

























































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
RAPIDS
End-to-end data-science and geospatial analytics with GPUs, RAPIDS, and Apache Arrow. 用GPU,RAPIDS和Apache Arrow打造端到端的数据科学与地理空间分析系统。
展开查看详情
1 .End-to-end data-science and geospatial analytics with GPUs, RAPIDS, and Apache Arrow Joshua Patterson – GM, Data Science
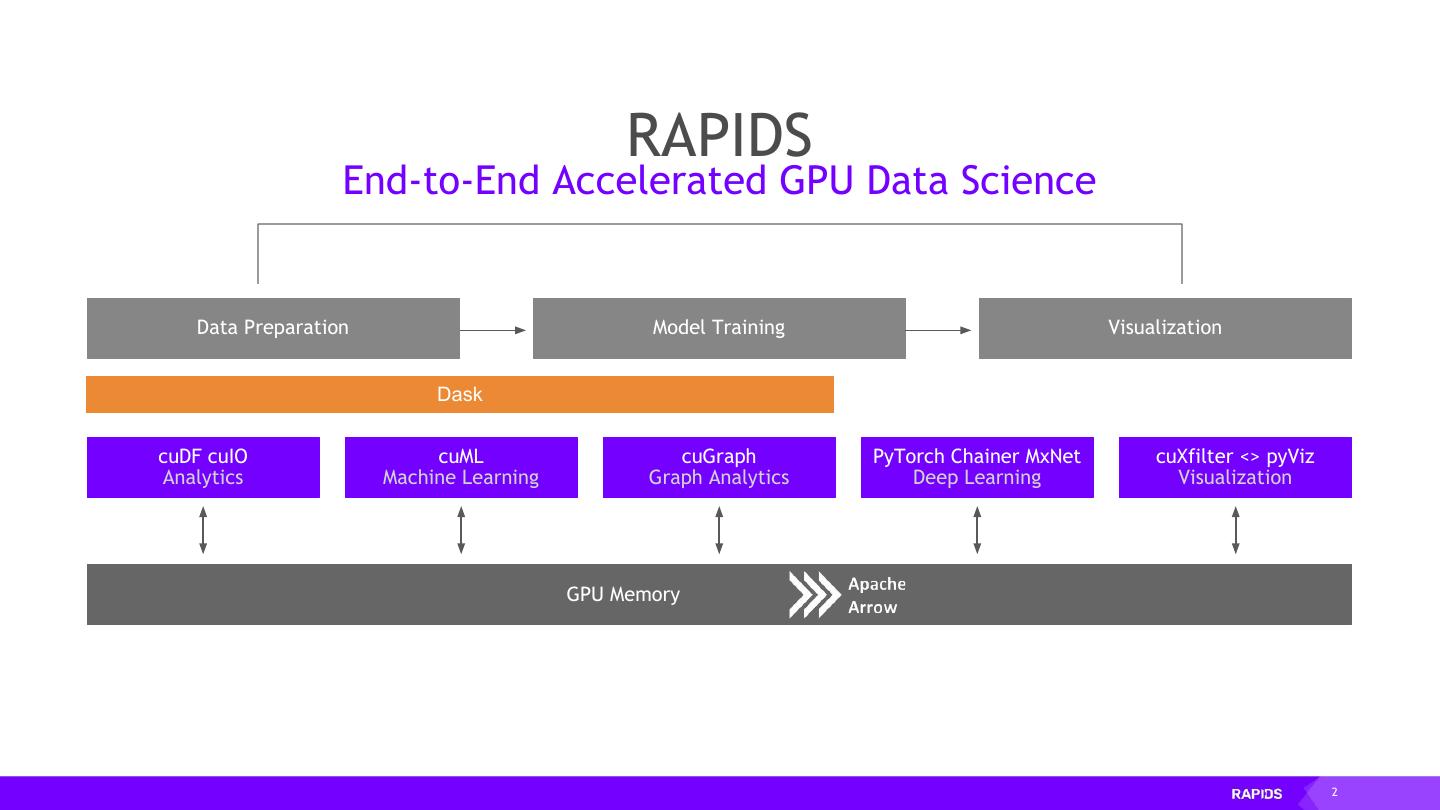
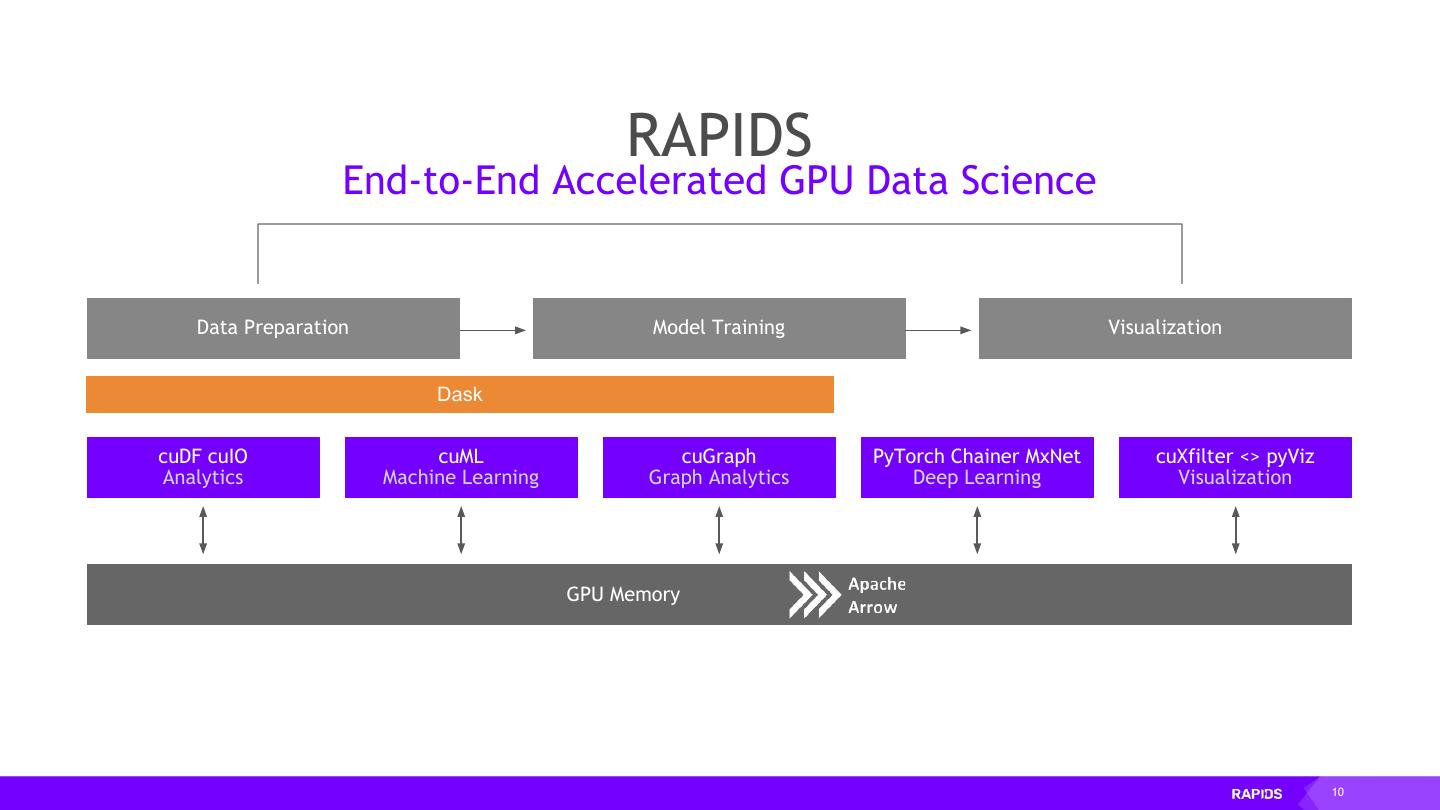
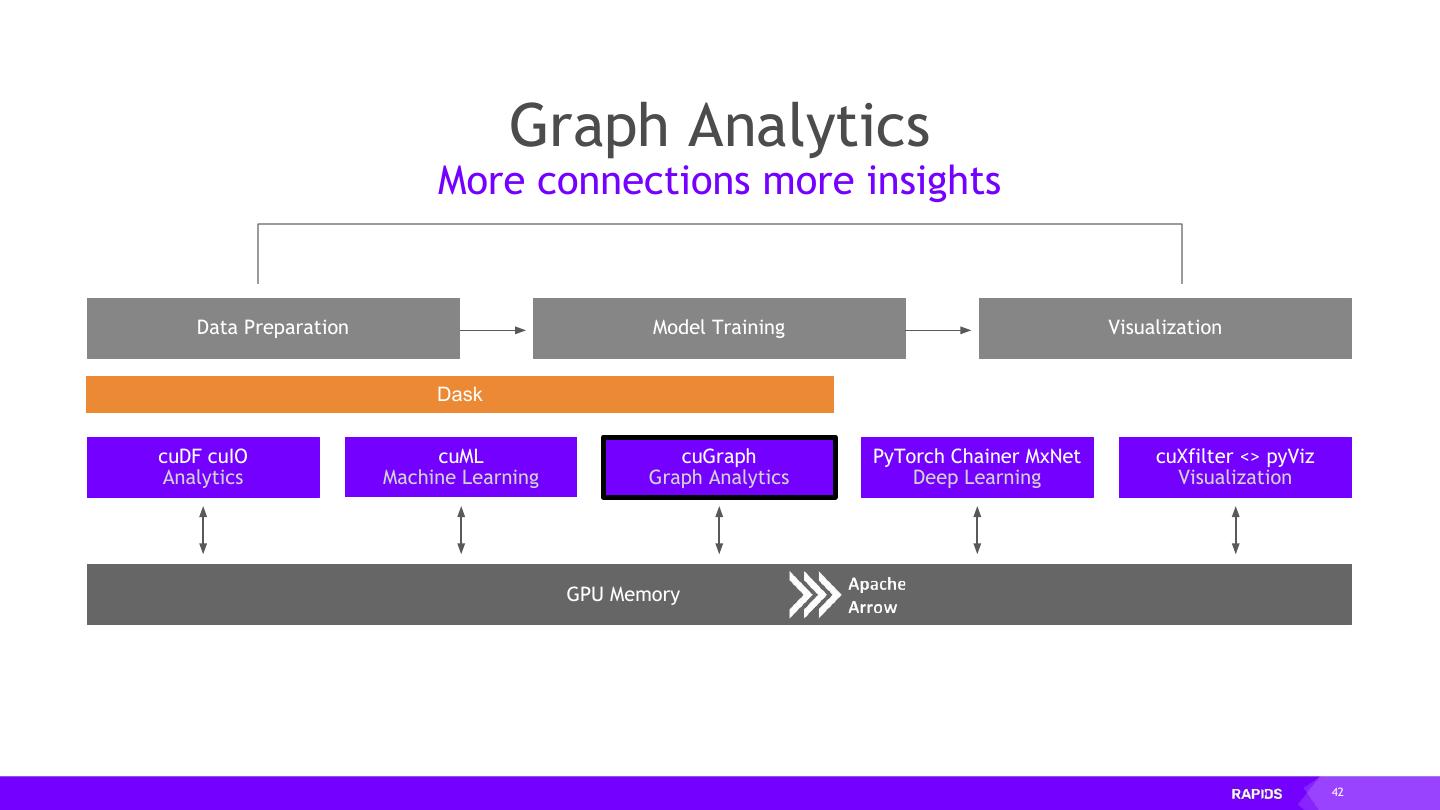
2 . RAPIDS End-to-End Accelerated GPU Data Science Data Preparation Model Training Visualization Dask cuDF cuIO cuML cuGraph PyTorch Chainer MxNet cuXfilter <> pyViz Analytics Machine Learning Graph Analytics Deep Learning Visualization GPU Memory 2
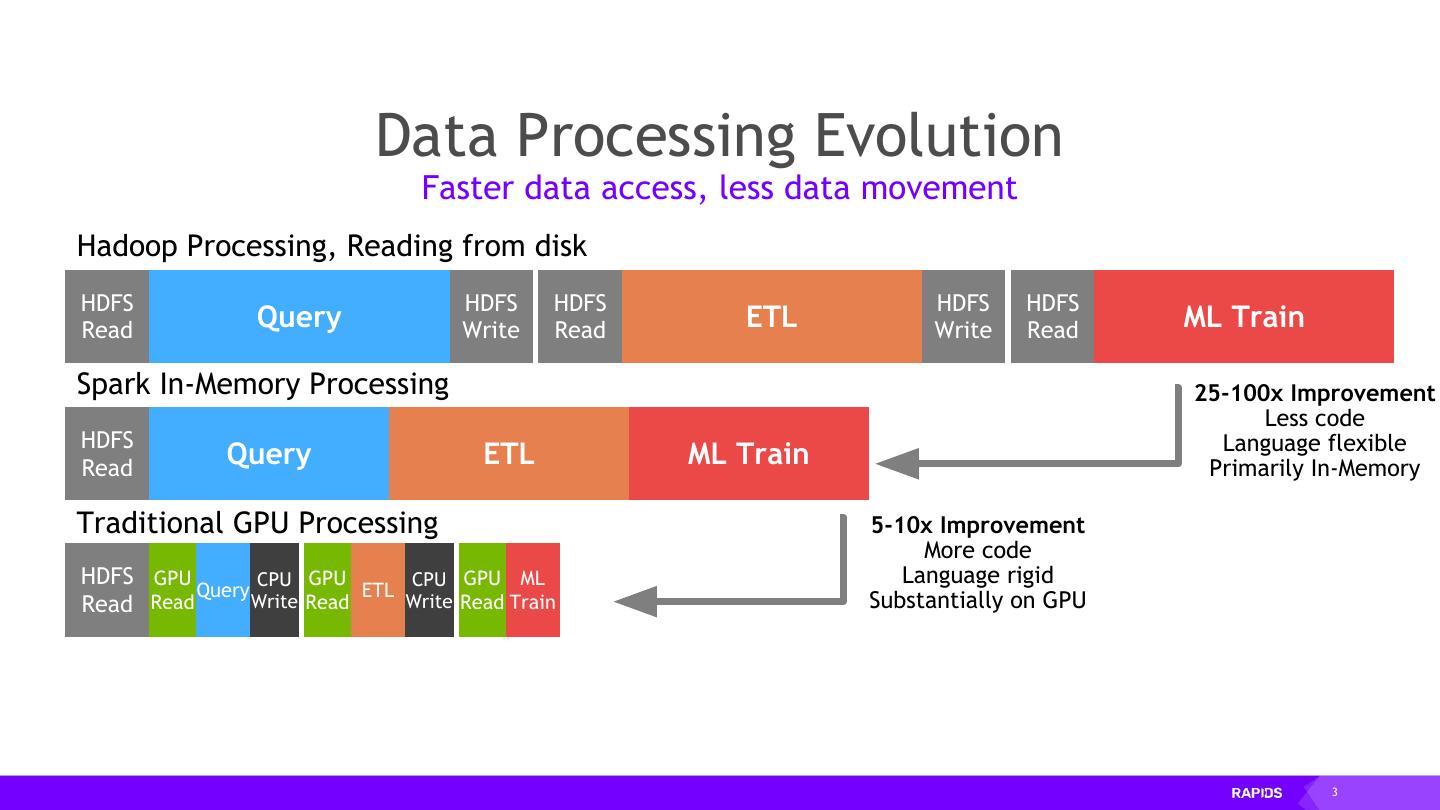
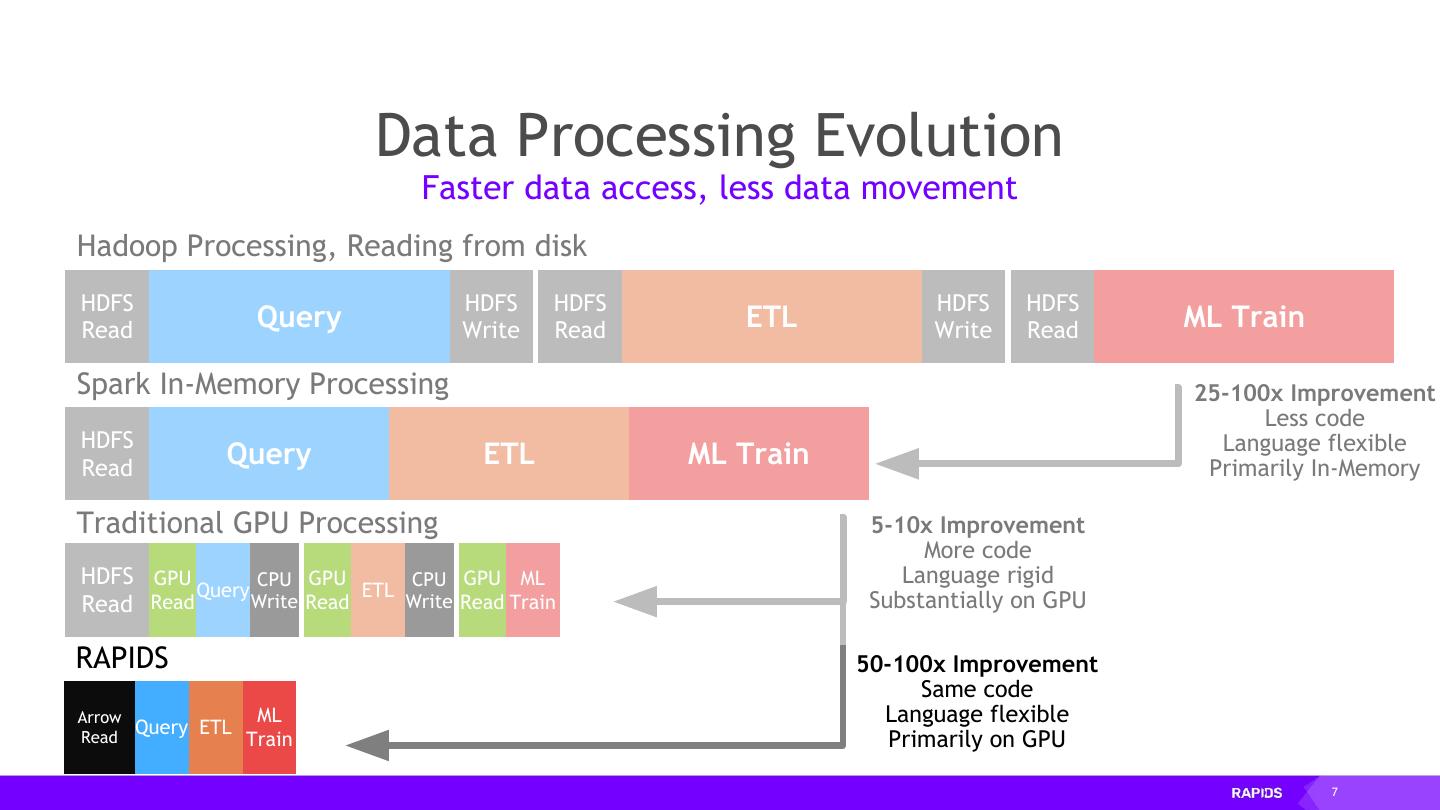
3 . Data Processing Evolution Faster data access, less data movement Hadoop Processing, Reading from disk HDFS HDFS HDFS HDFS HDFS Read Query Write Read ETL Write Read ML Train Spark In-Memory Processing 25-100x Improvement Less code HDFS Language flexible Read Query ETL ML Train Primarily In-Memory Traditional GPU Processing 5-10x Improvement More code HDFS GPU CPU GPU CPU GPU ML Language rigid Query ETL Read Read Write Read Write Read Train Substantially on GPU 3
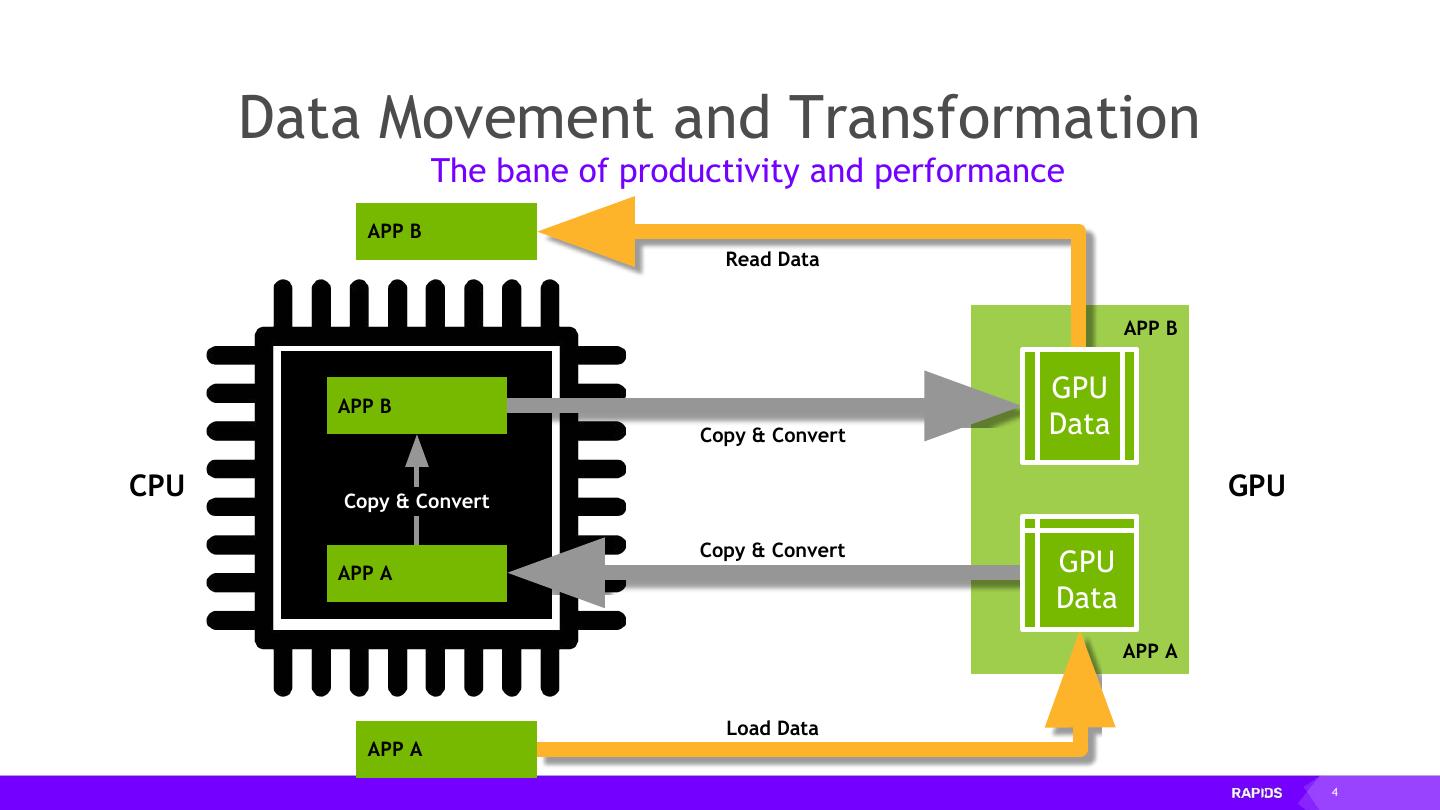
4 . Data Data Movement Movement and and Transformation Transformation The bane of productivity and performance APP B Read Data APP B APP B GPU Copy & Convert Data CPU Copy & Convert GPU Copy & Convert APP A GPU Data APP A Load Data APP A 4
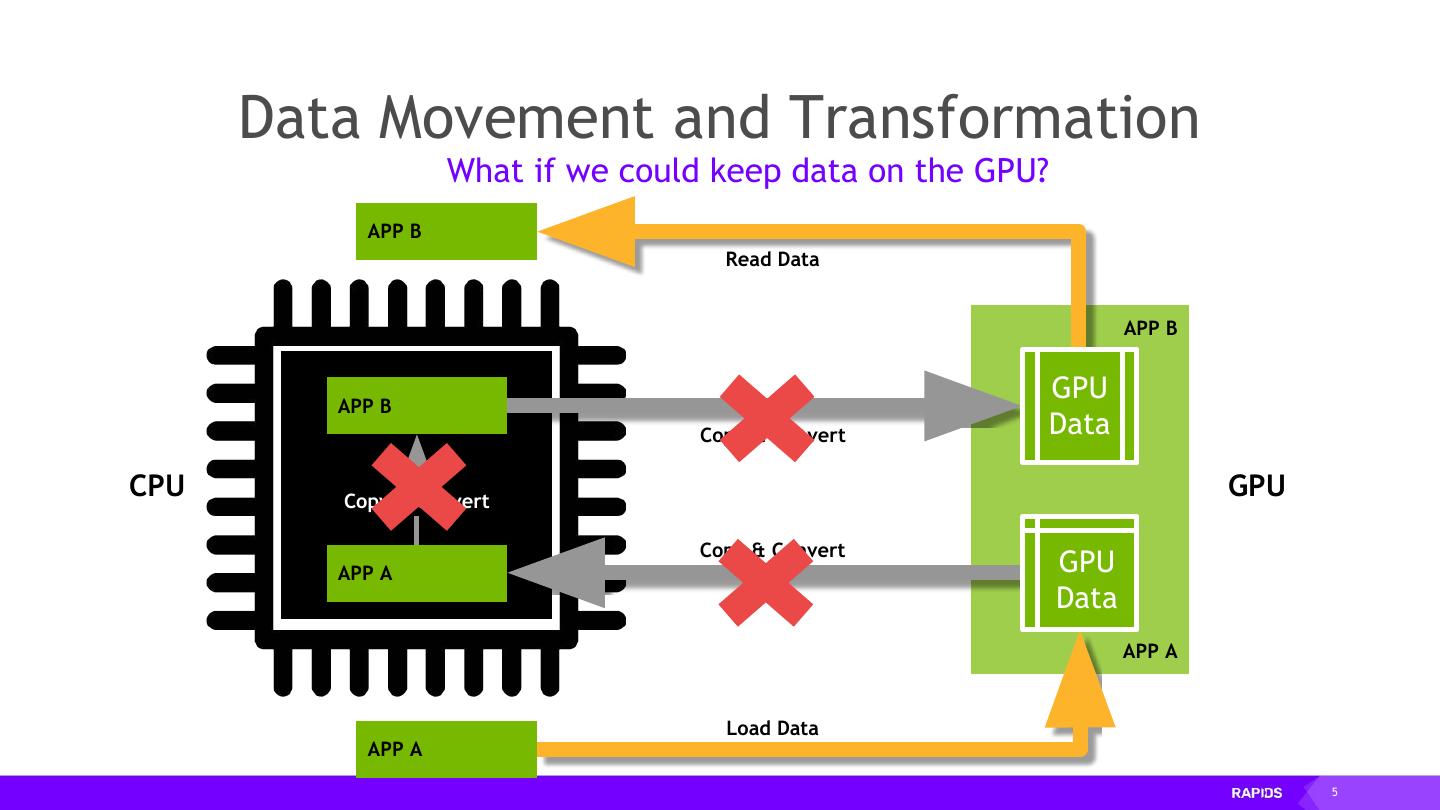
5 . Data Data Movement Movement and and Transformation Transformation What if we could keep data on the GPU? APP B Read Data APP B APP B GPU Copy & Convert Data CPU Copy & Convert GPU Copy & Convert APP A GPU Data APP A Load Data APP A 5
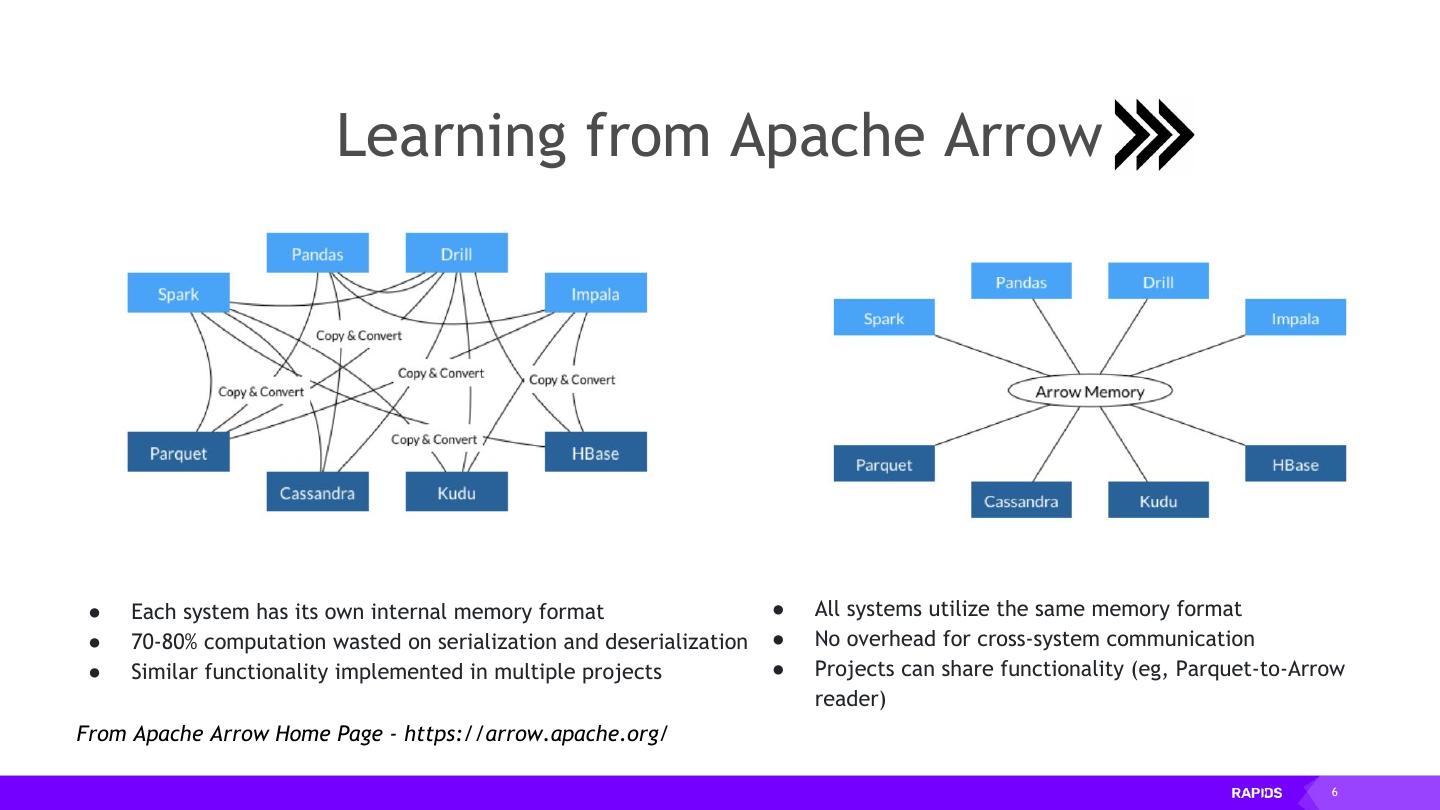
6 . Learning from Apache Arrow ● Each system has its own internal memory format ● All systems utilize the same memory format ● 70-80% computation wasted on serialization and deserialization ● No overhead for cross-system communication ● Similar functionality implemented in multiple projects ● Projects can share functionality (eg, Parquet-to-Arrow reader) From Apache Arrow Home Page - https://arrow.apache.org/ 6
7 . Data Processing Evolution Faster data access, less data movement Hadoop Processing, Reading from disk HDFS HDFS HDFS HDFS HDFS Read Query Write Read ETL Write Read ML Train Spark In-Memory Processing 25-100x Improvement Less code HDFS Language flexible Read Query ETL ML Train Primarily In-Memory Traditional GPU Processing 5-10x Improvement More code HDFS GPU CPU GPU CPU GPU ML Language rigid Query ETL Read Read Write Read Write Read Train Substantially on GPU RAPIDS 50-100x Improvement Same code Arrow ML Language flexible Query ETL Read Train Primarily on GPU 7
8 .RAPIDS Core 8
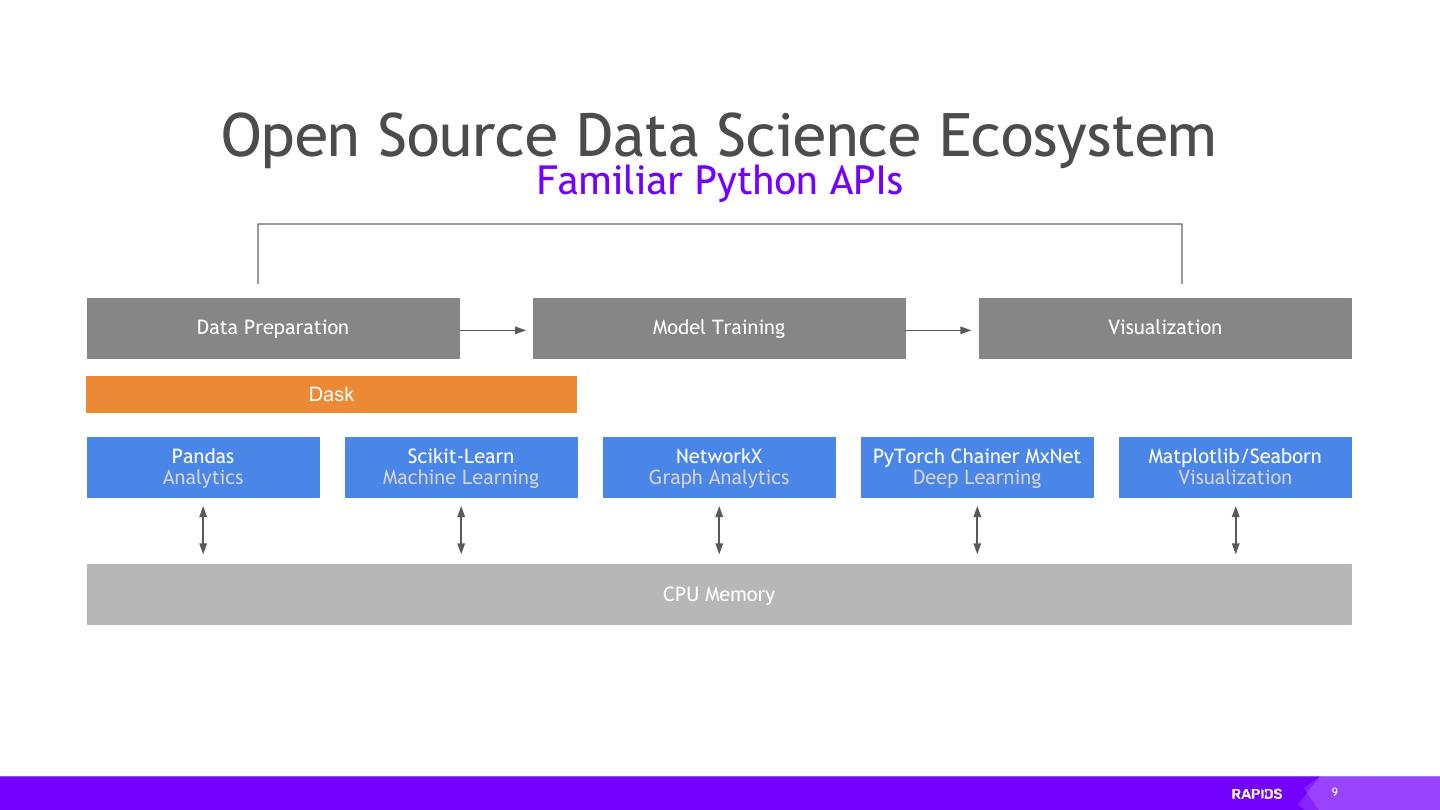
9 . Open Source Data Science Ecosystem Familiar Python APIs Data Preparation Model Training Visualization Dask Pandas Scikit-Learn NetworkX PyTorch Chainer MxNet Matplotlib/Seaborn Analytics Machine Learning Graph Analytics Deep Learning Visualization CPU Memory 9
10 . RAPIDS End-to-End Accelerated GPU Data Science Data Preparation Model Training Visualization Dask cuDF cuIO cuML cuGraph PyTorch Chainer MxNet cuXfilter <> pyViz Analytics Machine Learning Graph Analytics Deep Learning Visualization GPU Memory 10
11 .Dask 11
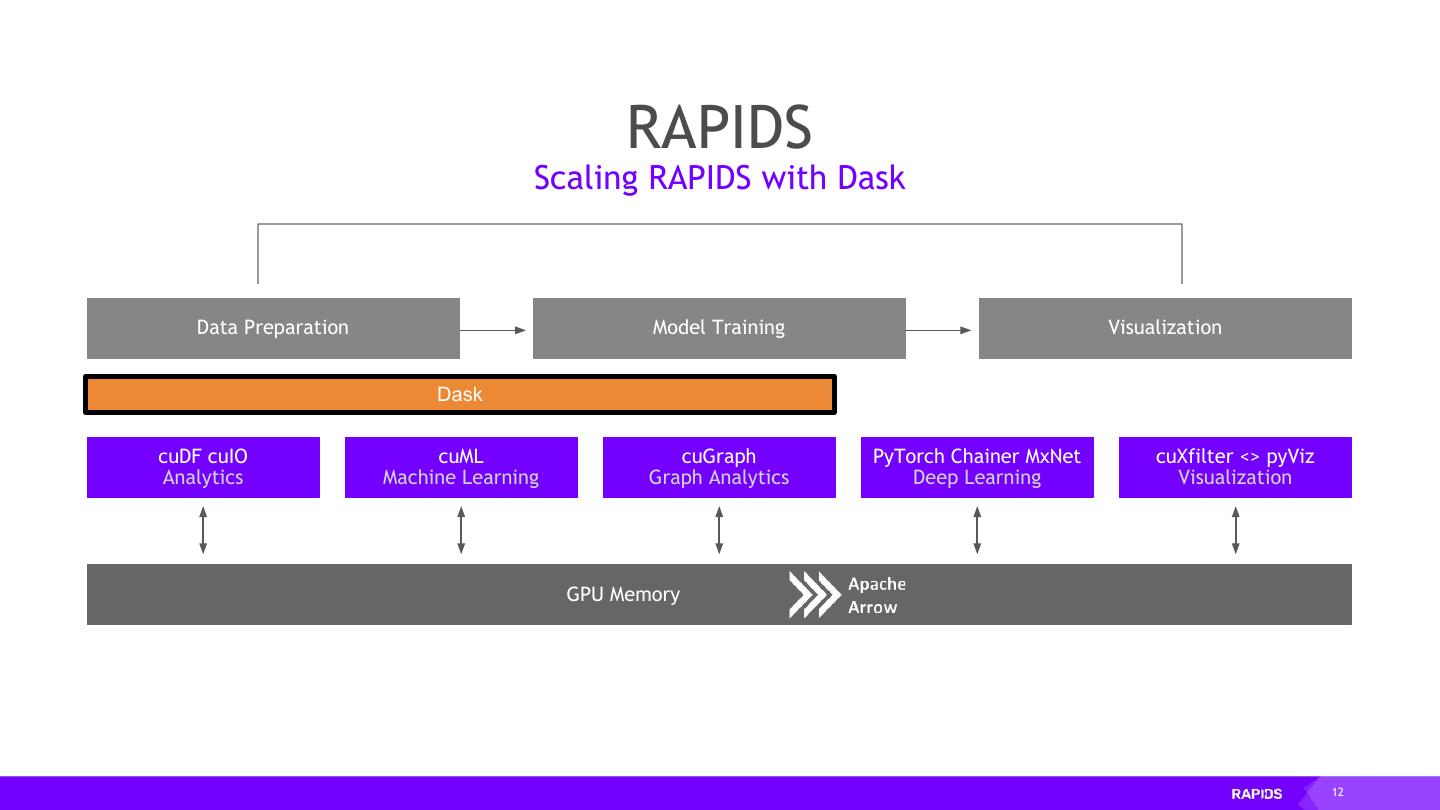
12 . RAPIDS Scaling RAPIDS with Dask Data Preparation Model Training Visualization Dask cuDF cuIO cuML cuGraph PyTorch Chainer MxNet cuXfilter <> pyViz Analytics Machine Learning Graph Analytics Deep Learning Visualization GPU Memory 12
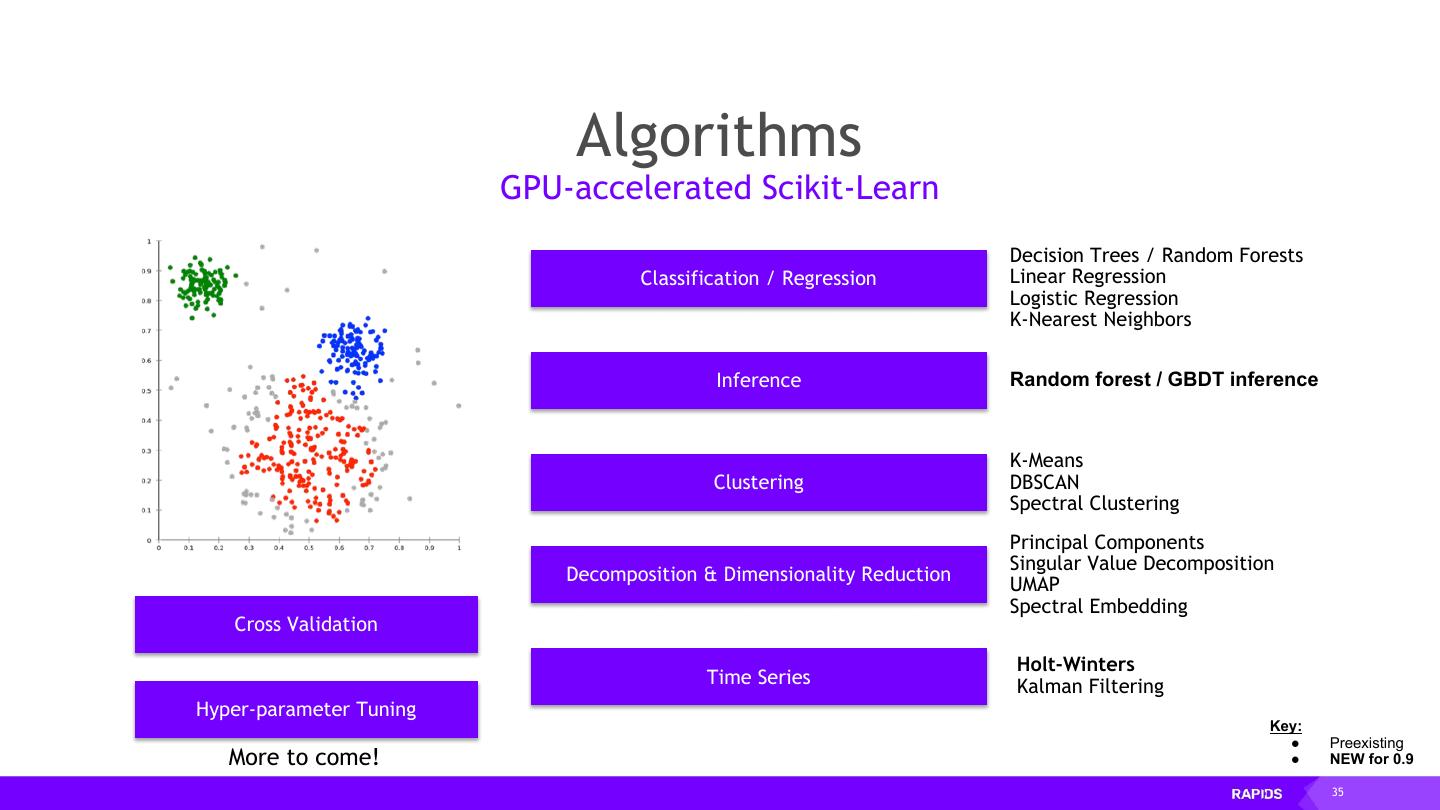
13 . Why Dask? PyData Native • Easy Migration: Built on top of NumPy, Pandas Scikit-Learn, etc. • Easy Training: With the same APIs • Trusted: With the same developer community Deployable Easy Scalability • HPC: SLURM, PBS, LSF, SGE • Easy to install and use on a laptop • Cloud: Kubernetes • Scales out to thousand-node clusters • Hadoop/Spark: Yarn Popular • Most common parallelism framework today in the PyData and SciPy community 13
14 . Why OpenUCX? Bringing hardware accelerated communications to Dask • TCP sockets are slow! • UCX provides uniform access to transports (TCP, InfiniBand, shared memory, NVLink) • Python bindings for UCX (ucx-py) in the works https://github.com/rapidsai/ucx-py • Will provide best communication performance, to Dask based on available hardware on nodes/cluster 14
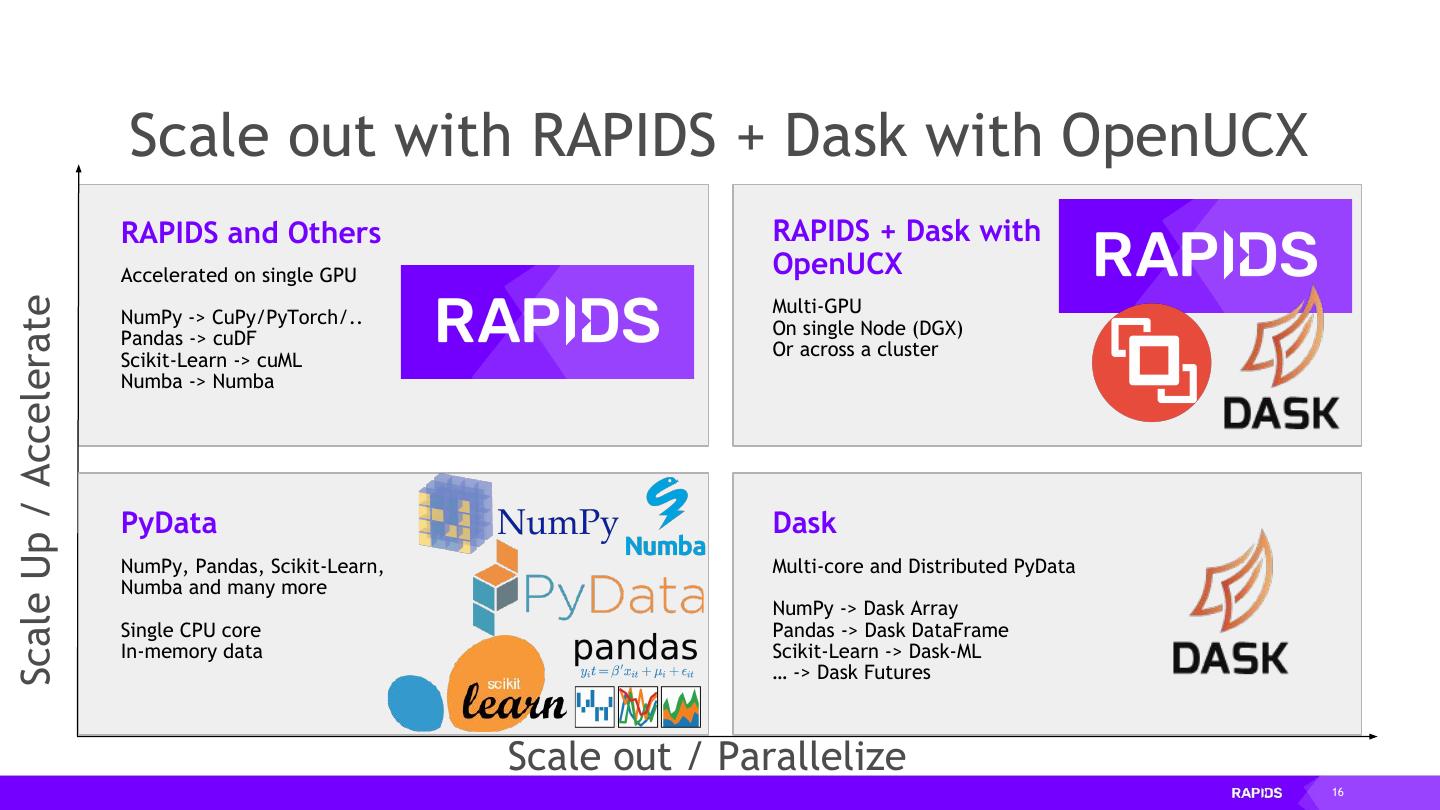
15 . Scale up with RAPIDS RAPIDS and Others Accelerated on single GPU Scale Up / Accelerate NumPy -> CuPy/PyTorch/.. Pandas -> cuDF Scikit-Learn -> cuML Numba -> Numba PyData NumPy, Pandas, Scikit-Learn, Numba and many more Single CPU core In-memory data 15
16 . Scale out with RAPIDS + Dask with OpenUCX RAPIDS and Others RAPIDS + Dask with Accelerated on single GPU OpenUCX Scale Up / Accelerate Multi-GPU NumPy -> CuPy/PyTorch/.. On single Node (DGX) Pandas -> cuDF Or across a cluster Scikit-Learn -> cuML Numba -> Numba PyData Dask NumPy, Pandas, Scikit-Learn, Multi-core and Distributed PyData Numba and many more NumPy -> Dask Array Single CPU core Pandas -> Dask DataFrame In-memory data Scikit-Learn -> Dask-ML … -> Dask Futures Scale out / Parallelize 16
17 .cuDF 17
18 . RAPIDS GPU Accelerated data wrangling and feature engineering Data Preparation Model Training Visualization Dask cuDF cuIO cuML cuGraph PyTorch Chainer MxNet cuXfilter <> pyViz Analytics Machine Learning Graph Analytics Deep Learning Visualization GPU Memory 18
19 . ETL - the Backbone of Data Science libcuDF is… CUDA C++ Library ● Low level library containing function implementations and C/C++ API ● Importing/exporting Apache Arrow in GPU memory using CUDA IPC ● CUDA kernels to perform element-wise math operations on GPU DataFrame columns ● CUDA sort, join, groupby, reduction, etc. operations on GPU DataFrames 19
20 .ETL - the Backbone of Data Science cuDF is… Python Library ● A Python library for manipulating GPU DataFrames following the Pandas API ● Python interface to CUDA C++ library with additional functionality ● Creating GPU DataFrames from Numpy arrays, Pandas DataFrames, and PyArrow Tables ● JIT compilation of User-Defined Functions (UDFs) using Numba 20
21 .Benchmarks: single-GPU Speedup vs. Pandas cuDF v0.9, Pandas 0.24.2 Running on NVIDIA DGX-1: GPU: NVIDIA Tesla V100 32GB CPU: Intel(R) Xeon(R) CPU E5-2698 v4 @ 2.20GHz Benchmark Setup: DataFrames: 2x int32 columns key columns, 3x int32 value columns Merge: inner GroupBy: count, sum, min, max calculated for each value column 21
22 . ETL - the Backbone of Data Science String Support Current v0.9 String Support •Regular Expressions •Element-wise operations • Split, Find, Extract, Cat, Typecasting, etc… •String GroupBys, Joins •Categorical columns fully on GPU Future v0.10+ String Support • Combining cuStrings into libcudf • Extensive performance optimization • More Pandas String API compatibility • JIT-compiled String UDFs 22
23 . Extraction is the Cornerstone cuIO for Faster Data Loading • Follow Pandas APIs and provide >10x speedup • CSV Reader - v0.2, CSV Writer v0.8 • Parquet Reader – v0.7, Parquet Writer v0.10 • ORC Reader – v0.7, ORC Writer v0.10 • JSON Reader - v0.8 • Avro Reader - v0.9 • GPU Direct Storage integration in progress for bypassing PCIe bottlenecks! • Key is GPU-accelerating both parsing and decompression wherever possible Source: Apache Crail blog: SQL Performance: Part 1 - Input File Formats 23
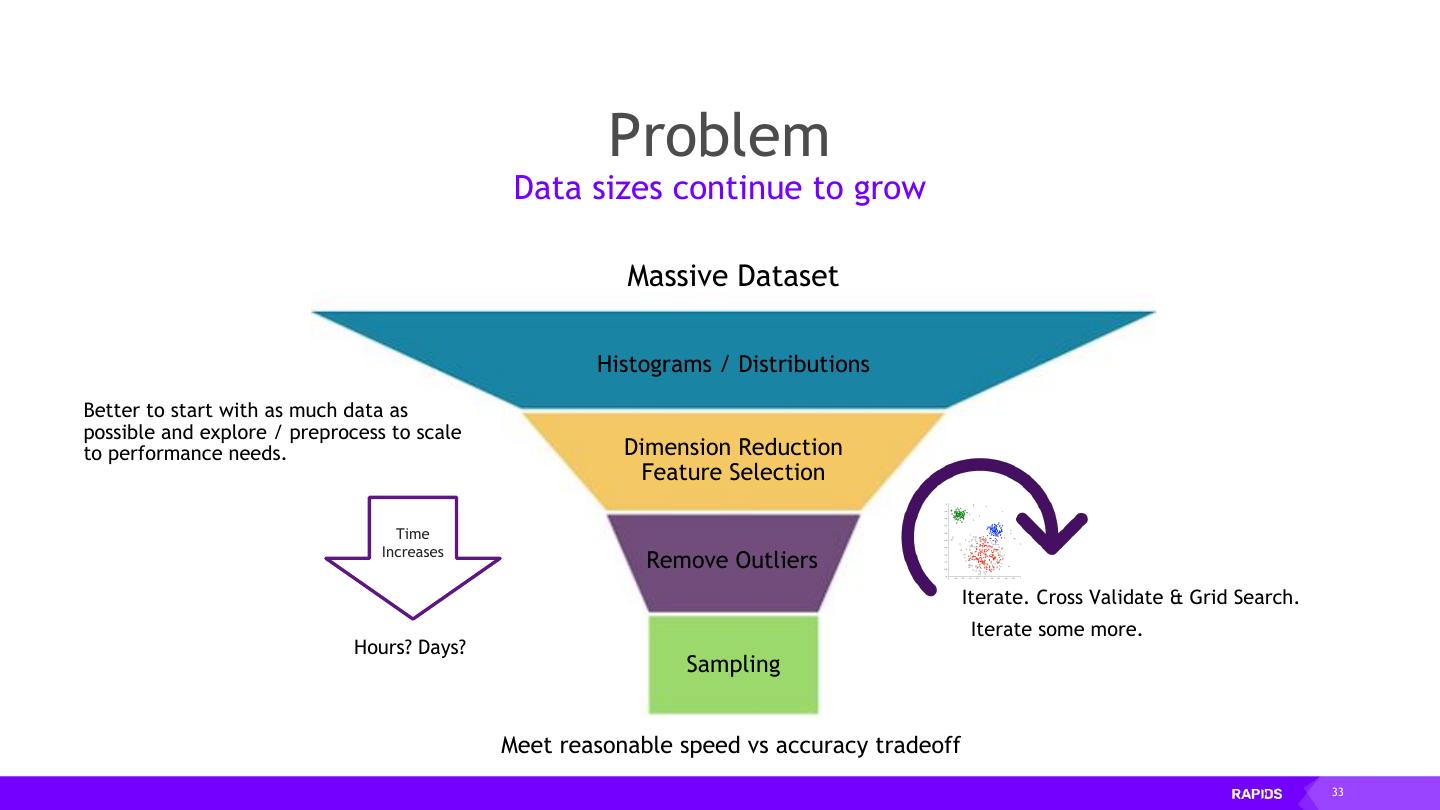
24 .ETL is not just DataFrames! 24
25 . RAPIDS Building bridges into the array ecosystem Data Preparation Model Training Visualization Dask cuDF cuIO cuML cuGraph PyTorch Chainer MxNet cuXfilter <> pyViz Analytics Machine Learning Graph Analytics Deep Learning Visualization GPU Memory 25
26 .Interoperability for the Win DLPack and __cuda_array_interface__ mpi4py 26
27 .Interoperability for the Win DLPack and __cuda_array_interface__ mpi4py 27
28 .ETL – Arrays and DataFrames Dask and CUDA Python arrays • Scales NumPy to distributed clusters • Used in climate science, imaging, HPC analysis up to 100TB size • Now seamlessly accelerated with GPUs 28
29 . Benchmark: single-GPU CuPy vs NumPy More details: https://blog.dask.org/2019/06/27/single-gpu-cupy-benchmarks 29
3秒后跳转登录页面
去登陆

