
















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
1.基于Intel-AlphaFold2实现高通量和超长序列蛋白结构解析-杨威
基于AVX512高位宽优势和TB级内存支持,英特尔至强可扩展处理器拓展了AlphaFold2的两方面能力:
- 针对短序列可实现单节点高通量推理优化,加快了蛋白组学结构分析进程;
- 可以完成>4000aa超长样本的预测,扩大了AlphaFold2的蛋白结构探索范围。
杨威,英特尔人工智能方案架构师。北京大学生命科学博士,曾在饶毅实验室基于ML/DL模型辅助研究睡眠,现在Intel从事AI和GPU的售前技术支持。
展开查看详情
1 .基于 Intel-AlphaFold2 辅助 高通量和长序列蛋白结构解析 杨威 Intel SMG AI TSS
2 .Part 1 蛋白预测 Intel AI TSS, Beijing 杨威
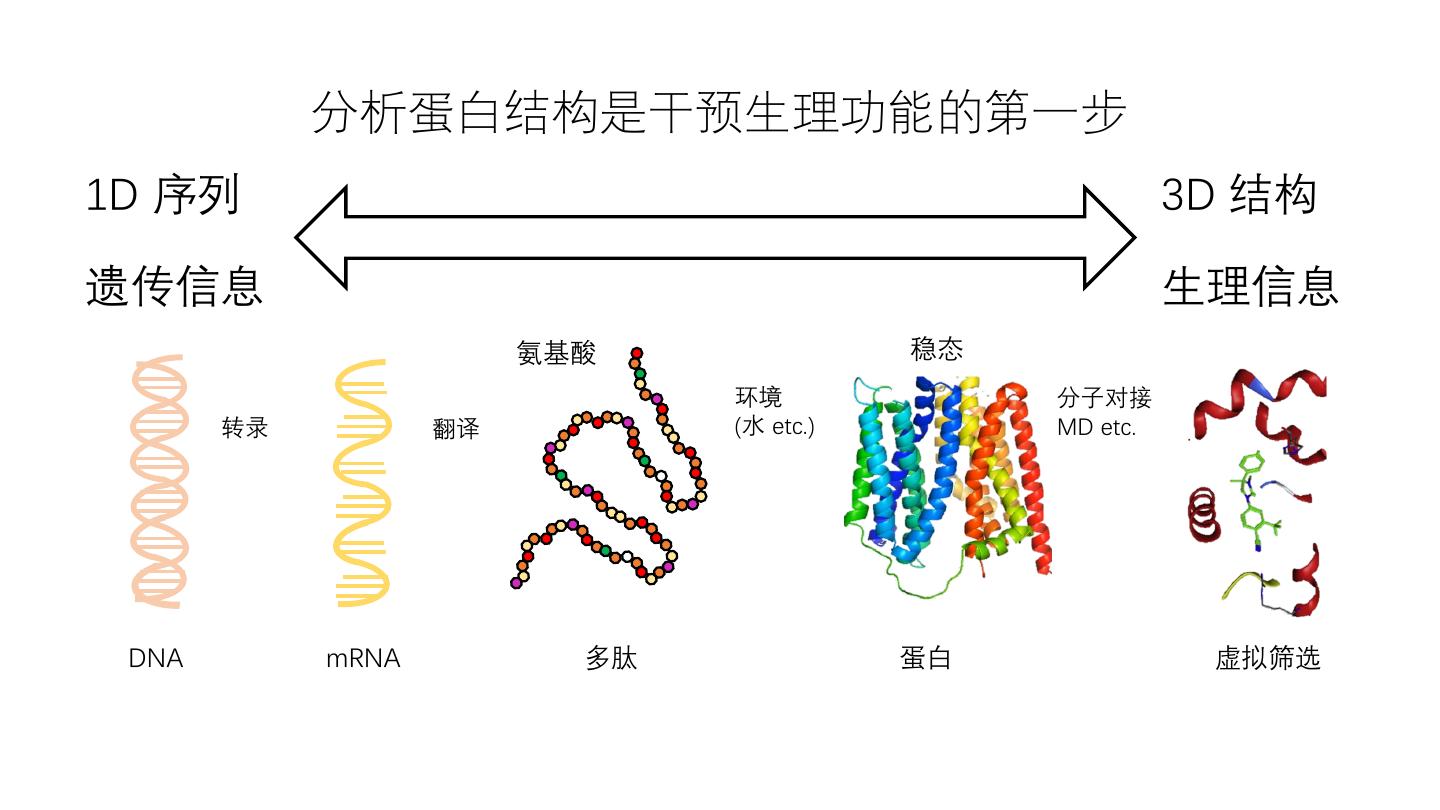
3 . 分析蛋白结构是干预生理功能的第一步 1D 序列 3D 结构 遗传信息 生理信息 氨基酸 稳态 环境 分子对接 转录 翻译 (水 etc.) MD etc. DNA mRNA 多肽 蛋白 虚拟筛选
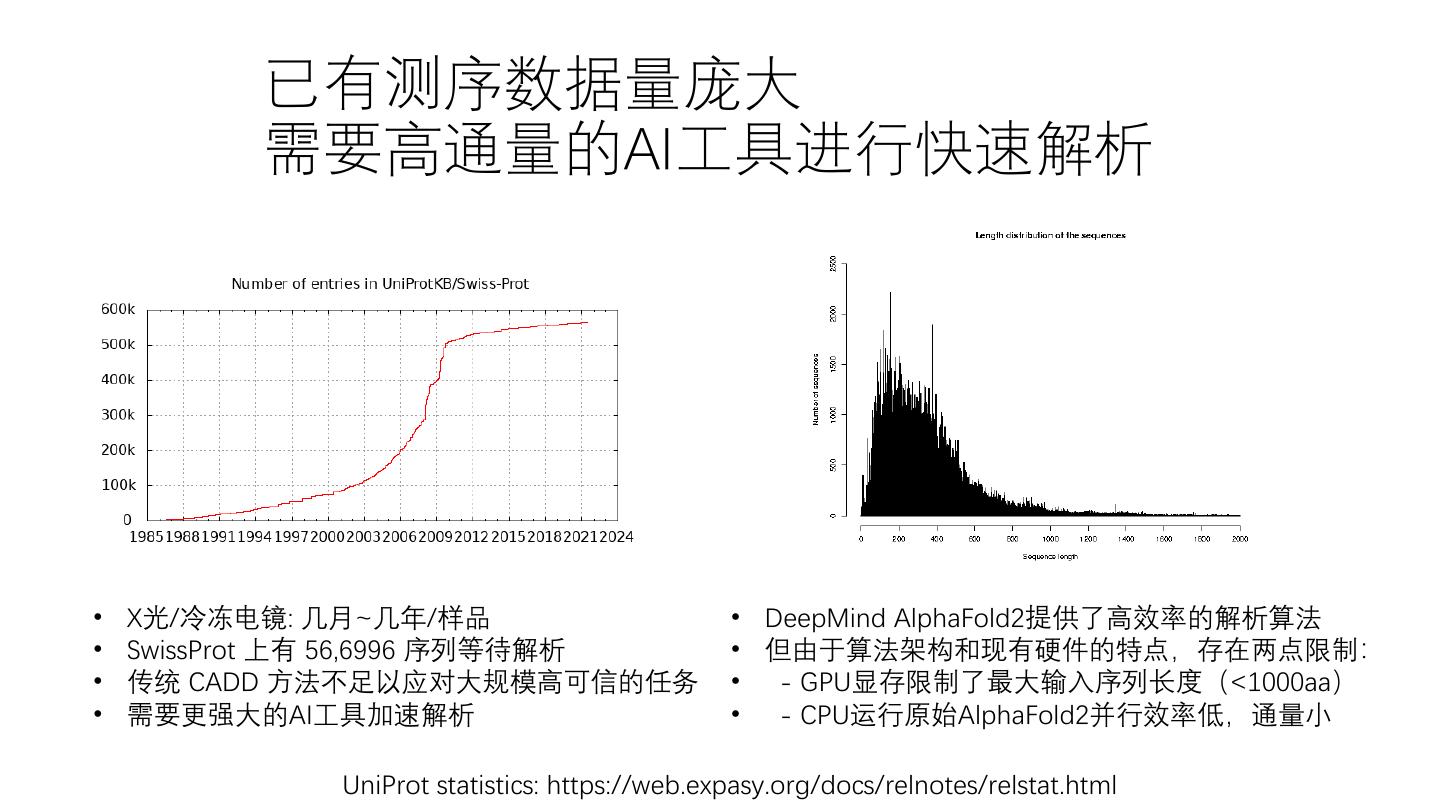
4 . 已有测序数据量庞大 需要高通量的AI工具进行快速解析 • X光/冷冻电镜: 几月~几年/样品 • DeepMind AlphaFold2提供了高效率的解析算法 • SwissProt 上有 56,6996 序列等待解析 • 但由于算法架构和现有硬件的特点,存在两点限制: • 传统 CADD 方法不足以应对大规模高可信的任务 • - GPU显存限制了最大输入序列长度(<1000aa) • 需要更强大的AI工具加速解析 • - CPU运行原始AlphaFold2并行效率低,通量小 UniProt statistics: https://web.expasy.org/docs/relnotes/relstat.html
5 .Part 2 提高通量 Intel AI TSS, Beijing 杨威
6 . Intel-AlphaFold2 优化效果 推理通量 (samples per day, 序列长度 = 765 *1 至强 ICX8358 • 基于至强可扩展处理器的Intel-AlphaFold2 推理管线 (精度 FP32) • AlphaFold2 是药物设计领域的突破性成果 • Intel架构为 AlphaFold2 通量带来 23.11x 提升 • 5.05x 源自模型和op优化 • 4.56x 源自傲腾 PMem TB级内存支持 性能声明 工作负载、配置信息见附页 "Performance Test System Configurations". 实际性能受使用情况、配置和其他因素的差异影响,结果可能不同。 更多信息请见www.Intel.com/PerformanceIndex。
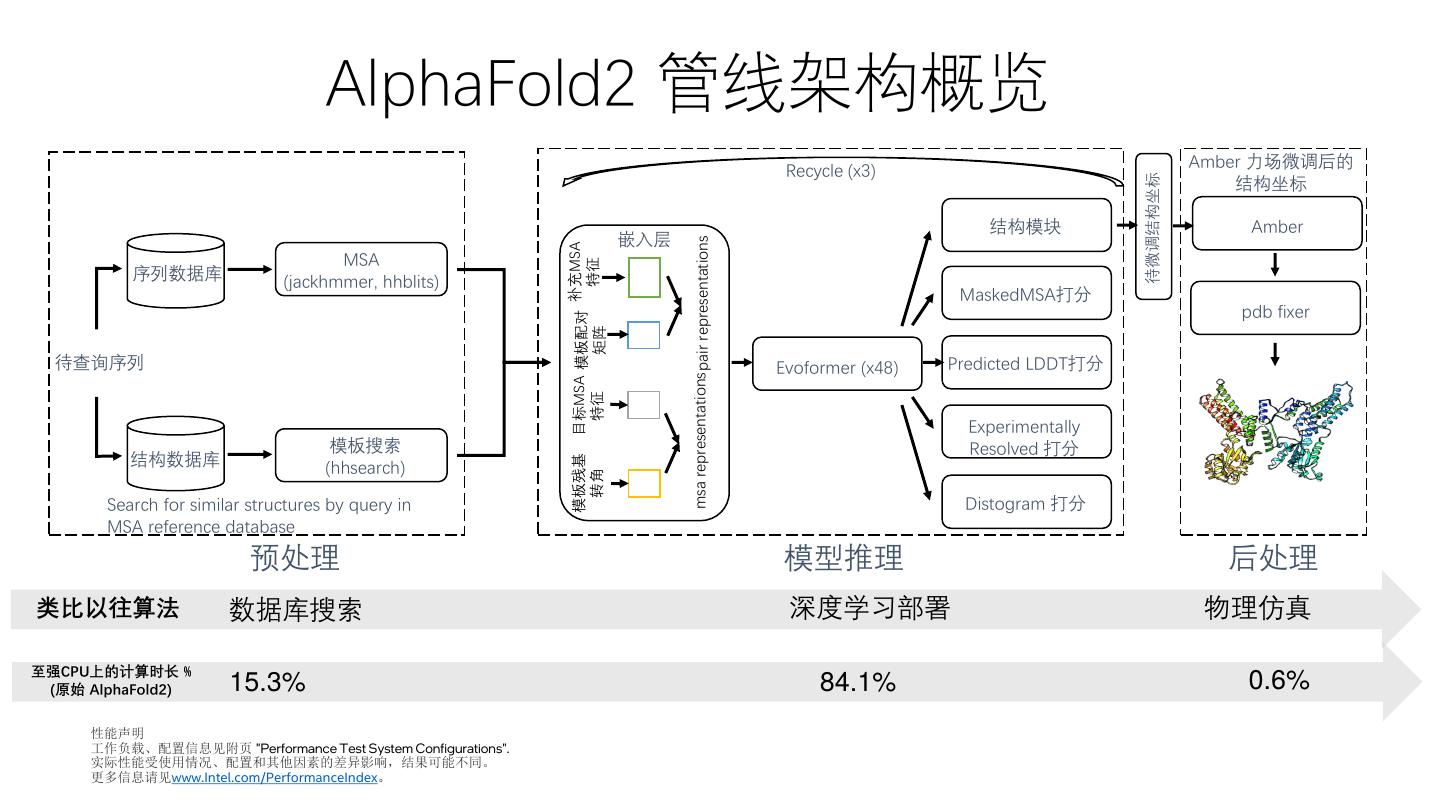
7 . AlphaFold2 管线架构概览 Recycle (x3) Amber 力场微调后的 待微调结构坐标 结构坐标 结构模块 Amber 嵌入层 msa representations pair representations 目标MSA 模板配对 补充MSA MSA 特征 序列数据库 (jackhmmer, hhblits) MaskedMSA打分 pdb fixer 矩阵 待查询序列 Evoformer (x48) Predicted LDDT打分 特征 Experimentally 模板搜索 Resolved 打分 结构数据库 模板残基 (hhsearch) 转角 Search for similar structures by query in Distogram 打分 MSA reference database 预处理 模型推理 后处理 类比以往算法 数据库搜索 深度学习部署 物理仿真 至强CPU上的计算时长 % (原始 AlphaFold2) 15.3% 84.1% 0.6% 性能声明 工作负载、配置信息见附页 "Performance Test System Configurations". 实际性能受使用情况、配置和其他因素的差异影响,结果可能不同。 更多信息请见www.Intel.com/PerformanceIndex。
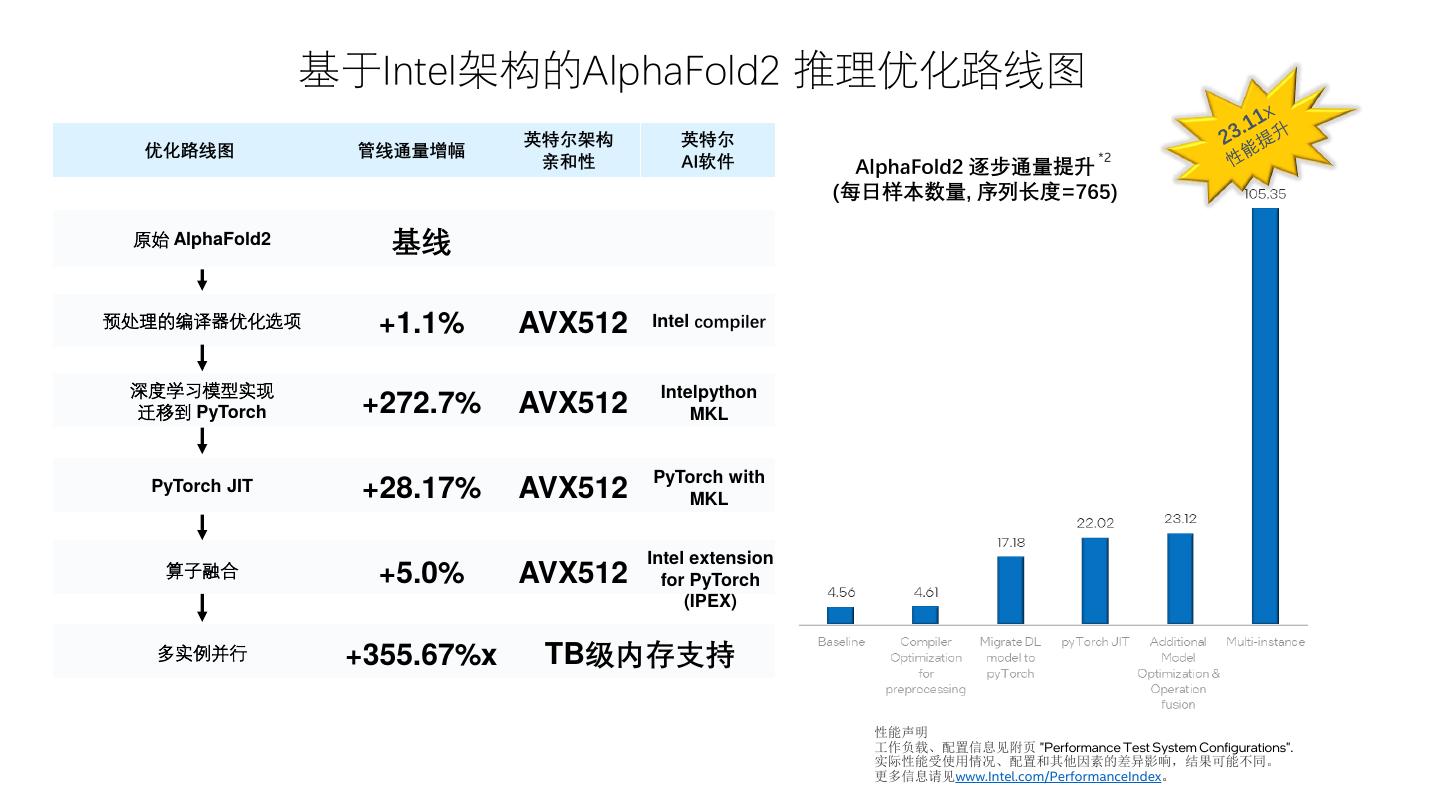
8 . 基于Intel架构的AlphaFold2 推理优化路线图 英特尔架构 英特尔 优化路线图 管线通量增幅 *2 亲和性 AI软件 AlphaFold2 逐步通量提升 (每日样本数量, 序列长度=765) 原始 AlphaFold2 基线 预处理的编译器优化选项 +1.1% AVX512 Intel compiler 深度学习模型实现 Intelpython 迁移到 PyTorch +272.7% AVX512 MKL PyTorch with PyTorch JIT +28.17% AVX512 MKL Intel extension 算子融合 +5.0% AVX512 for PyTorch (IPEX) 多实例并行 +355.67%x TB级内存支持 性能声明 工作负载、配置信息见附页 "Performance Test System Configurations". 实际性能受使用情况、配置和其他因素的差异影响,结果可能不同。 更多信息请见www.Intel.com/PerformanceIndex。
9 . Alphafold2 预处理的优化策略 基于SIMD的性能提升 ▪ 利用 AVX512 提升MSA和模板搜索通量 (加入 Intel®Compiler icc 选项) ▪ -O2, -O3 ▪ -no-prec-div ▪ -march=icelake-server https://www.intel.com/content/www/us/en/developer/tools/oneapi/hpc-toolkit.html
10 . 将 AlphaFold2 深度学习模型迁移至 PyTorch • 原始 AlphaFold2 是基于 JAX 开发的 • 初衷是便于应用 google’s XLA 编译 • 但该框架至今没有基于Intel架构的优化 • 迁移至PyTorch • 手动翻译所有模块 (嵌入层, Evoformer, 头部网络) • 模型准确率评估: <1.63% 输出误差(来自MSA随机误差) • 修正所有函数接口以适应 PyTorch JIT script *4 • 目前以私有代码包的形式递交客户 性能声明 工作负载、配置信息见附页 "Performance Test System Configurations". • 计划在 Intel Model Zoo 开源 实际性能受使用情况、配置和其他因素的差异影响,结果可能不同。 更多信息请见www.Intel.com/PerformanceIndex。
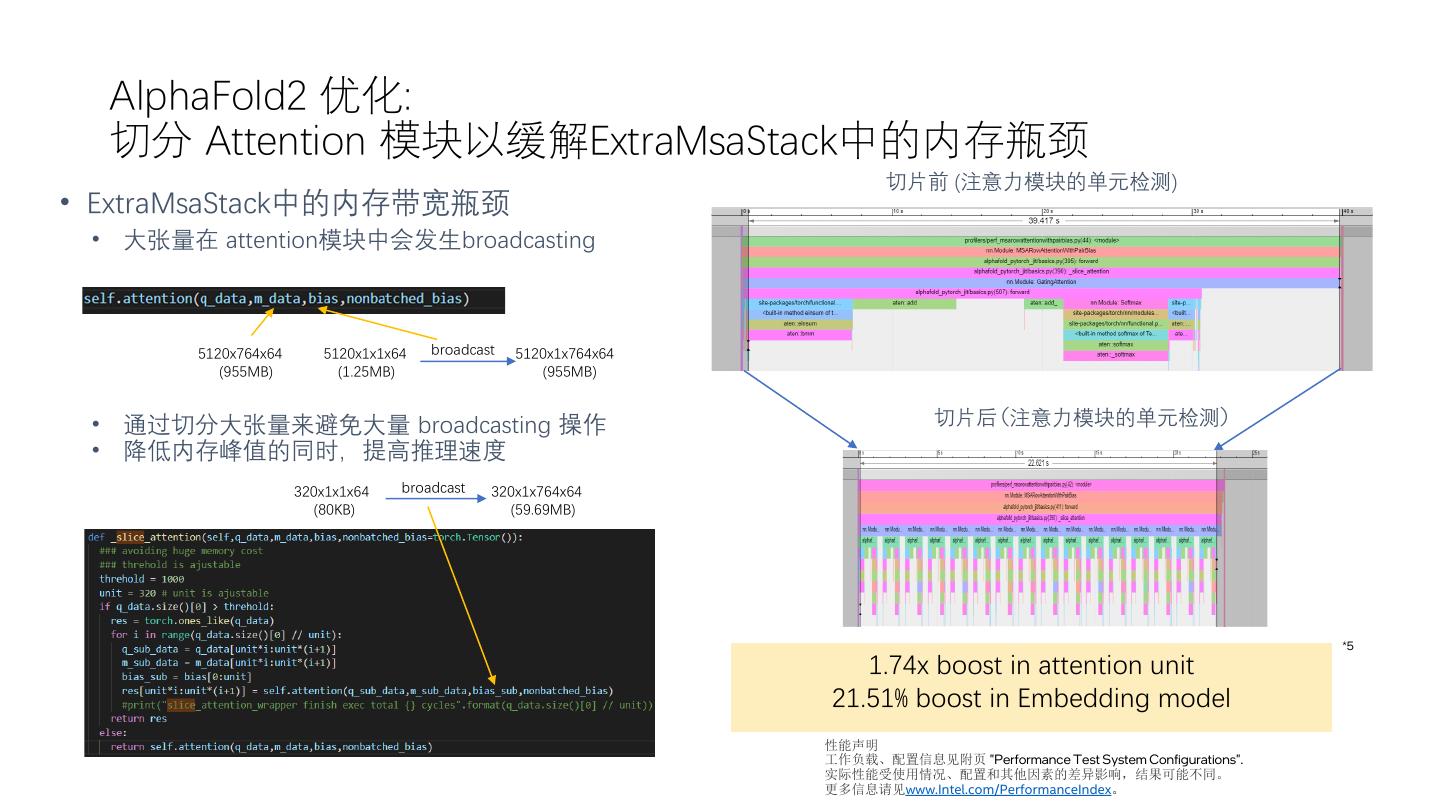
11 . AlphaFold2 优化: 切分 Attention 模块以缓解ExtraMsaStack中的内存瓶颈 切片前 (注意力模块的单元检测) • ExtraMsaStack中的内存带宽瓶颈 • 大张量在 attention模块中会发生broadcasting 5120x764x64 5120x1x1x64 broadcast 5120x1x764x64 (955MB) (1.25MB) (955MB) • 通过切分大张量来避免大量 broadcasting 操作 切片后 (注意力模块的单元检测) • 降低内存峰值的同时,提高推理速度 320x1x1x64 broadcast 320x1x764x64 (80KB) (59.69MB) *5 1.74x boost in attention unit 21.51% boost in Embedding model 性能声明 工作负载、配置信息见附页 "Performance Test System Configurations". 实际性能受使用情况、配置和其他因素的差异影响,结果可能不同。 更多信息请见www.Intel.com/PerformanceIndex。
12 .AlphaFold2 优化: 融合 Einsum 和 Add Operations in Evoformer Evoformer 模块 • Einsum+Add op融合 • 在 IPEX1.11.100 (oneDNN 2.6) 及以上版本中已有支持 Before fusion (unit test) After fusion (unit test) *6 Large Tenors (~140MB per tensor) Einsum+Add op 在单元检测中提升 6.03x 性能 Evoformer模块 10.02% boost 5.0% boost in AlphaFold2 pipeline 性能声明 Add with broadcasting 工作负载、配置信息见附页 "Performance Test System Configurations". 实际性能受使用情况、配置和其他因素的差异影响,结果可能不同。 Batch Matrix Multiplication(BMM) 更多信息请见www.Intel.com/PerformanceIndex。
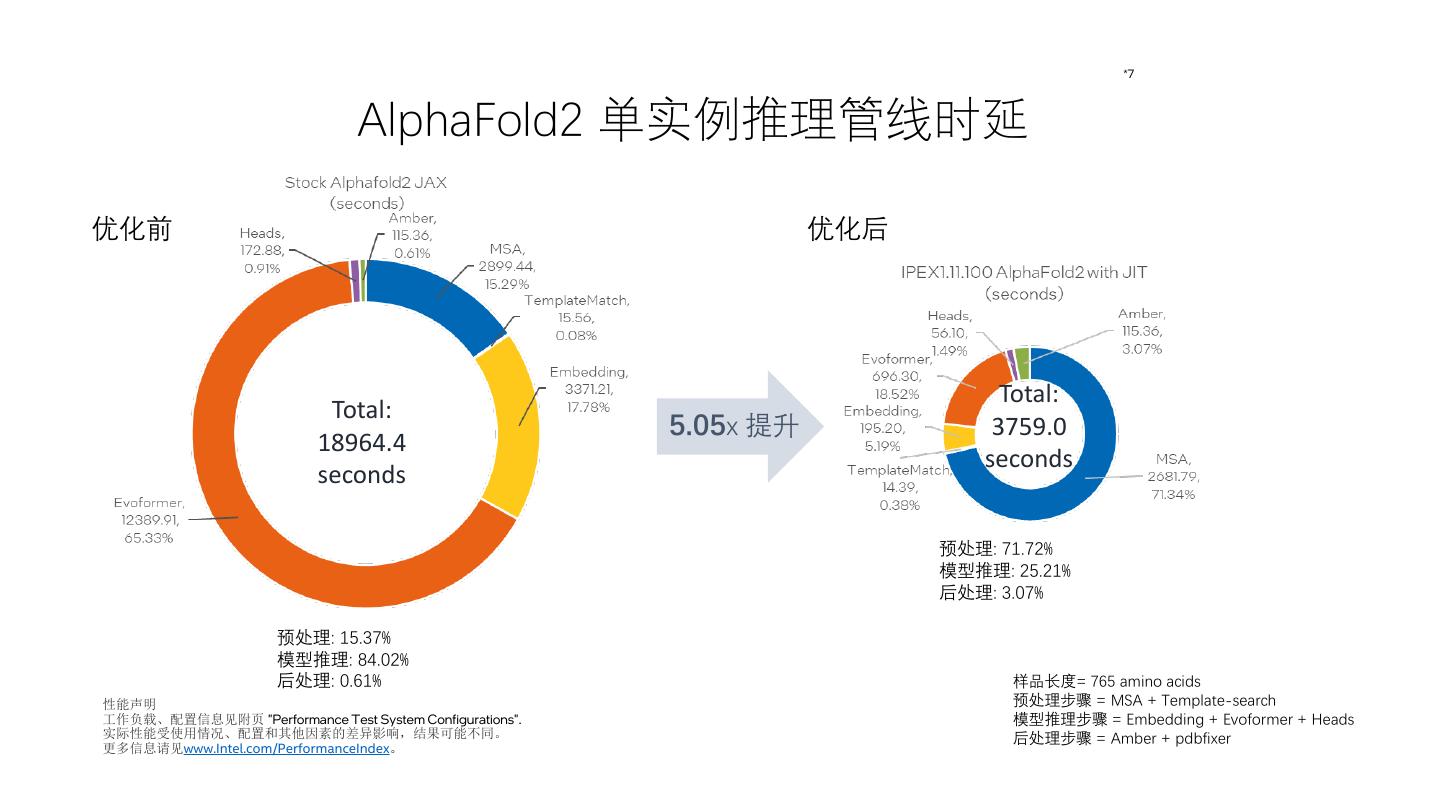
13 . *7 AlphaFold2 单实例推理管线时延 优化前 优化后 Total: Total: 5.05x 提升 3759.0 18964.4 seconds seconds 预处理: 71.72% 模型推理: 25.21% 后处理: 3.07% 预处理: 15.37% 模型推理: 84.02% 后处理: 0.61% 样品长度= 765 amino acids 性能声明 预处理步骤 = MSA + Template-search 工作负载、配置信息见附页 "Performance Test System Configurations". 模型推理步骤 = Embedding + Evoformer + Heads 实际性能受使用情况、配置和其他因素的差异影响,结果可能不同。 后处理步骤 = Amber + pdbfixer 更多信息请见www.Intel.com/PerformanceIndex。
14 .Part 3 扩大范围 Intel AI TSS, Beijing 杨威
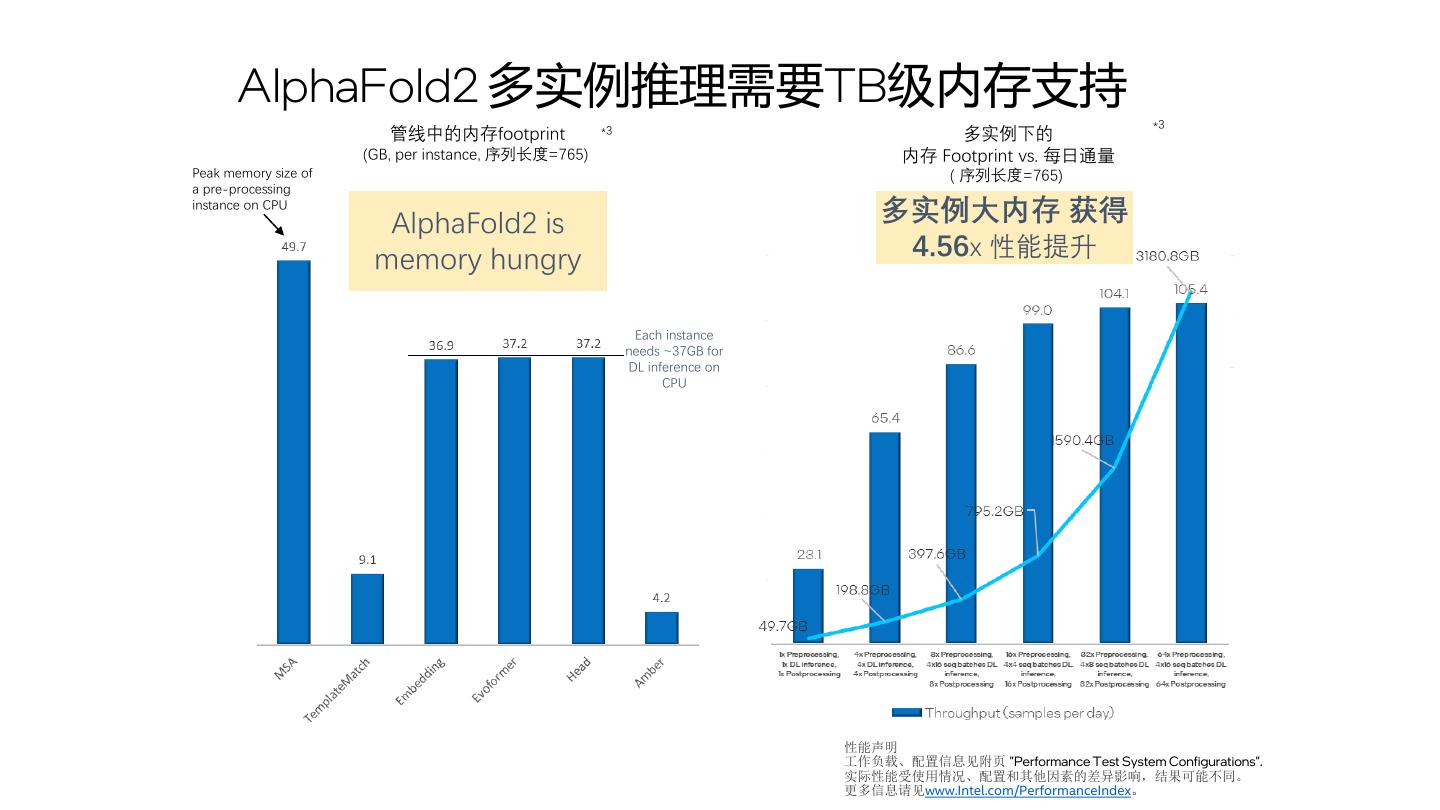
15 . AlphaFold2 多实例推理需要TB级内存支持 *3 *3 管线中的内存footprint 多实例下的 (GB, per instance, 序列长度=765) 内存 Footprint vs. 每日通量 Peak memory size of ( 序列长度=765) a pre-processing instance on CPU AlphaFold2 is 多实例大内存 获得 memory hungry 4.56x 性能提升 Each instance needs ~37GB for DL inference on CPU 性能声明 工作负载、配置信息见附页 "Performance Test System Configurations". 实际性能受使用情况、配置和其他因素的差异影响,结果可能不同。 更多信息请见www.Intel.com/PerformanceIndex。
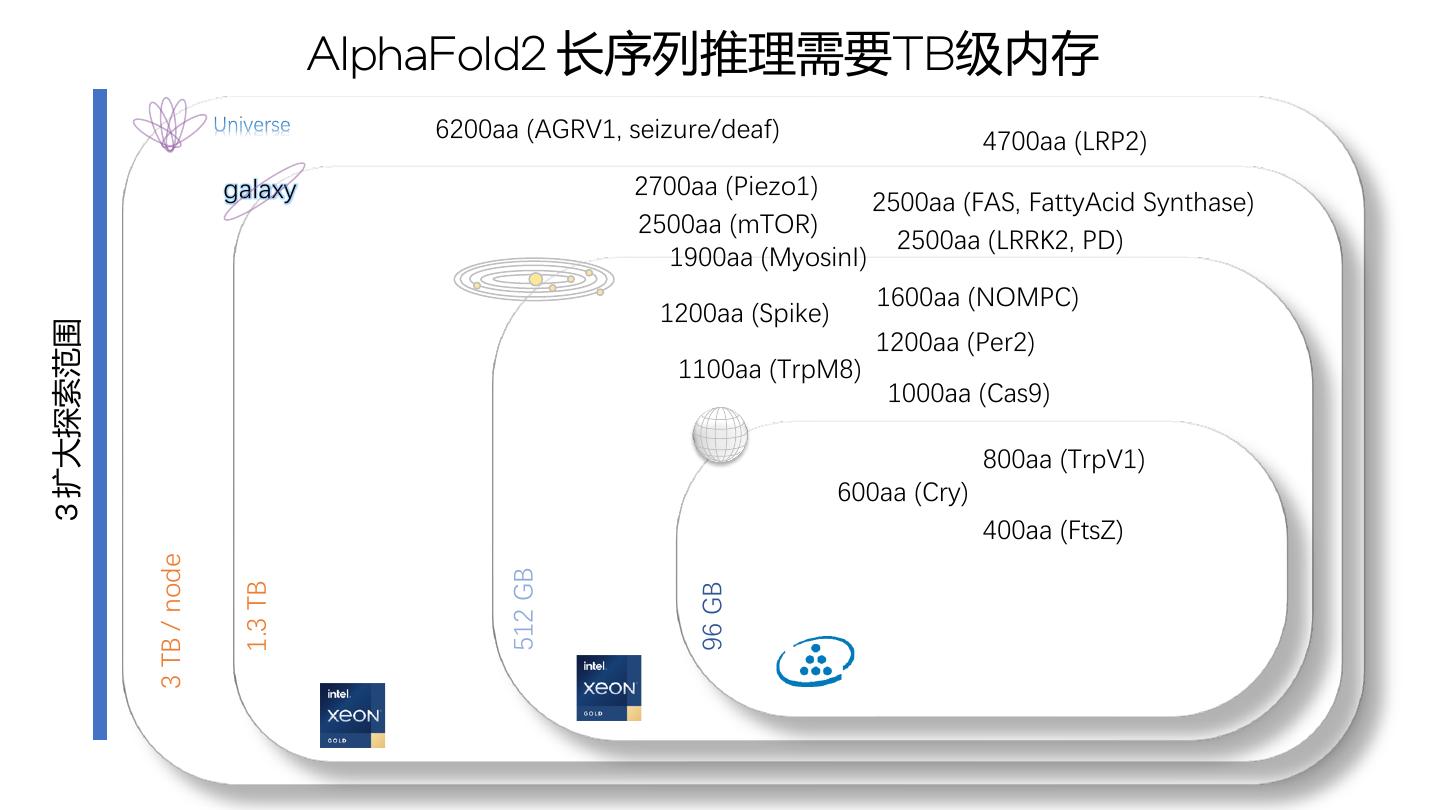
16 . AlphaFold2 长序列推理需要TB级内存 6200aa (AGRV1, seizure/deaf) 4700aa (LRP2) galaxy 2700aa (Piezo1) 2500aa (FAS, FattyAcid Synthase) 2500aa (mTOR) 2500aa (LRRK2, PD) 1900aa (MyosinI) 1600aa (NOMPC) 1200aa (Spike) 3 扩大探索范围 1200aa (Per2) 1100aa (TrpM8) 1000aa (Cas9) 800aa (TrpV1) 600aa (Cry) 400aa (FtsZ) 3 TB / node 512 GB 1.3 TB 96 GB
17 . 至强CPU集群可以实现线性扩展 *9 ▪ 客户需要使用集群完成业务扩展,以达到预期的高通量预测 datasets storage Intel® Xeon Intel® Xeon Intel® Xeon Scalable Processor Scalable Processor …… Scalable Processor 2 sockets system 2 sockets system 2 sockets system Compute/Worker nodes – Xeon SP Workers connectivity– IB/100G for large scale, 10/25GbE for small scale 性能声明 Storage and management Connectivity – 10/25/40/100GbE 工作负载、配置信息见附页 "Performance Test System Configurations". 实际性能受使用情况、配置和其他因素的差异影响,结果可能不同。 Storage Cluster – NFS/Lustre/GlusterFS/Ceph 更多信息请见www.Intel.com/PerformanceIndex。 Containers – Singularity Schedulers – PBS/SLURM ▪ mpirun -np $total_instances –ppn $instance_num --bind-to core:PE=1 --map-by socket --host $hostlist $cmd *1 Based on amino acids length=361 performance data *2 Based on Inspur system configuration/price on previous page
18 .Part 4下游探讨 Intel AI TSS, Beijing 杨威
19 . Orphan Protein 不同源但同结构 Z. M. Lin et al. bioRxiv 2022 X. M. Fang et al. arxiv 2022 1 去掉MSA,用蛋白表征模型代劳保守信息的特征输入 ESMFold: R. D. Wu et al. bioRxiv 2022 https://www.biorxiv.org/content/10.1101/2022.07.20.500902v1.full.pdf HelixFold-Single: ESMFold https://github.com/PaddlePaddle/PaddleHelix/tree/dev/apps/protein_folding/helixfold-single OmegaFold: HelixFold-Single https://github.com/HeliXonProtein/OmegaFold OmegaFold 2 利用结构相似性寻找同结构的蛋白 M. v. Kempen et al. bioRxiv 2022 Foldseek: https://github.com/steineggerlab/foldseek Z. M. Lin et al. bioRxiv 2022 3 利用降维、聚类等方法进行结构分组 UMAP: https://github.com/lmcinnes/umap Foldseek UMAP
20 . 按结构变化设计蛋白 Y. Zhang et al. bioRxiv 2021 4 点突变与结构稳定性变化: 点突变-稳定性 ProdCoNN + AlphaFold2 + Sequential MC: https://www.biorxiv.org/content/10.1101/2021.11.03.467194v2 5 蛋白幻想:自编码产生随机序列 A. Anishchico et al. Nature 2021 Fold + 对比学习(代理任务MCMC): https://github.com/gjoni/trDesign 幻想 AlphaFold-based Hallucination ColabDesign: https://github.com/sokrypton/ColabDesign
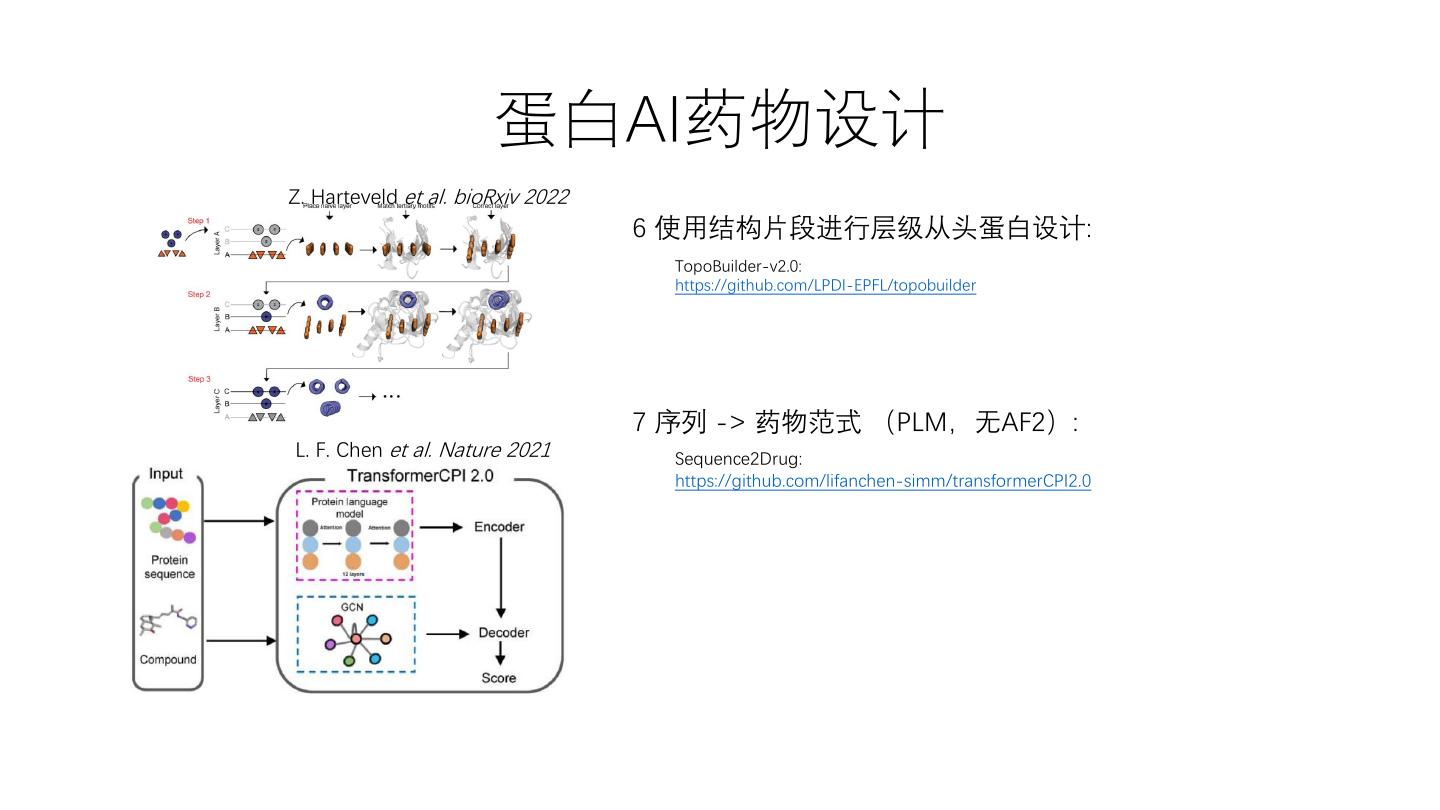
21 . 蛋白AI药物设计 Z. Harteveld et al. bioRxiv 2022 6 使用结构片段进行层级从头蛋白设计: TopoBuilder-v2.0: https://github.com/LPDI-EPFL/topobuilder 7 序列 -> 药物范式 (PLM,无AF2): L. F. Chen et al. Nature 2021 Sequence2Drug: https://github.com/lifanchen-simm/transformerCPI2.0
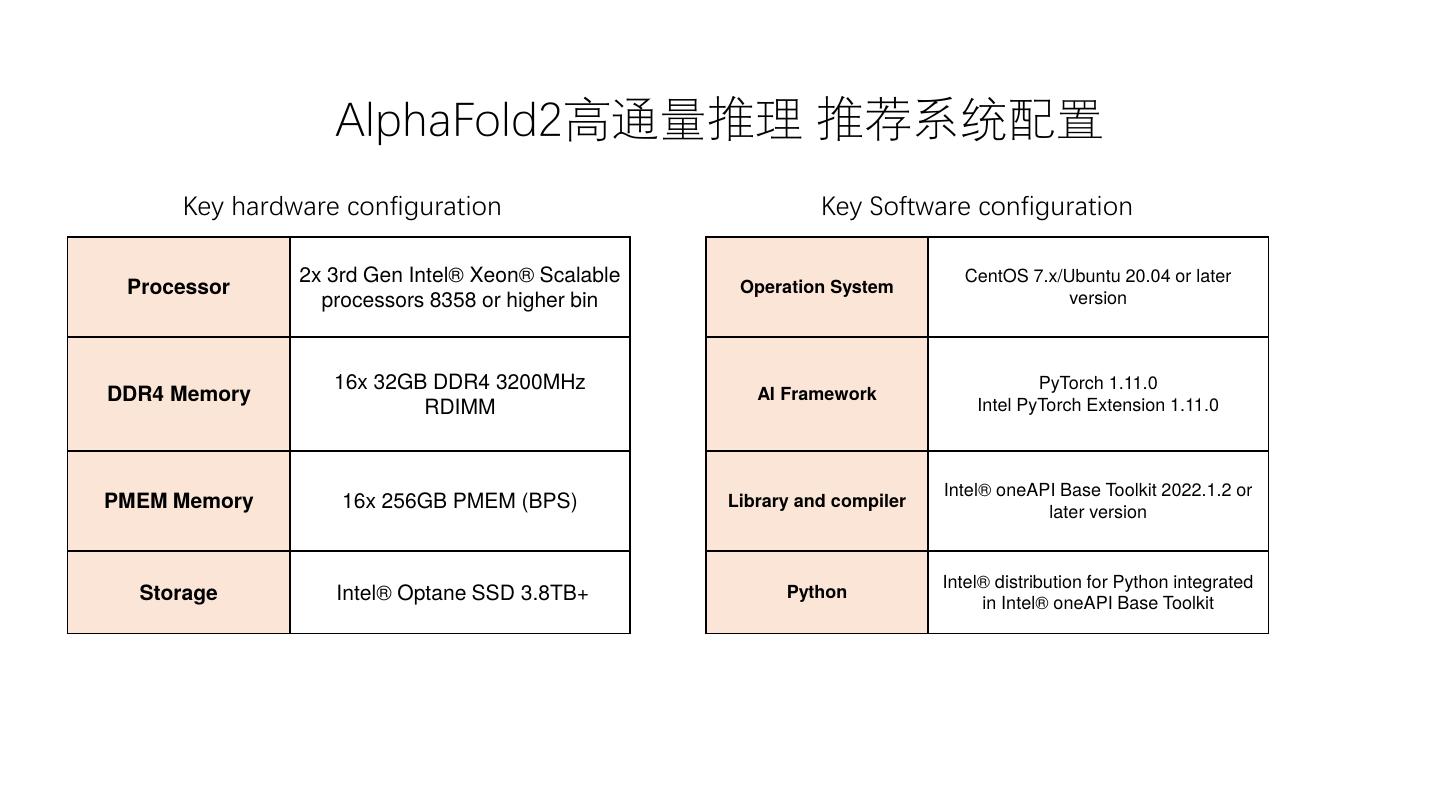
22 . AlphaFold2高通量推理 推荐系统配置 Key hardware configuration Key Software configuration 2x 3rd Gen Intel® Xeon® Scalable CentOS 7.x/Ubuntu 20.04 or later Processor Operation System version processors 8358 or higher bin 16x 32GB DDR4 3200MHz PyTorch 1.11.0 DDR4 Memory AI Framework Intel PyTorch Extension 1.11.0 RDIMM Intel® oneAPI Base Toolkit 2022.1.2 or PMEM Memory 16x 256GB PMEM (BPS) Library and compiler later version Intel® distribution for Python integrated Storage Intel® Optane SSD 3.8TB+ Python in Intel® oneAPI Base Toolkit
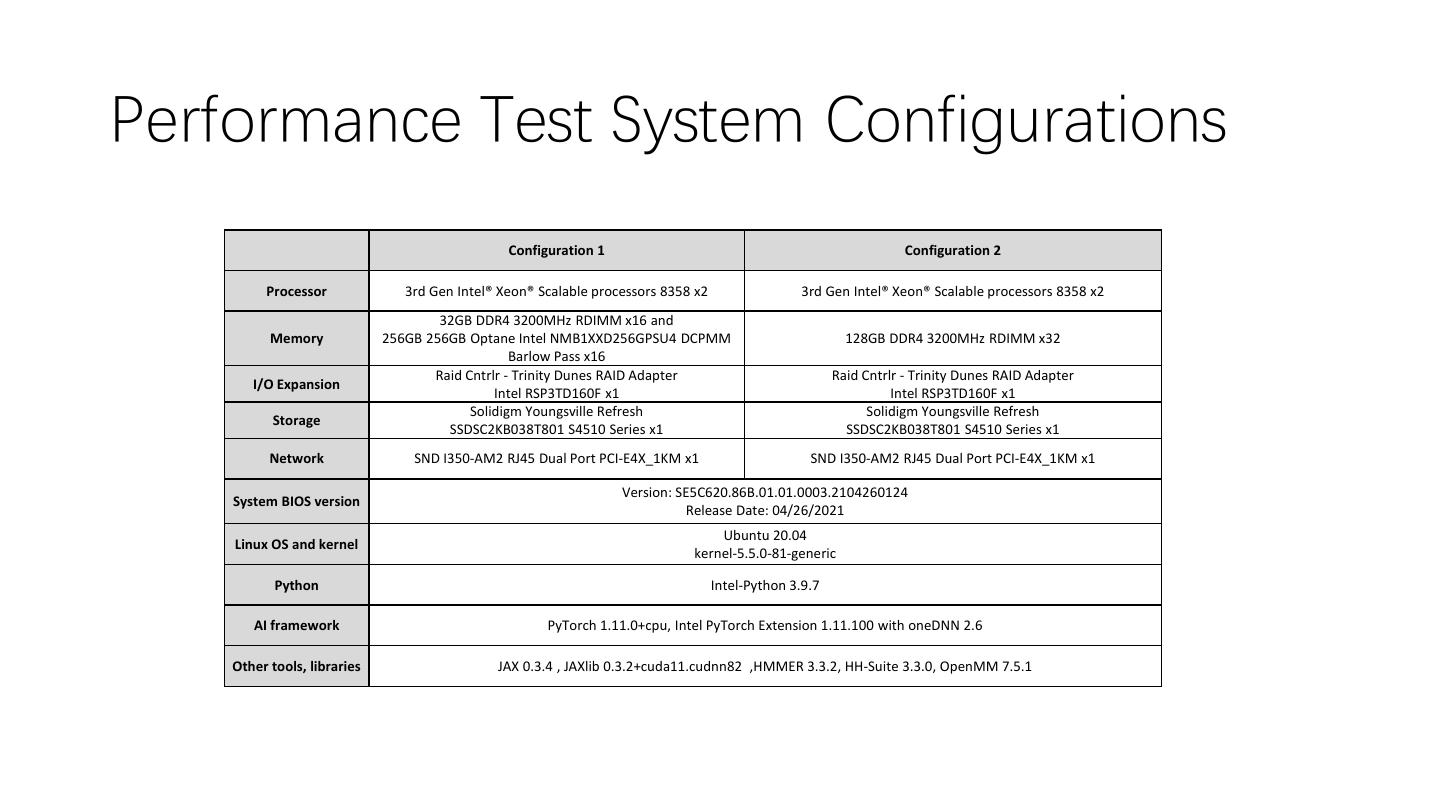
23 .Performance Test System Configurations Configuration 1 Configuration 2 Processor 3rd Gen Intel® Xeon® Scalable processors 8358 x2 3rd Gen Intel® Xeon® Scalable processors 8358 x2 32GB DDR4 3200MHz RDIMM x16 and Memory 256GB 256GB Optane Intel NMB1XXD256GPSU4 DCPMM 128GB DDR4 3200MHz RDIMM x32 Barlow Pass x16 Raid Cntrlr - Trinity Dunes RAID Adapter Raid Cntrlr - Trinity Dunes RAID Adapter I/O Expansion Intel RSP3TD160F x1 Intel RSP3TD160F x1 Solidigm Youngsville Refresh Solidigm Youngsville Refresh Storage SSDSC2KB038T801 S4510 Series x1 SSDSC2KB038T801 S4510 Series x1 Network SND I350-AM2 RJ45 Dual Port PCI-E4X_1KM x1 SND I350-AM2 RJ45 Dual Port PCI-E4X_1KM x1 Version: SE5C620.86B.01.01.0003.2104260124 System BIOS version Release Date: 04/26/2021 Ubuntu 20.04 Linux OS and kernel kernel-5.5.0-81-generic Python Intel-Python 3.9.7 AI framework PyTorch 1.11.0+cpu, Intel PyTorch Extension 1.11.100 with oneDNN 2.6 Other tools, libraries JAX 0.3.4 , JAXlib 0.3.2+cuda11.cudnn82 ,HMMER 3.3.2, HH-Suite 3.3.0, OpenMM 7.5.1
24 . 法律声明 • 所有定价信息仅供参考,实际价格请以您的设备供应商报价为准。 • 实际性能受使用情况、配置和其他因素的差异影响。更多信息请见www.Intel.com/PerformanceIndex。 • 性能测试结果基于配置信息中显示的日期进行测试,且可能并未反映所有公开可用的安全更新。详情请 参阅配置信息披露。没有任何产品或组件是绝对安全的。 • 具体成本和结果可能不同。 • 英特尔技术可能需要启用硬件、软件或激活服务。 • 英特尔未做出任何明示和默示的保证,包括但不限于,关于适销性、适合特定目的及不侵权的默示保证, 以及在履约过程、交易过程或贸易惯例中引起的任何保证。 • 英特尔并不控制或审计第三方数据。请您审查该内容,咨询其他来源,并确认提及数据是否准确。 • © 英特尔公司版权所有。英特尔、英特尔标识以及其他英特尔商标是英特尔公司或其子公司在美国和/或 其他国家的商标
25 .
3秒后跳转登录页面
去登陆

