




















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Doris的数据导入机制以及原子性保证
Apache Doris 是百度贡献给Apache 社区的一款高性能企业级MPP数据库。支持近实时数据分析, 支持大规模数据导入,亚秒级实时性保证,可高效处理数据读取和写入。本次将与您分享Doris的数据导入中的事务管理和底层原理。
展开查看详情
1 .Doris 的数据导入事务及原子性保证 杨政国 百度资深研发工程师 Doris Committer
2 . 01 02 03 04 Doris简介 导入的问题 Doris中的导入 使用案例
3 . 01 Doris简介
4 . 01 Doris简介 系统定位 • 基于MPP(大规模并行处理)架构的分析型数据库 • 性能卓越,PB级别数据毫秒/秒级响应 • 适用于高并发、低延时下的多维分析、实时报表等场景 • 由百度自研,2017年开源,2018年贡献给Apache社区后更名为 Apache Doris • 百度内部统称其为“百度数据仓库Palo”,同时百度云上提供Palo的企业级托管版本
5 . 01 Doris简介 发展历程 2008 2009 2012 • 1.0版本正式上线 • 进行了通用化改造,开始承 • 随百度业务飞速发展,对 • 应用于百度凤巢统计报表的 接公司内部其他报表系统 Doris的性能、可用性、拓 需求场景,上线后数据更新 • 助力百度统计成为国内最大 展性进行了全面升级 频率从天级提升至分钟级 的中文网站分析工具 • 承担百度所有统计报表业务 01 02 03
6 . 01 Doris简介 2013 2015 2017 2018 • 全新的数据模型,查询存储 • 精简架构、统一用户客户端, • 正式开源 • 贡 献 给 Apache社 区 , 更 名 效率大幅提升 实现高可用 • 希望能帮助更多人、让更多 为Apache Doris • MPP框架,支持分布式计算 • 正式开始对外提供服务 人帮助Doris • 截止目前,社区2000+star, Contributor 100+,一线互 联网广泛使用 04 05 06 07
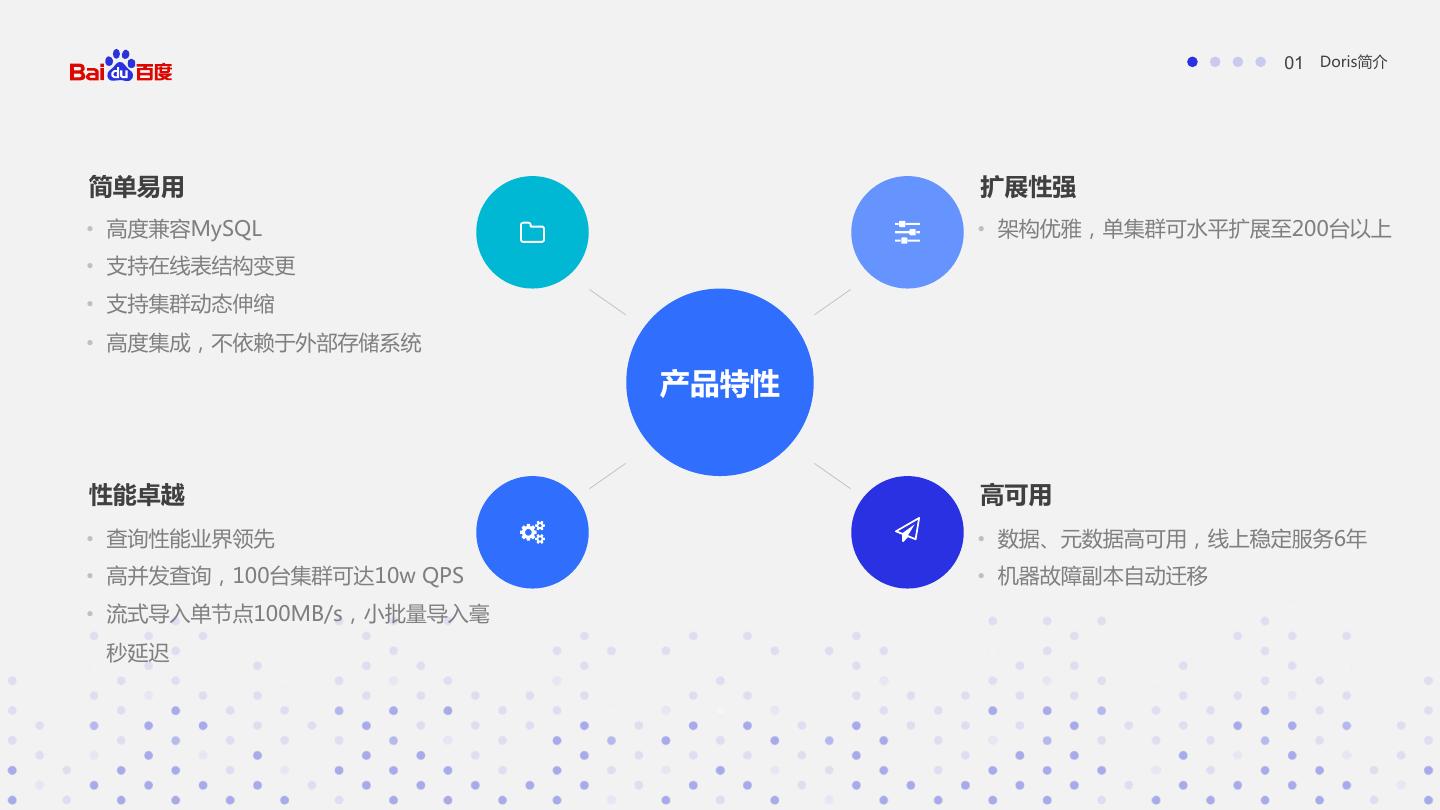
7 . 01 Doris简介 简单易用 扩展性强 • 高度兼容MySQL • 架构优雅,单集群可水平扩展至200台以上 • 支持在线表结构变更 • 支持集群动态伸缩 • 高度集成,不依赖于外部存储系统 产品特性 性能卓越 高可用 • 查询性能业界领先 • 数据、元数据高可用,线上稳定服务6年 • 高并发查询,100台集群可达10w QPS • 机器故障副本自动迁移 • 流式导入单节点100MB/s,小批量导入毫 秒延迟
8 . 01 Doris 简介 MySQL Tools (MySQL Networking) 整体架构简单,产品易用 • 高度兼容MySQL协议 FE FE FE FE (Leader,JAVA) (Follower,JAVA) (Follower,JAVA) (Obsever,JAVA) • 主从架构,不依赖任何其他组件 • FE负责解析/生成/调度查询计划 • BE负责执行查询计划、数据存储 BE BE BE BE (C++) (C++) (C++) (C++) • 任何节点都可线性扩展
9 . 02 导入的问题
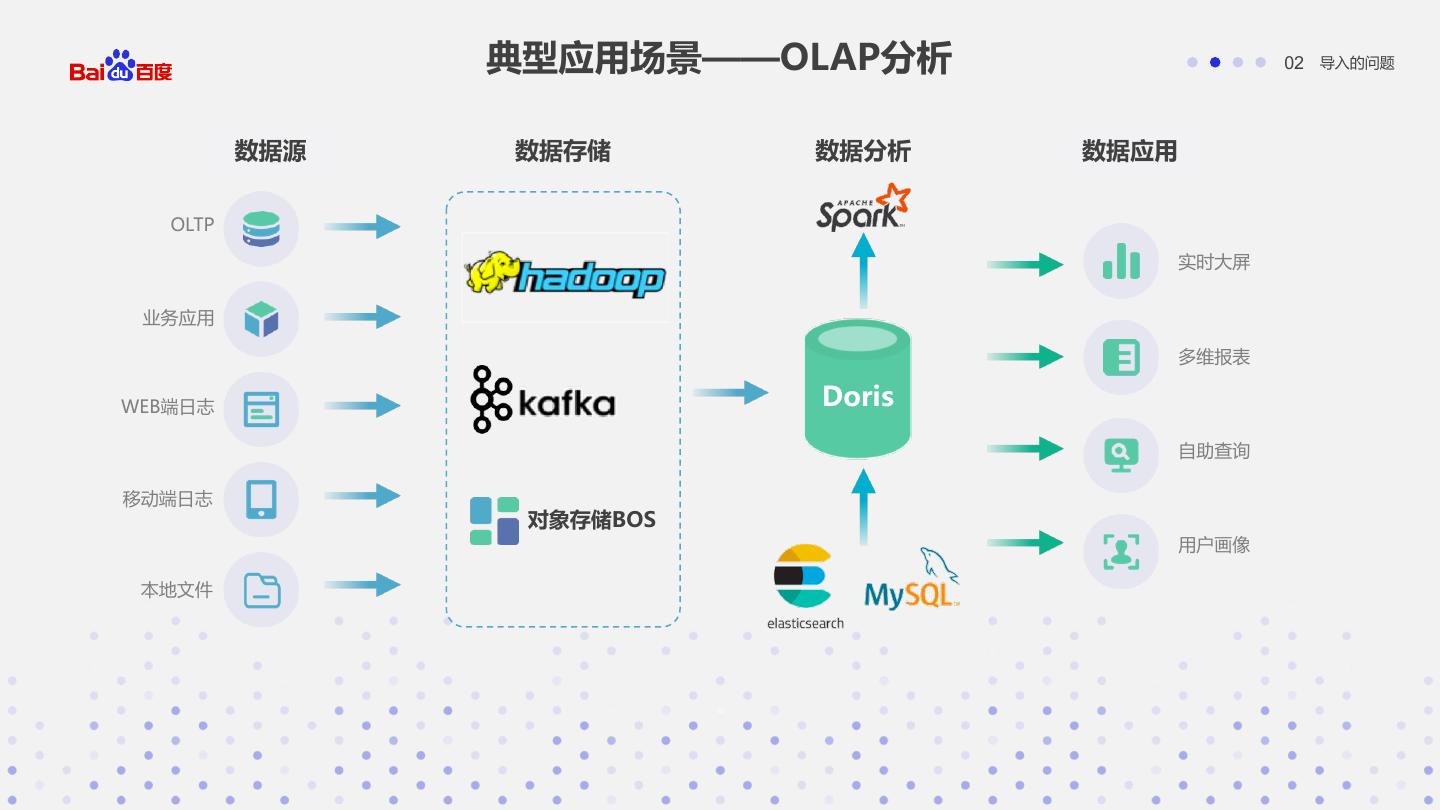
10 . 典型应用场景——OLAP分析 02 导入的问题 数据源 数据存储 数据分析 数据应用 OLTP 实时大屏 业务应用 多维报表 WEB端日志 Doris 自助查询 移动端日志 对象存储BOS 用户画像 本地文件
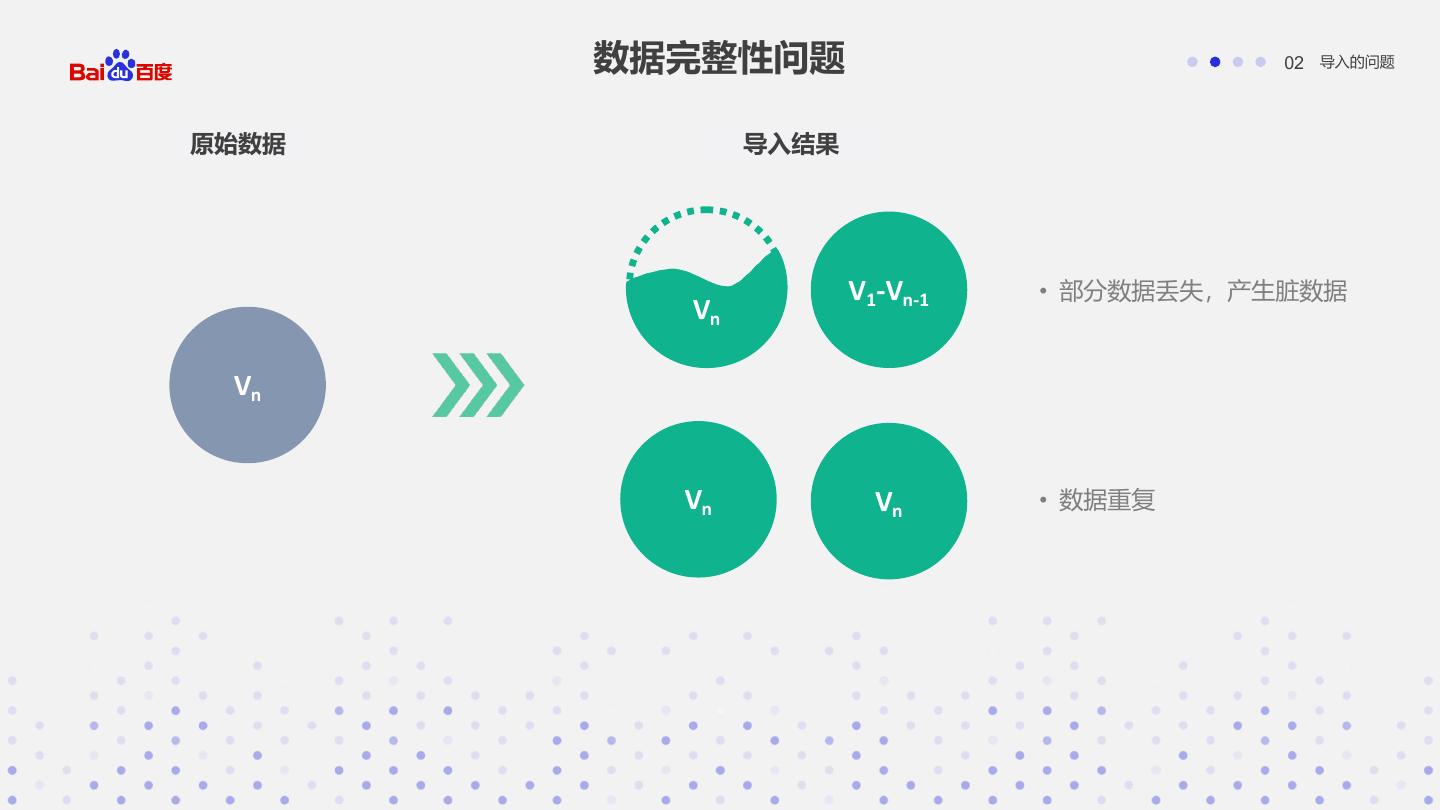
11 . 数据完整性问题 02 导入的问题 原始数据 导入结果 V1-Vn-1 • 部分数据丢失,产生脏数据 Vn Vn Vn Vn • 数据重复
12 . 读写冲突问题 02 导入的问题 原始数据 查询导入结果 未生效 已生效 数据 V1-Vn-1 • 读取到未生效数据 Vn 已生效 已生效 Vn V1-Vn-1 • 生效的数据未被读取到
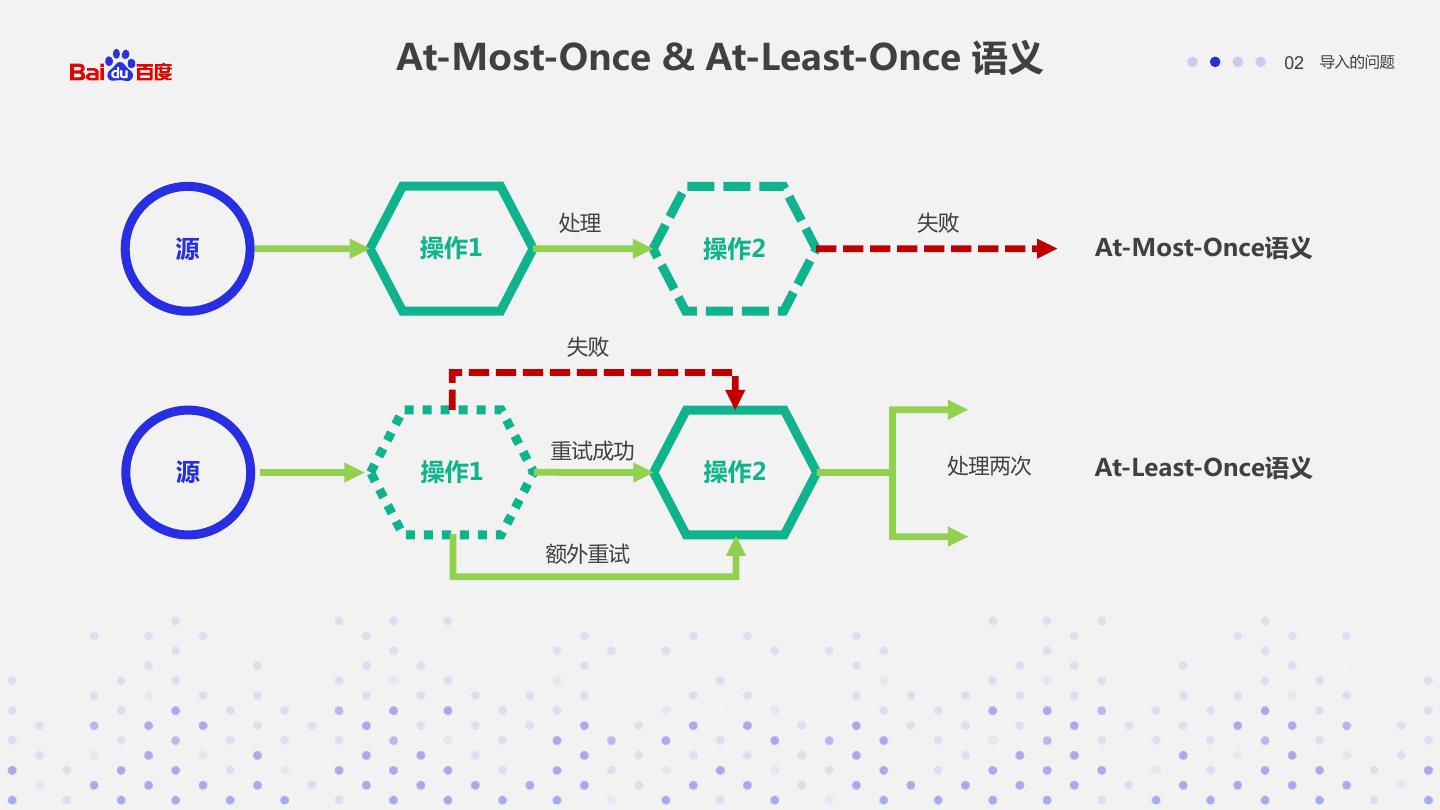
13 . At-Most-Once & At-Least-Once 语义 02 导入的问题 处理 失败 源 操作1 操作2 At-Most-Once语义 失败 重试成功 源 操作1 操作2 处理两次 At-Least-Once语义 额外重试
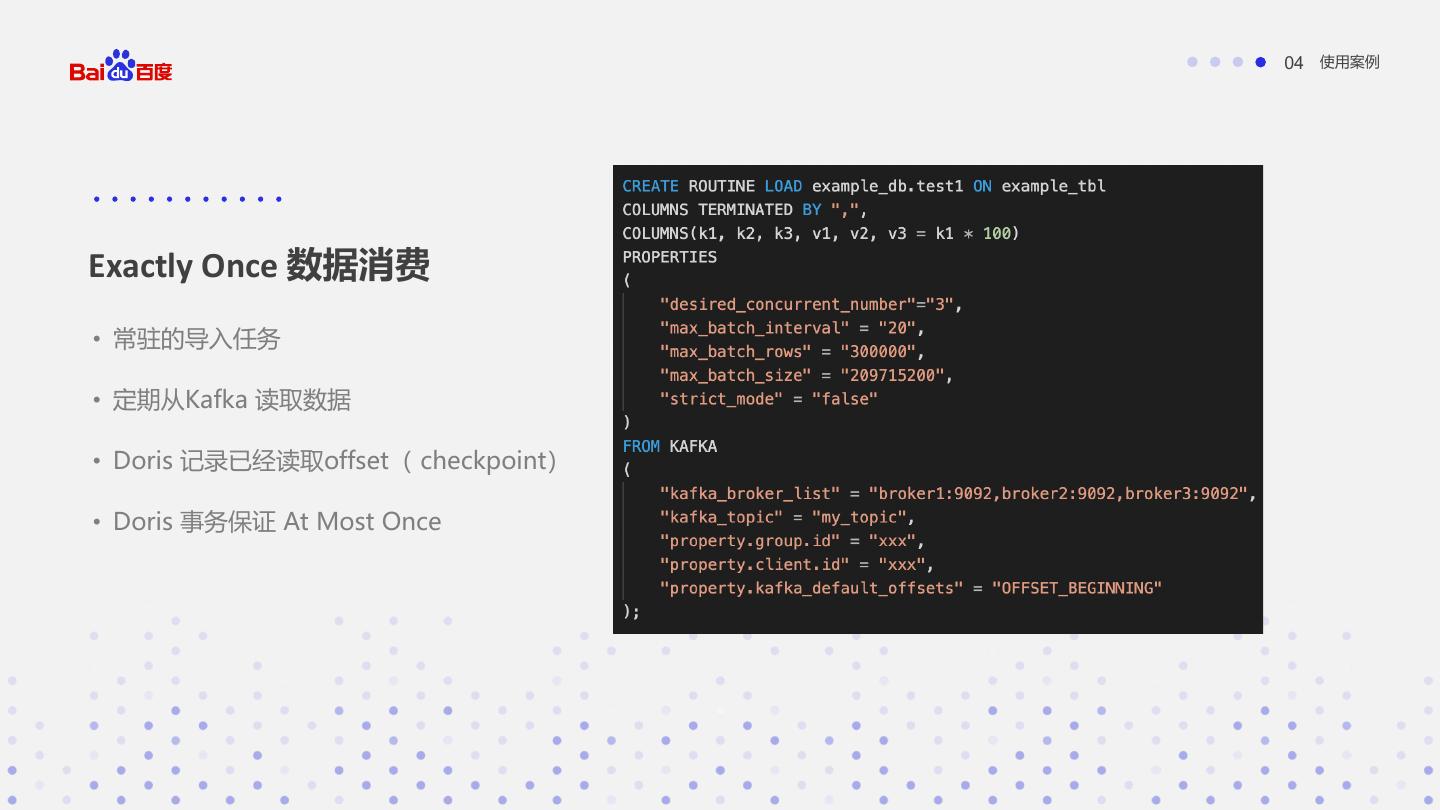
14 . Exactly-Once 语义 02 导入的问题 失败 重试成功 成功 源 操作1 操作2 只处理一次 Exactly-Once语义 重试 LOG Checkpoint
15 . 03 Doris中的导入
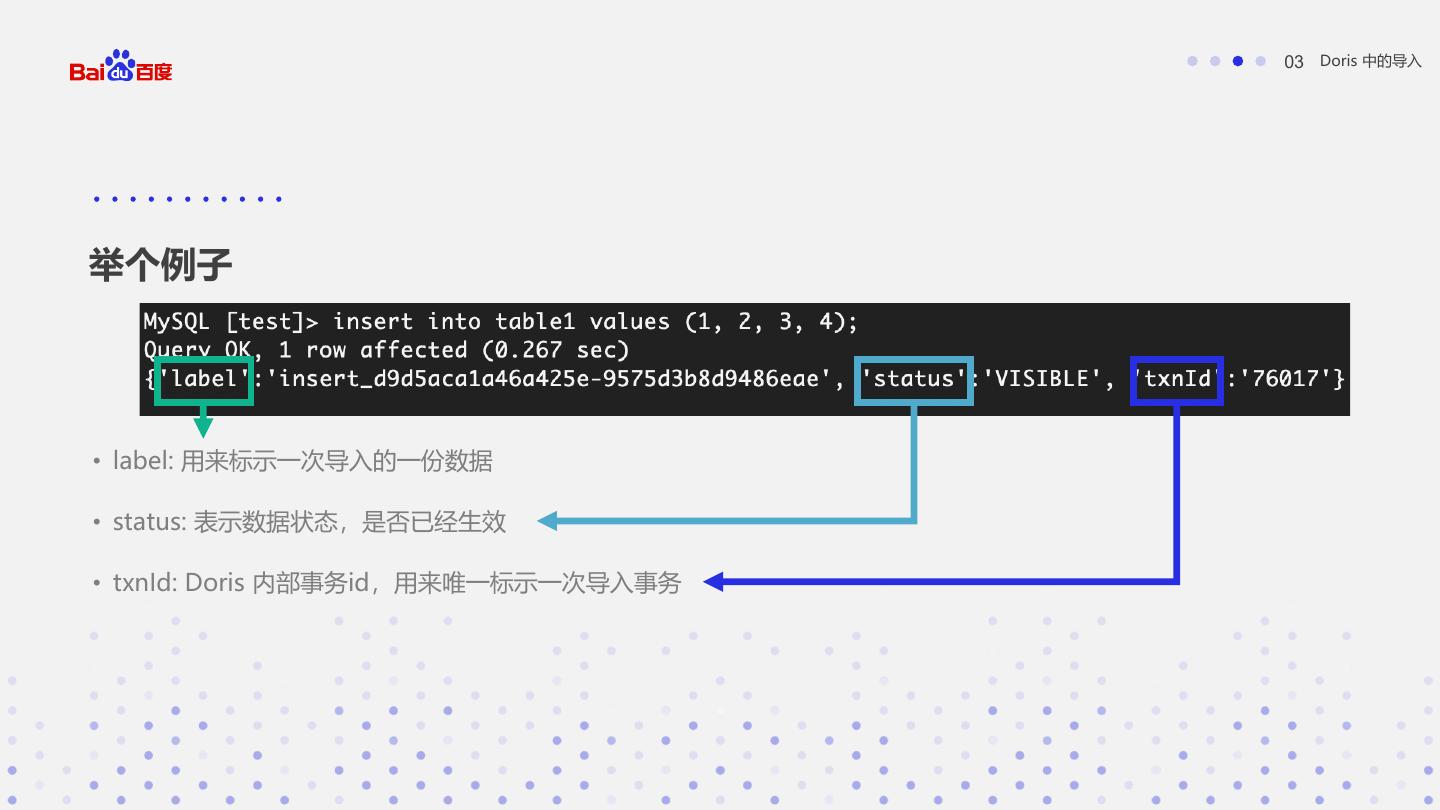
16 . 03 Doris 中的导入 举个例子 • label: 用来标示一次导入的一份数据 • status: 表示数据状态,是否已经生效 • txnId: Doris 内部事务id,用来唯一标示一次导入事务
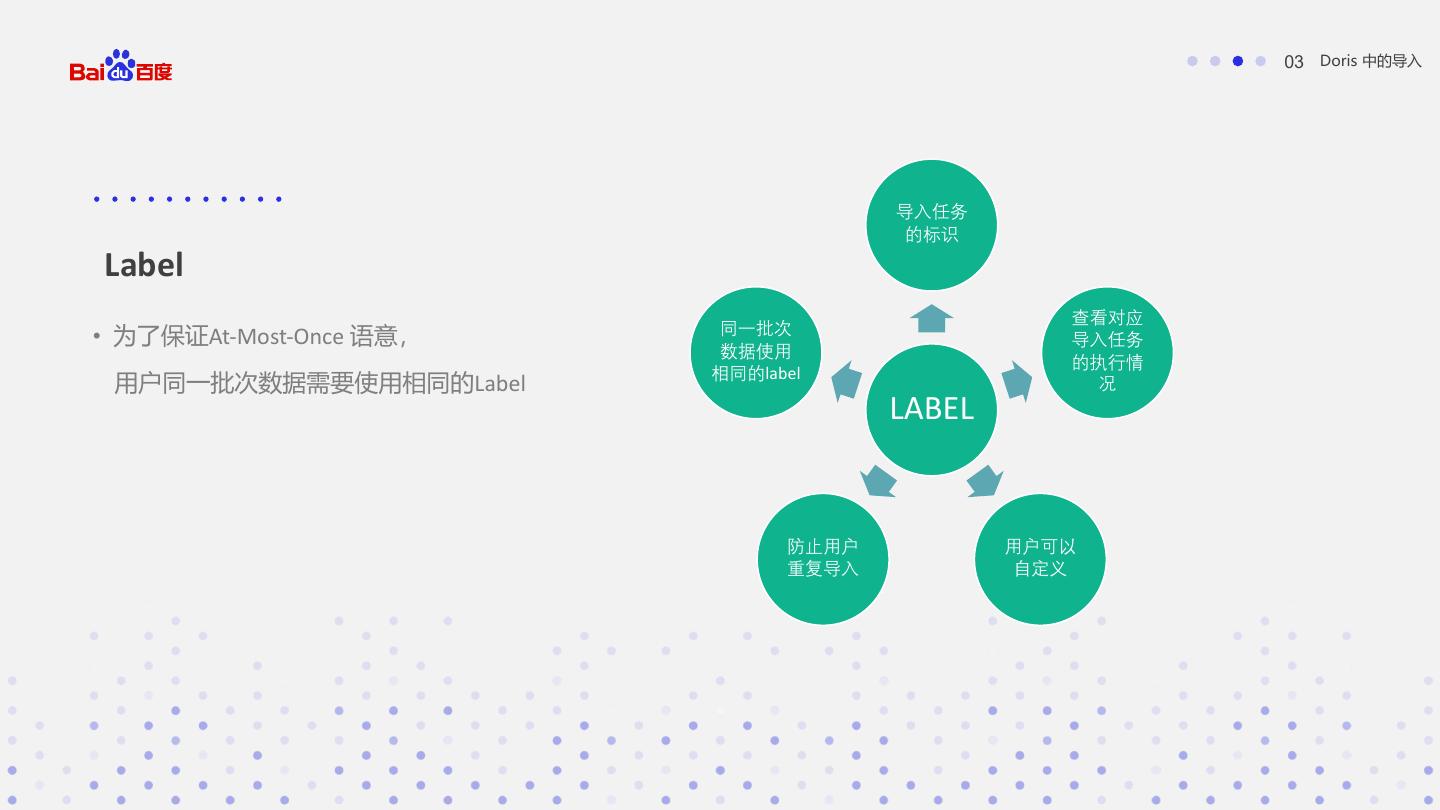
17 . 03 Doris 中的导入 导入任务 的标识 Label 查看对应 同一批次 • 为了保证At-Most-Once 语意, 导入任务 数据使用 的执行情 相同的label 用户同一批次数据需要使用相同的Label 况 LABEL 防止用户 用户可以 重复导入 自定义
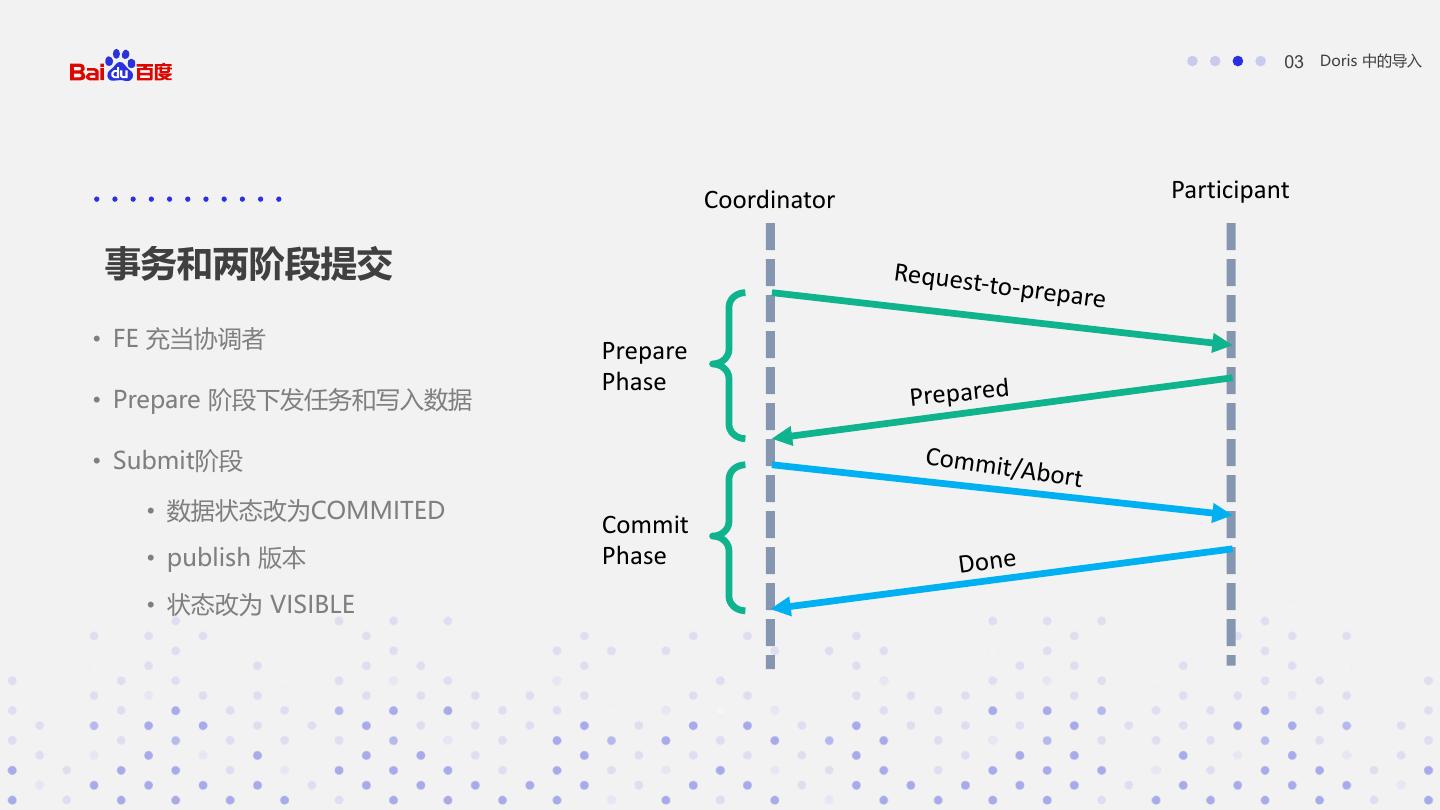
18 . 03 Doris 中的导入 Coordinator Participant 事务和两阶段提交 Request-t o -prepare • FE 充当协调者 Prepare Phase • Prepare 阶段下发任务和写入数据 Prepared • Submit阶段 Commit/ Abort • 数据状态改为COMMITED Commit • publish 版本 Phase D on e • 状态改为 VISIBLE
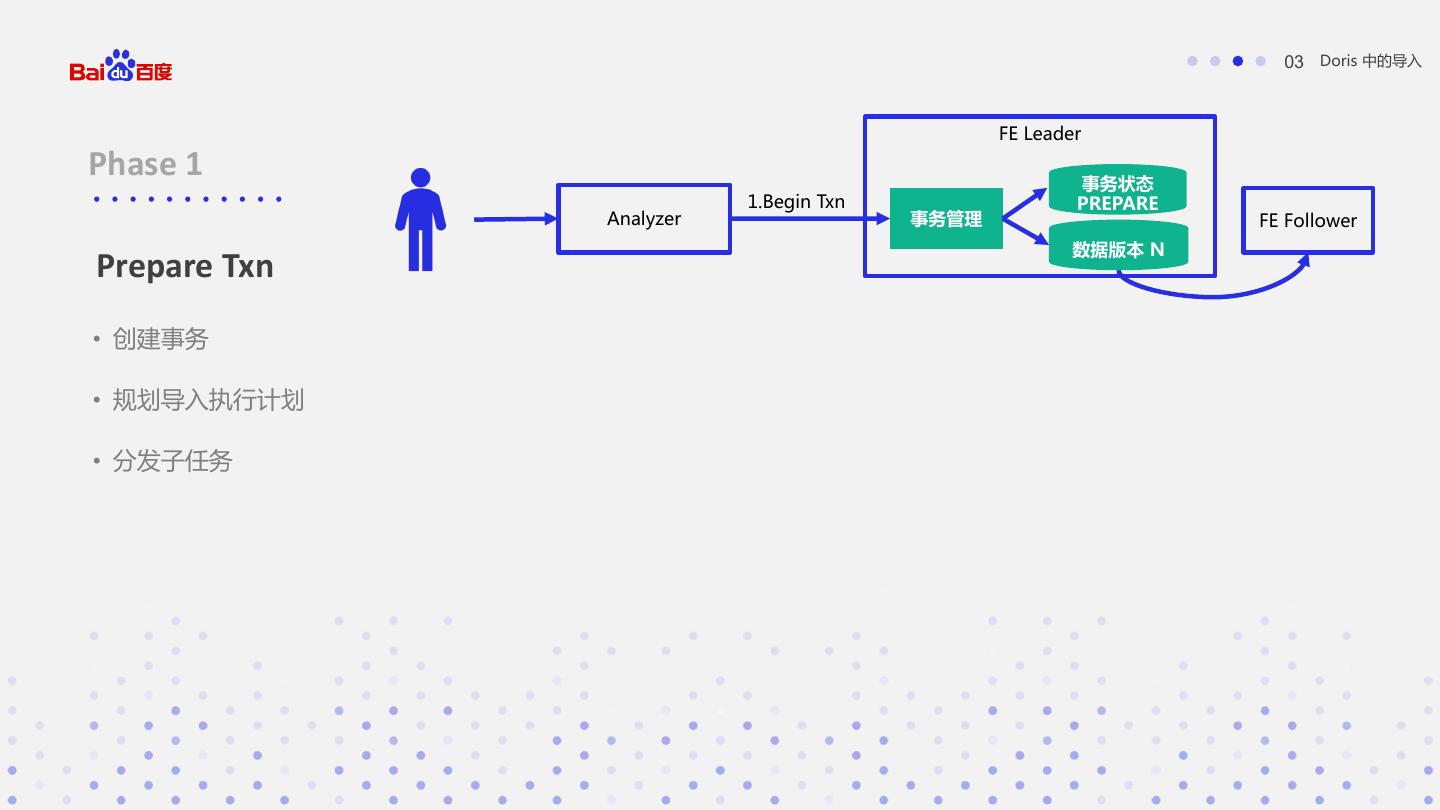
19 . 03 Doris 中的导入 FE Leader Phase 1 事务状态 1.Begin Txn PREPARE Analyzer 事务管理 FE Follower 数据版本 N Prepare Txn • 创建事务 • 规划导入执行计划 • 分发子任务
20 . 03 Doris 中的导入 FE Leader Phase 1 事务状态 1.Begin Txn PREPARE Analyzer 事务管理 FE Follower 数据版本 N Execute Txn 3.汇报导入 • 接受查询计划 • 初始化ScanNode BE • 初始化 TableSink和 tablet writer 2. Load 数据 BE 未生效数据 生效数据 • Extract & Transform & Load tid-1 V1 V2 • 汇报导入结果 tid-n … Vn BE
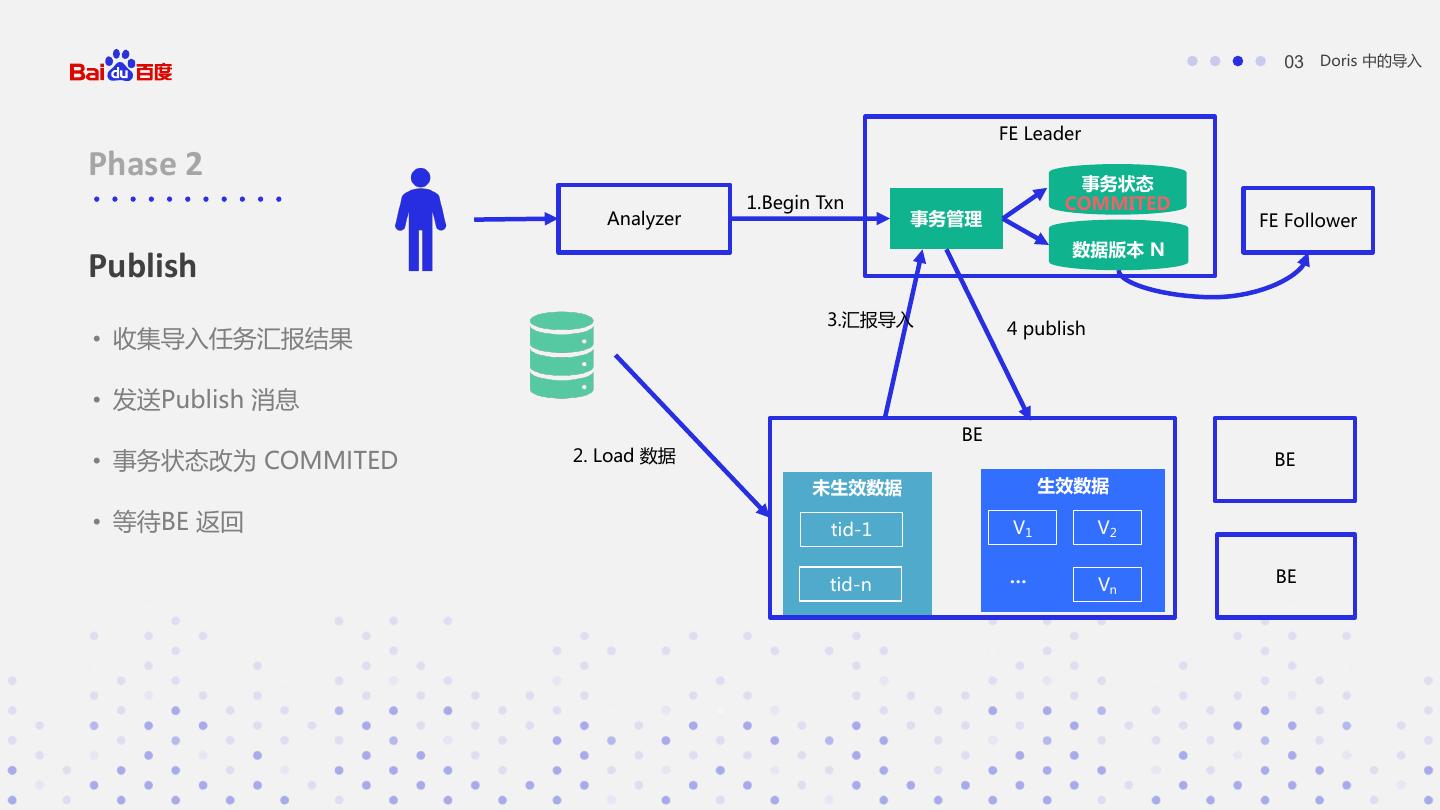
21 . 03 Doris 中的导入 FE Leader Phase 2 事务状态 1.Begin Txn COMMITED Analyzer 事务管理 FE Follower 数据版本 N Publish 3.汇报导入 4 publish • 收集导入任务汇报结果 • 发送Publish 消息 BE • 事务状态改为 COMMITED 2. Load 数据 BE 未生效数据 生效数据 • 等待BE 返回 tid-1 V1 V2 tid-n … Vn BE
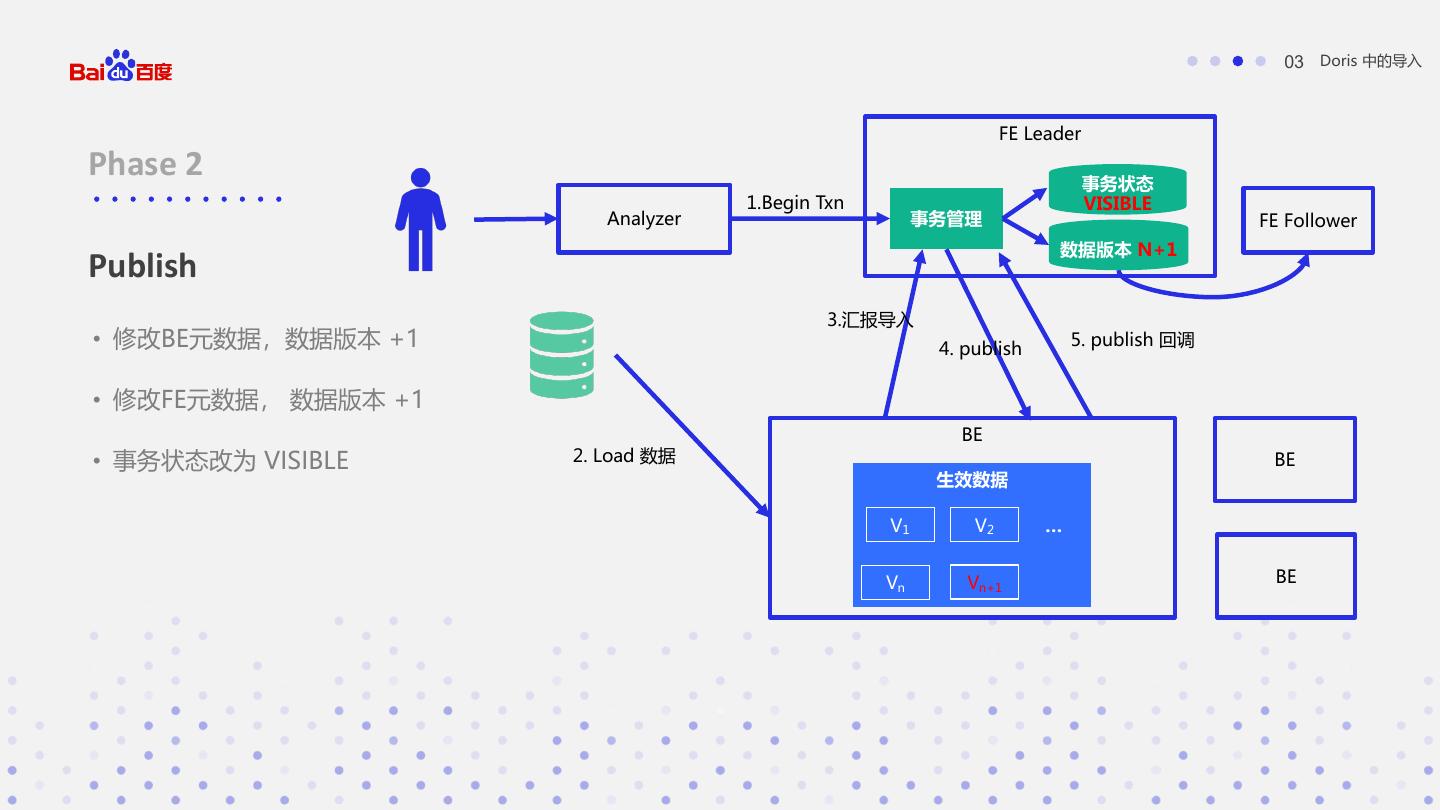
22 . 03 Doris 中的导入 FE Leader Phase 2 事务状态 1.Begin Txn VISIBLE Analyzer 事务管理 FE Follower 数据版本 N+1 Publish 3.汇报导入 • 修改BE元数据,数据版本 +1 4. publish 5. publish 回调 • 修改FE元数据, 数据版本 +1 BE • 事务状态改为 VISIBLE 2. Load 数据 BE 生效数据 V1 V2 … Vn Vn+1 BE
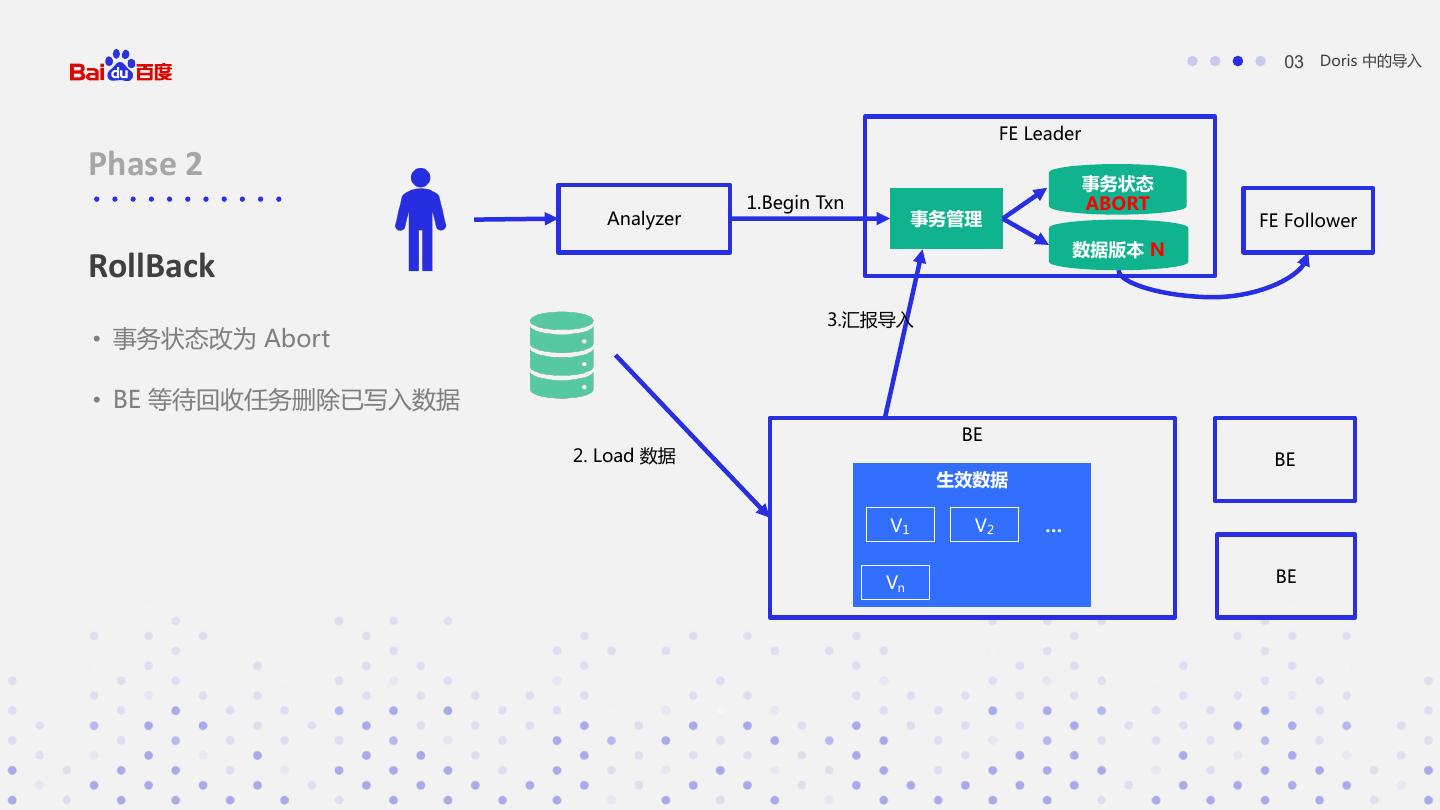
23 . 03 Doris 中的导入 FE Leader Phase 2 事务状态 1.Begin Txn ABORT Analyzer 事务管理 FE Follower 数据版本 N RollBack 3.汇报导入 • 事务状态改为 Abort • BE 等待回收任务删除已写入数据 BE 2. Load 数据 BE 生效数据 V1 V2 … Vn BE
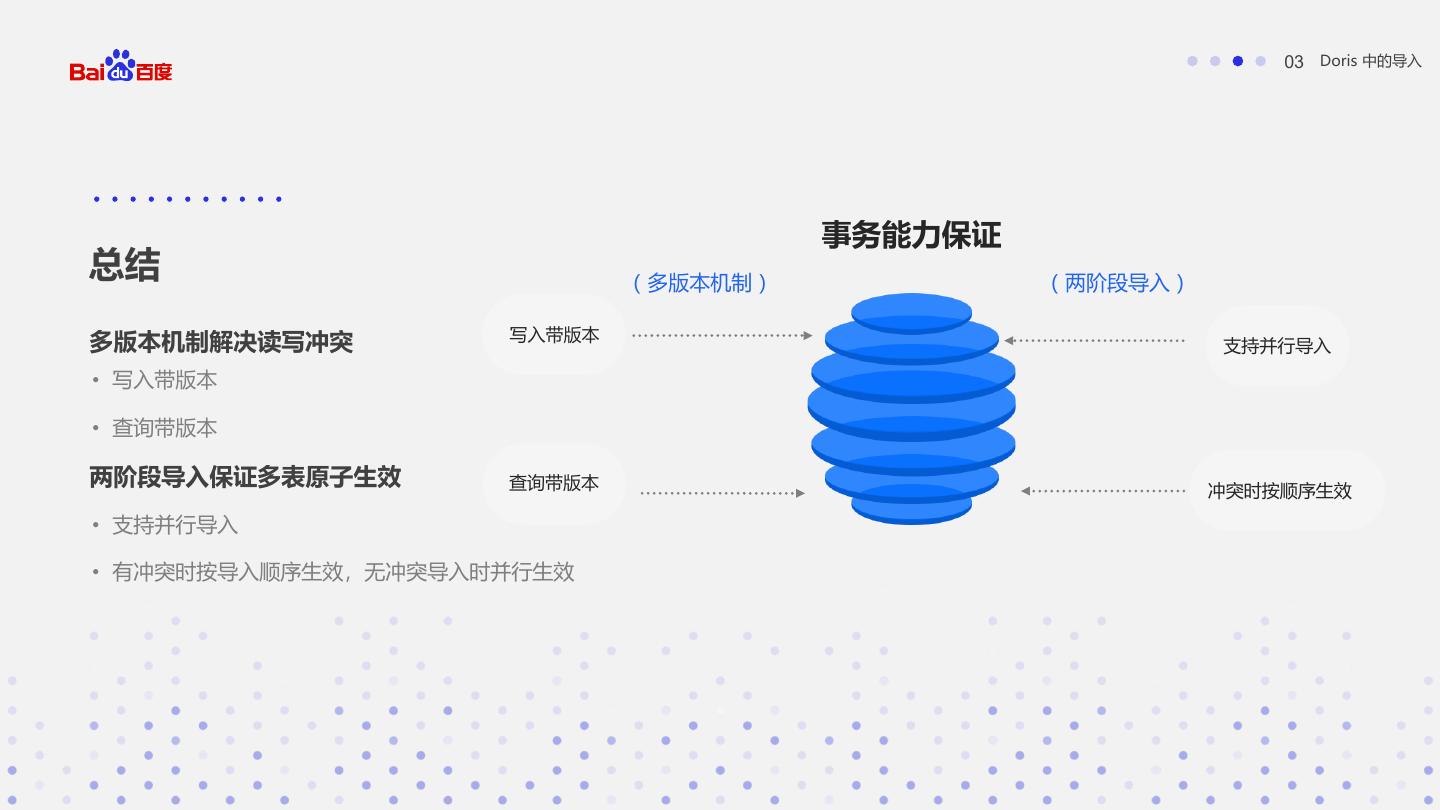
24 . 03 Doris 中的导入 事务能力保证 总结 (多版本机制) (两阶段导入) 写入带版本 多版本机制解决读写冲突 支持并行导入 • 写入带版本 • 查询带版本 两阶段导入保证多表原子生效 查询带版本 冲突时按顺序生效 • 支持并行导入 • 有冲突时按导入顺序生效,无冲突导入时并行生效
25 . 04 使用案例
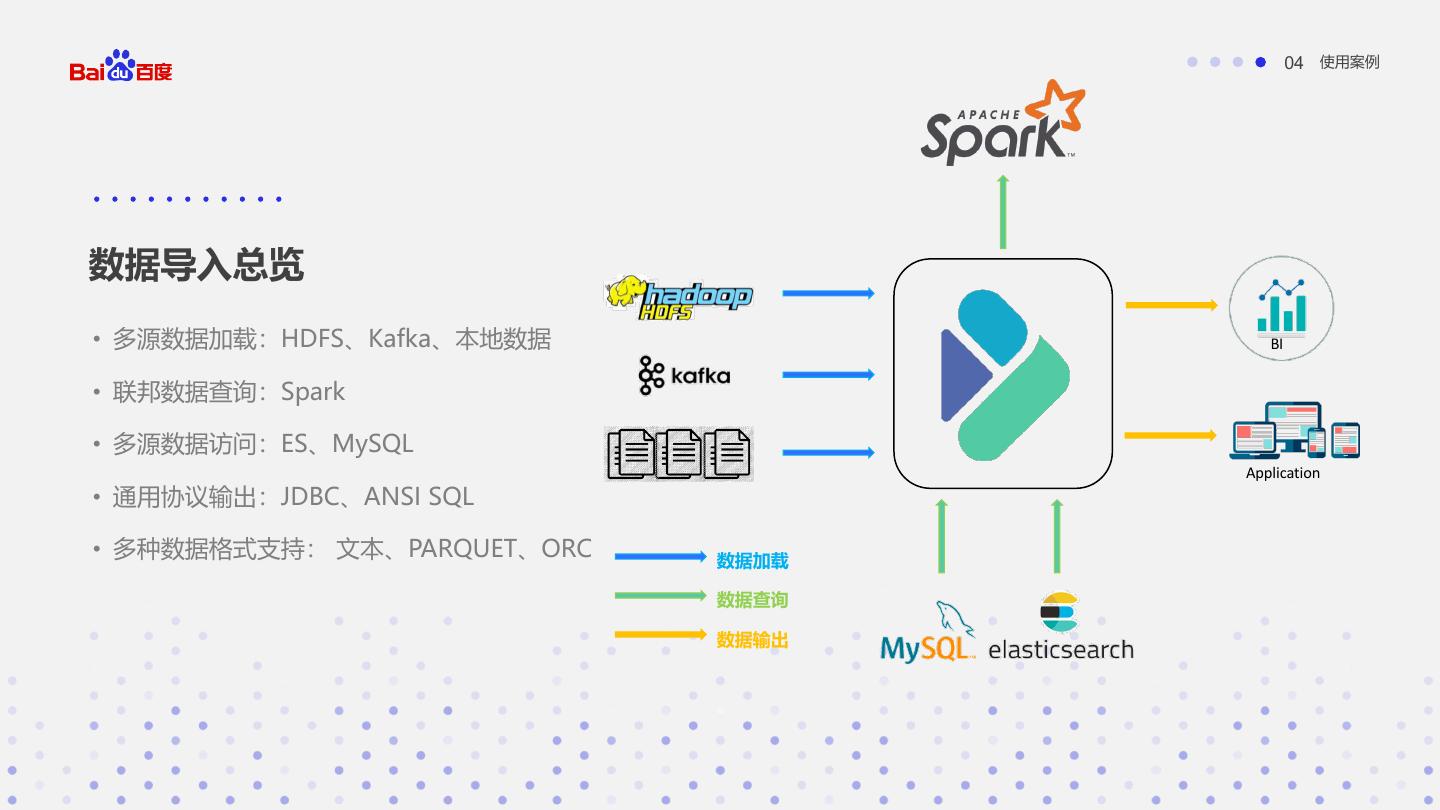
26 . 04 使用案例 数据导入总览 • 多源数据加载:HDFS、Kafka、本地数据 BI • 联邦数据查询:Spark • 多源数据访问:ES、MySQL Application • 通用协议输出:JDBC、ANSI SQL • 多种数据格式支持: 文本、PARQUET、ORC 数据加载 数据查询 数据输出
27 . 04 使用案例 导入方式 导入方式 同步/异步 场景 接口 Broker Load 异步 HDFS、BOS对象存储 MySQL Routine Load 异步 Kafka MySQL Stream load 同步 本地文件,数据流 HTTP Insert into 同步 命令行 MySQL Spark Load 异步 Spark MySQL
28 . 04 使用案例 选择合适的导入方式 • 根据数据源所在位置选择导入方式。 最佳实践 确定导入方式的协议 • 使用 MySQL 协议定期提交和查看导入作业。 确定导入方式的类型 • 导入方式为同步或异步。 制定 Label 生成策略 • 每一批次数据唯一且固定,保证 At-Most-Once • 外部系统需要保证自身的 At-Least-Once,这样就可以保证 程序自身保证 At-Least-Once 导入流程的 Exactly-Once。
29 . 04 使用案例 多表原子性导入 • 每个表拆分多个任务,并下发BE • BE执行后汇报FE • FE 判断导入多数完成 publish 生效版本 • 后续查询规划时使用新的数据版本
3秒后跳转登录页面
去登陆

