展开查看详情
1 .已经上线的听众,欢迎加入本场直播的微信讨论群
与讲师交流
�
2 .云上全托管HDFS技术解析
Juicedata,苏锐
2020/12/29
�
3 . 大纲
• 公有云大数据存储的选择与差异
• 理想中的大数据存储
• JuiceFS 的架构设计与 HDFS 的异同
• 多应用生态融合
• Recap
• Q&A
�
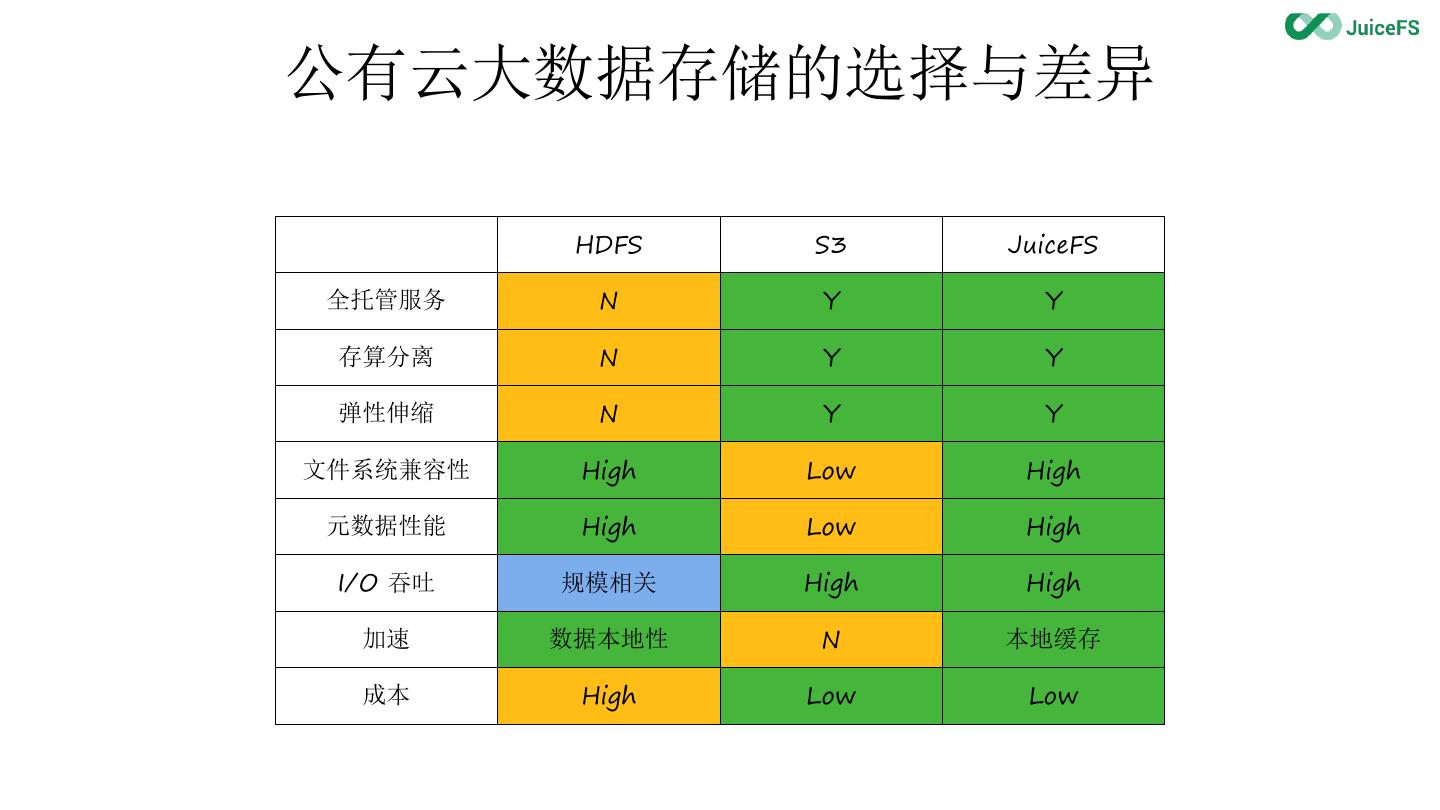
4 .公有云大数据存储的选择与差异
HDFS S3 JuiceFS
全托管服务 N Y Y
存算分离 N Y Y
弹性伸缩 N Y Y
文件系统兼容性 High Low High
元数据性能 High Low High
I/O 吞吐 规模相关 High High
加速 数据本地性 N 本地缓存
成本 High Low Low
�
5 .理想的大数据存储
JuiceFS 的目标
• 全托管服务
• 存储服务的运维是头大的
• 弹性伸缩
• 不用扩容,增效;提升利用率,降本
• 高可用,高性能,海量文件管理
• 大家都需要
• 完整的 POSIX 兼容
�
6 . JuiceFS 的架构设计
先看看 HDFS 的架构设计
ZooKeeper
DataNode1
JournalNode1
JournalNode2 NameNode DataNode2
JournalNode3 DataNode3
NameNode Standby
HDFS Client (JVM)
�
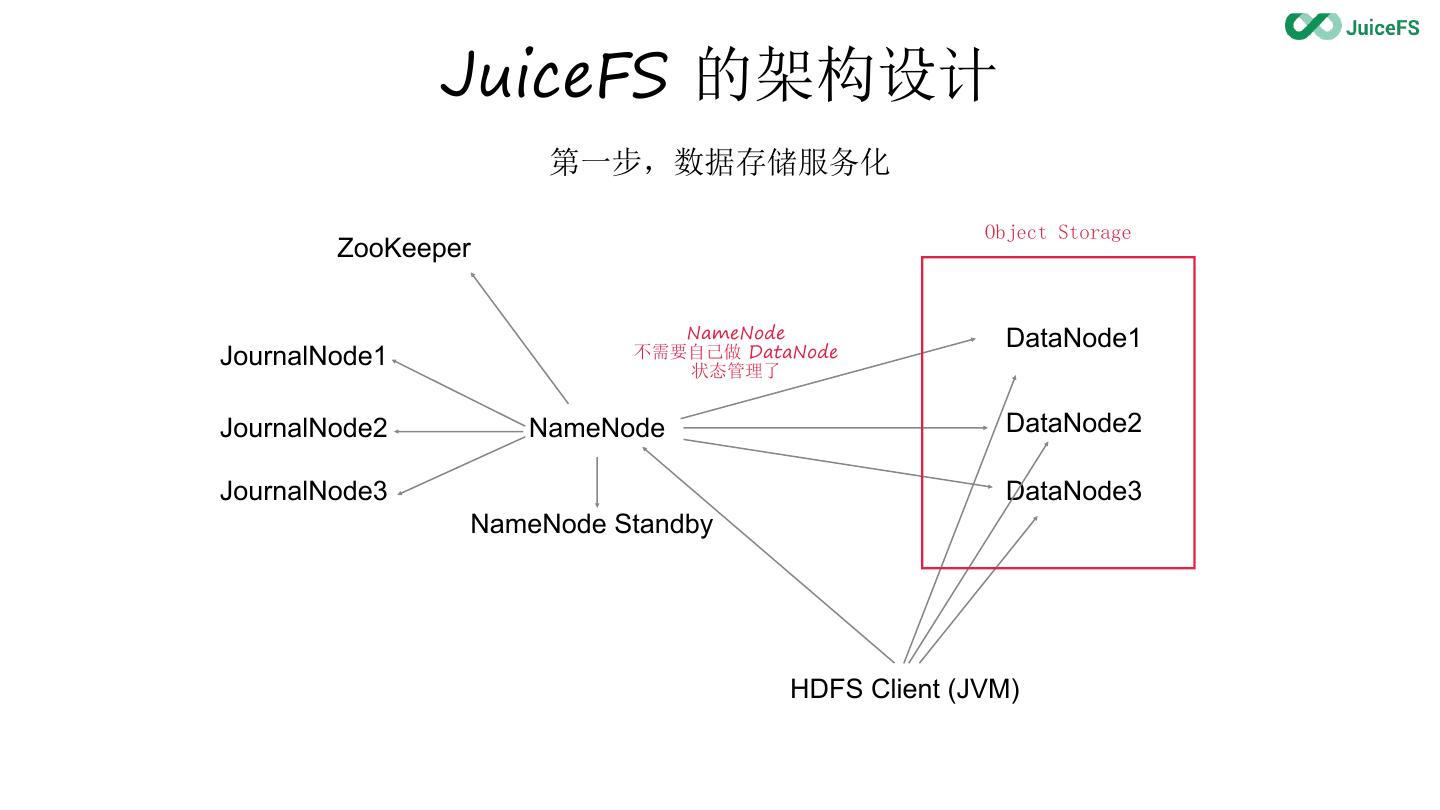
7 . JuiceFS 的架构设计
第一步,数据存储服务化
Object Storage
ZooKeeper
DataNode1
JournalNode1
JournalNode2 NameNode DataNode2
JournalNode3 DataNode3
NameNode Standby
HDFS Client (JVM)
�
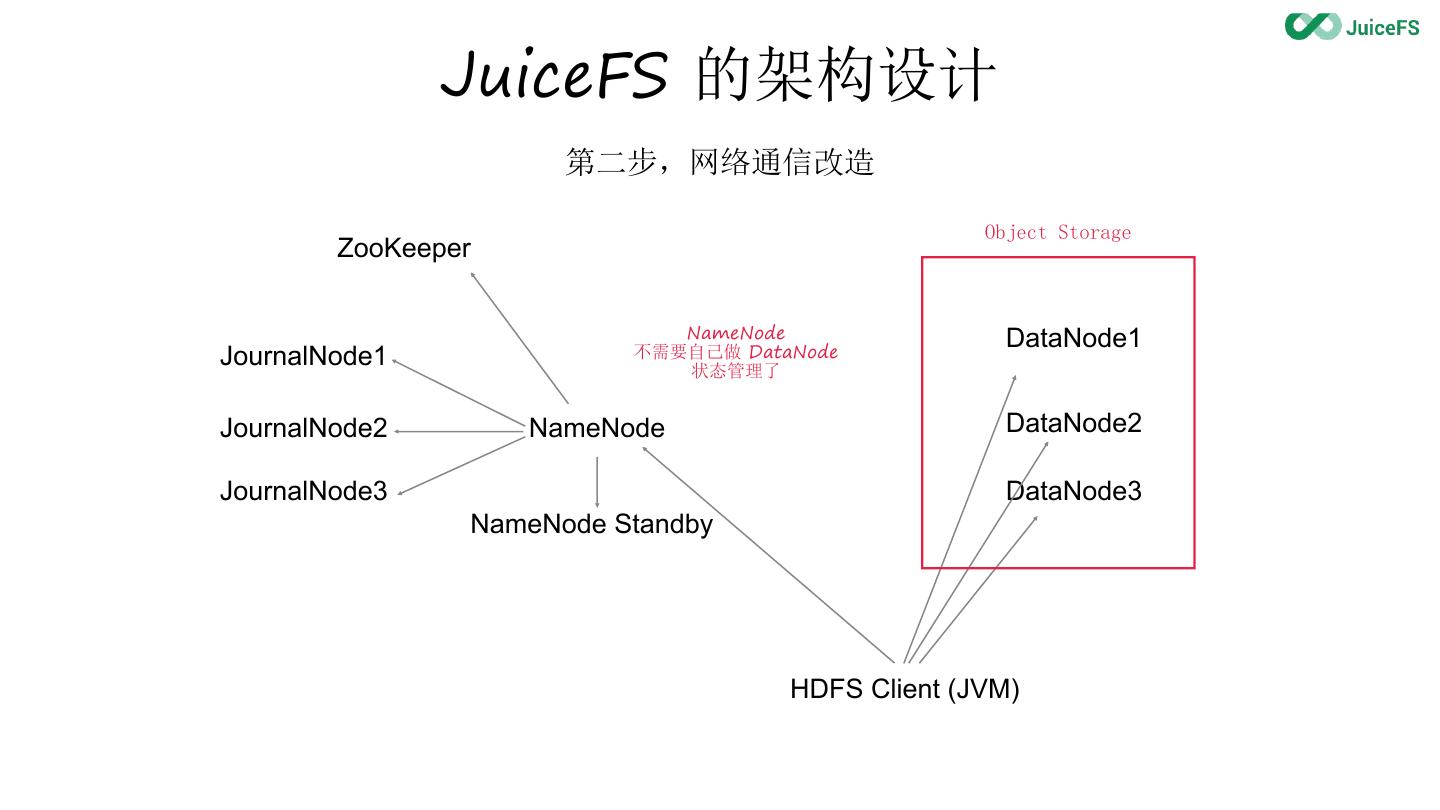
8 . JuiceFS 的架构设计
第一步,数据存储服务化
Object Storage
ZooKeeper
NameNode DataNode1
JournalNode1 不需要自己做 DataNode
状态管理了
JournalNode2 NameNode DataNode2
JournalNode3 DataNode3
NameNode Standby
HDFS Client (JVM)
�
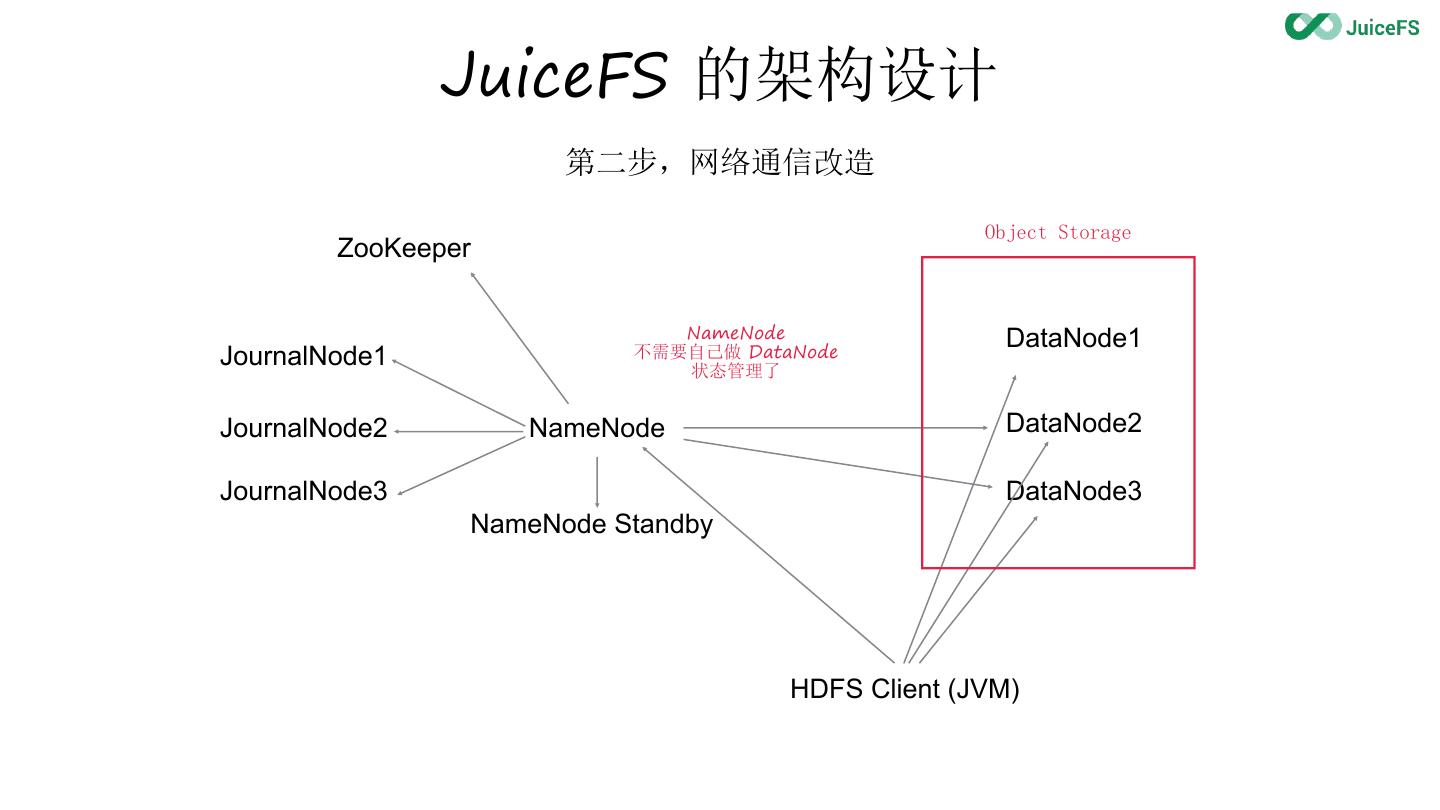
9 . JuiceFS 的架构设计
第二步,网络通信改造
Object Storage
ZooKeeper
NameNode DataNode1
JournalNode1 不需要自己做 DataNode
状态管理了
JournalNode2 NameNode DataNode2
JournalNode3 DataNode3
NameNode Standby
HDFS Client (JVM)
�
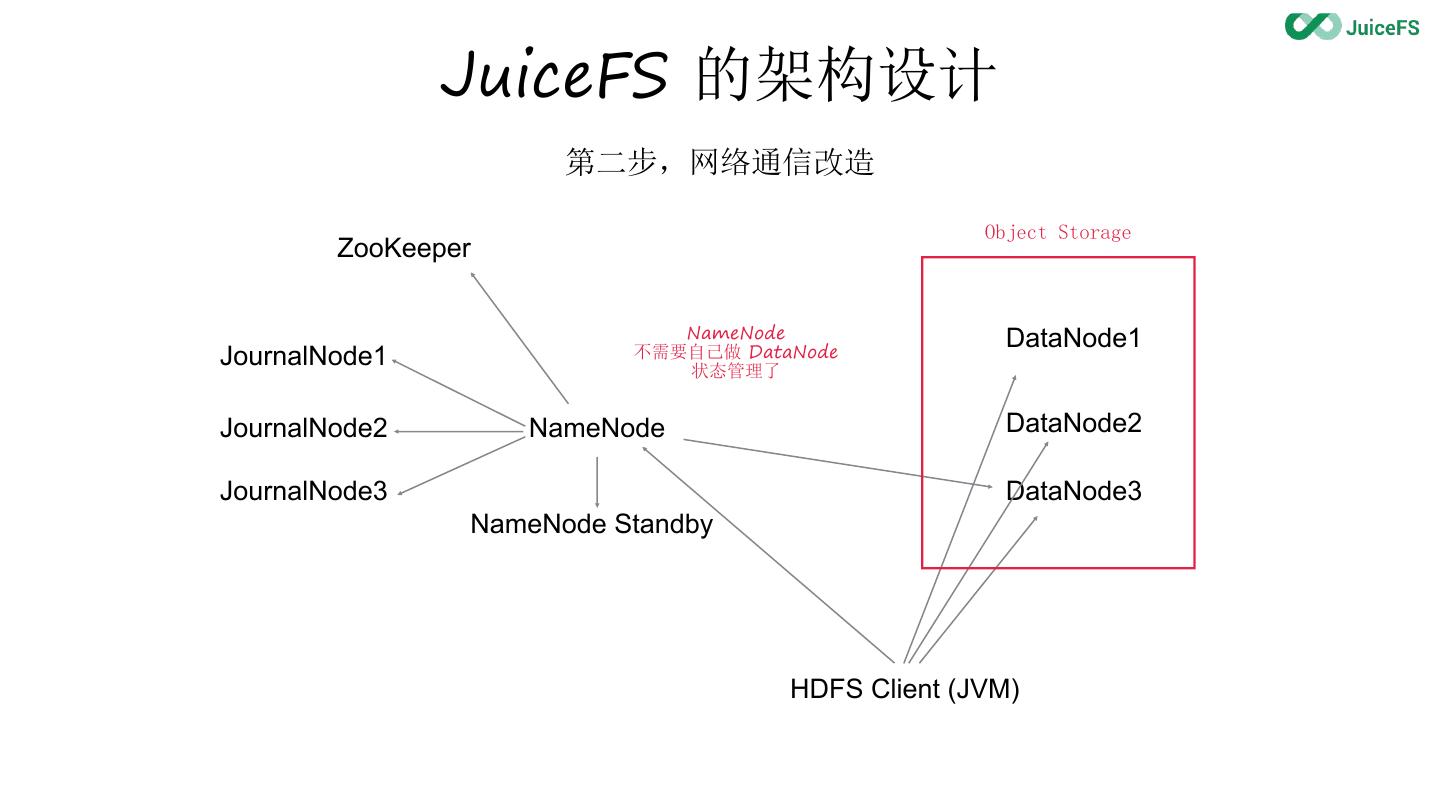
10 . JuiceFS 的架构设计
第二步,网络通信改造
Object Storage
ZooKeeper
NameNode DataNode1
JournalNode1 不需要自己做 DataNode
状态管理了
JournalNode2 NameNode DataNode2
JournalNode3 DataNode3
NameNode Standby
HDFS Client (JVM)
�
11 . JuiceFS 的架构设计
第二步,网络通信改造
Object Storage
ZooKeeper
NameNode DataNode1
JournalNode1 不需要自己做 DataNode
状态管理了
JournalNode2 NameNode DataNode2
JournalNode3 DataNode3
NameNode Standby
HDFS Client (JVM)
�
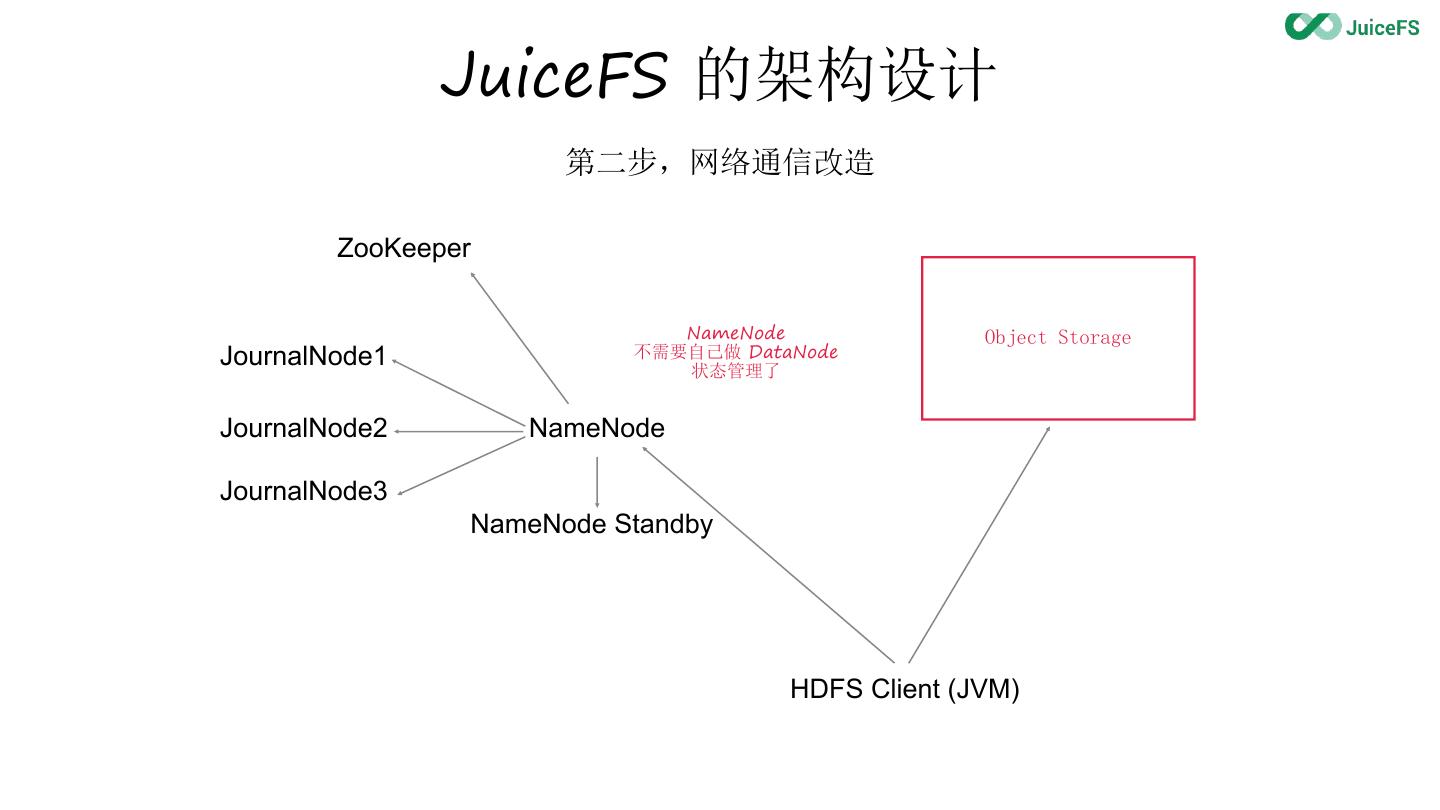
12 . JuiceFS 的架构设计
第二步,网络通信改造
ZooKeeper
NameNode Object Storage
JournalNode1 不需要自己做 DataNode
状态管理了
JournalNode2 NameNode
JournalNode3
NameNode Standby
HDFS Client (JVM)
�
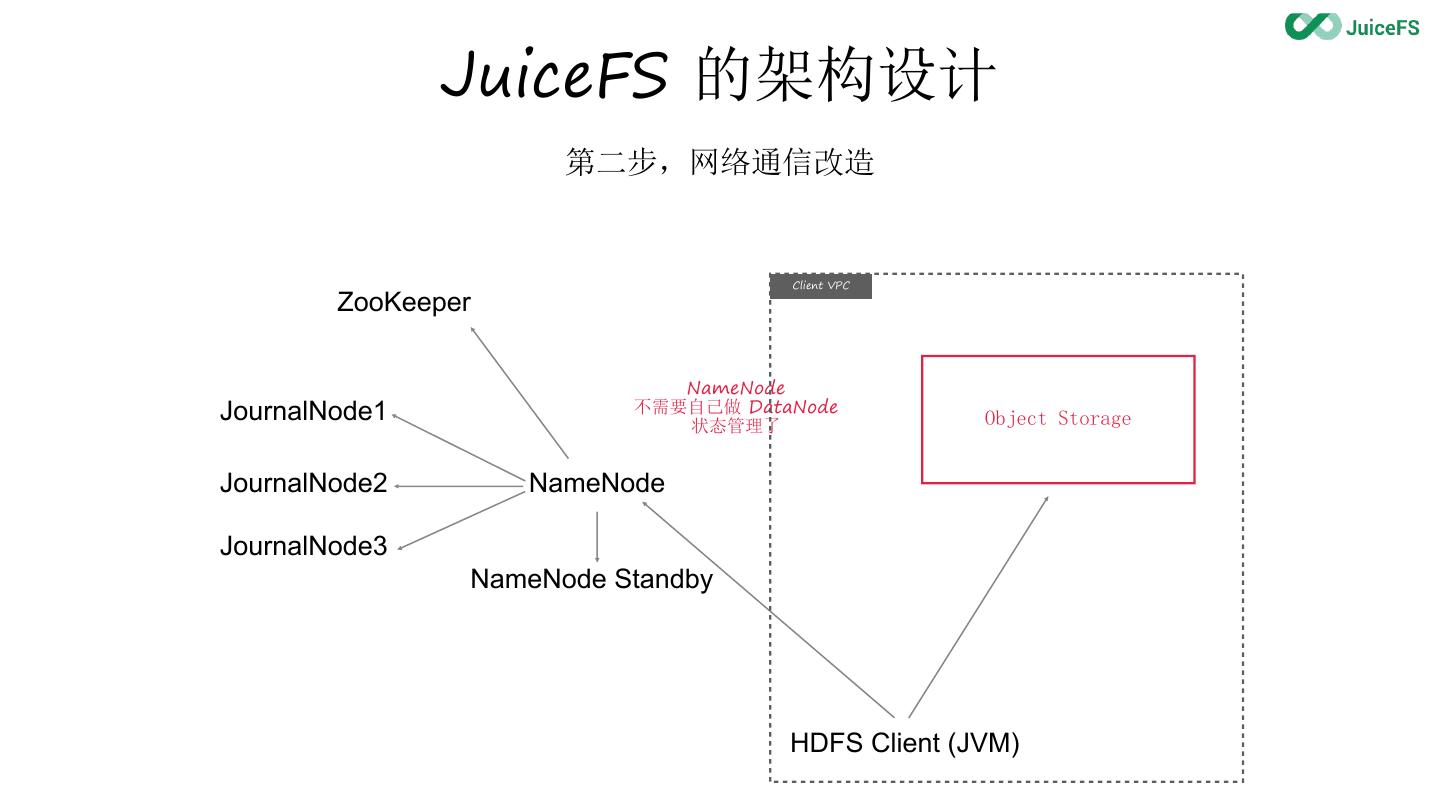
13 . JuiceFS 的架构设计
第二步,网络通信改造
Client VPC
ZooKeeper
NameNode
JournalNode1 不需要自己做 DataNode
状态管理了 Object Storage
JournalNode2 NameNode
JournalNode3
NameNode Standby
HDFS Client (JVM)
�
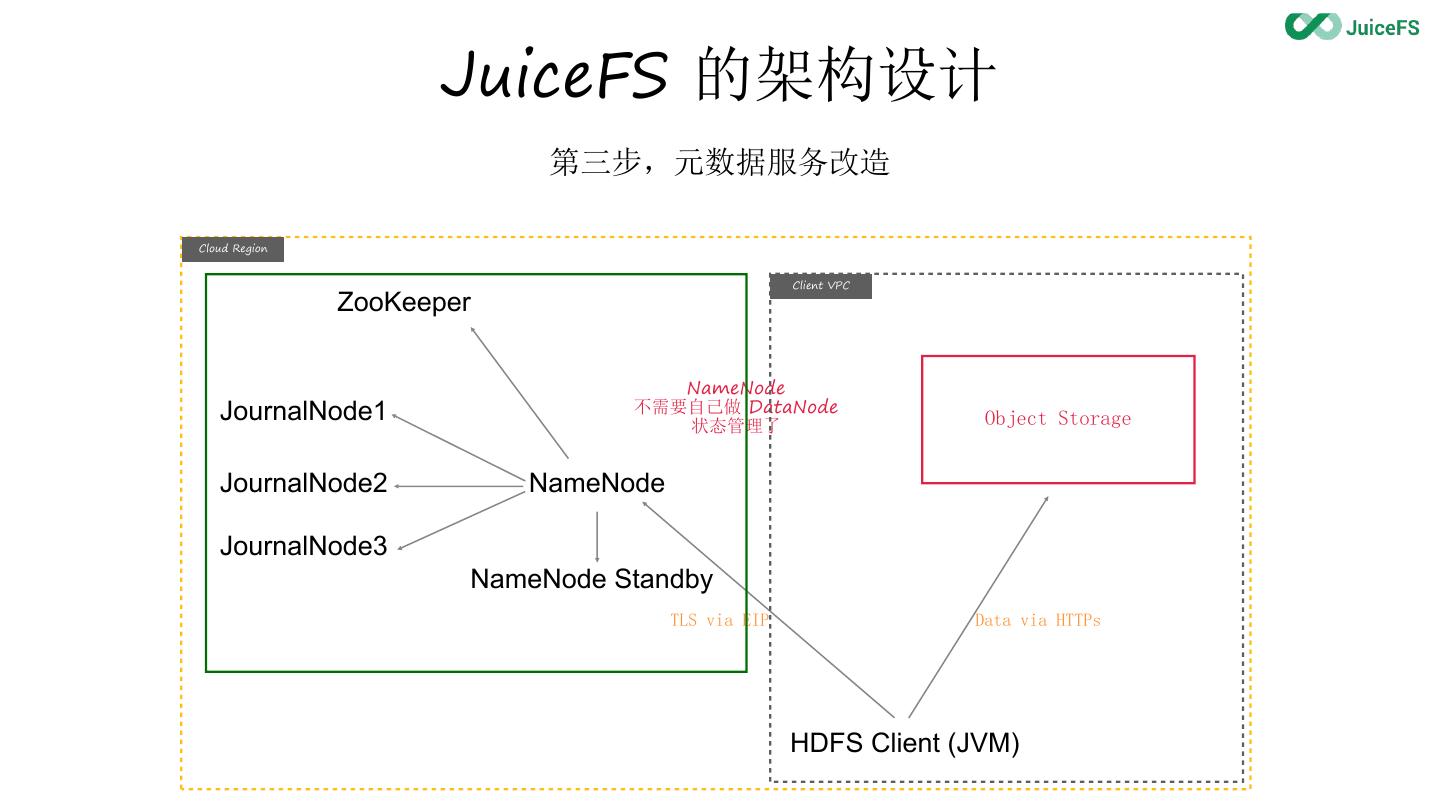
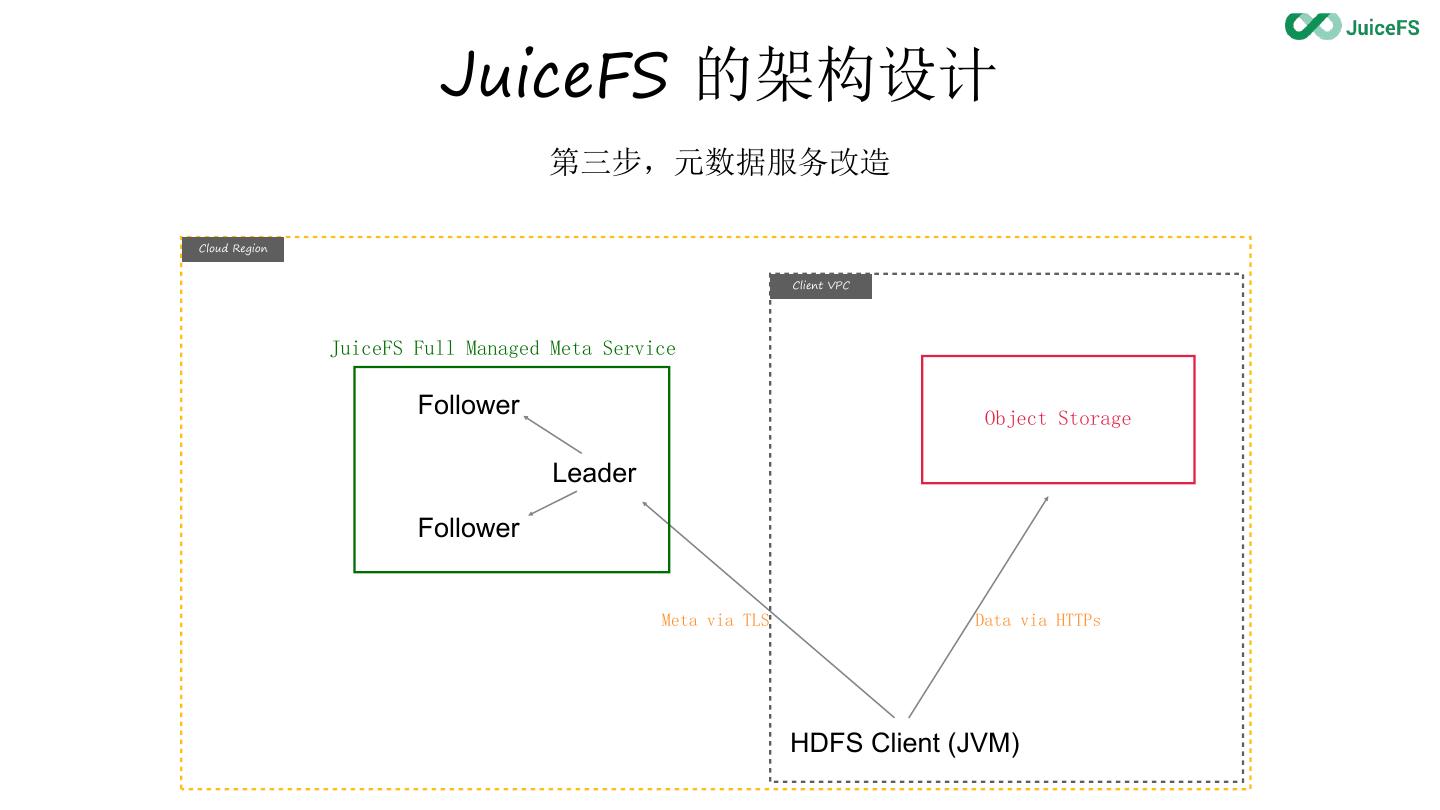
14 . JuiceFS 的架构设计
第三步,元数据服务改造
Cloud Region
Client VPC
ZooKeeper
NameNode
JournalNode1 不需要自己做 DataNode
状态管理了 Object Storage
JournalNode2 NameNode
JournalNode3
NameNode Standby
TLS via EIP Data via HTTPs
HDFS Client (JVM)
�
15 . JuiceFS 的架构设计
第三步,元数据服务改造
Cloud Region
Client VPC
JuiceFS Full Managed Meta Service
Follower Object Storage
Leader
Follower
Meta via TLS Data via HTTPs
HDFS Client (JVM)
�
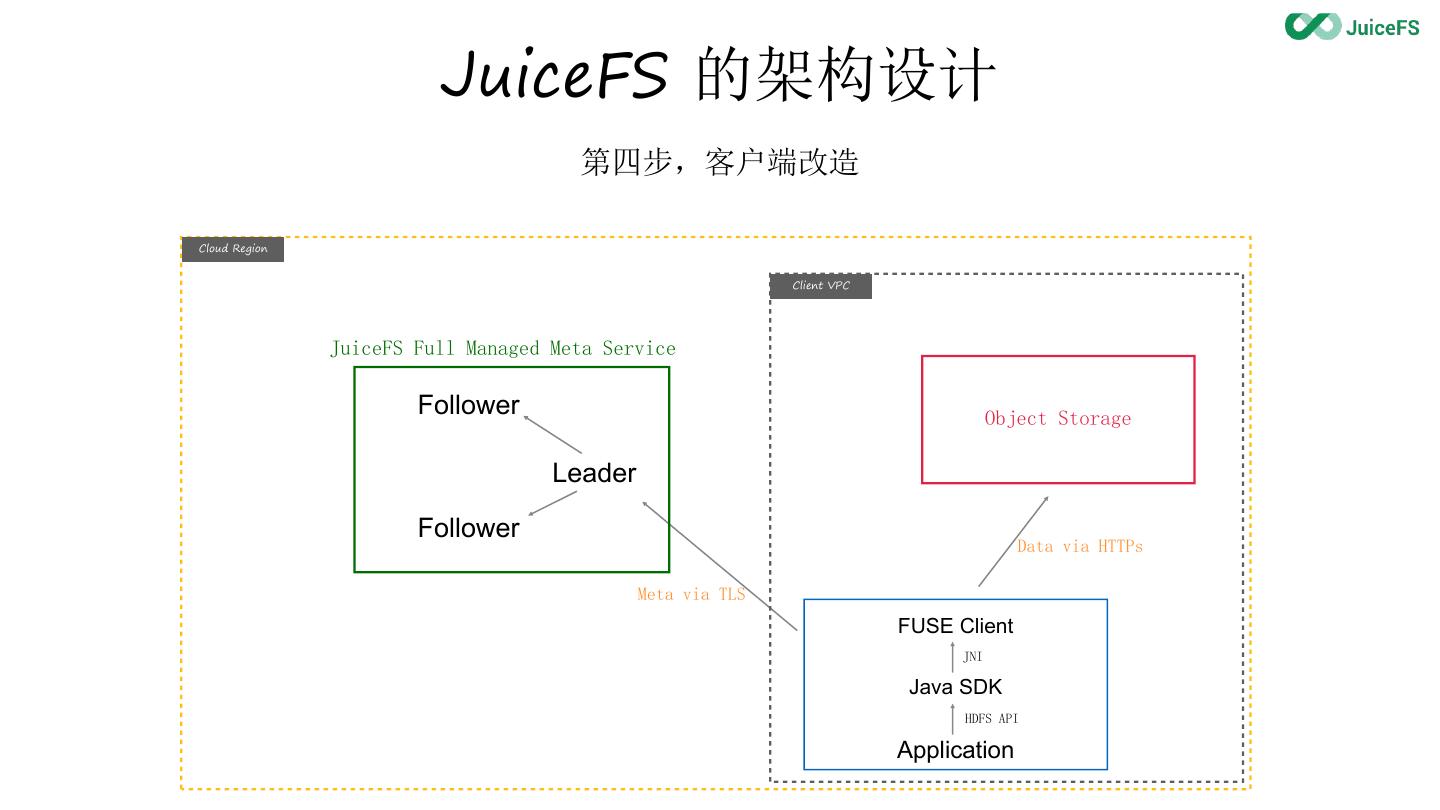
16 . JuiceFS 的架构设计
第四步,客户端改造
Cloud Region
Client VPC
JuiceFS Full Managed Meta Service
Follower Object Storage
Leader
Follower
Data via HTTPs
Meta via TLS
FUSE Client
JNI
Java SDK
HDFS API
Application
�
17 . JuiceFS 的架构设计
POSIX 与 HDFS 的差异
• rename
• POSIX - 当目标存在时会覆盖掉
• HDFS - 当目标存在时不会覆盖
• 递归删除
• POSIX - 不支持
• HDFS - 支持
• 符号链接
• POSIX - 能直接看到
• HDFS - 不能直接看到
�
18 . JuiceFS 的架构设计
POSIX 与 HDFS 的差异
• 元数据设计
• POSIX - 基于 inode,需要一层层递归查找
• HDFS - 基于 path,可以一次拿到完整信息
• JuiceFS 在 Java SDK 中做了一个优化,支持基于 inode 做多级查找,一次得到
最终的 inode
�
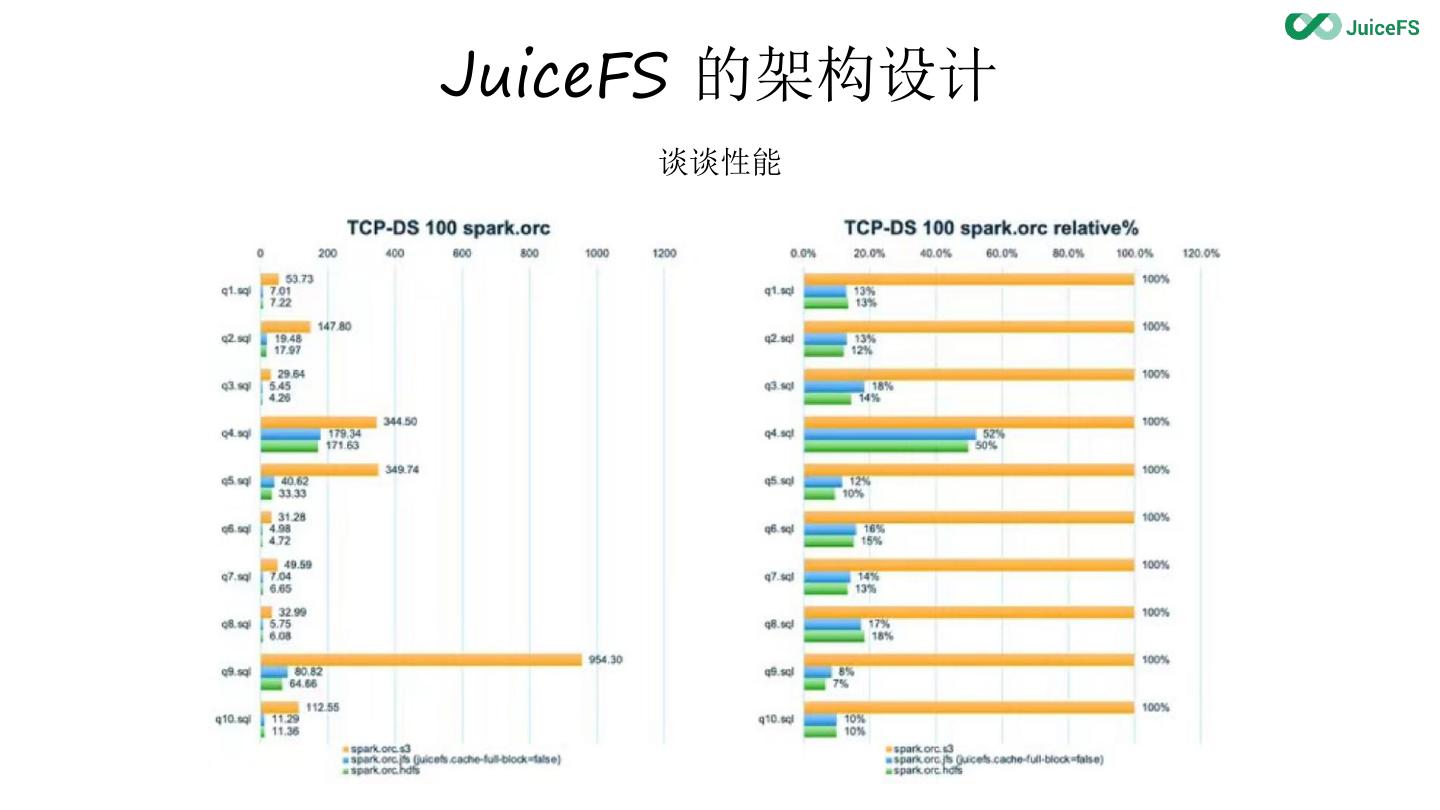
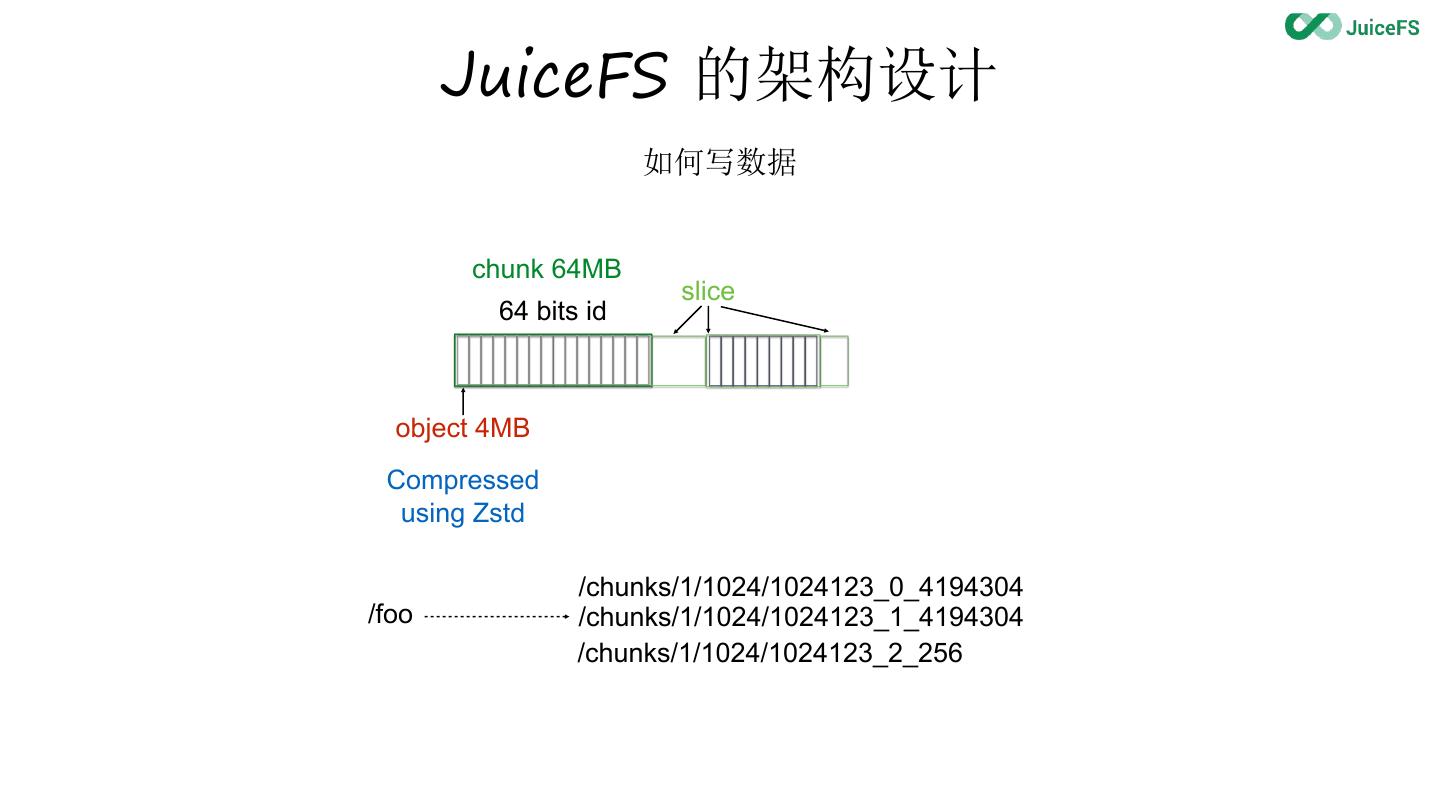
20 . JuiceFS 的架构设计
如何写数据
chunk 64MB
slice
64 bits id
object 4MB
Compressed
using Zstd
/chunks/1/1024/1024123_0_4194304
/foo /chunks/1/1024/1024123_1_4194304
/chunks/1/1024/1024123_2_256
�
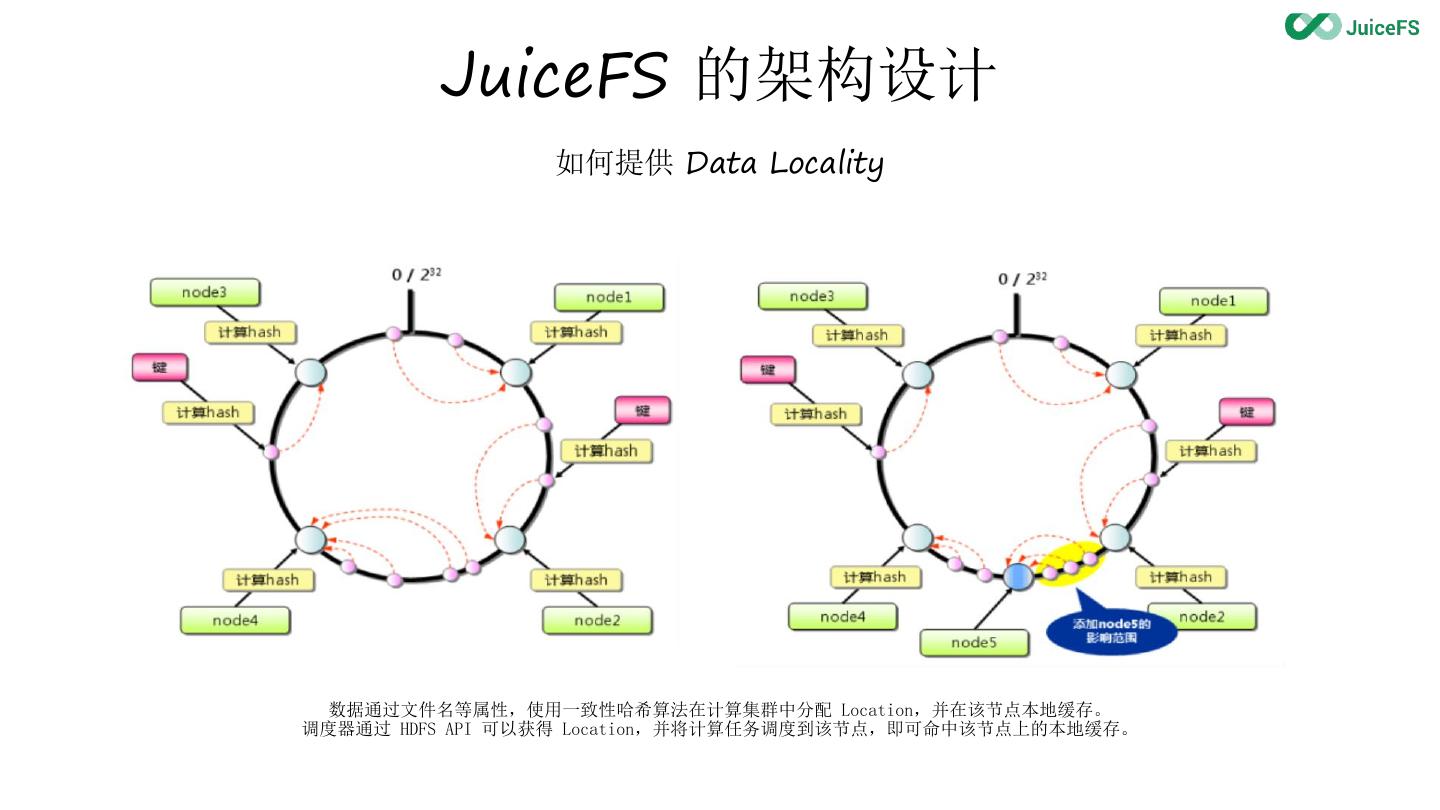
21 . JuiceFS 的架构设计
如何提供 Data Locality
数据通过文件名等属性,使用一致性哈希算法在计算集群中分配 Location,并在该节点本地缓存。
调度器通过 HDFS API 可以获得 Location,并将计算任务调度到该节点,即可命中该节点上的本地缓存。
�
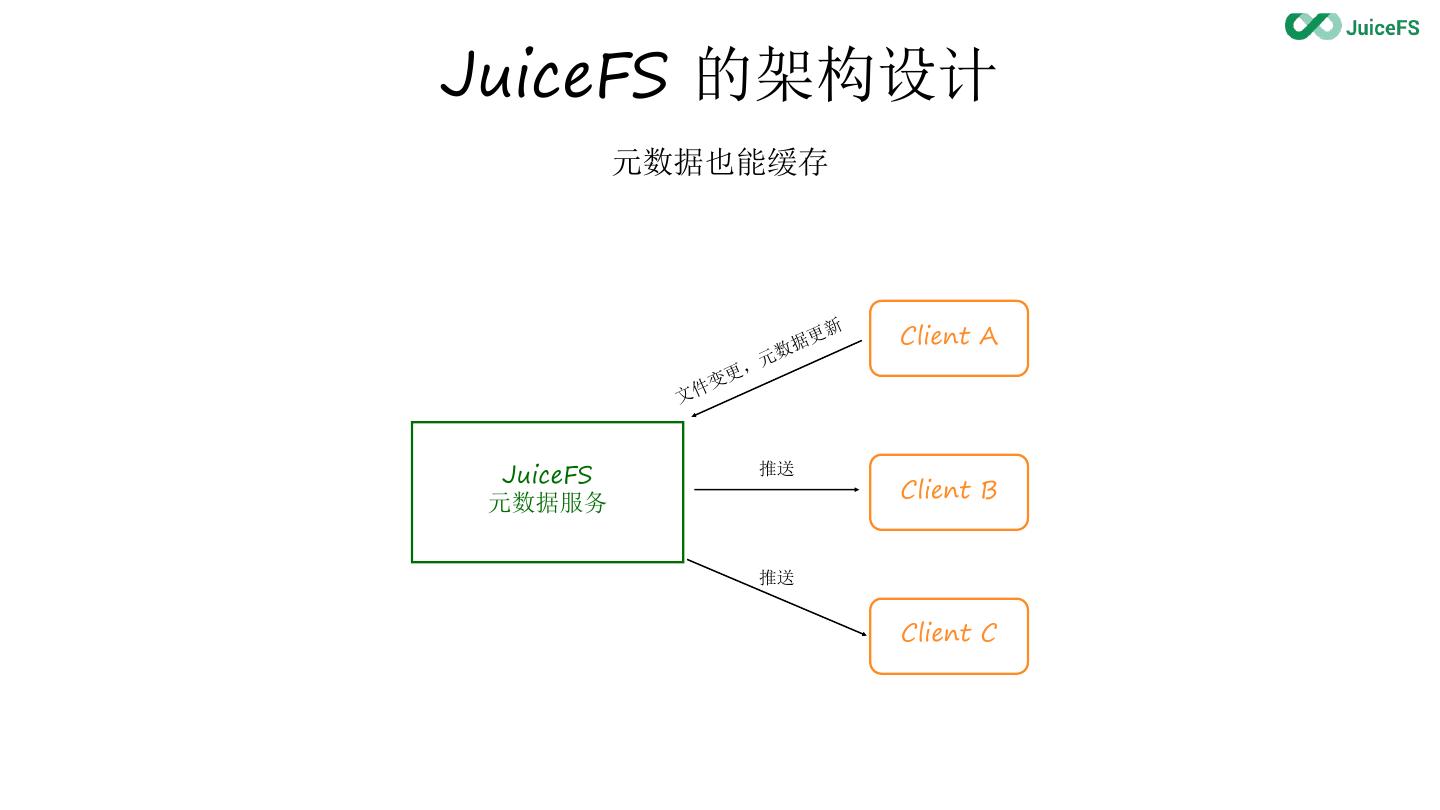
22 .JuiceFS 的架构设计
元数据也能缓存
据 更 新 Client A
元 数
变更,
文 件
JuiceFS 推送
Client B
元数据服务
推送
Client C
�
23 .多应用生态融合
POSIX 带来的优势
JuiceFS
�
24 . JuiceFS 的挑战
• 无止境的挑战 - 可靠、便宜、快;
• 数据湖,多业务场景融合 - IoT、边缘存储、异地数据多活
• 千亿文件管理
�
25 . Recap
• 基于 HDFS 架构,如何一步步实现全托管服务的架构改造;
• 如何实现高可用、强一致、弹性伸缩、本地缓存等大数据领域的核心特性;
• POSIX 兼容带来的多应用生态融合。
�