
































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
赋能5G与大数据时代的内存计算平台-VoltDB
VOLTDB是由2014图灵奖得主、 冯诺依曼奖获得者 、 美国国家工程院院士 、Postgres和Vertica等产品的联合创始人Mike Stonebraker博士领导开发的下一代关系型、内存数据库管理系统,面向毫秒级实时事务处理、实时数据分析、边缘计算和复杂流处理计算等应用。
VOLTDB大幅降低了服务器资源开销,首先实现在廉价x86服务器集群或虚拟环境上实现每秒数百万次数据处理。单节点每秒数据处理远远高于其它数据库管理系统。
VOLTDB提供开源版本和商业发行版本。
VOLTDB的设计动力源于系统对于数据的时效性要求越来越高、越来越迫切,而传统数据库由于架构陈旧、数据在本地文件保存,所以不论并发还是处理速度,都难以满足要求。而新型的NoSQL数据库,又缺乏SQL支持以及完整的ACID和事务的支持,完全无法替代传统数据库。
VOLTDB采用类MPP架构,完全在内存中运行,提供定期拍摄磁盘快照的选择。采用横向可扩展的架构。传统的关系数据库将数据写入基于磁盘的日志文件。 VOLTDB则不然,是同时对内存内的多台机器进行修改。例如,即使两台机器发生故障,K-Safety系数为2时即可保证不会造成数据损失,因为数据至少存入三台服务器内存。事务作为存储过程(stored procedure)提交,可在数据库中异步执行,并且数据自动分区(分片),分配至系统内的节点,尽管可复制维表数据以最大限度地提高连接性能。
展开查看详情
1 .赋能5G与大数据时代的内存计算平台 www.voltdb.com
2 . 个人介绍 郭力圣, 2018年加入VoltDB全球技术支持部门, 负责中国区与全球其他客户的技术支持工作。 2
3 . 大纲 ➢VoltDB简介 ➢架构概览 ➢产品特点 ➢版本规划 ➢简单演示 ➢参考论文和资料 ➢Q&A 3
4 . VOLTDB简介 1980 1996 2003 2005 2009 2013 VOLTDB是由2014图灵奖得主、 冯诺依曼奖获得者 、 美国国家工程院院士 、 Postgres和Vertica等产品的联合创始人Mike Stonebraker博士领导开发的下一代关系型、内 存数据库管理系统,面向毫秒级实时事务处理、实时数据分析、边缘计算和复杂流处理计算等 应用。 VOLTDB大幅降低了服务器资源开销,首先实现在廉价x86服务器集群或虚拟环境上实 现每秒数百万次数据处理。单节点每秒数据处理远远高于其它数据库管理系统。 VOLTDB提供开源版本和商业发行版本。 VOLTDB中国 VOLTDB于2017年官方正式进入中国市场,已经建立了本土团队,包括销售、研发、售 前售后和市场推广等职能。国内团队目前分布在北京、南京、成都。VOLTDB承若可为国内商 业客户提供7X24的远程和现场售后支持服务。 4 4
5 . 架构概览 5
6 . VOLTDB设计理念 VOLTDB的设计动力源于系统对于数据的时效性要求越来 越高、越来越迫切,而传统数据库由于架构陈旧、数据在本地 VOLTDB、NoSQL和传统关系型数据库的对比如下所示: 文件保存,所以不论并发还是处理速度,都难以满足要求。而 新型的NoSQL数据库,又缺乏SQL支持以及完整的ACID和事务 的支持,完全无法替代传统数据库。 VOLTDB采用类MPP架构,完全在内存中运行,提供定期 拍摄磁盘快照的选择。采用横向可扩展的架构。传统的关系数 据库将数据写入基于磁盘的日志文件。 VOLTDB则不然,是同 时对内存内的多台机器进行修改。例如,即使两台机器发生故 障,K-Safety系数为2时即可保证不会造成数据损失,因为数据 至少存入三台服务器内存。 事务作为存储过程(stored procedure)提交,可在数据库中 异步执行,并且数据自动分区(分片),分配至系统内的节点, 尽管可复制维表数据以最大限度地提高连接性能。 6
7 . 趋势研究 伟大的想法–VoltDB初创研究团队想进行在 线交易处理,并使其更快,更具伸缩性,并且希 望更便宜。 他们注意到内存越来越大,CPU核心数量在 增加,并且所有东西的价格都在下降。 现在有可 能获得许多廉价的功能强大的服务器,而他想利 用这一优势。 一个明确的方向是留意内存并利用内存价格 下跌的优势。 为了弄清楚如何做到这一点,他们在内存中 运行了一个基于磁盘的数据库,使用RAM磁盘而 不是硬盘驱动器-摆脱了磁盘I/O延迟。 然后,他们测量了CPU时间都用到了什么环 节,以查看是否可以获得更多的性能。 ➢ The End of an Architecture Era(It’s Time for a Complete Rewrite) ➢ OLTP Through the Looking Glass, and What We Found There 7
8 . 技术探索 Useful Work Mike Stonebraker博士的研究团 12% Index 队通过对传统数据库进行分析,发现 Mangement 数据只有12%左右的CPU时间在做真 11% 正有意义的数据操作,而其他绝大部 分时间都被缓存,并发控制等消耗了。 Logging 传统数据库有约88%的CPU时间 20% Buffer 都消耗在这些对于实际操作无意义的 Management 步骤上,要提升数据库性能,只有从 29% 根本上减少这些冗余的步骤,集中进 行数据运算,才能完全利用 CPU。 Locking 18% Latching 10% 8
9 . 通过怎样的方式能加速OLTP的处理 减少或者消除缓冲区池管理 稳定可预测的并发 完全在内存中完成所有数据存储 单线程访问内存数据结构,从而 与更新,从而减少页面缓存与磁 减少锁带来的额外开销 盘的交换 9
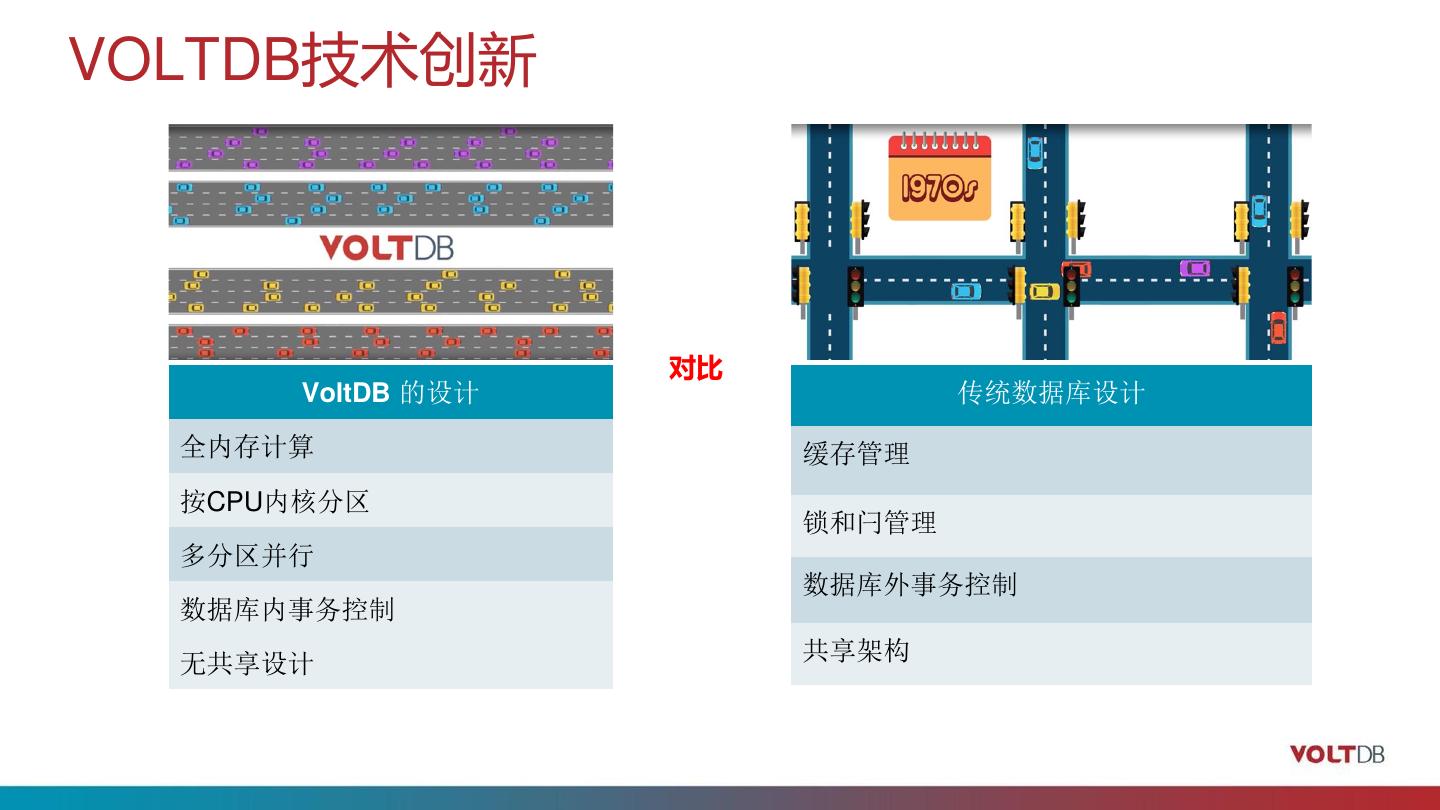
10 .VOLTDB技术创新 对比 VoltDB 的设计 传统数据库设计 全内存计算 缓存管理 按CPU内核分区 锁和闩管理 多分区并行 数据库外事务控制 数据库内事务控制 无共享设计 共享架构
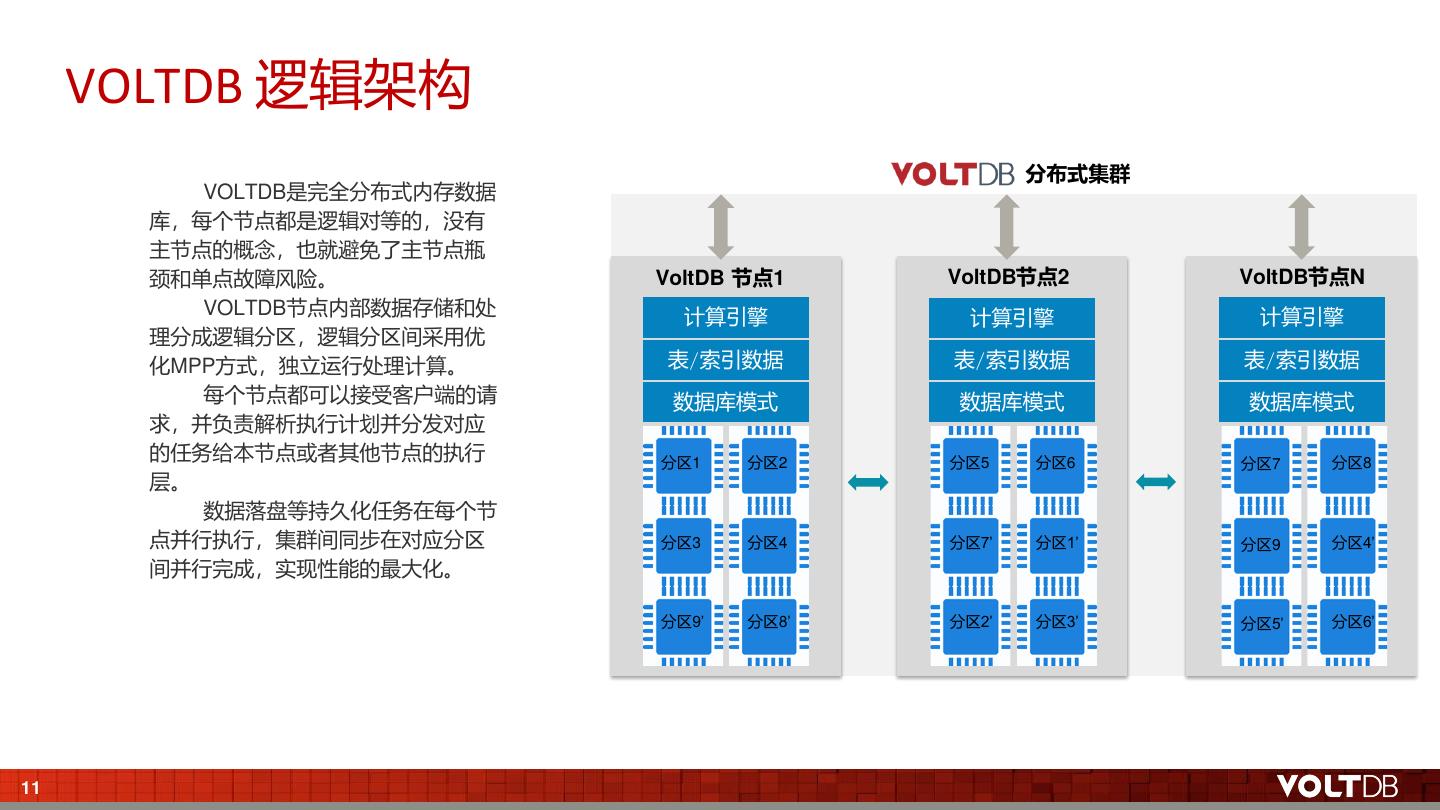
11 . VOLTDB 逻辑架构 分布式集群 VOLTDB是完全分布式内存数据 库,每个节点都是逻辑对等的,没有 主节点的概念,也就避免了主节点瓶 颈和单点故障风险。 VoltDB 节点1 VoltDB节点2 VoltDB节点N VOLTDB节点内部数据存储和处 计算引擎 计算引擎 计算引擎 理分成逻辑分区,逻辑分区间采用优 化MPP方式,独立运行处理计算。 表/索引数据 表/索引数据 表/索引数据 每个节点都可以接受客户端的请 数据库模式 数据库模式 数据库模式 求,并负责解析执行计划并分发对应 的任务给本节点或者其他节点的执行 分区1 分区2 分区5 分区6 分区7 分区8 层。 数据落盘等持久化任务在每个节 点并行执行,集群间同步在对应分区 分区3 分区4 分区7’ 分区1’ 分区9 分区4’ 间并行完成,实现性能的最大化。 分区9’ 分区8’ 分区2’ 分区3’ 分区5’ 分区6’ 11
12 . 不使用客户端事务处理 SET autocommit = 0; START TRANSACTION; SELECT @orderNumber:=MAX(orderNumber)+1 FROM orders; INSERT INTO orders(orderNumber, orderDate, shippedDate, status, customerNumber) VALUES(@orderNumber, '2005-05-31’, '2005-06-11', 'In Process', 145); INSERT INTO orderitems(orderNumber, productCode, quantityOrdered, priceEach, orderLineNumber) VALUES(@orderNumber,'S18_1749', 30, '136', 1), (@orderNumber,'S18_2248', 50, '55.09', 2); COMMIT; ➢ 使用服务端的存储过程开发业务逻辑,可以同时支持Java与SQL对存储过程进 行开发。 ➢ 减少数据在网络间的传输次数与延时,将计算移向数据。 12
13 . 在CPU核心与服务器节点上进行横向扩展 Partition data across multiple cores and multiple machines 将数据在多个CPU核心以及多台服务器节点上进行分区扩展。 Achieve concurrency by sending transactions to the partition that has the data 通过将事务的执行发送到数据所在的分区上实现并发 Scales out on commodity hardware 无需使用专用服务器才能获得更高的性能,使用通用商业服务器也能实现 13
14 . 对数据的实际商业应用中的其他需求 High Availability and Snapshots/高可用与快照 Point-in-Time Durability/基于时间点的恢复 Streaming Output/流式数据导出 Disaster Recovery (Active/Passive Replication)/灾难恢复(数据复制) Streaming Input/流式数据导入 Cross Data-Center Replication (Active/Active Replication)/跨数据中心复制 Elastic Cluster Resizing/弹性伸缩(动态增加减少服务器节点) 14
15 . VoltB适用于什么场景? 现在,我们来讨论一下VoltDB适合的场景,有什么特点。 16
16 . CAP 理论 Consistency VoltDB 一致性 C A x C P • Partition Availability Partition- Tolerance Tolerant AP 可用性 分区容错性 • Consistent 17
17 . 事务隔离级别-严格的可序列化隔离 https://aphyr.com/posts/331-jepsen-voltdb-6-3, 这个链接是使用Jepsen测试框 架对VoltDB进行测试的报告。 Jepsen是一个测试框架,旨在测试分布式系统的分区容错性。 Jepsen创建网络 分区,同时用随机操作触发被测试系统某些容错处理。 分析结果以查看系统是否违 反了它声称的任何一致性属性。 测试结果表明,与大多数SQL数据库不同,大多数SQL数据库由于性能原因默 认将隔离级别设置为较弱的隔离级别,而VoltDB选择默认提供严格的可序列化隔离 (Strong Serializable)。 可序列化性是ANSI SQL四个隔离级别中最强的:事务必须以某种顺序执行,一 次执行一个事务。 它禁止许多一致性异常,包括脏读、不可重复读、幻读。 18
18 . 什么是NOSQL 非关系型数据库 • Key/Value 数据库, 比如Redis • 文档数据库,比如MongoDB • 图数据库,比如Neo4j 通过横向扩展服务器节点 • 没有 ACID • 在满足较低的一致性上实现快速处理和横向扩展 某些NOSQL数据库正在增加对SQL的支持,比如CockroachDB 19
19 . 什么是NEWSQL SQL 并不是一个扩展性问题,而是一门语言,很多研发人员都了解的语言。 扩展性和一致性可以通过其他方式实现: • VoltDB – 将数据分区,单线程访问处理,没有服务器以外的事务,完全一致性。 • Cloud Spanner – Google分布式数据库, 基于 atomic clock time构建。 • Yugabyte, CockroachDB – 类似于 Cloud Spanner。 20
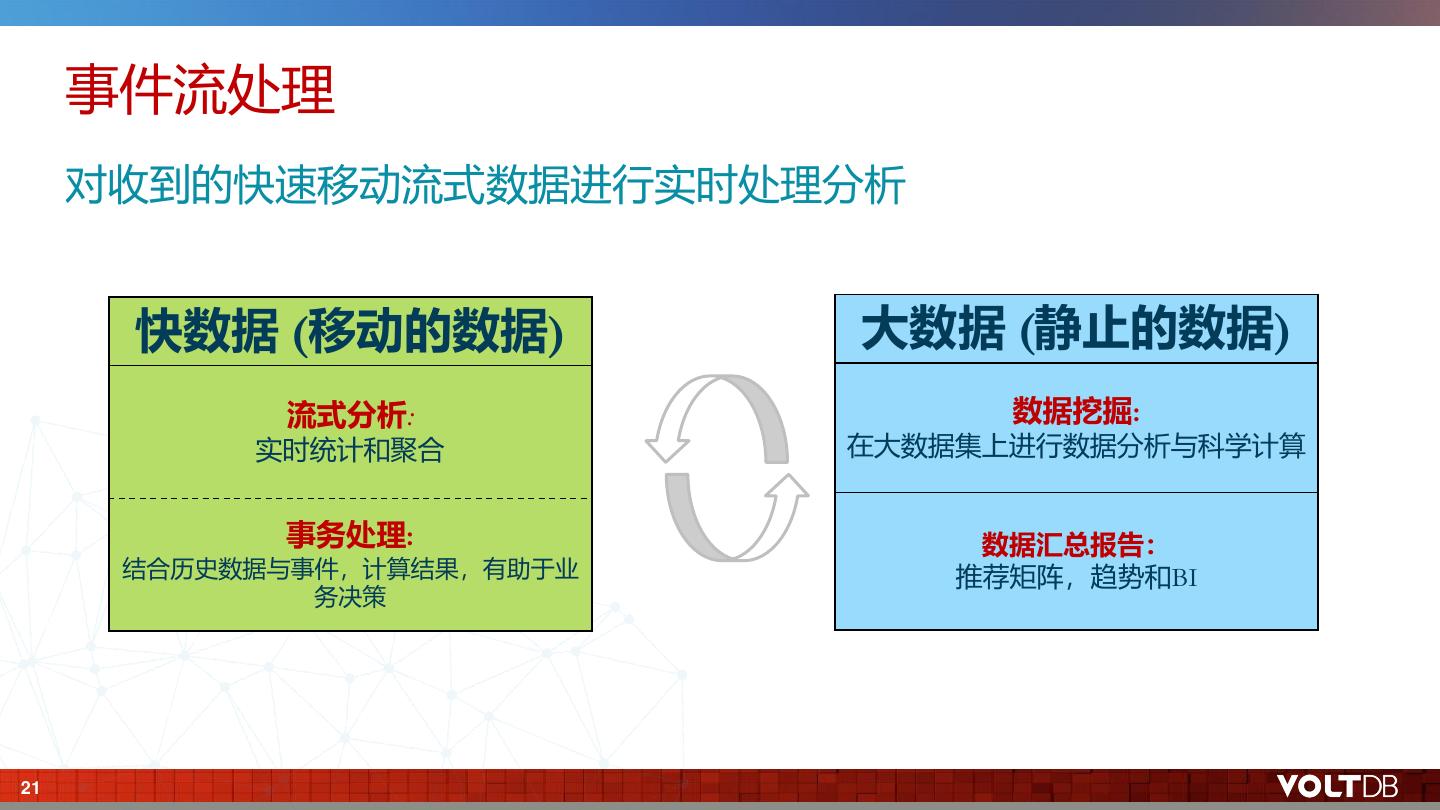
20 . 事件流处理 对收到的快速移动流式数据进行实时处理分析 快数据 (移动的数据) 大数据 (静止的数据) 流式分析: 数据挖掘: 实时统计和聚合 在大数据集上进行数据分析与科学计算 事务处理: 数据汇总报告: 结合历史数据与事件,计算结果,有助于业 推荐矩阵,趋势和BI 务决策 21
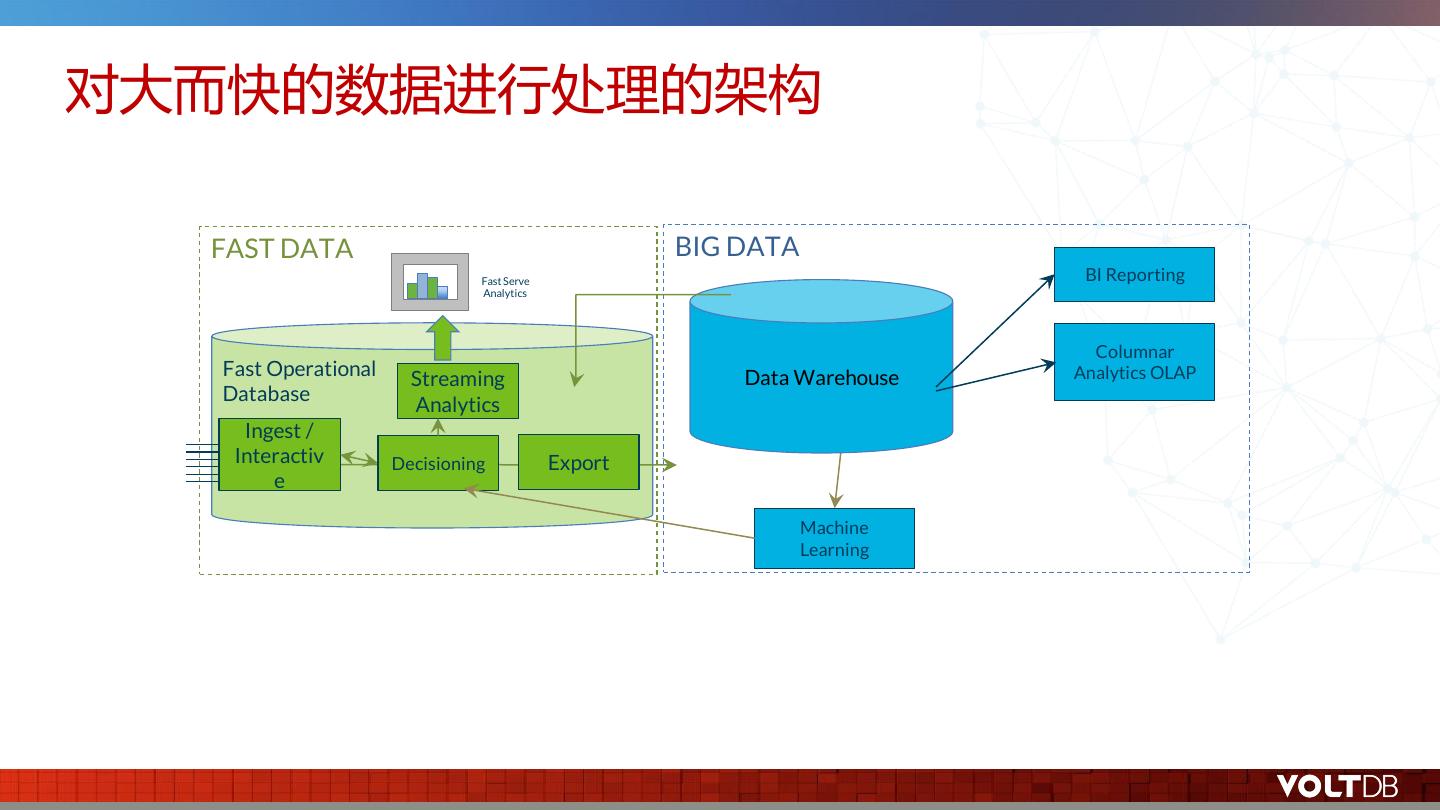
21 .对大而快的数据进行处理的架构 FAST DATA BIG DATA Fast Serve BI Reporting Analytics Columnar Fast Operational Data Warehouse Analytics OLAP Streaming Database Analytics Ingest / Interactiv Decisioning Export e Machine Learning
22 . VoltB有哪些特性? 现在,我们来讨论一下VoltDB的特性。 23
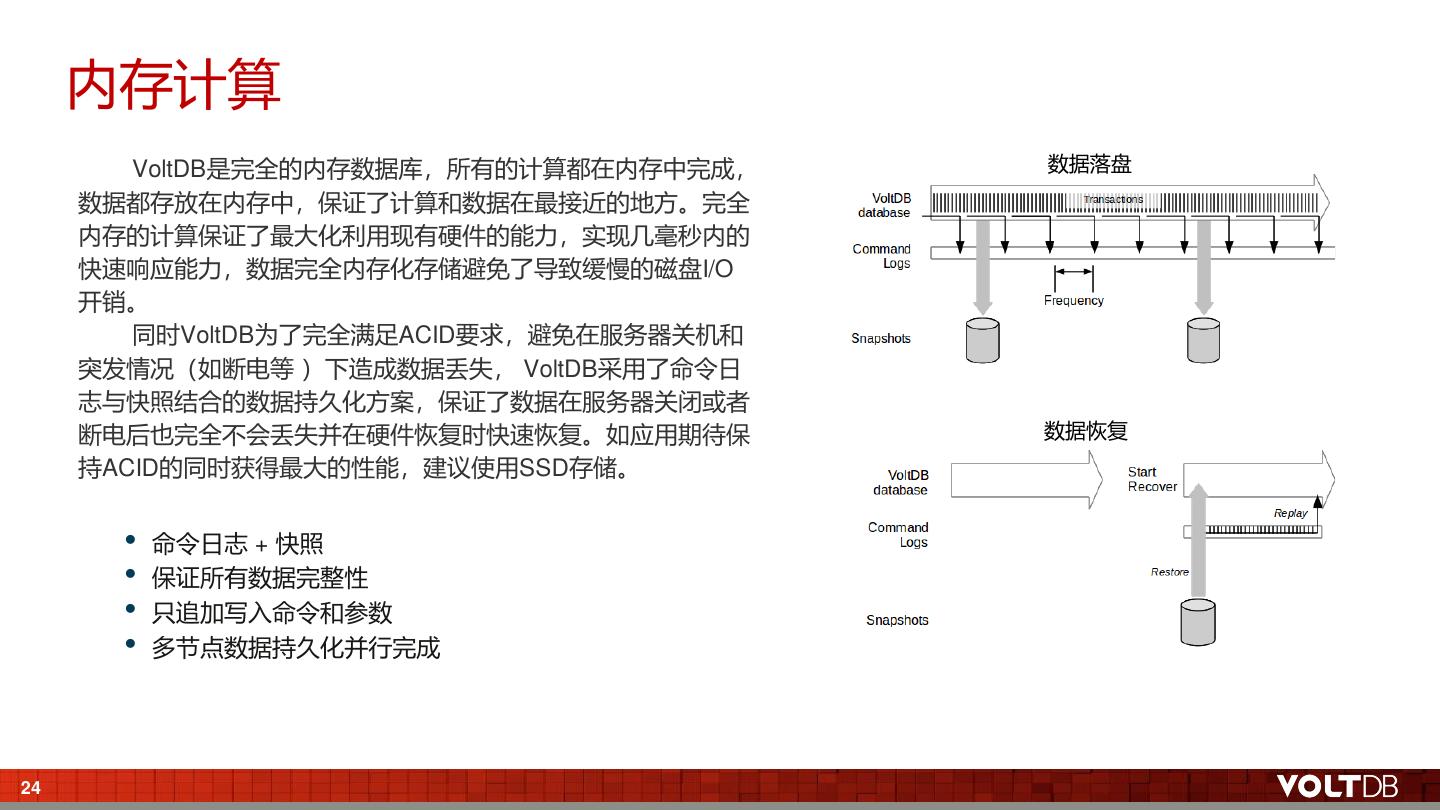
23 . 内存计算 VoltDB是完全的内存数据库,所有的计算都在内存中完成, 数据落盘 数据都存放在内存中,保证了计算和数据在最接近的地方。完全 内存的计算保证了最大化利用现有硬件的能力,实现几毫秒内的 快速响应能力,数据完全内存化存储避免了导致缓慢的磁盘I/O 开销。 同时VoltDB为了完全满足ACID要求,避免在服务器关机和 突发情况(如断电等 )下造成数据丢失, VoltDB采用了命令日 志与快照结合的数据持久化方案,保证了数据在服务器关闭或者 断电后也完全不会丢失并在硬件恢复时快速恢复。如应用期待保 数据恢复 持ACID的同时获得最大的性能,建议使用SSD存储。 • 命令日志 + 快照 • 保证所有数据完整性 • 只追加写入命令和参数 • 多节点数据持久化并行完成 24
24 . 安全易用 标准SQL ACID VoltDB使用标准SQL,包括 CREATE INDEX,CREATE VoltDB能够在保证事务完整性的同时提供并发和性能线性 TABLE, CREATE VIEW ,SELECT, INSERT, UPDATE, 扩展的能力; VoltDB把每个事务都当作一个存储过程, 保证数据 DELETE操作等。学习成本和代码迁移成本很低,代码复用程度 一致性。传统的数据库为了保证事务完整性,往往耗费非常多的 高,现有使用SQL实现的应用,可以相对容易的迁移到VoltDB。 CPU资源在锁、插销和缓冲区管理这些执行准备工作上,阻碍了 同时VoltDB还支持用户自定义函数,通过Java编写并导入数据库, 数据库的性能和扩展能力。VoltDB通过全局事务串行执行和单线 用户自定义函数能在SQL语句中使用。 程分区并行执行,保证事务执行串行隔离,同时避免了锁的使用 和缓冲区的管理,同时满足ACID和高性能。 复杂计算 JDBC VoltDB使用行式结构存储数据,兼容JAVA数据类型,同时 VoltDB兼容JDBC,允许用户进行动态的SQL查询,动态 提供了多表JOIN、聚合、窗口、地理等查询。同时,VoltDB 提供 SQL查询也能参与存储结构优化(比如索引),所以可根据应用需 数据即席查询(Ad-Hoc),可根据自己的需求灵活的选择查询条件, 求结合预先编好存储过程一起使用。 以作为实时数据分析和实时数仓使用。 25
25 . 高可用 数据多副本 K-SAFETY 该图描述了K-SAFETY=1的数据分布情况 数据多副本分布 VoltDB可以自定义数据的副本数量(0 ~ 集群节点数-1),用户 只需在表定义时设定分区字段,数据就可自动分区,副本分区保存在不 同的节点以保证有节点退出时不影响集群整体稳定性。 VoltDB表的类型包括分区表和复制表。分区表根据分区字段自动 分片,通常用来保存业务表数据。复制表在集群每一个节点有一份完整 数据,通常用来保存主表数据。所以在执行诸如多表联合查询计算时, 最大化的发挥本地内存计算优势,避免昂贵的网络开销。 VoltDB数据多副本架构同时带来并行查询的优势,但是过多的副 本也可能导致增加数据写入和更新的延迟,通常建议副本数量不超过3 份。 26
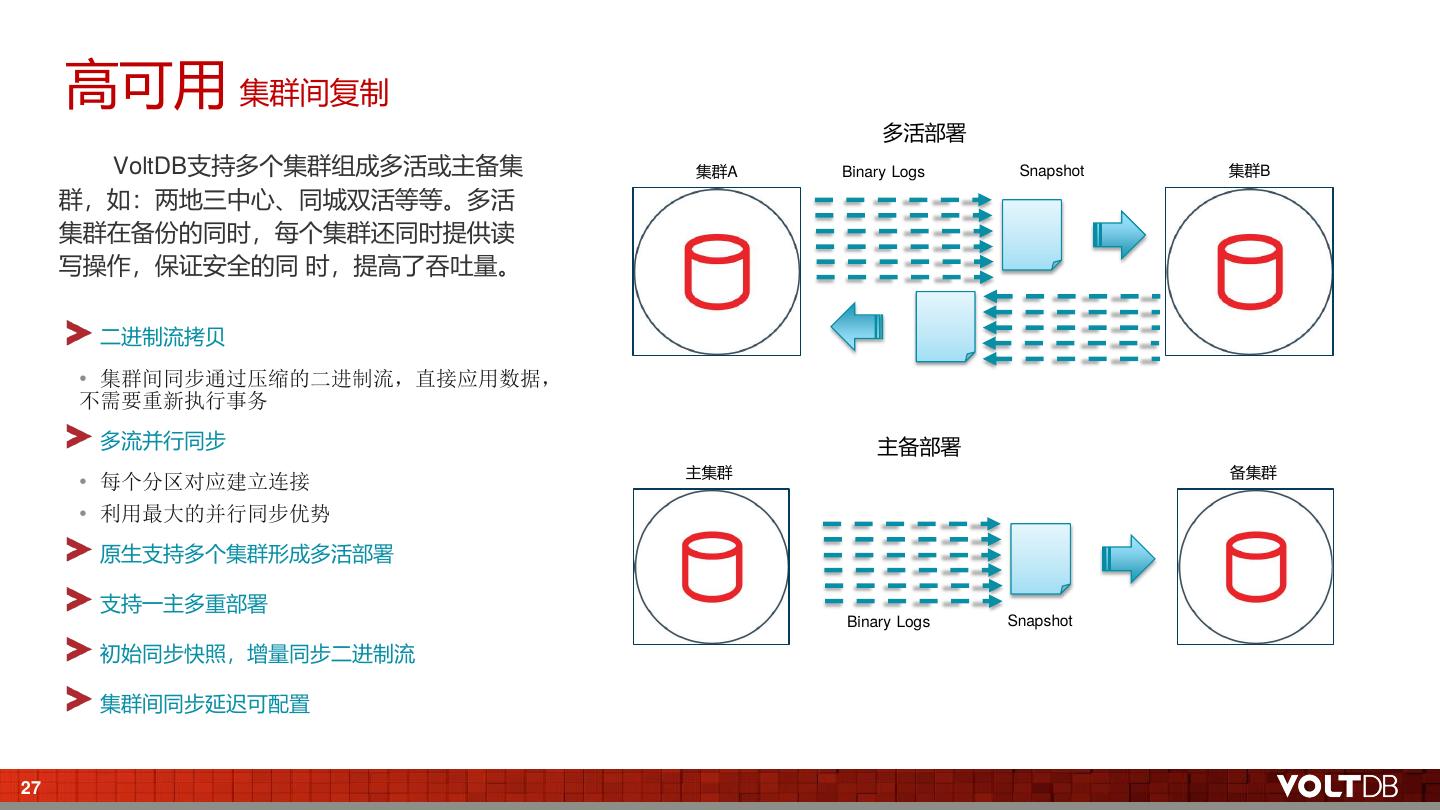
26 . 高可用 集群间复制 多活部署 VoltDB支持多个集群组成多活或主备集 集群A Binary Logs Snapshot 集群B 群,如:两地三中心、同城双活等等。多活 集群在备份的同时,每个集群还同时提供读 写操作,保证安全的同 时,提高了吞吐量。 二进制流拷贝 • 集群间同步通过压缩的二进制流,直接应用数据, 不需要重新执行事务 多流并行同步 主备部署 主集群 备集群 • 每个分区对应建立连接 • 利用最大的并行同步优势 原生支持多个集群形成多活部署 支持一主多重部署 Binary Logs Snapshot 初始同步快照,增量同步二进制流 集群间同步延迟可配置 27
27 . 运维监控 集成普罗米修斯 VOLTDB提供丰富的运维监控工具,能 够实时监控集群运行状态,查询执行状态等, 并可按需配置监控报警事件。 支持执行计划分析 • 可以分析最小粒度的SQL执行情况,可以查看具 体分区的具体存储过程中单一SQL的执行性能和资 源消耗等。 提供图形管理接口 提供命令行管理接口 图形管理接口 可与三方监控平台集成 • 如普罗米修斯、Newrelic等 28
28 . 云化部署 虚拟化/容器化 VoltDB支持虚拟化、容器化部署,可无缝 运行于虚拟化环境。 VoltDB VoltDB VoltDB 支持特性: 集中控制、部署 虚拟机 /容器 虚拟机 /容器 虚拟机 /容器 在线扩容 (VM/Container) (VM/ Container) (VM/ Container) 在线缩容 自动化编排k8s 主机操作系统 物理服务器 29
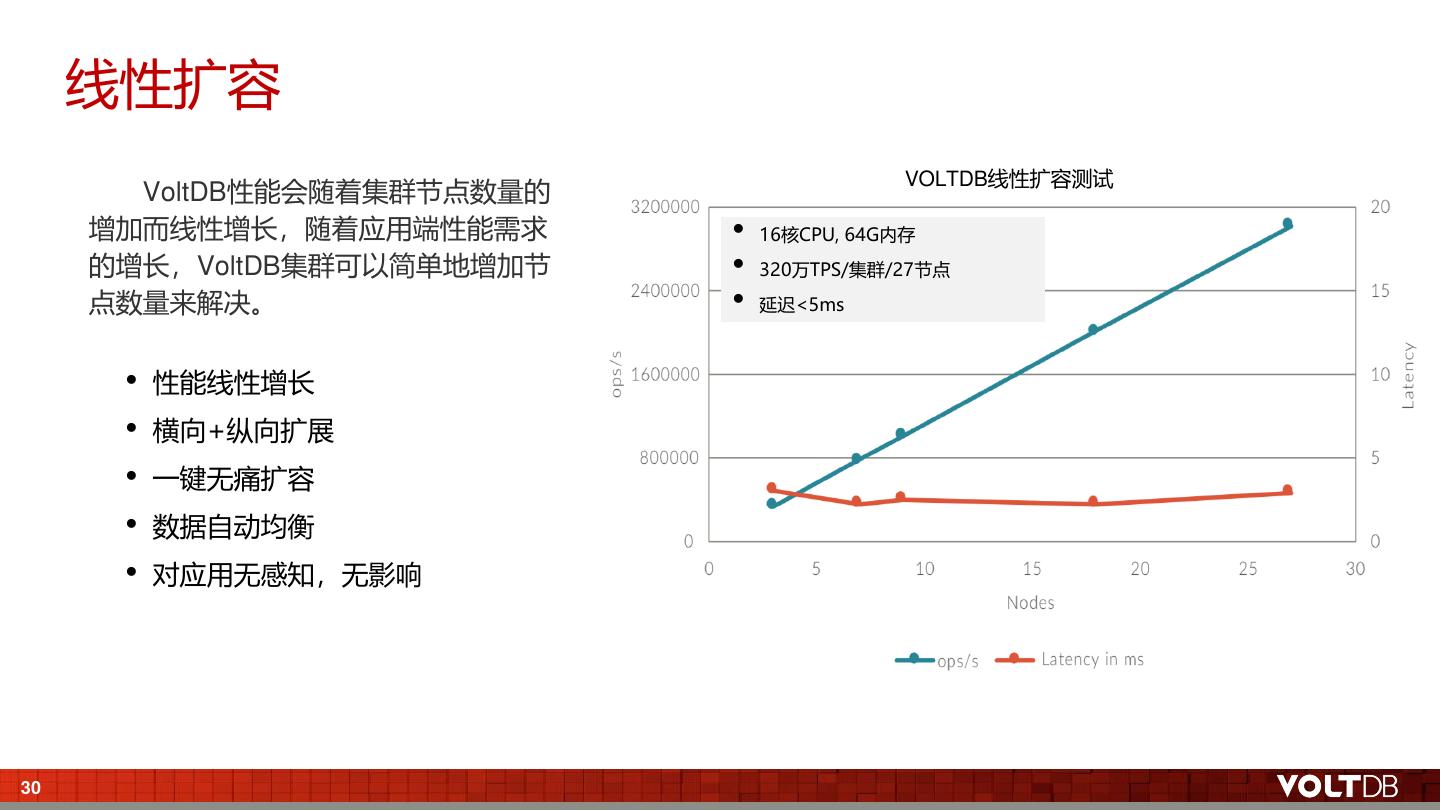
29 . 线性扩容 VOLTDB线性扩容测试 VoltDB性能会随着集群节点数量的 增加而线性增长,随着应用端性能需求 • 16核CPU, 64G内存 的增长,VoltDB集群可以简单地增加节 • 320万TPS/集群/27节点 点数量来解决。 • 延迟<5ms • 性能线性增长 • 横向+纵向扩展 • 一键无痛扩容 • 数据自动均衡 • 对应用无感知,无影响 30
3秒后跳转登录页面
去登陆

