

























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
深入Amazon Redshift 构建云上数据分析完善架构
Amazon Redshift 是一种完全托管的 PB 级云原生数据仓库服务。支持以简单且经济高效的方式对 PB 级结构化数据运行高性能查询,与数据湖和AWS云服务实现最深集成。本次将为您分享Redshift高性能逻辑,最佳实践以及AWS推荐的云上数据分析架构。
展开查看详情
1 .深入Amazon Redshift 构建云上数据分析完善架构
2 .Amazon Redshift 简介和典型用例 Amazon Redshift 技术解析 Amazon Redshift 领先特征 通用参考架构
3 .AWS 连续第6年被评为 云数据库领导者 Gartner, Magic Quadrant for Cloud Database Management Systems, Donald Feinberg, Merv Adrian, Rick Greenwald, Adam Ronthal, Henry Cook, 23 November 2020. This graphic was published by Gartner, Inc. as part of a larger research document and should be evaluated in the context of the entire document. The Gartner document is available upon request from AWS. Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose. © 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
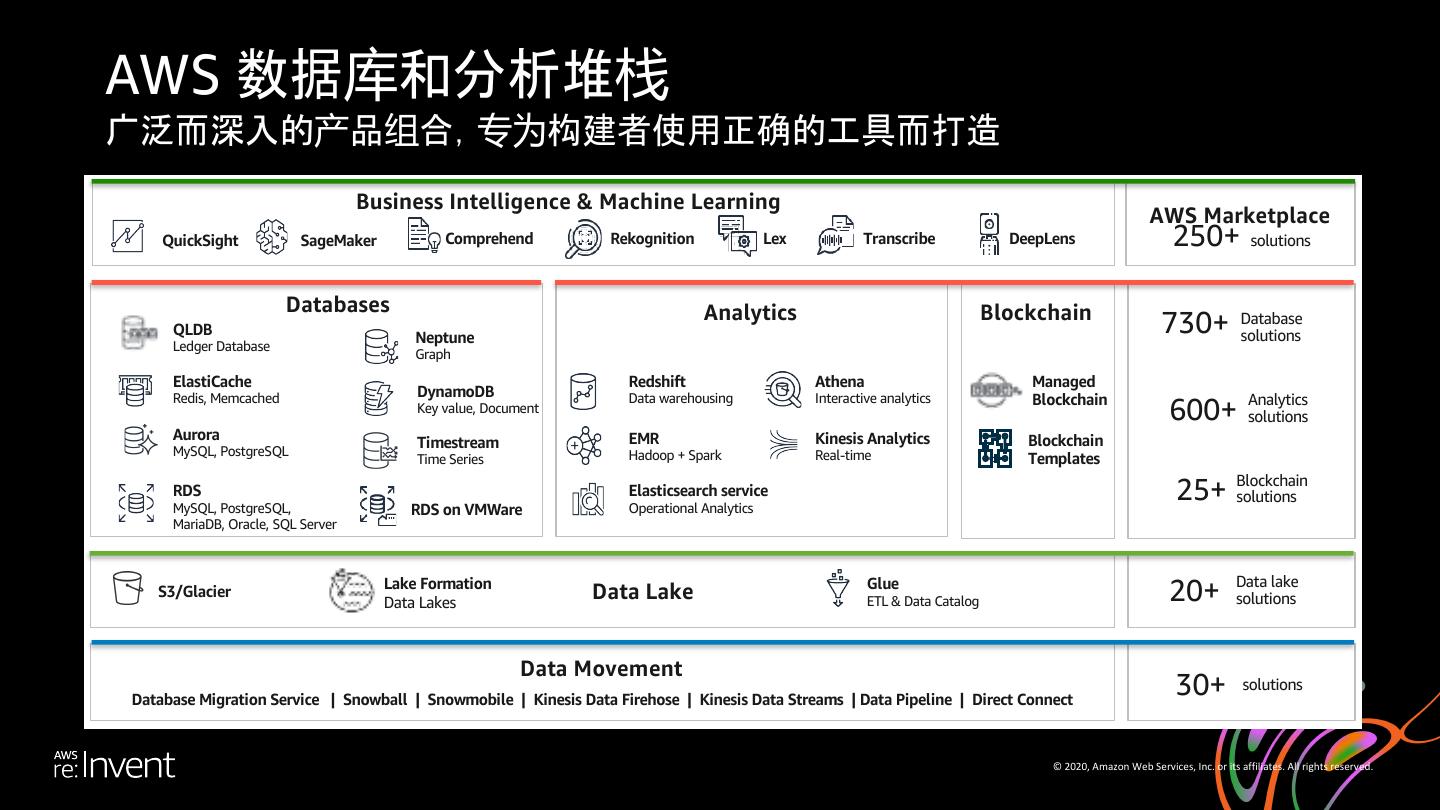
4 .AWS 数据库和分析堆栈 广泛而深入的产品组合,专为构建者使用正确的工具而打造 Business Intelligence & Machine Learning AWS Marketplace QuickSight SageMaker Comprehend Rekognition Lex Transcribe DeepLens 250+ solutions Databases Analytics Blockchain QLDB Neptune 730+ Database solutions Ledger Database Graph ElastiCache Redshift Athena Managed Redis, Memcached DynamoDB Data warehousing Interactive analytics Blockchain Analytics Key value, Document 600+ solutions Aurora Timestream EMR Kinesis Analytics Blockchain MySQL, PostgreSQL Hadoop + Spark Real-time Time Series Templates Blockchain RDS MySQL, PostgreSQL, RDS on VMWare Elasticsearch service Operational Analytics 25+ solutions MariaDB, Oracle, SQL Server Data lake S3/Glacier Lake Formation Data Lakes Data Lake Glue ETL & Data Catalog 20+ solutions Data Movement Database Migration Service | Snowball | Snowmobile | Kinesis Data Firehose | Kinesis Data Streams | Data Pipeline | Direct Connect 30+ solutions © 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
5 .Amazon Redshift 概要 Forrester Wave™ Big Data Warehouse Q4 2018 AWS 名列前 Amazon Redshift 当今云数据仓库的代表:是延 茅,并在许多 伸到数据湖的数据仓库 领域(如用例、 路线图、市场 • 不是独立的数据仓库,而是与数据湖无缝集成的数据仓库, 意识和执行能 力)中获得了 使数据保持“自由” 最高分(5/5 • 完全托管、ACID 和 ANSI SQL 兼容的云数据仓库 分)。 • 大规模并行,无共享 OLAP 体系结构,列式数据存储,支持 Gartner Magic Quadrant, 2018 从 GB 到 PB 级数据查询 AWS 定位 为 Gartner • 自动缩放,计算和存储容量可以独立扩展 数据管理 魔力象限 • 端到端加密,通过 SOC 1/2/3、HIPAA、FedRamp 合规认 的领导者 证等,确保安全 分析解决方案 • 全球高度评价和最受欢迎的云数据仓库(超过一万个部署) © 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
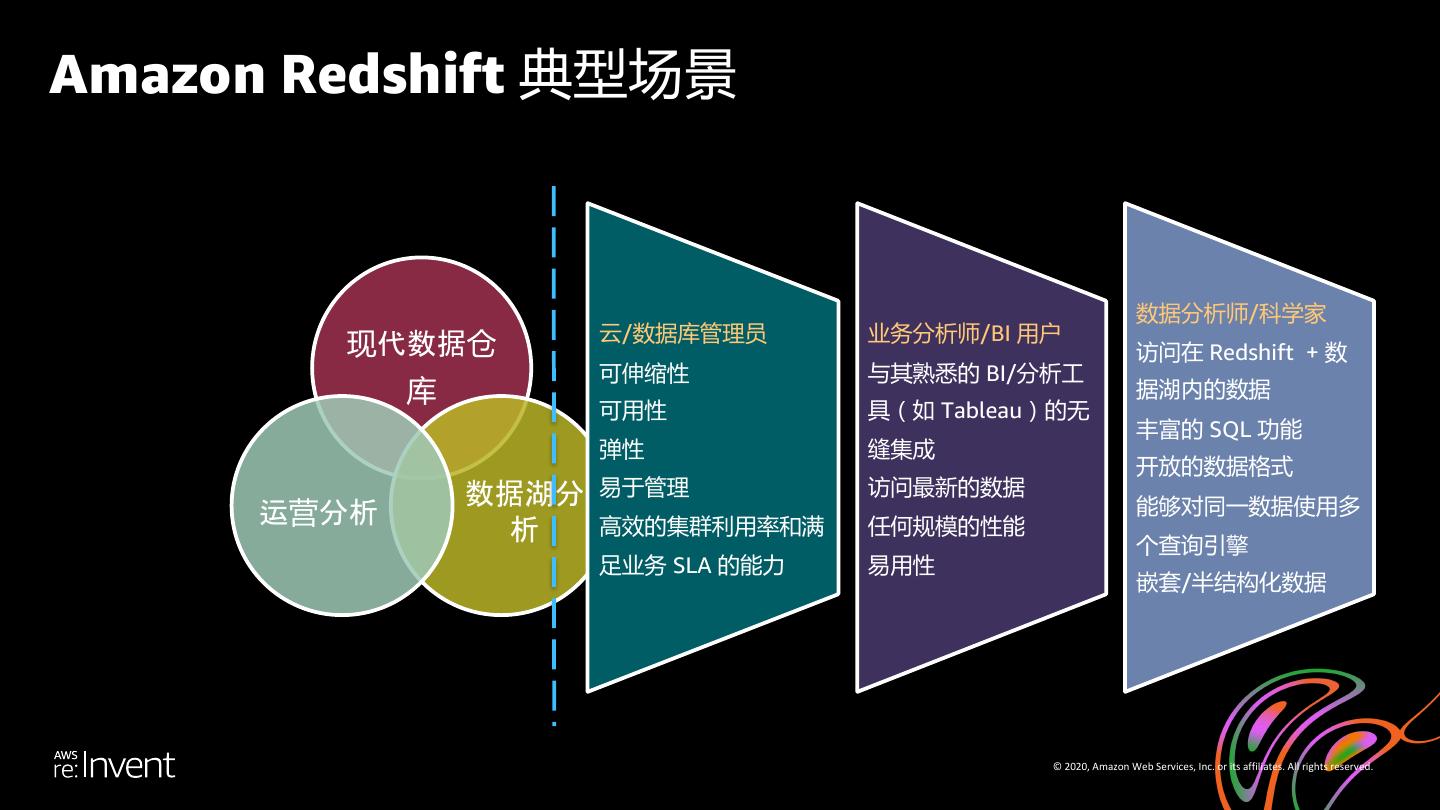
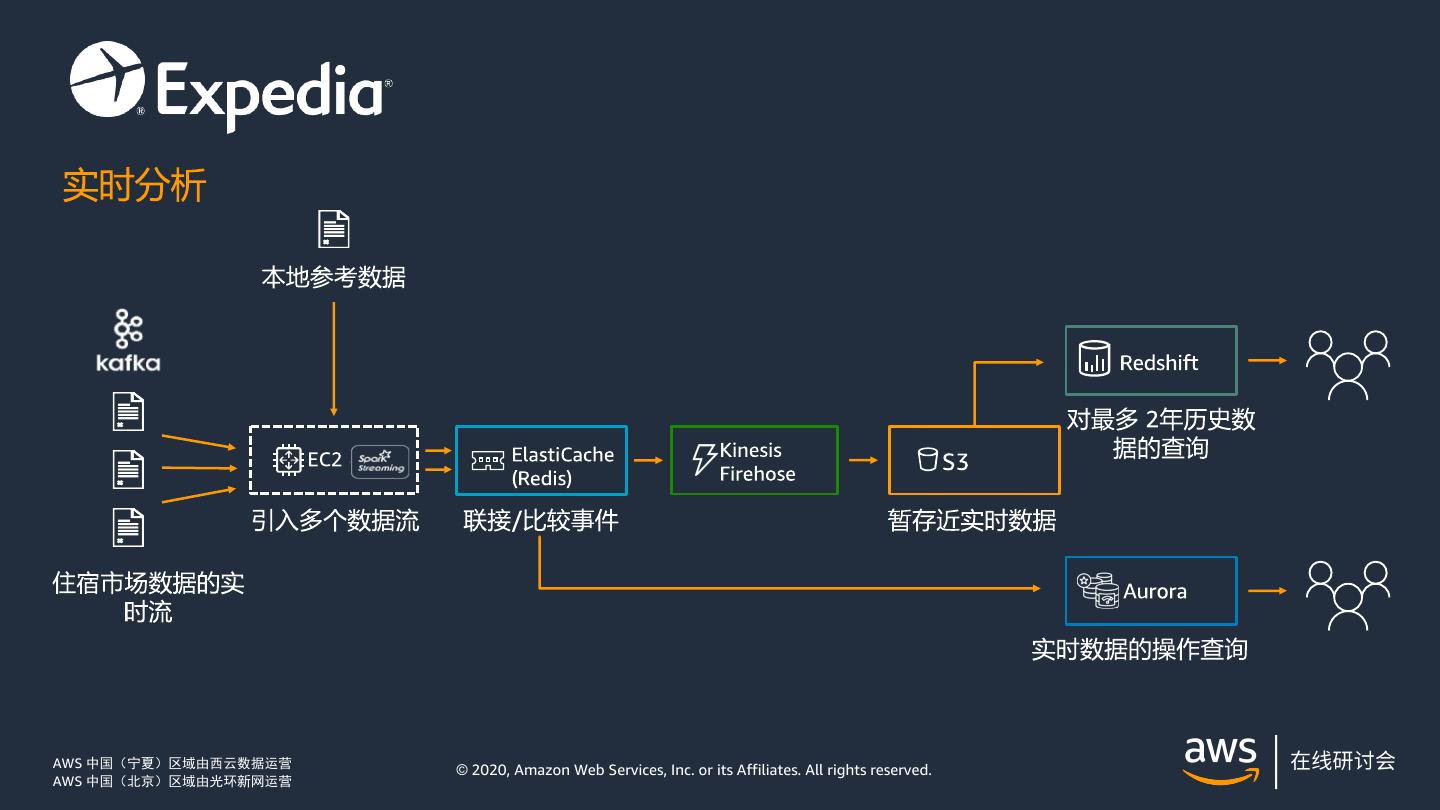
6 .Amazon Redshift 典型场景 数据分析师/科学家 云/数据库管理员 业务分析师/BI 用户 现代数据仓 访问在 Redshift + 数 可伸缩性 与其熟悉的 BI/分析工 库 据湖内的数据 可用性 具(如 Tableau)的无 丰富的 SQL 功能 弹性 缝集成 开放的数据格式 数据湖分 易于管理 访问最新的数据 运营分析 能够对同一数据使用多 析 高效的集群利用率和满 任何规模的性能 个查询引擎 足业务 SLA 的能力 易用性 嵌套/半结构化数据 © 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
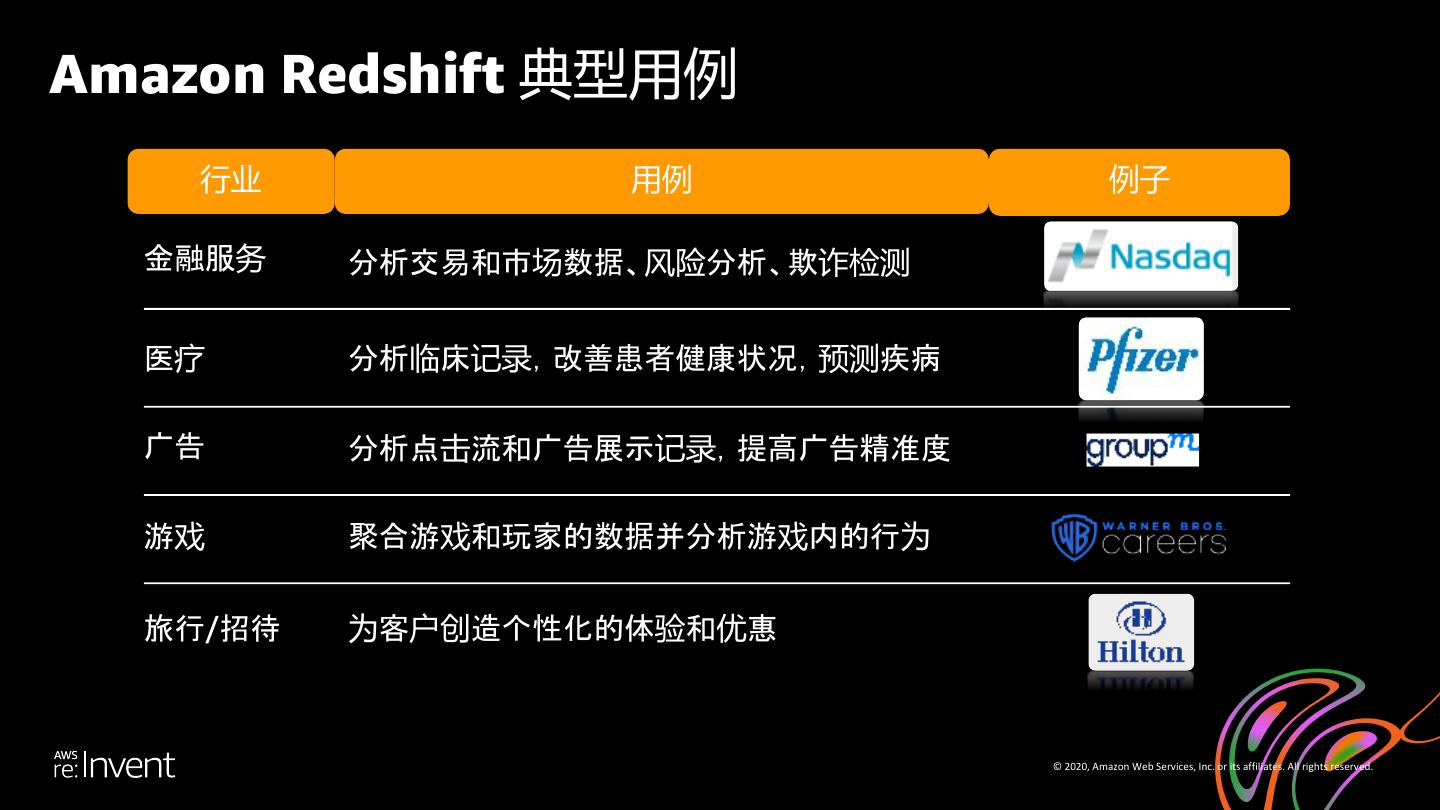
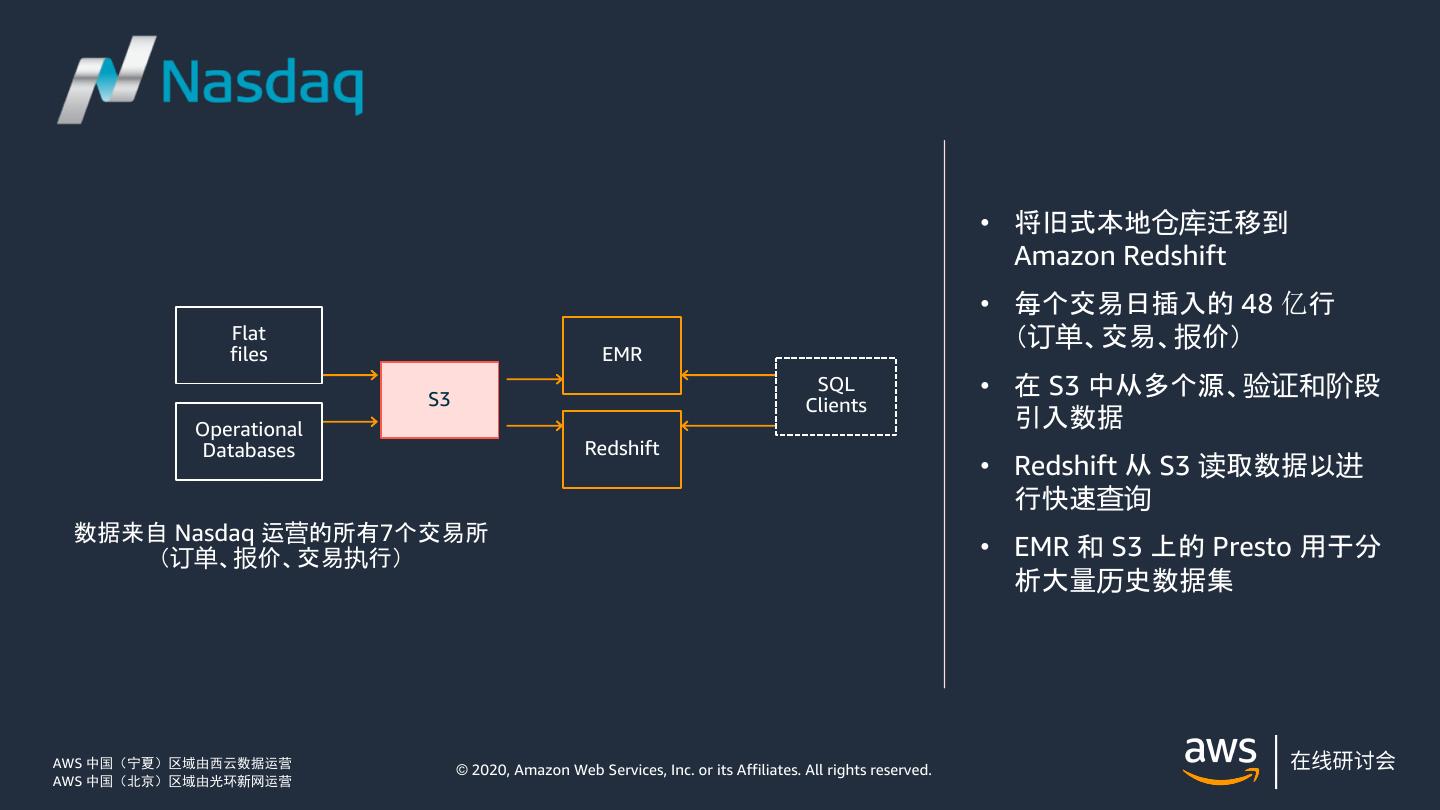
7 .Amazon Redshift 典型用例 行业 用例 例子 金融服务 分析交易和市场数据、风险分析、欺诈检测 医疗 分析临床记录,改善患者健康状况,预测疾病 广告 分析点击流和广告展示记录,提高广告精准度 游戏 聚合游戏和玩家的数据并分析游戏内的行为 旅行/招待 为客户创造个性化的体验和优惠 © 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
8 .Amazon Redshift 简介和典型用例 Amazon Redshift 技术解析 Amazon Redshift 领先特征 通用参考架构
9 .云原生架构 更好的性能、更低的成本 © 2020, Amazon Web Services, Inc. or its affiliates. All rights reserved.
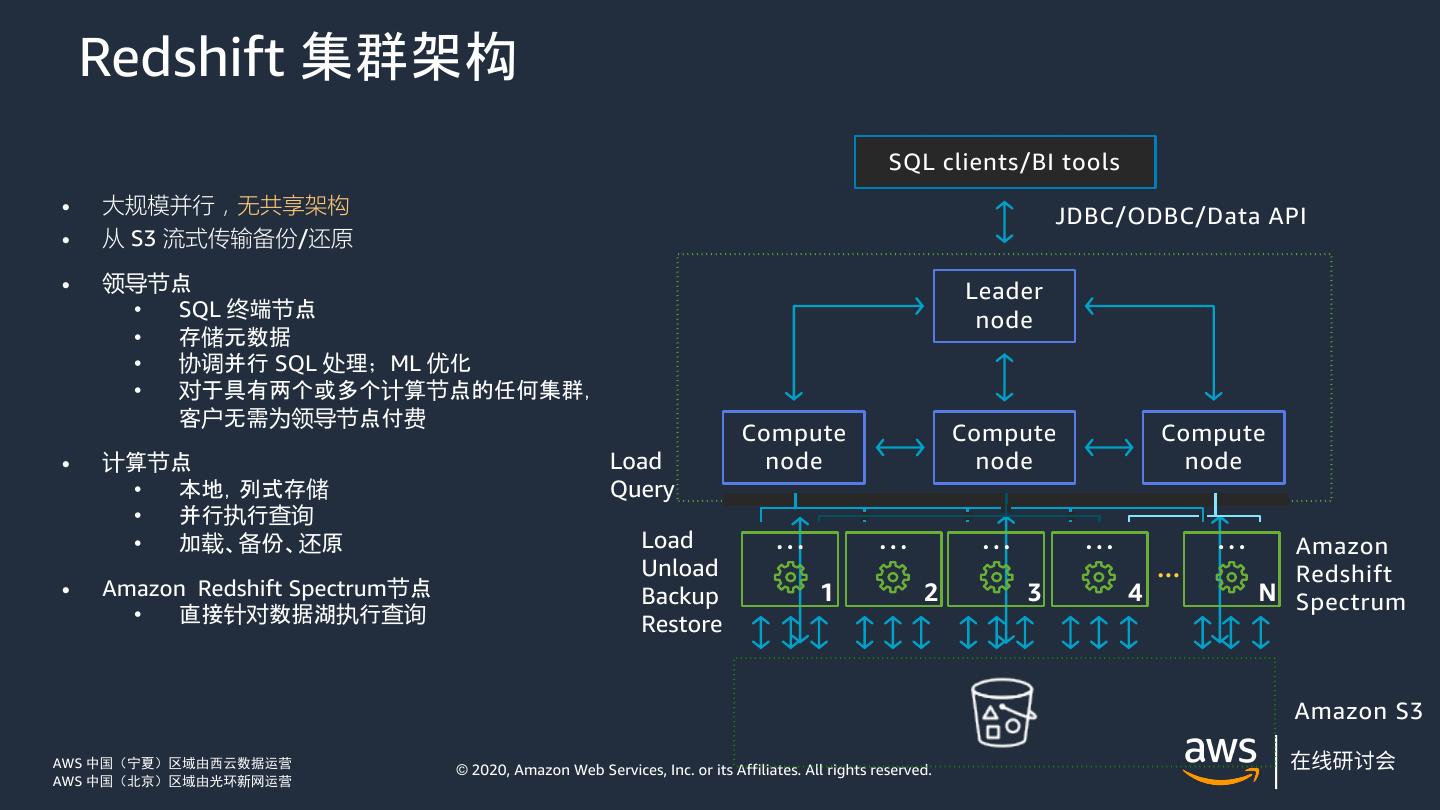
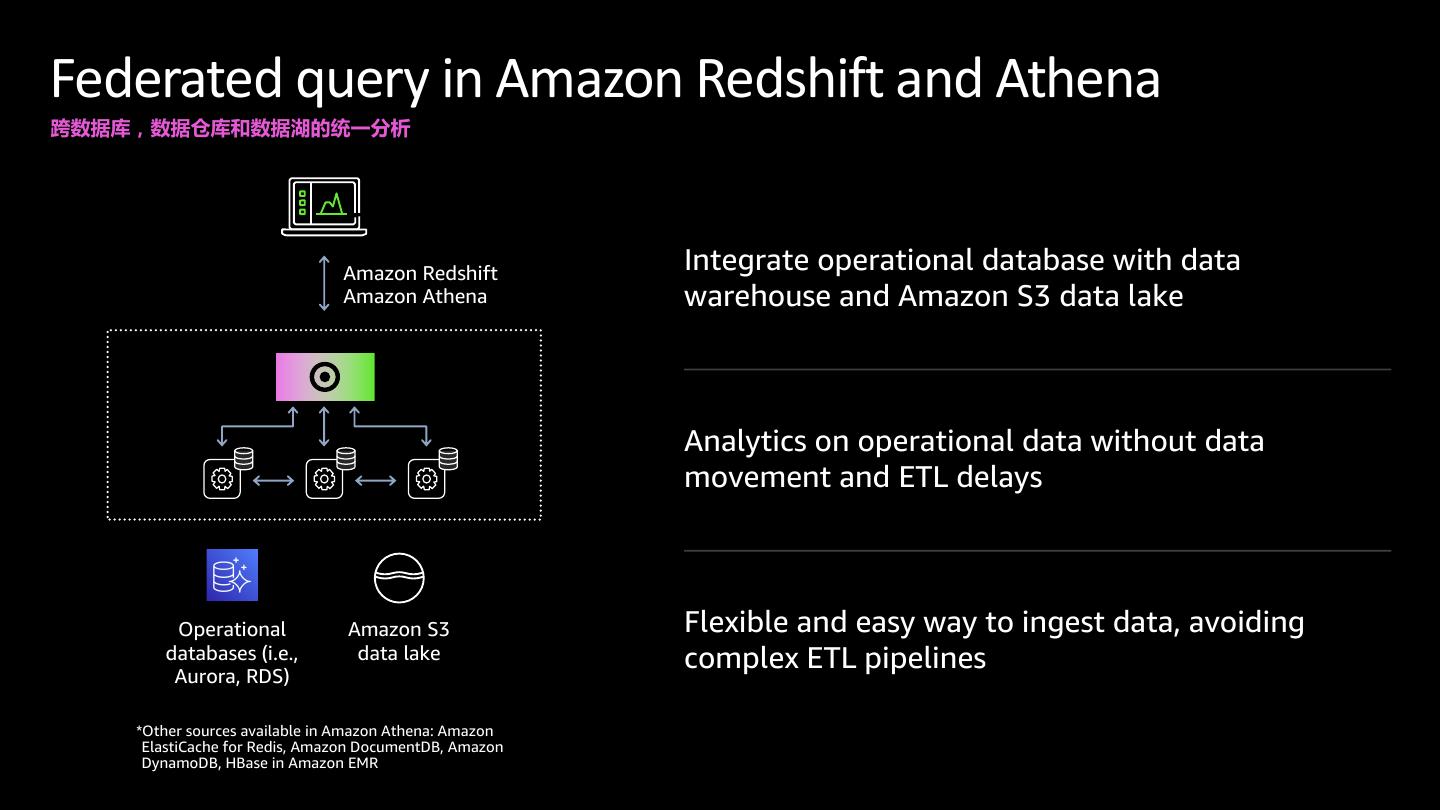
10 . Redshift 集群架构 SQL clients/BI tools • 大规模并行,无共享架构 JDBC/ODBC/Data API • 从 S3 流式传输备份/还原 • 领导节点 Leader • SQL 终端节点 node • 存储元数据 • 协调并行 SQL 处理;ML 优化 • 对于具有两个或多个计算节点的任何集群, 客户无需为领导节点付费 Compute Compute Compute • 计算节点 Load node node node • 本地,列式存储 Query • 并行执行查询 • 加载、备份、还原 Load Amazon Unload ... Redshift • Amazon Redshift Spectrum节点 Backup 1 2 3 4 N Spectrum • 直接针对数据湖执行查询 Restore Amazon S3 AWS 中国(宁夏)区域由西云数据运营 © 2020, Amazon Web Services, Inc. or its Affiliates. All rights reserved. AWS 中国(北京)区域由光环新网运营
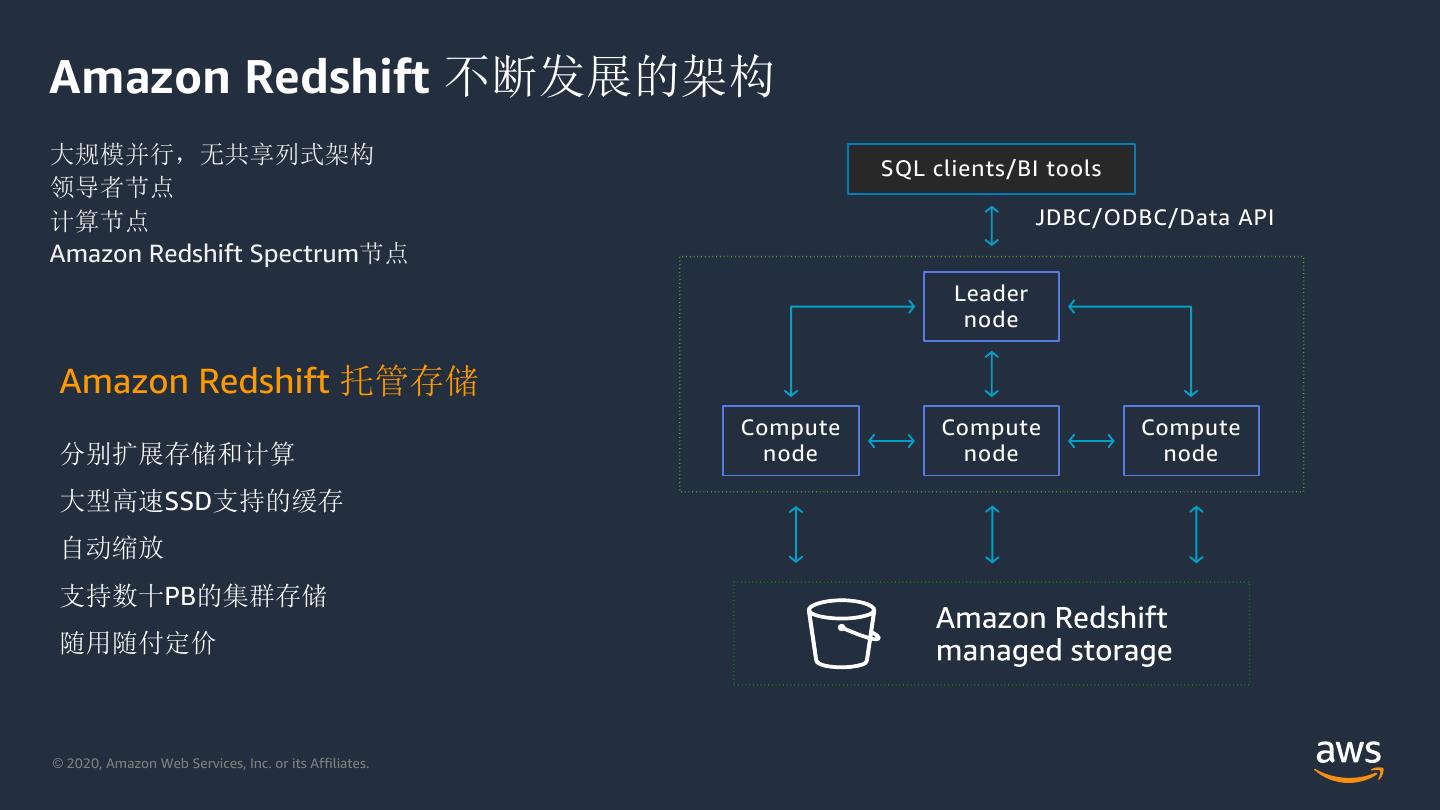
11 .Amazon Redshift 不断发展的架构 大规模并行,无共享列式架构 SQL clients/BI tools 领导者节点 计算节点 JDBC/ODBC/Data API Amazon Redshift Spectrum节点 Leader node Amazon Redshift 托管存储 Compute Compute Compute 分别扩展存储和计算 node node node 大型高速SSD支持的缓存 自动缩放 支持数十PB的集群存储 随用随付定价 © 2020, Amazon Web Services, Inc. or its Affiliates.
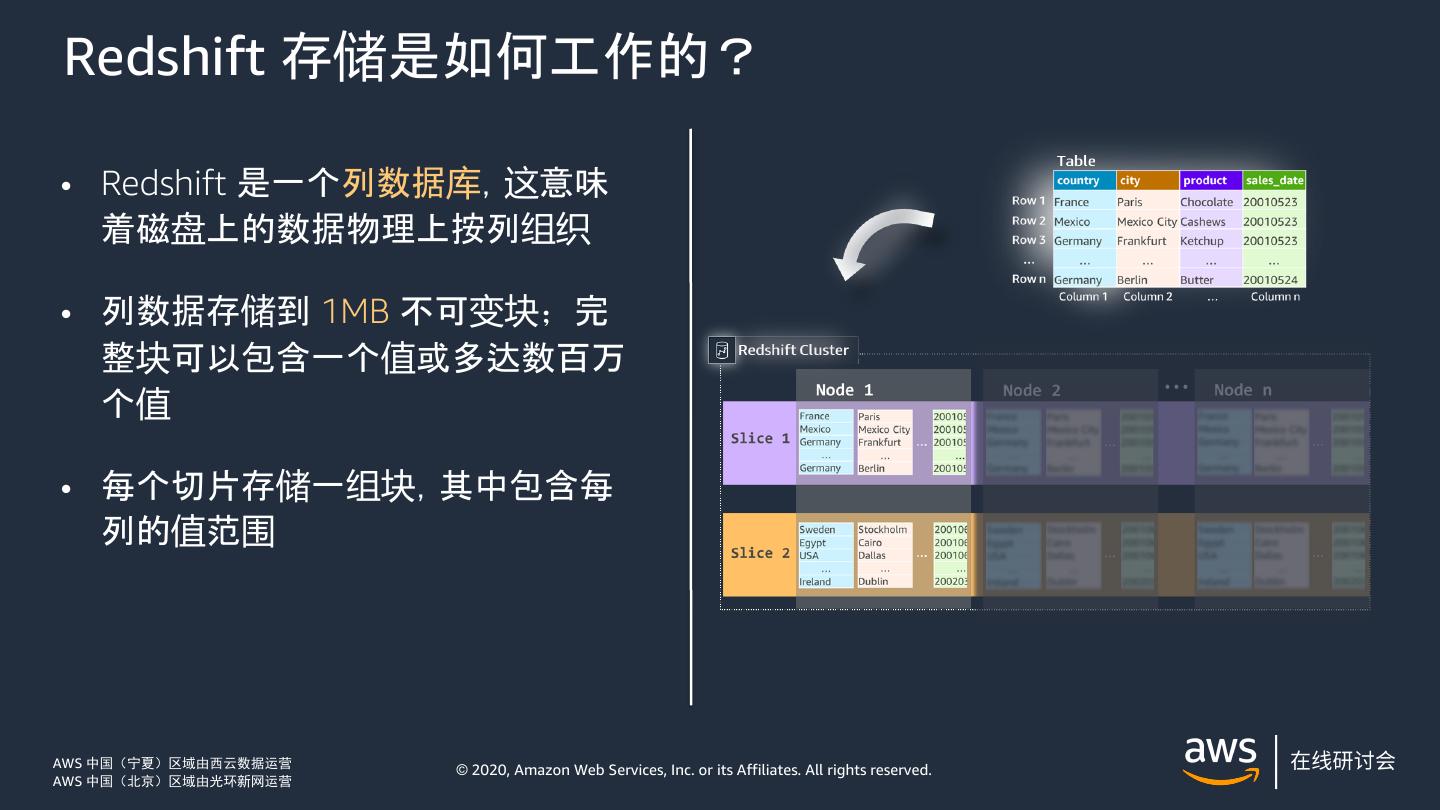
12 .Redshift 存储是如何工作的? • Redshift 是一个列数据库,这意味 着磁盘上的数据物理上按列组织 • 列数据存储到 1MB 不可变块;完 整块可以包含一个值或多达数百万 个值 • 每个切片存储一组块,其中包含每 列的值范围 AWS 中国(宁夏)区域由西云数据运营 © 2020, Amazon Web Services, Inc. or its Affiliates. All rights reserved. AWS 中国(北京)区域由光环新网运营
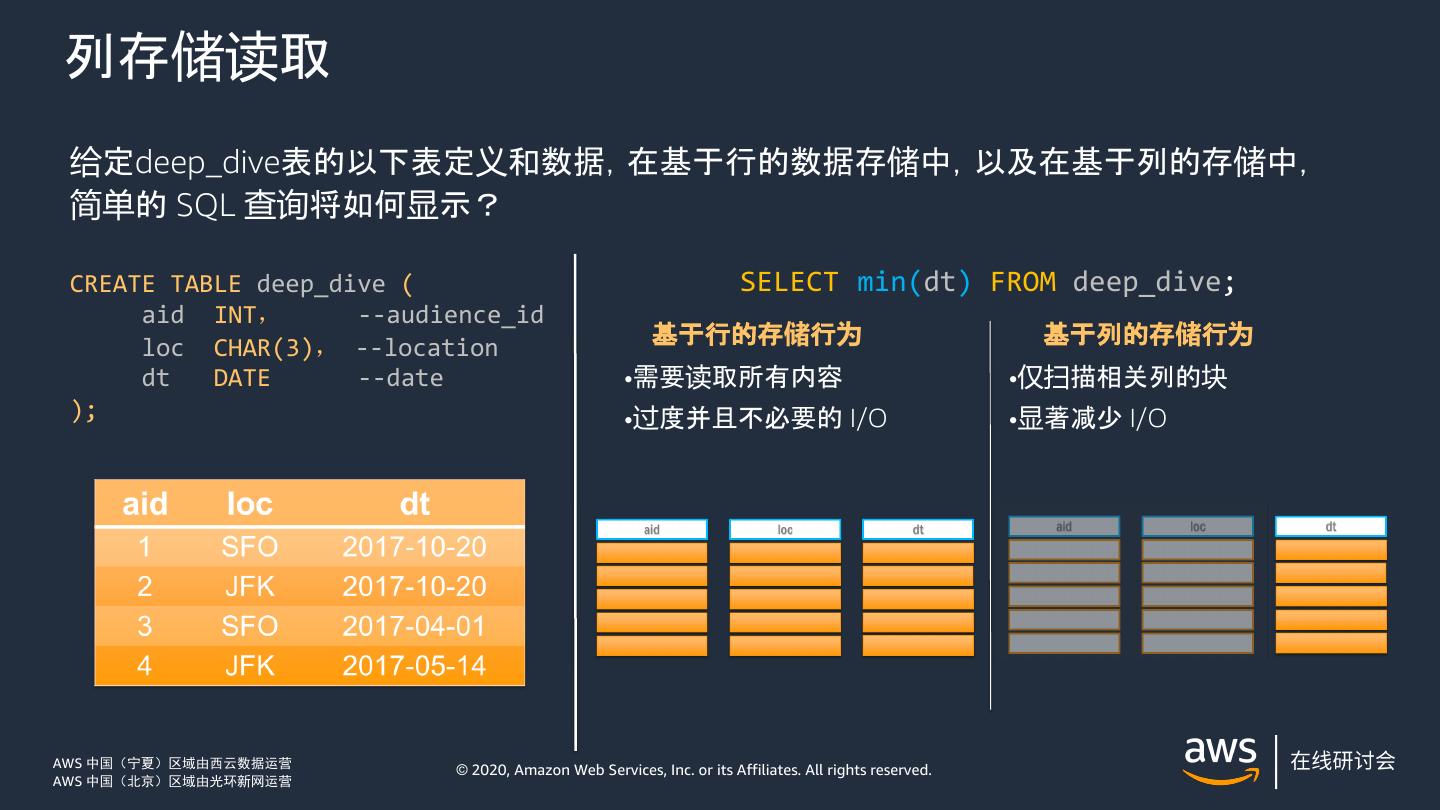
13 .列存储读取 给定deep_dive表的以下表定义和数据,在基于行的数据存储中,以及在基于列的存储中, 简单的 SQL 查询将如何显示? CREATE TABLE deep_dive ( SELECT min(dt) FROM deep_dive; aid INT, --audience_id 基于行的存储行为 基于列的存储行为 loc CHAR(3), --location dt DATE --date •需要读取所有内容 •仅扫描相关列的块 ); •过度并且不必要的 I/O •显著减少 I/O AWS 中国(宁夏)区域由西云数据运营 © 2020, Amazon Web Services, Inc. or its Affiliates. All rights reserved. AWS 中国(北京)区域由光环新网运营
14 .列压缩 CREATE TABLE deep_dive ( aid INT ENCODE AZ64 aid loc dt ,loc CHAR(3) ENCODE BYTEDICT 1 SFO 2017-10-20 ,dt DATE ENCODE RUNLENGTH ); 2 JFK 2017-10-20 3 SFO 2017-04-01 4 JFK 2017-05-14 aid loc dt • 列式压缩非常好 • 单个列中的每个值都具有相同的数据类型 • 单个列中可能具有重复值 • Redshift 通常可实现 3-4 倍的数据压缩比 • 压缩可降低存储要求,也通过降低 I/O 来提高性能 • 列在 Redshift 中独立增长和收缩
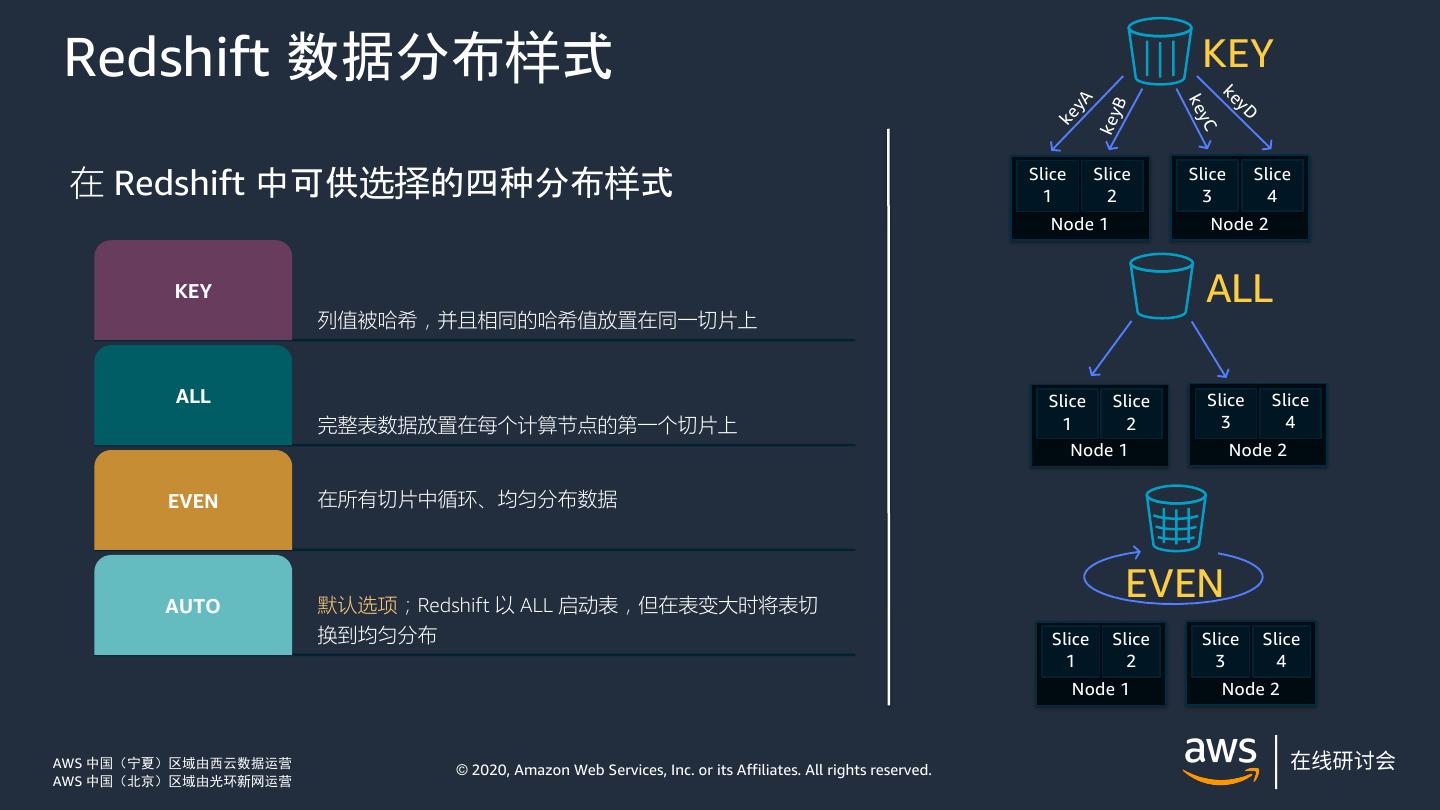
15 .Redshift 数据分布样式 KEY ke yD yA ke B key ke yC 在 Redshift 中可供选择的四种分布样式 Slice 1 Slice 2 Slice 3 Slice 4 Node 1 Node 2 KEY ALL 列值被哈希,并且相同的哈希值放置在同一切片上 ALL Slice Slice Slice Slice 完整表数据放置在每个计算节点的第一个切片上 1 2 3 4 Node 1 Node 2 EVEN 在所有切片中循环、均匀分布数据 AUTO 默认选项;Redshift 以 ALL 启动表,但在表变大时将表切 EVEN 换到均匀分布 Slice Slice Slice Slice 1 2 3 4 Node 1 Node 2 AWS 中国(宁夏)区域由西云数据运营 © 2020, Amazon Web Services, Inc. or its Affiliates. All rights reserved. AWS 中国(北京)区域由光环新网运营
16 .数据分布:EVEN 示例 给定 deep_dive 表的定义,插入新行,并查看双节点 Redshift 集群的 EVEN 分布样式,每个节 点具有两个切片 CREATE TABLE deep_dive ( INSERT INTO deep_dive VALUES aid INT --audience_id (1, 'SFO', '2016-09-01'), ,loc CHAR(3) --location (2, 'JFK', '2016-09-14'), ,dt DATE --date (3, 'SFO', '2017-04-01'), ) DISTSTYLE EVEN; (4, 'JFK', '2017-05-14'); Node 1 Node 2 Table: deep_dive Slice 0 Slice 1 Slice 2 Slice 3 User Columns System Columns aid loc dt ins del row # Rows: 10 # Rows: 10 # Rows: 10 # Rows: 10 AWS 中国(宁夏)区域由西云数据运营 © 2020, Amazon Web Services, Inc. or its Affiliates. All rights reserved. AWS 中国(北京)区域由光环新网运营
17 .数据分布:KEY 示例 (高基数键) 给定 deep_dive 表的定义,插入新行,并查看双节点 Redshift 集群的 KEY 分布样式(使用辅助 列作为键列),每个节点具有两个切片 选择具有高基数的分 CREATE TABLE deep_dive ( INSERT INTO deep_dive VALUES 布键对于避免行倾 aid INT --audience_id (1, 'SFO', '2016-09-01'), 斜非常重要 ,loc CHAR(3) --location (2, 'JFK', '2016-09-14'), ,dt DATE --date (3, 'SFO', '2017-04-01'), ) DISTSTYLE KEY DISTKEY (aid); (4, 'JFK', '2017-05-14'); Node 1 Node 2 Table: deep_dive Slice 0 Slice 1 Slice 2 Slice 3 User Columns System Columns aid loc dt ins del row # Rows: 10 # Rows: 10 # Rows: 10 # Rows: 10 AWS 中国(宁夏)区域由西云数据运营 © 2020, Amazon Web Services, Inc. or its Affiliates. All rights reserved. AWS 中国(北京)区域由光环新网运营
18 .数据分布:ALL 示例 给定 deep_dive 表的定义,插入新行,并查看双节点 Redshift 集群的 ALL 分布样式,每个节点 具有两个切片 CREATE TABLE deep_dive ( INSERT INTO deep_dive VALUES aid INT --audience_id (1, 'SFO', '2016-09-01'), ,loc CHAR(3) --location (2, 'JFK', '2016-09-14'), ,dt DATE --date (3, 'SFO', '2017-04-01'), ) DISTSTYLE ALL; (4, 'JFK', '2017-05-14'); Node 1 Node 2 Table: deep_dive Slice 0 Slice 1 Slice 2 Slice 3 User Columns System Columns aid loc dt ins del row # Rows: 32104 # Rows: 0 # Rows: 13240 # Rows: 0 AWS 中国(宁夏)区域由西云数据运营 © 2020, Amazon Web Services, Inc. or its Affiliates. All rights reserved. AWS 中国(北京)区域由光环新网运营
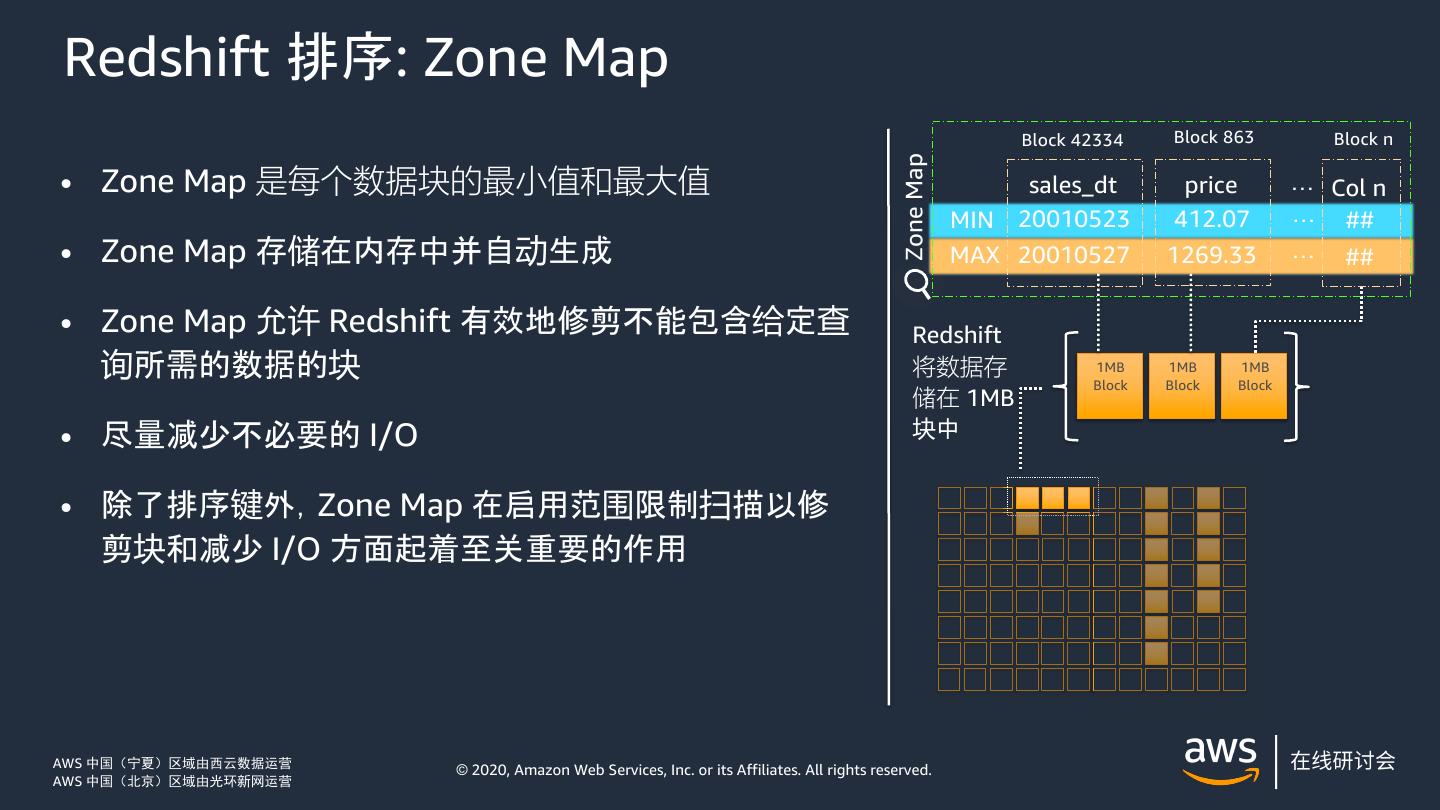
19 .Redshift 排序: Zone Map Block 42334 Block 863 Block n Zone Map • Zone Map 是每个数据块的最小值和最大值 sales_dt price … Col n MIN 20010523 412.07 … ## • Zone Map 存储在内存中并自动生成 MAX 20010527 1269.33 … ## • Zone Map 允许 Redshift 有效地修剪不能包含给定查 Redshift 询所需的数据的块 将数据存 1MB Block 1MB Block 1MB Block 储在 1MB • 尽量减少不必要的 I/O 块中 • 除了排序键外,Zone Map 在启用范围限制扫描以修 剪块和减少 I/O 方面起着至关重要的作用 AWS 中国(宁夏)区域由西云数据运营 © 2020, Amazon Web Services, Inc. or its Affiliates. All rights reserved. AWS 中国(北京)区域由光环新网运营
20 .Redshift 排序: Sort Key • Redshift 使用 Sort Key 在磁盘上物理排序数据 • 结合 Zone Map,Sort Key 可启用范围限制扫描以修 Redshift 排序 剪块并减少 I/O • 与 Zone Map 组合起来的 Sort Key 的功能类似于一 通过在一个或多个列上指定 SORTKEY 表属性,可以将排序键添 组给定列的索引 加到表中 • Sort Key 有利于 MERGE JOIN 性能,排序速度更快 • Redshift 支持两种类型的排序键 • 复合排序键(默认) • 交错排序键 AWS 中国(宁夏)区域由西云数据运营 © 2020, Amazon Web Services, Inc. or its Affiliates. All rights reserved. AWS 中国(北京)区域由光环新网运营
21 .Zone Map 和 Sort Key:示例 未排序的表 按日期排序 SELECT count(*) FROM deep_dive MIN: 01-JUNE-2017 MIN: 01-JUNE-2017 WHERE dt = '06-09-2017'; MAX: 20-JUNE-2017 MAX: 06-JUNE-2017 MIN: 08-JUNE-2017 MIN: 07-JUNE-2017 MAX: 30-JUNE-2017 MAX: 12-JUNE-2017 Zone Map 和 Sort Key 可以 通过减少查询执行期间检查 的块数(最终是 I/O)达到显 MIN: 12-JUNE-2017 MIN: 13-JUNE-2017 著优化的目的 MAX: 20-JUNE-2017 MAX: 21-JUNE-2017 MIN: 02-JUNE-2017 MIN: 21-JUNE-2017 MAX: 25-JUNE-2017 MAX: 30-JUNE-2017 AWS 中国(宁夏)区域由西云数据运营 © 2020, Amazon Web Services, Inc. or its Affiliates. All rights reserved. AWS 中国(北京)区域由光环新网运营
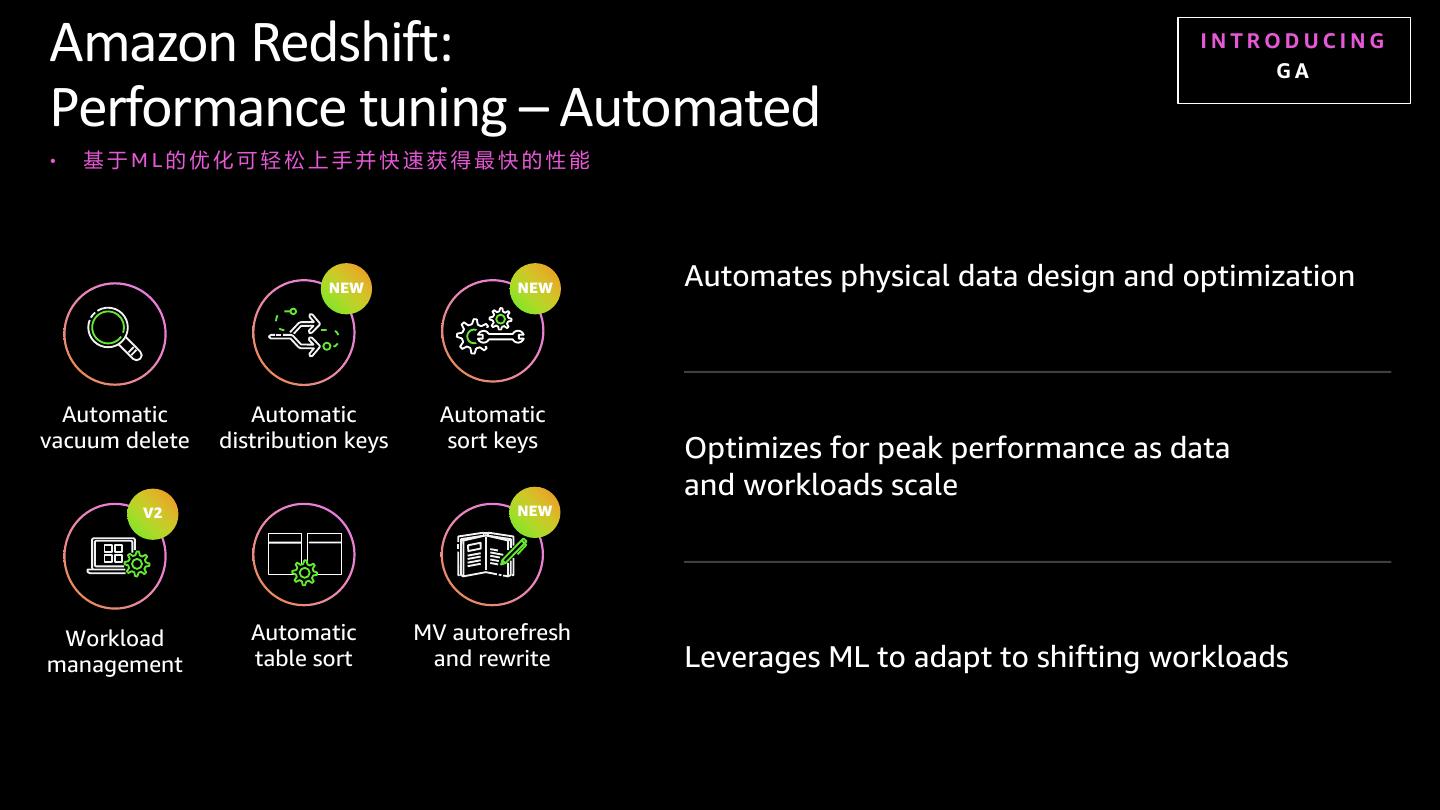
22 . 查询最佳实践:集群设计 要设计Redshift集群以实现最佳的查询性能,请记住 5 个属性 – SET DW S Sort Key:确保存在排序键,以便利与 where 子句中的筛选器 E Encoding(压缩):减少的 I/O 提高了查询性能 Table Maintenance :当前表统计信息提高了排序密钥有效性,而表碎片整理减少了浪费的存储,同时提高了 T 查询性能 D Data Distribution:确保存在分布密钥以便利与最常见的联接 W Workload Management:机器学习算法配置文件查询,以便将其放置在具有适当资源的相应队列中 AWS 中国(宁夏)区域由西云数据运营 © 2020, Amazon Web Services, Inc. or its Affiliates. All rights reserved. AWS 中国(北京)区域由光环新网运营
23 .Redshift工作负载管理 工作负载管理 (WLM) 是一项功能,可帮助管理工作负载,避 免短、快速运行的查询卡在长时间运行的查询队列之后 三种 WLM 方法 Redshift 工作负载管理 查询可用的内存量是 WLM 始终根据用户组、查询组或 WLM 规则将 Redshift •运行查询的 WLM 队列 队列(基本 中执行的每个查询分配给特定队列 (例如, •分配给 WLM 队列的内存百分比 WLM) [return_row_count > 1000000]) •查询正在使用的查询槽数 Redshift 使用机器学习来确定集群中构成”short“运行查 短查询加速 询的内容,然后自动识别运行的”short"运行查询, 如果发 (SQA) 生排队,则立即在短查询队列中运行 Redshift 使用机器学习来预测集群中的排队情况,当排队 并发缩放 时,瞬态 Amazon Redshift 集群将添加到集群中,并将查 询路由到相应集群从而执行 AWS 中国(宁夏)区域由西云数据运营 © 2020, Amazon Web Services, Inc. or its Affiliates. All rights reserved. AWS 中国(北京)区域由光环新网运营
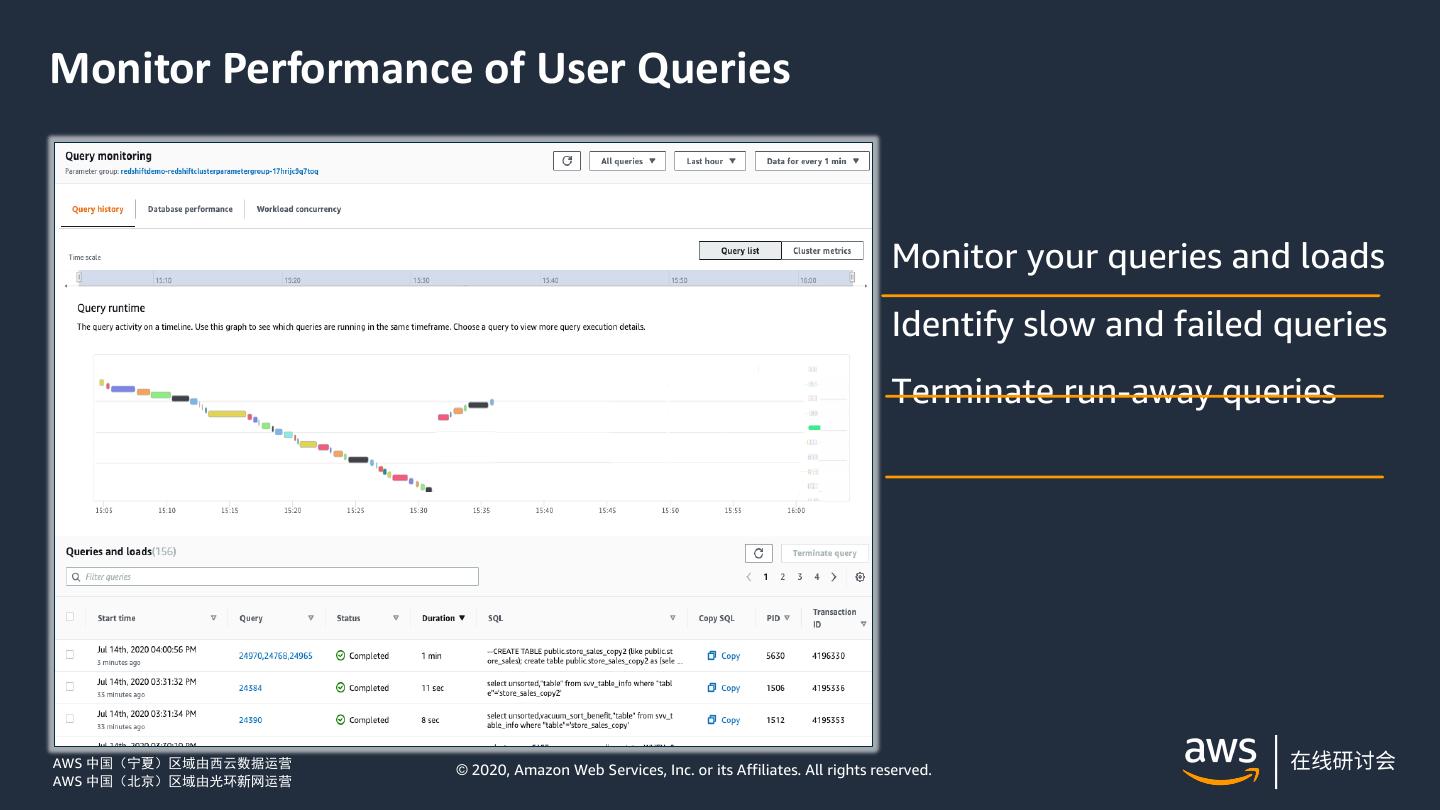
24 .Monitor Performance of User Queries Monitor your queries and loads Identify slow and failed queries Terminate run-away queries AWS 中国(宁夏)区域由西云数据运营 © 2020, Amazon Web Services, Inc. or its Affiliates. All rights reserved. AWS 中国(北京)区域由光环新网运营
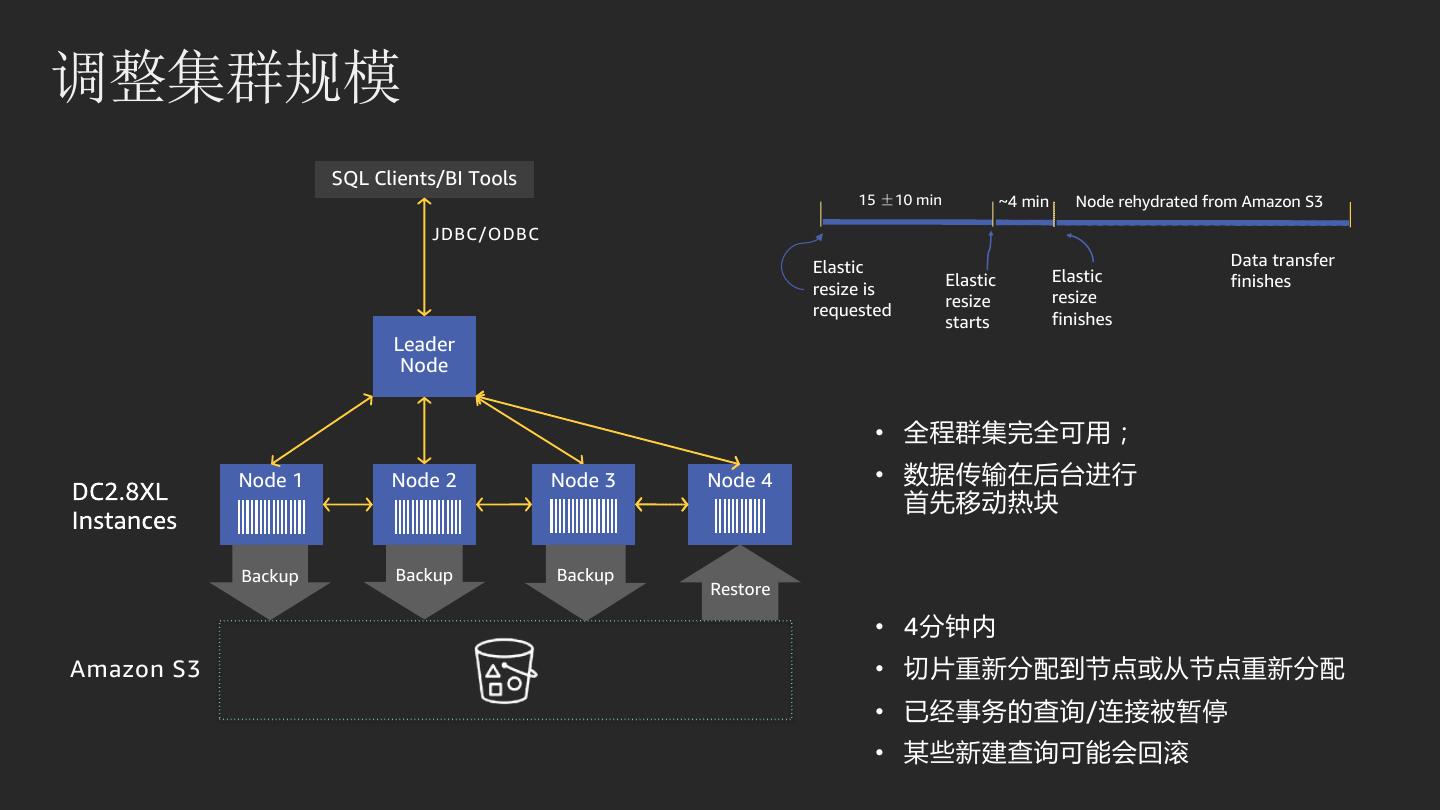
25 .调整集群规模 SQL Clients/BI Tools 15 ±10 min ~4 min Node rehydrated from Amazon S3 JDBC/ODBC Elastic Data transfer Elastic Elastic finishes resize is resize resize requested starts finishes Leader Node • 全程群集完全可用; Node 1 Node 2 Node 3 Node 4 • 数据传输在后台进行 首先移动热块 Backup Backup Backup Restore • 4分钟内 Amazon S3 • 切片重新分配到节点或从节点重新分配 • 已经事务的查询/连接被暂停 • 某些新建查询可能会回滚
26 .Amazon Redshift 简介和典型用例 Amazon Redshift 技术解析 Amazon Redshift 领先特征 通用参考架构
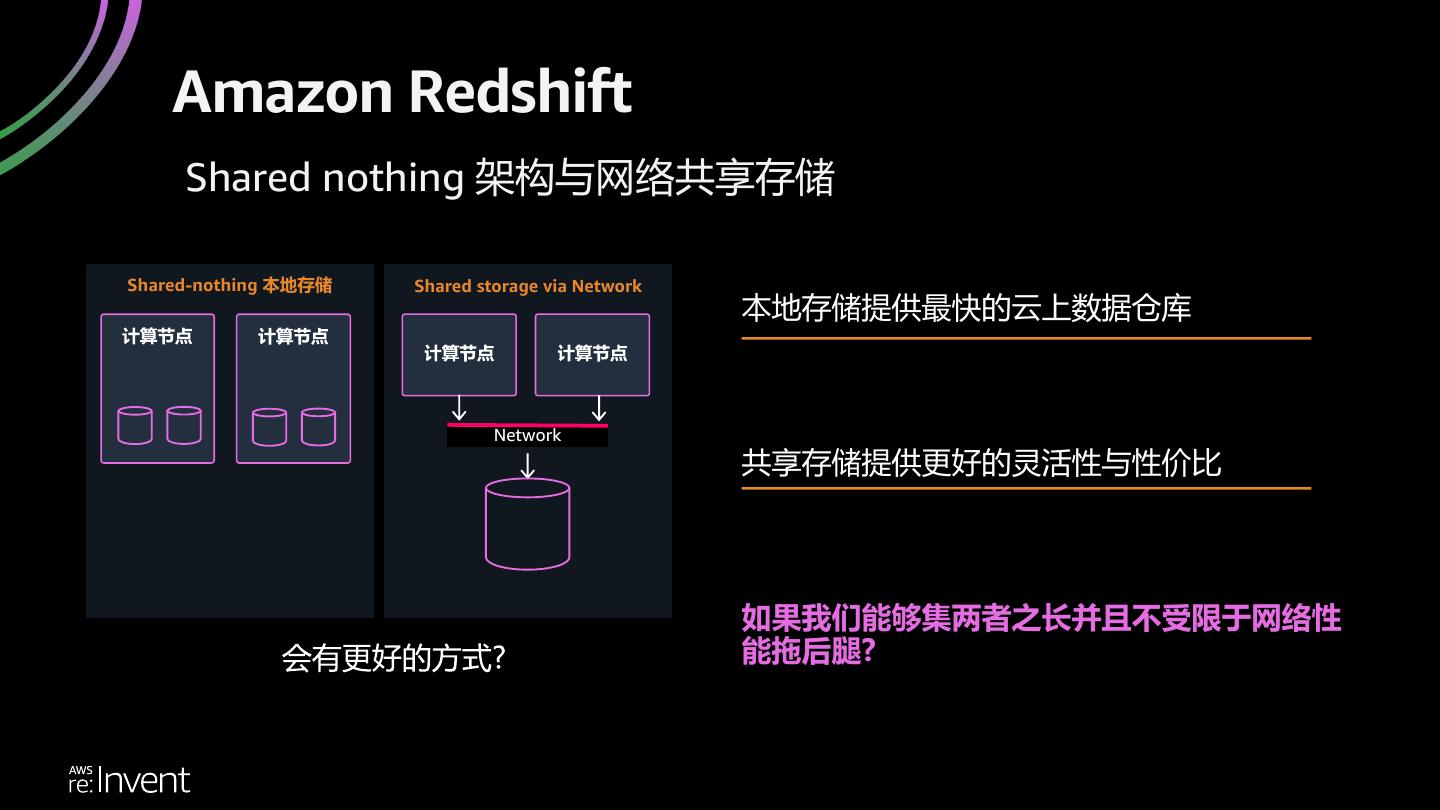
27 . Amazon Redshift Shared nothing 架构与网络共享存储 Shared-nothing 本地存储 Shared storage via Network 本地存储提供最快的云上数据仓库 Network 共享存储提供更好的灵活性与性价比 如果我们能够集两者之长并且不受限于网络性 能拖后腿?
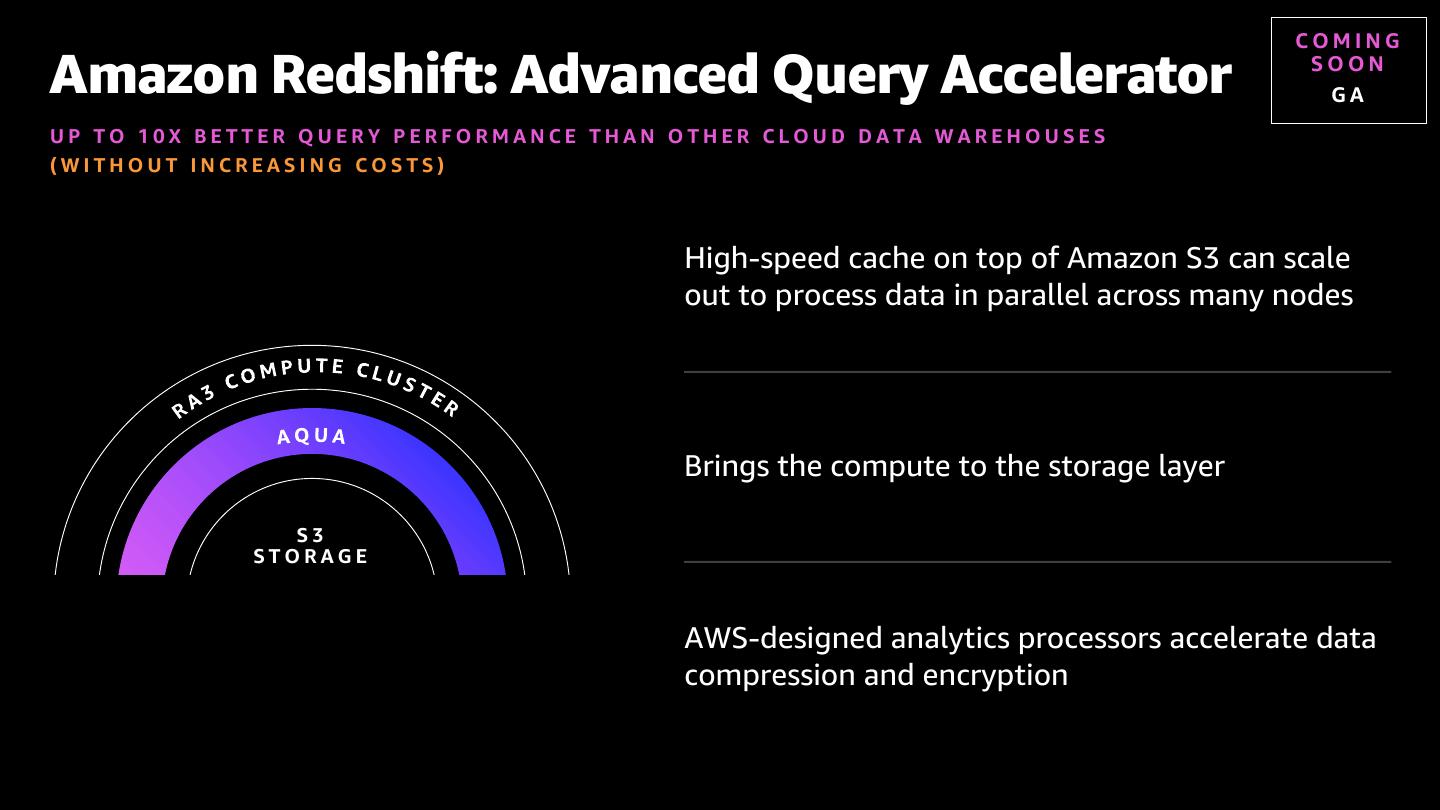
28 . COMING Amazon Redshift: Advanced Query Accelerator SOON GA UP TO 10X BETTER QUERY PERFORMANCE THAN OTHER CLOUD DATA WAREHOUSES (WITHOUT INCREASING COSTS) High-speed cache on top of Amazon S3 can scale out to process data in parallel across many nodes Brings the compute to the storage layer S3 STORAGE AWS-designed analytics processors accelerate data compression and encryption
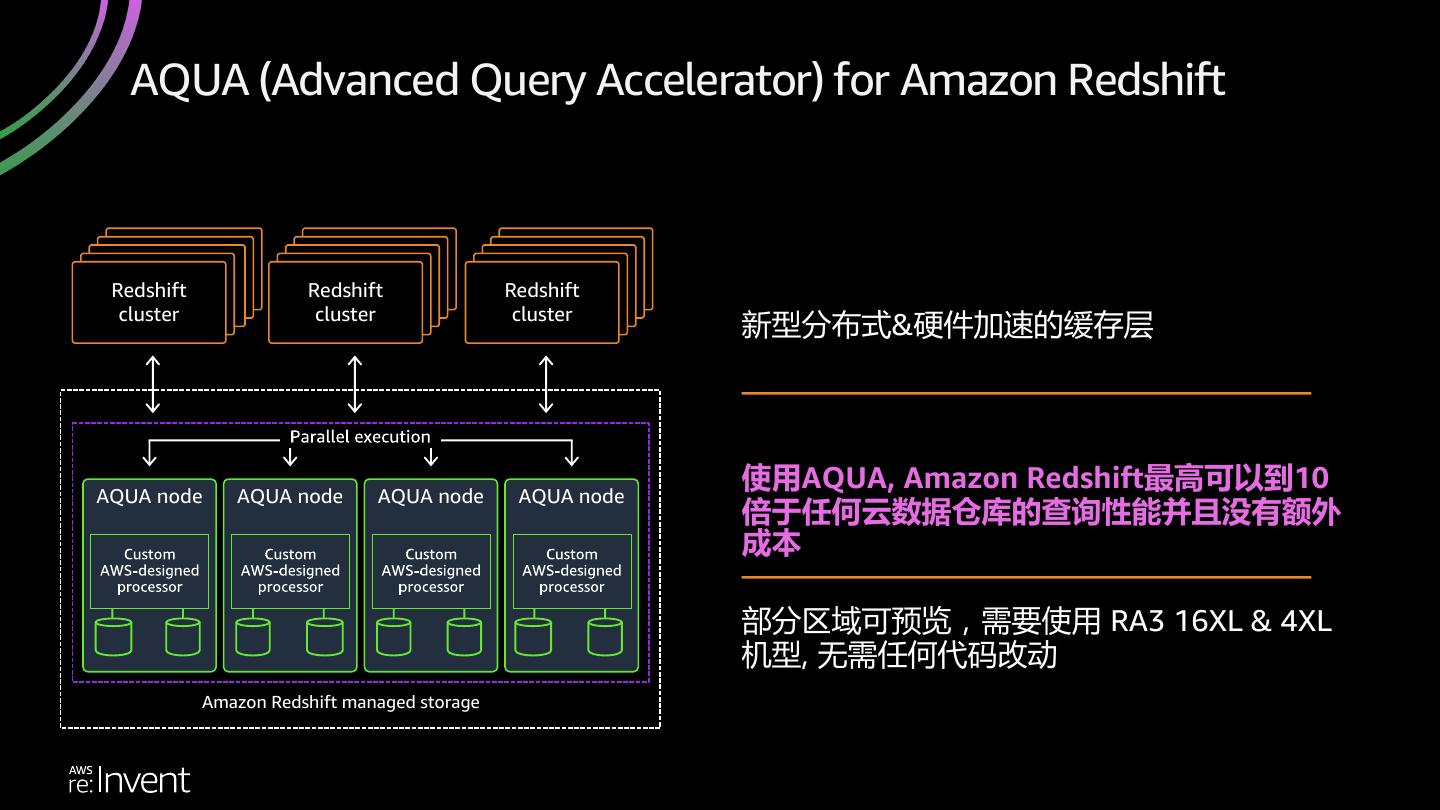
29 . AQUA (Advanced Query Accelerator) for Amazon Redshift Compute Compute Compute Compute Compute Compute Compute Clusters Compute Compute Clusters Compute Compute Clusters Compute Clusters Redshift Clusters Clusters Redshift Clusters Clusters Redshift Clusters Clusters cluster Clusters cluster Clusters cluster 新型分布式&硬件加速的缓存层 使用AQUA, Amazon Redshift最高可以到10 AQUA node AQUA node AQUA node AQUA node 倍于任何云数据仓库的查询性能并且没有额外 成本 部分区域可预览,需要使用 RA3 16XL & 4XL 机型, 无需任何代码改动 Amazon Redshift managed storage
3秒后跳转登录页面
去登陆

