



























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
AI技术如何打造智能语音质检系统
展开查看详情
1 .【第12期】图像、NLP、语音技术在58的应用实践 欢迎关注AICUG人工智能技术社区 欢迎关注 58AILab 公众号 欢迎关注58技术公众号 (www.aicug.cn)
2 .【第2讲】AI技术如何打造智能 语音质检系统 分享嘉宾:陈璐-58同城AI Lab算法高级工程师
3 . 个人简介 • 教育背景 • 2013.09 ~ 2016.04,硕士就读于北京邮电大学 • 2009.09 ~ 2013.07,本科就读于哈尔滨工业大学 • 工作经历 • 2018.09 ~ 至今,入职58同城,参与智能客服、语音质检和语音机器 人的算法工作 • 2016.07 ~ 2018.09,于京东商城,负责推荐后台研发,NLP算法研 发工作 联系方式:chenlu17@58.com
4 . CONTENTS 01 02 03 04 背景介绍 总体架构 核心功能 业务案例
5 . 背景介绍 客户 • 语音质检是什么 销 VIP 售 • 传统语音质检通常是指质检员听取一定比例的电话录 用户 音进行人工质检,检测坐席在通话过程中是否有违规 客 普通 服 或非标准话术的行为 用户 呼叫中心 • 58同城呼叫中心简介 • 支撑数千名销售、客服人员工作 • 年通话数1亿+,通话时长数百万小时 • 采用传统方式开展质检 • 纯人工抽检录音,覆盖率低 • 人工质检效率低,人均单日可听3小时录音
6 . 智能语音质检系统优势 语音转写成文字 实时采集 AI质检模型构建 语音数据 自然 传统人工质检 智能语音质检 语言 抽检不足1%, 处理 全量机器质检 覆盖率低 机器 数据 学习 挖掘 实时反馈,升级 机器质检 质检标准不一致 处理 + VS 人工复检 数据可视化 风险信息难发现 风险精准识别 反馈及管理 质检效率低,人 少量人工复检, 力成本高 且质检效率高 全量 机器 问题 人工 工作模式: 质检 复检 录音 录音 Web平台:人工复检、数据分析…
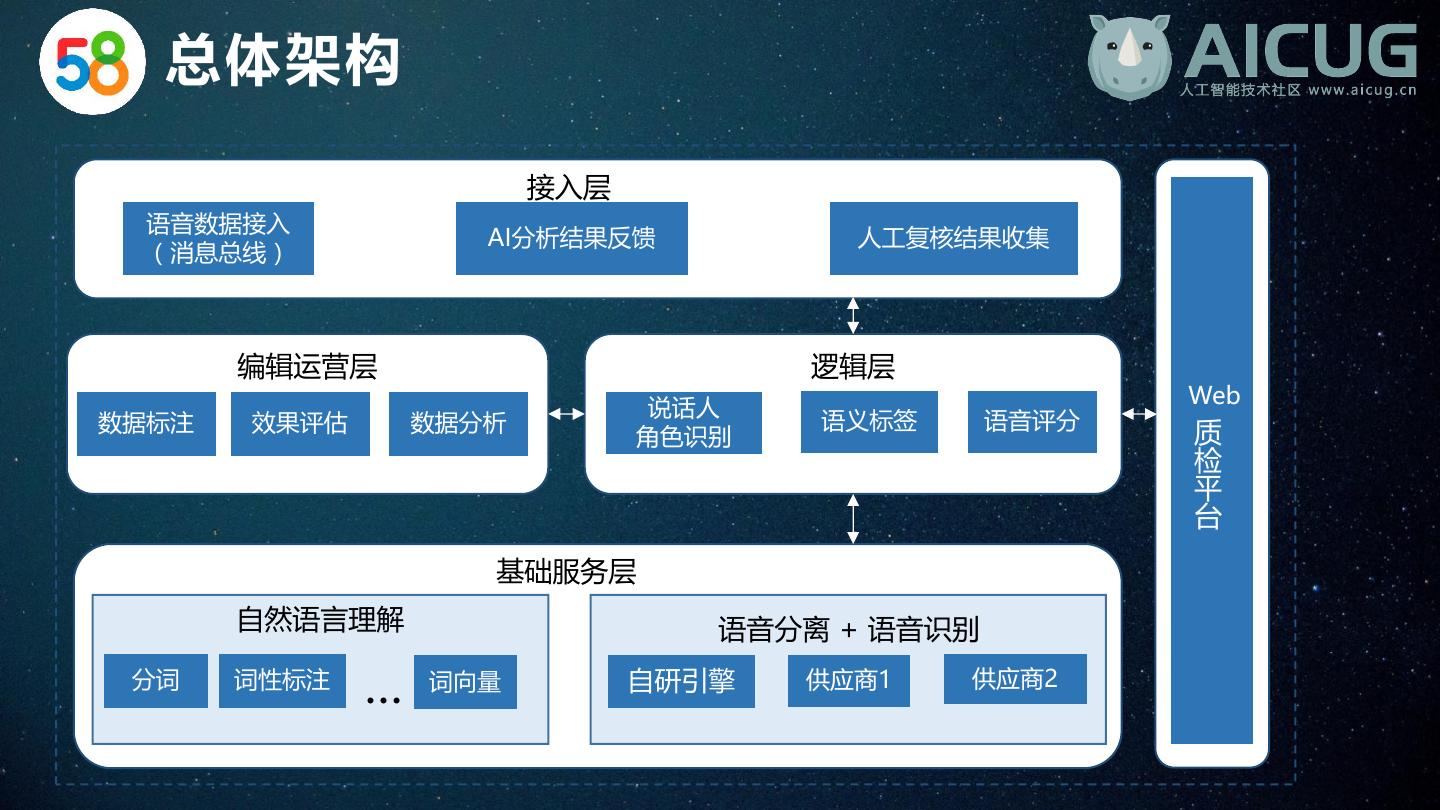
7 . 总体架构 接入层 语音数据接入 AI分析结果反馈 人工复核结果收集 (消息总线) 编辑运营层 逻辑层 Web 质检平台 说话人 数据标注 效果评估 数据分析 语义标签 语音评分 角色识别 基础服务层 自然语言理解 语音分离 + 语音识别 分词 词性标注 … 词向量 自研引擎 供应商1 供应商2
8 . 语音分离 + 语音识别 • 语音分离 • 分离单声 道录音 • 评价指标 • DER(Diarization Error Rate) • 语音识别 • 将语音转 写成文 本 • 评价指标 说话人角色识别: 说话人a -> 坐席 ? • CER(Character Error Rate) 说话人b -> 用户 ?
9 . 单声道语音分离 • DER(分离错误率) • 识别错误的音频的时长总和 / 总时长 错误包括以下三种: 1. false(静音识别为人声) 2. miss(人声识别为静音) 3. confusion(说话人识别错误)
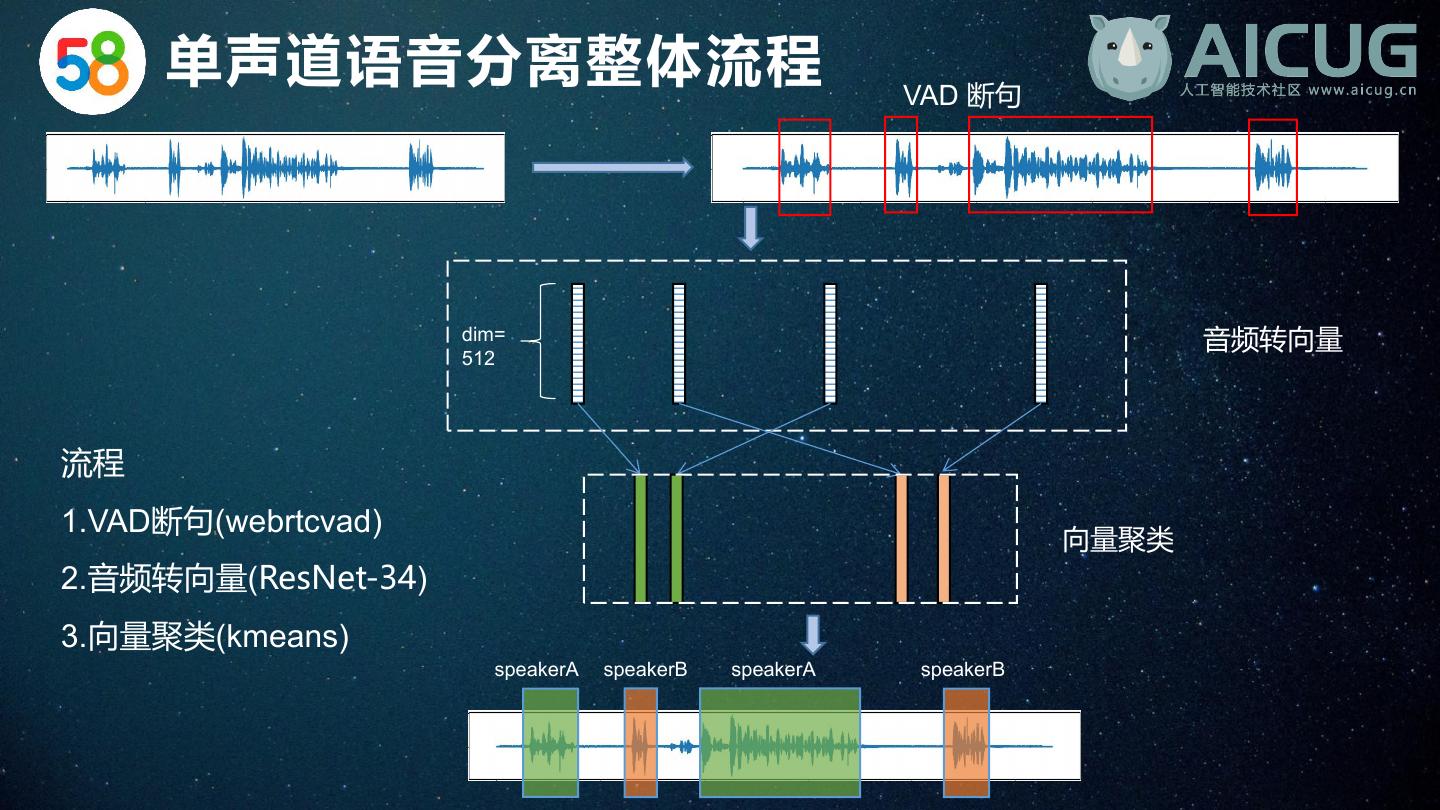
10 . 单声道语音分离整体流程 VAD 断句 dim= 音频转向量 512 流程 1.VAD断句(webrtcvad) 向量聚类 2.音频转向量(ResNet-34) 3.向量聚类(kmeans) speakerA speakerB speakerA speakerB
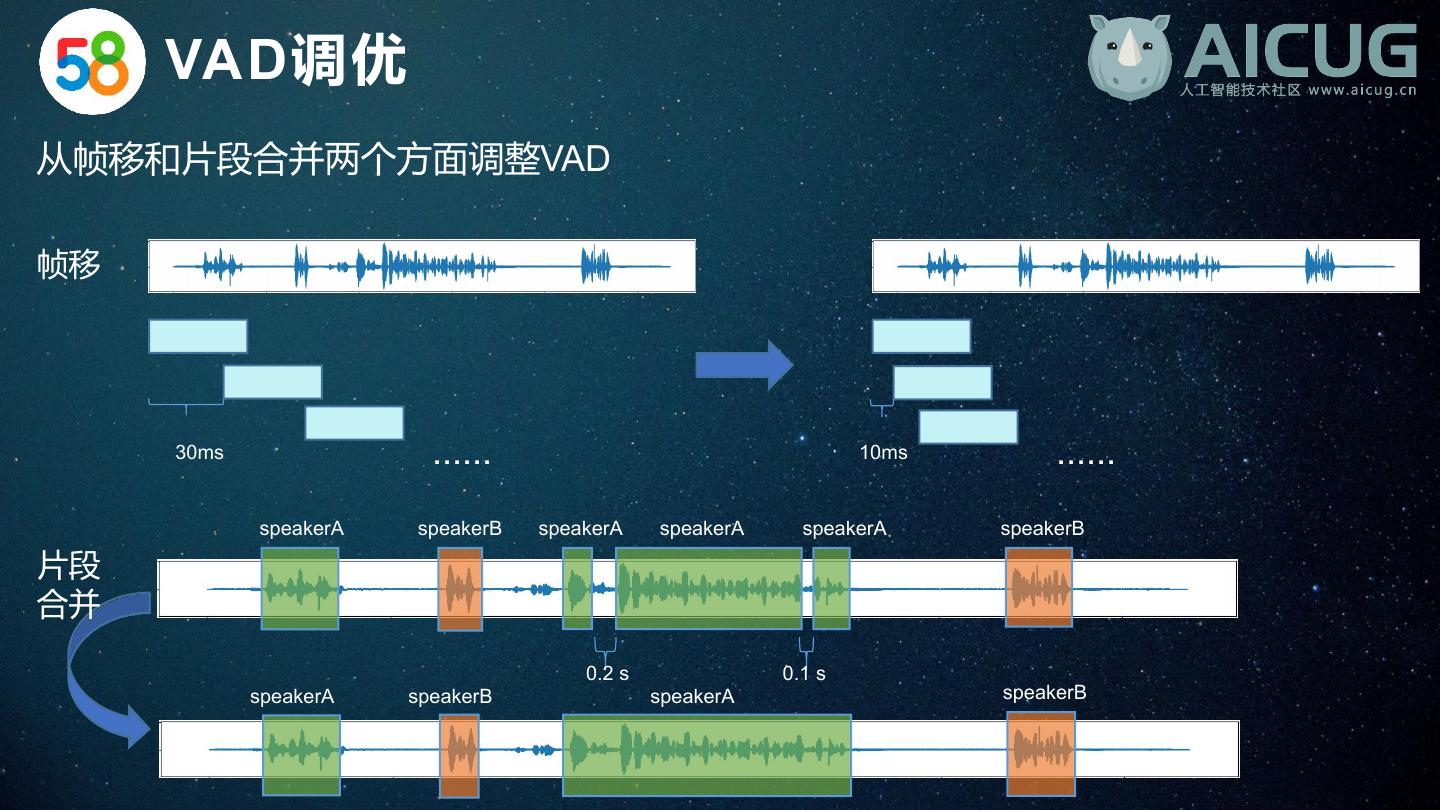
11 . VAD调优 从帧移和片段合并两个方面调整VAD 帧移 30ms ...... 10ms ...... speakerA speakerB speakerA speakerA speakerA speakerB 片段 合并 0.2 s 0.1 s speakerA speakerB speakerA speakerB
12 . 音频转向量 ResNet-34 网络结构 softmax 音频向量 ResNet-34 频谱 采样向量 speakerA
13 . 角色识别 说话人a 坐席 客户 不好意思啊 a 唉哥,打扰了 噢我现在手上 有点事啊 a 我58同城的国 顺! 不好意思 说话人b 啊 b 唉哥,打 噢我现在手上 扰了 有点事啊 b 回头我联系您。 我58同城 的国顺! a 回头我联 系您。 角色识别整体流程
14 . 角色识别主要模型 性别识别模型 单句角色纠正模型 Label 坐席 Softmax Full Connected Layer V0 V1 V2 … VT VS BERT PreTrainModel 2 Layer CLS W1 W2 … WT SEP 模型: 您 还 在 招 人吗 ? VGGish + Bi-lstm + Attention
15 . 质检算法模块-单句标签 TextCNN模型(初版)
16 . 质检算法模块-单句标签 使用业务数据预训练了SPTM(Simple Pre-trained Model)模型 SPTM模(2019.04诞生) Label 客户表示将去投诉 Softmax Full Connected Layer • 一层SPTM推理耗时12ms • 评测效果和BERT-Base持平 V0 V1 V2 … VT-1 VT Simple Pre-trained Model 1layer W0 W1 W2 … WT-1 WT 我真的要去投诉了,一直打电话你们 好意思吗?
17 . 轻量级预训练语言模型SPTM SPTM开源项目地址:https://github.com/wuba/qa_match 19年4月诞生,在18年10月底诞生的BERT基础上改动 ①尝试替换Trm 为Bi-LSTM ②去掉NSP BERT(2018.10) SPTM(2019.04)
18 .轻量级预训练语言模型SPTM • 将Tr a ns f or m e r 替换为B i- LS T M ② 通过预测掩码 的token达到 Pretrain LM ③ 残差学习 ① 随机掩码15% 的token 优点 预训练 / 推理 速度快 缺点 表达能力略有下降
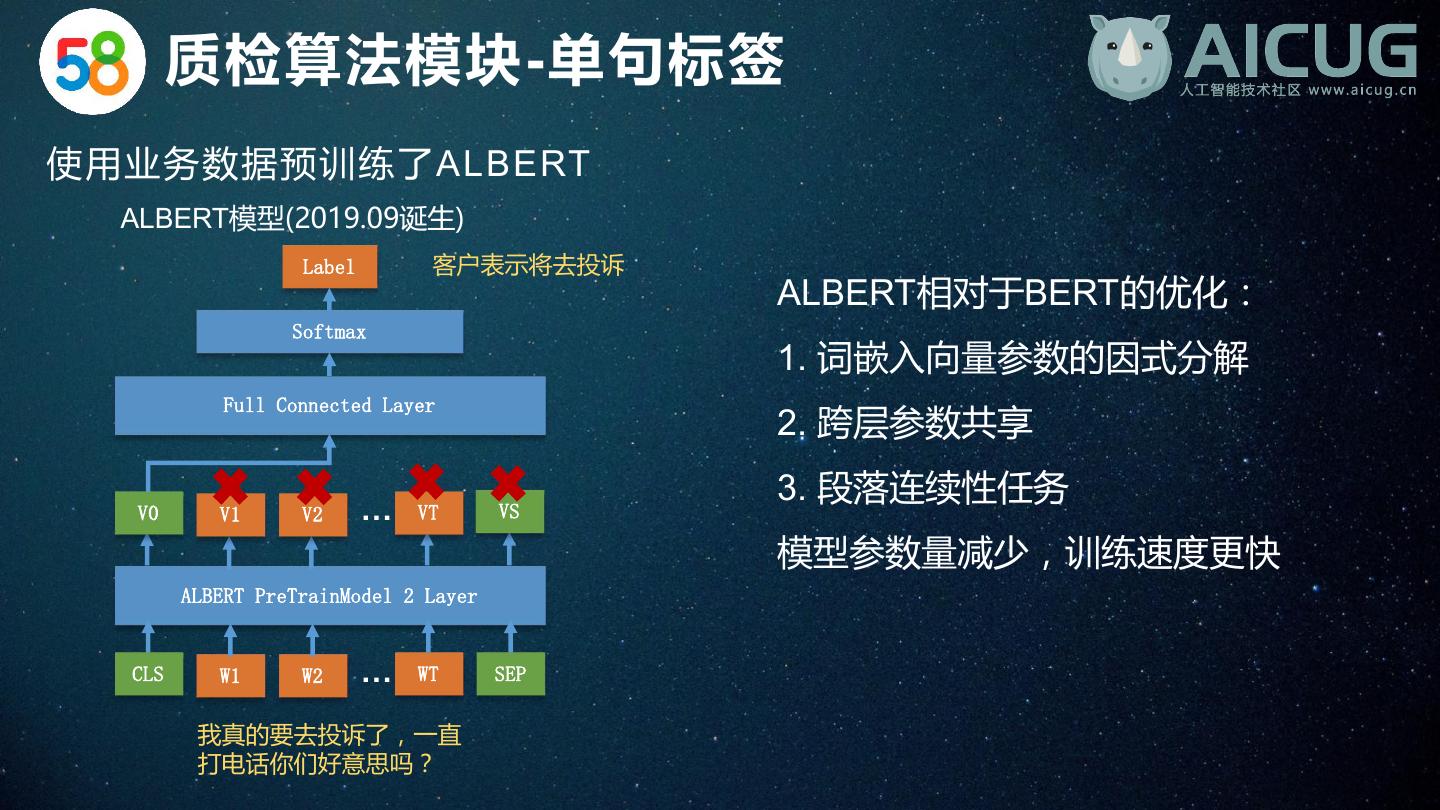
19 . 质检算法模块-单句标签 使用业务数据预训练了ALBERT ALBERT模型(2019.09诞生) Label 客户表示将去投诉 ALBERT相对于BERT的优化: Softmax 1. 词嵌入向量参数的因式分解 Full Connected Layer 2. 跨层参数共享 3. 段落连续性任务 V0 V1 V2 … VT VS 模型参数量减少,训练速度更快 ALBERT PreTrainModel 2 Layer CLS W1 W2 … WT SEP 我真的要去投诉了,一直 打电话你们好意思吗?
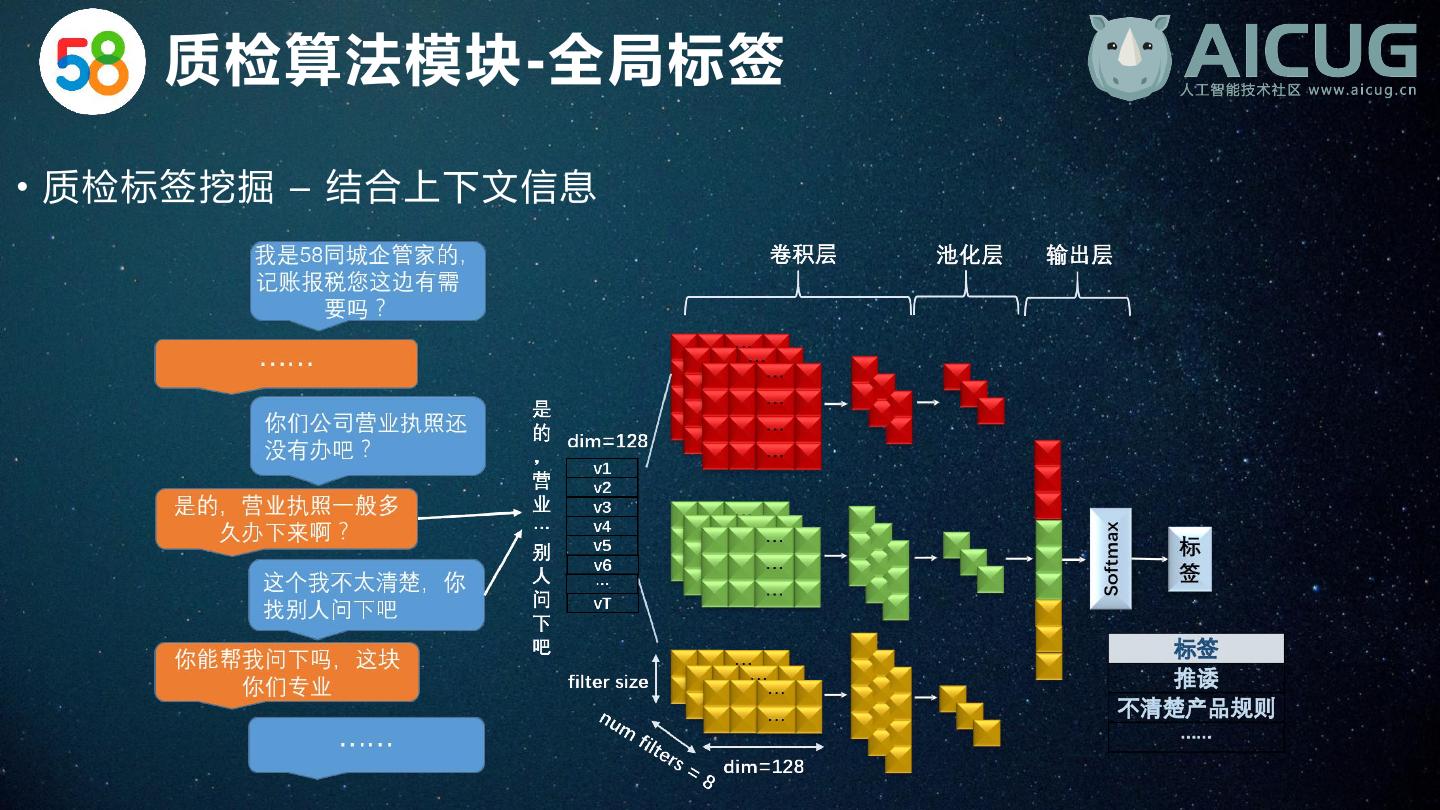
20 . 质检算法模块-全局标签 • 质检标签挖掘 – 结合上下文信息
21 . 质检算法模块 • 质检标签挖掘 – 规则挖掘 NGram规则挖掘 新词发现算法:发现常用 • 发现对正例敏感的规则 的词语或表述 将语料进行分词 利用点互信息筛选出 备用词 通过左右熵输出最终 的新词
22 . Web质检系统 • 机器质检 + 人工复检;辅助人工高效复检
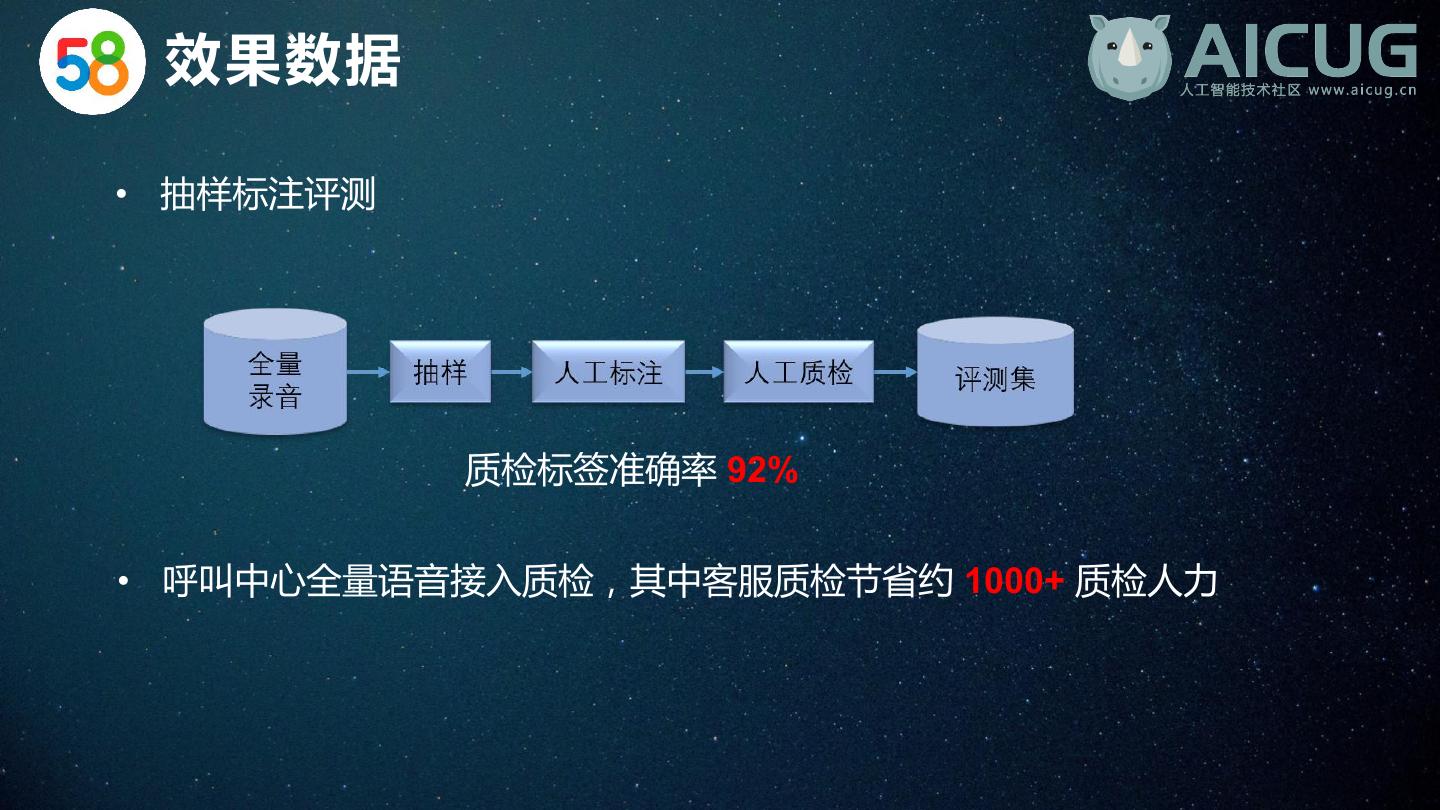
23 . 效果数据 • 抽样标注评测 质检标签准确率 92% • 呼叫中心全量语音接入质检,其中客服质检节省约 1000+ 质检人力
24 . 业务案例-销售高危录音质检 • 判断在销售和客户沟通过程中是否发生高风险行为 • 质检标签 标签类型 标签 客户表示被骚扰 高危标签 客户表示将去投诉 发生辱骂 客户快速挂断(听到58同城) 客户表示不需要 普通标签 客户表示不要再打电话 客户表示电话过多 工作作假-空白通时
25 . 业务案例-销售高危录音质检 • 针对高危录音的管理动作 CRM(销售主管管理) 高危标签录音 电话进入沉寂库 客户表示被骚扰 人工复检 客户表示将去投诉 电话保护180天 发生辱骂 ……
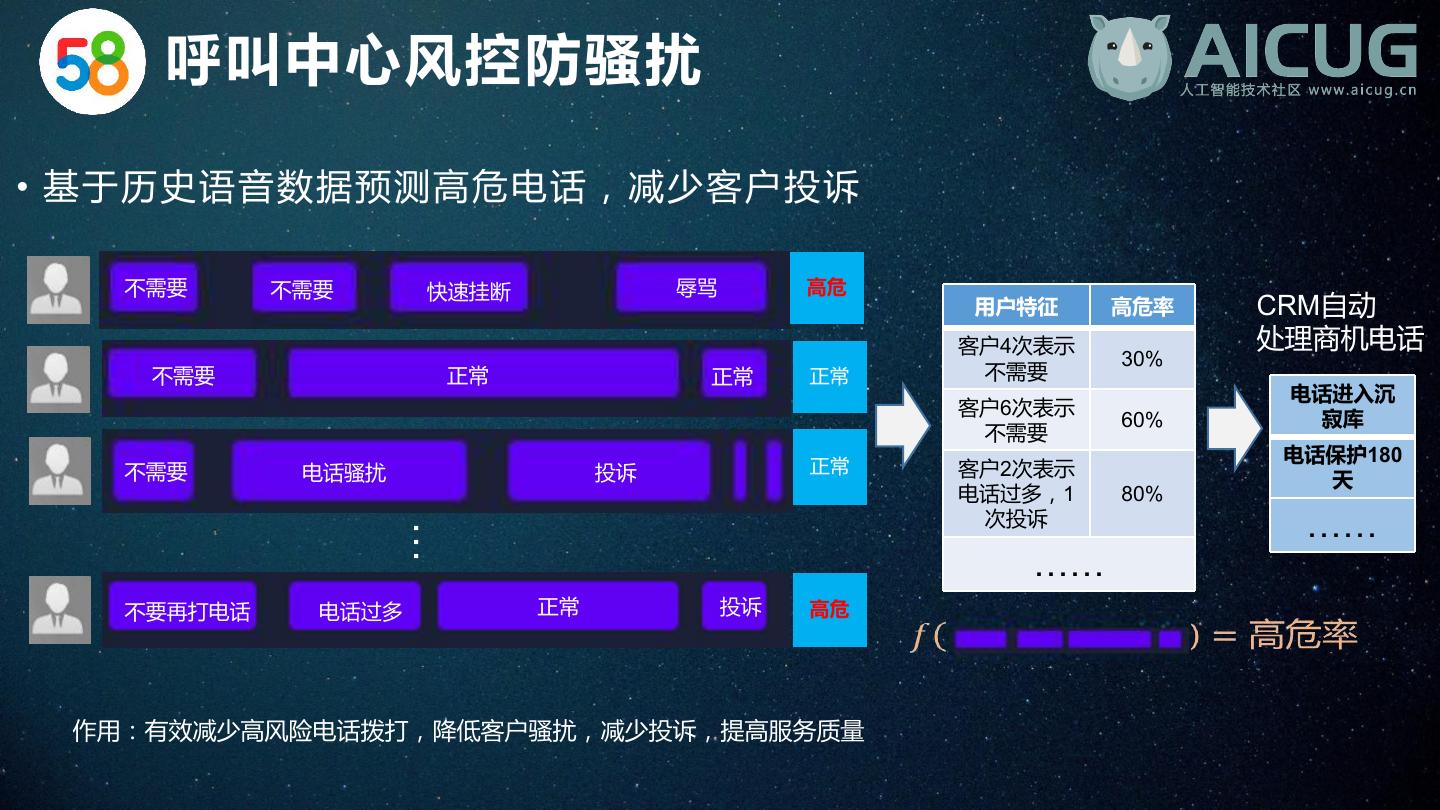
26 . 呼叫中心风控防骚扰 • 基于历史语音数据预测高危电话,减少客户投诉 不需要 不需要 快速挂断 辱骂 高危 用户特征 高危率 CRM自动 客户4次表示 处理商机电话 30% 不需要 正常 正常 正常 不需要 电话进入沉 客户6次表示 60% 寂库 不需要 电话保护180 不需要 电话骚扰 投诉 正常 客户2次表示 天 电话过多,1 80% 次投诉 …… … …… 不要再打电话 电话过多 正常 投诉 高危 作用:有效减少高风险电话拨打,降低客户骚扰,减少投诉,提高服务质量
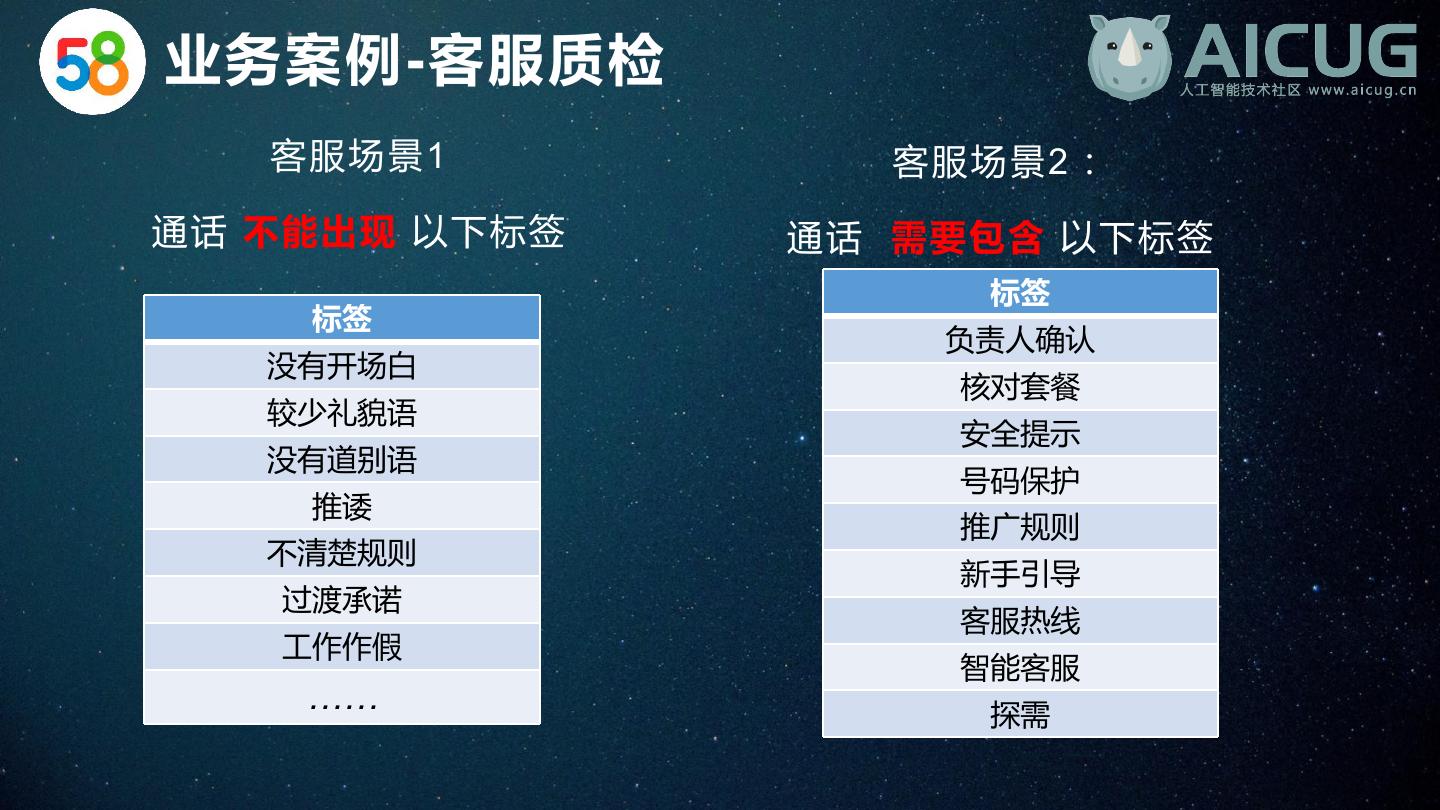
27 .业务案例-客服质检 客服场景1 客服场景2: 通话 不能出现 以下标签 通话 需要包含 以下标签 标签 标签 负责人确认 没有开场白 核对套餐 较少礼貌语 安全提示 没有道别语 号码保护 推诿 推广规则 不清楚规则 新手引导 过渡承诺 客服热线 工作作假 智能客服 …… 探需
28 .AI Lab开源项目推介:qa_match “qa_match是一款基于深度学习的问答匹配工具,支持一层和两层结构 知识库问答。qa_match通过意图匹配模型支持一层结构知识库问答,通 过融合领域分类模型和意图匹配模型的结果支持两层结构知识库问答。 qa_match同时支持无监督预训练功能,通过轻量级预训练语言模型 (SPTM,Simple Pre-trained Model)可以提升基于知识库问答等下 游任务的效果。” • 开源地址 • https://github.com/wuba/qa_match
29 . AI Lab开源项目推介:dl_inference “dl_inference 是58同城开源的通用深度学习推理服务,可在生产环境 中快速上线由TensorFlow、PyTorch和Caffe框架训练出的深度学习模型, 提供GPU和CPU两种部署方式,并且实现了模型多节点部署时的负载均 衡策略,支持线上海量推理请求,dl_inference支撑了58同城各AI场景下 日均超过10亿次的线上推理请求。” • 开源地址 • https://github.com/wuba/dl_inference
3秒后跳转登录页面
去登陆

