch/pytorch_installation.sh ❑PyTorch Lightning https://pytorch-lightning.readthedocs.io/en/latest/accelerators/hpu.html ❑Hugging Face Optimum-Habana https://huggingface.co/docs/optimum/habana_index Habana Labs – Confidential Information 5
6 . General overview - Orchestration Solutions ❑Docker ❑Kubernetes ❑OpenShift (OCP) ❑VMware Tanzu ❑AWS https://docs.habana.ai/en/latest/Orchestration/index.html Habana Labs – Confidential Information 6
7 . Contents ❑General overview ❑Migration PyTorch model to HPU ❑PyTorch Mixed Precision Training on HPU ❑PyTorch Distributed Training with HPU ❑Profiling & Performance Optimization Habana Labs – Confidential Information 7
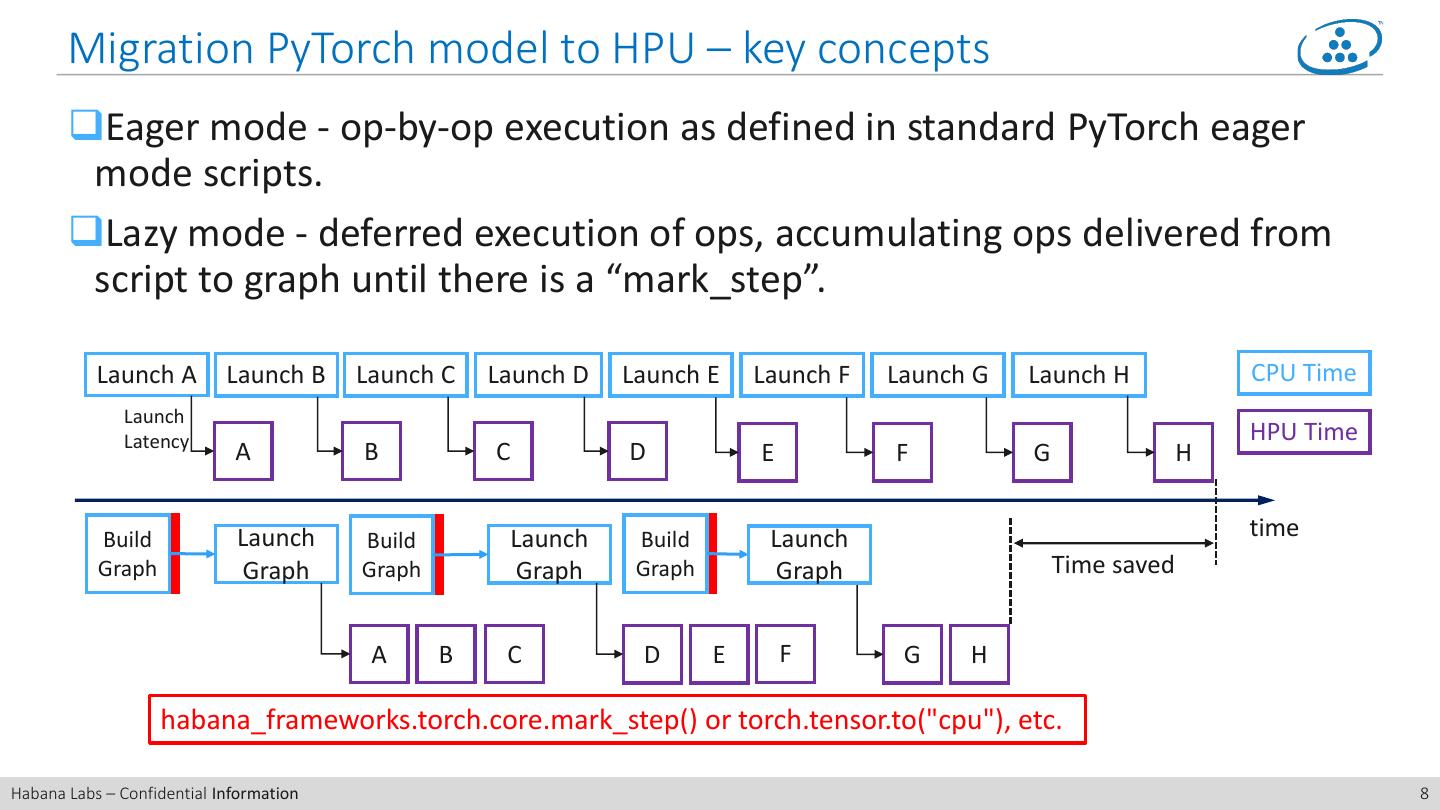
8 . Migration PyTorch model to HPU – key concepts ❑Eager mode - op-by-op execution as defined in standard PyTorch eager mode scripts. ❑Lazy mode - deferred execution of ops, accumulating ops delivered from script to graph until there is a “mark_step”. Launch A Launch B Launch C Launch D Launch E Launch F Launch G Launch H CPU Time Launch Latency HPU Time A B C D E F G H Build Launch Build Launch Build Launch time Graph Graph Graph Graph Graph Graph Time saved A B C D E F G H habana_frameworks.torch.core.mark_step() or torch.tensor.to("cpu"), etc. Habana Labs – Confidential Information 8
9 . Migration PyTorch model to HPU – Base Codes https://github.com/pytorch/examples/tree/main/imagenet https://github.com/JoursBleu/resnet_torch_habana Habana Labs – Confidential Information 9
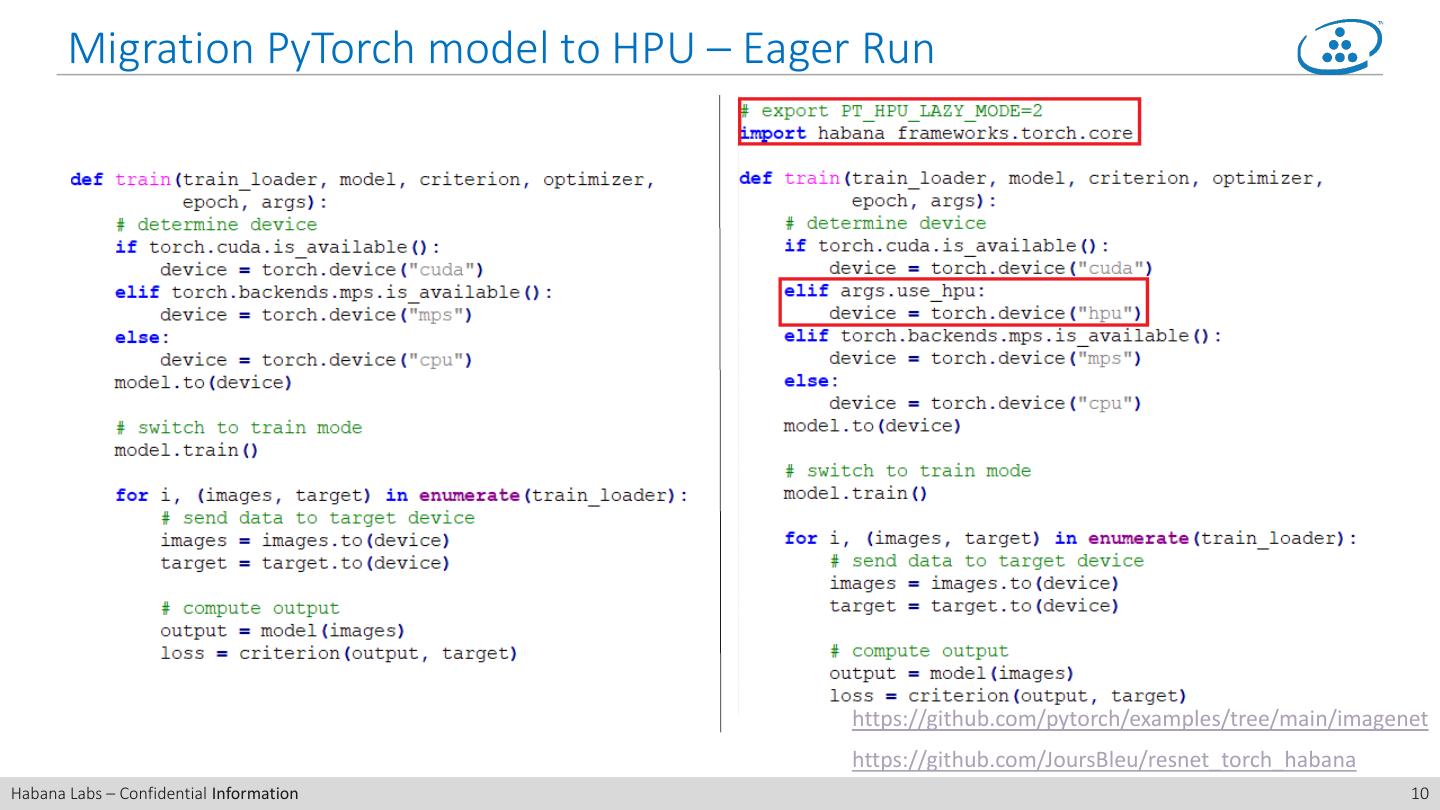
10 . Migration PyTorch model to HPU – Eager Run https://github.com/pytorch/examples/tree/main/imagenet https://github.com/JoursBleu/resnet_torch_habana Habana Labs – Confidential Information 10
11 . Migration PyTorch model to HPU – Lazy Run https://github.com/pytorch/examples/tree/main/imagenet https://github.com/JoursBleu/resnet_torch_habana Habana Labs – Confidential Information 11
12 . Migration PyTorch model to HPU - Summary 1. import habana_frameworks.torch 2. model.to("hpu") && input.to("hpu") 3. (Lazy mode) add mark_step Habana Labs – Confidential Information 12
13 . Contents ❑General overview ❑Migration PyTorch model to HPU ❑PyTorch Mixed Precision Training on HPU ❑PyTorch Distributed Training with HPU ❑Profiling & Performance Optimization Habana Labs – Confidential Information 13
14 . PyTorch Mixed Precision Training on HPU - hmp.convert ❑Turn on mixed precision training support: from habana_frameworks.torch.hpex import hmp hmp.convert(opt_level="O1", bf16_file_path="", fp32_file_path="", isVerbose=False) ❑Convert Rules ❑Two different lists are maintained: (i) BF16, (ii) FP32 ❑Any OPs not in the above two lists will run with precision type of its 1st input ❑For OPs with multiple tensor inputs, cast all inputs to the widest precision type among all input precision types. ❑For in-place OPs, cast all inputs to precision type of 1st input. Habana Labs – Confidential Information 14
15 . PyTorch Mixed Precision Training on HPU - hmp.convert ❑Turn on mixed precision training support: from habana_frameworks.torch.hpex import hmp hmp.convert(opt_level="O1", bf16_file_path="", fp32_file_path="", isVerbose=False) ❑opt_level ❑O1(default) Default BF16 list = [addmm, bmm, conv1d, conv2d, conv3d, dot, mm, mv] Default FP32 list = [batch_norm, cross_entropy, log_softmax, softmax, nll_loss, topk] ❑O2 In this mode, only GEMM and Convolution type OPs (e.g. conv1d, conv2d, conv3d, addmm, mm, bmm, mv, dot) should run in BF16 and all other OPs should run in FP32 Habana Labs – Confidential Information 15
16 . PyTorch Mixed Precision Training on HPU - hmp.convert ❑Turn on mixed precision training support: from habana_frameworks.torch.hpex import hmp hmp.convert(opt_level="O1", bf16_file_path="", fp32_file_path="", isVerbose=False) ❑bf16_file_path=<.txt> && fp32_file_path=<.txt> ❑isVerbose ❑enable verbose logs https://github.com/JoursBleu/resnet_torch_habana Habana Labs – Confidential Information 16
17 . PyTorch Mixed Precision Training on HPU - hmp.disable_casts ❑Any segment of script (e.g. optimizer) in which you want to avoid using mixed precision should be kept under the following Python context: from habana_frameworks.torch.hpex import hmp with hmp.disable_casts(): #code line 1 #code line 2 #... Habana Labs – Confidential Information 17
18 . PyTorch Mixed Precision Training on HPU https://github.com/pytorch/examples/tree/main/imagenet https://github.com/JoursBleu/resnet_torch_habana Habana Labs – Confidential Information 18
19 . PyTorch Mixed Precision Training on HPU - Summary 1. from habana_frameworks.torch.hpex import hmp 2. hmp.convert 3. (Optional) Add bf16_file_path & fp32_file_path 4. (Optional) hmp.disable_casts Habana Labs – Confidential Information 19
20 . Contents ❑General overview ❑Migration PyTorch model to HPU ❑PyTorch Mixed Precision Training on HPU ❑PyTorch Distributed Training with HPU ❑Profiling & Performance Optimization Habana Labs – Confidential Information 20
21 . PyTorch Distributed Training with HPU Step 1: follow PyTorch official docs to export the model distributed. https://pytorch.org/docs/stable/notes/ddp.html Step 2: use hccl backend. import habana_frameworks.torch.distributed.hccl torch.distributed.init_process_group(backend='hccl', rank=rank, world_size=world_size) Habana Labs – Confidential Information 21
22 . Summary Single card – FP32 1. import habana_frameworks.torch 2. to("hpu") 3. (Lazy mode) add mark_step Single card – BF16 1. from habana_frameworks.torch.hpex import hmp 2. hmp.convert 3. (Optional) hmp.disable_casts 4. (Optional) Add bf16_file_path & fp32_file_path Distributed 1. import habana_frameworks.torch.distributed.hccl 2. Modify backend of init_process_group to “hccl” Habana Labs – Confidential Information 22
23 . Contents ❑General overview ❑Migration PyTorch model to HPU ❑PyTorch Mixed Precision Training on HPU ❑PyTorch Distributed Training with HPU ❑Profiling & Performance Optimization Habana Labs – Confidential Information 23
24 . Profiling ❑High level profile Users familiar with TensorBoard who develop with TensorFlow or PyTorch can start using the respective profiler similar to MKL, GPU or TPU. ❑Low level profile Users interested in low-level focused profiling as well as those writing their models in SynapseAI® language without framework can use SynapseAI Profiling Subsystem. Habana Labs – Confidential Information 24
25 . Performance Optimization ❑Batch Size ❑PyTorch Mixed Precision ❑Gradient Buckets in Multi-card/Multi-node Training https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html ❑Pinning Memory For Dataloader https://pytorch.org/docs/stable/data.html#memory-pinning ❑Use Fused Operators https://docs.habana.ai/en/latest/PyTorch/Model_Optimization_PyTorch/Custom_Ops_PyTorch.html#c ustom-operators ❑Use HPU Graph APIs https://docs.habana.ai/en/latest/PyTorch/PyTorch_User_Guide/Python_Packages.html#hpu-graph- apis https://docs.habana.ai/en/latest/PyTorch/Model_Optimization_PyTorch/index.html Habana Labs – Confidential Information 25
26 . Performance Optimization - HPU Graph ❑HPU Graph APIs import torch import habana_frameworks.torch as ht ❑capture_begin() - Begins capturing g = ht.hpu.HPUGraph() HPU work on the current stream. s = ht.hpu.Stream() with ht.hpu.stream(s): ❑capture_end() - Ends capturing HPU g.capture_begin() work on the current stream. a = torch.full((100,), 1, device="hpu") b=a ❑replay() - Replays the HPU work captured by this graph. b=b+1 g.capture_end() g.replay() ht.hpu.synchronize() https://github.com/pytorch/examples/tree/main/imagenet https://github.com/JoursBleu/resnet_torch_habana Habana Labs – Confidential Information 26
27 . Performance Optimization - HPU Graph CPU Time Build Launch Build Launch Build Launch Build Launch Graph 1 Graph 1 Graph 2 Graph 2 Graph 1 Graph 1 Graph 2 Graph 2 HPU Time A B C D E A B C D E time Build Launch Build Launch Launch Launch Launch Graph 1 Graph 1 Graph 2 Graph 2 Graph 1 Graph 2 Graph 1 A B C D E A B C D E A B C Time saved Time saved Habana Labs – Confidential Information 27
28 . The End Thank you for your time! Habana Labs – Confidential Information 28
29 .Habana Labs – Confidential Information 29
3秒后跳转登录页面
去登陆

